本日、Meta が開発した Code Llama 基盤モデルが、以下を通じてお客様に提供されることを発表できることを嬉しく思います。 Amazon SageMaker ジャンプスタート ワンクリックでデプロイして推論を実行できます。 Code Llama は、コードと自然言語プロンプトの両方からコードとコードに関する自然言語を生成できる最先端の大規模言語モデル (LLM) です。このモデルを SageMaker JumpStart で試すことができます。SageMaker JumpStart は、アルゴリズム、モデル、ML ソリューションへのアクセスを提供する機械学習 (ML) ハブであり、ML をすぐに始めることができます。この投稿では、SageMaker JumpStart 経由で Code Llama モデルを検出してデプロイする方法を説明します。
コードラマ
Code Llamaは、から発売されているモデルです。 Meta この最先端のモデルは、開発者が高品質で十分に文書化されたコードを作成できるようにすることで、開発者のプログラミング タスクの生産性を向上させるように設計されています。このモデルは、Python、C++、Java、PHP、C#、TypeScript、Bash に優れており、開発者の時間を節約し、ソフトウェア ワークフローをより効率的にする可能性があります。
これには、幅広いアプリケーションをカバーするように設計された 7 つのバリアントがあり、基本モデル (Code Llama)、Python に特化したモデル (Code Llama Python)、および自然言語命令を理解するための命令追従モデル (Code Llama Instruct) です。すべての Code Llama バリアントには、13B、34B、70B、および 7B パラメータの 13 つのサイズがあります。 2B および 500B のベースおよび命令バリアントは、周囲のコンテンツに基づいた埋め込みをサポートしているため、コード アシスタント アプリケーションに最適です。モデルは Llama 100 をベースとして設計され、その後 100,000 億トークンのコード データでトレーニングされ、Python 特化バージョンは増分 16,000 億トークンでトレーニングされました。 Code Llama モデルは、最大 100,000 個のコンテキスト トークンを含む安定した世代を提供します。すべてのモデルは XNUMX トークンのシーケンスでトレーニングされ、最大 XNUMX トークンの入力で改善が見られます。
このモデルは同じ下で入手可能です Llama 2 としてのコミュニティ ライセンス。
SageMaker の基盤モデル
