生成 AI は、AI の分野に多くの可能性をもたらしました。テキスト生成、コード生成、要約、翻訳、チャットボットなど、数多くの用途が見られます。進化している分野の 1 つは、自然言語処理 (NLP) を使用して、直感的な SQL クエリを通じてデータにアクセスする新たな機会を開拓することです。ビジネス ユーザーやデータ アナリストは、複雑な技術コードを扱う代わりに、わかりやすい言葉でデータや洞察に関連する質問をすることができます。主な目標は、自然言語テキストから SQL クエリを自動的に生成することです。これを行うには、テキスト入力が構造化表現に変換され、この表現からデータベースへのアクセスに使用できる SQL クエリが作成されます。
この投稿では、Text to SQL (Text2SQL) の概要を説明し、ユースケース、課題、設計パターン、ベスト プラクティスを探ります。具体的には、次のことについて説明します。
- Text2SQL が必要な理由
- Text to SQL の主要コンポーネント
- 自然言語またはテキストから SQL へのエンジニアリングに関する迅速な考慮事項
- 最適化とベストプラクティス
- アーキテクチャパターン
なぜ Text2SQL が必要なのでしょうか?
現在、従来のデータ分析、データ ウェアハウジング、データベースでは大量のデータが利用可能ですが、大多数の組織メンバーにとってこれらのデータをクエリしたり理解したりするのは簡単ではない可能性があります。 Text2SQL の主な目標は、技術者以外のユーザーでもデータベースのクエリを利用しやすくし、自然言語でクエリを提供できるようにすることです。
NLP SQL を使用すると、ビジネス ユーザーはデータを分析し、次のような自然言語で質問を入力または発話することで回答を得ることができます。
- 「先月の各商品の売上合計を表示」
- 「どの製品がより多くの収益を生み出しましたか?」
- 「各地域からの顧客の割合は何パーセントですか?」
アマゾンの岩盤 は、単一の API を介して高性能の基盤モデル (FM) の選択肢を提供するフルマネージド サービスで、Gen AI アプリケーションを簡単に構築および拡張できるようにします。これを利用して、上記の質問と同様の質問に基づいて SQL クエリを生成し、組織の構造化データをクエリして、クエリ応答データから自然言語応答を生成できます。
テキストから SQL への主要コンポーネント
Text-to-SQL システムには、自然言語クエリを実行可能な SQL に変換するためのいくつかの段階が含まれます。
- 自然言語処理:
- ユーザーの入力クエリを分析する
- 重要な要素と意図を抽出する
- 構造化フォーマットに変換する
- SQLの生成:
- 抽出された詳細を SQL 構文にマッピングする
- 有効な SQL クエリを生成する
- データベースクエリ:
- AI が生成した SQL クエリをデータベース上で実行します。
- 結果の取得
- ユーザーに結果を返す
大規模言語モデル (LLM) の注目すべき機能の 1 つは、データベース用の構造化照会言語 (SQL) を含むコードの生成です。これらの LLM を利用して、自然言語の質問を理解し、対応する SQL クエリを出力として生成できます。 LLM は、より多くのデータが提供されるにつれて、コンテキスト内の学習と設定の微調整を採用することで恩恵を受けます。
次の図は、基本的な Text2SQL フローを示しています。

自然言語から SQL へのエンジニアリングに関する迅速な考慮事項
LLM を使用して自然言語を SQL クエリに変換する場合、プロンプトは非常に重要であり、プロンプト エンジニアリングにはいくつかの重要な考慮事項があります。
効果的な 迅速なエンジニアリング SQL システムに自然言語を開発する鍵となります。明確でわかりやすいプロンプトは、言語モデルに対するより適切な指示を提供します。ユーザーが SQL クエリを要求しているというコンテキストと、関連するデータベース スキーマの詳細を提供することで、モデルが意図を正確に変換できるようになります。自然言語プロンプトと対応する SQL クエリの注釈付きの例をいくつか含めることは、モデルが構文に準拠した出力を生成するように導くのに役立ちます。さらに、モデルが処理中に同様の例を取得する取得拡張生成 (RAG) を組み込むことで、マッピングの精度がさらに向上します。自然言語を SQL クエリに確実に変換するには、モデルに十分な指示、コンテキスト、例、検索の拡張を提供する適切に設計されたプロンプトが不可欠です。
以下は、ホワイトペーパーのデータベースのコード表現を含むベースライン プロンプトの例です。 大規模言語モデルの少数ショット Text-to-SQL 機能の強化: プロンプト設計戦略に関する研究.
