概要
情報が氾濫する世界では、関連データに効率的にアクセスして抽出することが非常に重要です。 ResearchBot は、OpenAI の LLM の機能を使用する、最先端の LLM ベースのアプリケーション プロジェクトです (大規模な言語モデル) 情報検索用の Langchain を使用します。 この記事は、独自の ResearchBot を作成し、それが実際の生活でどのように役立つかについてのステップバイステップのマニュアルのようなものです。 それは、データの海から必要な情報を見つけてくれる、インテリジェントなアシスタントがいるようなものです。 コーディングが好きな人でも、AI に興味がある人でも、このガイドは、カスタマイズされた LLM を利用した AI アシスタントで研究を強化するのに役立ちます。 これは、LLM の可能性を解き放ち、情報へのアクセス方法に革命を起こす旅です。

学習目標
- LLM (Large Language Model)、Langchain、Vector Database、および Embedding のより深い概念を理解します。
- 研究、顧客サポート、コンテンツ生成などの分野における LLM と ResearchBot の実際のアプリケーションを探索します。
- ResearchBot を既存のプロジェクトやワークフローに統合し、生産性と意思決定を向上させるためのベスト プラクティスを発見します。
- ResearchBot を構築して、データ抽出とクエリへの応答のプロセスを合理化します。
- LLM テクノロジーのトレンドと、この情報へのアクセスと使用方法に革命をもたらす可能性に関する最新情報を入手してください。
この記事は、の一部として公開されました データサイエンスブログ。
目次
リサーチボットとは何ですか?
ResearchBot は、LLM を利用した研究アシスタントです。 これは、コンテンツにすばやくアクセスして要約できる革新的なツールであり、さまざまな業界の専門家にとって優れたパートナーになります。
複数の記事、ドキュメント、Web サイトのページを読んで理解し、関連性のある短い要約を提供してくれる、パーソナライズされたアシスタントがいると想像してください。 私たちの ResearchBot の目的は、研究目的に必要な時間と労力を削減することです。
実際のユースケース
- 財務分析: 最新の市場ニュースを常に入手し、財務上の質問に対する迅速な回答を入手してください。
- ジャーナリズム: 記事の背景情報、出典、参考文献を効率的に収集します。
- 健康管理: 研究目的で最新の医学研究論文や要約にアクセスします。
- 学者: 関連する学術論文、研究資料、研究上の質問への回答を検索します。
- 法的研究: 法的文書、判決、法的問題に関する洞察を迅速に取得します。
専門用語
ベクターデータベース
テキスト データのベクトル埋め込みを保存するコンテナは、類似性に基づく効率的な検索にとって重要です。
セマンティック検索
ユーザーのクエリの意図とコンテキストを理解して、キーワードの完全な一致に完全に依存せずに検索を実行します。
埋め込み
効率的な比較と検索を可能にするテキスト データの数値表現。
プロジェクトの技術アーキテクチャ
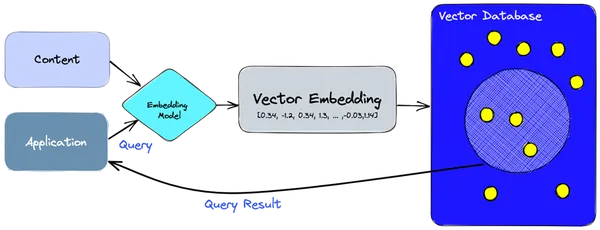
- 埋め込みモデルを使用して、インデックスを作成する必要がある情報またはコンテンツのベクトル埋め込みを作成します。
- ベクトル埋め込みは、埋め込みが作成された元のコンテンツを参照して、ベクトル データベースに挿入されます。
- アプリケーションがクエリを発行すると、同じ埋め込みモデルを使用してクエリの埋め込みを作成し、それらの埋め込みを使用してデータベースに同様のベクトル埋め込みをクエリします。
- これらの同様の埋め込みは、その作成に使用された元のコンテンツに関連付けられています。
ResearchBot はどのように機能しますか?
