
編集者による画像
あなたは聞いたことがありますか アンドレ・カルパシー?彼は、深層学習とニューラル ネットワークの研究で知られる著名なコンピューター科学者および AI 研究者です。彼は OpenAI で ChatGPT の開発で重要な役割を果たし、以前は Tesla で AI 担当シニア ディレクターを務めていました。その前から、彼は最初の深層学習クラスを設計し、主な講師を務めていました。 スタンフォード – CS 231n: 視覚認識のための畳み込みニューラル ネットワーク。このクラスはスタンフォード最大のクラスの 150 つとなり、2015 年の入学者数 750 名から 2017 年には XNUMX 名にまで増加しました。ディープ ラーニングに興味がある人は、このクラスを YouTube で視聴することを強くお勧めします。彼についてはこれ以上詳しくは述べませんが、YouTube で最も人気のある講演の XNUMX つに焦点を移していきます。 百万回の視聴回数 「大規模言語モデルの紹介」この講演は、忙しい人向けの LLM の紹介であり、LLM に興味がある人は必見です。
この講演の内容を簡潔にまとめました。これに興味を持った場合は、この記事の最後にあるスライドと YouTube リンクに目を通すことを強くお勧めします。
この講演では、LLM、その機能、およびその使用に関連する潜在的なリスクについて包括的に紹介します。大きく次の 3 つの部分に分かれています。
パート 1: LLM

アンドレイ・カルパシーによるスライド
LLM は、人間のような応答を生成するために、大規模なテキスト コーパスでトレーニングされます。このパートでは、Andrej が Llama 2-70b モデルについて具体的に説明します。これは、70 億のパラメータを持つ最大の LLM の XNUMX つです。モデルは、パラメーター ファイルと実行ファイルという XNUMX つの主要コンポーネントで構成されます。パラメーター ファイルは、モデルの重みとバイアスが含まれる大きなバイナリ ファイルです。これらの重みとバイアスは、本質的にモデルがトレーニング中に学習した「知識」です。実行ファイルは、パラメーター ファイルをロードしてモデルを実行するために使用されるコードの一部です。モデルのトレーニング プロセスは、次の XNUMX つの段階に分けることができます。
1. 事前トレーニング
これには、約 10 テラバイトの大量のテキストをインターネットから収集し、GPU クラスターを使用してこのデータに基づいてモデルをトレーニングすることが含まれます。トレーニング プロセスの結果は、インターネットの非可逆圧縮である基本モデルです。一貫性のある関連性のあるテキストを生成できますが、質問に直接答えることはできません。
2.微調整
事前トレーニングされたモデルは、より有用になるように高品質のデータセットでさらにトレーニングされます。これにより、アシスタント モデルが作成されます。 Andrej 氏は、比較ラベルの使用を伴う微調整の第 3 段階についても言及しています。モデルには、ゼロから回答を生成するのではなく、複数の回答候補が与えられ、最適なものを選択するように求められます。これは、回答を生成するよりも簡単かつ効率的であり、モデルのパフォーマンスをさらに向上させることができます。このプロセスは、ヒューマン フィードバックからの強化学習 (RLHF) と呼ばれます。
パート 2: LLM の将来
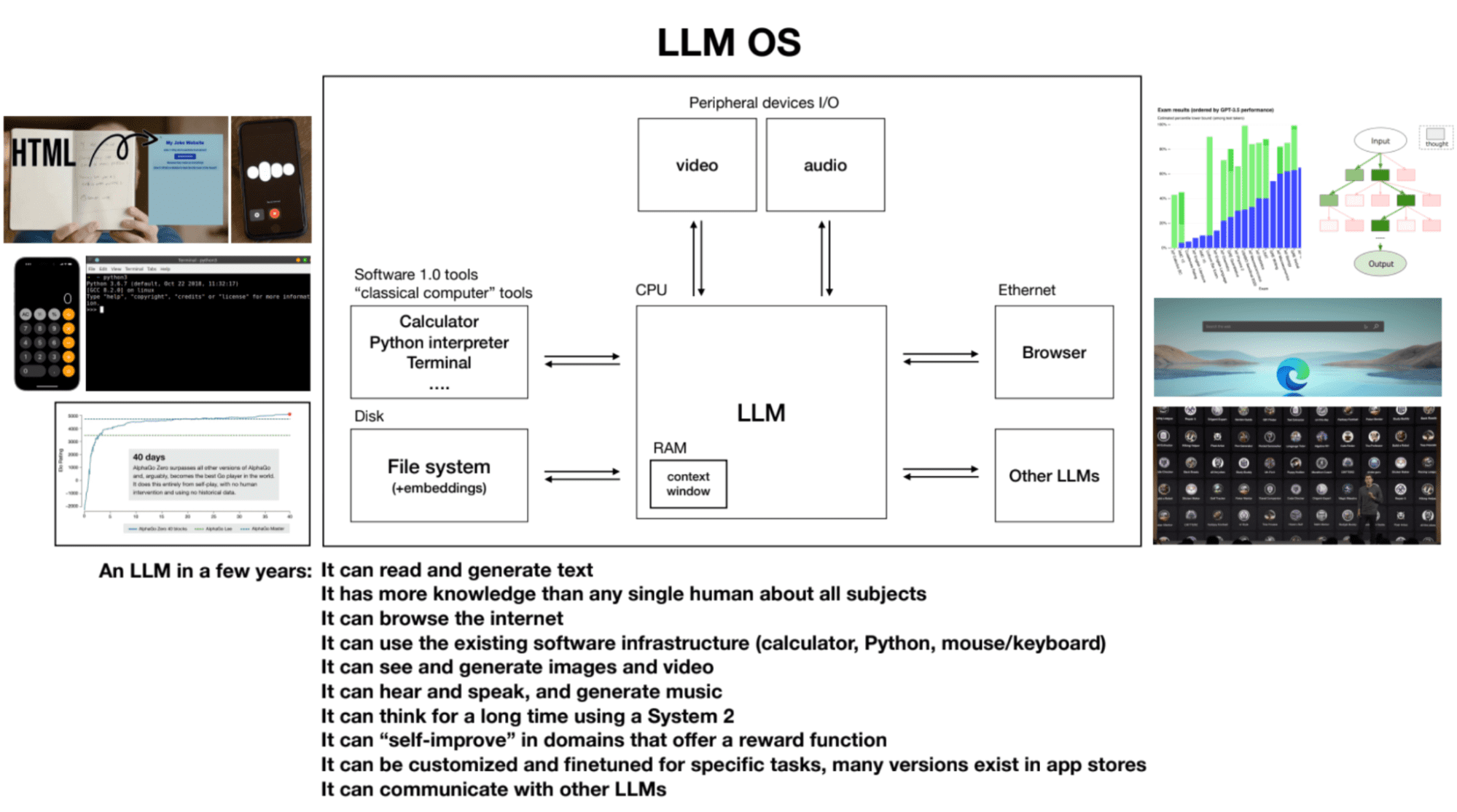
アンドレイ・カルパシーによるスライド
大規模な言語モデルとその機能の将来について説明しながら、次の重要な点について説明します。
1. スケーリングの法則
