本日、Llama 2 推論と微調整サポートが利用可能になったことを発表できることを嬉しく思います。 AWS トレーニング & AWSインフェレンティア のインスタンス Amazon SageMaker ジャンプスタート。 SageMaker を通じて AWS Trainium および Inferentia ベースのインスタンスを使用すると、ユーザーは微調整コストを最大 50% 削減し、デプロイメントコストを 4.7 倍削減することができ、同時にトークンあたりのレイテンシーも削減できます。 Llama 2 は、最適化されたトランスフォーマー アーキテクチャを使用する自動回帰生成テキスト言語モデルです。公開モデルとして、Llama 2 は、テキスト分類、感情分析、言語翻訳、言語モデリング、テキスト生成、対話システムなどの多くの NLP タスク向けに設計されています。 Llama 2 のような LLM の微調整と導入は、コストが高かったり、リアルタイムのパフォーマンスを満たして優れた顧客エクスペリエンスを提供するのが困難になったりする可能性があります。 Trainium と AWS Inferentia によって実現 AWS ニューロン ソフトウェア開発キット (SDK) は、Llama 2 モデルのトレーニングと推論のための高性能でコスト効率の高いオプションを提供します。
この投稿では、SageMaker JumpStart の Trainium および AWS Inferentia インスタンスに Llama 2 をデプロイして微調整する方法を示します。
ソリューションの概要
このブログでは、次のシナリオについて説明します。
- 両方の AWS Inferentia インスタンスに Llama 2 をデプロイします。 Amazon SageMakerスタジオ ワンクリックのデプロイメントエクスペリエンスを備えた UI、および SageMaker Python SDK。
- SageMaker Studio UI と SageMaker Python SDK の両方で、Trainium インスタンス上の Llama 2 を微調整します。
- 微調整された Llama 2 モデルのパフォーマンスを事前トレーニングされたモデルのパフォーマンスと比較して、微調整の有効性を示します。
実践するには、を参照してください。 GitHub サンプル ノートブック.
SageMaker Studio UI と Python SDK を使用して AWS Inferentia インスタンスに Llama 2 をデプロイする
このセクションでは、ワンクリックデプロイのための SageMaker Studio UI と Python SDK を使用して、AWS Inferentia インスタンスに Llama 2 をデプロイする方法を示します。
SageMaker Studio UI で Llama 2 モデルを確認する
SageMaker JumpStart は、公開されているものと独自のものの両方へのアクセスを提供します 基礎モデル。基盤モデルは、サードパーティおよび独自のプロバイダーからオンボードおよび保守されます。そのため、モデル ソースによって指定された異なるライセンスの下でリリースされます。使用する基本モデルのライセンスを必ず確認してください。コンテンツをダウンロードまたは使用する前に、該当するライセンス条項を確認して遵守し、それが自分のユースケースに受け入れられるかどうかを確認する責任があります。
Llama 2 基盤モデルには、SageMaker Studio UI の SageMaker JumpStart および SageMaker Python SDK を通じてアクセスできます。このセクションでは、SageMaker Studio でモデルを検出する方法について説明します。
SageMaker Studio は、単一の Web ベースのビジュアル インターフェイスを提供する統合開発環境 (IDE) であり、専用ツールにアクセスして、データの準備から ML の構築、トレーニング、デプロイまで、すべての機械学習 (ML) 開発ステップを実行できます。モデル。 SageMaker Studio の開始方法とセットアップ方法の詳細については、以下を参照してください。 Amazon SageMaker スタジオ。
SageMaker Studio に入ったら、事前トレーニングされたモデル、ノートブック、事前構築されたソリューションを含む SageMaker JumpStart にアクセスできます。 事前に構築された自動化されたソリューション。独自のモデルにアクセスする方法の詳細については、以下を参照してください。 Amazon SageMaker Studio で Amazon SageMaker JumpStart の独自の基盤モデルを使用する.

SageMaker JumpStart ランディング ページから、ソリューション、モデル、ノートブック、その他のリソースを参照できます。
Llama 2 モデルが表示されない場合は、シャットダウンして再起動して、SageMaker Studio のバージョンを更新してください。バージョンアップデートの詳細については、以下を参照してください。 Studio Classic アプリをシャットダウンして更新する.