この例に示されているように、プロンプトベースの少数ショット学習では、プロンプト自体に注釈付きの少数の例がモデルに提供されます。これは、モデルの自然言語と SQL の間のターゲット マッピングを示しています。通常、プロンプトには、自然言語クエリと同等の SQL ステートメントを示すペアが 2 ~ 3 個含まれます。これらのいくつかの例は、大規模なトレーニング データを必要とせずに、自然言語から構文に準拠した SQL クエリを生成するモデルをガイドします。
微調整と迅速なエンジニアリング
SQL システムに自然言語を構築する場合、モデルを微調整することが正しい手法なのか、それとも効果的なプロンプト エンジニアリングを行うべきなのかという議論がよく行われます。どちらのアプローチも、適切な一連の要件に基づいて検討および選択できます。
-
- 微調整 – ベースライン モデルは大規模な一般テキスト コーパスで事前トレーニングされており、 指示ベースの微調整これは、ラベル付きの例を使用して、テキスト SQL 上の事前トレーニングされた基礎モデルのパフォーマンスを向上させます。これにより、モデルがターゲット タスクに適合します。微調整では、最終タスクでモデルを直接トレーニングしますが、多くのテキスト SQL サンプルが必要です。 LLM に基づいた教師あり微調整を使用して、text-to-SQL の効率を向上させることができます。このために、次のようないくつかのデータセットを使用できます。 クモ, ウィキSQL, 追跡, BIRD-SQLまたは コSQL.
- 迅速なエンジニアリング – モデルは、ターゲット SQL 構文を要求するように設計されたプロンプトを完了するようにトレーニングされています。 LLM を使用して自然言語から SQL を生成する場合、モデルの出力を制御するには、プロンプトに明確な指示を提供することが重要です。プロンプトでは、列やスキーマを指すなどのさまざまなコンポーネントに注釈を付け、作成する SQL のタイプを指示します。これらは、SQL 出力のフォーマット方法をモデルに指示する命令のように機能します。次のプロンプトは、テーブルの列を指定して MySQL クエリの作成を指示する例を示しています。
text-to-SQL モデルの効果的なアプローチは、タスク固有の微調整を行わずに、まずベースライン LLM から開始することです。適切に作成されたプロンプトを使用して、ベース モデルを調整して駆動し、テキストから SQL へのマッピングを処理できます。この迅速なエンジニアリングにより、微調整を行うことなく機能を開発できます。基本モデルでのプロンプト エンジニアリングが十分な精度に達しない場合は、さらなるプロンプト エンジニアリングとともに、少数のテキスト SQL サンプルの微調整を検討できます。
未加工の事前トレーニング済みモデルでのプロンプト エンジニアリングだけでは要件を満たさない場合は、微調整とプロンプト エンジニアリングの組み合わせが必要になる場合があります。ただし、最初は微調整せずに迅速なエンジニアリングを試みることが最善です。これにより、データを収集せずに迅速な反復が可能になります。これで十分なパフォーマンスが得られない場合は、迅速なエンジニアリングと並行して微調整を行うことが次のステップとして実行可能です。この全体的なアプローチにより効率が最大化され、純粋にプロンプトベースの方法だけでは不十分な場合でもカスタマイズが可能になります。
最適化とベストプラクティス
