アパッチ氷山 大規模なデータセット用のオープン テーブル形式です。 Amazon シンプル ストレージ サービス (Amazon S3) を提供し、大規模なテーブルに対する高速なクエリ パフォーマンス、アトミック コミット、同時書き込み、SQL 互換テーブルの進化を実現します。 Apache Iceberg を使用してトランザクション データ レイクを構築し、機能的なユース ケースを解決する場合は、運用環境を最適化するために S3 データ レイクの運用上のユース ケースに焦点を当てる必要があります。 組織が重点を置いている S3 データレイクの非機能的な重要なユースケースには、ストレージコストの最適化、災害復旧とビジネス継続性の機能、データレイクへのクロスアカウントおよびマルチリージョンのアクセス、増加する Amazon S3 の処理などがあります。リクエスト料金。
この投稿では、Apache Iceberg テーブル上に構築されたテーブルの運用効率を向上させる方法を説明します。 Amazon S3 データレイク & アマゾンEMR ビッグデータプラットフォーム。
データレイクストレージを最適化する
Amazon S3 上に最新のデータレイクを構築する主な利点の 3 つは、パフォーマンスを犠牲にすることなくコストを削減できることです。 Amazon S3 ライフサイクル設定と Apache Iceberg テーブルでの Amazon S3 オブジェクトのタグ付けを使用して、データ レイク ストレージ全体のコストを最適化できます。 Amazon S3 ライフサイクル設定は、Amazon SXNUMX がオブジェクトのグループに適用するアクションを定義する一連のルールです。 アクションには次の XNUMX 種類があります。
- 移行アクション – これらのアクションは、オブジェクトが別のストレージ クラスに移行するタイミングを定義します。 たとえば、Amazon S3 Standard から Amazon S3 Glacier へ。
- 有効期限切れアクション – これらのアクションは、オブジェクトの有効期限がいつ切れるかを定義します。 Amazon S3 は、ユーザーに代わって期限切れのオブジェクトを削除します。
Amazon S3 は、オブジェクトのタグ付けを使用して、各タグがキーと値のペアであるストレージを分類します。 Apache Iceberg の観点から見ると、カスタム Amazon S3 オブジェクトをサポートします。 タグ テーブルへの書き込みおよび削除中に、S3 オブジェクトに追加できます。 Iceberg では、バケット レベルでタグベースのオブジェクト ライフサイクル ポリシーを設定して、オブジェクトを別の Amazon S3 層に移行することもできます。 とともに s3.delete.tags Iceberg の config プロパティを使用すると、オブジェクトは削除前に設定されたキーと値のペアでタグ付けされます。 カタログプロパティの場合 s3.delete-enabled に設定されています false、オブジェクトは Amazon S3 から完全に削除されません。 これは Amazon S3 のタグ付け削除と組み合わせて使用されることが想定されているため、オブジェクトはタグ付けされ、削除されます。 Amazon S3 ライフサイクル ポリシー。 このプロパティは次のように設定されています true デフォルトでは
この投稿のサンプル ノートブックは、ストレージ コストを最適化するための、Apache Iceberg テーブルの S3 オブジェクトのタグ付けとライフサイクル ルールの実装例を示しています。
事業継続性の実現
Amazon S3 を使用すると、Amazon が独自の Web サイトのグローバル ネットワークを運営するために使用しているものと同じ、拡張性が高く、信頼性が高く、高速で安価なデータ ストレージ インフラストラクチャにすべての開発者がアクセスできます。 Amazon S3 は 99.999999999% (11 9) の耐久性を実現するように設計されており、S3 Standard は 99.99% の可用性を実現するように設計されており、Standard – IA は 99.9% の可用性を実現するように設計されています。 それでも、予期せぬ停止状況においてデータレイクのワークロードの可用性を高めるために、S3 データをバックアップとして別の AWS リージョンにレプリケートできます。 S3 データが複数のリージョンに存在する場合、バックアップ リージョンからデータにアクセスするためのソリューションとして S3 マルチリージョン アクセス ポイントを使用できます。 