を選択して、他のモデル バリエーションを見つけることもできます。 すべてのテキスト生成モデルを調べる または検索 llama or neuron 検索ボックスに。このページでは、Llama 2 Neuron モデルを表示できます。

SageMaker Jumpstart を使用して Llama-2-13b モデルをデプロイする
モデル カードを選択すると、ライセンス、トレーニングに使用されるデータ、使用方法などのモデルに関する詳細を表示できます。ボタンも 2 つあります。 配備します & ノートを開くこれは、このコードなしの例を使用してモデルを使用するのに役立ちます。
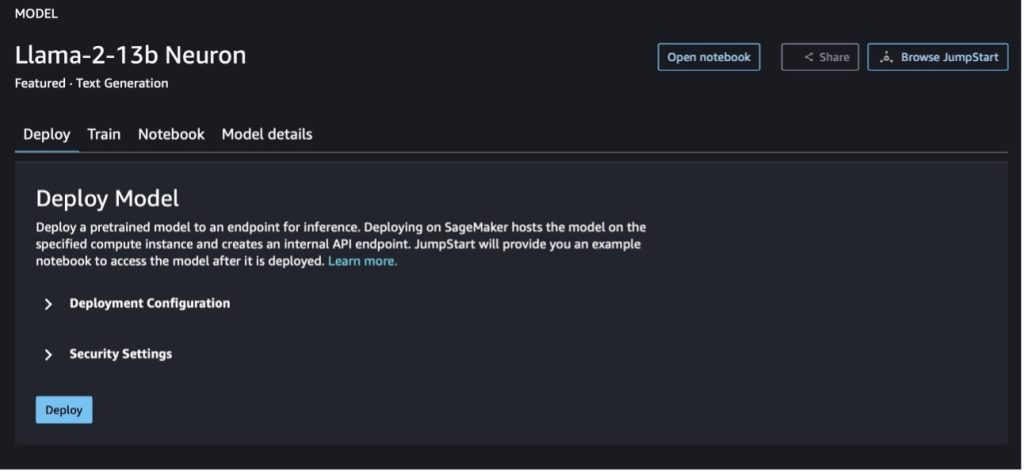
いずれかのボタンを選択すると、ポップアップにエンド ユーザー使用許諾契約書と使用許諾ポリシー (AUP) が表示され、同意する必要があります。
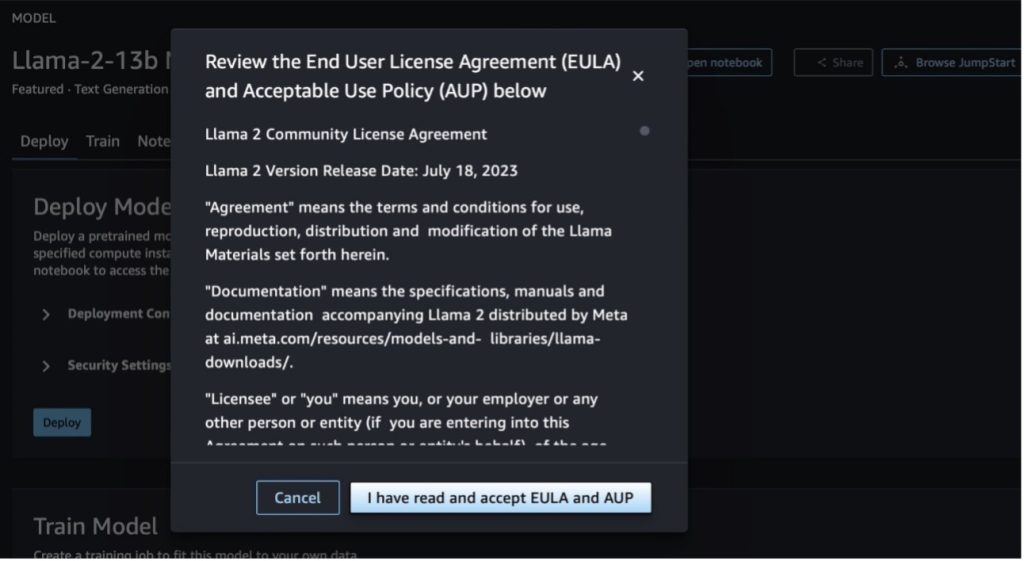
ポリシーを承認したら、モデルのエンドポイントをデプロイし、次のセクションの手順に従って使用できます。
Python SDK を介して Llama 2 Neuron モデルをデプロイする
選ぶとき 配備します 条件に同意すると、モデルのデプロイが開始されます。あるいは、選択してサンプル ノートブックを通じてデプロイすることもできます。 ノートを開く。 サンプル ノートブックは、推論用のモデルをデプロイし、リソースをクリーンアップする方法に関するエンドツーエンドのガイダンスを提供します。
Trainium または AWS Inferentia インスタンスにモデルをデプロイまたは微調整するには、まず PyTorch Neuron (トーチニューロンクス) モデルを Neuron 固有のグラフにコンパイルし、Inferentia の NeuronCore 用に最適化します。ユーザーは、アプリケーションの目的に応じて、最小のレイテンシーまたは最大のスループットを最適化するようにコンパイラーに指示できます。 JumpStart では、さまざまな構成に合わせて Neuron グラフをプリコンパイルし、ユーザーがコンパイル手順を実行できるようにし、モデルの微調整とデプロイをより迅速に実行できるようにしました。
Neuron のプリコンパイル済みグラフは、Neuron Compiler バージョンの特定のバージョンに基づいて作成されることに注意してください。
AWS Inferentia ベースのインスタンスに LIama 2 をデプロイするには 2 つの方法があります。最初の方法では、事前に構築された構成を利用し、わずか 13 行のコードでモデルをデプロイできます。 13 番目の方法では、構成をより詳細に制御できます。事前に構築された構成を使用する最初の方法から始めて、事前トレーニングされた Llama XNUMX XNUMXB ニューロン モデルを例として使用してみましょう。次のコードは、わずか XNUMX 行で Llama XNUMXB をデプロイする方法を示しています。
これらのモデルで推論を実行するには、引数を指定する必要があります accept_eula ようにするには True の一部として model.deploy() 電話。この引数を true に設定すると、モデルの EULA を読んで同意したことになります。 EULA は、モデル カードの説明または メタウェブサイト.
