大規模言語モデル (LLM) をデプロイする場合、機械学習 (ML) 担当者は通常、モデル提供パフォーマンスの 2 つの測定値を気にします。1 つは単一のトークンの生成にかかる時間で定義されるレイテンシー、もう 1 つは生成されるトークンの数で定義されるスループットです。毎秒。デプロイされたエンドポイントへの 1 つのリクエストは、モデルのレイテンシの逆数にほぼ等しいスループットを示しますが、複数の同時リクエストが同時にエンドポイントに送信される場合、これは必ずしも当てはまりません。クライアント側での同時リクエストの連続バッチ処理などのモデル サービング手法により、レイテンシとスループットには複雑な関係があり、モデル アーキテクチャ、サービング構成、インスタンス タイプのハードウェア、同時リクエストの数、入力ペイロードの変動などに基づいて大きく異なります。入力トークンと出力トークンの数として。
この投稿では、Llama 2、Falcon、Mistral のバリアントを含む、Amazon SageMaker JumpStart で利用可能な LLM の包括的なベンチマークを通じてこれらの関係を調査します。 SageMaker JumpStart を使用すると、ML 実践者は、公開されている基盤モデルの幅広い選択肢から選択して、専用のモデルにデプロイできます。 アマゾンセージメーカー ネットワークから隔離された環境内のインスタンス。アクセラレータの仕様が LLM ベンチマークにどのような影響を与えるかについての理論的原則を提供します。また、単一のエンドポイントの背後に複数のインスタンスをデプロイした場合の影響も示します。最後に、レイテンシ、スループット、コスト、利用可能なインスタンス タイプの制約に関する要件に合わせて SageMaker JumpStart デプロイメント プロセスを調整するための実践的な推奨事項を提供します。すべてのベンチマーク結果と推奨事項は、多用途のベンチマークに基づいています。 ノート ユースケースに適応できるということです。
導入されたエンドポイントのベンチマーク
次の図は、さまざまなモデル タイプとインスタンス タイプにわたるデプロイメント構成の最小レイテンシ (左) と最大スループット (右) の値を示しています。重要なのは、これらの各モデルのデプロイメントでは、デプロイメントに必要なモデル ID とインスタンス タイプが指定された場合に、SageMaker JumpStart によって提供されるデフォルト設定が使用されることです。
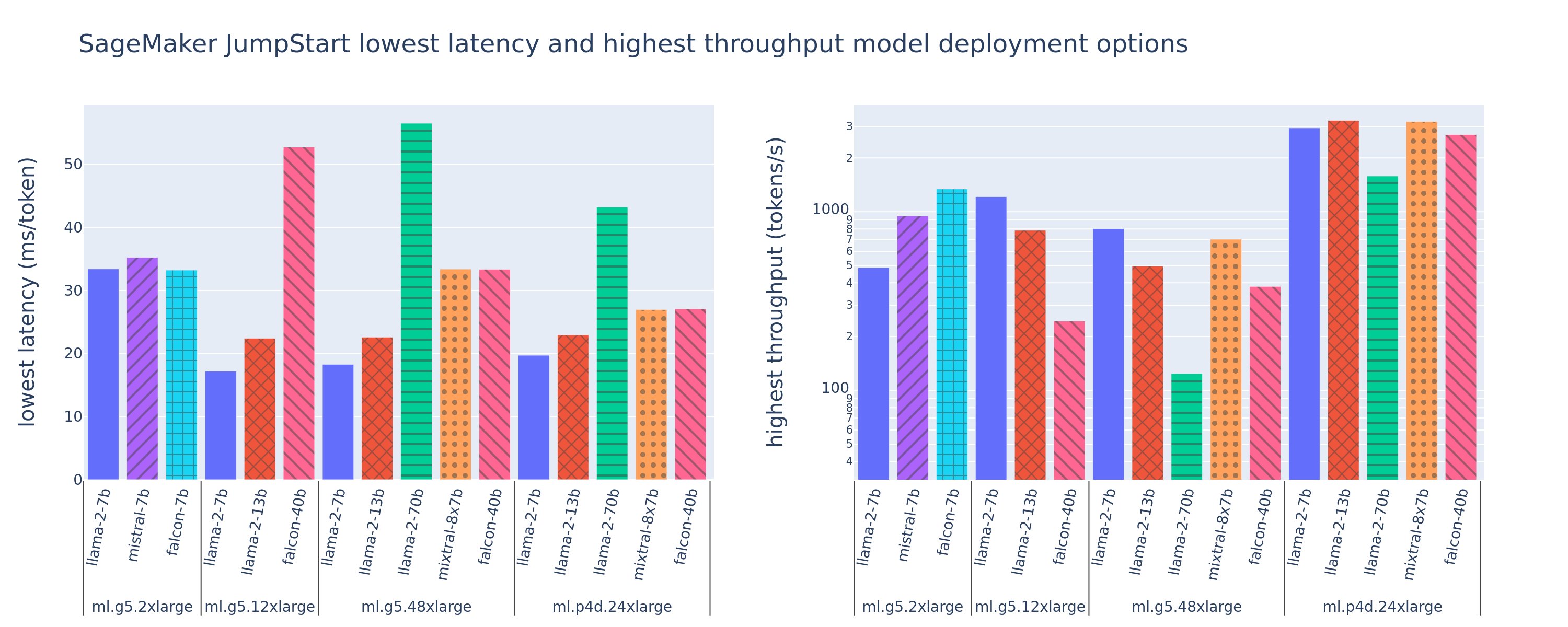
これらのレイテンシとスループットの値は、256 個の入力トークンと 256 個の出力トークンを含むペイロードに対応します。レイテンシーが最も低い構成では、単一の同時リクエストに対応するモデルが制限され、スループットが最も高い構成では、可能な同時リクエストの数が最大化されます。ベンチマークでわかるように、同時リクエストが増加するとスループットは単調に増加しますが、大規模な同時リクエストの改善は減少します。さらに、モデルはサポートされているインスタンス上で完全にシャード化されます。たとえば、ml.g5.48xlarge インスタンスには 8 つの GPU があるため、このインスタンスを使用するすべての SageMaker JumpStart モデルは、XNUMX つの利用可能なアクセラレータすべてでテンソル並列処理を使用してシャーディングされます。
この図からいくつかの点に注目することができます。まず、すべてのモデルがすべてのインスタンスでサポートされているわけではありません。 Falcon 7B などの一部の小規模モデルはモデル シャーディングをサポートしていませんが、大規模なモデルではより高いコンピューティング リソース要件が必要になります。第 XNUMX に、シャーディングが増加するとパフォーマンスは通常向上しますが、小規模なモデルの場合は必ずしも向上するとは限りません。. これは、7B や 13B などの小規模なモデルでは、あまりにも多くのアクセラレータ間でシャーディングすると、かなりの通信オーバーヘッドが発生するためです。これについては後ほど詳しく説明します。最後に、ml.p4d.24xlarge インスタンスは、A100G GPU よりも A10 のメモリ帯域幅の向上により、スループットが大幅に向上する傾向があります。後で説明するように、特定のインスタンス タイプを使用するかどうかは、レイテンシ、スループット、コストの制約などのデプロイメント要件によって異なります。
これらの最小のレイテンシと最大のスループット構成値を取得するにはどうすればよいでしょうか?まずは、次の曲線に示すように、2 個の入力トークンと 7 個の出力トークンを持つペイロードの ml.g5.12xlarge インスタンス上の Llama 256 256B エンドポイントのレイテンシとスループットをプロットしてみましょう。同様の曲線が、デプロイされたすべての LLM エンドポイントに存在します。

