Dies ist ein Gastbeitrag, der zusammen mit Fred Wu von Sportradar geschrieben wurde.
Sportradar ist das weltweit führende Sporttechnologieunternehmen an der Schnittstelle zwischen Sport, Medien und Wetten. Mehr als 1,700 Sportverbände, Medienunternehmen, Wettanbieter und Verbraucherplattformen in 120 Ländern verlassen sich auf das Know-how und die Technologie von Sportradar, um ihr Geschäft anzukurbeln.
Sportradar verwendet Daten und Technologie, um:
- Halten Sie Wettanbieter mit den Produkten und Dienstleistungen, die sie für die Verwaltung ihrer Sportwetten benötigen, auf dem Laufenden
- Geben Sie Medienunternehmen die Tools, um mehr mit Fans zu interagieren
- Stellen Sie Teams, Ligen und Verbänden die Daten zur Verfügung, die sie zum Erfolg benötigen
- Halten Sie die Branche sauber, indem Sie Betrug, Doping und Spielmanipulationen aufdecken und verhindern
Dieser Beitrag zeigt, wie Sportradar gebraucht von Amazon Tiefe Java-Bibliothek (DJL) auf AWS daneben Amazon Elastic Kubernetes-Service (Amazon EKS) und Amazon Simple Storage-Service (Amazon S3), um eine produktionsreife Inferenzlösung für maschinelles Lernen (ML) zu entwickeln, die wesentliche Tools in Java beibehält, die betriebliche Effizienz optimiert und die Produktivität des Teams durch bessere Leistung und Zugriff auf Protokolle und Systemmetriken steigert.
DJL ist ein Deep-Learning-Framework, das von Grund auf neu entwickelt wurde, um Benutzer von Java- und JVM-Sprachen wie Scala, Kotlin und Clojure zu unterstützen. Derzeit werden die meisten Deep-Learning-Frameworks für Python erstellt, aber dies vernachlässigt die große Anzahl von Java-Entwicklern und Entwicklern, die über vorhandene Java-Codebasen verfügen, in die sie die immer leistungsfähigeren Fähigkeiten von Deep Learning integrieren möchten. Mit dem DJL ist die Integration dieses Deep Learning einfach.
In diesem Beitrag diskutiert das Sportradar-Team die Herausforderungen, auf die es gestoßen ist, und die Lösungen, die es entwickelt hat, um seine Modellinferenzplattform mit DJL aufzubauen.
Geschäftsanforderungen
Wir sind die US-Truppe der Sportradar-KI-Abteilung. Seit 2018 entwickelt unser Team eine Vielzahl von ML-Modellen, um Wettprodukte für NFL- und NCAA-Fußball zu ermöglichen. Vor kurzem haben wir vier weitere neue Modelle entwickelt.
Die Fourth-Down-Entscheidungsmodelle für die NFL und die NCAA sagen die Wahrscheinlichkeiten des Ergebnisses eines Fourth-Down-Spiels voraus. Ein Spielergebnis kann ein Field-Goal-Versuch, ein Spiel oder ein Punt sein.
Die Drive-Ergebnismodelle für die NFL und die NCAA sagen die Wahrscheinlichkeiten des Ergebnisses des aktuellen Drives voraus. Ein Drive-Ergebnis kann ein Ende der Hälfte, ein Field Goal-Versuch, ein Touchdown, ein Turnover, ein Turnover on Downs oder ein Punt sein.

Unsere Modelle sind die Bausteine anderer Modelle, bei denen wir eine Liste von Live-Wettmärkten erstellen, einschließlich Spread, Gesamtzahl, Gewinnwahrscheinlichkeit, nächster Ergebnistyp, nächstes Team, das ein Tor erzielt, und mehr.