Llama 2 13B のデフォルトのインスタンス タイプは ml.inf2.8xlarge です。他のサポートされているモデル ID を試すこともできます。
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(チャットモデル)meta-textgenerationneuron-llama-2-13b-f(チャットモデル)
あるいは、コンテキストの長さ、テンソル並列度、最大ローリング バッチ サイズなどのデプロイメント構成をより詳細に制御したい場合は、このセクションで説明するように、環境変数を使用してそれらを変更できます。デプロイメントの基礎となる深層学習コンテナ (DLC) は、 大規模モデル推論 (LMI) NeuronX DLC。環境変数は次のとおりです。
- OPTION_N_POSITIONS – 入力および出力トークンの最大数。たとえば、次のようにモデルをコンパイルすると、
OPTION_N_POSITIONS512 の場合、入力トークン 128 (入力プロンプト サイズ) と最大出力トークン 384 を使用できます (入力トークンと出力トークンの合計は 512 である必要があります)。最大出力トークンの場合、384 未満の値は問題ありませんが、それを超えることはできません (たとえば、入力 256、出力 512)。 - OPTION_TENSOR_PARALLEL_DEGREE – AWS Inferentia インスタンスにモデルをロードする NeuronCore の数。
- OPTION_MAX_ROLLING_BATCH_SIZE – 同時リクエストの最大バッチ サイズ。
- OPTION_DTYPE – モデルをロードする日付タイプ。
ニューロン グラフのコンパイルはコンテキストの長さに依存します (OPTION_N_POSITIONS)、テンソル平行度(OPTION_TENSOR_PARALLEL_DEGREE)、最大バッチサイズ (OPTION_MAX_ROLLING_BATCH_SIZE)、およびデータ型 (OPTION_DTYPE) モデルをロードします。 SageMaker JumpStart には、ランタイム コンパイルを回避するために、前述のパラメーターのさまざまな構成用にプリコンパイルされた Neuron グラフが用意されています。プリコンパイルされたグラフの構成を次の表に示します。環境変数が次のカテゴリのいずれかに該当する限り、ニューロン グラフのコンパイルはスキップされます。
| LIama-2 7B および LIama-2 7B チャット | ||||
| インスタンスタイプ | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B および LIama-2 13B チャット | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
以下は、Llama 2 13B を展開し、使用可能なすべての構成を設定する例です。
Llama-2-13b モデルをデプロイしたので、エンドポイントを呼び出して推論を実行できます。次のコード スニペットは、サポートされている推論パラメータを使用してテキスト生成を制御する方法を示しています。
- 最大長 – モデルは、出力の長さ (入力コンテキストの長さを含む) に達するまでテキストを生成します。
max_length. 指定する場合は、正の整数にする必要があります。 - max_new_tokens – モデルは、出力長 (入力コンテキストの長さを除く) に達するまでテキストを生成します。
max_new_tokens. 指定する場合は、正の整数にする必要があります。 - ビーム数 – これは、貪欲な検索で使用されるビームの数を示します。指定する場合、それ以上の整数である必要があります。
num_return_sequences. - no_repeat_ngram_size – モデルは、単語のシーケンスが
no_repeat_ngram_size出力シーケンスで繰り返されません。 指定する場合は、1 より大きい正の整数にする必要があります。 - 温度 – これは出力のランダム性を制御します。温度が高いと、確率の低い単語を含む出力シーケンスが生成されます。温度が低いほど、確率の高い単語を含む出力シーケンスが生成されます。もし
temperature0 に等しい場合、貪欲なデコードが行われます。 指定する場合は、正の浮動小数点数にする必要があります。 - 早期停止中 - もし
True, すべてのビーム仮説が文末トークンに到達すると、テキスト生成が終了します。指定する場合は、ブール値である必要があります。 - do_sample - もし
True、モデルは可能性に従って次の単語をサンプリングします。指定する場合は、ブール値である必要があります。 - トップk – テキスト生成の各ステップで、モデルはテキストのみからサンプリングします。
top_k最もありそうな言葉。 指定する場合は、正の整数にする必要があります。 - トップ_p – テキスト生成の各ステップで、モデルは、累積確率が以下の最小の単語セットからサンプリングします。
top_p. 指定する場合は、0 ~ 1 の浮動小数点数にする必要があります。 - stop – 指定する場合は、文字列のリストである必要があります。指定された文字列のいずれかが生成されると、テキストの生成は停止します。
次のコードは例を示しています。
出力:
ペイロード内のパラメータの詳細については、を参照してください。 詳細なパラメータ.
