
Imagine trying to bake a cake without a recipe. You might remember bits and pieces, but chances are you’ll miss something crucial. This is similar to how traditional Large Language Models (LLMs) function, they’re brilliant but sometimes lack specific, up-to-date information.
The Naive RAG paradigm represents the earliest methodology, which gained prominence shortly after ChatGPT became widely adopted. This approach follows a traditional process that includes indexing, retrieval, and generation, often referred to as a “Retrieve-Read” framework.
The image below illustrates a Naive RAG pipeline:
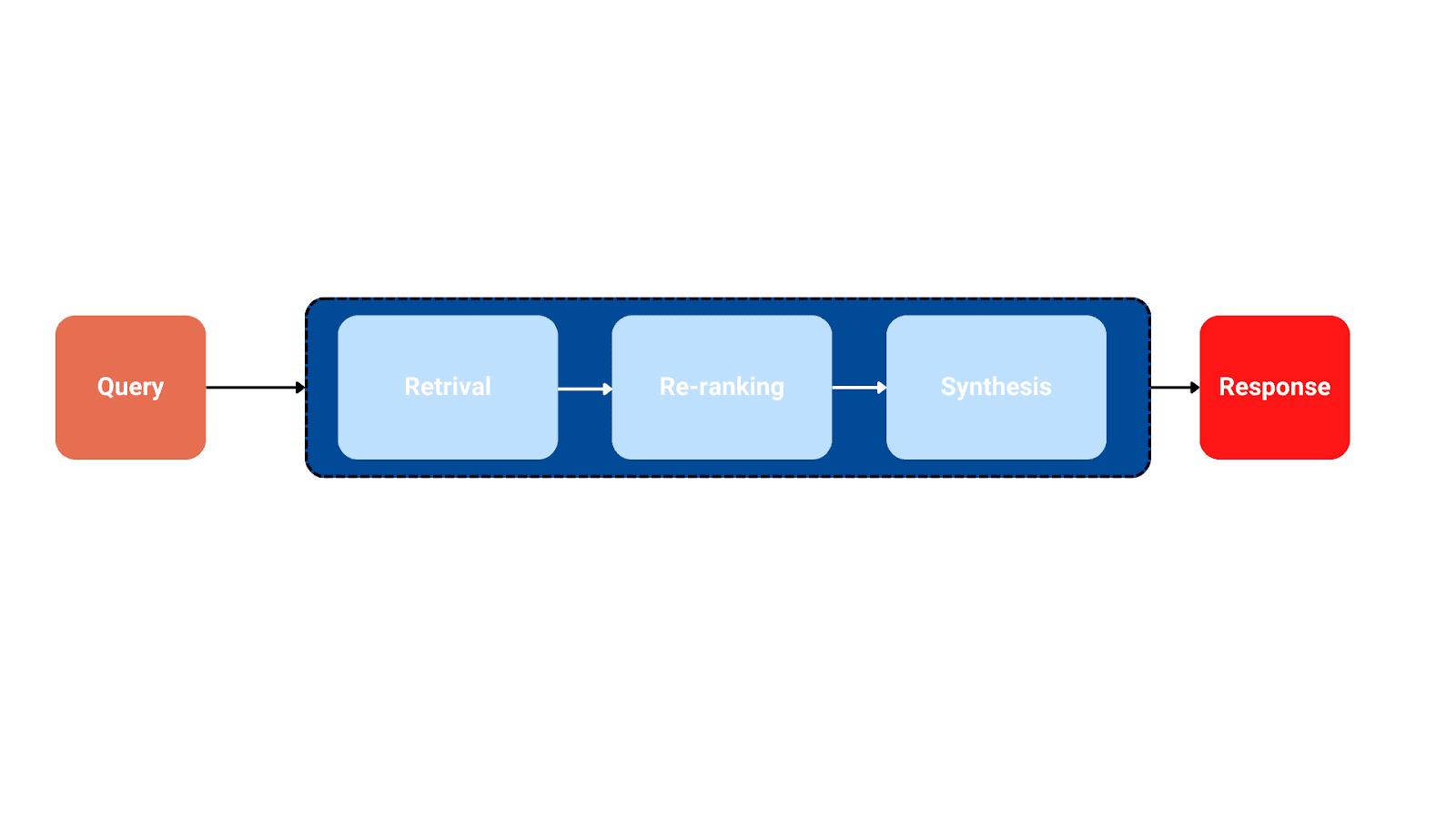
This image shows the Naive RAG pipeline from query to the retrieval and the response | Image by author
Implementing Agentic RAG using LangChain takes this a step further. Unlike the naive RAG approach, Agentic RAG introduces the concept of an ‘agent’ that can actively interact with the retrieval system to improve the quality of the generated output.
To begin, let’s first define what Agentic RAG is.
What is Agentic RAG?
Agentic RAG (Agent-Based Retrieval-Augmented Generation) is an innovative approach to answering questions across multiple documents. Unlike traditional methods that rely solely on large language models, Agentic RAG utilizes intelligent agents that can plan, reason, and learn over time.
These agents are responsible for comparing documents, summarizing specific documents, and evaluating summaries. This provides a more flexible and dynamic framework for question answering, as the agents collaborate to accomplish complex tasks.
The key components of Agentic RAG are:
- Document Agents: Responsible for question answering and summarization within their designated documents.
- Meta-Agent: The top-level agent that oversees the document agents and coordinates their efforts.
This hierarchical structure allows Agentic RAG to leverage the strengths of both individual document agents and the meta-agent, resulting in enhanced capabilities in tasks requiring strategic planning and nuanced decision-making.