と Amazon S3 マルチリージョン アクセス ポイントのフェイルオーバー制御を使用すると、すべての S3 データ リクエスト トラフィックを単一のグローバル エンドポイント経由でルーティングし、リージョン間の S3 データ リクエスト トラフィックのシフトをいつでも直接制御できます。 計画的または計画外のリージョン トラフィック中断中に、フェイルオーバー制御を使用すると、異なるリージョンおよびアカウントのバケット間のフェイルオーバーを数分以内に制御できます。 Apache Iceberg のサポート アクセスポイント バケットからアクセス ポイントへのマッピングを指定して S3 操作を実行します。 この投稿の後半には、Apache Iceberg を使用した S3 アクセス ポイントの実装例が含まれています。
Amazon S3 のパフォーマンスとスループットを向上させる
Amazon S3 は、バケット内のプレフィックスごとに 3,500 秒あたり 5,500 の PUT/COPY/POST/DELETE リクエストまたは 3 の GET/HEAD リクエストのリクエスト レートをサポートします。 このリクエスト レートのリソースは、プレフィックスの作成時に自動的に割り当てられません。 代わりに、プレフィックスのリクエストレートが徐々に増加すると、Amazon S3 は増加したリクエストレートを処理するために自動的にスケーリングします。 プレフィックス内のオブジェクトのリクエストレートを急激に増加させる必要がある特定のワークロードの場合、Amazon S503 が XNUMX Slow Down エラー (別名「XNUMX Slow Down」エラー) を返す場合があります。 S3 スロットリング。 これは、増加したリクエスト レートを処理するためにバックグラウンドでスケールしながら行われます。 また、サポートされているリクエスト レートを超えた場合は、オブジェクトとリクエストを複数に分散することがベスト プラクティスです。 プレフィックス。 このソリューションを実装してオブジェクトとリクエストを複数のプレフィックスに分散するには、データ入力またはデータ出力アプリケーションの変更が必要になります。 S3 データレイクに Apache Iceberg ファイル形式を使用すると、 ObjectStoreLocationProvider この機能は、指定した S3 オブジェクト パスに S0 ハッシュ [7*3FFFFF] プレフィックスを追加します。
Iceberg はデフォルトで Hive ストレージ レイアウトを使用しますが、Hive ストレージ レイアウトを使用するように切り替えることができます。 ObjectStoreLocationProvider。 このオプションは、ハッシュ プレフィックスを追加する場所を柔軟に選択できるようにするために、デフォルトでは有効になっていません。 と ObjectStoreLocationProvider、保存されたファイルごとに決定論的ハッシュが生成され、パラメーターを使用して指定された S3 フォルダーの直後にサブフォルダーが追加されます。 write.data.path (write.object-storage-path Iceberg バージョン 0.12 以下の場合)。 これにより、Amazon S3 に書き込まれるファイルが S3 バケット内の複数のプレフィックスに均等に分散されるようになり、スロットリング エラーが最小限に抑えられます。 次の例では、 write.data.path としての値 s3://my-table-data-bucket、Iceberg が生成した S3 ハッシュ プレフィックスは、この場所の後に追加されます。
S3 ファイルは、次のように MURMUR3 S3 ハッシュ プレフィックスの下に配置されます。
氷山の使用 ObjectStoreLocationProvider S3 503 エラーを回避する確実なメカニズムではありません。 さらなる回復力を提供するには、適切な EMRFS 再試行を設定する必要があります。 デフォルトの指数バックオフ再試行戦略の最大再試行制限を増やすか、加法増加/乗法減少 (AIMD) 再試行戦略を有効にして構成することによって、再試行戦略を調整できます。 AIMD は、Amazon EMR リリース 6.4.0 以降でサポートされています。 詳細については、以下を参照してください。 EMRFS を使用して Amazon S3 リクエストを再試行します.