最適化とベストプラクティスは、有効性を高め、リソースが最適に使用され、可能な限り最善の方法で適切な結果が達成されるようにするために不可欠です。このテクニックは、パフォーマンスの向上、コストの管理、より高品質な結果の達成に役立ちます。
LLM を使用して text-to-SQL システムを開発する場合、最適化手法によりパフォーマンスと効率を向上させることができます。考慮すべき重要な領域は次のとおりです。
- キャッシング – 待ち時間、コスト管理、標準化を改善するために、解析された SQL と text-to-SQL LLM からの認識されたクエリ プロンプトをキャッシュできます。これにより、繰り返されるクエリの再処理が回避されます。
- 監視 – text-to-SQL LLM システムを監視するには、クエリ解析、プロンプト認識、SQL 生成、および SQL 結果に関するログとメトリックを収集する必要があります。これにより、プロンプトを更新したり、更新されたデータセットを使用して微調整を再検討したりする最適化例が可視化されます。
- マテリアライズドビューとテーブルの比較 – マテリアライズド ビューにより SQL 生成が簡素化され、一般的な text-to-SQL クエリのパフォーマンスが向上します。テーブルに直接クエリを実行すると、SQL が複雑になり、インデックスなどのパフォーマンス手法の継続的な作成など、パフォーマンスの問題も発生する可能性があります。さらに、同じテーブルをアプリケーションの他の領域で同時に使用する場合のパフォーマンスの問題を回避できます。
- データの更新 – text-to-SQL クエリのデータを最新の状態に保つために、マテリアライズド ビューをスケジュールに従って更新する必要があります。バッチまたは増分更新アプローチを使用して、オーバーヘッドのバランスをとることができます。
- 中央データカタログ – 一元化されたデータ カタログを作成すると、組織のデータ ソースが一元的に表示され、LLM が適切なテーブルとスキーマを選択してより正確な応答を提供できるようになります。ベクター 埋め込み 中央データ カタログから作成されたデータは、関連する正確な SQL 応答を生成するために要求された情報とともに LLM に提供できます。
キャッシュ、監視、マテリアライズド ビュー、スケジュールされた更新、中央カタログなどの最適化のベスト プラクティスを適用すると、LLM を使用した Text-to-SQL システムのパフォーマンスと効率を大幅に向上させることができます。
アーキテクチャパターン
テキストから SQL へのワークフローに実装できるいくつかのアーキテクチャ パターンを見てみましょう。
迅速なエンジニアリング
次の図は、プロンプト エンジニアリングを使用して LLM でクエリを生成するためのアーキテクチャを示しています。
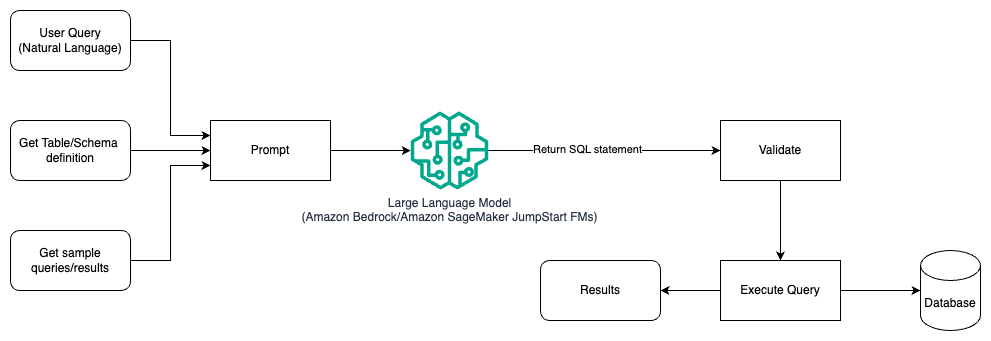
このパターンでは、ユーザーはプロンプトベースの少数ショット学習を作成し、プロンプト自体に注釈付きの例をモデルに提供します。これには、テーブルとスキーマの詳細とその結果を含むいくつかのサンプル クエリが含まれます。 LLM は、提供されたプロンプトを使用して AI 生成の SQL を返します。SQL は検証されてからデータベースに対して実行され、結果が得られます。これは、プロンプト エンジニアリングの使用を開始する最も簡単なパターンです。このために、次を使用できます アマゾンの岩盤 or 基礎モデル in Amazon SageMaker ジャンプスタート.
