Amazonレッドシフト は、高速でスケーラブル、安全、および完全に管理されたクラウドデータウェアハウスであり、標準SQLを使用してすべてのデータを簡単かつ費用効果の高い方法で分析できます。 Amazon Redshiftは、他のクラウドデータウェアハウスよりも最大XNUMX倍優れた価格パフォーマンスを提供します。 何万人もの顧客がAmazonRedshiftを使用して、XNUMX日あたり数エクサバイトのデータを処理し、高性能ビジネスインテリジェンス(BI)レポート、ダッシュボードアプリケーション、データ探索、リアルタイム分析などの分析ワークロードを強化しています。
IoTデバイス、ソーシャルメディア、およびクラウドアプリケーションによって生成されるデータの量が増え続けるにつれて、組織は、最小限の洞察時間でこのデータを簡単かつコスト効率よく分析しようとしています。 このデータの膨大な量は半構造化形式で利用可能であり、アクセス可能にするため、または分析のために構造化データと統合するために、追加の抽出、変換、および読み込み(ETL)プロセスが必要です。 Amazon Redshiftは、最新のデータアーキテクチャを強化します。これにより、データウェアハウス、データレイク、運用データベース全体でデータをクエリして、他の方法では不可能な、より高速でより深い洞察を得ることができます。 最新のデータアーキテクチャを使用すると、半構造化形式でデータを保存できます。 Amazon シンプル ストレージ サービス (Amazon S3)データレイクし、AmazonRedshiftの構造化データと統合します。 これにより、このデータをサイロに固定するのではなく、他の分析アプリケーションや機械学習アプリケーションで利用できるようになります。
この投稿では、Amazon RedshiftのUNLOAD機能と、AmazonRedshiftクラスターからAmazonS3データレイク上のJSONファイルにデータをエクスポートする方法について説明します。
AmazonRedshiftのJSONサポート機能
COPY、UNLOAD、およびなどのAmazonRedshift機能 AmazonRedshiftスペクトラム データウェアハウスとデータレイクの間でデータを移動およびクエリできるようにします。
アンロード コマンドを使用すると、クエリ結果セットをテキスト、JSON、またはApacheParquetファイル形式でAmazonS3にエクスポートできます。 データウェアハウスから大きな結果セットを取得する必要がある場合にも、UNLOADコマンドをお勧めします。 UNLOADは、AmazonRedshiftのコンピューティングノードからAmazonS3にデータを並行して処理およびエクスポートするため、ネットワークオーバーヘッドが削減され、多数の行を読み取る時間が短縮されます。 UNLOADでJSONオプションを使用すると、Amazon Redshiftは、クエリ結果の完全なレコードを表すJSONオブジェクトを含む各行を含むJSONファイルにアンロードします。 JSONファイルでは、AmazonRedshiftタイプが最も近いJSON表現としてアンロードされます。 たとえば、ブール値はtrueまたはfalseとしてアンロードされ、NULL値はnullとしてアンロードされ、タイムスタンプ値は文字列としてアンロードされます。 デフォルトのJSON表現が特定のユースケースに適していない場合は、次の方法で変更できます。 鋳造 UNLOADステートメントのSELECTクエリで目的のタイプに変更します。
さらに、有効なJSONオブジェクトを作成するには、クエリ結果の各列の名前が一意である必要があります。 クエリ結果の列名が一意でない場合、JSONUNLOADプロセスは失敗します。 これを回避するには、適切な列エイリアスを使用して、アンロードされている間、クエリ結果の各列が一意のままになるようにすることをお勧めします。 この動作については、この投稿の後半で説明します。
AmazonRedshiftを使用する スーパー データ型の場合、ローカルのAmazonRedshiftテーブルにJSON形式でデータを保存できます。 このようにして、ネットワークオーバーヘッドなしでデータを処理し、Amazon Redshiftスキーマプロパティを使用して、半構造化データをローカルに最適に保存およびクエリできます。 低レイテンシを実現することに加えて、クエリに強い一貫性、予測可能なクエリパフォーマンス、複雑なクエリサポート、進化するスキーマやスキーマレスデータの使いやすさが必要な場合は、SUPERデータ型を使用することもできます。 Amazon Redshiftは、クエリ結果にSUPER列が含まれている場合にネストされたJSONの書き込みをサポートします。
絶えず進化するスキーマを使用してデータを更新および維持することは困難な場合があり、分析パイプラインに追加のETLステップを追加します。 JSONファイル形式は、スキーマ定義のサポートを提供し、軽量であり、さまざまなサービス、ツール、およびテクノロジーによるデータ転送メカニズムとして広く使用されています。
アマゾンオープンサーチサービス(アマゾンエラスティックサーチサービスの後継) は、リアルタイムのアプリケーションモニタリング、ログ分析、Webサイト検索など、幅広いユースケースに使用される分散型のオープンソース検索および分析スイートです。 データ取り込みでサポートされているファイル形式としてJSONを使用します。 データをJSON形式でAmazonRedshiftからAmazonS3データレイクにネイティブにアンロードする機能により、データをさらに分析するためにAmazon OpenSearch Serviceに取り込む必要がある場合に、複雑さと追加のデータ処理手順が軽減されます。
これは、シームレスなデータ移動が、Amazon S3のデータレイク、Amazon Redshiftのデータウェアハウス、Amazon OpenSearchServiceやその他のJSON指向のダウンストリーム分析ソリューションを使用した検索とログ分析を備えた統合データプラットフォームの構築にどのように役立つかの一例です。 レイクハウスアプローチの詳細については、を参照してください。 AWSでレイクハウスアーキテクチャを構築する.
