企業は通常、BI (ビジネス インテリジェンス) を使用して迅速かつ適切な意思決定を行うための重要な洞察を得るために、膨大な量のデータを生成して保管します。 このデータは混在し複雑であるため、生産的で費用対効果の高いデータ分析が必要です。 データ自動化は、この目的を達成するために実装および統合できる重要なプロセスです。
データ自動化とは
データの自動化は、これらの手順を手動で行うのではなく、自動化されたテクノロジーを利用してデータを処理、アップロード、および処理することと解釈されます。 データ パイプライン デバイスの長期的な実行可能性は、データ取り込み方法の自動化に依存しています。 更新されたデータは、個人が他の義務とともに取得しなければならない追加のタスクであるため、停止される危険性があります。 データ自動化は、データ エコシステムの手動労働を、コンピューターとユーザーに代わって機能する方法で復元します。
この手順では、人間の介入なしに、インテリジェントなプロセス、人工知能、インフラストラクチャ、およびソフトウェアを利用して、データをコンパイル、保存、変換、および分析します。 データ ソーシングを自動化することで、企業の効率を高めながら、時間とお金を節約できます。 データ自動化は、データが構造化された方法で確実にパックされるようにすることで、エラーを削減するという利点もあります。 会社が適切な道を進むためには、データから主要なビジネスの理解を収集する必要があります。 結果として、自動化されたデータ分析手順を持つことで、ビジネス ユーザーはデータの準備ではなくデータ分析に集中できます。
データ自動化の要素
抽出、変換、およびロードは、データ自動化の XNUMX つの中心的なコンポーネントであり、以下に特徴があります。
エキス: 単一またはさまざまなソース システムからのデータの抽出が含まれます。
最適化の適用: CSV フラット ファイル形式のように、データを必要な構造に適合させます。 これには、州の単語全体ですべての州の略語を復元することが含まれる場合があります。
負荷: この問題では、オープン データ ポータルは、ある操作から別の操作にデータを転送します。
データのアップロードを完全に自動化し、適切に完了するには、各ステップが重要です。
データ処理の自動化を検討していますか?
Nanonets のノーコード ワークフロー プラットフォームを無料で使用して、クリーニング、抽出、解析などのデータ タスクを自動化します。 私たちのチームに連絡することができます 複雑なユース ケースがある場合は、複雑なユース ケースを設定します。
データ自動化の利点
業界は、データ自動化から広範囲に支援できます。 これらの目標は、以下で詳しく理解されています。
処理時間の短縮
異種の参照からの膨大なデータを処理することは、単純な作業ではありません。 さまざまなソースから抽出されたデータは、形式が異なります。 統合ネットワークに詰め込む前に、形式化して評価する必要があります。 自動化は、データ パイプラインの一部を形成する雑用を処理するために多くの時間を取り戻します。 また、手作業による介入が減少するため、予備の使用率が低くなり、時間の節約になり、データの信頼性が向上します。
スケーリング能力とパフォーマンスの向上
データ自動化により、データ セットのスケーラビリティとパフォーマンスが向上します。 たとえば、変更データ キャプチャ (CDC) を容易にすることで、ソース レベルで行われたすべての変更が、トリガーに基づいて投資システム全体で生成されます。 これとは対照的に、データの雑用を手動で更新するには時間がかかり、かなりの専門知識が必要です。
自動化されたデータ統合機器を使用すると、データのパッキングと CDC の調整を同時に行うことが、ビジュアル デザイナーでオブジェクトを持ち上げたり降ろしたりするだけです。 自動化によって分析の勢いを高めることができます。 分析で人間の入力がほとんど必要ない場合、データ サイエンティストはより迅速に分析を実行でき、コンピューターは複雑で時間のかかる作業を人間に代わって効率的に実行できます。 膨大なデータを効率的に評価するための鍵は自動化です。
コスト効率
自動化されたデータ分析は、業界の時間と費用を回収します。 データ分析中の従業員の時間は、コンピューティング リソースよりもコストがかかり、デバイスは分析を迅速に実行できます。
より良い時間配分
データ サイエンティストは、人間の独創性をあまり期待しない割り当てを自動化することで、意思決定をサポートするための新鮮な洞察を生み出すことに集中できます。 データ チームの何人かのメンバーは、データ分析の自動化の恩恵を受けています。 これにより、データ サイエンティストは、高品質で完全な最新のデータを処理できるようになります。
顧客体験の向上
優れた製品やサービスを提供するだけでは十分ではありません。 消費者もあなたとの楽観的な経験を予測します. 会計委員会から消費者ケアまで、データ自動化により、教職員は関連データをすぐに利用できるようになり、クライアントのニーズを満たすことができます。
データ品質の向上
膨大な量のデータを手動で処理すると、人的ミスの危険にさらされ、データの追跡を維持するために時代遅れで統合が不十分なテクノロジに依存すると、同じ困難に直面することになります。 エラーのない技術に適したデータ処理
販売戦略と管理
販売およびマーケティング委員会は、詳細なデータに基づいて良好な見込み客を特定し、適応したキャンペーンを通じてそれらを達成します。 データ自動化により、データを一貫して最新の状態に維持できるようになり、成功への最大の機会がもたらされます。
組織内のデータを自動化する方法は?