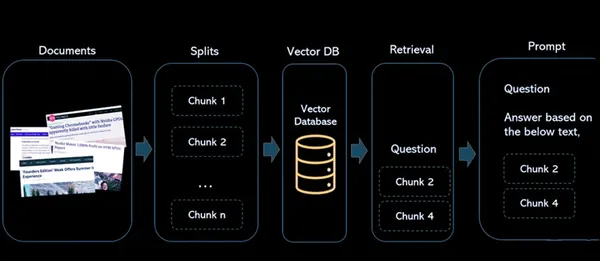
このアーキテクチャにより、コンテンツの保存、検索、および対話が容易になり、ResearchBot が情報の検索と分析のための強力なツールになります。 ベクター埋め込みとベクター データベースを利用して、迅速かつ正確なコンテンツ検索を容易にします。
コンポーネント
- ドキュメント: これらは、将来の参照や取得のためにインデックスを作成する記事またはコンテンツです。
- 分割: これにより、ドキュメントをより小さく管理しやすいチャンクに分割するプロセスが処理されます。 これは、大きなドキュメントや記事を操作し、それらが言語モデルの制約に完全に適合していることを確認し、効率的にインデックスを作成するために重要です。
- ベクターデータベース: ベクトル データベースはアーキテクチャの重要な部分です。 コンテンツから生成されたベクトル埋め込みを保存します。 各ベクトルは、そのベクトルが派生した元のコンテンツに関連付けられ、数値表現とソース素材の間にリンクが作成されます。
- 検索: ユーザーがシステムにクエリを実行すると、同じ埋め込みモデルを使用してクエリの埋め込みが作成されます。 これらのクエリ埋め込みは、ベクトル データベースで類似のベクトル埋め込みを検索するために使用されます。 その結果、それぞれが元のコンテンツ ソースに関連付けられた、類似したベクトルの大きなグループが生成されます。
- プロンプト: ユーザーがシステムと対話する場所で定義されます。 ユーザーがクエリを入力すると、システムはこれらのクエリを処理してベクター データベースから関連情報を取得し、回答とソース コンテンツへの参照を提供します。
LangChain のドキュメント ローダー
ドキュメント ローダーを使用して、ソースからドキュメントの形式でデータをロードします。 ドキュメントは、テキストとそれに関連付けられたメタデータです。 たとえば、単純な .txt ファイルをロードしたり、記事やブログのテキスト コンテンツをロードしたり、YouTube ビデオのトランスクリプトをロードしたりするためのドキュメント ローダーがあります。
ドキュメント ローダーにはさまざまな種類があります。
| ローダー | 使用法 |
|---|---|
| TextLoader | 処理のためにプレーン テキスト ドキュメントを読み込みます。 |
| CSVローダー | CSV ファイルからデータをインポートします。 |
| ディレクトリローダー | ディレクトリからコンテンツを読み取り、ロードします。 |
| 非構造化HTMLローダー | 非構造化 HTML コンテンツを取得して処理します。 |
| JSONローダー | JSON ファイルからデータを読み込みます。 |
| 非構造化マークダウンローダー | 非構造化マークダウン コンテンツを処理して読み込みます。 |
| PyPDFLoader | さらに処理するために PDF ファイルからテキスト コンテンツを抽出します。 |
例 – TextLoader
このコードは、Langchain の TextLoader の機能を示しています。 既存のファイル「Langchain.txt」からテキスト データを TextLoader クラスにロードし、さらに処理できるように準備します。 「file_path」変数には、将来の目的のためにロードされるファイルへのパスが保存されます。
# Import the TextLoader class from the langchain.document_loaders module
from langchain.document_loaders import TextLoader # consider the TextLoader class by mentioning the file to load, Here "Langchain.txt"