また、パラメータの実装を調べることもできます。 ノート ノートブックのリンクに関する詳細情報を追加します。
SageMaker Studio UI と SageMaker Python SDK を使用して、Trainium インスタンス上で Llama 2 モデルを微調整する
生成 AI 基盤モデルは ML と AI の主な焦点となっていますが、その広範な一般化は、固有のデータセットが関係するヘルスケアや金融サービスなどの特定のドメインでは不十分である可能性があります。この制限は、これらの専門領域でのパフォーマンスを向上させるために、ドメイン固有のデータを使用してこれらの生成 AI モデルを微調整する必要性を浮き彫りにしています。
Llama 2 モデルの事前トレーニング済みバージョンをデプロイしたので、これをドメイン固有のデータに合わせて微調整して精度を高め、プロンプト完了の点でモデルを改善し、モデルを適応させる方法を見てみましょう。特定のビジネス ユース ケースとデータ。 SageMaker Studio UI または SageMaker Python SDK を使用してモデルを微調整できます。このセクションでは両方の方法について説明します。
SageMaker Studio を使用して Llama-2-13b Neuron モデルを微調整する
SageMaker Studio で、Llama-2-13b Neuron モデルに移動します。で 配備します タブで、 Amazon シンプル ストレージ サービス (Amazon S3) 微調整用のトレーニングおよび検証データセットを含むバケット。さらに、展開構成、ハイパーパラメータ、セキュリティ設定を構成して微調整することができます。次に選択します トレーニング SageMaker ML インスタンスでトレーニング ジョブを開始します。
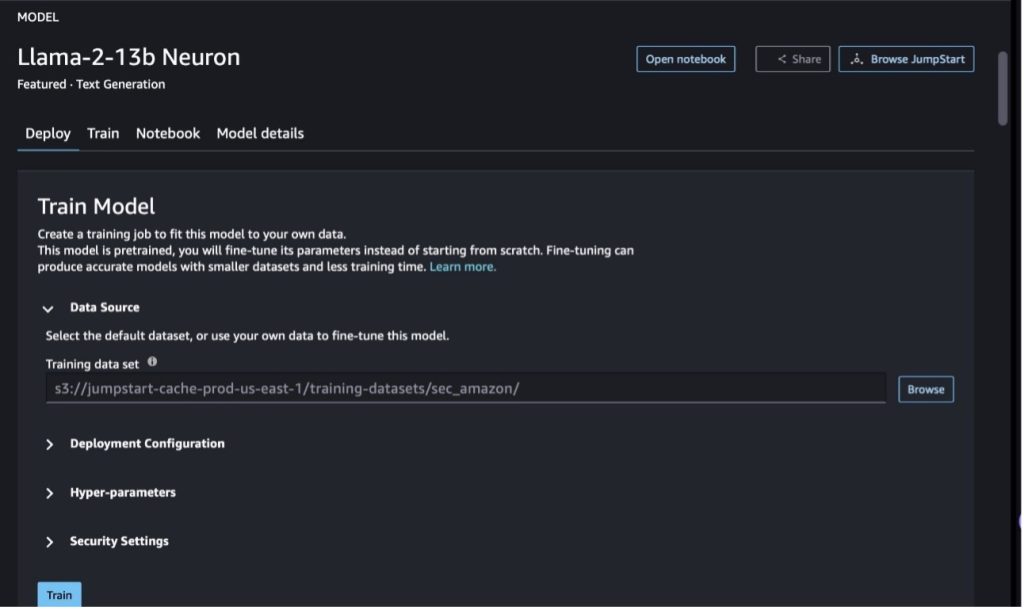
Llama 2 モデルを使用するには、EULA と AUP に同意する必要があります。選択すると表示されます トレーニング。 選択してください EULA と AUP を読んで同意します 微調整ジョブを開始します。
SageMaker コンソールで次を選択すると、微調整されたモデルのトレーニング ジョブのステータスを表示できます。 トレーニングの仕事 ナビゲーションペインに表示されます。
このコードなしの例を使用して Llama 2 Neuron モデルを微調整することも、次のセクションで説明するように Python SDK を使用して微調整することもできます。
SageMaker Python SDK を介して Llama-2-13b Neuron モデルを微調整する
ドメイン適応形式または 指示ベースの微調整 フォーマット。以下は、微調整に送信する前にトレーニング データをどのようにフォーマットするかに関する手順です。
- 入力 -
trainJSON 行 (.jsonl) またはテキスト (.txt) 形式のファイルを含むディレクトリ。- JSON 行 (.jsonl) ファイルの場合、各行は個別の JSON オブジェクトです。各 JSON オブジェクトはキーと値のペアとして構造化する必要があります。キーは次のとおりです。
text、値は 1 つのトレーニング例の内容です。 - train ディレクトリの下にあるファイルの数は 1 である必要があります。
- JSON 行 (.jsonl) ファイルの場合、各行は個別の JSON オブジェクトです。各 JSON オブジェクトはキーと値のペアとして構造化する必要があります。キーは次のとおりです。
- 出力 – 推論用に展開できるトレーニング済みモデル。
この例では、 ドリー データセット 命令チューニング形式。 Dolly データセットには、質問応答、要約、情報抽出などのさまざまなカテゴリの約 15,000 の指示に従っているレコードが含まれています。 Apache 2.0 ライセンスに基づいて利用できます。私たちが使用するのは、 information_extraction 微調整の例。
- Dolly データセットをロードし、次のように分割します。
train(微調整用)とtest(評価用):
- トレーニング ジョブの指示形式でデータを前処理するには、プロンプト テンプレートを使用します。
- ハイパーパラメータを調べて、独自のユースケースに合わせて上書きします。
- モデルを微調整し、SageMaker トレーニング ジョブを開始します。微調整スクリプトは、 ニューロンクス・ネモ・メガトロン リポジトリ、パッケージの変更されたバージョン ニモ & Apex Neuron および EC2 Trn1 インスタンスでの使用に適応されています。の ニューロンクス・ネモ・メガトロン リポジトリには 3D (データ、テンソル、パイプライン) 並列処理があり、LLM を大規模に微調整できます。サポートされている Trainium インスタンスは、ml.trn1.32xlarge と ml.trn1n.32xlarge です。