組織内のデータを自動化するための適切なプロセスを確保する必要があります。 データの自動化を開始する手順は次のとおりです。
データを特定します。
自動化する必要があるデータを特定します。 データを取得できるデータセットを選択し、データをダウンロードまたは編集するための適切なアクセス権があることを確認してください。
適切なデータ自動化プラットフォームを選択する
データを適切に収集、分析、報告するための適切なツールセットがあることを確認してください。 選択したプラットフォームがすべてのビジネス ソフトウェアと統合され、日常的なデータ タスクを簡単に自動化するためのワークフロー自動化機能を備えていることを確認してください。 これにより、戦略と実装に集中できる従業員の余分な負担が軽減されます。
ETL プロセスの開発とテスト
データ処理のすべてのステップを計画します。 接続するデータ ソース、選択する必要がある変数、必要な値の形式、および出力で期待される内容を把握します。
適切な ETL プロセスは、ルールベースのワークフローでデータの自動化を合理化できます。
自動化された作業のスケジューリング
データセットが毎日改訂されるように計画します。 更新頻度、データ収集、および更新頻度に関して、データ インベントリの一部としてコンパイルしたメタデータ領域に関係することができます。
自動化手順の明確な目標と期待を事前に設定すると、自動化手順が実装された後にチームが効果的に協力し、その改善を追跡するのに役立ちます。
エンタープライズ データ自動化のためのナノネット
Nanonets は、高度なワークフロー自動化とクラス最高の OCR ソフトウェアを備えた AI ベースのインテリジェント ドキュメント処理ソフトウェアです。 Nanonets は、自動操縦であらゆるドキュメント (画像、手書きの画像、PDF など) からデータを抽出できます。 ノーコード ワークフローを使用して、次のようなタスクを実行できます。
そして、もっと。
Nanonets は完全にカスタマイズ可能なプラットフォームです。つまり、ユース ケースや要件に応じてカスタマイズできます。 ナノネットは、金融、建設、物流、医療、銀行など、複数の業界で使用されています。
Nanonets でのデータ自動化の簡単な使用例を見てみましょう。
データフォーマットの自動化
Nanonets の PDF ドキュメントから表形式のデータを抽出する
Nanonets でデータ自動化を行うには?
企業には多くのドキュメントがあり、手動で実行する必要がある多くのタスクがありますが、ナノネットを使用して自動化できます。
どの会社も購入しています。 また、ベンダーや社内チームから複数のドキュメントを受け取ります。これらは、支払いが行われる前に確認する必要があります。
組織が発注書、販売注文書、および請求書間のデータ照合を自動化し、承認、その後の支払い、およびデータのアップロードを自動化する方法について、ユース ケースを取り上げてみましょう。