loader = TextLoader("Langchain.txt") # Load the content from provided file ("Langchain.txt") into the TextLoader class
loader.load() # Check the type of the 'loader' instance, which should be 'TextLoader'
type(loader) # The file path associated with the TextLoader in the 'file_path' variable
loader.file_path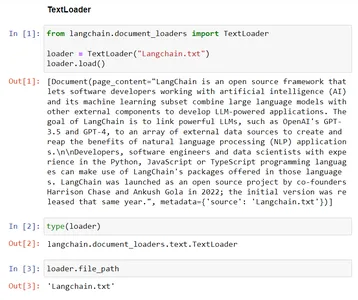
LangChain のテキスト スプリッター
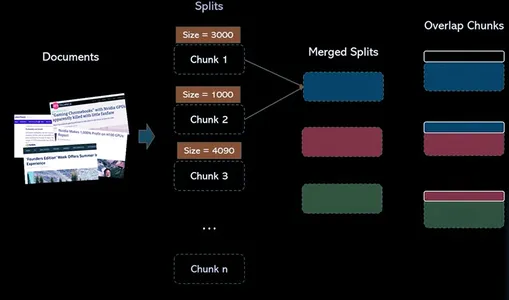
テキスト スプリッターは、ドキュメントを小さなドキュメントに分割する役割を果たします。 これらの小さな単位により、コンテンツの操作と効率的な処理が容易になります。 ResearchBot プロジェクトのコンテキストでは、テキスト スプリッターを使用して、さらなる分析と取得のためにデータを準備します。
なぜテキスト分割ツールが必要なのでしょうか?
LLM にはトークン制限があります。 したがって、各チャンクのサイズがトークン制限を下回るように、大きくなる可能性のあるテキストを小さなチャンクに分割する必要があります。
テキストをチャンクに分割する手動アプローチ
# Taking some random text from wikipedia
text # Say LLM token limit is 100, in our code we can do simple thing such as this text[:100]

そうですね、でも完全な単語が必要で、テキスト全体に対してこれを実行したいのですが、Python の分割関数を使用できるかもしれません。
words = text.split(" ")
len(words) chunks = [] s = ""
for word in words: s += word + " " if len(s)>200: chunks.append(s) s = "" chunks.append(s) chunks[:2]
データをチャンクに分割することはネイティブ Python で実行できますが、面倒なプロセスです。 また、必要に応じて、各チャンクがそれぞれの LLM のトークン長制限を超えないように、複数の区切り文字を連続して試してみる必要がある場合があります。
Langchain は、テキスト スプリッター クラスを介したより良い方法を提供します。 langchain にはこれを可能にする複数のテキスト スプリッター クラスがあります。
1. 文字テキストスプリッター
このクラスは、特定の区切り文字に基づいてテキストを小さなチャンクに分割するように設計されています。 段落、ピリオド、カンマ、改行(n)など。 これは、テキストを複数のチャンクに分割してさらに処理する場合に便利です。
from langchain.text_splitter import CharacterTextSplitter splitter = CharacterTextSplitter( separator = "n", chunk_size=200, chunk_overlap=0
) chunks = splitter.split_text(text)
len(chunks) for chunk in chunks: print(len(chunk))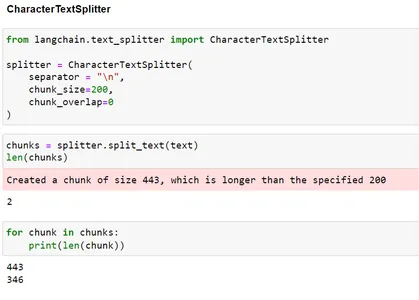
ご覧のとおり、分割は n に基づいていたため、チャンク サイズを 200 に指定しましたが、最終的にはサイズ 200 よりも大きなチャンクが作成されてしまいました。
