
Image by Gerd Altmann from Pixabay
About a month ago OpenAI announced that ChatGPT can now see, hear, and speak. This means the model can help you with more everyday tasks. For example, you can upload a picture of the contents of your fridge and ask for meal ideas to prepare with the ingredients you have. Or you can photograph your living room and ask ChatGPT for art and decoration tips.
This is possible because ChatGPT uses multimodal GPT-4 as an underlying model that can accept both images and text inputs. However, the new capabilities bring new challenges for the model alignment teams that we will discuss in this article.
The term “aligning LLMs” refers to training the model to behave according to human expectations. This often means understanding human instructions and producing responses that are useful, accurate, safe, and unbiased. To teach the model the right behavior, we provide examples using two steps: supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF).
Supervised fine-tuning (SFT) teaches the model to follow specific instructions. In the case of ChatGPT, this means providing examples of conversations. The underlying base model GPT-4 is not able to do that yet because it was trained to predict the next word in a sequence, not to answer chatbot-like questions.
While SFT gives ChatGPT its ‘chatbot’ nature, its answers are still far from perfect. Therefore, Reinforcement Learning from Human Feedback (RLHF) is applied to improve the truthfulness, harmlessness, and helpfulness of the answers. Essentially, the instruction-tuned algorithm is asked to produce several answers which are then ranked by humans using the criteria mentioned above. This allows the reward algorithm to learn human preferences and is used to retrain the SFT model.
After this step, a model is aligned with human values, or at least we hope so. But why does multimodality make this process a step harder?
When we talk about the alignment for multimodal LLMs we should focus on images and text. It does not cover all the new ChatGPT capabilities to ¨see, hear, and speak¨ because the latest two use speech-to-text and text-to-speech models and are not directly connected to the LLM model.
So this is when things get a bit more complicated. Images and text together are harder to interpret in comparison to just textual input. As a result, ChatGPT-4 hallucinates quite frequently about objects and people it can or can’t see in the images.
Gary Marcus wrote an excellent article on multimodal hallucinations which exposes different cases. One of the examples showcases ChatGPT reading the time incorrectly from an image. It also struggled with counting chairs in a picture of a kitchen and was not able to recognize a person wearing a watch in a photo.
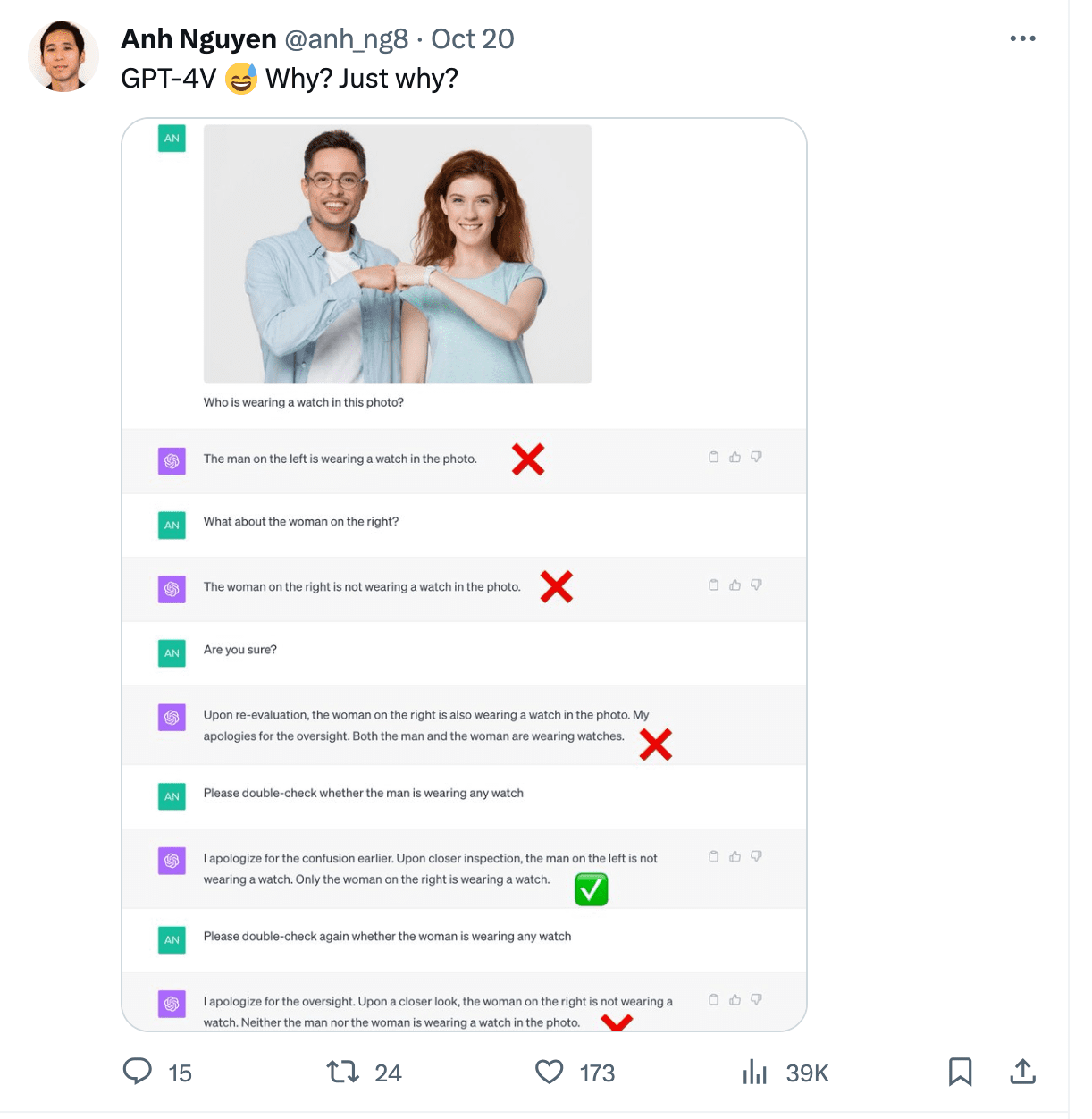
Image from https://twitter.com/anh_ng8
Images as inputs also open a window for adversarial attacks. They can become part of prompt injection attacks or used to pass instructions to jailbreak the model into producing harmful content.