Amazon Redshift JSONUNLOADの例
この投稿では、次のさまざまなシナリオを紹介します。
- 例 –顧客データをJSON形式でAmazon S3にアンロードし、Apache Hiveの規則に従って、顧客の誕生月をパーティションキーとして、出力ファイルをパーティションフォルダーに分割します。 UNLOADコマンドのSELECTステートメントの列にいくつかの変更を加えます。
- 変換
c_preferred_cust_flag文字からブール値への列 - から先頭と末尾のスペースを削除します
c_first_name,c_last_name,c_email_addressAmazonRedshift組み込み関数を使用した列 ブトリム
- 変換
- 例 –データがパーティション化されていない状態でJSON形式のラインアイテムデータ(SUPER列を含む)をAmazonS3にアンロードします
- 例 – JSON形式のラインアイテムデータ(SUPER列を含む)をAmazon S3にアンロードし、Apache Hiveの規則に従って、顧客キーをパーティションキーとして、出力ファイルをパーティションフォルダーにパーティション化します。
最初の例では、 customer テーブルとデータ TPCDSデータセット。 SUPER列のあるテーブルを含む例では、 customer_orders_lineitem 以下の表とデータ チュートリアル.
例1:顧客データをエクスポートする
この例では、顧客テーブルとTPCDSデータセットのデータを使用しました。 データベーススキーマを作成し、 customer テーブルにデータをコピーしました。 次のコードを参照してください。
デフォルトを作成できます AWS IDおよびアクセス管理 (IAM)AmazonRedshiftクラスターがAmazonS3の場所からコピーおよびアンロードするための役割。 詳細については、を参照してください。 Amazon RedshiftのデフォルトのIAMロールを使用して、他のAWSサービスへのアクセスを簡素化します.
この例では、1992年に誕生したすべての顧客の顧客データをJSON形式でパーティションなしでAmazonS3にアンロードしました。 UNLOADステートメントに次の変更を加えます。
- 変換
c_preferred_cust_flag文字からブール値への列 - から先頭と末尾のスペースを削除します
c_first_name,c_last_name,c_email_addressを使用する列btrimfunction - AmazonS3でエクスポートされるファイルの最大サイズを64MBに設定します
次のコードを参照してください。
UNLOADコマンドを実行すると、を使用した列がエラーになったため、エラーが発生しました。 btrim 関数はすべて次のようにエクスポートしようとしました btrim (これは、一緒に選択された複数の列に同じ関数が適用された場合のAmazon Redshiftのデフォルトの動作です)。 このエラーを回避するには、列ごとに一意の列エイリアスを使用する必要があります。 btrim 関数が使用されました。
を選択した場合 c_first_name, c_last_name, c_email_address 適用することによる列 btrim 機能と c_preferred_cust_flag、文字からブール値に変換できます。
次のクエリを実行しました AmazonRedshiftクエリエディターv2:
を使用したXNUMXつの列すべて btrim 機能は次のように設定されます btrim それぞれの列名の代わりに、出力結果に表示されます。
列エイリアスを使用しなかったため、UNLOADでエラーが発生しました。
次のコードに列エイリアスを追加しました。
列エイリアスを追加した後、UNLOADコマンドは正常に完了し、ファイルはAmazonS3の目的の場所にエクスポートされました。
次のスクリーンショットは、Apache Hiveの規則に従い、AmazonRedshiftからAmazonS3へのパーティションキーとして顧客の誕生月を使用して、出力ファイルをパーティションフォルダーにパーティション化するJSON形式でデータがアンロードされることを示しています。 customer 列で番号の横にあるXをクリックします。