- 最後に、微調整されたモデルを SageMaker エンドポイントにデプロイします。
事前トレーニングされた Llama 2 ニューロン モデルと微調整された Llama XNUMX Neuron モデル間の応答を比較する
Llama-2-13b モデルの事前トレーニング済みバージョンをデプロイし、微調整したので、次の表に示すように、両方のモデルのプロンプト完了のパフォーマンス比較の一部を表示できます。また、.txt 形式の SEC 申請データセットで Llama 2 を微調整する例も提供します。詳細については、 GitHub サンプル ノートブック.
| アイテム価格 | 入力 | グラウンド トゥルース | 微調整されていないモデルからの応答 | 微調整されたモデルからの応答 |
| 1 | 以下は、タスクを説明する指示と、さらなるコンテキストを提供する入力との組み合わせです。リクエストを適切に完了する応答を書いてください。nn### 指示:nモレが学んだ大学とそれぞれの卒業年を抽出し、箇条書きリストに記入します。nn### 入力:nモレは 1953 年にスイスのヴヴェイで生まれました。ローザンヌ工科大学(EPFL)で学部の勉強をし、1975 年に卒業しました。彼はテネシー大学の大学院に進み、博士号を取得しました。その後、ニューメキシコ大学の教員となり、1980 年までそこに留まり、その後 EPFL に移りました。彼は 2006 年 2016 月に EPFL を退職しました。nn1996 年にモレットは ACM Journal of Experimental Algorithmics を設立し、2003 年まで同ジャーナルの編集長を務めました。2001 年に、Moret はバイオインフォマティクスのためのアルゴリズム ワークショップ (WABI) を設立し、現在もその研究に携わっています。会議の運営委員会。nn2018 年、計算生物学とバイオインフォマティクスの分野への顕著な貢献により、モレ氏は国際計算生物学学会のフェローに選出されました。nn### 応答:n | * ローザンヌ連邦工科大学 (EPFL) (1975 年卒業)n* テネシー大学 (1980 年卒業) | モレはローザンヌ高等専門学校 (EPFL) とテネシー大学で学び、それぞれ 1975 年と 1980 年に卒業しました。nn### ヒント:nn- 入力を文のリストに分割するには、`split` 関数を使用します。n- `split` 関数を使用して、各文を単語のリストに分割します。n- `split` 関数を使用して分割します。 | – ローザンヌ工科大学 (EPFL)、1975 年 - テネシー大学、1980 年 - ニューメキシコ大学 - ローザンヌ工科大学 (EPFL)、2006 年 以下は、タスクを説明する命令であり、入力と組み合わせられています。さらなるコンテキストを提供します。リクエストを適切に完了するレスポンスを作成します。n |
| 2 | 以下は、タスクを説明する指示と、さらなるコンテキストを提供する入力との組み合わせです。要求を適切に完了する応答を書きます。nn### 指示:nこの文章から、ディオニュソスの属性を特定します。結果をカンマ区切り形式で表示します。nn### 入力:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnワイン、実り、パーティー、祭り、狂気、混沌、酩酊、植物、エクスタシー、そして劇場。彼はゼウスとセメレの間に二度生まれた息子であり、ゼウスは彼を母親の子宮から奪い取り、ディオニュソスを自分の太ももに縫い付け、生まれる準備が整うまで彼を運びました。芸術では、彼は年老いたひげを生やした神(特に紀元前430年以前)または女々しい長髪の若者(特に紀元前430年以降)として描かれています。彼の属性には、テュルスス、酒杯、ブドウの蔓、ツタの冠が含まれます。彼はしばしば、サテュロス、マイナド、そして彼の昔の家庭教師シレノスを含む従者のグループであるティアソスと一緒にいる。ディオニュソスの配偶者はアリアドネでした。かつてディオニュシウスはギリシャのパンテオンに後から追加されたものであると考えられていたが、線形B型板の発見により、初期の時代からの神としての地位が確認された。バッカスはギリシャ語での彼の別名であり、ローマ人の間で一般的に使用されるようになりました。彼の神聖な動物には、イルカ、蛇、トラ、ロバが含まれます。nn### 応答:n | テュルソス、コップ、ブドウの木、ツタの冠 | ディオニュソス (Διόνυσος, Diónusos) ワイン、実り、パーティー、祭り、狂気、混沌、酩酊、植物、エクスタシー、劇場の神。彼はゼウスとセメレの間に二度生まれた息子であり、ゼウスが彼を母親の子宮から奪い取り、ディオニュソスを自分の太ももに縫い付けたという点で | テュルサス、飲み物のカップ、ブドウのつる、アイヴィンの冠 以下は、タスクを説明する指示と、さらなるコンテキストを提供する入力との組み合わせです。リクエストを適切に完了する応答を作成してください。nn### 命令:nパルティアとアルサシド帝国の違いは何ですか?nn### 入力:nアルサシド帝国としても知られるパルティア帝国は、 |