SageMaker JumpStart は、Hugging Face、PyTorch Hub、TensorFlow Hub などの一般的なモデル ハブのさまざまなモデルへのアクセスを提供し、SageMaker の ML 開発ワークフロー内で使用できます。 ML の最近の進歩により、として知られる新しいクラスのモデルが誕生しました。 基礎モデルこれらは通常、数十億のパラメータでトレーニングされ、テキストの要約、デジタル アートの生成、言語翻訳など、幅広いカテゴリのユースケースに適応できます。これらのモデルのトレーニングにはコストがかかるため、顧客はこれらのモデルを自分でトレーニングするのではなく、既存の事前トレーニングされた基礎モデルを使用し、必要に応じて微調整することを望んでいます。 SageMaker は、SageMaker コンソールで選択できる厳選されたモデルのリストを提供します。
SageMaker JumpStart 内でさまざまなモデルプロバイダーの基礎モデルを見つけることができるため、基礎モデルをすぐに開始できます。さまざまなタスクやモデルプロバイダーに基づいて基礎モデルを検索し、モデルの特性や使用条件を簡単に確認できます。テスト UI ウィジェットを使用してこれらのモデルを試すこともできます。基礎モデルを大規模に使用したい場合は、モデルプロバイダーから事前に構築されたノートブックを使用することで、SageMaker を離れることなく使用できます。モデルは AWS でホストおよびデプロイされるため、モデルの評価または大規模な使用に使用されるデータが第三者と共有されることは決してないので、ご安心ください。
SageMaker JumpStart で Code Llama モデルを発見する
Code Llama 70B モデルを展開するには、次の手順を実行します。 Amazon SageMakerスタジオ:
- SageMaker Studio のホームページで、 ジャンプスタート ナビゲーションペインに表示されます。
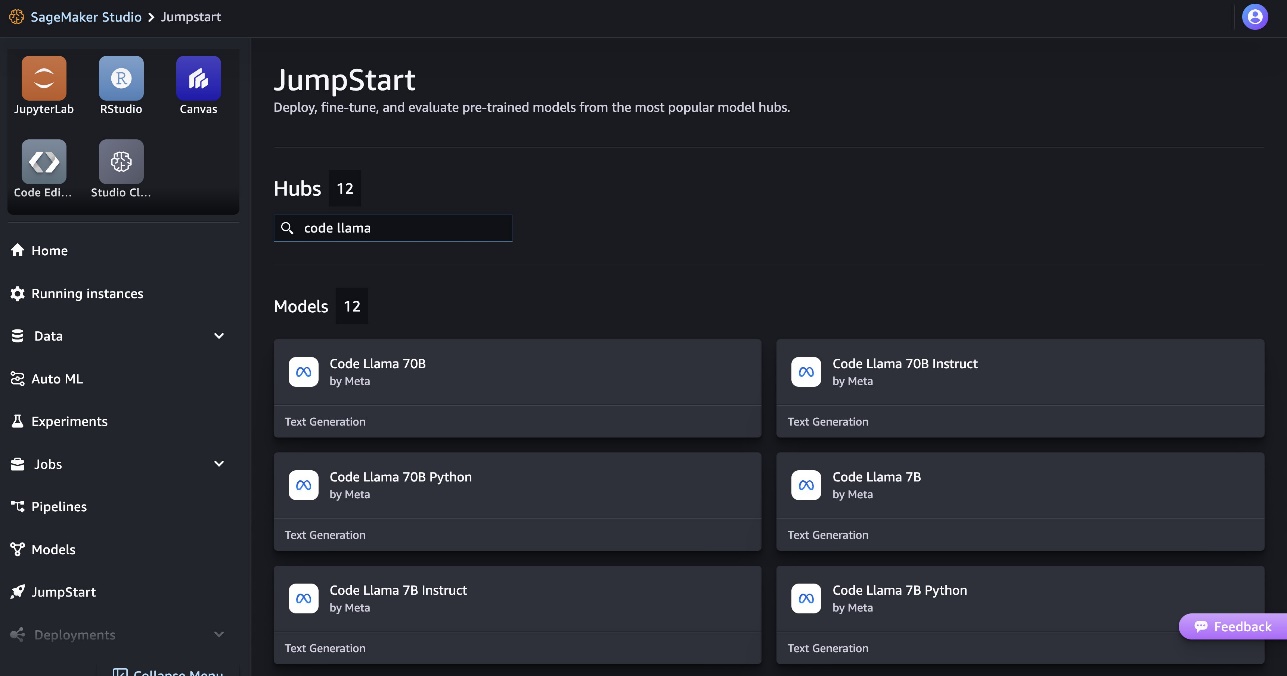
- Code Llama モデルを検索し、表示されたモデルのリストから Code Llama 70B モデルを選択します。
モデルの詳細については、Code Llama 70B モデル カードをご覧ください。
次のスクリーンショットは、エンドポイント設定を示しています。オプションを変更することも、デフォルトのオプションを使用することもできます。
- エンドユーザー使用許諾契約書 (EULA) に同意し、選択します。 配備します.
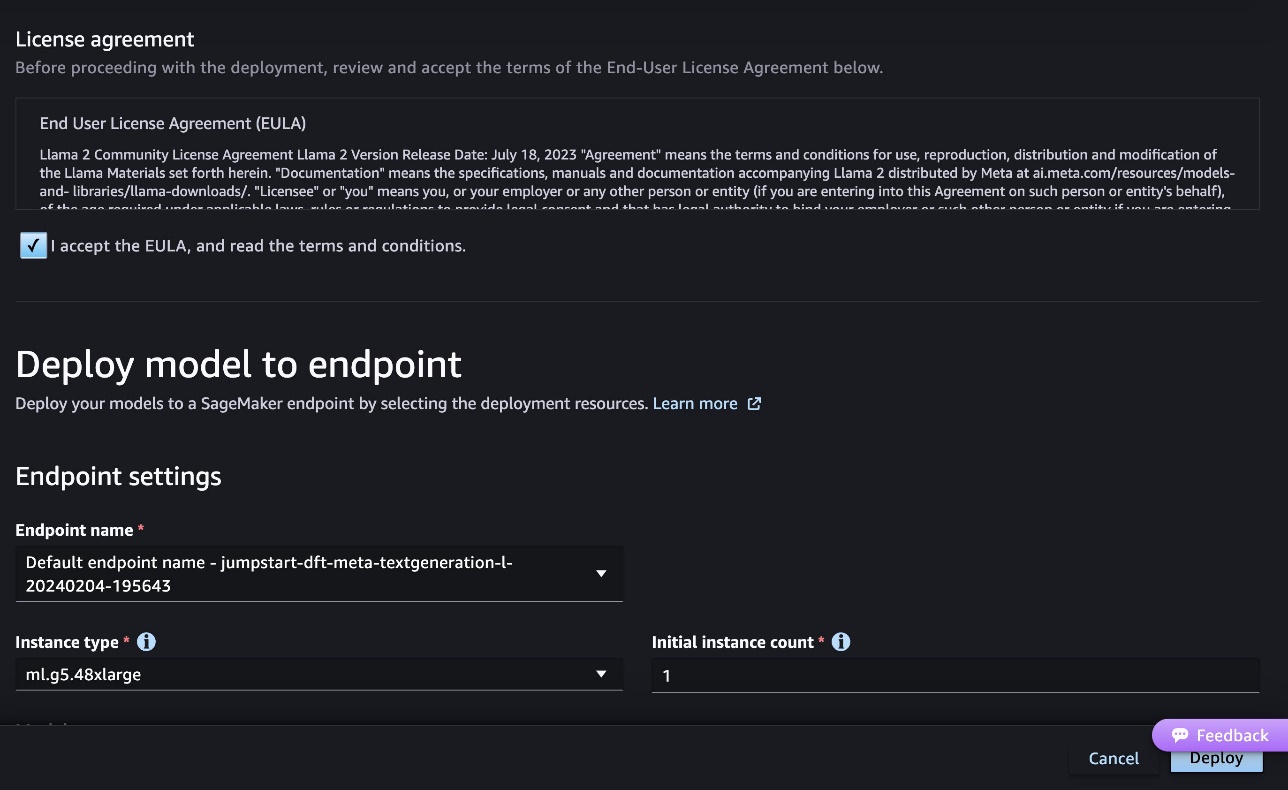
これにより、次のスクリーンショットに示すように、エンドポイント展開プロセスが開始されます。
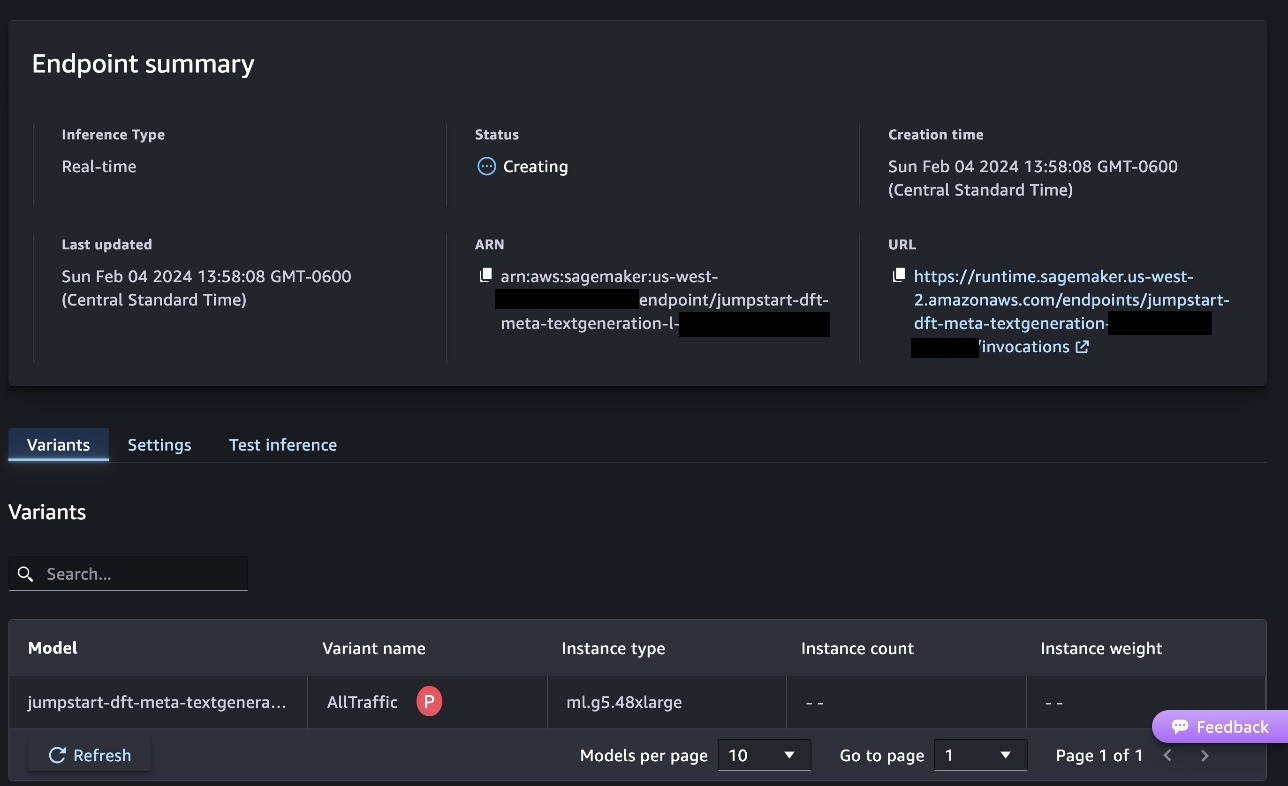
SageMaker Python SDK を使用してモデルをデプロイする
あるいは、選択してサンプル ノートブックを通じてデプロイすることもできます。 ノートブックを開く Classic Studio のモデル詳細ページ内。サンプル ノートブックは、推論用のモデルをデプロイし、リソースをクリーンアップする方法に関するエンドツーエンドのガイダンスを提供します。
