Inhaltsverzeichnis
- Python-Interviewfragen für Studienanfänger
- 1. Was ist Python?
- 2. Warum Python?
- 3. Wie installiere ich Python?
- 4. Was sind die Anwendungen von Python?
- 5. Was sind die Vorteile von Python?
- 6. Was sind die Hauptfunktionen von Python?
- 7. Was meinen Sie mit Python-Literalen?
- 8. Welche Art von Sprache ist Python?
- 9. Inwiefern ist Python eine interpretierte Sprache?
- 10. Was ist Pep 8?
- 11. Was ist Namespace in Python?
- 12. Was ist PYTHON PATH?
- 13. Was sind Python-Module?
- 14. Was sind lokale Variablen und globale Variablen in Python?
- 15. Erklären Sie, was Flask ist und welche Vorteile es hat.
- 16. Ist Django besser als Flask?
- 17. Nennen Sie die Unterschiede zwischen Django, Pyramid und Flask.
- 18. Besprechen Sie die Django-Architektur
- 19. Bereich in Python erklären?
- 20. Die gängigen integrierten Datentypen in Python auflisten?
- 21. Was sind globale, geschützte und private Attribute in Python?
- 22. Was sind Schlüsselwörter in Python?
- 23. Was ist der Unterschied zwischen Listen und Tupeln in Python?
- 24. Wie können Sie zwei Tupel verketten?
- 25. Was sind Funktionen in Python?
- 26. Wie können Sie ein 5*5-numpy-Array nur mit Nullen initialisieren?
- 27. Was sind Pandas?
- 28. Was sind Datenrahmen?
- 29. Was ist eine Pandas-Serie?
- 30. Was verstehst du über Pandas Groupby?
- 31. Wie erstelle ich einen Datenrahmen aus Listen?
- 32. Wie erstelle ich einen Datenrahmen aus einem Wörterbuch?
- 33. Wie kombiniert man Datenrahmen in Pandas?
- 34. Welche Art von Joins bietet Pandas an?
- 35. Wie werden Datenrahmen in Pandas zusammengeführt?
- 36. Geben Sie dem folgenden Datenrahmen alle Zeilen mit Nan löschen.
- 37. Wie greife ich auf die ersten fünf Einträge eines Datenrahmens zu?
- 38. Wie greife ich auf die letzten fünf Einträge eines Datenrahmens zu?
- 39. Wie rufe ich einen Dateneintrag aus einem Pandas-Datenrahmen mit einem bestimmten Wert im Index ab?
- 40. Was sind Kommentare und wie können Sie Kommentare in Python hinzufügen?
- 41. Was ist ein Wörterbuch in Python? Gib ein Beispiel.
- 42. Was ist der Unterschied zwischen einem Tupel und einem Wörterbuch?
- 43. Finden Sie Mittelwert, Median und Standardabweichung dieses numpy-Arrays heraus -> np.array([1,5,3,100,4,48])
- 44. Was ist ein Klassifikator?
- 45. Wie konvertiert man in Python einen String in Kleinbuchstaben?
- 46. Wie bekommt man eine Liste aller Schlüssel in einem Wörterbuch?
- 47. Wie können Sie den ersten Buchstaben einer Zeichenfolge groß schreiben?
- 48. Wie können Sie in Python ein Element an einem bestimmten Index einfügen?
- 49. Wie werden Sie doppelte Elemente aus einer Liste entfernen?
- 50. Was ist Rekursion?
- 51. Erklären Sie das Verständnis von Python-Listen.
- 52. Was ist die Funktion bytes()?
- 53. Was sind die verschiedenen Arten von Operatoren in Python?
- 54. Was ist die „with-Anweisung“?
- 55. Was ist eine map()-Funktion in Python?
- 56. Was ist __init__ in Python?
- 57. Welche Werkzeuge sind vorhanden, um statische Analysen durchzuführen?
- 58. Was ist pass in Python?
- 59. Wie kann ein Objekt in Python kopiert werden?
- 60. Wie kann eine Zahl in eine Zeichenfolge umgewandelt werden?
Sind Sie ein aufstrebender Python-Entwickler? Eine Karriere in Python hat im Jahr 2023 einen Aufwärtstrend erlebt, und Sie können Teil der ständig wachsenden Community sein. Wenn Sie also bereit sind, sich in den Wissenspool zu stürzen und sich auf das bevorstehende Python-Interview vorzubereiten, dann sind Sie hier genau richtig.
