Data Lakes erfreuen sich zunehmender Beliebtheit, da sie große Datenmengen aus unterschiedlichen Quellen auf skalierbare und kostengünstige Weise speichern. Da die Zahl der Datenkonsumenten wächst, müssen Data-Lake-Administratoren häufig fein abgestimmte Zugriffskontrollen für verschiedene Benutzerprofile implementieren. Abhängig von der Art des Benutzers, der die Anfrage stellt, müssen sie möglicherweise den Zugriff auf bestimmte Tabellen oder Spalten einschränken. Außerdem möchten Unternehmen manchmal Daten für externe Anwendungen verfügbar machen, sind sich aber nicht sicher, wie sie dies sicher tun können. Um diese Herausforderungen zu bewältigen, können sich Unternehmen an GraphQL wenden AWS Lake-Formation.
GraphQL bietet eine leistungsstarke, sichere und flexible Möglichkeit zum Abfragen und Abrufen von Daten. AWS AppSync ist ein Dienst zum Erstellen von GraphQL-APIs, der mehrere Datenbanken, Microservices und APIs von einem einheitlichen GraphQL-Endpunkt aus abfragen kann.
Data Lake-Administratoren können Lake Formation verwenden, um den Zugriff auf Data Lakes zu steuern. Lake Formation bietet fein abgestimmte Zugriffskontrollen für die Verwaltung von Benutzer- und Gruppenberechtigungen auf Tabellen-, Spalten- und Zellenebene. Dadurch kann die Datensicherheit und Compliance gewährleistet werden. Darüber hinaus lässt sich diese Lake Formation in andere AWS-Dienste integrieren, z Amazonas Athena, was es ideal für die Abfrage von Data Lakes über APIs macht.
In diesem Beitrag zeigen wir, wie man eine Anwendung erstellt, die über eine GraphQL-API Daten aus einem Data Lake extrahieren und die Ergebnisse basierend auf ihren spezifischen Datenzugriffsrechten an verschiedene Benutzertypen liefern kann. Die in diesem Beitrag beschriebene Beispielanwendung wurde von AWS Partner erstellt NETSOL-Technologien.
Lösungsüberblick
Unsere Lösung verwendet Einfacher Amazon-Speicherdienst (Amazon S3) um die Daten zu speichern, AWS-Kleber Data Catalog zur Aufnahme des Datenschemas und Lake Formation zur Bereitstellung der Governance über die AWS Glue Data Catalog-Objekte durch Implementierung eines rollenbasierten Zugriffs. Wir benützen auch Amazon EventBridge um Ereignisse in unserem Datensee zu erfassen und nachgelagerte Prozesse zu starten. Die Lösungsarchitektur ist im folgenden Diagramm dargestellt.
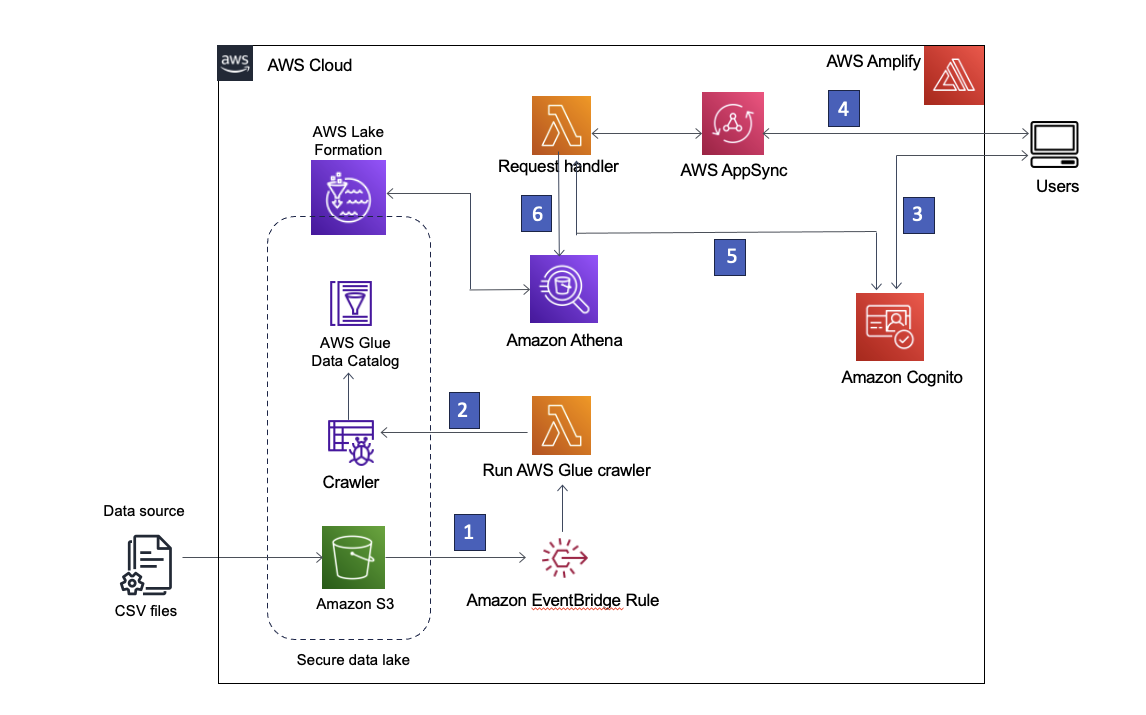
Abbildung 1 – Lösungsarchitektur
Nachfolgend finden Sie eine Schritt-für-Schritt-Beschreibung der Lösung:
- Der Data Lake wird in einem bei Lake Formation registrierten S3-Bucket erstellt. Immer wenn neue Daten eintreffen, wird eine EventBridge-Regel aufgerufen.