Die Geschäftsanforderungen für unsere Modelle sind wie folgt:
- Der Modellprädiktor sollte in der Lage sein, die vorab trainierte Modelldatei einmal zu laden und dann Vorhersagen für viele Spielzüge zu treffen
- Wir müssen die Wahrscheinlichkeiten für jedes Spiel unter einer Latenzzeit von 50 Millisekunden generieren
- Der Modellprädiktor (Feature-Extraktion und Modell-Inferenz) muss in Java geschrieben werden, damit das andere Team ihn als Maven-Abhängigkeit importieren kann
Herausforderungen mit dem In-Place-System
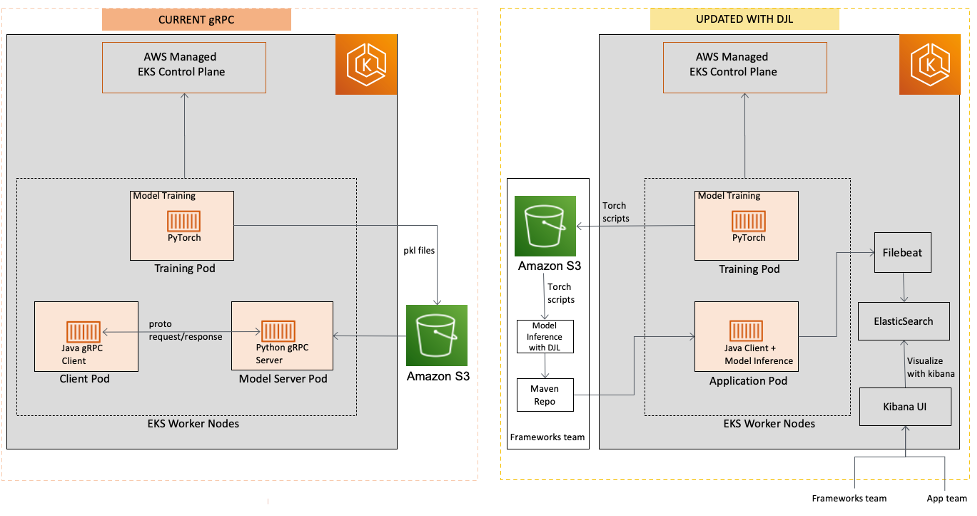
Die größte Herausforderung besteht darin, die Lücke zwischen dem Modelltraining in Python und der Modellinferenz in Java zu schließen. Unsere Data Scientists trainieren das Modell in Python mit Tools wie PyTorch und speichern das Modell als PyTorch-Skripte. Unser ursprünglicher Plan war, die Modelle auch in Python zu hosten und gRPC für die Kommunikation mit einem anderen Dienst zu verwenden, der den Java-gRPC-Client zum Senden der Anfrage verwendet.
Bei dieser Lösung traten jedoch einige Probleme auf. Hauptsächlich sahen wir den Netzwerk-Overhead zwischen zwei verschiedenen Diensten, die in separaten Laufumgebungen oder Pods ausgeführt wurden, was zu einer höheren Latenz führte. Aber der Wartungsaufwand war der Hauptgrund, warum wir diese Lösung aufgegeben haben. Wir mussten sowohl den gRPC-Server als auch das Clientprogramm separat erstellen und die Protokollpufferdateien konsistent und aktuell halten. Dann mussten wir die Anwendung dockerisieren, eine Bereitstellungs-YAML-Datei schreiben, den gRPC-Server in unserem Kubernetes-Cluster bereitstellen und sicherstellen, dass er zuverlässig und automatisch skalierbar ist.
Ein weiteres Problem: Wann immer ein Fehler auf der Seite des gRPC-Servers auftrat, erhielt der Anwendungsclient nur eine vage Fehlermeldung statt einer detaillierten Fehlerrückverfolgung. Der Client musste sich an den Betreuer des gRPC-Servers wenden, um genau zu erfahren, welcher Teil des Codes den Fehler verursacht hat.
Idealerweise möchten wir stattdessen die PyTorch-Skripts des Modells laden, die Funktionen aus der Modelleingabe extrahieren und die Modellinferenz vollständig in Java ausführen. Dann können wir es als Maven-Bibliothek erstellen und veröffentlichen, die in unserer internen Registrierung gehostet wird und die unser Serviceteam in ihre eigenen Java-Projekte importieren kann. Als wir online recherchierten, tauchte die Deep Java Library ganz oben auf. Nachdem wir einige Blogbeiträge und die offizielle Dokumentation von DJL gelesen hatten, waren wir uns sicher, dass DJL die beste Lösung für unser Problem bieten würde.
Lösungsüberblick
Das folgende Diagramm vergleicht die vorherige und die aktualisierte Architektur.