次のセクションでは、これらの使用例の例を示します。
ストレージコストの最適化
この例では、Iceberg の S3タグ機能 書き込みタグを次のように付けます write-tag-name=created そしてタグを次のように削除します delete-tag-name=deleted。 この例は、アプリケーション Hadoop 6.10.0、Jupyter Enterprise Gateway 3.3.3、および Spark 2.6.0 がインストールされている EMR バージョン emr-3.3.1 クラスターで実証されています。 この例は、EMR クラスターに接続された Jupyter Notebook 環境で実行されます。 Iceberg で EMR クラスターを作成し、Amazon EMR Studio を使用する方法の詳細については、を参照してください。 Spark で Iceberg クラスターを使用する と Amazon EMR スタジオ管理ガイドそれぞれ。
次の例は、次のサンプル ノートブックでも利用できます。 aws-samples GitHub リポジトリ 素早い実験用に。
Spark セッションで Iceberg を構成する
を使用して Spark セッションを構成します。 %%configure 魔法のコマンド。 どちらかを使用できます AWSGlueデータカタログ (推奨) または Iceberg テーブルの Hive カタログ。 この例では Hive カタログを使用していますが、次の構成を使用して Data Catalog に変更できます。
このステップを実行する前に、命名規則に従って AWS アカウントに S3 バケットと Iceberg フォルダーを作成します。 <your-iceberg-storage-blog>/iceberg/.
アップデイト your-iceberg-storage-blog 次の構成では、この例をテストするために作成したバケットを使用します。 設定パラメータに注意してください s3.write.tags.write-tag-name & s3.delete.tags.delete-tag-nameこれにより、新しい S3 オブジェクトと削除されたオブジェクトが対応するタグ値でタグ付けされます。 後のステップでこれらのタグを使用して、S3 ライフサイクル ポリシーを実装し、オブジェクトを低コストのストレージ層に移行するか、ユースケースに基づいてオブジェクトを期限切れにします。
