Generative Sprachmodelle haben sich bei der Lösung logischer und analytischer NLP-Aufgaben (Natural Language Processing) als äußerst geschickt erwiesen. Darüber hinaus ist die Verwendung von schnelles Engineering können ihre Leistung deutlich steigern. Zum Beispiel, Gedankenkette (CoT) verbessert bekanntermaßen die Kapazität eines Modells für komplexe mehrstufige Probleme. Um die Genauigkeit bei Aufgaben, die logisches Denken erfordern, zusätzlich zu erhöhen, a Selbstkonsistenz Es wurde ein Prompting-Ansatz vorgeschlagen, der die gierige Dekodierung durch eine stochastische Dekodierung während der Sprachgenerierung ersetzt.
Amazonas Grundgestein ist ein vollständig verwalteter Dienst, der über eine einzige API eine Auswahl leistungsstarker Basismodelle von führenden KI-Unternehmen und Amazon sowie eine breite Palette an Aufbaufunktionen bietet generative KI Anwendungen mit Sicherheit, Datenschutz und verantwortungsvoller KI. Mit dem Batch-Inferenz API können Sie Amazon Bedrock verwenden, um stapelweise Inferenzen mit Fundamentmodellen auszuführen und Antworten effizienter zu erhalten. In diesem Beitrag wird gezeigt, wie Sie Selbstkonsistenz-Prompts über Batch-Inferenz auf Amazon Bedrock implementieren, um die Modellleistung bei Rechen- und Multiple-Choice-Argumentationsaufgaben zu verbessern.
Lösungsübersicht
Die Eingabeaufforderung zur Selbstkonsistenz von Sprachmodellen beruht auf der Generierung mehrerer Antworten, die zu einer endgültigen Antwort zusammengefasst werden. Im Gegensatz zu Single-Generation-Ansätzen wie CoT erstellt das Self-Consistency Sample-and-Marginalize-Verfahren eine Reihe von Modellvervollständigungen, die zu einer konsistenteren Lösung führen. Die Generierung unterschiedlicher Antworten für eine bestimmte Eingabeaufforderung ist aufgrund der Verwendung einer stochastischen und nicht einer gierigen Decodierungsstrategie möglich.
Die folgende Abbildung zeigt, wie sich Selbstkonsistenz von Greedy CoT dadurch unterscheidet, dass sie verschiedene Argumentationspfade generiert und diese aggregiert, um die endgültige Antwort zu erhalten.

Dekodierungsstrategien zur Textgenerierung
Von Nur-Decoder-Sprachmodellen generierter Text entfaltet sich Wort für Wort, wobei das nachfolgende Token auf der Grundlage des vorherigen Kontexts vorhergesagt wird. Für eine bestimmte Eingabeaufforderung berechnet das Modell eine Wahrscheinlichkeitsverteilung, die die Wahrscheinlichkeit angibt, mit der jedes Token als nächstes in der Sequenz erscheint. Beim Dekodieren werden diese Wahrscheinlichkeitsverteilungen in tatsächlichen Text übersetzt. Die Textgenerierung wird durch eine Reihe von vermittelt Inferenzparameter Dabei handelt es sich häufig um Hyperparameter der Decodierungsmethode selbst. Ein Beispiel ist das Temperatur, die die Wahrscheinlichkeitsverteilung des nächsten Tokens moduliert und die Zufälligkeit der Modellausgabe beeinflusst.
Gierige Dekodierung ist eine deterministische Decodierungsstrategie, die bei jedem Schritt das Token mit der höchsten Wahrscheinlichkeit auswählt. Obwohl dieser Ansatz unkompliziert und effizient ist, besteht die Gefahr, dass er in sich wiederholende Muster verfällt, da er den breiteren Wahrscheinlichkeitsraum außer Acht lässt. Das Setzen des Temperaturparameters auf 0 zum Inferenzzeitpunkt entspricht im Wesentlichen der Implementierung einer gierigen Decodierung.