Nanonets での流れは次のようになります。
ステップ1: ドキュメントは自動的にプラットフォームにアップロードされます。 Nanonets プラットフォームはドキュメント タイプを自動的に識別し、ドキュメントを送信してドキュメントからデータを抽出します。

ステップ2: データが抽出されたら、今度はデータを照合します。

抽出されたデータから値を参照し、データを一致させることができます。 不一致がある場合、ファイルは手動レビューのために転送されます。 ノーコード ワークフロー ブロックを使用してトリガーを簡単に追加できます。
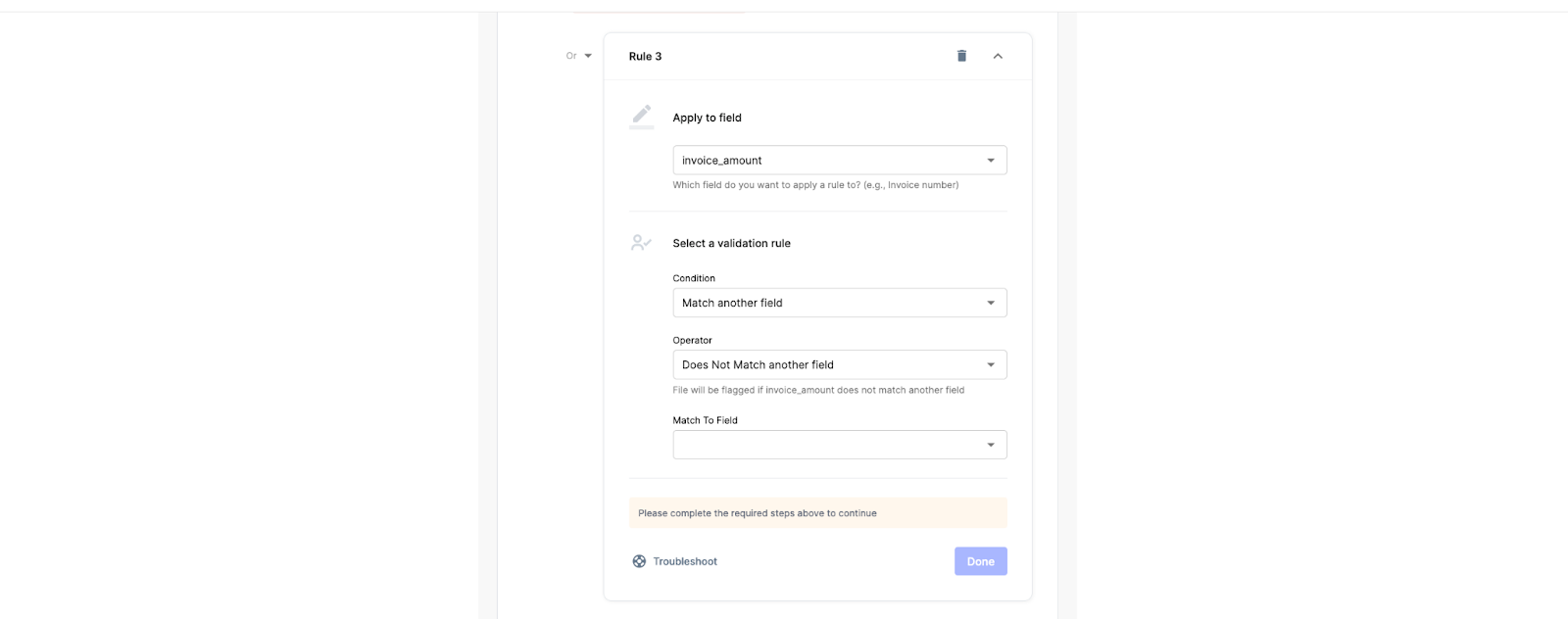
ステップ4: すべてがクリアされたら、支払いリクエストをに送信できます ナノネットの流れ.

これは、ナノネットでデータを自動化できる方法の XNUMX つにすぎません。
ナノネットは、以下を含むさまざまなタスクに使用できます。
別のユースケースをお考えの場合は、お問い合わせください。 コードなしのワークフローを使用して、わずかなコストでデータの抽出、処理、およびアーカイブを自動化できます。
どのデータを自動化する必要がありますか?
可能な限り多くのデータを! データをアップロードするための「デフォルトで自動化する」戦略を承認すればするほど、高品質のデータを維持するために長期的に必要となる限られた予約が必要になります。 自動アップロードの候補データセットを見つけるためのアドバイスを次に示します。
- データセットは四半期ごとまたはそれ以上の頻度で編集されますか?
- アップロード後にデータセットに変更または何らかの形の操作を行う必要がありますか?
- データセットは巨大ですか (250MB 以上)?
- ファイル全体ではなく、連続する更新ごとに変更された行のみを取得できますか?
- 個人からではなく、ソース ネットワークからデータを取得していることは明らかですか?
上記の質問のいずれかに「はい」と答えるデータセットは、更新の自動化に最適です。自動化により、後でリソースと時間が不足するリスクを排除できるからです。
データ自動化戦略を理解する
企業にとって包括的なデータ自動化の提案を行うことは重要です。 技術を長期間維持することで、社内で適切なタイミングで適切な人材を雇用することができます。 堅牢なデータ自動化技術がなければ、企業は本来あるべきルートから逸脱し、時間とリソースを浪費することになります。 また、逸失利益という点で追加のお金になる可能性もあります。 結果として、データ プロセスの自動化の提案は、業界の目標と一致する必要があります。
Nanonets のノーコード ワークフローを使用して、ありふれたデータ処理タスクをエラー 0 で自動化します。
データ自動化戦略を策定するには?