Spark-SQL を使用して Apache Iceberg テーブルを作成する
ここで、Iceberg テーブルを作成します。 Amazon 商品レビュー データセット:
次のステップでは、Spark アクションを使用してテーブルにデータセットを読み込みます。
Icebergテーブルにデータをロードします
データを挿入するときに、データを次のように分割します。 review_date テーブル定義に従って。 PySpark ノートブックで次の Spark コマンドを実行します。
単一のレコードを同じ Iceberg テーブルに挿入して、現在のレコードでパーティションを作成します。 review_date:
Iceberg スナップショットをクエリすることで、この追加操作の後に新しいスナップショットが作成されたことを確認できます。
テーブルに対して実行された操作を示す次のような出力が表示されます。
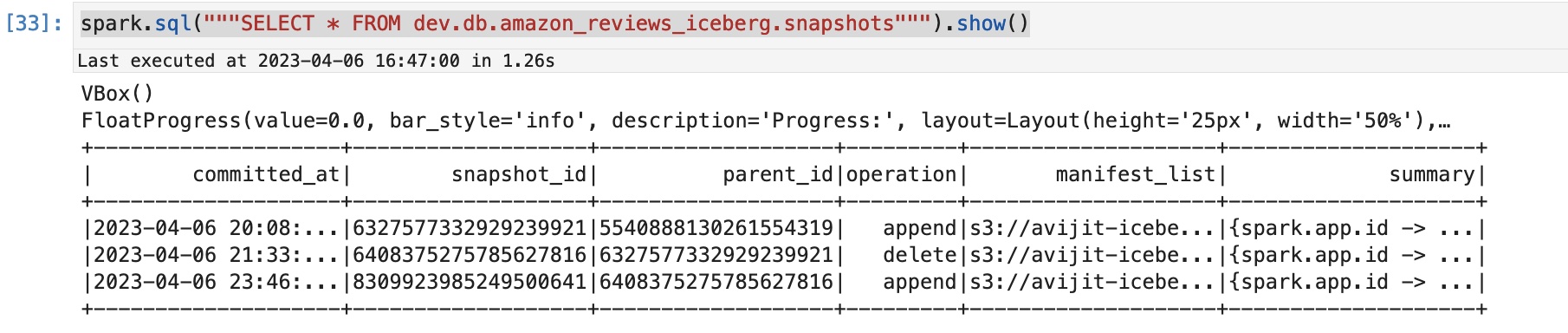
S3 タグの数を確認する
あなたが使用することができます AWSコマンドラインインターフェイス (AWS CLI)または AWSマネジメントコンソール 新しい書き込みに対して入力されたタグを確認します。 単一行挿入で作成されたオブジェクトに対応するタグを確認してみましょう。
Amazon S3 コンソールで、S3 フォルダーを確認します。 s3://your-iceberg-storage-blog/iceberg/db/amazon_reviews_iceberg/data/ そしてパーティションをポイントします review_date_year=2023/。 次に、このフォルダーの下にある Parquet ファイルをチェックして、Parquet 形式のデータ ファイルに関連付けられているタグを確認します。
AWS CLI から次のコマンドを実行して、タグが Spark 設定に基づいて作成されていることを確認します。 spark.sql.catalog.dev.s3.write.tags.write-tag-name":"created":
このステップでは、Iceberg テーブルからレコードを削除し、削除されたレコードに対応するスナップショットを期限切れにします。 現在のレコードで挿入した新しい単一レコードを削除します。 review_date:
これで、操作にフラグが付けられた新しいスナップショットが作成されたことを確認できます。 delete:
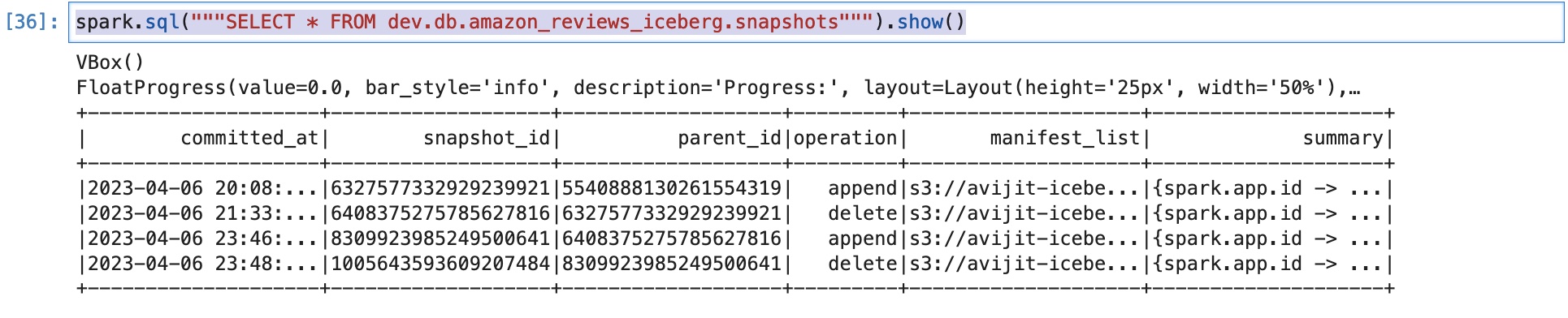
これは、将来タイムトラベルして削除された行を確認したい場合に便利です。 その場合、テーブルに対してクエリを実行する必要があります。 snapshot-id 削除された行に対応します。 ただし、この投稿ではタイムトラベルについては説明しません。
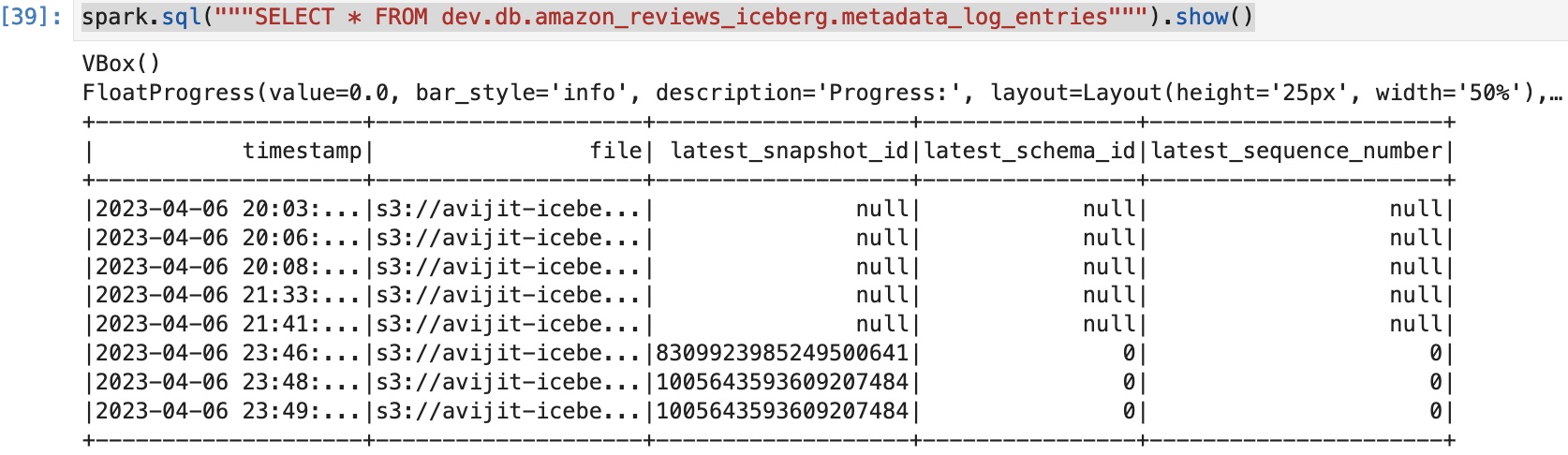
テーブルから古いスナップショットを期限切れにし、最後の XNUMX つだけを保持します。 スナップショットを保持するための特定の要件に基づいてクエリを変更できます。
スナップショットに対して同じクエリを実行すると、利用可能なスナップショットが XNUMX つだけであることがわかります。

AWS CLI から次のコマンドを実行すると、タグが Spark 設定に基づいて作成されたことを確認できます。 spark.sql.catalog.dev.s3. delete.tags.delete-tag-name":"deleted":
期限が切れたスナップショットには、最新のスナップショット ID が次のように表示されます。 null.
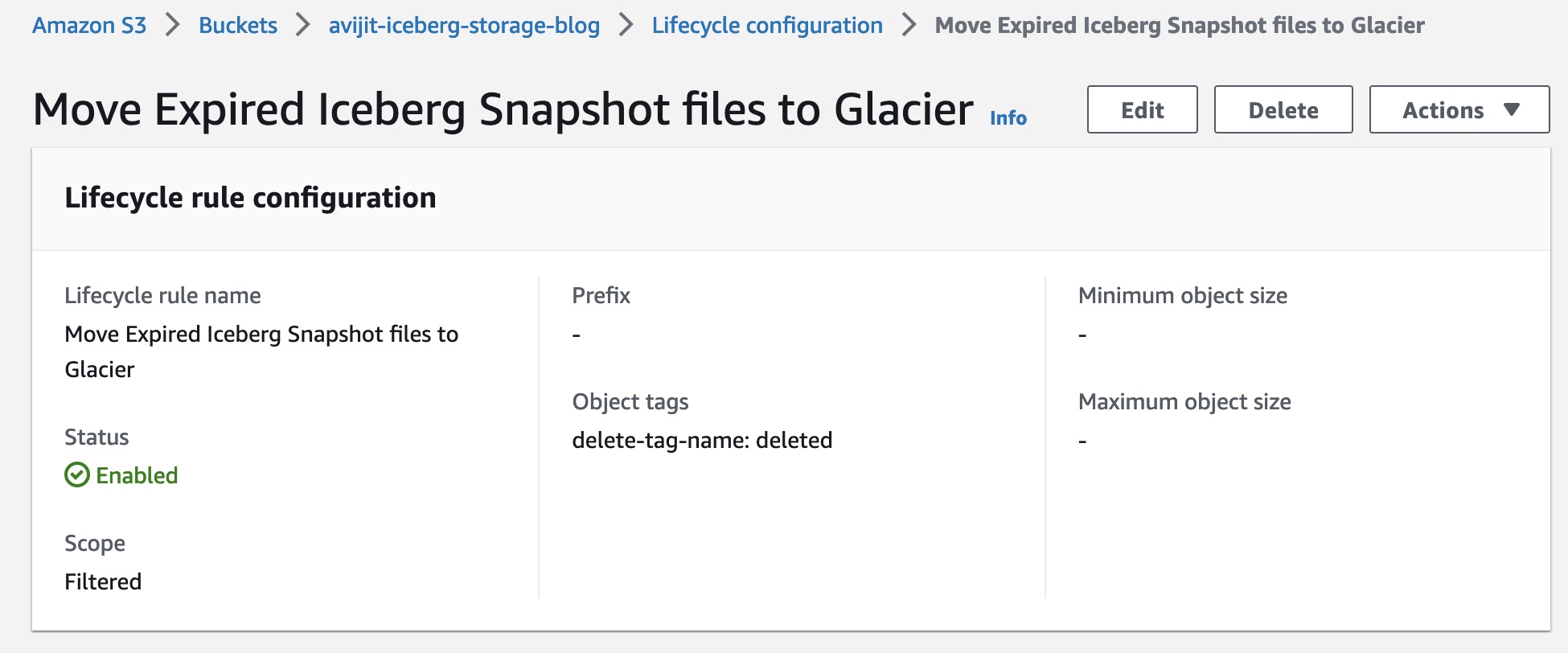
バケットを別のストレージ層に移行するための S3 ライフサイクル ルールを作成する
delete-tag-name=deleted S3 タグを持つオブジェクトを Glacier Instant Retrieval クラスに移行するためのバケットのライフサイクル設定を作成します。 Amazon S3 は、ライフサイクル ルールを毎日 48 回、協定世界時 (UTC) の午前 3 時に実行します。新しいライフサイクル ルールは、最初の実行が完了するまでに最大 3 時間かかる場合があります。 Amazon S68 Glacier は、即時アクセス (ミリ秒単位の取得) が必要なデータのアーカイブに適しています。 S3 Glacier Instant Retrieval を使用すると、データが四半期に 3 回アクセスされる場合、SXNUMX 標準 - 低頻度アクセス (SXNUMX 標準 - IA) ストレージ クラスを使用する場合と比較して、ストレージ コストを最大 XNUMX% 節約できます。