Probennahme führt Stochastizität in den Dekodierungsprozess ein, indem jedes nachfolgende Token basierend auf der vorhergesagten Wahrscheinlichkeitsverteilung zufällig ausgewählt wird. Diese Zufälligkeit führt zu einer größeren Ausgabevariabilität. Die stochastische Dekodierung erweist sich als geschickter bei der Erfassung der Vielfalt potenzieller Ergebnisse und führt häufig zu einfallsreicheren Antworten. Höhere Temperaturwerte führen zu mehr Schwankungen und erhöhen die Kreativität der Modellreaktion.
Aufforderungstechniken: CoT und Selbstkonsistenz
Die Argumentationsfähigkeit von Sprachmodellen kann durch Prompt Engineering verbessert werden. Insbesondere CoT hat sich als wirksam erwiesen Argumentation hervorrufen bei komplexen NLP-Aufgaben. Eine Möglichkeit, a zu implementieren Nullschuss CoT erfolgt durch eine zeitnahe Erweiterung mit der Anweisung „Schritt für Schritt zu denken“. Eine andere besteht darin, das Modell Beispielen für Zwischenschritte im Denken auszusetzen Wenig-Schuss-Eingabeaufforderung Mode. In beiden Szenarien wird typischerweise eine gierige Dekodierung verwendet. CoT führt zu erheblichen Leistungssteigerungen im Vergleich zu einfachen Anweisungen zur Eingabeaufforderung bei Rechen-, Vernunft- und symbolischen Denkaufgaben.
Aufforderung zur Selbstkonsistenz basiert auf der Annahme, dass die Einführung von Diversität im Argumentationsprozess von Vorteil sein kann, um den Modellen dabei zu helfen, sich auf die richtige Antwort zu konvergieren. Die Technik nutzt stochastische Dekodierung, um dieses Ziel in drei Schritten zu erreichen:
- Fordern Sie das Sprachmodell mit CoT-Beispielen auf, um Argumente hervorzurufen.
- Ersetzen Sie die gierige Dekodierung durch eine Sampling-Strategie, um vielfältige Argumentationspfade zu generieren.
- Fassen Sie die Ergebnisse zusammen, um die konsistenteste Antwort im Antwortsatz zu finden.
Es hat sich gezeigt, dass die Selbstkonsistenz die CoT-Eingabeaufforderung bei gängigen Benchmarks für Arithmetik und logisches Denken übertrifft. Eine Einschränkung des Ansatzes ist der höhere Rechenaufwand.
Dieser Beitrag zeigt, wie Selbstkonsistenz-Prompting die Leistung generativer Sprachmodelle bei zwei NLP-Argumentationsaufgaben verbessert: arithmetisches Problemlösen und domänenspezifische Multiple-Choice-Fragenbeantwortung. Wir demonstrieren den Ansatz mithilfe der Batch-Inferenz auf Amazon Bedrock:
- Wir greifen auf das Amazon Bedrock Python SDK in JupyterLab zu Amazon Sage Maker Notebook-Instanz.
- Zum arithmetischen Denken fordern wir auf Cohere-Kommando zum GSM8K-Datensatz von Grundschul-Matheaufgaben.
- Für Multiple-Choice-Argumentation bitten wir Sie AI21 Labs Jurassic-2 Mid zu einer kleinen Auswahl von Fragen aus der AWS Certified Solutions Architect – Associate-Prüfung.
Voraussetzungen:
Diese exemplarische Vorgehensweise setzt die folgenden Voraussetzungen voraus:

Die geschätzten Kosten für die Ausführung des in diesem Beitrag gezeigten Codes betragen 100 US-Dollar, vorausgesetzt, Sie führen die Selbstkonsistenz-Eingabeaufforderung einmal mit 30 Argumentationspfaden unter Verwendung eines Werts für die temperaturbasierte Stichprobe aus.