Langchain の別のクラスを使用して、区切り文字のリストに基づいてテキストを再帰的に分割できます。 このクラスは RecursiveTextSplitter です。 どのように機能するかを見てみましょう。
2. 再帰的テキストスプリッター
これは、テキスト内の文字を再帰的に分析することによって動作する、一種のテキスト スプリッターです。 テキストをさまざまな文字で分割し、テキストとさまざまな種類のシェルを効果的に分割する分割アプローチを特定するまで、さまざまな文字の組み合わせを繰り返し見つけます。
from langchain.text_splitter import RecursiveCharacterTextSplitter r_splitter = RecursiveCharacterTextSplitter( separators = ["nn", "n", " "], # List of separators chunk_size = 200, # size of each chunk created chunk_overlap = 0, # size of overlap between chunks length_function = len # Function to calculate size,
) chunks = r_splitter.split_text(text) for chunk in chunks: print(len(chunk)) first_split = text.split("nn")[0]
first_split
len(first_split) second_split = first_split.split("n")
second_split
for split in second_split: print(len(split)) second_split[2]
second_split[2].split(" ")
これらのチャンクがどのように形成されたかを理解しましょう。
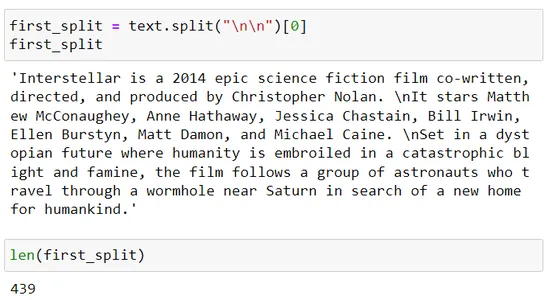
再帰的テキスト分割ツールは区切り文字のリストを使用します。つまり、区切り文字 = [“nn”, “n”, “.”]
したがって、最初に nn を使用して分割し、次に結果のチャンク サイズが chunk_size パラメーター (このシーンでは 200) を超える場合は、次のセパレーター n を使用します。
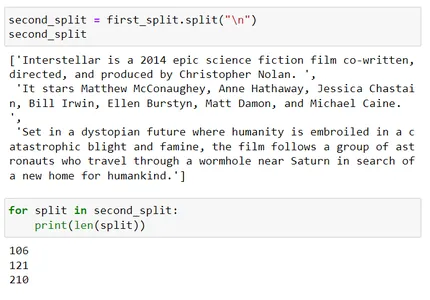
200 番目の分割はチャンク サイズ XNUMX を超えています。今度は、XNUMX 番目の区切り文字「 」 (スペース) を使用してさらに分割しようとします。
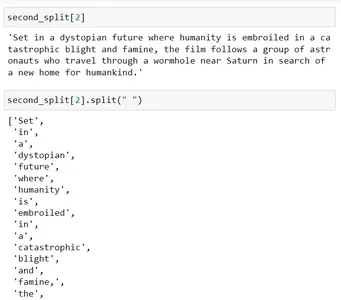
これをスペースを使用して分割すると (つまり、 Second_split[2].split(" "))、各単語が分離され、サイズが 200 近くになるようにそれらのチャンクがマージされます。
ベクターデータベース
ここで、数百万、さらには数十億の単語埋め込みを保存する必要があるシナリオを考えてみましょう。これは、現実世界のアプリケーションでは重要な場面になります。 リレーショナル データベースは、構造化データを保存できますが、このような大量のデータの処理には制限があるため、適切ではない場合があります。
ここでベクター データベースが活躍します。 ベクター データベースは、ベクター データを効率的に保存および取得できるように設計されており、単語の埋め込みに適しています。
ベクター データベースは、セマンティック検索を使用して情報検索に革命をもたらしています。 単語の埋め込みとスマートなインデックス作成技術を利用して、検索をより高速かつ正確に実行します。
ベクトルインデックスとベクトルデータベースの違いは何ですか?