同時実行性が増加すると、スループットと遅延も単調に増加します。したがって、レイテンシが最も低くなるのは同時リクエスト値 1 のときであり、同時リクエストを増やすことでコスト効率よくシステム スループットを向上させることができます。この曲線には明確な「膝」が存在します。ここでは、追加の同時実行に関連するスループットの向上が、関連するレイテンシの増加を上回らないことが明らかです。この膝の正確な位置は使用例によって異なります。一部の実践者は、事前に指定されたレイテンシ要件 (たとえば、100 ミリ秒/トークン) を超えた時点でニーを定義する場合がありますが、負荷テスト ベンチマークやハーフ レイテンシ ルールなどのキュー理論手法を使用する人もいます。理論上の加速器仕様。
また、同時リクエストの最大数には制限があることにも注意してください。上の図では、ライン トレースは 192 個の同時リクエストで終了します。この制限の原因は SageMaker 呼び出しタイムアウト制限であり、SageMaker エンドポイントは 60 秒後に呼び出し応答をタイムアウトします。この設定はアカウント固有であり、個々のエンドポイントに対して構成することはできません。 LLM の場合、大量の出力トークンの生成には数秒、場合によっては数分かかる場合があります。したがって、入力ペイロードまたは出力ペイロードが大きいと、呼び出しリクエストが失敗する可能性があります。さらに、同時リクエストの数が非常に多い場合、多くのリクエストでキュー時間が長くなり、この 60 秒のタイムアウト制限が大きくなります。この調査では、タイムアウト制限を使用して、モデルのデプロイメントで可能な最大スループットを定義します。重要なのは、SageMaker エンドポイントは呼び出し応答タイムアウトを監視せずに多数の同時リクエストを処理する可能性がありますが、レイテンシとスループットの曲線のニー点に関して最大同時リクエストを定義することが必要になる場合があります。これはおそらく、水平スケーリングを検討し始めるポイントです。水平スケーリングでは、単一のエンドポイントがモデル レプリカを持つ複数のインスタンスをプロビジョニングし、受信リクエストをレプリカ間で負荷分散して、より多くの同時リクエストをサポートします。
これをさらに一歩進めて、次の表には、入力トークンと出力トークンの数、インスタンス タイプ、同時リクエストの数など、Llama 2 7B モデルのさまざまな構成のベンチマーク結果が含まれています。上の図は、このテーブルの単一行のみをプロットしていることに注意してください。
| . | スループット (トークン/秒) | レイテンシ (ミリ秒/トークン) | ||||||||||||||||||
| 同時リクエスト | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| 総トークン数:512、出力トークン数:256 | ||||||||||||||||||||
| ml.g5.2xラージ | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xラージ | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xラージ | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| 総トークン数:4096、出力トークン数:256 | ||||||||||||||||||||
| ml.g5.2xラージ | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xラージ | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xラージ | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
このデータには追加のパターンがいくつか観察されます。コンテキスト サイズを増やすと、レイテンシが増加し、スループットが低下します。たとえば、同時実行性が 5.2 の ml.g1xlarge では、総トークン数が 30 の場合、スループットは 512 トークン/秒ですが、総トークン数が 20 の場合は 4,096 トークン/秒になります。これは、入力が大きくなると処理に時間がかかるためです。また、GPU の機能とシャーディングの増加が、最大スループットとサポートされる最大同時リクエストに影響を与えることもわかります。この表は、Llama 2 7B の最大スループット値がインスタンス タイプごとに著しく異なり、これらの最大スループット値は同時リクエストの異なる値で発生することを示しています。これらの特性により、ML 実践者は、あるインスタンスのコストを別のインスタンスよりも正当化することになります。たとえば、低レイテンシー要件を考慮すると、実践者は ml.g5.12xlarge インスタンス (4 つの A10G GPU) ではなく ml.g5.2xlarge インスタンス (1 つの A10G GPU) を選択する可能性があります。高スループット要件が与えられた場合、フル シャーディングでの ml.p4d.24xlarge インスタンス (8 つの A100 GPU) の使用は、同時実行性が高い場合にのみ正当化されます。ただし、多くの場合、代わりに 7B モデルの複数の推論コンポーネントを単一の ml.p4d.24xlarge インスタンスにロードする方が有益であることに注意してください。このようなマルチモデルのサポートについては、この投稿の後半で説明します。