Datensatz zur Untersuchung der Fähigkeiten zum arithmetischen Denken
GSM8K ist ein Datensatz von von Menschen zusammengestellten Grundschul-Matheaufgaben mit einer hohen sprachlichen Vielfalt. Die Lösung jedes Problems erfordert 2–8 Schritte und erfordert die Durchführung einer Folge elementarer Berechnungen mit grundlegenden arithmetischen Operationen. Diese Daten werden häufig verwendet, um die Fähigkeiten generativer Sprachmodelle zum mehrstufigen arithmetischen Denken zu bewerten. Der GSM8K-Zugset umfasst 7,473 Datensätze. Das Folgende ist ein Beispiel:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Einrichten, um Batch-Inferenz mit Amazon Bedrock auszuführen
Mit der Batch-Inferenz können Sie mehrere Inferenzaufrufe an Amazon Bedrock asynchron ausführen und die Leistung der Modellinferenz bei großen Datensätzen verbessern. Der Dienst befindet sich zum jetzigen Zeitpunkt in der Vorschau und ist nur über die API verfügbar. Beziehen auf Batch-Inferenz ausführen um über benutzerdefinierte SDKs auf Batch-Inferenz-APIs zuzugreifen.
Nachdem Sie die Datei heruntergeladen und entpackt haben Python-SDK In einer SageMaker-Notebook-Instanz können Sie es installieren, indem Sie den folgenden Code in einer Jupyter-Notebook-Zelle ausführen:
Eingabedaten formatieren und in Amazon S3 hochladen
Eingabedaten für die Batch-Inferenz müssen im JSONL-Format mit vorbereitet werden recordId und modelInput Schlüssel. Letzteres sollte mit dem Body-Feld des Modells übereinstimmen, das auf Amazon Bedrock aufgerufen werden soll. Insbesondere einige Unterstützte Inferenzparameter für Cohere Command sind temperature für Zufälligkeit, max_tokens für die Ausgabelänge und num_generations um mehrere Antworten zu generieren, die alle zusammen mit dem übergeben werden prompt as modelInput:
See Inferenzparameter für Fundamentmodelle Weitere Informationen finden Sie auch bei anderen Modellanbietern.
Unsere Experimente zum arithmetischen Denken werden in der Wenig-Schuss-Einstellung durchgeführt, ohne dass Cohere Command angepasst oder verfeinert werden muss. Wir verwenden denselben Satz von acht Exemplaren mit wenigen Schüssen aus der Gedankenkette (Tabelle 20) und Selbstkonsistenz (Tabelle 17) Papiere. Eingabeaufforderungen werden durch Verketten der Beispiele mit jeder Frage aus dem GSM8K-Zugsatz erstellt.
Legen wir fest max_tokens zu 512 und num_generations auf 5, das von Cohere Command zugelassene Maximum. Für gierige Dekodierung setzen wir temperature auf 0 und aus Gründen der Selbstkonsistenz führen wir drei Experimente bei den Temperaturen 0.5, 0.7 und 1 durch. Jede Einstellung liefert unterschiedliche Eingabedaten entsprechend den jeweiligen Temperaturwerten. Die Daten werden als JSONL formatiert und in Amazon S3 gespeichert.
Erstellen und führen Sie Batch-Inferenzjobs in Amazon Bedrock aus
Für die Erstellung von Batch-Inferenzaufträgen ist ein Amazon Bedrock-Client erforderlich. Wir geben die S3-Eingabe- und Ausgabepfade an und geben jedem Aufrufjob einen eindeutigen Namen:
Jobs sind erstellt indem Sie die IAM-Rolle, die Modell-ID, den Jobnamen und die Eingabe-/Ausgabekonfiguration als Parameter an die Amazon Bedrock-API übergeben:
Auflistung, Überwachung und Einstellung Batch-Inferenzjobs werden durch ihre jeweiligen API-Aufrufe unterstützt. Bei der Erstellung erscheinen Jobs zuerst als Submitted, dann als InProgress, und schließlich als Stopped, Failed, oder Completed.