- Die EventBridge-Regel führt eine aus AWS Lambda Funktion zum Starten eines AWS Glue-Crawlers, um neue Daten zu erkennen und alle Schemaänderungen zu aktualisieren, damit die neuesten Daten abgefragt werden können.
Hinweis: AWS Glue-Crawler können auch direkt von Amazon S3-Ereignissen aus gestartet werden, wie hier beschrieben Blog-Post. - AWS verstärken ermöglicht es Benutzern, sich mit anzumelden Amazon Cognito als Identitätsanbieter. Cognito authentifiziert die Anmeldeinformationen des Benutzers und gibt Zugriffstokens zurück.
- Authentifizierte Benutzer rufen über Amplify eine AWS AppSync GraphQL-API auf und rufen Daten aus dem Data Lake ab. Zur Bearbeitung der Anfrage wird eine Lambda-Funktion ausgeführt.
- Die Lambda-Funktion ruft die Benutzerdetails von Cognito ab und übernimmt die AWS Identitäts- und Zugriffsverwaltung (IAM) Rolle, die der Cognito-Benutzergruppe des anfordernden Benutzers zugeordnet ist.
- Die Lambda-Funktion führt dann eine Athena-Abfrage für die Data Lake-Tabellen aus und gibt die Ergebnisse an AWS AppSync zurück, das die Ergebnisse dann an den Benutzer zurückgibt.
Voraussetzungen:
Um diese Lösung bereitzustellen, müssen Sie zunächst Folgendes tun:
Bereiten Sie die Genehmigungen für die Lake Formation vor
Melden Sie sich bei der an LakeFormation-Konsole und fügen Sie sich als Administrator hinzu. Wenn Sie sich zum ersten Mal bei Lake Formation anmelden, können Sie dies tun, indem Sie auf dem Bildschirm „Willkommen bei Lake Formation“ die Option „Ich selbst hinzufügen“ und dann „Erste Schritte“ auswählen, wie in Abbildung 2 dargestellt.

Abbildung 2 – Fügen Sie sich selbst als Lake Formation-Administrator hinzu
Andernfalls können Sie in der linken Navigationsleiste „Administrative Rollen und Aufgaben“ auswählen und dann „Administratoren verwalten“ auswählen, um sich selbst hinzuzufügen. Wenn Sie fertig sind, sollten Sie Ihren IAM-Benutzernamen unter Data Lake-Administratoren mit Vollzugriff sehen.
Wählen Sie in der linken Navigationsleiste Datenkatalogeinstellungen aus und stellen Sie sicher, dass die beiden IAM-Zugriffskontrollfelder nicht ausgewählt sind, wie in Abbildung 3 dargestellt. Sie möchten, dass Lake Formation und nicht IAM den Zugriff auf neue Datenbanken steuert.