上記の観察は、Llama 2 7B モデルに対して行われました。ただし、同様のパターンは他のモデルにも当てはまります。主なポイントは、レイテンシとスループットのパフォーマンス数値はペイロード、インスタンス タイプ、同時リクエストの数に依存するため、特定のアプリケーションに最適な構成を見つける必要があるということです。ユースケースに応じて上記の数値を生成するには、リンクされたコマンドを実行できます。 ノートここでは、モデル、インスタンス タイプ、ペイロードに対してこの負荷テスト分析を構成できます。
アクセラレータの仕様を理解する
LLM 推論に適したハードウェアの選択は、特定の使用例、ユーザー エクスペリエンスの目標、および選択した LLM に大きく依存します。このセクションでは、アクセラレータの仕様に基づいた高レベルの原理に関して、レイテンシーとスループットの曲線におけるニー点を理解することを試みます。これらの原則だけでは決定を下すのに十分ではありません。実際のベンチマークが必要です。用語 デバイス ここでは、すべての ML ハードウェア アクセラレータを包含するために使用されます。レイテンシとスループットの曲線の曲がり角は、次の 2 つの要因のいずれかによって決まると主張します。
- アクセラレータが KV 行列をキャッシュするためのメモリを使い果たしたため、後続のリクエストはキューに入れられます
- アクセラレータには KV キャッシュ用の予備メモリがまだありますが、十分な大きさのバッチ サイズが使用されているため、処理時間はメモリ帯域幅ではなく計算操作のレイテンシによって決まります。
これはアクセラレータのリソースが飽和していることを意味するため、通常は 2 番目の要素によって制限されることを好みます。基本的に、支払ったリソースを最大限に活用することになります。この主張をさらに詳しく見てみましょう。
KV キャッシュとデバイス メモリ
標準のトランスフォーマ アテンション メカニズムは、以前のすべてのトークンに対して新しいトークンごとにアテンションを計算します。最新の ML サーバーのほとんどは、各ステップでの再計算を避けるために、アテンション キーと値をデバイス メモリ (DRAM) にキャッシュします。これをこれといいます KVキャッシュ、バッチサイズとシーケンスの長さに応じて増加します。これは、並行して処理できるユーザー リクエストの数を定義し、利用可能な DRAM を考慮して、前述の 2 番目のシナリオのコンピューティング制限領域がまだ満たされていない場合に、レイテンシとスループットの曲線の曲がり角を決定します。次の式は、最大 KV キャッシュ サイズの大まかな近似値です。

この式では、B はバッチ サイズ、N はアクセラレータの数です。たとえば、A2G GPU (7 GB DRAM) で動作する FP16 の Llama 2 10B モデル (24 バイト/パラメーター) は約 14 GB を消費し、KV キャッシュ用に 10 GB が残ります。モデルの完全なコンテキスト長 (N = 4096) と残りのパラメーター (n_layers=32、n_kv_attention_heads=32、および d_attention_head=128) を差し込むと、この式は、DRAM の制約により、並列処理できるバッチ サイズが XNUMX ユーザーに制限されることを示しています。 。前の表の対応するベンチマークを観察すると、これは、このレイテンシとスループットの曲線で観察されたニーの適切な近似値となります。などの方法 グループ化されたクエリの注意 (GQA) は KV キャッシュ サイズを削減できます。GQA の場合、同じ係数で KV ヘッドの数が削減されます。
演算強度とデバイスのメモリ帯域幅
ML アクセラレータの計算能力の増大は、メモリ帯域幅を上回っています。つまり、ML アクセラレータは、データの各バイトにアクセスするのにかかる時間内に、より多くの計算を実行できることになります。