以下に、データ自動化戦略を策定するために試みることができるいくつかのポイントを示します。
問題の特定
あなたの会社のどのコア地域が自動化の助けになるかを推測してください。 データ自動化が役立つ可能性がある場合のみを検討してください。 これを評価してください: データ調査員の時間のどれくらいが物理的な作業に費やされていますか? データ システムのどの要素が常に失敗していますか? 強化できるすべての手順のリストを作成します。
データの分類
データ自動化の準備段階では、重要性とアクセシビリティに基づいてソース データを分類します。 ソース システム インデックスを調べて、エントリがある参照も確認します。 自動データ抽出ツールを利用する場合は、ビジネスにとって重要なフォーマットにメリットがあることを確認してください。
業務の優先順位付け
費やされた時間を使用して、手順の重要性を評価します。 肉体労働に費やされる時間が長いほど、収益に対する自動化の影響が大きくなります。 プロセスを自動化するために必要な時間に特定の特性を持たせます。 業界の所有者に自動化の重要性を示しながら、全員の精神を維持するため、鋭い勝利は進むべき手段です。
必要な変換の概要
次のステージでは、ソース データをターゲット数量に復元するために必要な変更を指定します。 難しい頭字語を全文単語に変換するのと同じくらい簡単な場合もあれば、リレーショナル データベースを CSV ファイルに変換するのと同じくらい複雑な場合もあります。 データ自動化中に意図した結果を達成するために不可欠な変換を指定することは非常に重要です。 そうしないと、データセット全体が汚染される可能性があります。
業務の遂行
データ技術の実行は、技術的に最も問題のあるコンポーネントです。 これらは、適切なレポート、エンジニアリング パイプライン、適切な機械学習方法という XNUMX つの異なるプロセスを実装しています。
更新のためのデータのスケジュール
次のステップは、データを記録して、通常の基準で改訂されるようにすることです。 このフェーズでは、ワークフローの自動化、タスクのスケジューリングなどのプロセス自動化機能を備えた ETL 製品を利用するように指示されます。 これにより、物理的な介入なしで手順が実行されることが保証されます。
反復的な手動タスクを自動化したいですか? 効率を高めながら、時間、労力、お金を節約しましょう!
データ自動化の欠点
データの自動化はビジネスに役立ちますが、いくつかの欠点があります。
欠点の XNUMX つは、データ自動化を使用するには多額の費用がかかることです。 決定を下す前に、どれだけの費用を費やす必要があるか、および自動化を使用することでどれだけの利益が得られるかを検討する必要があります。
もう XNUMX つの欠点は、インテリジェントな自動化によって仕事が奪われる可能性があることです。 必要がなくなったために仕事を失う人もいます。 しかし、これは必ずしも悪いことである必要はありません。 インテリジェントなデータ自動化は、人々がよりエキサイティングで重要な仕事をするのを助け、ビジネスがより多くのお金を稼ぎ、新しい仕事を生み出すのに役立ちます。
最後に、特に生産手順が変更された場合、データの自動化が反復的になることがあります。 新しい製品や生産方法に合わせて自動化システムを簡単に変更できるようにすることが重要です。
別のユースケースを考えている場合は、お問い合わせください。 コードなしのワークフローを使用して、わずかなコストでデータの抽出、処理、およびアーカイブを自動化できます。
Nanonets でのデータ処理の詳細については、こちらをご覧ください。
よくあるご質問
ソース データの自動化
これは、ソース ネットワークからデータを抽出することによって達成されるデータの自動化のようなものです。 ソースデータの自動化があります。 スーパーマーケットでバーコードリーダーを使用するのと同じようにデータを挿入することを意味します。 これにより、店舗の所有者は、次の四半期の在庫に関する結論を出すために、販売と在庫を調整するために必要なすべてのデータを簡単に入手できます。
これは、人間の努力と不確実性を根絶するため、好ましいデータ入力手法です。 従来のデータ入力技術では、紙で情報を取得し、それを自動化されたデータベース管理ソフトウェアに転送して検査する必要がありました。 人間の作業は、エラー、冗長性、不正確さ、および誤った計算に向けられた一貫性のないデータから解放される傾向があまりありません。
したがって、Source Data Automation デバイスはデータをすぐにフィードするため、すぐにアクセスできるデータを処理する準備が整います。 コンピュータは一貫性と計算を保持しているため、このプロセスの精度に疑問を呈することはできません。
ソースデータ自動化の例は?