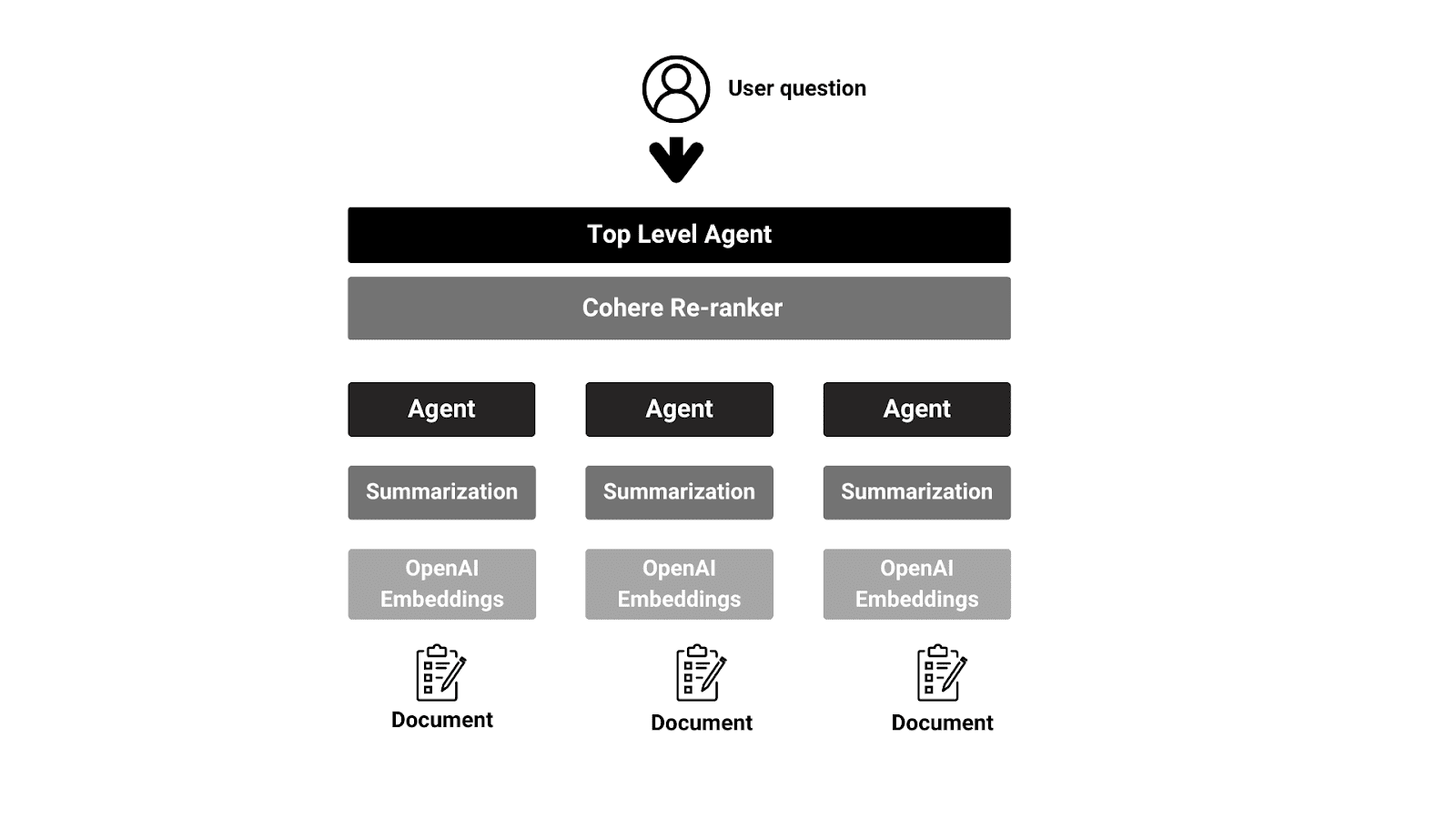
This image illustrates the different layers of agents from the top-level agent down to the subordinate document agents | source: LlamaIndex
Benefits of Using Agentic RAG
Using an agent-based implementation in Retrieval-Augmented Generation (RAG) offers several benefits which include task specialization, parallel processing, scalability, flexibility, and fault tolerance. This is explained in detail below:
- Task specialization: Agent-based RAG allows for task specialization among different agents. Each agent can focus on a specific aspect of the task, such as document retrieval, summarization, or question answering. This specialization enhances efficiency and accuracy by ensuring that each agent is well-suited to its designated role.
- Parallel processing: Agents in an agent-based RAG system can work in parallel, processing different aspects of the task simultaneously. This parallel processing capability leads to faster response times and improved overall performance, especially when dealing with large datasets or complex tasks.
- Scalability: The architectures of Agent-based RAG are inherently scalable. New agents can be added to the system as needed, allowing it to handle increasing workloads or accommodate additional functionalities without significant changes to the overall architecture. This scalability ensures that the system can grow and adapt to changing requirements over time.
- Flexibility: These systems offer flexibility in task allocation and resource management. Agents can be dynamically assigned to tasks based on workload, priority, or specific requirements, allowing for efficient resource utilization and adaptability to varying workloads or user demands.
- Fault tolerance: Agent-based RAG architectures are inherently fault-tolerant. If one agent fails or becomes unavailable, other agents can continue to perform their tasks independently, reducing the risk of system downtime or data loss. This fault tolerance improves the reliability and robustness of the system, ensuring uninterrupted service even in the face of failures or disruptions.
Now that we have learned what it is, in the next part, we will implement agentic RAG.
Shittu Olumide is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/how-to-implement-agentic-rag-using-langchain-part-1?utm_source=rss&utm_medium=rss&utm_campaign=how-to-implement-agentic-rag-using-langchain-part-1

