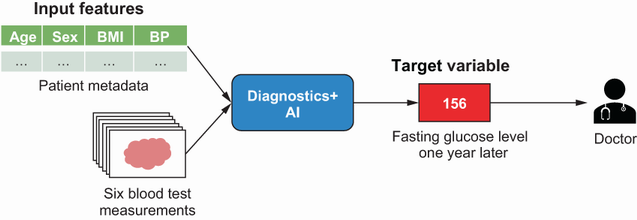
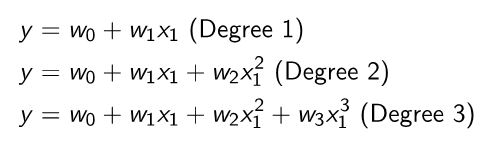from sklearn.datasets import load_diabetes #A
diabetes = load_diabetes() #B
X, y = diabetes[‘data’], diabetes[‘target’] #C #A Import scikit-learn function to load open diabetes dataset
#B Load the diabetes dataset
#C Extract the features and the target variable
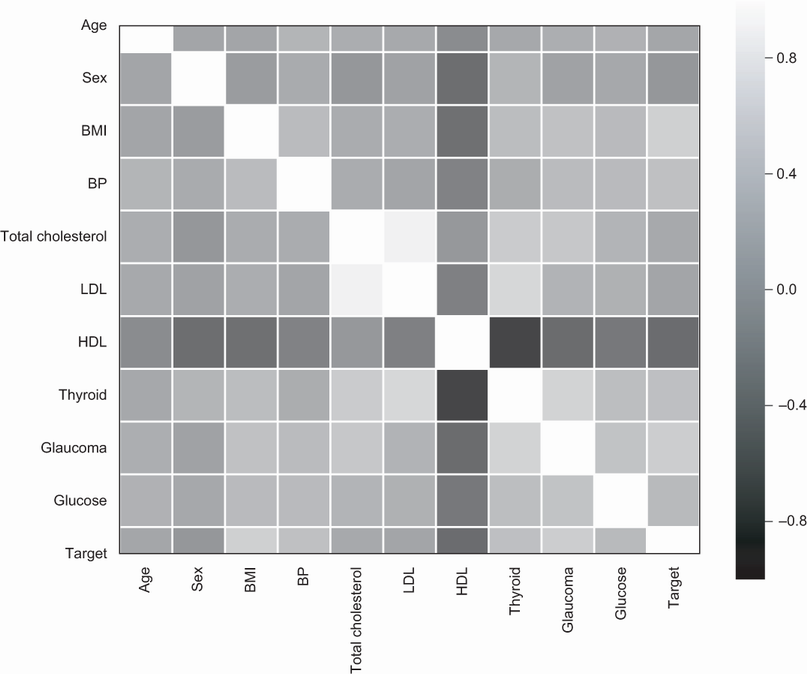
feature_rename = {'age': 'Age', #A 'sex': 'Sex', #A 'bmi': 'BMI', #A 'bp': 'BP', #A 's1': 'Total Cholesterol', #A 's2': 'LDL', #A 's3': 'HDL', #A 's4': 'Thyroid', #A 's5': 'Glaucoma', #A 's6': 'Glucose'} #A df_data = pd.DataFrame(X, #B columns=diabetes['feature_names']) #C
df_data.rename(columns=feature_rename, inplace=True) #D
df_data['target'] = y #E #A: Mapping of feature names provided by scikit-learn to a more readable form
#B: Load all the features (X) into a DataFrame
#C: Use the scikit-learn feature names as column names
#D: Rename the scikit-learn feature names to a more readable form
#E: Include the target variable (y) as a separate column
from pygam import LinearGAM #A
from pygam imports #B
from pygam import f #C # Load data using the code snippet in Section 2.2 gam = LinearGAM(s(0) + #D f(1) + #E s(2) + #F s(3) + #G s(4) + #H s(5) + #I s(6) + #J s(7) + #K s(8) + #L s(9), #M n_splines=35) #N gam.gridsearch(X_train, y_train) #O y_pred = gam.predict(X_test) #P mae = np.mean(np.abs(y_test - y_pred)) #Q #A Import the LinearGAM class from pygam that can be used to train a GAM for regression tasks