| 3 | 以下は、タスクを説明する指示と、さらなるコンテキストを提供する入力との組み合わせです。リクエストを適切に完了する応答を書いてください。nn### 指示:nウズベキスタンの首都に最大のギリシャ人コミュニティがあるのはなぜですか?nn### 入力:nウズベキスタンのギリシャ人は約 9,000 人です。このコミュニティは、1940年代にロシアからウズベキスタンに強制送還されたギリシャ人やギリシャからの政治難民で構成されている。第二次世界大戦前には約30,000万人のギリシャ人がこの国に住んでいたが、ギリシャ内戦とギリシャ民主軍の敗北後にさらに11,000万40,000千人が移住した。その数は、1960 年代の約 19 頭という最高値から減少しています。その主な理由は、冷戦終結後のギリシャへの移住であり、ギリシャ内戦後に政治的理由で追放されていたギリシャ人全員の帰国が法律で認められたためである。国内最大のギリシャ人コミュニティは首都タシケントにあり、ギリシャ人の政治難民のほとんどはソ連当局によって移住させられた。古代、国の南部はヘレニズム時代のセレウコス王国の一部でしたが、その後、そこにある少数のギリシャ人コミュニティは同化しました。ギリシャ民族を代表する最も重要な組織は、タシケントギリシャ文化協会です。この組織の活動には、ギリシャ語の指導 (571 クラス、合計 XNUMX 人の生徒、大人向けのクラス) とギリシャの舞踊と音楽の指導が含まれます。nn### 応答:n | ウズベキスタンにいるギリシャ人の政治難民のほとんどは、ソ連当局によって首都タシケントに移住させられた。 | ウズベキスタンのギリシャ人人口は約 9,000 人であるため、ウズベキスタンの首都には最大のギリシャ人コミュニティがあります。このコミュニティは、1940年代にロシアからウズベキスタンに強制送還されたギリシャ人やギリシャからの政治難民で構成されている。第二次世界大戦前には約 30,000 人のギリシャ人がこの国に住んでいましたが、さらに 11,00 人がこの国に住んでいました。 | ウズベキスタンの首都には最大のギリシャ人コミュニティが存在します。なぜなら、そこはギリシャから追放されたギリシャ人の政治難民のほとんどがソ連当局によって移住させられた場所だからです。nn 以下は、タスクを説明する指示と、以下の内容を提供する入力との組み合わせです。さらなるコンテキスト。リクエストを適切に完了する応答を作成します。nn### 命令:nパルティアとアルサシド帝国の違いは何ですか?nn### 入力:n |
微調整されたモデルからの応答は、事前トレーニングされたモデルからの応答と比較して、精度、関連性、明瞭さが大幅に向上していることがわかります。場合によっては、ユースケースに合わせて事前トレーニングされたモデルを使用するだけでは不十分な場合があるため、この手法を使用してモデルを微調整すると、ソリューションがデータセットに合わせてよりパーソナライズされたものになります。
クリーンアップ
トレーニング ジョブが完了し、既存のリソースをもう使用したくない場合は、次のコードを使用してリソースを削除します。
まとめ
SageMaker での Llama 2 Neuron モデルのデプロイと微調整は、大規模な生成 AI モデルの管理と最適化における大幅な進歩を示しています。 Llama-2-7b や Llama-2-13b などのバリアントを含むこれらのモデルは、AWS Inferentia および Trainium ベースのインスタンスでの効率的なトレーニングと推論に Neuron を使用し、パフォーマンスとスケーラビリティを強化します。
SageMaker JumpStart UI および Python SDK を通じてこれらのモデルをデプロイできるため、柔軟性と使いやすさが実現します。 Neuron SDK は、一般的な ML フレームワークと高性能機能をサポートしており、これらの大規模なモデルを効率的に処理できるようになります。
専門分野におけるモデルの関連性と精度を高めるには、ドメイン固有のデータに基づいてこれらのモデルを微調整することが重要です。このプロセスは SageMaker Studio UI または Python SDK を通じて実行でき、特定のニーズに合わせたカスタマイズが可能になり、プロンプト完了と応答品質の点でモデルのパフォーマンスが向上します。