Das folgende Diagramm skizziert den Arbeitsablauf der DJL-Lösung.
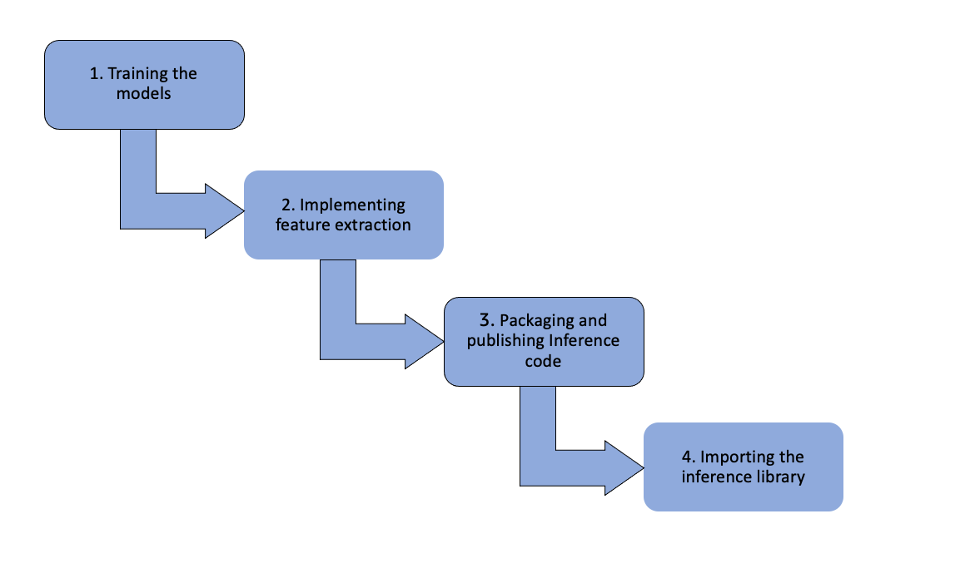
Die Schritte sind wie folgt:
- Trainieren der Modelle – Unsere Data Scientists trainieren die Modelle mit PyTorch und speichern die Modelle als Torch-Skripte. Diese Modelle werden dann zu einem gepusht Amazon Simple Storage-Service (Amazon S3)-Bucket mit DVC, einem Versionskontrolltool für ML-Modelle.
- Implementieren von Feature-Extraktion und Einspeisen von ML-Features – Das Framework-Team zieht die Modelle aus Amazon S3 in ein Java-Repository, wo es die Feature-Extraktion implementiert und ML-Features in den Prädiktor einspeist. Sie verwenden die DJL PyTorch-Engine, um den Modellprädiktor zu initialisieren.
- Verpacken und Veröffentlichen des Inferenzcodes und der Modelle – Die GitLab CI/CD-Pipeline verpackt und veröffentlicht die JAR-Datei, die den Inferenzcode und die Modelle enthält, in einer internen Apache Archiva-Registrierung.
- Importieren der Inferenzbibliothek und Aufrufen – Der Java-Client importiert die Inferenzbibliothek als Maven-Abhängigkeit. Alle Inferenzaufrufe erfolgen über Java-Funktionsaufrufe innerhalb desselben Kubernetes-Pods. Da es keine gRPC-Aufrufe gibt, wird die Rückschlussreaktionszeit verbessert. Darüber hinaus kann der Java-Client die Inferenzbibliothek bei Bedarf problemlos auf eine frühere Version zurücksetzen. Im Gegensatz dazu ist der serverseitige Fehler in gRPC-basierten Lösungen für die Clientseite nicht transparent, was die Fehlerverfolgung erschwert.