モデルのパフォーマンスは、パラメーターの数とトレーニング テキストの量という 2 つの変数と相関します。より多くのデータでトレーニングされたモデルが大きいほど、パフォーマンスが向上する傾向があります。
2. ツールの使用方法
ChatGPT のような LLM は、ブラウザ、計算機、Python ライブラリなどのツールを利用して、モデルだけでは困難または不可能なタスクを実行できます。
3. LLM におけるシステム XNUMX とシステム XNUMX の考え方
現在、LLM は主にシステム 1 思考、つまり高速、直感的、パターンベースの思考を採用しています。しかし、システム 2 の思考、つまり、より遅く、合理的で、意識的な努力を必要とする思考に取り組むことができる LLM の開発に関心が集まっています。
4.LLM OS
LLM は、新しいオペレーティング システムのカーネル プロセスと考えることができます。システム 2 を使用して、テキストを読んだり生成したり、さまざまな主題に関する広範な知識を持ったり、インターネットを閲覧したりローカル ファイルを参照したり、既存のソフトウェア インフラストラクチャを使用したり、画像やビデオを生成したり、聞いたり話したり、長時間考えたりすることができます。 LLM はコンピュータの RAM に似ており、カーネル プロセスはタスクを実行するためにコンテキスト ウィンドウの内外で関連情報をページングしようとします。
パート 3: LLM のセキュリティ

アンドレイ・カルパシーによるスライド
Andrej 氏は、LLM に関連するセキュリティ上の課題に対処するために進行中の研究活動を強調します。次の攻撃について説明します。
1.脱獄
LLM の安全対策をバイパスして、有害または不適切な情報を抽出しようとします。例としては、モデルを欺くためのロールプレイングや、最適化された単語や画像のシーケンスを使用した応答の操作などが挙げられます。
2. 即時注入
新しい命令またはプロンプトを LLM に挿入して、その応答を操作します。攻撃者は画像や Web ページ内に命令を隠し、モデルの回答に無関係または有害なコンテンツが含まれる可能性があります。
3. データポイズニング/バックドア攻撃/スリーパーエージェント攻撃
トリガー フレーズを含む悪意のあるデータまたは操作されたデータに対する大規模な言語モデルのトレーニングが含まれます。モデルがトリガー フレーズに遭遇すると、望ましくないアクションを実行したり、誤った予測を提供したりするようにモデルが操作される可能性があります。
以下をクリックすると、YouTube で包括的なビデオをご覧いただけます。
[埋め込みコンテンツ][埋め込みコンテンツ]
スライド: こちらをクリックしてください
LLM を初めて使用し、その取り組みを開始するためのリソースを探している場合は、この包括的なリストが出発点として最適です。強固な基盤を構築するのに役立つ基礎コースと LLM 固有のコースの両方が含まれています。さらに、より構造化された学習体験に興味がある場合は、 マキシム・ラボンヌ 最近、ニーズと経験レベルに基づいて選択できる 3 つの異なるトラックを備えた LLM コースを開始しました。参考までに、両方のリソースへのリンクを次に示します。
カンワル・メーリーン は、データ サイエンスと医療における AI の応用に強い関心を持つ意欲的なソフトウェア開発者です。 Kanwal は、APAC 地域の Google Generation Scholar 2022 に選ばれました。 Kanwal は、流行のトピックに関する記事を書いて技術知識を共有することを好み、技術業界における女性の割合を改善することに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