Wenn die Aufträge erfolgreich abgeschlossen werden, können die generierten Inhalte über ihren eindeutigen Ausgabespeicherort von Amazon S3 abgerufen werden.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
Selbstkonsistenz verbessert die Modellgenauigkeit bei Rechenaufgaben
Die Selbstkonsistenzaufforderung von Cohere Command übertrifft eine gierige CoT-Basislinie in Bezug auf die Genauigkeit des GSM8K-Datensatzes. Aus Gründen der Selbstkonsistenz testen wir 30 unabhängige Argumentationspfade bei drei verschiedenen Temperaturen mit topP und topK auf ihre eingestellt Standardwerte. Endgültige Lösungen werden aggregiert, indem mittels Mehrheitsabstimmung das konsistenteste Vorkommen ausgewählt wird. Bei Stimmengleichheit wählen wir zufällig eine der Mehrheitsantworten aus. Wir berechnen die Genauigkeits- und Standardabweichungswerte gemittelt über 100 Läufe.
Die folgende Abbildung zeigt die Genauigkeit des GSM8K-Datensatzes von Cohere Command mit Eingabeaufforderung mit Greedy CoT (blau) und Selbstkonsistenz bei Temperaturwerten von 0.5 (gelb), 0.7 (grün) und 1.0 (orange) als Funktion der Anzahl der Proben Argumentationswege.
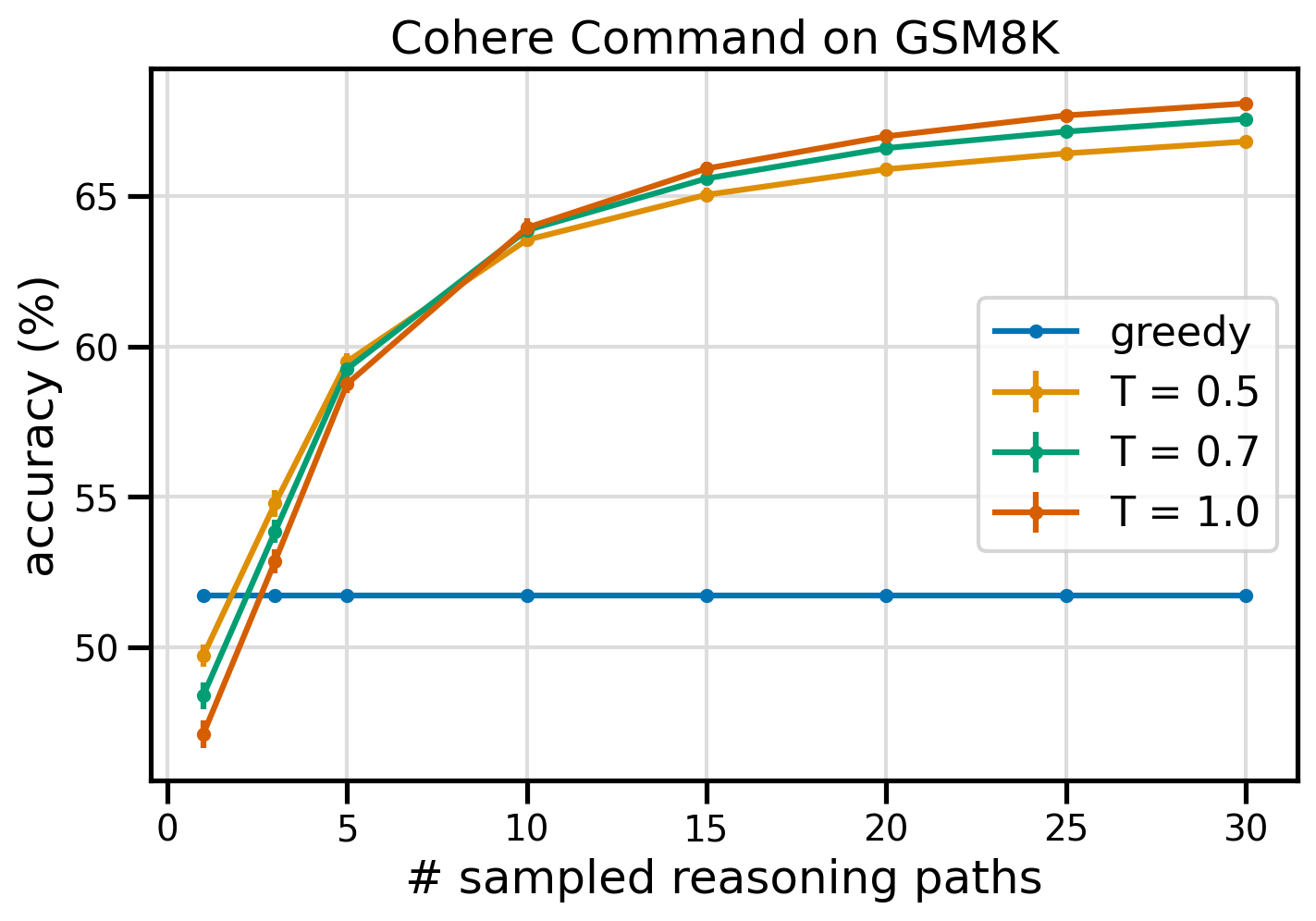
Die vorherige Abbildung zeigt, dass Selbstkonsistenz die arithmetische Genauigkeit gegenüber gierigem CoT verbessert, wenn die Anzahl der abgetasteten Pfade nur drei beträgt. Die Leistung nimmt mit weiteren Argumentationspfaden stetig zu, was die Bedeutung der Einführung von Diversität in die Gedankengenerierung bestätigt. Cohere Command löst den GSM8K-Fragensatz mit einer Genauigkeit von 51.7 %, wenn er mit CoT aufgefordert wird, im Vergleich zu 68 % mit 30 selbstkonsistenten Argumentationspfaden bei T=1.0. Alle drei untersuchten Temperaturwerte liefern ähnliche Ergebnisse, wobei niedrigere Temperaturen auf weniger abgetasteten Pfaden vergleichsweise leistungsfähiger sind.
Praktische Überlegungen zu Effizienz und Kosten