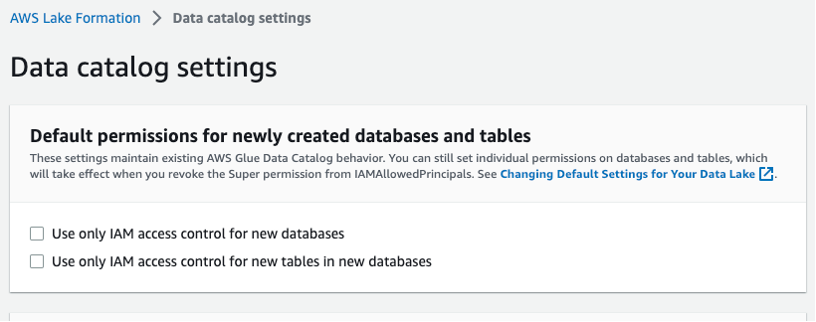
Abbildung 3 – Einstellungen des Lake Formation-Datenkatalogs
Stellen Sie die Lösung bereit
Um die Lösung in Ihrer AWS-Umgebung zu erstellen, starten Sie den folgenden AWS CloudFormation-Stack: ![]()
Die folgenden Ressourcen werden über die CloudFormation-Vorlage gestartet:
- Amazon VPC und Netzwerkkomponenten (Subnetze, Sicherheitsgruppen und NAT-Gateway)
- IAM-Rollen
- Lake Formation kapselt S3-Bucket, AWS Glue-Crawler und AWS Glue-Datenbank
- Lambda-Funktionen
- Cognito-Benutzerpool
- AWS AppSync GraphQL-API
- EventBridge-Regeln
Nachdem die erforderlichen Ressourcen aus dem CloudFormation-Stack bereitgestellt wurden, müssen Sie zwei Lambda-Funktionen erstellen und den Datensatz auf Amazon S3 hochladen. Lake Formation verwaltet den Data Lake, der im S3-Bucket gespeichert ist.
Erstellen Sie die Lambda-Funktionen
Immer wenn eine neue Datei im angegebenen S3-Bucket abgelegt wird, wird eine EventBridge-Regel aufgerufen, die eine Lambda-Funktion startet, um den AWS Glue-Crawler zu starten. Der Crawler aktualisiert den AWS Glue-Datenkatalog, um alle Änderungen am Schema widerzuspiegeln.
Wenn die Anwendung über die GraphQL-API eine Datenabfrage durchführt, wird eine Lambda-Funktion des Anforderungshandlers aufgerufen, um die Abfrage zu verarbeiten und die Ergebnisse zurückzugeben.
Um diese beiden Lambda-Funktionen zu erstellen, gehen Sie wie folgt vor.
- Melden Sie sich bei der Lambda-Konsole an.
- Wählen Sie die Lambda-Funktion des Anforderungshandlers mit dem Namen aus
dl-dev-crawlerLambdaFunction. - Suchen Sie die Crawler-Lambda-Funktionsdatei in Ihrem
lambdas/crawler-lambdaOrdner im Git-Repository, das Sie auf Ihren lokalen Computer geklont haben. - Kopieren Sie den Code aus dieser Datei und fügen Sie ihn in den Abschnitt „Code“ ein
dl-dev-crawlerLambdaFunctionin Ihrer Lambda-Konsole. Wählen Sie dann „Bereitstellen“, um die Funktion bereitzustellen.
Abbildung 4 – Code kopieren und in die Lambda-Funktion einfügen
- Wiederholen Sie die Schritte 2 bis 4 für die genannte Anforderungshandlerfunktion
dl-dev-requestHandlerLambdaFunctionmit dem Code inlambdas/request-handler-lambda.
Erstellen Sie eine Ebene für den Anforderungshandler Lambda
Sie müssen jetzt zusätzlichen Bibliothekscode hochladen, der für die Lambda-Funktion des Anforderungshandlers benötigt wird.
- Auswählen Schichten im linken Menü und wählen Sie Ebene erstellen.
- Geben Sie einen Namen ein, z
appsync-lambda-layer. - Herunteraden Sie diese ZIP-Datei der Paketschicht zu Ihrem lokalen Computer.
- Laden Sie die ZIP-Datei mit hoch Hochladen Taste auf der Ebene erstellen
- Auswählen Python 3.7 als Laufzeit für die Ebene.
- Auswählen Erstellen.
- Auswählen Funktionen im linken Menü und wählen Sie die aus
dl-dev-requestHandlerLambda-Funktion. - Scrollen Sie nach unten zum Schichten Abschnitt und wählen Sie Eine Ebene hinzufügen.
- Wähle aus Benutzerdefinierte Ebenen Option und wählen Sie dann die Ebene aus, die Sie oben erstellt haben.
- Klicken Sie auf Kostenlos erhalten und dann auf Installieren. Speichern.
Laden Sie die Daten auf Amazon S3 hoch
Navigieren Sie zum Stammverzeichnis des geklonten Git-Repositorys und führen Sie die folgenden Befehle aus, um den Beispieldatensatz hochzuladen. Ersetze das bucket_name Platzhalter mit dem S3-Bucket, der mithilfe der CloudFormation-Vorlage bereitgestellt wurde. Sie können den Bucket-Namen von der CloudFormation-Konsole abrufen, indem Sie zu gehen Ausgänge Tab mit Schlüssel datalakes3bucketName wie im Bild unten gezeigt.