ノートブックを使用してデプロイするには、まず、 model_id。 次のコードを使用して、選択したモデルのいずれかを SageMaker にデプロイできます。
これにより、デフォルトのインスタンス タイプやデフォルトの VPC 構成などのデフォルト構成でモデルが SageMaker にデプロイされます。 これらの構成は、デフォルト以外の値を指定することで変更できます。 ジャンプスタートモデル。デフォルトでは、 accept_eula に設定されています False。 設定する必要があります accept_eula=True エンドポイントを正常にデプロイします。これにより、前述のユーザー使用許諾契約および利用規定に同意したことになります。あなたもすることができます ダウンロード ライセンス契約。
SageMaker エンドポイントを呼び出す
エンドポイントがデプロイされたら、Boto3 または SageMaker Python SDK を使用して推論を実行できます。次のコードでは、SageMaker Python SDK を使用して推論用のモデルを呼び出し、応答を出力します。
関数 print_response ペイロードとモデル応答で構成されるペイロードを取得し、出力を出力します。コード Llama は、推論の実行中に多くのパラメーターをサポートします。
- 最大長 – モデルは、出力の長さ (入力コンテキストの長さを含む) に達するまでテキストを生成します。
max_length. 指定する場合は、正の整数にする必要があります。 - max_new_tokens – モデルは、出力長 (入力コンテキストの長さを除く) に達するまでテキストを生成します。
max_new_tokens. 指定する場合は、正の整数にする必要があります。 - ビーム数 – これは、貪欲な検索で使用されるビームの数を指定します。指定する場合、それ以上の整数である必要があります。
num_return_sequences. - no_repeat_ngram_size – モデルは、単語のシーケンスが
no_repeat_ngram_size出力シーケンスで繰り返されません。 指定する場合は、1 より大きい正の整数にする必要があります。 - 温度 – これは出力のランダム性を制御します。より高い
temperature確率の低い単語を含む出力シーケンスが生成されます。temperatureその結果、確率の高い単語を含む出力シーケンスが生成されます。もしtemperatureが 0 の場合、貪欲なデコードが行われます。指定する場合は、正の浮動小数点数でなければなりません。 - 早期停止中 - もし
True, すべてのビーム仮説が文末トークンに到達すると、テキスト生成が終了します。指定する場合は、ブール値である必要があります。 - do_sample - もし