算術強度、またはメモリ アクセスに対する計算操作の比率により、操作が選択したハードウェアのメモリ帯域幅または計算能力によって制限されるかどうかが決まります。たとえば、10 TFLOPS FP5 と 70 GB/秒の帯域幅を備えた A16G GPU (g600 インスタンス タイプ ファミリ) は、約 116 ops/バイトを計算できます。 A100 GPU (p4d インスタンス タイプ ファミリ) は、約 208 ops/バイトを計算できます。トランスフォーマ モデルの演算強度がその値を下回る場合、メモリに依存します。上記を超えている場合は、コンピューティングに依存します。 Llama 2 7B のアテンション メカニズムでは、バッチ サイズ 62 で 1 ops/バイトが必要です (説明については、「 LLM 推論とパフォーマンスのガイド)、これはメモリに依存していることを意味します。アテンション メカニズムがメモリに依存している場合、高価な FLOPS が使用されないままになります。
アクセラレータを有効活用して演算強度を高める方法は 2 つあります。 操作に必要なメモリ アクセスを減らすことです (これが、 フラッシュ注意 に焦点を当てます)、またはバッチサイズを増やします。ただし、DRAM が小さすぎて対応する KV キャッシュを保持できない場合、バッチ サイズをコンピューティング制限に達するのに十分な量に増やすことができない可能性があります。標準 GPT デコーダ推論において、コンピューティング依存領域とメモリ依存領域を区別する重要なバッチ サイズ B* の大まかな近似は、次の式で記述されます。ここで、A_mb はアクセラレータ メモリ帯域幅、A_f はアクセラレータ FLOPS、N は数値です。加速器の。この重要なバッチ サイズは、メモリ アクセス時間が計算時間と等しくなる場所を見つけることで導き出すことができます。参照する このブログ記事 式 2 とその仮定をより詳細に理解するために。
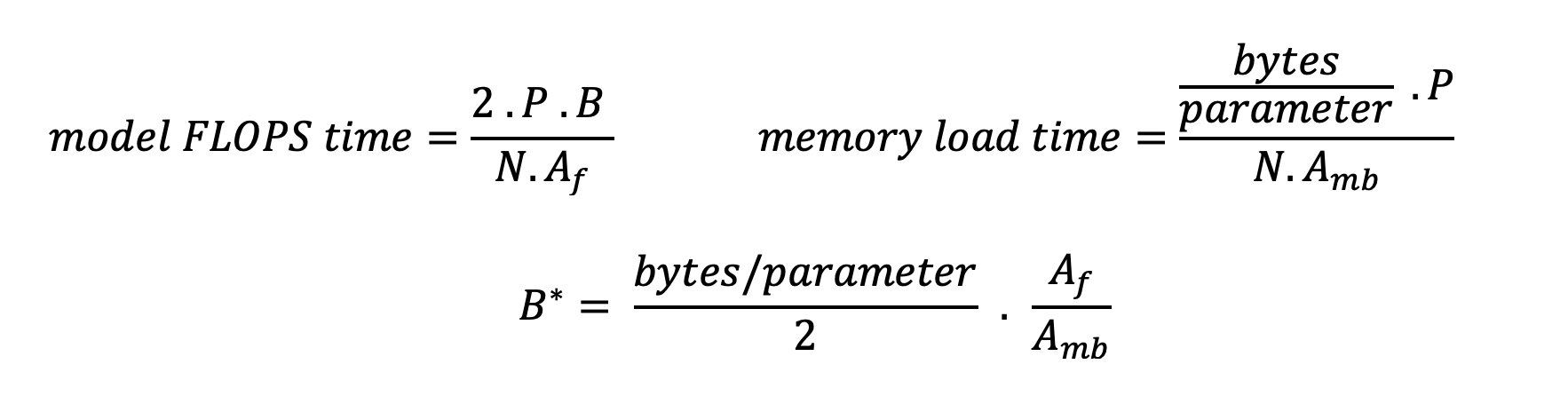
これは、A10G について以前に計算した演算数/バイト比と同じであるため、この GPU のクリティカル バッチ サイズは 116 です。この理論上のクリティカル バッチ サイズに近づく XNUMX つの方法は、モデルのシャーディングを増やし、より多くの N 個のアクセラレータにキャッシュを分割することです。これにより、KV キャッシュ容量とメモリ制限のあるバッチ サイズが効果的に増加します。
モデル シャーディングのもう 1 つの利点は、モデル パラメーターとデータ読み込み作業を N 個のアクセラレータに分割できることです。このタイプのシャーディングは、モデル並列処理の一種であり、シャーディングとも呼ばれます。 テンソル並列処理。単純に言えば、メモリ帯域幅と計算能力は合計で N 倍になります。いかなる種類のオーバーヘッド (通信、ソフトウェアなど) もないと仮定すると、メモリに制約されている場合、トークンごとのデコード レイテンシが N 減少します。これは、この領域でのトークン デコード レイテンシは、モデルのロードにかかる時間によって制限されるためです。重みとキャッシュ。ただし、実際には、シャーディングの度合いを高めると、すべてのモデル層で中間アクティベーションを共有するためのデバイス間の通信が増加します。この通信速度は、デバイスの相互接続帯域幅によって制限されます。その影響を正確に見積もることは困難です (詳細については、 モデルの並列処理)、ただし、これにより最終的にはメリットが得られなくなったり、パフォーマンスが低下したりする可能性があります。これは特に小規模なモデルに当てはまります。これは、データ転送が小さくなると転送速度が低下するためです。
仕様に基づいて ML アクセラレータを比較するには、以下をお勧めします。まず、2 番目の式に従って各アクセラレータ タイプのおおよそのクリティカル バッチ サイズを計算し、最初の式に従ってクリティカル バッチ サイズの KV キャッシュ サイズを計算します。その後、アクセラレータで利用可能な DRAM を使用して、KV キャッシュとモデル パラメータに適合させるために必要なアクセラレータの最小数を計算できます。複数のアクセラレータを選択する場合は、メモリ帯域幅の GB/秒あたりのコストが最も低い順にアクセラレータを優先します。最後に、これらの構成をベンチマークし、必要なレイテンシの上限に対して最適なコスト/トークンがいくらであるかを検証します。
エンドポイント展開構成を選択します
SageMaker JumpStart によって配布される多くの LLM は、 テキスト生成推論 (TGI) SageMaker コンテナ モデルサービス用。次の表では、さまざまなモデル サービス パラメーターを調整して、レイテンシとスループットの曲線に影響を与えるモデル サービスに影響を与える方法、またはエンドポイントを過負荷にするリクエストからエンドポイントを保護する方法について説明します。これらは、ユースケースに合わせてエンドポイント展開を構成するために使用できる主なパラメータです。特に指定がない限り、デフォルトを使用します テキスト生成ペイロードパラメータ & TGI 環境変数.