データにアクセスしたい場合は、次の操作を行うことができます。 アーカイブされたオブジェクトを一括復元する。 オブジェクトを S3 標準クラスに復元した後、クエリ目的でメタデータとデータをアーカイブ テーブルとして登録できます。 メタデータ ファイルの場所は、前に示したように、メタテーブルのメタデータ ログ エントリから取得できます。 前述したように、Null 値を含む最新のスナップショット ID は、期限切れのスナップショットを示します。 期限切れのスナップショットの XNUMX つを取得して、一括復元を実行できます。
災害復旧とビジネス継続性、データレイクへのクロスアカウントおよびマルチリージョンアクセスの機能
Iceberg は相対パスをサポートしていないため、次を使用できます。 アクセスポイント バケットからアクセスポイントへのマッピングを指定して、Amazon S3 オペレーションを実行します。 これは、マルチリージョン アクセス、クロスリージョン アクセス、災害復旧などに役立ちます。
クロスリージョンのアクセス ポイントの場合、追加で設定する必要があります。 use-arn-region-enabled カタログプロパティを true 有効にする S3FileIO リージョンを越えた通話を行うため。 Amazon S3 リソース ARN が、クライアントが設定されたリージョンとは異なるリージョンを持つ Amazon S3 オペレーションのターゲットとして渡される場合、このフラグを ' に設定する必要があります。true' クライアントが ARN で指定されたリージョンへのクロスリージョン呼び出しを行うことを許可します。そうでない場合は、例外がスローされます。 ただし、同じまたは複数リージョンのアクセス ポイントの場合、 use-arn-region-enabled フラグは「」に設定する必要がありますfalse'。
たとえば、Spark 3 でマルチリージョン アクセスで S3.3 アクセス ポイントを使用するには、次のコードを使用して Spark SQL シェルを起動できます。
この例では、Amazon S3 のオブジェクトは my-bucket1 & my-bucket2 バケットは arn:aws:s3::123456789012:accesspoint:mfzwi23gnjvgw.mrap すべての Amazon S3 操作のアクセス ポイント。
アクセスポイントの使用方法について詳しくは、「アクセスポイントの使用方法」を参照してください。 互換性のある Amazon S3 操作でアクセス ポイントを使用する.