このパターンでは、ユーザーはプロンプトベースの少数ショット学習を作成し、プロンプト自体に注釈付きの例をモデルに提供します。これには、テーブルとスキーマの詳細と、その結果を含むいくつかのサンプル クエリが含まれます。 LLM は、提供されたプロンプトを使用して、AI が生成した SQL を返します。SQL は検証され、データベースに対して実行されて結果が得られます。これは、プロンプト エンジニアリングの使用を開始する最も簡単なパターンです。このために、次を使用できます アマゾンの岩盤 これは、セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築するために必要な幅広い機能とともに、単一の API を介して大手 AI 企業の高性能基盤モデル (FM) の選択肢を提供するフルマネージド サービスです。または JumpStart ファウンデーション モデル コンテンツ作成、コード生成、質問応答、コピーライティング、要約、分類、情報検索などのユースケースに最先端の基盤モデルを提供します。
迅速なエンジニアリングと微調整
次の図は、プロンプト エンジニアリングと微調整を使用して LLM でクエリを生成するためのアーキテクチャを示しています。
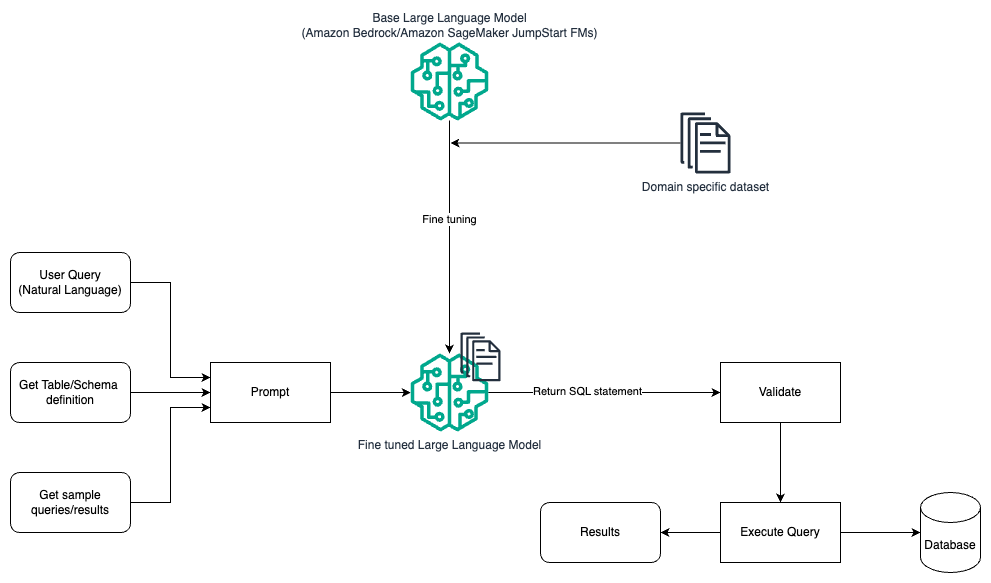
このフローは、主にプロンプト エンジニアリングに依存する前のパターンに似ていますが、ドメイン固有のデータセットを微調整する追加のフローが含まれています。微調整された LLM は、プロンプトのコンテキスト内値を最小限に抑えた SQL クエリを生成するために使用されます。このため、SageMaker JumpStart を使用して、モデルをトレーニングしてデプロイするのと同じ方法で、ドメイン固有のデータセット上で LLM を微調整できます。 アマゾンセージメーカー.
迅速なエンジニアリングとRAG
次の図は、プロンプト エンジニアリングと RAG を使用して LLM でクエリを生成するためのアーキテクチャを示しています。
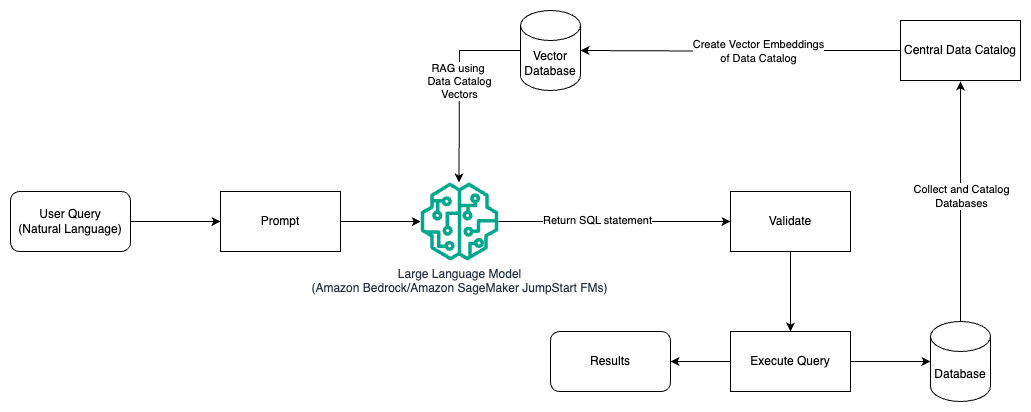
このパターンでは、 検索拡張生成 ベクトル埋め込みストアを使用するなど Amazon Titan の埋め込み or コヒア埋め込み、オン アマゾンの岩盤 中央データカタログから AWSグルー データカタログ、組織内のデータベースの。ベクトル埋め込みは、次のようなベクトル データベースに保存されます。 Amazon OpenSearch サーバーレス用のベクトル エンジン, PostgreSQL用のAmazonリレーショナルデータベースサービス(Amazon RDS) ベクター 拡張子、または アマゾンケンドラ。 LLM は、SQL クエリを作成するときに、ベクトル埋め込みを使用して、適切なデータベース、テーブル、およびテーブルからの列をより迅速に選択します。 RAG の使用は、LLM によって取得する必要があるデータおよび関連情報が複数の個別のデータベース システムに保存されており、LLM がこれらすべての異なるシステムからデータを検索またはクエリできる必要がある場合に役立ちます。この場合、一元化または統合されたデータ カタログのベクトル埋め込みを LLM に提供すると、LLM からより正確で包括的な情報が返されます。
まとめ