Wir haben eine umfassende Liste mit Fragen und Antworten zu Python-Interviews zusammengestellt, die sich im Bedarfsfall als nützlich erweisen werden. Sobald Sie mit den Fragen, die wir in unserer Liste erwähnt haben, vorbereitet sind, sind Sie bereit, in zahlreiche Python-Jobrollen wie Python-Entwickler, Datenwissenschaftler, Softwareingenieur, Datenbankadministrator, Qualitätssicherungstester und mehr einzusteigen.
Die Python-Programmierung kann mehrere Funktionen mit wenigen Codezeilen erreichen und unterstützt leistungsstarke Berechnungen mit leistungsstarken Bibliotheken. Aufgrund dieser Faktoren steigt die Nachfrage nach Fachleuten mit Python-Programmierkenntnissen. Schauen Sie sich das kostenlose an Python-Kursum mehr zu erfahren
Dieser Blog behandelt die am häufigsten gestellten Python-Interviewfragen, die Ihnen helfen werden, tolle Jobangebote zu erhalten.
Die Fragen sind in mehrere Kategorien unterteilt, wie unten aufgeführt:
- Python-Interviewfragen für Studienanfänger
- Python-Interviewfragen für Erfahrene
- Fragen in Vorstellungsgesprächen zur Python-Programmierung
- Häufig gestellte Fragen zu Python-Interviewfragen
Python-Interviewfragen für Studienanfänger
Dieser Abschnitt zu Python-Interviewfragen für Studienanfänger behandelt über 70 Fragen, die häufig während des Vorstellungsgesprächs gestellt werden. Als Studienanfänger sind Sie vielleicht neu im Vorstellungsgespräch; Das Lernen dieser Fragen wird Ihnen jedoch helfen, dem Interviewer selbstbewusst zu antworten und Ihr bevorstehendes Interview zu meistern.
1. Was ist Python?
Python wurde 1991 von Guido van Rossum erstellt und erstmals veröffentlicht. Es handelt sich um eine allgemeine Programmiersprache auf hohem Niveau, die die Lesbarkeit des Codes betont und eine einfach zu verwendende Syntax bietet. Mehrere Entwickler und Programmierer bevorzugen die Verwendung von Python für ihre Programmieranforderungen aufgrund seiner Einfachheit. Nach 30 Jahren trat Van Rossum 2018 als Leiter der Community zurück.
Python-Interpreter sind für viele Betriebssysteme verfügbar. CPython, die Referenzimplementierung von Python, ist Open-Source-Software und hat ein Community-basiertes Entwicklungsmodell, wie fast alle seine Variantenimplementierungen. Die gemeinnützige Python Software Foundation verwaltet Python und CPython.
2. Warum Python?
Python ist eine allgemeine Programmiersprache auf hoher Ebene. Python ist eine Programmiersprache, die zum Erstellen von Desktop-GUI-Apps, Websites und Online-Anwendungen verwendet werden kann. Als höhere Programmiersprache ermöglicht Ihnen Python außerdem, sich auf die wesentlichen Funktionen der Anwendung zu konzentrieren, während Sie routinemäßige Programmieraufgaben erledigen. Die grundlegenden Grammatikbeschränkungen der Programmiersprache machen es erheblich einfacher, die Codebasis verständlich und die Anwendung überschaubar zu halten.