Abbildung 5 – Der Name des S3-Buckets wird auf der Registerkarte „Ausgaben“ von CloudFormation angezeigt
Geben Sie die folgenden Befehle in Ihren Projektordner auf Ihrem lokalen Computer ein, um den Datensatz in den S3-Bucket hochzuladen.
Werfen wir nun einen Blick auf die bereitgestellten Artefakte.
Datensee
Der S3-Bucket enthält Beispieldaten für zwei Entitäten: Unternehmen und ihre jeweiligen Eigentümer. Der Bucket ist bei Lake Formation registriert, wie in Abbildung 6 dargestellt. Dadurch kann Lake Formation Datenkataloge erstellen und verwalten sowie Berechtigungen für die Daten verwalten.

Abbildung 6 – Lake Formation-Konsole, die den Standort des Datensees zeigt
Es wird eine Datenbank erstellt, die das Schema der in Amazon S3 vorhandenen Daten speichert. Ein AWS Glue-Crawler wird verwendet, um alle Änderungen im Schema im S3-Bucket zu aktualisieren. Diesem Crawler wird die Berechtigung zum Erstellen, Ändern und Löschen von Tabellen in der Datenbank mithilfe von Lake Formation erteilt.
Wenden Sie Zugriffskontrollen für den Data Lake an
Es werden zwei IAM-Rollen erstellt: dl-us-east-1-developer und dl-us-east-1-business-analyst, jeweils einer anderen Cognito-Benutzergruppe zugeordnet. Jeder Rolle werden über Lake Formation unterschiedliche Berechtigungen zugewiesen. Die Rolle „Entwickler“ erhält Zugriff auf jede Spalte im Data Lake, während die Rolle „Business Analyst“ nur Zugriff auf die Spalten mit nicht persönlich identifizierbaren Informationen (PII) erhält.
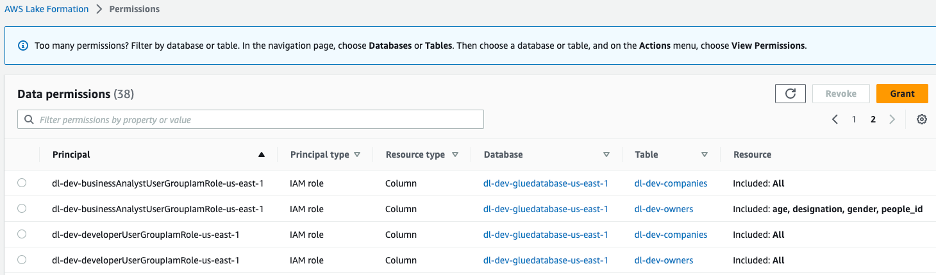
Abbildung 7 – Den Gruppenrollen zugewiesene Data Lake-Berechtigungen der Lake Formation-Konsole
GraphQL-Schema
Die GraphQL-API kann über die AWS AppSync-Konsole angezeigt werden. Der Companies Der Typ enthält mehrere Attribute, die die Eigentümer der Unternehmen beschreiben.
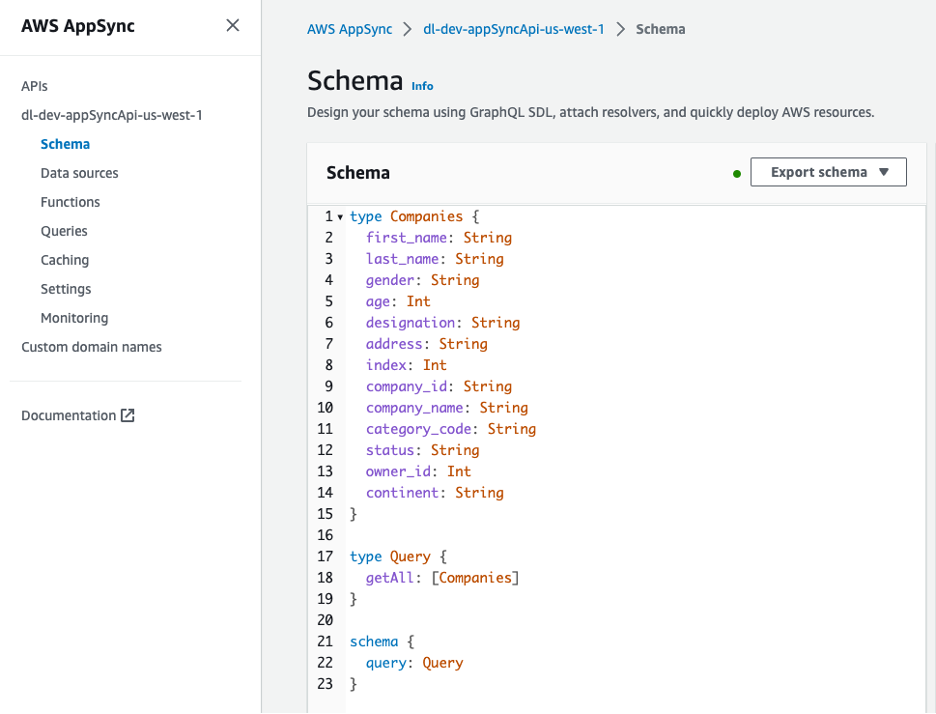
Abbildung 8 – Schema für die GraphQL-API
Die Datenquelle für die GraphQL-API ist eine Lambda-Funktion, die die Anfragen verarbeitet.