Die Selbstkonsistenz wird durch die erhöhte Reaktionszeit und die Kosten eingeschränkt, die bei der Generierung mehrerer Ausgaben pro Eingabeaufforderung entstehen. Zur praktischen Veranschaulichung: Die Batch-Inferenz für gierige Generierung mit Cohere Command für 7,473 GSM8K-Datensätze war in weniger als 20 Minuten abgeschlossen. Der Job benötigte 5.5 Millionen Token als Eingabe und generierte 630,000 Ausgabe-Token. Derzeit Amazon Bedrock-InferenzpreiseDie Gesamtkosten beliefen sich auf rund 9.50 US-Dollar.
Für die Selbstkonsistenz mit Cohere Command verwenden wir Inferenzparameter num_generations um mehrere Vervollständigungen pro Eingabeaufforderung zu erstellen. Zum jetzigen Zeitpunkt erlaubt Amazon Bedrock maximal fünf Generationen und drei gleichzeitige Submitted Batch-Inferenzjobs. Jobs fahren mit dem fort InProgress Status nacheinander, daher erfordert das Abtasten von mehr als fünf Pfaden mehrere Aufrufe.
Die folgende Abbildung zeigt die Laufzeiten für Cohere Command im GSM8K-Datensatz. Die Gesamtlaufzeit wird auf der x-Achse und die Laufzeit pro abgetastetem Argumentationspfad auf der y-Achse angezeigt. Die gierige Generierung läuft in kürzester Zeit ab, verursacht jedoch einen höheren Zeitaufwand pro abgetastetem Pfad.

Die Greedy-Generierung ist für den gesamten GSM20K-Satz in weniger als 8 Minuten abgeschlossen und erprobt einen einzigartigen Argumentationspfad. Die Selbstkonsistenz mit fünf Beispielen dauert etwa 50 % länger und kostet etwa 14.50 $, erzeugt in dieser Zeit jedoch fünf Pfade (über 500 %). Die Gesamtlaufzeit und die Kosten erhöhen sich schrittweise mit jeweils fünf weiteren abgetasteten Pfaden. Eine Kosten-Nutzen-Analyse legt nahe, dass 1–2 Batch-Inferenzjobs mit 5–10 abgetasteten Pfaden die empfohlene Einstellung für die praktische Umsetzung der Selbstkonsistenz sind. Dadurch wird eine verbesserte Modellleistung erreicht und gleichzeitig Kosten und Latenz in Schach gehalten.