テーブルのパスが以下にあるとします。 mybucket1、だから両方 mybucket1 リージョン 1 および mybucket2 リージョンには次のパスがあります mybucket1 メタデータ ファイル内。 S3 (GET/PUT) 呼び出し時に、 mybucket1 マルチリージョン アクセス ポイントを使用した参照。
増加した S3 リクエスト率の処理
使用時 ObjectStoreLocationProvider (詳細については、を参照してください) オブジェクトストアファイルのレイアウト)、保存されたファイルごとに決定論的ハッシュが生成され、そのハッシュはファイルの直後に追加されます。 write.data.path。 これの問題は、デフォルトのハッシュ アルゴリズムが最大整数のハッシュ値を生成することです。 MAX_VALUE、Java では (2^31)-1 です。 これを 0 進数に変換すると 7x0FFFFFFF が生成されるため、最初の文字の差異は [8-3] のみに制限されます。 Amazon SXNUMXによると 提言これを軽減するには、ここで分散を最大にする必要があります。
価格 (税別) アマゾンEMR6.10, Amazon EMR は、[0-9][AZ][az] の文字セットを使用して、生成されたプレフィックス ハッシュの最初の XNUMX 文字が均一に分散されるようにする、最適化されたロケーションプロバイダーを追加しました。
この位置情報プロバイダーは最近、Amazon EMR によってオープンソース化されました。 コア: オブジェクト ストレージ レイアウトのビット密度を向上させる Iceberg 1.3.0 以降で利用可能になります。
使用するには、 iceberg.enabled 分類は次のように設定されています true, write.location-provider.impl に設定されています org.apache.iceberg.emr.OptimizedS3LocationProvider.