| 環境変数 | 説明 | SageMaker JumpStart のデフォルト値 |
| モデル提供構成 | . | . |
MAX_BATCH_PREFILL_TOKENS |
事前入力操作のトークンの数を制限します。この操作により、新しい入力プロンプト シーケンスの KV キャッシュが生成されます。これはメモリを大量に消費し、計算量が多いため、この値が 1 回の事前入力操作で許可されるトークンの数を制限します。プレフィルの実行中は、他のクエリのデコード ステップが一時停止します。 | 4096 (TGI デフォルト) またはモデル固有のサポートされる最大コンテキスト長 (SageMaker JumpStart が提供) のいずれか大きい方。 |
MAX_BATCH_TOTAL_TOKENS |
デコード中、またはモデルを通過する単一の前方パス中にバッチ内に含めるトークンの最大数を制御します。理想的には、これは、使用可能なすべてのハードウェアの使用率を最大化するように設定されます。 | 指定されていません (TGI のデフォルト)。 TGI は、モデルのウォームアップ中に残りの CUDA メモリに対してこの値を設定します。 |
SM_NUM_GPUS |
使用するシャードの数。つまり、テンソル並列処理を使用してモデルを実行するために使用される GPU の数です。 | インスタンスに依存します (SageMaker JumpStart が提供します)。 SageMaker JumpStart は、特定のモデルでサポートされているインスタンスごとに、テンソル並列処理の最適な設定を提供します。 |
| エンドポイントを保護するための構成 (ユースケースに合わせて設定します) | . | . |
MAX_TOTAL_TOKENS |
これにより、入力シーケンス内のトークンの数と出力シーケンス内のトークンの数を制限することによって、単一のクライアント リクエストのメモリ バジェットが制限されます ( max_new_tokens ペイロードパラメータ)。 |
モデル固有のサポートされるコンテキストの最大長。たとえば、Llama 4096 の場合は 2 です。 |
MAX_INPUT_LENGTH |
単一のクライアント要求の入力シーケンスで許可されるトークンの最大数を識別します。この値を増やすときに考慮すべき点は次のとおりです。入力シーケンスが長くなると、より多くのメモリが必要になり、連続バッチ処理に影響します。また、多くのモデルにはサポートされているコンテキストの長さがあり、それを超えてはなりません。 | モデル固有のサポートされるコンテキストの最大長。たとえば、Llama 4095 の場合は 2 です。 |
MAX_CONCURRENT_REQUESTS |
デプロイされたエンドポイントで許可される同時リクエストの最大数。この制限を超える新しいリクエストは、現在の処理リクエストの遅延の低下を防ぐために、モデルのオーバーロード エラーを直ちに発生させます。 | 128 (TGI のデフォルト)。この設定により、さまざまなユースケースで高いスループットを得ることができますが、SageMaker 呼び出しタイムアウト エラーを軽減するために、必要に応じて固定する必要があります。 |
TGI サーバーは連続バッチ処理を使用します。これは、同時リクエストを動的にバッチ処理して、単一のモデル推論フォワード パスを共有します。フォワード パスには、プレフィルとデコードの 2 種類があります。新しいリクエストごとに、単一の事前入力フォワード パスを実行して、入力シーケンス トークンの KV キャッシュを設定する必要があります。 KV キャッシュが設定された後、デコード フォワード パスは、バッチ化されたすべてのリクエストに対して単一の次トークン予測を実行します。これが反復的に繰り返されて、出力シーケンスが生成されます。新しいリクエストがサーバーに送信されると、新しいリクエストに対して事前入力ステップを実行できるように、次のデコード ステップは待機する必要があります。これは、それらの新しいリクエストが後続の連続的にバッチ処理されるデコード ステップに含まれる前に行われる必要があります。ハードウェアの制約により、デコードに使用される連続バッチ処理にはすべてのリクエストが含まれない場合があります。この時点で、リクエストは処理キューに入り、スループットの向上はわずかですが、推論のレイテンシが大幅に増加し始めます。
LLM レイテンシのベンチマーク分析を、プリフィル レイテンシ、デコード レイテンシ、キュー レイテンシに分離することができます。これらの各コンポーネントで消費される時間は本質的に根本的に異なります。プレフィルは 1 回限りの計算であり、デコードは出力シーケンス内のトークンごとに 1 回発生し、キューイングにはサーバーのバッチ処理が含まれます。複数の同時リクエストが処理されている場合、これらの各コンポーネントからのレイテンシを解きほぐすことは困難になります。これは、特定のクライアント リクエストによって発生するレイテンシには、新しい同時リクエストを事前に入力する必要性によって引き起こされるキュー レイテンシと、インクルードによって引き起こされるキュー レイテンシが含まれるためです。バッチデコードプロセスでのリクエストの。このため、この投稿ではエンドツーエンドの処理遅延に焦点を当てます。待ち時間とスループットの曲線の曲がりは、キューの待ち時間が大幅に増加し始める飽和点で発生します。この現象はどのモデル推論サーバーでも発生し、アクセラレータの仕様によって引き起こされます。
導入時の一般的な要件には、最小必要スループット、最大許容レイテンシ、時間あたりの最大コスト、および 1 万個のトークンを生成するための最大コストを満たすことが含まれます。これらの要件は、エンドユーザーのリクエストを表すペイロードに基づいて条件付けする必要があります。これらの要件を満たす設計では、特定のモデル アーキテクチャ、モデルのサイズ、インスタンス タイプ、インスタンス数 (水平スケーリング) などの多くの要素を考慮する必要があります。次のセクションでは、遅延を最小限に抑え、スループットを最大化し、コストを最小限に抑えるためのエンドポイントの展開に焦点を当てます。この分析では、合計 512 個のトークンと 256 個の出力トークンを考慮します。
遅延を最小限に抑える
レイテンシーは、多くのリアルタイム使用例において重要な要件です。次の表では、各モデルと各インスタンス タイプの最小レイテンシを示します。設定することで遅延を最小限に抑えることができます MAX_CONCURRENT_REQUESTS = 1.