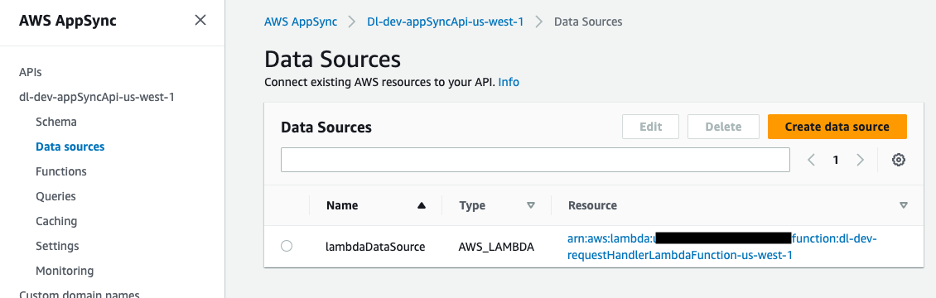
Abbildung 9 – AWS AppSync-Datenquelle, zugeordnet zur Lambda-Funktion
Bearbeitung der GraphQL-API-Anfragen
Die Lambda-Funktion des GraphQL-API-Anforderungshandlers ruft die Cognito-Benutzerpool-ID aus den Umgebungsvariablen ab. Mit der boto3-Bibliothek erstellen Sie einen Cognito-Client und verwenden den get_group Methode zum Abrufen der IAM-Rolle, die der Cognito-Benutzergruppe zugeordnet ist.
Sie verwenden eine Hilfsfunktion in der Lambda-Funktion, um die Rolle abzurufen.
Verwendung der AWS Security Token Service (AWS STS) Über einen boto3-Client können Sie die IAM-Rolle übernehmen und die temporären Anmeldeinformationen erhalten, die Sie zum Ausführen der Athena-Abfrage benötigen.
Wir übergeben die temporären Anmeldeinformationen als Parameter beim Erstellen unseres Boto3 Amazon Athena-Clients.
athena_client = boto3.client('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)Der Client und die Abfrage werden an unsere Athena-Abfragehilfsfunktion übergeben, die die Abfrage ausführt und eine Abfrage-ID zurückgibt. Mit der Abfrage-ID können wir die Ergebnisse aus S3 lesen und als Python-Wörterbuch bündeln, um es in der Antwort zurückzugeben.
Ermöglichen des clientseitigen Zugriffs auf den Data Lake
Auf der Clientseite ist AWS Amplify mit einem Amazon Cognito-Benutzerpool zur Authentifizierung konfiguriert. Wir navigieren zur Amazon Cognito-Konsole, um den Benutzerpool und die erstellten Gruppen anzuzeigen.
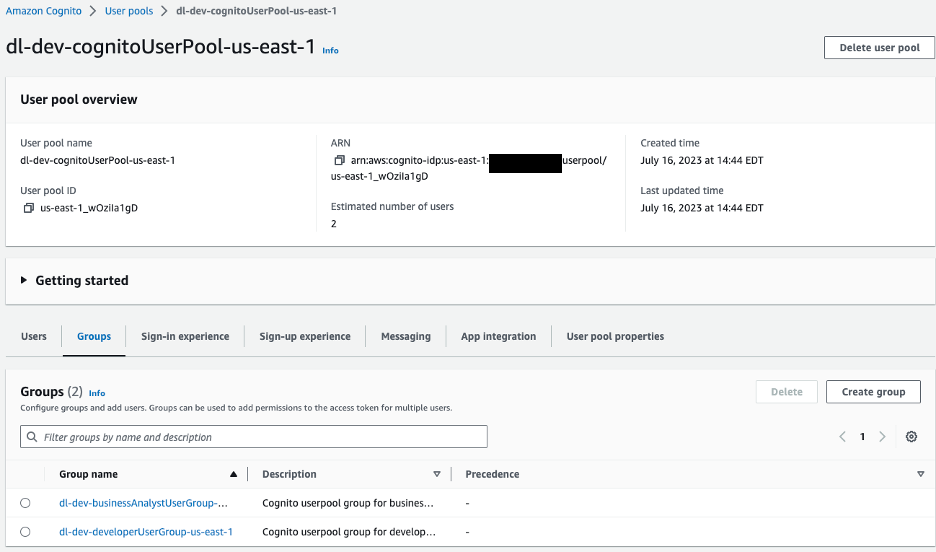
Abbildung 10 – Amazon Cognito-Benutzerpools
Für unsere Beispielanwendung haben wir zwei Gruppen in unserem Benutzerpool:
dl-dev-businessAnalystUserGroup– Business-Analysten mit eingeschränkten Berechtigungen.dl-dev-developerUserGroup– Entwickler mit vollständigen Berechtigungen.