True、モデルは可能性に従って次の単語をサンプリングします。指定する場合は、ブール値である必要があります。 - トップk – テキスト生成の各ステップで、モデルはテキストのみからサンプリングします。
top_k最もありそうな言葉。 指定する場合は、正の整数にする必要があります。 - トップ_p – テキスト生成の各ステップで、モデルは累積確率で可能な最小の単語セットからサンプリングします。
top_p。 指定する場合は、0 から 1 までの浮動小数点でなければなりません。 - return_full_text - もし
True、入力テキストは、生成された出力テキストの一部になります。指定する場合は、ブール値である必要があります。デフォルト値は次のとおりです。False. - stop – 指定する場合は、文字列のリストである必要があります。指定された文字列のいずれかが生成されると、テキストの生成は停止します。
エンドポイントを呼び出すときに、これらのパラメーターの任意のサブセットを指定できます。次に、これらの引数を使用してエンドポイントを呼び出す方法の例を示します。
コード補完
次の例は、予期されるエンドポイント応答がプロンプトの自然な継続である場合に、コード補完を実行する方法を示しています。
まず次のコードを実行します。
次の出力が得られます。
次の例では、次のコードを実行します。
次の出力が得られます。
コード生成
次の例は、Code Llama を使用した Python コード生成を示しています。
まず次のコードを実行します。
次の出力が得られます。
次の例では、次のコードを実行します。
次の出力が得られます。
これらは、Code Llama 70B を使用したコード関連タスクの例の一部です。モデルを使用して、さらに複雑なコードを生成できます。独自のコード関連の使用例や例を使用して試してみることをお勧めします。
クリーンアップ
エンドポイントをテストした後、料金が発生しないように、SageMaker 推論エンドポイントとモデルを必ず削除してください。次のコードを使用します。
まとめ
この投稿では、SageMaker JumpStart の Code Llama 70B を紹介しました。 Code Llama 70B は、コードだけでなく自然言語プロンプトからもコードを生成するための最先端のモデルです。 SageMaker JumpStart のいくつかの簡単な手順でモデルをデプロイし、それを使用してコード生成やコード埋め込みなどのコード関連タスクを実行できます。次のステップとして、独自のコード関連のユースケースとデータでモデルを使用してみてください。
著者について
 カイル・ウルリッヒ博士 Amazon SageMaker JumpStart チームの応用科学者です。 彼の研究対象には、スケーラブルな機械学習アルゴリズム、コンピューター ビジョン、時系列、ベイジアン ノンパラメトリック、ガウス プロセスなどがあります。 彼はデューク大学で博士号を取得しており、NeurIPS、Cell、および Neuron で論文を発表しています。