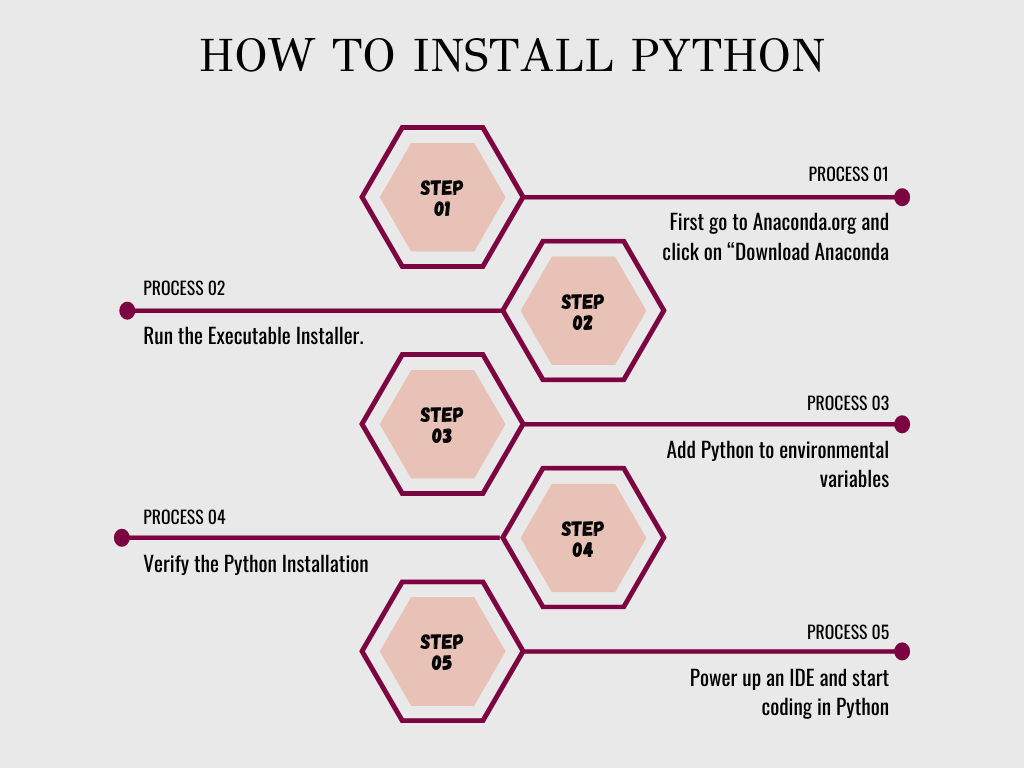
3. Wie installiere ich Python?
Um Python zu installieren, gehen Sie zu Anaconda.org und klicken Sie auf „Anaconda herunterladen“. Hier können Sie die neueste Version von Python herunterladen. Nachdem Python installiert ist, ist es ein ziemlich einfacher Prozess. Der nächste Schritt besteht darin, eine IDE hochzufahren und mit dem Programmieren in Python zu beginnen. Wenn Sie mehr über den Prozess erfahren möchten, lesen Sie dies Python-Tutorial. Zur kasse Wie installiere ich Python.
Schauen Sie sich diese bildliche Darstellung der Python-Installation an.
4. Was sind die Anwendungen von Python?
Python zeichnet sich durch seinen universellen Charakter aus, wodurch es in praktisch allen Bereichen der Softwareentwicklung eingesetzt werden kann. Python kann in fast jedem neuen Bereich gefunden werden. Es ist die beliebteste Programmiersprache und kann zum Erstellen beliebiger Anwendungen verwendet werden.
- Web Applikationen
Wir können Python verwenden, um Webanwendungen zu entwickeln. Es enthält HTML- und XML-Bibliotheken, JSON-Bibliotheken, E-Mail-Verarbeitungsbibliotheken, Anforderungsbibliotheken, schöne Suppe Bibliotheken, Feedparser-Bibliotheken und andere Internetprotokolle. Instagram verwendet Django, ein Python-Webframework.
– Desktop-GUI-Anwendungen
Die grafische Benutzeroberfläche (GUI) ist eine Benutzeroberfläche, die eine einfache Interaktion mit jedem Programm ermöglicht. Python enthält das Tk-GUI-Framework zum Erstellen von Benutzeroberflächen.
– Konsolenbasierte Anwendung
Die Befehlszeile oder Shell wird verwendet, um konsolenbasierte Programme auszuführen. Dies sind Computerprogramme, die zur Ausführung von Aufträgen verwendet werden. Diese Art von Programm war in der vorherigen Generation von Computern häufiger anzutreffen. Es ist bekannt für seine REPL- oder Read-Eval-Print-Schleife, die es ideal für Befehlszeilenanwendungen macht.
Python verfügt über eine Reihe kostenloser Bibliotheken und Module, die bei der Erstellung von Befehlszeilenanwendungen helfen. Zum Lesen und Schreiben werden die entsprechenden IO-Bibliotheken verwendet. Es verfügt über integrierte Funktionen zum Verarbeiten von Parametern und zum Generieren von Konsolenhilfetext. Es gibt zusätzliche erweiterte Bibliotheken, die zum Erstellen eigenständiger Konsolenanwendungen verwendet werden können.