| 最小レイテンシー (ミリ秒/トークン) | |||||
| モデルID | ml.g5.2xラージ | ml.g5.12xラージ | ml.g5.48xラージ | ml.p4d.24xlarge | ml.p4de.24xlarge |
| ラマ2 7B | 33 | 17 | 18 | 20 | - |
| ラマ 2 7B チャット | 33 | 17 | 18 | 20 | - |
| ラマ2 13B | - | 22 | 23 | 23 | - |
| ラマ 2 13B チャット | - | 23 | 23 | 23 | - |
| ラマ2 70B | - | - | 57 | 43 | - |
| ラマ 2 70B チャット | - | - | 57 | 45 | - |
| ミストラル 7B | 35 | - | - | - | - |
| ミストラル 7B 指示 | 35 | - | - | - | - |
| ミストラル 8x7B | - | - | 33 | 27 | - |
| ファルコン7B | 33 | - | - | - | - |
| ファルコン 7B の指示 | 33 | - | - | - | - |
| ファルコン40B | - | 53 | 33 | 27 | - |
| ファルコン 40B の指示 | - | 53 | 33 | 28 | - |
| ファルコン180B | - | - | - | - | 42 |
| ファルコン 180B チャット | - | - | - | - | 42 |
モデルのレイテンシを最小限に抑えるには、次のコードを使用して、目的のモデル ID とインスタンス タイプを置き換えます。
レイテンシーの数値は、入力トークンと出力トークンの数に応じて変化することに注意してください。ただし、環境変数を除き、デプロイメントプロセスは同じままです。 MAX_INPUT_TOKENS & MAX_TOTAL_TOKENS。ここで、これらの環境変数は、入力シーケンスが大きくなるとレイテンシ要件に違反する可能性があるため、エンドポイントのレイテンシ要件を保証するために設定されています。 SageMaker JumpStart は、インスタンス タイプを選択するときに他の最適な環境変数をすでに提供していることに注意してください。たとえば、ml.g5.12xlarge を使用すると、 SM_NUM_GPUS モデル環境では 4 に変わります。
スループットを最大化する
このセクションでは、1 秒あたりに生成されるトークンの数を最大化します。これは通常、モデルとインスタンス タイプの有効な同時リクエストの最大数で達成されます。次の表では、リクエストの SageMaker 呼び出しタイムアウトが発生する前に達成される最大同時リクエスト値で達成されるスループットを報告します。
| 最大スループット (トークン/秒)、同時リクエスト数 | |||||
| モデルID | ml.g5.2xラージ | ml.g5.12xラージ | ml.g5.48xラージ | ml.p4d.24xlarge | ml.p4de.24xlarge |
| ラマ2 7B | 486(64) | 1214(128) | 804(128) | 2945(512) | - |
| ラマ 2 7B チャット | 493(64) | 1207(128) | 932(128) | 3012(512) | - |
| ラマ2 13B | - | 787(128) | 496(64) | 3245(512) | - |
| ラマ 2 13B チャット | - | 782(128) | 505(64) | 3310(512) | - |
| ラマ2 70B | - | - | 124(16) | 1585(256) | - |
| ラマ 2 70B チャット | - | - | 114(16) | 1546(256) | - |
| ミストラル 7B | 947(64) | - | - | - | - |
| ミストラル 7B 指示 | 986(128) | - | - | - | - |
| ミストラル 8x7B | - | - | 701(128) | 3196(512) | - |
| ファルコン7B | 1340(128) | - | - | - | - |
| ファルコン 7B の指示 | 1313(128) | - | - | - | - |
| ファルコン40B | - | 244(32) | 382(64) | 2699(512) | - |
| ファルコン 40B の指示 | - | 245(32) | 415(64) | 2675(512) | - |
| ファルコン180B | - | - | - | - | 1100(128) |
| ファルコン 180B チャット | - | - | - | - | 1081(128) |
モデルのスループットを最大化するには、次のコードを使用できます。
同時リクエストの最大数は、モデル タイプ、インスタンス タイプ、入力トークンの最大数、および出力トークンの最大数によって異なることに注意してください。したがって、設定する前にこれらのパラメータを設定する必要があります。 MAX_CONCURRENT_REQUESTS.