#B Import the smoothing term function to be used for numerical features
#C Import the factor term function to be used for categorical features
#D Cubic spline term for the Age feature
#E Factor term for the Sex feature which is categorical
#F Cubic splineterm for the BMI feature
#G Cubic spline term for the BP feature
#H Cubic spline term for the Total Cholesterol feature
#I Cubic spline term for the LDL feature
#J Cubic spline term for the HDL feature
#K Cubic spline term for the Thyroid feature
#L Cubic spline term for the Glaucoma feature
#M Cubic spline term for the Glucose feature
#N Maximum number of splines to be used for each feature
#O Using grid search to perform training and cross-validation to determine the number of splines, the regularization parameter lambda and the optimum weights for the regression splines for each feature
#P Use trained GAM model to predict on the test
#Q Evaluate the performance of the model on the test set using the MAE metric
grid_locs1 = [(0, 0), (0, 1), #A (1, 0), (1, 1)] #A
fig, ax = plt.subplots(2, 2, figsize=(10, 8)) #B
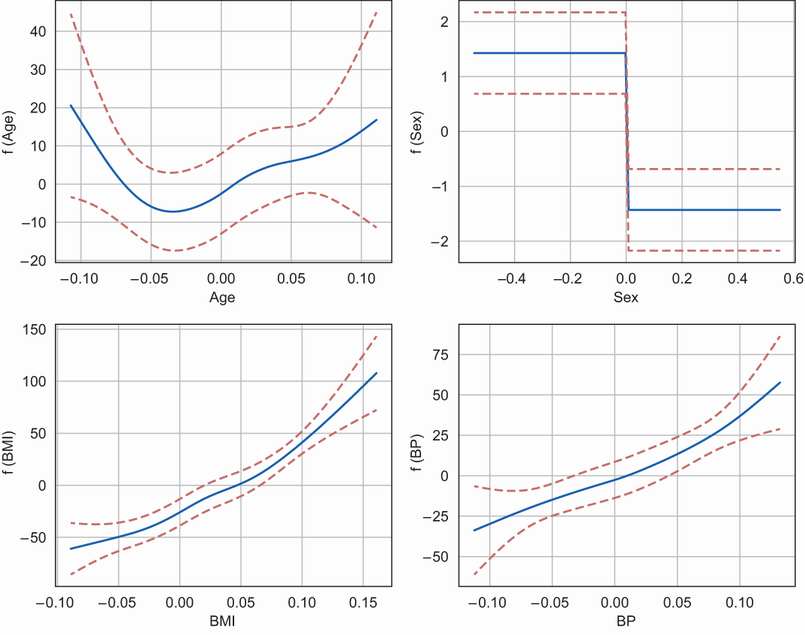