Wir haben eine stabile Inferenzlaufzeit und zuverlässige Vorhersageergebnisse gesehen. Die DJL-Lösung bietet mehrere Vorteile gegenüber gRPC-basierten Lösungen:
- Verbesserte Reaktionszeit – Ohne gRPC-Aufrufe wird die Rückschlussantwortzeit verbessert
- Einfache Rollbacks und Upgrades – Der Java-Client kann die Inferenzbibliothek problemlos auf eine frühere Version zurücksetzen oder auf eine neue Version aktualisieren
- Transparente Fehlerverfolgung – In der DJL-Lösung kann der Client im Falle von Inferenzfehlern detaillierte Fehler-Trackback-Meldungen erhalten
Umfassende Übersicht über die Java-Bibliothek
Das DJL ist ein vollständiges Deep-Learning-Framework, das den Deep-Learning-Lebenszyklus vom Erstellen eines Modells über das Trainieren auf einem Datensatz bis hin zur Bereitstellung in der Produktion unterstützt. Es verfügt über intuitive Helfer und Dienstprogramme für Modalitäten wie Computer Vision, Verarbeitung natürlicher Sprache, Audio, Zeitreihen und tabellarische Daten. DJL bietet auch einen einfachen Modellzoo mit Hunderten von vortrainierten Modellen, die sofort verwendet und in bestehende Systeme integriert werden können.
Es ist auch ein vollständig von Apache-2 lizenziertes Open-Source-Projekt und kann auf GitHub gefunden werden. Das DJL wurde 2019 bei Amazon erstellt und als Open Source veröffentlicht. Heute wird die Open-Source-Community von DJL von Amazon geleitet und ist auf viele Länder, Unternehmen und Bildungseinrichtungen angewachsen. Der DJL wächst weiter in seiner Fähigkeit, verschiedene Hardware, Modelle und Engines zu unterstützen. Es beinhaltet auch Unterstützung für neue Hardware wie ARM (sowohl in Servern wie AWS Graviton und Laptops mit Apfel M1) und AWS-Inferenz.
Die Architektur von DJL ist maschinenunabhängig. Es zielt darauf ab, eine Schnittstelle zu sein, die beschreibt, wie Deep Learning in der Java-Sprache aussehen könnte, lässt aber Raum für mehrere verschiedene Implementierungen, die unterschiedliche Fähigkeiten oder Hardwareunterstützung bieten könnten. Heutzutage werden die gängigsten Frameworks wie PyTorch und TensorFlow mit einem Python-Frontend erstellt, das eine Verbindung zu einem leistungsstarken nativen C++-Backend herstellt. Die DJL kann dies verwenden, um sich mit denselben nativen Backends zu verbinden, um ihre Arbeit an Hardwareunterstützung und -leistung zu nutzen.
Aus diesem Grund verwenden viele DJL-Benutzer es auch nur zur Inferenz. Das heißt, sie trainieren ein Modell mit Python und laden es dann mit DJL zur Bereitstellung als Teil ihres vorhandenen Java-Produktionssystems. Da die DJL dieselbe Engine verwendet, die Python antreibt, kann sie ohne Leistungseinbußen oder Genauigkeitsverluste ausgeführt werden. Genau diese Strategie haben wir gefunden, um die neuen Modelle zu unterstützen.
Das folgende Diagramm veranschaulicht den Workflow unter der Haube.
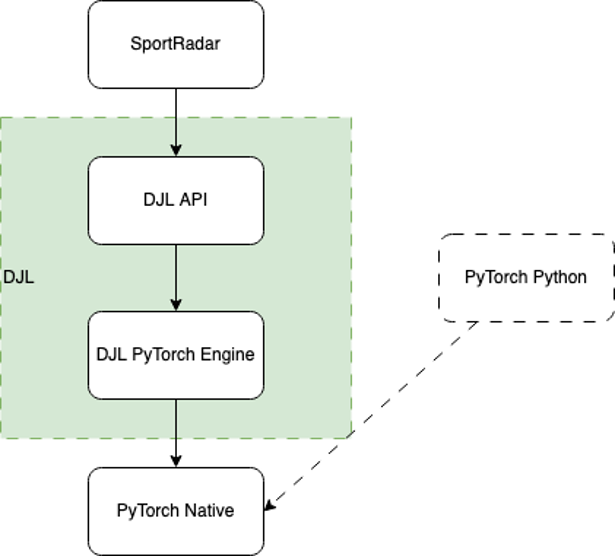
Wenn die DJL geladen wird, findet sie alle im Klassenpfad verfügbaren Engine-Implementierungen unter Verwendung von Java ServiceLoader. In diesem Fall erkennt es die DJL-PyTorch-Engine-Implementierung, die als Brücke zwischen der DJL-API und PyTorch Native fungiert.