また、レイテンシーの最小化に関心のあるユーザーは、スループットの最大化に関心のあるユーザーと対立することが多いことにも注意してください。前者はリアルタイム応答に関心があるのに対し、後者はエンドポイント キューが常に飽和状態になるようにバッチ処理に関心があり、それによって処理のダウンタイムが最小限に抑えられます。レイテンシ要件に応じてスループットを最大化したいユーザーは、レイテンシとスループットの曲線の中間点での動作に関心を持つことがよくあります。
コストを最小限に抑える
コストを最小限に抑えるための最初のオプションには、時間あたりのコストを最小限に抑えることが含まれます。これにより、選択したモデルを 1 時間当たりの最低コストで SageMaker インスタンスにデプロイできます。 SageMaker インスタンスのリアルタイムの価格については、以下を参照してください。 Amazon SageMakerの料金。一般に、SageMaker JumpStart LLM のデフォルトのインスタンス タイプは、最もコストの低い展開オプションです。
コストを最小限に抑える 1 番目のオプションには、1 万個のトークンを生成するコストを最小限に抑えることが含まれます。これは、スループットを最大化するために前に説明したテーブルの単純な変換です。最初に、1 万個のトークンを生成するのにかかる時間を数時間で計算できます (6e3600 / スループット / 1)。次に、この時間を乗算して、指定された SageMaker インスタンスの XNUMX 時間あたりの価格で XNUMX 万トークンを生成できます。
時間あたりのコストが最も低いインスタンスは、1 万個のトークンを生成するためのコストが最も低いインスタンスと同じではないことに注意してください。たとえば、呼び出しリクエストが散発的である場合は、XNUMX 時間あたりのコストが最も低いインスタンスが最適である可能性がありますが、スロットリング シナリオでは、XNUMX 万個のトークンを生成するための最も低いコストがより適切である可能性があります。
Tensor 並列とマルチモデルのトレードオフ
これまでのすべての分析では、デプロイメント インスタンス タイプの GPU の数と等しいテンソル並列度を持つ単一モデル レプリカをデプロイすることを検討しました。これは、SageMaker JumpStart のデフォルトの動作です。ただし、前述したように、モデルのシャーディングによってモデルのレイテンシとスループットを改善できるのは、一定の制限までのみであり、それを超えると、デバイス間通信要件が計算時間の大半を占めます。これは、より高いテンソル並列度を持つ単一のモデルよりも、より低いテンソル並列度を持つ複数のモデルを 1 つのインスタンスにデプロイする方が有益であることが多いことを意味します。
ここでは、Llama 2 7B および 13B エンドポイントを、テンソル並列 (TP) 次数 4、24、1、および 2 の ml.p4d.8xlarge インスタンスにデプロイします。モデルの動作を明確にするために、これらの各エンドポイントは XNUMX つのモデルのみをロードします。
| . | スループット (トークン/秒) | レイテンシ (ミリ秒/トークン) | ||||||||||||||||||
| 同時リクエスト | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| TP学位 | ラマ2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | ラマ2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
これまでの分析では、ml.p4d.24xlarge インスタンスでスループットが大幅に向上していることがすでに示されており、これは多くの場合、同時リクエストの負荷が高い条件下で g1 インスタンス ファミリよりも 5 万個のトークンを生成するコストの観点からパフォーマンスが向上することにつながります。この分析は、単一インスタンス内でのモデルのシャーディングとモデルのレプリケーションの間のトレードオフを考慮する必要があることを明確に示しています。つまり、完全にシャード化されたモデルは、通常、4B および 24B モデル ファミリの ml.p7d.13xlarge コンピューティング リソースの最適な用途ではありません。実際、7B モデル ファミリの場合、テンソル並列次数が 4 ではなく 8 である単一モデル レプリカで最高のスループットが得られます。
ここから、7B モデルの最高のスループット構成には、1 つのモデル レプリカを使用したテンソル並列度 13 が含まれ、2B モデルの最高のスループット構成は、XNUMX つのモデル レプリカを使用したテンソル並列度 XNUMX である可能性が高いと推測できます。これを実現する方法の詳細については、以下を参照してください。 Amazon SageMaker の最新機能を使用して、モデルのデプロイメントコストを平均 50% 削減します、推論コンポーネントベースのエンドポイントの使用を示します。負荷分散技術、サーバー ルーティング、および CPU リソースの共有により、レプリカの数と 1 つのレプリカのスループットの積に正確に等しいスループットの向上が完全に達成されない可能性があります。
水平スケーリング
前述したように、各エンドポイント デプロイメントには、入力トークンと出力トークンの数およびインスタンス タイプに応じて、同時リクエストの数に制限があります。これがスループットまたは同時リクエストの要件を満たさない場合は、デプロイされたエンドポイントの背後で複数のインスタンスを利用するようにスケールアップできます。 SageMaker は、インスタンス間のクエリの負荷分散を自動的に実行します。たとえば、次のコードは 3 つのインスタンスでサポートされるエンドポイントをデプロイします。
次の表は、Llama 2 7B モデルのインスタンス数の係数としてのスループットの向上を示しています。
| . | . | スループット (トークン/秒) | レイテンシ (ミリ秒/トークン) | ||||||||||||||
| . | 同時リクエスト | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| インスタンス数 | インスタンスタイプ | 総トークン数:512、出力トークン数:256 | |||||||||||||||
| 1 | ml.g5.2xラージ | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xラージ | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xラージ | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
特に、インスタンス数が増えると、マルチインスタンス エンドポイント内でより多くの同時リクエストを処理できるため、レイテンシーとスループットの曲線の屈曲部分が右にシフトします。この表の場合、同時リクエストの値はエンドポイント全体のものであり、個々のインスタンスが受信する同時リクエストの数ではありません。
また、ワークロードを監視し、容量を動的に調整する機能である自動スケーリングを使用して、可能な限り低いコストで安定した予測可能なパフォーマンスを維持することもできます。これはこの投稿の範囲を超えています。自動スケーリングの詳細については、以下を参照してください。 Amazon SageMaker で自動スケーリング推論エンドポイントを設定する.