- Software-Entwicklung
Python ist nützlich für den Softwareentwicklungsprozess. Es ist eine Unterstützungssprache, die verwendet werden kann, um Kontrolle und Verwaltung, Tests und andere Dinge einzurichten.
- SCons werden verwendet, um die Steuerung aufzubauen.
- Kontinuierliche Kompilierung und Tests werden mit Buildbot und Apache Gumps automatisiert.
– Wissenschaftlich und Numerisch
Dies ist die Zeit der künstlichen Intelligenz, in der eine Maschine Aufgaben genauso gut ausführen kann wie ein Mensch. Python ist eine hervorragende Programmiersprache für Anwendungen der künstlichen Intelligenz und des maschinellen Lernens. Es verfügt über eine Reihe von wissenschaftlichen und mathematischen Bibliotheken, die das Ausführen schwieriger Berechnungen vereinfachen.
Machine-Learning-Algorithmen in die Praxis umzusetzen, erfordert viel Arithmetik. Numpy, Pandas, Scipy, Scikit-learn und andere wissenschaftliche und numerische Python-Bibliotheken stehen zur Verfügung. Wenn Sie mit Python vertraut sind, können Sie Bibliotheken zusätzlich zum Code importieren. Nachfolgend sind einige bekannte Frameworks für Maschinenbibliotheken aufgeführt.
– Geschäftsanwendungen
Standard-Apps sind nicht dasselbe wie Geschäftsanwendungen. Diese Art von Programm erfordert viel Skalierbarkeit und Lesbarkeit, die Python bietet.
Oddo ist eine Python-basierte All-in-One-Anwendung, die eine breite Palette von Geschäftsanwendungen bietet. Die kommerzielle Anwendung basiert auf der Tryton-Plattform, die von Python bereitgestellt wird.
– Audio- oder Video-basierte Anwendungen
Python ist eine vielseitige Programmiersprache, die zum Erstellen von Multimedia-Anwendungen verwendet werden kann. Beispiele sind TimPlayer, cplay und andere in Python geschriebene Multimedia-Programme.
– 3D-CAD-Anwendungen
Engineering-bezogene Architektur wird mit CAD (Computer Aided Design) entworfen. Es wird verwendet, um eine dreidimensionale Visualisierung einer Systemkomponente zu erstellen. Die folgenden Funktionen in Python können verwendet werden, um eine 3D-CAD-Anwendung zu entwickeln:
- Fandango (beliebt)
- CAMVOX
- HeeksCNC
- AnyCAD
- RCAM
- Geschäftliche Anwendungen
Python kann verwendet werden, um Apps für die Verwendung innerhalb eines Unternehmens oder einer Organisation zu entwickeln. OpenERP, Tryton, Picalo all diese Echtzeitanwendungen sind Beispiele.
– Bildverarbeitungsanwendung
Python hat viele Bibliotheken für die Arbeit mit Bildern. Das Bild kann nach unseren Vorgaben verändert werden. OpenCV, Pillow und SimpleITK sind alles Bildverarbeitungsbibliotheken, die in Python vorhanden sind. In diesem Thema haben wir eine breite Palette von Anwendungen behandelt, bei deren Entwicklung Python eine entscheidende Rolle spielt. Wir werden im kommenden Tutorial mehr über Python-Prinzipien erfahren.
5. Was sind die Vorteile von Python?
Python ist eine universelle dynamische Programmiersprache, die auf hohem Niveau ist und interpretiert wird. Sein architektonisches Framework priorisiert die Lesbarkeit des Codes und nutzt die Einrückung ausgiebig.
- Module von Drittanbietern sind vorhanden.
- Mehrere unterstützende Bibliotheken sind verfügbar (NumPy für numerische Berechnungen, Pandas für Datenanalysen usw.)
- Community-Entwicklung und Open Source
- Anpassbar, einfach zu lesen, zu lernen und zu schreiben
- Datenstrukturen, die ziemlich einfach zu bearbeiten sind
- Hochsprache
- Die Sprache, die dynamisch typisiert wird (keine Angabe des Datentyps basierend auf dem zugewiesenen Wert, es wird der Datentyp verwendet)
- Objektorientierte Programmiersprache
- Interaktiv und transportabel
- Ideal für Prototypen, da Sie zusätzliche Funktionen mit minimalem Code hinzufügen können.