Selbstkonsistenz verbessert die Modellleistung über das arithmetische Denken hinaus
Eine entscheidende Frage zum Nachweis der Eignung des Selbstkonsistenz-Promptings ist, ob die Methode über weitere NLP-Aufgaben und Sprachmodelle hinweg erfolgreich ist. Als Erweiterung zu einem Amazon-bezogenen Anwendungsfall führen wir eine kleine Analyse anhand von Beispielfragen aus dem durch AWS Solutions Architect Associate-Zertifizierung. Hierbei handelt es sich um eine Multiple-Choice-Prüfung zu AWS-Technologie und -Diensten, die Domänenkenntnisse und die Fähigkeit erfordert, über mehrere Optionen nachzudenken und zwischen ihnen zu entscheiden.
Wir bereiten einen Datensatz vor SAA-CO01 und SAA-CO03 Beispielprüfungsfragen. Von den 20 verfügbaren Fragen verwenden wir die ersten 4 als Beispiele für wenige Stichproben und veranlassen das Modell, die restlichen 16 zu beantworten. Dieses Mal führen wir eine Inferenz mit dem Jurassic-21 Mid-Modell von AI2 Labs durch und generieren maximal 10 Argumentationspfade Temperatur 0.7. Die Ergebnisse zeigen, dass Selbstkonsistenz die Leistung steigert: Obwohl der gierige CoT 11 richtige Antworten liefert, ist Selbstkonsistenz bei zwei weiteren erfolgreich.
Die folgende Tabelle zeigt die Genauigkeitsergebnisse für 5 und 10 abgetastete Pfade, gemittelt über 100 Durchläufe.
| . | Gierige Dekodierung | T = 0.7 |
| # abgetastete Pfade: 5 | 68.6 | 74.1 ± 0.7 |
| # abgetastete Pfade: 10 | 68.6 | 78.9 ± 0.3 |
In der folgenden Tabelle stellen wir zwei Prüfungsfragen vor, die von Greedy CoT falsch beantwortet werden, während die Selbstkonsistenz gelingt, und heben jeweils die richtigen (grün) oder falschen (rot) Argumentationsspuren hervor, die dazu geführt haben, dass das Modell richtige oder falsche Antworten lieferte. Obwohl nicht jeder durch Selbstkonsistenz generierte abgetastete Pfad korrekt ist, konvergiert die Mehrheit mit zunehmender Anzahl abgetasteter Pfade der wahren Antwort. Wir stellen fest, dass 5 bis 10 Pfade in der Regel ausreichen, um die gierigen Ergebnisse zu übertreffen, wobei die Erträge in Bezug auf die Effizienz jenseits dieser Werte sinken.
| Fragen (FAQ) |
Eine Webanwendung ermöglicht es Kunden, Bestellungen in einen S3-Bucket hochzuladen. Die resultierenden Amazon S3-Ereignisse lösen eine Lambda-Funktion aus, die eine Nachricht in eine SQS-Warteschlange einfügt. Eine einzelne EC2-Instanz liest Nachrichten aus der Warteschlange, verarbeitet sie und speichert sie in einer DynamoDB-Tabelle, die nach einer eindeutigen Auftrags-ID partitioniert ist. Es wird erwartet, dass der Datenverkehr im nächsten Monat um den Faktor 10 zunehmen wird und ein Lösungsarchitekt die Architektur auf mögliche Skalierungsprobleme überprüft. Welche Komponente muss am wahrscheinlichsten umgestaltet werden, um sich an den neuen Datenverkehr anpassen zu können? A. Lambda-Funktion |
Eine auf AWS ausgeführte Anwendung verwendet eine Amazon Aurora Multi-AZ DB-Cluster-Bereitstellung für ihre Datenbank. Bei der Auswertung von Leistungsmetriken stellte ein Lösungsarchitekt fest, dass die Datenbanklesevorgänge hohe I/O-Vorgänge verursachen und die Latenz der Schreibanforderungen an die Datenbank erhöhen. Was sollte der Lösungsarchitekt tun, um die Leseanforderungen von den Schreibanforderungen zu trennen? A. Aktivieren Sie das Read-Through-Caching für die Aurora-Datenbank. |