データの自動化により、商用データ入力がより詳細でアクセスしやすくなり、不正確な作業を避けられない仕事をしてくれる人を雇うための莫大なコストが節約されました.
たとえば、個人がダイナーで注文を見つけた場合、料金はタッチ スクリーンを介してデータベースに即座に記録されます。 したがって、データがダイナーによって XNUMX 回文書化されているとは想定されません。 ほとんどのファーストフード チェーンや小売店では、これらの展示品をワークステーションで使用しています。 これらのアプライアンスの目的は、正確な請求書の作成とは別に、ソース データの自動化です。
ソースデータ自動化の追加の利点は、手動入力の必要性を根絶することにより、各消費者がチェックアウトカウンターで費やす時間がほとんどないことです. すべてのスーパーマーケットは、商品のバーコードを見つけて、チェックアウトの瞬間にスキャンし、すべての重要な情報を記録し、請求書を作成できます。 コンパイルされたデータは、どの製品が在庫内の他の製品よりも速く売れているかに関するデータを提供し、所有者に補充するのに十分な時間を提供します.
評価には、MICR によって解読される磁気コーディングも含まれているため、小切手処理がよりシンプルで費用対効果の高いものになります。 カウンター オペレーターが各消費者を処理するために節約した時間を、毎日より多くの消費者にサービスを拡大するために使用できるため、組織は繁栄することができます。 ソースデータの自動化に使用される機器の一部を次に示します。
ソース データ入力装置は、データを一貫した形式で迅速に調べて、コンピューターに入力することを目的としています。 それらのいくつかは次のとおりです。
データ入力デバイス
スキャナーズ: スキャナは光感知技術を利用して、その前に置かれた肖像画を読み取り、デジタル形式でコンピュータに保存します。
バーコードリーダー: バーコードリーダーは、その名の通り、バーコードを調べて理解するために使用されます。 これらのバーコードは、製品とそのレートに関するすべてのデータを含むプログレス コーディング シンボルです。 リーダーがコードを調べると、コンピューターに保存されているデジタル レイアウトに変換されます。
無線自動識別 (RFID): RFID はマイクロチップを使用してラベルを検査します。 各マイクロチップにはエネルギー源があり、RFID によって検査されたコード番号が含まれています。 このより高度なデータ自動化手法は、さまざまなシナリオでバーコード リーダーを刷新し始めています。
MICR – 磁気インク文字認識: これらは、小切手の底に発行されているような、磁化されたインクを読み取る実質的な認識装置です。
OMR — 光学式マーク認識: 候補者の合計をテストに保存し、一意の OMR 用紙に鉛筆のマークを付けます。 空白の光と曖昧さを利用してデータを識別します。
OCR — 光学式文字認識: 消費者に手動でフィードバックフォームに記入してもらうさまざまな機関は、分析よりもメーリングリストを改善するために電子メールアドレスを必要としています. OCR ソフトウェアを使用して、手書きのメッセージをコンピュータで編集可能なスクリプトに復元できます。 この装置はハンドヘルド スキャナーのように見え、データをコンピューターに保存できるデジタル レイアウトに変換します。
ビッグデータの自動化とは?
ビッグデータは、組織とデジタルのランドスケープの機能に革命をもたらしました。 分析は、従業員の業績または市場の特定の製品のすべての不一致に疑問を投げかけています. この優れたテクノロジーにより、教育機関はバージョンを修正するか理解するかにかかわらず、バージョンのパターンを見つけることができます。
しかし、ビッグデータの編集は、人的および資金的リソースが不足しているため、組織にとって問題を引き起こす可能性があります。 幸いなことに、データの自動化は業界を救い、関連する手動操作なしでデータ収集を可能にしました。 このようにして、物理的な努力を修正するための追加のステップを経る必要なく、投影を達成することができます。
データ アクセスと所有権について
チームの配置に応じて、さまざまなグループが ETL プロセスの要素を所有します。
一元化されたデータ アクセスと操作
ETL 手順全体とデータ自動化は、主要な IT 部門によって取得されます。
ハイブリッド データ アクセスと操作
選択と変換の方法は通常、別々の機関やオフィスが取得しますが、中央の IT 機関がロード手順を取得することがよくあります。
分散型データ アクセスと操作
各機関またはオフィスは、独自の ETL 手順を担当します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/data-automation/