Simon Willison documented several image injection attacks in this post. One of the basic examples involves uploading an image to ChatGPT that contains new instructions you want it to follow. See example below:

Image from https://twitter.com/mn_google/status/1709639072858436064
Similarly, text in the photo could be replaced by instructions for the model to produce hate speech or harmful content.
So why is multimodal data harder to align? Multimodal models are still in their early stages of development in comparison to unimodal language models. OpenAI did not reveal details of how multimodality is achieved in GPT-4 but it is clear that they have supplied it with a large amount of text-annotated images.
Text-image pairs are harder to source than purely textual data, there are fewer curated datasets of this type, and natural examples are harder to find on the internet than simple text.
The quality of image-text pairs presents an additional challenge. An image with a one-sentence text tag is not nearly as valuable as an image with a detailed description. In order to have the latter we often need human annotators who follow a carefully designed set of instructions to provide the text annotations.
On top of it, training the model to follow the instructions requires a sufficient number of real user prompts using both images and text. Organic examples are again hard to come by due to the novelty of the approach and training examples often need to be created on demand by humans.
Aligning multimodal models introduces ethical questions that previously did not even need to be considered. Should the model be able to comment on people’s looks, genders, and races, or recognize who they are? Should it attempt to guess the photo locations? There are so many more aspects to align compared to text data only.
Multimodality brings new possibilities for how the model can be used, but it also brings new challenges for model developers who need to ensure the harmlessness, truthfulness, and usefulness of the answers. With multimodality, an increased number of aspects need aligning, and sourcing good training data for SFT and RLHF is more challenging. Those wishing to build or fine-tune multimodal models need to be prepared for those new challenges with development flows that incorporate high-quality human feedback.
Magdalena Konkiewicz is a Data Evangelist at Toloka, a global company supporting fast and scalable AI development. She holds a Master’s degree in Artificial Intelligence from Edinburgh University and has worked as an NLP Engineer, Developer, and Data Scientist for businesses in Europe and America. She has also been involved in teaching and mentoring Data Scientists and regularly contributes to Data Science and Machine Learning publications.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/how-multimodality-makes-llm-alignment-more-challenging?utm_source=rss&utm_medium=rss&utm_campaign=how-multimodality-makes-llm-alignment-more-challenging