- Sehr effektiv
- Möglichkeiten des Internets der Dinge (IoT).
- Portable interpretierte Sprache über Betriebssysteme hinweg
- Da es sich um eine interpretierte Sprache handelt, führt sie jeden Code Zeile für Zeile aus und gibt einen Fehler aus, wenn etwas fehlt.
- Python kann kostenlos verwendet werden und hat eine große Open-Source-Community.
- Python bietet viel Unterstützung für Bibliotheken, die zahlreiche Funktionen für jede anstehende Aufgabe bereitstellen.
- Eine der besten Eigenschaften von Python ist seine Portabilität: Es kann und wird auf jeder Plattform ausgeführt, ohne dass die Anforderungen geändert werden müssen.
- Bietet viel Funktionalität in weniger Codezeilen im Vergleich zu anderen Programmiersprachen wie Java, C++ usw.
Knacken Sie Ihr Python-Interview
6. Was sind die Hauptfunktionen von Python?
Python ist eine der beliebtesten Programmiersprachen, die von Datenwissenschaftlern und AIML-Experten verwendet wird. Diese Popularität ist auf die folgenden Hauptmerkmale von Python zurückzuführen:
- Python ist aufgrund seiner klaren Syntax und Lesbarkeit leicht zu erlernen
- Python ist einfach zu interpretieren, was das Debuggen einfach macht
- Python ist kostenlos und Open Source
- Es kann in verschiedenen Sprachen verwendet werden
- Es ist eine objektorientierte Sprache, die Konzepte von Klassen unterstützt
- Es kann leicht in andere Sprachen wie C++, Java und mehr integriert werden
7. Was meinen Sie mit Python-Literalen?
Ein Literal ist eine einfache und direkte Form, einen Wert auszudrücken. Literale spiegeln die Optionen für primitive Typen wieder, die in dieser Sprache verfügbar sind. Ganzzahlen, Fließkommazahlen, Boolesche Werte und Zeichenfolgen sind einige der häufigsten Formen von Literalen. Python unterstützt die folgenden Literale:
Literale in Python beziehen sich auf die Daten, die in einer Variablen oder Konstante gehalten werden. In Python gibt es mehrere Arten von Literalen
String-Literale: Es ist eine Folge von Zeichen, die in eine Reihe von Codes eingeschlossen sind. Je nach Anzahl der verwendeten Anführungszeichen kann es sich um einfache, doppelte oder dreifache Zeichenfolgen handeln. Einzelne Zeichen, die in einfache oder doppelte Anführungszeichen eingeschlossen sind, werden als Zeichenliterale bezeichnet.
Numerische Literale: Dies sind unveränderliche Zahlen, die in drei Typen unterteilt werden können: Ganzzahl, Float und Komplex.
Boolesche Literale: Ihnen kann True oder False zugeordnet werden, was '1' bzw. '0' bedeutet.
Spezielle Literale: Es wird verwendet, um Felder zu kategorisieren, die nicht generiert wurden. „None“ ist der Wert, der verwendet wird, um es darzustellen.
- Zeichenfolgenliterale: „halo“ , '12345'
- Int-Literale: 0,1,2,-1,-2
- Lange Literale: 89675L
- Float-Literale: 3.14
- Komplexe Literale: 12j
- Boolesche Literale: True oder False
- Spezielle Literale: Keine
- Unicode-Literale: u"Hallo"
- Listenliterale: [], [5, 6, 7]
- Tupelliterale: (), (9,), (8, 9, 0)
- Dict-Literale: {}, {'x':1}
- Literale festlegen: {8, 9, 10}
8. Welche Art von Sprache ist Python?
Python ist eine interpretierte, interaktive, objektorientierte Programmiersprache. Klassen, Module, Ausnahmen, dynamische Typisierung und dynamische Datentypen auf extrem hoher Ebene sind alle vorhanden.
Python ist eine interpretierte Sprache mit dynamischer Typisierung. Da der Code nicht in eine binäre Form konvertiert wird, werden diese Sprachen manchmal als „Skriptsprachen“ bezeichnet. Während ich dynamisch typisiert sage, beziehe ich mich auf die Tatsache, dass Typen beim Codieren nicht angegeben werden müssen; der Interpreter findet sie zur Laufzeit heraus.