for i, feature in enumerate(feature_names[:4]): #C gl = grid_locs1[i] #D XX = gam.generate_X_grid(term=i) #E ax[gl[0], gl[1]].plot(XX[:, i], gam.partial_dependence(term=i, X=XX)) #F ax[gl[0], gl[1]].plot(XX[:, i], gam.partial_dependence(term=i, X=XX, width=.95)[1], c='r', ls='--') #G ax[gl[0], gl[1]].set_xlabel('%s' % feature) #H ax[gl[0], gl[1]].set_ylabel('f ( %s )' % feature) #H #A Locations of the 4 graphs in the 2x2 matplotlib grid
#B Create 2x2 grid of matplotlib graphs
#C Iterate through the 4 patient metadata features
#D Get location of feature in the 2x2 grid
#E Generate the partial dependence of the feature values with the target marginalizing on the other features
#F Plot the partial dependence values as a solid line
#G Plot the 95% confidence interval around the partial dependence values as a dashed line
#H Add labels for the x and y axes
grid_locs2 = [(0, 0), (0, 1), #A (1, 0), (1, 1), #A (2, 0), (2, 1)] #A
fig2, ax2 = plt.subplots(3, 2, figsize=(12, 12)) #B
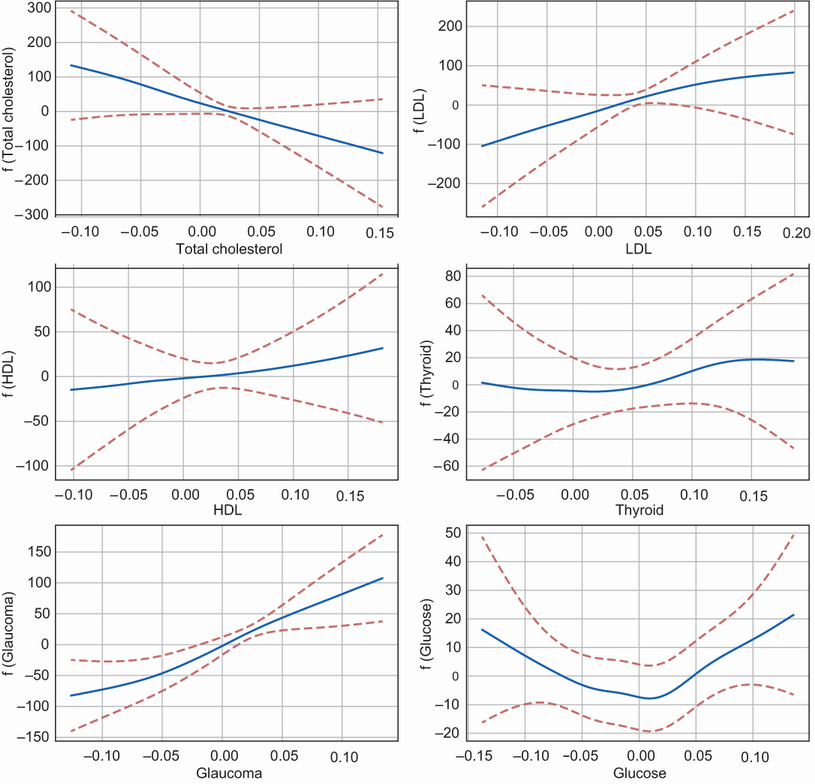
for i, feature in enumerate(feature_names[4:]): #C idx = i + 4 #D gl = grid_locs2[i] #D XX = gam.generate_X_grid(term=idx) #E ax2[gl[0], gl[1]].plot(XX[:, idx], gam.partial_dependence(term=idx, X=XX)) #F ax2[gl[0], gl[1]].plot(XX[:, idx], gam.partial_dependence(term=idx, X=XX, width=.95)[1], c='r', ls='--') #G ax2[gl[0], gl[1]].set_xlabel('%s' % feature) #H ax2[gl[0], gl[1]].set_ylabel('f ( %s )' % feature) #H #A Locations of the 6 graphs in the 3x2 matplotlib grid