| Korrekte Antwort | C – Eine einzelne EC2-Instanz lässt sich nicht skalieren und stellt einen Single Point of Failure in der Architektur dar. Eine viel bessere Lösung wäre, EC2-Instanzen in einer Auto Scaling-Gruppe über zwei Verfügbarkeitszonen hinweg Nachrichten aus der Warteschlange lesen zu lassen. Bei den anderen Antworten handelt es sich ausschließlich um verwaltete Dienste, die für die Skalierung konfiguriert werden können oder automatisch skaliert werden. | C – Aurora Replicas bieten eine Möglichkeit, den Leseverkehr auszulagern. Aurora-Replikate nutzen denselben zugrunde liegenden Speicher wie die Hauptdatenbank, sodass die Verzögerungszeit im Allgemeinen sehr gering ist. Aurora Replicas verfügen über eigene Endpunkte, daher muss die Anwendung so konfiguriert werden, dass sie den Leseverkehr an die neuen Endpunkte weiterleitet. |
| Gierige Dekodierung | Eine direkte Skalierung der EC2-Instanz ist möglicherweise nicht möglich, da die Größe der Instanz möglicherweise nicht geändert werden kann. Die Skalierung der Lambda-Funktion ist möglicherweise nicht ausreichend, da für Lambda-Funktionen eine Speicherzuweisungsbeschränkung von 6 GB gilt. Die Skalierung der SQS-Warteschlange reicht möglicherweise nicht aus, da SQS ein Limit von 10,000 Nachrichten hat. DynamoDB-Tabellen können durch die Bereitstellung weiterer Kapazitätseinheiten skaliert werden. Die richtige Antwort ist D. | Ändern der Anwendung zum Lesen aus der Multi-AZ-Standby-Instanz (Option B) ist der beste Ansatz. Die Standby-Instanz wird asynchron von der Primärinstanz repliziert, sodass Lesevorgänge die Schreibvorgänge nicht beeinträchtigen. Read-Through-Caching aktivieren (Option A) oder Durch das Erstellen einer Aurora-Replik (Option C) wird das E/A-Konfliktproblem nicht gelöst. Auch das Erstellen einer zweiten Aurora-Datenbank und deren Verknüpfung als Lesereplikat (Option D) löst das Problem der E/A-Konflikte nicht. Die richtige Antwort ist B. |
| Gesampelter Pfad Nr. 1 | Eine Skalierung der EC2-Instanz auf das Zehnfache ihrer aktuellen Größe ist möglicherweise weder aus Kosten- noch aus Leistungsgründen machbar. Es würde eine größere Instanz erfordern, was teuer sein kann. Ein kostengünstigerer Ansatz könnte darin bestehen, einen Schwarm kleinerer Instanzen (z. B. Auto Scaling Group) zu verwenden, um die Last zu teilen. In diesem Fall müsste die EC2-Instanz wahrscheinlich neu strukturiert werden. Die richtige Antwort ist C. | Das Ändern der Anwendung zur Verwendung der entsprechenden Endpunkte ist keine praktische Lösung, da hierfür Änderungen am Anwendungscode erforderlich wären. Die richtige Antwort ist C: Erstellen Sie ein Aurora-Replikat und ändern Sie die Anwendung, um die entsprechenden Endpunkte zu verwenden. |
| Gesampelter Pfad Nr. 2 | Die Skalierung einer einzelnen EC2-Instanz ist schwieriger und problematischer als die Skalierung der anderen Servicekomponenten. Amazon SQS, Lambda und DynamoDB können alle automatisch skaliert werden um der erhöhten Belastung gewachsen zu sein. Die richtige Antwort ist C. |
(C) Erstellen Sie ein Aurora-Replikat und ändern Sie die Anwendung so, dass sie die entsprechenden Endpunkte verwendet. Durch die Konfiguration eines Aurora-Replikats können Sie den Leseverkehr vom Schreibverkehr trennen. Die Aurora-Replikate verwenden unterschiedliche Endpunkt-URLs, sodass Sie den Leseverkehr an das Replikat statt an die Primärdatenbank weiterleiten können. Das Replikat kann Leseanforderungen parallel zu Schreibanforderungen an die Primärdatenbank verarbeiten, wodurch E/A und Latenz reduziert werden. |
Aufräumen
Für die Ausführung der Batch-Inferenz in Amazon Bedrock fallen Gebühren gemäß den Amazon Bedrock-Preisen an. Wenn Sie die exemplarische Vorgehensweise abgeschlossen haben, löschen Sie Ihre SageMaker-Notebook-Instanz und entfernen Sie alle Daten aus Ihren S3-Buckets, um zukünftige Gebühren zu vermeiden.