Wenn Sie diese Gruppen erkunden, werden Sie sehen, dass jeder Gruppe eine IAM-Rolle zugeordnet ist. Dies ist die IAM-Rolle, die dem Benutzer bei der Authentifizierung zugewiesen wird. Athena übernimmt diese Rolle bei der Abfrage des Data Lake.
Wenn Sie sich die Berechtigungen für diese IAM-Rolle ansehen, werden Sie feststellen, dass sie keine Zugriffskontrollen unterhalb der Tabellenebene enthält. Sie benötigen die zusätzliche Governance-Ebene von Lake Formation, um eine differenzierte Zugriffskontrolle hinzuzufügen.
Nachdem der Benutzer von Cognito verifiziert und authentifiziert wurde, verwendet Amplify Zugriffstoken, um die AWS AppSync GraphQL-API aufzurufen und die Daten abzurufen. Basierend auf der Gruppe des Benutzers übernimmt eine Lambda-Funktion die entsprechende Cognito-Benutzergruppenrolle. Unter Verwendung der angenommenen Rolle wird eine Athena-Abfrage ausgeführt und das Ergebnis an den Benutzer zurückgegeben.
Erstellen Sie Testbenutzer
Erstellen Sie zwei Benutzer, einen für Entwickler und einen für Geschäftsanalysten, und fügen Sie sie zu Benutzergruppen hinzu.
- Navigieren Sie zu Cognito und wählen Sie den Benutzerpool aus.
dl-dev-cognitoUserPool, das ist geschaffen. - Auswählen Benutzer erstellen und geben Sie die Details an, um einen neuen Business-Analyst-Benutzer zu erstellen. Der Benutzername kann sein Biz-Analyst. Lassen Sie die E-Mail-Adresse leer und geben Sie ein Passwort ein.
- Wähle aus Nutzer Klicken Sie auf die Registerkarte und wählen Sie den Benutzer aus, den Sie gerade erstellt haben.
- Fügen Sie diesen Benutzer zur Geschäftsanalystengruppe hinzu, indem Sie Folgendes auswählen Benutzer zur Gruppe hinzufügen .
- Befolgen Sie die gleichen Schritte, um einen weiteren Benutzer mit dem Benutzernamen zu erstellen Entwickler und fügen Sie den Benutzer zur Entwicklergruppe hinzu.
Testen Sie die Lösung
Um Ihre Lösung zu testen, starten Sie die React-Anwendung auf Ihrem lokalen Computer.
- Navigieren Sie im geklonten Projektverzeichnis zu
react-appVerzeichnis. - Installieren Sie die Projektabhängigkeiten.
- Installieren Sie die Amplify-CLI:
- Erstellen Sie eine neue Datei mit dem Namen
.envindem Sie die folgenden Befehle ausführen. Verwenden Sie dann einen Texteditor, um die Umgebungsvariablenwerte in der Datei zu aktualisieren.
Verwenden Sie das Ausgänge Klicken Sie auf die Registerkarte Ihres CloudFormation-Konsolenstapels, um die erforderlichen Werte aus den Schlüsseln wie folgt abzurufen:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- Fügen Sie die oben genannten Variablen zu Ihrer Umgebung hinzu.
- Generieren Sie den Code, der für die Interaktion mit der API erforderlich ist CodeGen verstärken. Suchen Sie auf der Registerkarte „Ausgaben“ Ihrer Cloudformation-Konsole neben Ihrer AWS Appsync-API-ID
appsyncApiIdKey.
Akzeptieren Sie alle Standardoptionen für den obigen Befehl, indem Sie drücken Enter bei jeder Eingabeaufforderung.
- Starten Sie die Anwendung.
Sie können bestätigen, dass die Anwendung ausgeführt wird, indem Sie auf klicken http://localhost:3000 und melden Sie sich als der Entwicklerbenutzer an, den Sie zuvor erstellt haben.