Die Lesbarkeit der prägnanten, leicht zu erlernenden Syntax von Python wird priorisiert, wodurch die Softwarewartungskosten gesenkt werden. Python stellt Module und Pakete bereit, die Programmmodularität und Wiederverwendung von Code ermöglichen. Der Python-Interpreter und seine umfassende Standardbibliothek können kostenlos heruntergeladen und in Quell- oder Binärform für alle wichtigen Plattformen verteilt werden.
9. Inwiefern ist Python eine interpretierte Sprache?
Ein Interpreter nimmt Ihren Code und führt die von Ihnen bereitgestellten Aktionen aus, erzeugt die von Ihnen angegebenen Variablen und führt eine Menge Arbeit hinter den Kulissen durch, um sicherzustellen, dass es reibungslos funktioniert, oder warnt Sie vor Problemen.
Python ist keine interpretierte oder kompilierte Sprache. Das Attribut der Implementierung ist, ob sie interpretiert oder kompiliert wird. Python ist ein Bytecode (eine Sammlung von Interpreter-lesbaren Anweisungen), der auf verschiedene Weise interpretiert werden kann.
Der Quellcode wird in einem gespeichert .py-Datei.
Python generiert aus dem Quellcode eine Reihe von Anweisungen für eine virtuelle Maschine. Dieses Zwischenformat ist als „Bytecode“ bekannt und wird durch Kompilieren des .py-Quellcodes in .pyc, das Bytecode ist, erstellt. Dieser Bytecode kann dann vom Standard-CPython-Interpreter oder dem JIT (Just-in-Time-Compiler) von PyPy interpretiert werden.
Python ist als interpretierte Sprache bekannt, weil es einen Interpreter verwendet, um den von Ihnen geschriebenen Code in eine Sprache umzuwandeln, die der Prozessor Ihres Computers verstehen kann. Sie werden später den Python-Interpreter herunterladen und verwenden, um Python-Code erstellen und auf Ihrem eigenen Computer ausführen zu können, wenn Sie an einem Projekt arbeiten.
10. Was ist Pep 8?
PEP 8, oft bekannt als PEP8 oder PEP-8, ist ein Dokument, das Best Practices und Empfehlungen zum Schreiben von Python-Code umreißt. Es wurde 2001 von Guido van Rossum, Barry Warsaw und Nick Coghlan geschrieben. Das Hauptziel von PEP 8 ist es, Python-Code lesbarer und konsistenter zu machen.
Python Enhancement Proposal (PEP) ist ein Akronym für Python Enhancement Proposal, und es gibt zahlreiche davon. Ein Python Enhancement Proposal (PEP) ist ein Dokument, das neue Funktionen erklärt, die für Python vorgeschlagen werden, und Elemente von Python für die Community, wie Design und Stil, beschreibt.
11. Was ist Namespace in Python?
In Python ist ein Namensraum ein System, das jedem Objekt einen eindeutigen Namen zuweist. Eine Variable oder eine Methode kann als Objekt betrachtet werden. Python hat einen eigenen Namensraum, der in Form eines Python-Wörterbuchs gehalten wird. Betrachten wir als Beispiel eine Verzeichnis-Dateisystemstruktur in einem Computer. Es versteht sich von selbst, dass eine gleichnamige Datei in mehreren Ordnern zu finden ist. Wenn man jedoch den absoluten Pfad der Datei angibt, kann man auf Wunsch dorthin geleitet werden.
Ein Namensraum ist im Wesentlichen eine Technik, um sicherzustellen, dass alle Namen in einem Programm eindeutig sind und austauschbar verwendet werden können. Sie wissen vielleicht bereits, dass alles in Python ein Objekt ist, einschließlich Strings, Listen, Funktionen und so weiter. Eine weitere bemerkenswerte Sache ist, dass Python Wörterbücher verwendet, um Namespaces zu implementieren. Es existiert eine Zuordnung von Name zu Objekt, wobei die Namen als Schlüssel und die Objekte als Werte dienen. Derselbe Name kann von vielen Namespaces verwendet werden, die ihn jeweils einem anderen Objekt zuordnen. Hier sind ein paar Namespace-Beispiele:
Lokaler Namensraum: Dieser Namensraum speichert die lokalen Namen von Funktionen. Dieser Namensraum wird erstellt, wenn eine Funktion aufgerufen wird, und lebt nur, bis die Funktion zurückkehrt.