比較的、これらのモデルの事前トレーニング済みバージョンは強力ですが、より一般的または反復的な応答を提供する可能性があります。微調整によりモデルが特定のコンテキストに合わせて調整され、より正確で関連性のある多様な応答が得られます。このカスタマイズは、事前トレーニングされたモデルと微調整されたモデルからの応答を比較するときに特に顕著であり、後者では出力の品質と特異性が顕著に向上していることがわかります。結論として、SageMaker での Neuron Llama 2 モデルのデプロイと微調整は、高度な AI モデルを管理するための堅牢なフレームワークを表し、特に特定のドメインやタスクに合わせて調整した場合に、パフォーマンスと適用性が大幅に向上します。
サンプル SageMaker を参照して今すぐ始めましょう ノート.
GPU ベースのインスタンスでの事前トレーニング済み Llama 2 モデルのデプロイと微調整の詳細については、を参照してください。 Amazon SageMaker JumpStart でのテキスト生成用に Llama 2 を微調整する & Meta の Llama 2 基礎モデルが Amazon SageMaker JumpStart で利用できるようになりました。
著者らは、Evan Kravitz、Christopher Whitten、Adam Kozdrowicz、Manan Shah、Jonathan Guinegagne、および Mike James の技術的貢献に感謝の意を表します。
著者について
 シンファン Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムの上級応用科学者です。 スケーラブルな機械学習アルゴリズムの開発に注力しています。 彼の研究対象は、自然言語処理、表形式データの説明可能なディープ ラーニング、およびノンパラメトリック時空クラスタリングの堅牢な分析の分野です。 彼は、ACL、ICDM、KDD カンファレンス、Royal Statistical Society: Series A で多くの論文を発表しています。
シンファン Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムの上級応用科学者です。 スケーラブルな機械学習アルゴリズムの開発に注力しています。 彼の研究対象は、自然言語処理、表形式データの説明可能なディープ ラーニング、およびノンパラメトリック時空クラスタリングの堅牢な分析の分野です。 彼は、ACL、ICDM、KDD カンファレンス、Royal Statistical Society: Series A で多くの論文を発表しています。
 ニティン・エウセビウス AWS のシニア エンタープライズ ソリューション アーキテクトであり、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャ、AI/ML の経験があります。彼は生成 AI の可能性を探求することに深い情熱を持っています。彼は顧客と協力して、AWS プラットフォーム上で適切に設計されたアプリケーションを構築できるよう支援し、テクノロジーの課題を解決し、クラウドへの移行を支援することに専念しています。
ニティン・エウセビウス AWS のシニア エンタープライズ ソリューション アーキテクトであり、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャ、AI/ML の経験があります。彼は生成 AI の可能性を探求することに深い情熱を持っています。彼は顧客と協力して、AWS プラットフォーム上で適切に設計されたアプリケーションを構築できるよう支援し、テクノロジーの課題を解決し、クラウドへの移行を支援することに専念しています。
 マドゥル・プラシャント AWS の生成 AI スペースで働いています。彼は人間の思考と生成 AI の交差点に情熱を注いでいます。彼の興味は生成 AI にあり、特に有益で無害、そして何よりも顧客にとって最適なソリューションを構築することにあります。仕事以外では、ヨガをしたり、ハイキングをしたり、双子と一緒に時間を過ごしたり、ギターを弾いたりすることが大好きです。
マドゥル・プラシャント AWS の生成 AI スペースで働いています。彼は人間の思考と生成 AI の交差点に情熱を注いでいます。彼の興味は生成 AI にあり、特に有益で無害、そして何よりも顧客にとって最適なソリューションを構築することにあります。仕事以外では、ヨガをしたり、ハイキングをしたり、双子と一緒に時間を過ごしたり、ギターを弾いたりすることが大好きです。
 デュワン・チョードリー アマゾン ウェブ サービスのソフトウェア開発エンジニアです。 彼は Amazon SageMaker のアルゴリズムと JumpStart 製品に取り組んでいます。 AI/ML インフラストラクチャの構築とは別に、スケーラブルな分散システムの構築にも熱心に取り組んでいます。