同時リクエストでエンドポイントを呼び出す
高スループット条件下でデプロイされたモデルから応答を生成するために使用したい大量のクエリのバッチがあるとします。たとえば、次のコード ブロックでは、各ペイロードが 1,000 個のトークンの生成を要求する、100 個のペイロードのリストをコンパイルします。合計で 100,000 トークンの生成をリクエストしています。
大量のリクエストを SageMaker ランタイム API に送信すると、スロットリング エラーが発生する可能性があります。これを軽減するには、再試行回数を増やすカスタム SageMaker ランタイム クライアントを作成できます。結果の SageMaker セッション オブジェクトを次のいずれかに提供できます。 JumpStartModel コンストラクターまたは sagemaker.predictor.retrieve_default すでにデプロイされているエンドポイントに新しいプレディクターを接続する場合。次のコードでは、デフォルトの SageMaker JumpStart 構成で Llama 2 モデルをデプロイするときにこのセッション オブジェクトを使用します。
このデプロイされたエンドポイントには、 MAX_CONCURRENT_REQUESTS = 128 デフォルトでは。次のブロックでは、同時フューチャー ライブラリを使用して、128 ワーカー スレッドを持つすべてのペイロードのエンドポイントの呼び出しを繰り返します。エンドポイントは最大 128 個の同時リクエストを処理し、リクエストが応答を返すたびに、エグゼキュータは直ちに新しいリクエストをエンドポイントに送信します。
これにより、単一の ml.g100,000xlarge インスタンス上で 1255 トークン/秒のスループットで合計 5.2 のトークンが生成されます。この処理には約 80 秒かかります。
このスループット値は、この記事の前の表にある ml.g2xlarge での Llama 7 5.2B の最大スループット (486 の同時リクエストで 64 トークン/秒) とは著しく異なることに注意してください。これは、入力ペイロードが 8 ではなく 256 トークンを使用し、出力トークン数が 100 ではなく 256 であり、トークン数が小さいため 128 個の同時リクエストが可能であるためです。これは、すべてのレイテンシーとスループットの数値がペイロードに依存するということを最後に思い出させるものです。ペイロード トークン数を変更すると、モデルの提供中のバッチ処理に影響があり、その結果、アプリケーションの緊急のプリフィル、デコード、キュー時間に影響します。
まとめ
この投稿では、Llama 2、Mistral、Falcon を含む SageMaker JumpStart LLM のベンチマークを紹介しました。また、エンドポイント展開構成のレイテンシー、スループット、コストを最適化するためのガイドも紹介しました。を実行して開始できます。 関連するノートブック ユースケースのベンチマークを行うために。
著者について
 カイル・ウルリッヒ博士 Amazon SageMaker JumpStart チームの応用科学者です。 彼の研究対象には、スケーラブルな機械学習アルゴリズム、コンピューター ビジョン、時系列、ベイジアン ノンパラメトリック、ガウス プロセスなどがあります。 彼はデューク大学で博士号を取得しており、NeurIPS、Cell、および Neuron で論文を発表しています。
カイル・ウルリッヒ博士 Amazon SageMaker JumpStart チームの応用科学者です。 彼の研究対象には、スケーラブルな機械学習アルゴリズム、コンピューター ビジョン、時系列、ベイジアン ノンパラメトリック、ガウス プロセスなどがあります。 彼はデューク大学で博士号を取得しており、NeurIPS、Cell、および Neuron で論文を発表しています。
 Dr。ヴィヴェク・マダン Amazon SageMaker JumpStart チームの応用科学者です。 イリノイ大学アーバナ シャンペーン校で博士号を取得し、ジョージア工科大学で博士研究員を務めました。 彼は機械学習とアルゴリズム設計の活発な研究者であり、EMNLP、ICLR、COLT、FOCS、および SODA カンファレンスで論文を発表しています。
Dr。ヴィヴェク・マダン Amazon SageMaker JumpStart チームの応用科学者です。 イリノイ大学アーバナ シャンペーン校で博士号を取得し、ジョージア工科大学で博士研究員を務めました。 彼は機械学習とアルゴリズム設計の活発な研究者であり、EMNLP、ICLR、COLT、FOCS、および SODA カンファレンスで論文を発表しています。
 アシッシュ・ケタン博士 Amazon SageMaker JumpStart の上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナ・シャンペーン校で博士号を取得しました。 彼は機械学習と統計的推論の積極的な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
アシッシュ・ケタン博士 Amazon SageMaker JumpStart の上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナ・シャンペーン校で博士号を取得しました。 彼は機械学習と統計的推論の積極的な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
 ジョアンモウラ AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。 João は、小規模なスタートアップ企業から大企業まで、AWS の顧客が大規模なモデルを効率的にトレーニングしてデプロイし、より広範に AWS 上で ML プラットフォームを構築できるよう支援しています。
ジョアンモウラ AWS のシニア AI/ML スペシャリスト ソリューション アーキテクトです。 João は、小規模なスタートアップ企業から大企業まで、AWS の顧客が大規模なモデルを効率的にトレーニングしてデプロイし、より広範に AWS 上で ML プラットフォームを構築できるよう支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