Globaler Namensraum: In diesem Namensraum werden Namen aus verschiedenen importierten Modulen gespeichert, die Sie in einem Projekt verwenden. Es wird gebildet, wenn das Modul zum Projekt hinzugefügt wird, und dauert, bis das Skript abgeschlossen ist.
Eingebauter Namensraum: Dieser Namensraum enthält die Namen von eingebauten Funktionen und Ausnahmen.
12. Was ist PYTHON PATH?
PYTHONPATH ist eine Umgebungsvariable, die es dem Benutzer ermöglicht, zusätzliche Ordner zur Verzeichnisliste sys.path für Python hinzuzufügen. Kurz gesagt handelt es sich um eine Umgebungsvariable, die vor dem Start des Python-Interpreters gesetzt wird.
13. Was sind Python-Module?
Ein Python-Modul ist eine Sammlung von Python-Befehlen und -Definitionen in einer einzigen Datei. In einem Modul können Sie Funktionen, Klassen und Variablen angeben. Ein Modul kann auch ausführbaren Code enthalten. Wenn Code in Module organisiert ist, ist er einfacher zu verstehen und zu verwenden. Es organisiert auch den Code logisch.
14. Was sind lokale Variablen und globale Variablen in Python?
Lokale Variablen werden innerhalb einer Funktion deklariert und haben einen Geltungsbereich, der nur auf diese Funktion beschränkt ist, während globale Variablen außerhalb jeder Funktion definiert sind und einen globalen Geltungsbereich haben. Anders ausgedrückt: Lokale Variablen sind nur innerhalb der Funktion verfügbar, in der sie erstellt wurden, globale Variablen sind jedoch im gesamten Programm und in jeder Funktion zugänglich.
Lokale Variablen
Lokale Variablen sind Variablen, die innerhalb einer Funktion erstellt werden und ausschließlich für diese Funktion gelten. Außerhalb der Funktion kann nicht darauf zugegriffen werden.
Globale Variablen
Globale Variablen sind Variablen, die außerhalb jeder Funktion definiert werden und im gesamten Programm verfügbar sind, dh sowohl innerhalb als auch außerhalb jeder Funktion.
15. Erklären Sie, was Flask ist und welche Vorteile es hat.
Flask ist ein Open-Source-Webframework. Flasche ist eine Reihe von Tools, Frameworks und Technologien zum Erstellen von Online-Anwendungen. Eine Webseite, ein Wiki, eine riesige webbasierte Kalendersoftware oder eine kommerzielle Website wird verwendet, um diese Web-App zu erstellen. Flask ist ein Mikro-Framework, was bedeutet, dass es sich nicht zu sehr auf andere Bibliotheken verlässt.
Vorteile:
Es gibt mehrere zwingende Gründe, Flask als Framework für Webanwendungen zu verwenden. Wie-
- Unit-Testing-Unterstützung, die integriert ist
- Es gibt einen integrierten Entwicklungsserver sowie einen schnellen Debugger.
- Restful-Request-Versand auf Unicode-Basis
- Die Verwendung von Cookies ist erlaubt.
- Templating WSGI 1.0-kompatibles jinja2
- Darüber hinaus gibt Ihnen die Flasche die vollständige Kontrolle über den Fortschritt Ihres Projekts.
- Verarbeitungsfunktion für HTTP-Anforderungen
- Flask ist ein leichtes und vielseitiges Web-Framework, das mit einigen Erweiterungen einfach integriert werden kann.
- Sie können Ihr bevorzugtes Gerät verwenden, um eine Verbindung herzustellen. Die Haupt-API für ORM Basic ist gut gestaltet und organisiert.
- Extrem anpassungsfähig
- In Bezug auf die Herstellung ist die Flasche einfach zu handhaben.
16. Ist Django besser als Flask?
Django ist beliebter, weil es viele sofort einsatzbereite Funktionen bietet, die das Erstellen komplizierter Anwendungen erleichtern. Django eignet sich am besten für größere Projekte mit vielen Funktionen. Die Funktionen können für kleinere Anwendungen übertrieben sein.
Wenn Sie neu in der Webprogrammierung sind, ist Flask ein fantastischer Ausgangspunkt. Viele Websites werden mit Flask erstellt und erhalten viel Verkehr, wenn auch nicht so viel wie Django-basierte Websites. Wenn Sie eine präzise Kontrolle wünschen, sollten Sie Flask verwenden, während ein Django-Entwickler auf eine große Community angewiesen ist, um einzigartige Websites zu erstellen.