以下は、Spark シェル コマンドのサンプルです。
次の例は、Iceberg テーブルでオブジェクト ストレージを有効にすると、S3 パスの DDL で指定した場所の直後にハッシュ プレフィックスが追加されることを示しています。
テーブルを定義する write.object-storage.enabled パラメータを指定して S3 パスを指定し、その後、次を使用してハッシュ プレフィックスを追加します。 write.data.path (Iceberg バージョン 0.13 以降の場合) または write.object-storage.path (Iceberg バージョン 0.12 以下の場合) パラメータ。
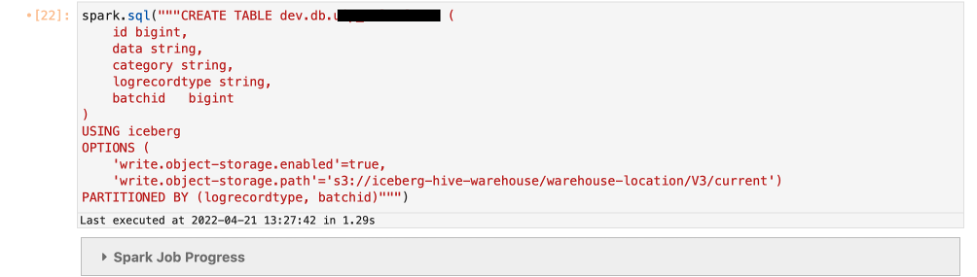
作成したテーブルにデータを挿入します。

ハッシュ プレフィックスは、DDL で定義されているように、S3 パスの /current/ プレフィックスの直後に追加されます。

クリーンアップ
テストが完了したら、リソースをクリーンアップして、繰り返し発生するコストを回避します。
- このテスト用に作成した S3 バケットを削除します。
- EMR クラスターを削除します。
- EMR ノートブック インスタンスを停止して削除します。
まとめ
企業が S3 データ レイク上の非常に大規模なデータセットに対して Apache Iceberg オープン テーブル フォーマットを使用して、新しいトランザクション データ レイクのユースケースを構築し続けるにつれて、コストを削減し、効率を向上させ、高機能を実装するために、ペタバイト規模の運用環境を最適化することにますます重点が置かれることになります。可用性。 この投稿では、AWS で実行される Apache Iceberg オープン テーブル フォーマットの運用効率を実装するメカニズムを実証しました。
Apache Iceberg の詳細と、トランザクション データ レイクのユースケースにこのオープン テーブル形式を実装するには、次のリソースを参照してください。
著者について
 アビジットゴスワミ データと分析を専門とする AWS のプリンシパル ソリューション アーキテクトです。 彼は、AWS マネージド サービスとオープンソース ソリューションを使用して、AWS で高性能、安全、かつスケーラブルなデータ レイク ソリューションを構築することで、AWS の戦略的顧客をサポートしています。 仕事以外では、旅行、サンフランシスコ ベイ エリアのトレイルでのハイキング、スポーツ観戦、音楽鑑賞が好きです。
アビジットゴスワミ データと分析を専門とする AWS のプリンシパル ソリューション アーキテクトです。 彼は、AWS マネージド サービスとオープンソース ソリューションを使用して、AWS で高性能、安全、かつスケーラブルなデータ レイク ソリューションを構築することで、AWS の戦略的顧客をサポートしています。 仕事以外では、旅行、サンフランシスコ ベイ エリアのトレイルでのハイキング、スポーツ観戦、音楽鑑賞が好きです。
 ラジャルシ・サルカール Amazon EMR/Athena のソフトウェア開発エンジニアです。 彼は Amazon EMR/Athena の最先端の機能に取り組んでおり、Apache Iceberg や Trino などのオープンソース プロジェクトにも携わっています。 余暇には、旅行したり、映画を見たり、友達と遊んだりするのが好きです。
ラジャルシ・サルカール Amazon EMR/Athena のソフトウェア開発エンジニアです。 彼は Amazon EMR/Athena の最先端の機能に取り組んでおり、Apache Iceberg や Trino などのオープンソース プロジェクトにも携わっています。 余暇には、旅行したり、映画を見たり、友達と遊んだりするのが好きです。
 プラシャント・シン AWS のソフトウェア開発エンジニアです。 彼はデータベースとデータ ウェアハウス エンジンに興味があり、EMR での Apache Spark パフォーマンスの最適化に取り組んできました。 彼は、Apache Spark や Apache Iceberg などのオープンソース プロジェクトに積極的に貢献しています。 自由時間には、新しい場所の探索、食べ物、ハイキングを楽しんでいます。
プラシャント・シン AWS のソフトウェア開発エンジニアです。 彼はデータベースとデータ ウェアハウス エンジンに興味があり、EMR での Apache Spark パフォーマンスの最適化に取り組んできました。 彼は、Apache Spark や Apache Iceberg などのオープンソース プロジェクトに積極的に貢献しています。 自由時間には、新しい場所の探索、食べ物、ハイキングを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/improve-operational-efficiencies-of-apache-iceberg-tables-built-on-amazon-s3-data-lakes/