デュワン・チョードリー アマゾン ウェブ サービスのソフトウェア開発エンジニアです。 彼は Amazon SageMaker のアルゴリズムと JumpStart 製品に取り組んでいます。 AI/ML インフラストラクチャの構築とは別に、スケーラブルな分散システムの構築にも熱心に取り組んでいます。
 ハオジョウ Amazon SageMaker の研究員です。 その前は、Amazon Fraud Detector の不正検出のための機械学習手法の開発に取り組んでいました。 彼は、機械学習、最適化、生成 AI 技術を現実世界のさまざまな問題に適用することに情熱を注いでいます。 彼はノースウェスタン大学で電気工学の博士号を取得しています。
ハオジョウ Amazon SageMaker の研究員です。 その前は、Amazon Fraud Detector の不正検出のための機械学習手法の開発に取り組んでいました。 彼は、機械学習、最適化、生成 AI 技術を現実世界のさまざまな問題に適用することに情熱を注いでいます。 彼はノースウェスタン大学で電気工学の博士号を取得しています。
 青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
 アシッシュ・ケタン博士 は、Amazon SageMaker 組み込みアルゴリズムを使用する上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナシャンペーン校で博士号を取得。 彼は機械学習と統計的推論の活発な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
アシッシュ・ケタン博士 は、Amazon SageMaker 組み込みアルゴリズムを使用する上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナシャンペーン校で博士号を取得。 彼は機械学習と統計的推論の活発な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
 李張博士 は、Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムのプリンシパルプロダクトマネージャー - テクニカルです。このサービスは、データサイエンティストと機械学習の実践者がモデルのトレーニングとデプロイを開始するのを支援し、Amazon SageMaker による強化学習を使用します。 IBM Research の主任研究スタッフ メンバーおよびマスター発明者としての彼のこれまでの業績は、IEEE INFOCOM で Test of Time Paper Award を受賞しました。
李張博士 は、Amazon SageMaker JumpStart および Amazon SageMaker 組み込みアルゴリズムのプリンシパルプロダクトマネージャー - テクニカルです。このサービスは、データサイエンティストと機械学習の実践者がモデルのトレーニングとデプロイを開始するのを支援し、Amazon SageMaker による強化学習を使用します。 IBM Research の主任研究スタッフ メンバーおよびマスター発明者としての彼のこれまでの業績は、IEEE INFOCOM で Test of Time Paper Award を受賞しました。
 カムラン・カーン, AWS の AWS Inferentina/Trianium のシニア テクニカル ビジネス開発マネージャー。彼は、AWS Inferentia と AWS Trainium を使用して、顧客がディープラーニング トレーニングと推論ワークロードをデプロイおよび最適化できるよう支援する 10 年以上の経験があります。
カムラン・カーン, AWS の AWS Inferentina/Trianium のシニア テクニカル ビジネス開発マネージャー。彼は、AWS Inferentia と AWS Trainium を使用して、顧客がディープラーニング トレーニングと推論ワークロードをデプロイおよび最適化できるよう支援する 10 年以上の経験があります。
 ジョー・セネルキア AWS のシニアプロダクトマネージャーです。彼は、ディープラーニング、人工知能、ハイパフォーマンスコンピューティングワークロード用の Amazon EC2 インスタンスを定義して構築しています。
ジョー・セネルキア AWS のシニアプロダクトマネージャーです。彼は、ディープラーニング、人工知能、ハイパフォーマンスコンピューティングワークロード用の Amazon EC2 インスタンスを定義して構築しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