この投稿では、自然言語から SQL 生成を使用してエンタープライズ データから価値を生成する方法について説明しました。主要なコンポーネント、最適化、ベスト プラクティスを検討しました。また、基本的なプロンプト エンジニアリングから微調整や RAG までのアーキテクチャ パターンも学びました。詳細については、を参照してください。 アマゾンの岩盤 基礎モデルを使用して生成 AI アプリケーションを簡単に構築および拡張する
著者について
 ランディ・デフォー AWS のシニア プリンシパル ソリューション アーキテクトです。 彼はミシガン大学で修士号を取得しており、そこで自動運転車のコンピューター ビジョンに取り組みました。 彼はコロラド州立大学で MBA も取得しています。 Randy は、ソフトウェア エンジニアリングから製品管理に至るまで、テクノロジー分野でさまざまな役職を歴任してきました。 氏は 2013 年にビッグデータ分野に参入し、引き続きその分野の探索を続けています。 彼は ML 分野のプロジェクトに積極的に取り組んでおり、Strata や GlueCon などの数多くのカンファレンスで講演を行っています。
ランディ・デフォー AWS のシニア プリンシパル ソリューション アーキテクトです。 彼はミシガン大学で修士号を取得しており、そこで自動運転車のコンピューター ビジョンに取り組みました。 彼はコロラド州立大学で MBA も取得しています。 Randy は、ソフトウェア エンジニアリングから製品管理に至るまで、テクノロジー分野でさまざまな役職を歴任してきました。 氏は 2013 年にビッグデータ分野に参入し、引き続きその分野の探索を続けています。 彼は ML 分野のプロジェクトに積極的に取り組んでおり、Strata や GlueCon などの数多くのカンファレンスで講演を行っています。
 ニティン・エウセビウス AWS のシニア エンタープライズ ソリューション アーキテクトであり、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャ、AI/ML の経験があります。彼は生成 AI の可能性を探求することに深い情熱を持っています。彼は顧客と協力して、AWS プラットフォーム上で適切に設計されたアプリケーションを構築できるよう支援し、テクノロジーの課題を解決し、クラウドへの移行を支援することに専念しています。
ニティン・エウセビウス AWS のシニア エンタープライズ ソリューション アーキテクトであり、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャ、AI/ML の経験があります。彼は生成 AI の可能性を探求することに深い情熱を持っています。彼は顧客と協力して、AWS プラットフォーム上で適切に設計されたアプリケーションを構築できるよう支援し、テクノロジーの課題を解決し、クラウドへの移行を支援することに専念しています。
 アルギャ・バナジー は、サンフランシスコ ベイエリアの AWS のシニア ソリューション アーキテクトであり、顧客による AWS クラウドの導入と使用の支援に重点を置いています。 Arghya は、ビッグ データ、データ レイク、ストリーミング、バッチ分析、AI/ML のサービスとテクノロジーに重点を置いています。
アルギャ・バナジー は、サンフランシスコ ベイエリアの AWS のシニア ソリューション アーキテクトであり、顧客による AWS クラウドの導入と使用の支援に重点を置いています。 Arghya は、ビッグ データ、データ レイク、ストリーミング、バッチ分析、AI/ML のサービスとテクノロジーに重点を置いています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