Nachdem Sie nun die Anwendung ausgeführt haben, werfen wir einen Blick darauf, wie jede Rolle von der bedient wird companies Endpunkt.
Zunächst müssen Sie sich als Entwicklerrolle anmelden, die Zugriff auf alle Felder hat, und die API-Anfrage an den Endpunkt des Unternehmens stellen. Beachten Sie, auf welche Felder Sie Zugriff haben.
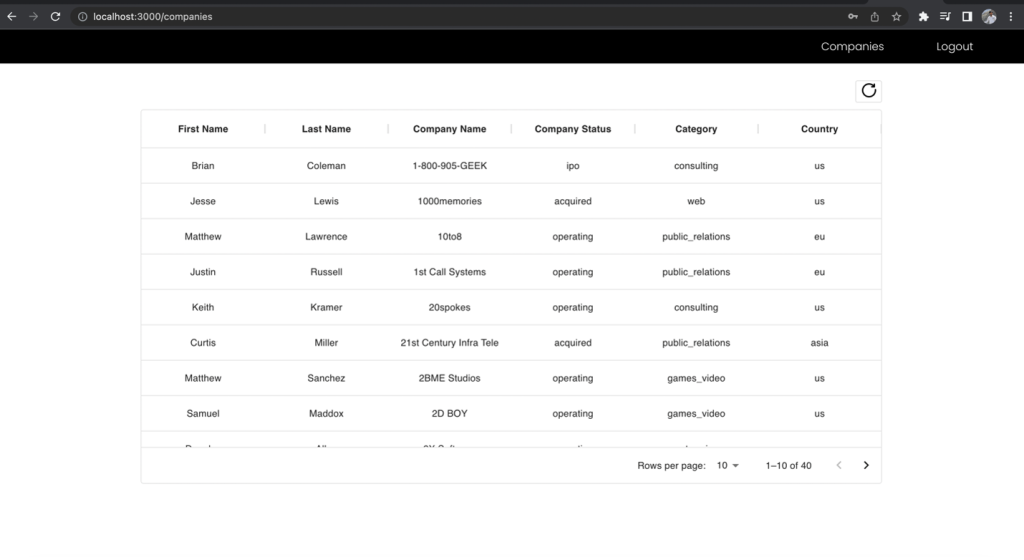
Abbildung 11 – Die Ergebnisse für die Entwicklerrolle
Melden Sie sich nun als Business-Analyst-Benutzer an, stellen Sie die Anfrage an denselben Endpunkt und vergleichen Sie die enthaltenen Felder.
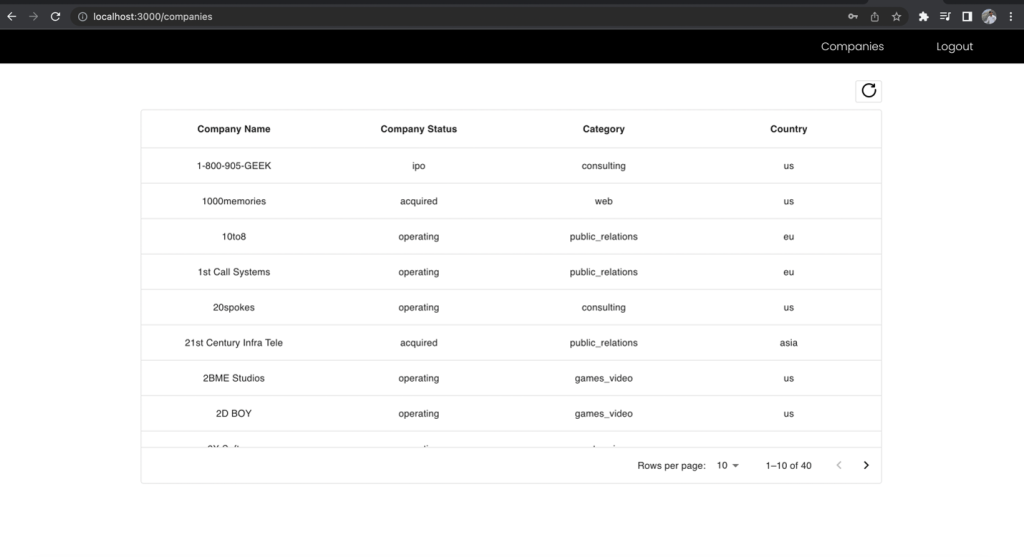
Abbildung 12 – Die Ergebnisse für die Rolle „Business Analyst“.