Amazon S3 Selectを使用したクエリでは、アンロードされたAmazonS3のJSONファイル内のデータのスニペットが表示されます。
列のエイリアス c_first_name, c_last_name, c_email_addr_trimmed SELECTクエリに従ってJSONレコードに書き込まれました。 ブール値はに保存されました c_preferred_cust_flag_bool 同様に。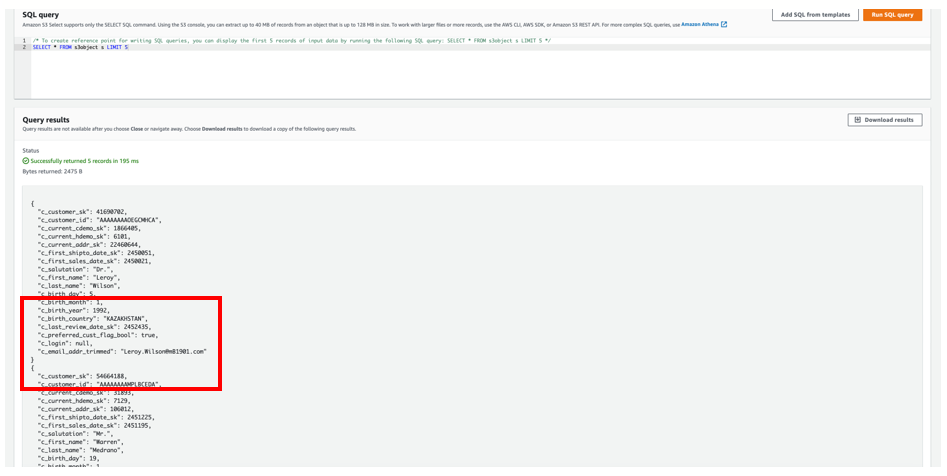
例2および3:SUPER列の使用
次のXNUMXつの例では、 customer_orders_lineitem テーブルとデータ。 作成しました customer_orders_lineitem 次のコードを使用してテーブルにデータをコピーします。
次に、いくつかのクエリを実行して、 customer_orders_lineitem テーブルのデータ:



例2:パーティションなし
この例では、のすべての行をアンロードしました customer_orders_lineitem パーティションのないAmazonS3へのJSON形式のテーブル:
UNLOADコマンドを実行すると、データは目的のAmazonS3の場所で利用できるようになります。 次のスクリーンショットは、データがパーティションなしでJSON形式でAmazonRedshiftからAmazonS3にアンロードされることを示しています。 customer_orders_lineitem 列で番号の横にあるXをクリックします。
Amazon S3 Selectを使用したクエリでは、アンロードされたAmazonS3のJSONファイル内のデータのスニペットが表示されます。
例3:パーティションあり
この例では、のすべての行をアンロードしました customer_orders_lineitem Apache Hiveの規則に従い、Amazon S3へのパーティションキーとして顧客キーを使用して、出力ファイルをパーティションフォルダーにパーティション化するJSON形式のテーブル:
UNLOADコマンドを実行すると、データは目的のAmazonS3の場所で利用できるようになります。 次のスクリーンショットは、Apache Hiveの規則に従って、AmazonRedshiftからAmazonS3へのパーティションキーとして顧客キーを使用して、出力ファイルをパーティションフォルダーにパーティション化するJSON形式でデータがアンロードされることを示しています。 customer_orders_lineitem 列で番号の横にあるXをクリックします。
Amazon S3 Selectを使用したクエリでは、アンロードされたAmazonS3のJSONファイル内のデータのスニペットが表示されます。
まとめ
この投稿では、Amazon Redshift UNLOADコマンドを使用して、クエリの結果を3つ以上のJSONファイルにアンロードしてAmazonS3の場所に移動する方法を示しました。 また、データをアンロードするときに、選択したパーティションキーを使用してデータをパーティション化する方法も示しました。 この機能を使用して、AmazonRedshiftクラスターまたはAmazonRedshiftサーバーレスエンドポイントからAmazonSXNUMXにデータをJSONファイルにエクスポートして、データ処理を簡素化し、統合データ分析プラットフォームを構築できます。
著者について
 ディパンカルクシャリ AWSのシニアアナリティクスソリューションアーキテクトです。
ディパンカルクシャリ AWSのシニアアナリティクスソリューションアーキテクトです。
 サヤリ・ジョジャン AWSのシニアアナリティクスソリューションアーキテクトです。 彼女は、データと分析に重点を置いて、AWSクラウド上でソリューションを設計および構築するために顧客と協力して7年の経験があります。
サヤリ・ジョジャン AWSのシニアアナリティクスソリューションアーキテクトです。 彼女は、データと分析に重点を置いて、AWSクラウド上でソリューションを設計および構築するために顧客と協力して7年の経験があります。
 コーディカニンガム AWSのソフトウェア開発エンジニアであり、AmazonRedshiftのデータ取り込みに取り組んでいます。
コーディカニンガム AWSのソフトウェア開発エンジニアであり、AmazonRedshiftのデータ取り込みに取り組んでいます。