カイル・ウルリッヒ博士 Amazon SageMaker JumpStart チームの応用科学者です。 彼の研究対象には、スケーラブルな機械学習アルゴリズム、コンピューター ビジョン、時系列、ベイジアン ノンパラメトリック、ガウス プロセスなどがあります。 彼はデューク大学で博士号を取得しており、NeurIPS、Cell、および Neuron で論文を発表しています。
 ファルーク・サビル博士 AWS のシニア人工知能および機械学習スペシャリスト ソリューション アーキテクトです。 テキサス大学オースティン校で電気工学の博士号と修士号を取得し、ジョージア工科大学でコンピューター サイエンスの修士号を取得しています。 彼は15年以上の実務経験があり、大学生を教えたり指導したりすることも好きです. AWS では、データ サイエンス、機械学習、コンピューター ビジョン、人工知能、数値最適化、および関連分野におけるビジネス上の問題を顧客が定式化して解決するのを支援しています。 テキサス州ダラスを拠点とする彼と彼の家族は、旅行が大好きで、長いドライブ旅行に出かけます。
ファルーク・サビル博士 AWS のシニア人工知能および機械学習スペシャリスト ソリューション アーキテクトです。 テキサス大学オースティン校で電気工学の博士号と修士号を取得し、ジョージア工科大学でコンピューター サイエンスの修士号を取得しています。 彼は15年以上の実務経験があり、大学生を教えたり指導したりすることも好きです. AWS では、データ サイエンス、機械学習、コンピューター ビジョン、人工知能、数値最適化、および関連分野におけるビジネス上の問題を顧客が定式化して解決するのを支援しています。 テキサス州ダラスを拠点とする彼と彼の家族は、旅行が大好きで、長いドライブ旅行に出かけます。
 ジューン・ウォン SageMaker JumpStart のプロダクト マネージャーです。 彼は、顧客が生成 AI アプリケーションを構築できるように、基礎モデルを簡単に見つけて使用できるようにすることに重点を置いています。 Amazon での経験には、モバイル ショッピング アプリケーションやラスト マイル配送も含まれます。
ジューン・ウォン SageMaker JumpStart のプロダクト マネージャーです。 彼は、顧客が生成 AI アプリケーションを構築できるように、基礎モデルを簡単に見つけて使用できるようにすることに重点を置いています。 Amazon での経験には、モバイル ショッピング アプリケーションやラスト マイル配送も含まれます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/code-llama-70b-is-now-available-in-amazon-sagemaker-jumpstart/