Die Engine arbeitet dann daran, PyTorch Native zu laden. Standardmäßig lädt es die entsprechende native Binärdatei basierend auf Ihrem Betriebssystem, Ihrer CPU-Architektur und Ihrer CUDA-Version herunter, wodurch es fast mühelos zu verwenden ist. Sie können die Binärdatei auch mithilfe einer der vielen verfügbaren nativen JAR-Dateien bereitstellen, die für Produktionsumgebungen zuverlässiger sind, die aus Sicherheitsgründen häufig über eingeschränkten Netzwerkzugriff verfügen.
Nach dem Laden verwendet die DJL die Native Java-Schnittstelle alle einfachen High-Level-Funktionalitäten in DJL in die entsprechenden nativen Low-Level-Anrufe zu übersetzen. Jede Operation in der DJL-API wird von Hand erstellt, um den Java-Konventionen am besten zu entsprechen und sie leicht zugänglich zu machen. Dazu gehört auch der Umgang mit nativem Speicher, der vom Java Garbage Collector nicht unterstützt wird.
Obwohl alle diese Details in der Bibliothek enthalten sind, könnte der Aufruf aus Benutzersicht nicht einfacher sein. Im folgenden Abschnitt gehen wir durch diesen Prozess.
Wie Sportradar DJL implementiert hat
Da wir unsere Modelle mit PyTorch trainieren, verwenden wir die PyTorch-Engine von DJL für die Modellinferenz.
Das Laden des Modells ist unglaublich einfach. Es ist lediglich erforderlich, ein Kriterium zu erstellen, das das zu ladende Modell und dessen Herkunft beschreibt. Dann laden wir es und verwenden das Modell, um eine neue Prädiktorsitzung zu erstellen. Siehe folgenden Code:
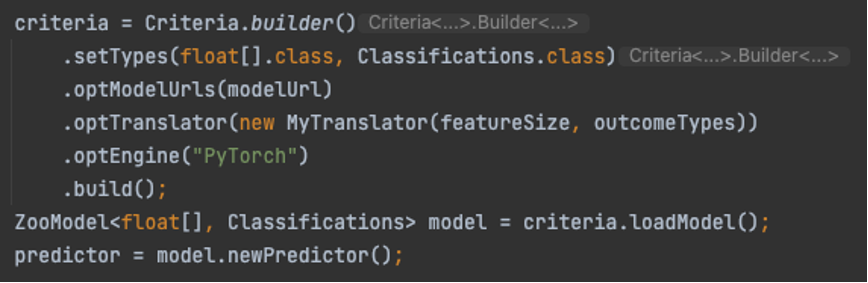
Für unser Modell haben wir auch einen benutzerdefinierten Übersetzer, den wir anrufen MyTranslator. Wir verwenden den Übersetzer, um den Vorverarbeitungscode zu kapseln, der von einem geeigneten Java-Typ in die vom Modell erwartete Eingabe konvertiert, und den Nachverarbeitungscode, der die Modellausgabe in eine geeignete Ausgabe konvertiert. In unserem Fall haben wir uns für a entschieden float[] als Eingabetyp und die eingebauten DJL-Klassifizierungen als Ausgabetyp. Das Folgende ist ein Ausschnitt unseres Übersetzercodes:

Es ist ziemlich erstaunlich, dass die DJL mit nur wenigen Codezeilen die PyTorch-Skripte und unseren benutzerdefinierten Übersetzer lädt und der Vorhersager dann bereit ist, die Vorhersagen zu treffen.
Zusammenfassung
Das auf der DJL-Lösung basierende Produkt von Sportradar wurde vor Beginn der regulären NFL-Saison 2022–23 live geschaltet und läuft seitdem reibungslos. Für die Zukunft plant Sportradar, bestehende Modelle, die auf gRPC-Servern gehostet werden, auf die DJL-Lösung umzurüsten.
Die DJL wächst in vielerlei Hinsicht weiter. Die neuste Veröffentlichung, v0.21.0, verfügt über viele Verbesserungen, darunter aktualisierte Engine-Unterstützung, Verbesserungen an Spark, Hugging Face-Batch-Tokenizer, ein NDScope für eine einfachere Speicherverwaltung und Verbesserungen an der Zeitreihen-API. Es hat auch die erste Hauptversion von DJL Null, eine neue API, die darauf abzielt, sowohl die Verwendung vortrainierter Modelle als auch das Training Ihrer eigenen benutzerdefinierten Deep-Learning-Modelle zu unterstützen, selbst wenn Sie keine Kenntnisse über Deep Learning haben.