#B Create 3x2 grid of matplotlib graphs
#C Iterate through the 6 blood test measurement features
#D Get location of feature in the 3x2 grid
#E Generate the partial dependence of the feature values with the target marginalizing on the other features
#F Plot the partial dependence values as a solid line
#G Plot the 95% confidence interval around the partial dependence values as a dashed line
#H Add labels for the x and y axes
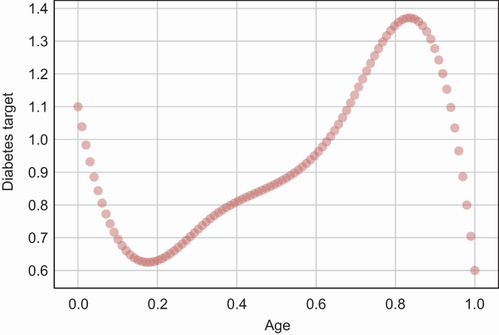
ターゲット変数をモデル化する
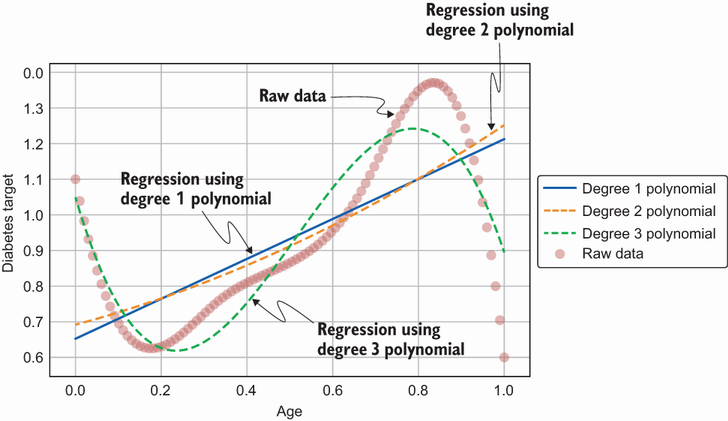
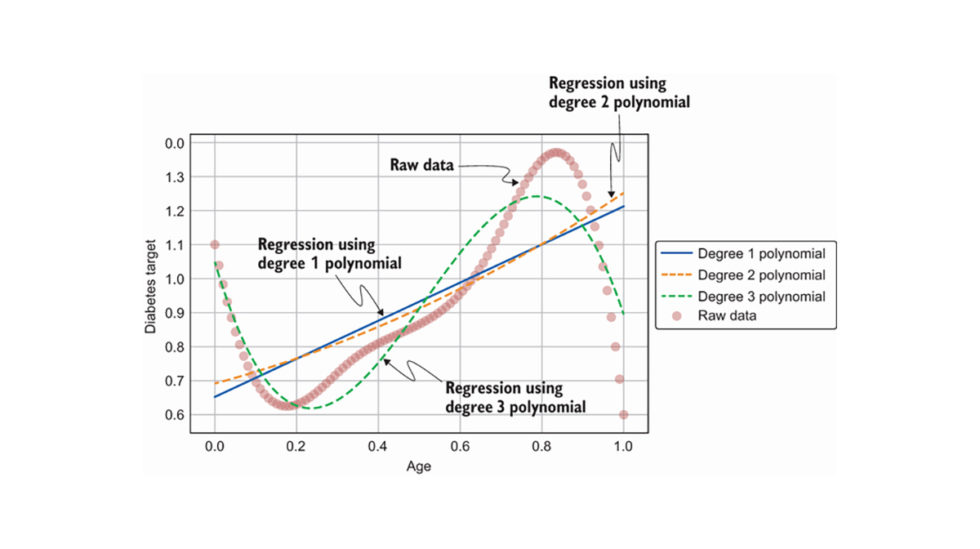
. 次数 1 の多項式は線形回帰と同じです。 次数 2 の多項式の場合、次の XNUMX 乗である追加の機能を追加します。
特徴間の関係をモデル化する関数です。
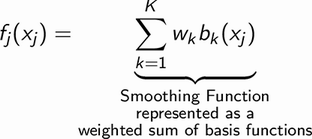
およびターゲット変数。 この関数は、重みが次のように表される基底関数の加重和として表されます。
基底関数は次のように表されます。
. GAM のコンテキストでは、関数

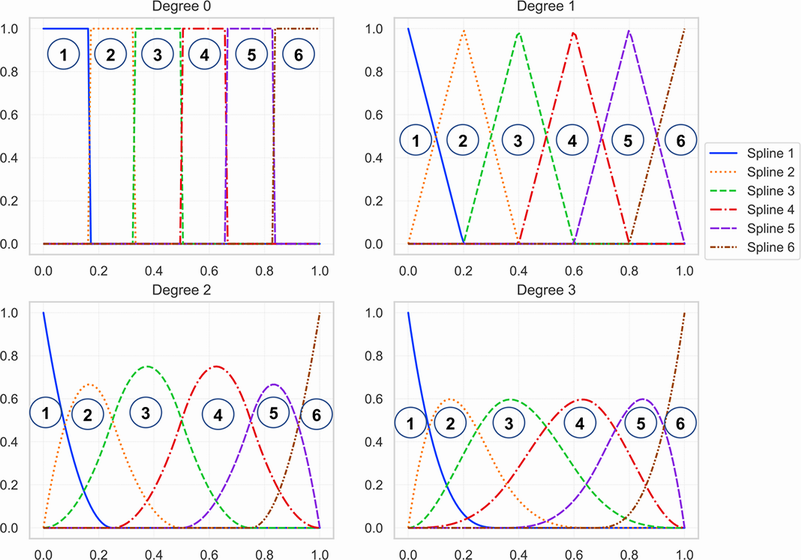
連続導関数。 イラストを使用すると、スプラインを理解しやすくなります。 図 3 は、さまざまな角度のスプラインを示しています。 左上のグラフは次数 0 の最も単純なスプラインを示しており、そこからより高い次数のスプラインを生成できます。 左上のグラフからわかるように、0 つのスプラインがグリッドに配置されています。 アイデアは、データの分布を部分に分割し、それらの各部分にスプラインを適合させることです。 したがって、この図では、データが XNUMX つの部分に分割されており、各部分を次数 XNUMX のスプラインとしてモデル化しています。
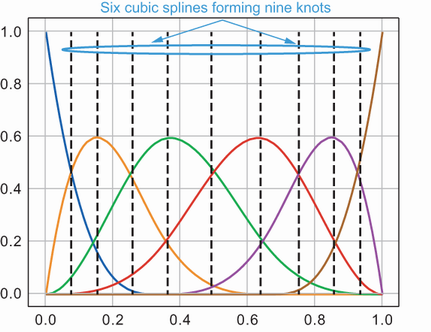
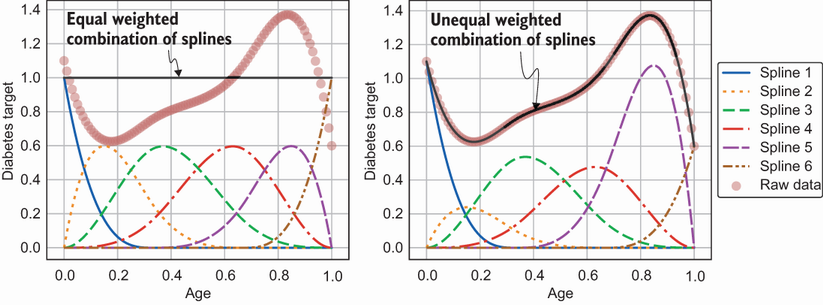
. 回帰スプラインの背後にある考え方は、各部分のデータの分布をモデル化できるように、各スプラインの重みを学習することです。 グリッド内の部分またはスプラインの数、
分割点、としても知られる ノット.
、揺れの強さを調整できます。 価値が高い