Überlegungen
Obwohl die demonstrierte Lösung eine verbesserte Leistung von Sprachmodellen zeigt, wenn sie mit Selbstkonsistenz aufgefordert wird, ist es wichtig zu beachten, dass die exemplarische Vorgehensweise noch nicht produktionsbereit ist. Vor der Bereitstellung in der Produktion sollten Sie diesen Proof of Concept an Ihre eigene Implementierung anpassen und dabei die folgenden Anforderungen berücksichtigen:
- Zugriffsbeschränkung auf APIs und Datenbanken, um unbefugte Nutzung zu verhindern.
- Einhaltung der Best Practices für die Sicherheit von AWS in Bezug auf IAM-Rollenzugriff und Sicherheitsgruppen.
- Validierung und Bereinigung von Benutzereingaben, um Prompt-Injection-Angriffe zu verhindern.
- Überwachung und Protokollierung ausgelöster Prozesse, um Tests und Audits zu ermöglichen.
Zusammenfassung
Dieser Beitrag zeigt, dass die Eingabeaufforderung zur Selbstkonsistenz die Leistung generativer Sprachmodelle bei komplexen NLP-Aufgaben verbessert, die arithmetische und logische Multiple-Choice-Fähigkeiten erfordern. Selbstkonsistenz nutzt temperaturbasierte stochastische Dekodierung, um verschiedene Argumentationspfade zu generieren. Dies erhöht die Fähigkeit des Modells, vielfältige und nützliche Gedanken hervorzurufen, um zu richtigen Antworten zu gelangen.
Mit der Batch-Inferenz von Amazon Bedrock wird das Sprachmodell Cohere Command aufgefordert, selbstkonsistente Antworten auf eine Reihe von Rechenproblemen zu generieren. Die Genauigkeit verbessert sich von 51.7 % bei gieriger Dekodierung auf 68 % bei Selbstkonsistenz-Abtastung von 30 Argumentationspfaden bei T=1.0. Die Abtastung von fünf Pfaden erhöht die Genauigkeit bereits um 7.5 Prozentpunkte. Der Ansatz ist auf andere Sprachmodelle und Argumentationsaufgaben übertragbar, wie die Ergebnisse des AI21 Labs Jurassic-2 Mid-Modells bei einer AWS-Zertifizierungsprüfung zeigen. In einem kleinen Fragensatz erhöht die Selbstkonsistenz mit fünf Stichprobenpfaden die Genauigkeit um 5 Prozentpunkte gegenüber gierigem CoT.
Wir empfehlen Ihnen, Selbstkonsistenz-Prompts für eine verbesserte Leistung in Ihren eigenen Anwendungen mit generativen Sprachmodellen zu implementieren. Lerne mehr über Cohere-Kommando und AI21 Labs Jurassic Modelle auf Amazon Bedrock erhältlich. Weitere Informationen zur Batch-Inferenz finden Sie unter Batch-Inferenz ausführen.
Danksagung
Der Autor dankt den technischen Gutachtern Amin Tajgardoon und Patrick McSweeney für ihr hilfreiches Feedback.
Über den Autor

Lucía Santamaría ist Senior Applied Scientist an der ML University von Amazon, wo sie sich darauf konzentriert, das Niveau der ML-Kompetenz im gesamten Unternehmen durch praktische Ausbildung zu steigern. Lucía hat einen Doktortitel in Astrophysik und engagiert sich leidenschaftlich für die Demokratisierung des Zugangs zu technischem Wissen und Werkzeugen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