Die DJL verfügt auch über einen Modellserver namens DJL serviert. Es macht es einfach, ein Modell auf einem HTTP-Server von einer der 10 unterstützten Engines zu hosten, einschließlich der Python-Engine zur Unterstützung von Python-Code. Mit v0.21.0 von DJL Serving enthält es eine schnellere Transformatorunterstützung, Amazon Sage Maker Endpunkt mit mehreren Modellen Support, Updates für Stable Diffusion, Verbesserungen für DeepSpeed und Updates für die Verwaltungskonsole. Sie können es jetzt verwenden Bereitstellen großer Modelle mit modellparalleler Inferenz mit DeepSpeed und SageMaker.
Auch beim DJL steht einiges an. Der größte Entwicklungsbereich ist die Unterstützung großer Sprachmodelle für Modelle wie ChatGPT oder Stable Diffusion. Es wird auch daran gearbeitet, Streaming-Inferenzanforderungen in DJL Serving zu unterstützen. Drittens gibt es Verbesserungen bei Demos und der Erweiterung für Spark. Natürlich gibt es auch standardmäßige fortlaufende Arbeit, einschließlich Funktionen, Fehlerbehebungen, Engine-Updates und mehr.
Weitere Informationen zum DJL und seinen anderen Funktionen finden Sie unter Tiefe Java-Bibliothek.
Folgen Sie unseren GitHub Repo, Demo-Repository, Schlafkanal und Twitter für mehr Dokumentation und Beispiele des DJL!
Über die Autoren
 Fred Wu ist Senior Data Engineer bei Sportradar, wo er Infrastruktur, DevOps und Data Engineering für verschiedene NBA- und NFL-Produkte leitet. Mit umfassender Erfahrung auf diesem Gebiet widmet sich Fred dem Aufbau robuster und effizienter Datenpipelines und -systeme zur Unterstützung modernster Sportanalysen.
Fred Wu ist Senior Data Engineer bei Sportradar, wo er Infrastruktur, DevOps und Data Engineering für verschiedene NBA- und NFL-Produkte leitet. Mit umfassender Erfahrung auf diesem Gebiet widmet sich Fred dem Aufbau robuster und effizienter Datenpipelines und -systeme zur Unterstützung modernster Sportanalysen.
 Zach Kimberg ist ein Softwareentwickler in der Amazon AI org. Er arbeitet daran, die Entwicklung, Schulung und Produktionsinferenz von Deep Learning zu ermöglichen. Dort half er bei der Gründung des DeepJavaLibrary-Projekts und entwickelt es weiter.
Zach Kimberg ist ein Softwareentwickler in der Amazon AI org. Er arbeitet daran, die Entwicklung, Schulung und Produktionsinferenz von Deep Learning zu ermöglichen. Dort half er bei der Gründung des DeepJavaLibrary-Projekts und entwickelt es weiter.
 Kanwaljit Khurmi ist Principal Solutions Architect bei Amazon Web Services. Er arbeitet mit den AWS-Kunden zusammen, um Anleitungen und technische Unterstützung bereitzustellen, die ihnen helfen, den Wert ihrer Lösungen bei der Verwendung von AWS zu verbessern. Kanwaljit ist darauf spezialisiert, Kunden mit containerisierten und maschinellen Lernanwendungen zu unterstützen.
Kanwaljit Khurmi ist Principal Solutions Architect bei Amazon Web Services. Er arbeitet mit den AWS-Kunden zusammen, um Anleitungen und technische Unterstützung bereitzustellen, die ihnen helfen, den Wert ihrer Lösungen bei der Verwendung von AWS zu verbessern. Kanwaljit ist darauf spezialisiert, Kunden mit containerisierten und maschinellen Lernanwendungen zu unterstützen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/how-sportradar-used-the-deep-java-library-to-build-production-scale-ml-platforms-for-increased-performance-and-efficiency/