Die Spalten „Vorname“ und „Nachname“ der Firmenliste werden in der Business-Analyst-Ansicht ausgeschlossen, obwohl Sie die Anfrage an denselben Endpunkt gestellt haben. Dies zeigt die Leistungsfähigkeit der Verwendung eines einheitlichen GraphQL-Endpunkts zusammen mit mehreren Cognito-Benutzergruppen-IAM-Rollen, die Lake Formation-Berechtigungen zugeordnet sind, um den rollenbasierten Zugriff auf Ihre Daten zu verwalten.
Aufräumen
Nachdem Sie die Lösung getestet haben, bereinigen Sie die folgenden Ressourcen, um künftige Kosten zu vermeiden:
- Leeren Sie die von der CloudFormation-Vorlage erstellten S3-Buckets.
- Löschen Sie den CloudFormation-Stack, um die S3-Buckets und andere Ressourcen zu entfernen.
Zusammenfassung
In diesem Beitrag haben wir Ihnen gezeigt, wie Sie authentifizierten Benutzern einer React-Anwendung basierend auf ihren rollenbasierten Zugriffsrechten Daten in einem Data Lake sicher bereitstellen können. Um dies zu erreichen, haben Sie GraphQL-APIs in AWS AppSync, fein abgestimmte Zugriffskontrollen von Lake Formation und Cognito zur Authentifizierung von Benutzern nach Gruppen und deren Zuordnung zu IAM-Rollen verwendet. Sie haben Athena auch zum Abfragen der Daten verwendet.
Weitere Informationen zu diesem Thema finden Sie unter Visualisierung großer Datenmengen mit AWS AppSync, Amazon Athena und AWS Amplify und Entwerfen Sie eine Data-Mesh-Architektur mit AWS Lake Formation und AWS Glue.
Werden Sie diesen Ansatz für die Bereitstellung von Daten aus Ihrem Data Lake implementieren? Lass es uns in den Kommentaren wissen!
Über die Autoren
 Rana Dutt ist Principal Solutions Architect bei Amazon Web Services. Er verfügt über Erfahrung in der Entwicklung skalierbarer Softwareplattformen für Finanzdienstleistungs-, Gesundheits- und Telekommunikationsunternehmen und ist begeistert davon, Kunden beim Aufbau auf AWS zu unterstützen.
Rana Dutt ist Principal Solutions Architect bei Amazon Web Services. Er verfügt über Erfahrung in der Entwicklung skalierbarer Softwareplattformen für Finanzdienstleistungs-, Gesundheits- und Telekommunikationsunternehmen und ist begeistert davon, Kunden beim Aufbau auf AWS zu unterstützen.
 Ranjith Rayaprolu ist Senior Solutions Architect bei AWS und arbeitet mit Kunden im pazifischen Nordwesten. Er unterstützt Kunden bei der Entwicklung und dem Betrieb von Well-Architected-Lösungen in AWS, die ihre Geschäftsprobleme lösen und die Einführung von AWS-Services beschleunigen. Er konzentriert sich auf AWS-Sicherheits- und Netzwerktechnologien, um Lösungen in der Cloud für verschiedene Branchen zu entwickeln. Ranjith lebt in der Gegend von Seattle und liebt Outdoor-Aktivitäten.
Ranjith Rayaprolu ist Senior Solutions Architect bei AWS und arbeitet mit Kunden im pazifischen Nordwesten. Er unterstützt Kunden bei der Entwicklung und dem Betrieb von Well-Architected-Lösungen in AWS, die ihre Geschäftsprobleme lösen und die Einführung von AWS-Services beschleunigen. Er konzentriert sich auf AWS-Sicherheits- und Netzwerktechnologien, um Lösungen in der Cloud für verschiedene Branchen zu entwickeln. Ranjith lebt in der Gegend von Seattle und liebt Outdoor-Aktivitäten.
 Justin Leto ist Senior Solutions Architect bei Amazon Web Services mit Spezialisierung auf Datenbanken, Big-Data-Analysen und maschinelles Lernen. Seine Leidenschaft besteht darin, Kunden dabei zu helfen, eine bessere Cloud-Einführung zu erreichen. In seiner Freizeit segelt er gerne auf hoher See und spielt Jazzklavier. Er lebt mit seiner Frau und seiner kleinen Tochter in New York City.
Justin Leto ist Senior Solutions Architect bei Amazon Web Services mit Spezialisierung auf Datenbanken, Big-Data-Analysen und maschinelles Lernen. Seine Leidenschaft besteht darin, Kunden dabei zu helfen, eine bessere Cloud-Einführung zu erreichen. In seiner Freizeit segelt er gerne auf hoher See und spielt Jazzklavier. Er lebt mit seiner Frau und seiner kleinen Tochter in New York City.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/using-aws-appsync-and-aws-lake-formation-to-access-a-secure-data-lake-through-a-graphql-api/