スタンドアロン ベクトル インデックスのような フェイス (Facebook AI 類似性検索) は、ベクトル埋め込みの検索と取得を改善できますが、db(データベース) の XNUMX つに存在する機能が欠けています。 一方、ベクトル データベースは、ベクトルの埋め込みを管理することを目的として構築されており、スタンドアロンのベクトル インデックスを使用するよりも多くの利点があります。
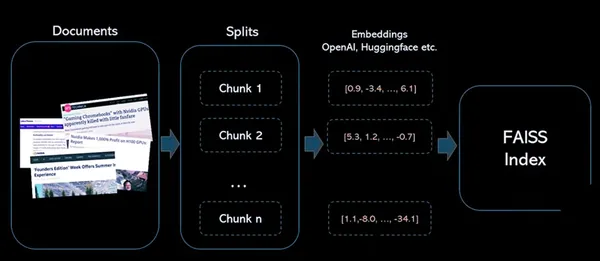
ステップ:
1 : テキスト列のソース埋め込みを作成する
2 : ベクトルの FAISS インデックスを構築する
3 : ソースベクトルを正規化し、インデックスに追加します
4 : 同じエンコーダを使用して検索テキストをエンコードし、出力ベクトルを正規化します
5: 作成したFAISSインデックスから類似ベクトルを検索
df = pd.read_csv("sample_text.csv")
df # Step 1 : Create source embeddings for the text column
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("all-mpnet-base-v2")
vectors = encoder.encode(df.text)
vectors # Step 2 : Build a FAISS Index for vectors
import faiss
index = faiss.IndexFlatL2(dim) # Step 3 : Normalize the source vectors and add to index
index.add(vectors)
index # Step 4 : Encode search text using same encoder
search_query = "looking for places to visit during the holidays"
vec = encoder.encode(search_query)
vec.shape
svec = np.array(vec).reshape(1,-1)
svec.shape # Step 5: Search for similar vector in the FAISS index
distances, I = index.search(svec, k=2)
distances
row_indices = I.tolist()[0]
row_indices
df.loc[row_indices]このデータセットをチェックアウトすると、
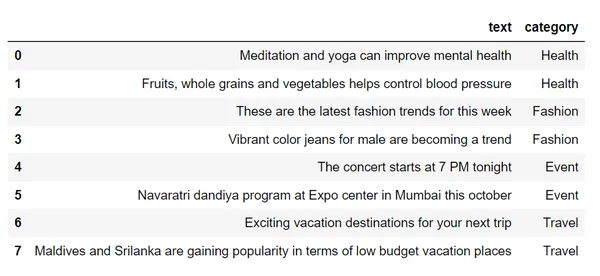
単語埋め込みを使用してこれらのテキストをベクトルに変換します
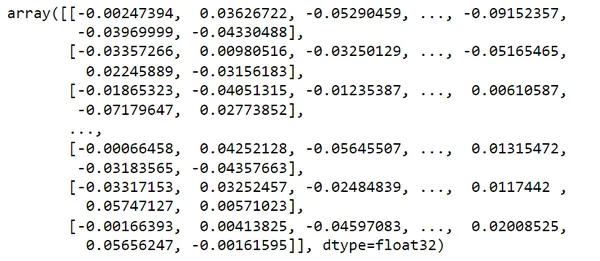
私の search_query = 「休暇中に訪れる場所を探しています」 を考えてみます。

旅行カテゴリのセマンティック検索を使用して、私のクエリに関連する最も類似した 2 つの結果が提供されます。
検索クエリを実行すると、データベースは局所性依存ハッシュ (LSH) などの手法を使用してプロセスを高速化します。 LSH は類似したベクトルをバケットにグループ化し、より高速でよりターゲットを絞った検索を可能にします。 これは、クエリ ベクトルを保存されているすべてのベクトルと比較する必要がないことを意味します。
検索
ユーザーがシステムにクエリを実行すると、同じ埋め込みモデルを使用してクエリの埋め込みが作成されます。 これらのクエリ埋め込みは、ベクトル データベースで類似のベクトル埋め込みを検索するために使用されます。 結果は、それぞれが元のコンテンツ ソースに関連付けられた、類似したベクトルのグループになります。
回収の課題
セマンティック検索での検索では、GPT-3 などの言語モデルによって課されるトークン制限など、いくつかの課題が見られます。 関連する複数のデータチャンクを扱う場合、応答の制限を超過します。
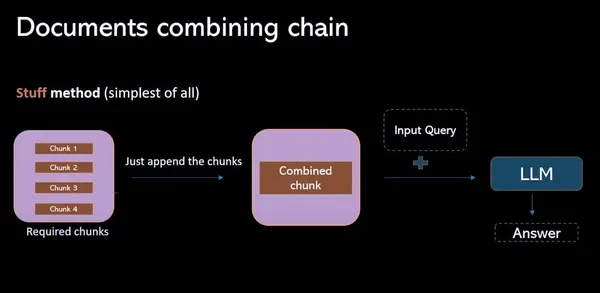
スタッフメソッド
このモデルでは、ベクター データベースから関連するすべてのデータ チャンクを収集し、それらをプロンプト (個別) に結合します。 このプロセスの主な欠点は、トークンの制限を超えるため、応答が不完全になることです。
マップリデュース方式
トークン制限の課題を克服し、取得 QA プロセスを合理化するために、このプロセスでは、チャンクが 4 つある場合に、関連するチャンクをプロンプト (個別) に組み合わせる代わりに、ソリューションを提供します。 すべてを個別に分離された LLM に渡します。 これらの質問は、言語モデルが各チャンクのコンテンツに個別に焦点を当てることを可能にするコンテキスト情報を提供します。 これにより、各チャンクに対して単一の回答のセットが得られます。 最後に、最終的な LLM 呼び出しが行われ、これらすべての単独の回答が結合され、各チャンクから収集された洞察に基づいて最適な回答が見つけられます。
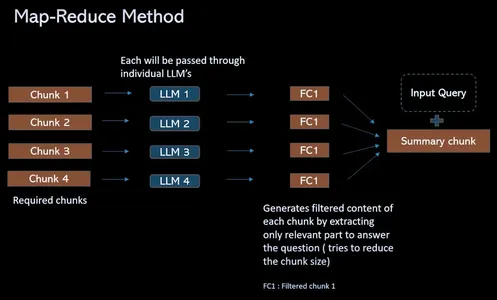
ResearchBotのワークフロー
(1) データのロード
このステップでは、テキストやドキュメントなどのデータがインポートされ、さらなる処理の準備が整い、分析に使用できるようになります。
#provide urls to scrape the data loaders = UnstructuredURLLoader(urls=[ "", ""
])
data = loaders.load() len(data)(2) データを分割してチャンクを作成する
データはより小さく管理しやすいセクションまたはチャンクに分割され、大きなテキストやドキュメントの効率的な処理が容易になります。
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200
) # use split_documents over split_text in order to get the chunks.
docs = text_splitter.split_documents(data)
len(docs)
docs[0](3) これらのチャンクの埋め込みを作成し、FAISS インデックスに保存します。
テキスト チャンクは数値ベクトル表現 (埋め込み) に変換され、Faiss インデックスに格納され、類似したベクトルの検索が最適化されます。
# Create the embeddings of the chunks using openAIEmbeddings
embeddings = OpenAIEmbeddings() # Pass the documents and embeddings inorder to create FAISS vector index
vectorindex_openai = FAISS.from_documents(docs, embeddings) # Storing vector index create in local
file_path="vector_index.pkl"
with open(file_path, "wb") as f: pickle.dump(vectorindex_openai, f) if os.path.exists(file_path): with open(file_path, "rb") as f: vectorIndex = pickle.load(f)(4) 指定された質問に対して同様の埋め込みを取得し、LLM を呼び出して最終的な回答を取得する
特定のクエリに対して、同様の埋め込みを取得し、これらのベクトルを使用して言語モデル (LLM) と対話することで、情報検索を効率化し、ユーザーの質問に対する最終的な回答を提供します。
# Initialise LLM with the necessary parameters
llm = OpenAI(temperature=0.9, max_tokens=500) chain = RetrievalQAWithSourcesChain.from_llm( llm=llm, retriever=vectorIndex.as_retriever()
)
chain query = "" #ask your query langchain.debug=True chain({"question": query}, return_only_outputs=True)最終申請
これらすべての段階 (ドキュメント ローダー、テキスト スプリッター、ベクター DB、取得、プロンプト) を使用し、streamlit を使用してアプリケーションを構築した後。 ResearchBot の構築が完了しました。
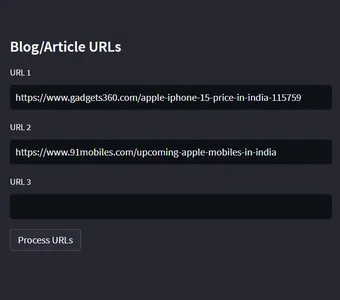
これはページ内のセクションで、ブログや記事の URL が挿入されます。 2023 年にリリースされた最新の Iphone モバイルのリンクを提供しました。このアプリケーション ResearchBot の構築を開始する前に、ChatGPT はすでにあるのに、なぜこの ResearchBot を構築するのかという疑問を誰もが抱くでしょう。 答えは次のとおりです。
ChatGPT の答え:

ResearchBot の答え:
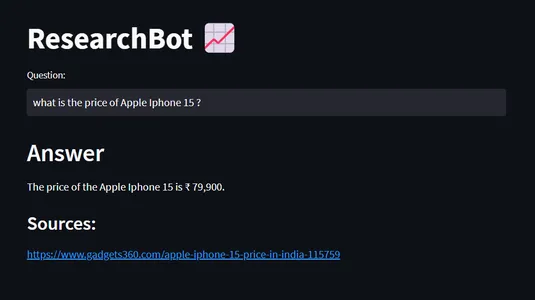
ここで、私のクエリは 「Apple iPhone 15の価格はいくらですか?」
このデータは 2023 年のもので、ChatGPT 3.5 では利用できませんが、Iphone に関する最新情報を使用して ResearchBot をトレーニングしました。 そこで、ResearchBot によって必要な回答が得られました。
ChatGPT の使用に関する 3 つの問題は次のとおりです。
- 記事の内容をコピーして貼り付けるのは面倒な作業です。
- 集合的なナレッジベースが必要です。
- 語数制限 – 3000語
まとめ
私たちは、現実世界のシナリオでセマンティック検索とベクトル データベースの概念を目の当たりにしてきました。 セマンティック検索を使用してベクター データベースから回答を効率的に取得する ResearchBot の機能は、情報検索および質問応答システムの分野におけるディープ LLM (adv) の大きな可能性を示しています。 高い能力と検索機能を備え、重要な情報を簡単に見つけて要約できる、非常に需要の高いツールを作りました。 知識を求める人にとっては強力なソリューションです。 このテクノロジーは、情報検索および質問応答システムに新たな地平を切り開き、データ駆動型の洞察を求めるあらゆる人にとって革新的なテクノロジーとなります。
よくある質問
A. これは、最新のセマンティック検索エンジンのバックボーンです。 ベクトル データベースは、高次元ベクトル データを処理するように設計された特殊なデータベースです。 これらは、データの複雑さと粒度に応じて、テキストやその他のタイプを表すベクトルなどの高次元データを保存および検索する効率的な方法を提供します。
A. 単語の意味を解釈するには、セマンティック検索エンジンの方が適しています。 クエリの意図をよりよく理解でき、従来の検索エンジンが表示するものよりも検索者にとってより関連性の高い検索結果を生成できます。
A. FAISS はベクトル データベースそのものではなく、ベクトル検索ライブラリです。 これは、ベクトル検索ライブラリであり、ベクトル類似性検索を実行するために使用されるスタンドアロン ライブラリです。 よくある例としては、FAISS、HNSW、Annoy などがあります。
A. 大規模言語モデル (LLM) は、深層学習技術と大規模なデータ セットを使用して、新しいコンテンツを理解、要約、生成、予測する人工知能 (AI) アルゴリズムの一種です。 これらのチャットボットは、自然言語の理解と会話において多くのスキルを備えています。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/10/empower-your-research-with-a-tailored-llm-powered-ai-assistant/