17. Nennen Sie die Unterschiede zwischen Django, Pyramid und Flask.
Flask ist ein „Mikro-Framework“, das für kleinere Anwendungen mit geringeren Anforderungen entwickelt wurde. Pyramid und Django sind beide auf größere Projekte ausgerichtet, gehen aber auf unterschiedliche Weise an Erweiterung und Flexibilität heran.
Eine Pyramide ist so konzipiert, dass sie flexibel ist und es dem Entwickler ermöglicht, die besten Tools für sein Projekt zu verwenden. Das bedeutet, dass der Entwickler die Datenbank, die URL-Struktur, den Templating-Stil und andere Optionen auswählen kann. Django strebt danach, alle Batterien aufzunehmen, die eine Webanwendung benötigen würde, sodass Programmierer einfach die Schachtel öffnen und mit der Arbeit beginnen müssen, wobei sie die vielen Komponenten von Django mit einbeziehen.
Django enthält standardmäßig ein ORM, aber Pyramid und Flask geben dem Entwickler die Kontrolle darüber, wie (und ob) ihre Daten gespeichert werden. SQLAlchemy ist das beliebteste ORM für Nicht-Django-Webanwendungen, aber es gibt viele alternative Optionen, die von DynamoDB und MongoDB bis hin zu einfacher lokaler Persistenz wie LevelDB oder regulärem SQLite reichen. Pyramid ist so konzipiert, dass es mit jeder Art von Persistenzschicht funktioniert, sogar mit solchen, die noch konzipiert werden müssen.
| Django | Pyramide | Flasche |
| Es ist ein Python-Framework. | Es ist dasselbe wie Django | Es ist ein Mikro-Framework. |
| Es wird verwendet, um große Anwendungen zu erstellen. | Es ist dasselbe wie Django | Es wird verwendet, um eine kleine Anwendung zu erstellen. |
| Es enthält ein ORM. | Es bietet Flexibilität und die richtigen Werkzeuge. | Es erfordert keine externen Bibliotheken. |
18. Besprechen Sie die Django-Architektur
Django hat eine MVC (Model-View-Controller) Architektur, die in drei Teile gegliedert ist:
1. Modell
Das Modell, das durch eine Datenbank dargestellt wird, ist die logische Datenstruktur, die dem gesamten Programm zugrunde liegt (im Allgemeinen relationale Datenbanken wie MySql, Postgres).
2. Aussicht
Die Ansicht ist die Benutzeroberfläche oder das, was Sie sehen, wenn Sie eine Website in Ihrem Browser besuchen. Zur Darstellung werden HTML/CSS/Javascript-Dateien verwendet.
3 Regler
Der Controller ist das Bindeglied zwischen der Ansicht und dem Modell und für die Übertragung von Daten aus dem Modell an die Ansicht verantwortlich.
Ihre Anwendung dreht sich mithilfe von MVC um das Modell und zeigt es entweder an oder ändert es.
19. Bereich in Python erklären?
Stellen Sie sich Umfang als Familienvater vor; Jedes Objekt arbeitet innerhalb eines Bereichs. Eine formale Definition wäre, dass dies ein Codeblock ist, unter dem, egal wie viele Objekte Sie deklarieren, sie relevant bleiben. Ein paar Beispiele dafür sind unten aufgeführt:
- Lokaler Geltungsbereich: Wenn Sie eine Variable innerhalb einer Funktion erstellen, die zum lokalen Gültigkeitsbereich dieser Funktion selbst gehört und nur innerhalb dieser Funktion verwendet wird.
Beispiel:
def harshit_fun():
y = 100
print (y) harshit_func()
100
- Globaler Geltungsbereich: Wenn eine Variable im Hauptteil des Python-Codes erstellt wird, wird sie als globaler Geltungsbereich bezeichnet. Das Beste am globalen Bereich ist, dass sie in jedem Teil des Python-Codes von jedem Bereich aus zugänglich sind, sei es global oder lokal.
Beispiel:
y = 100 def harshit_func():
print (y)
harshit_func()
print (y)
- Verschachtelte FunktionHinweis: Dies wird auch als Funktion innerhalb einer Funktion bezeichnet, wie im obigen Beispiel im lokalen Gültigkeitsbereich angegeben, die Variable y ist außerhalb der Funktion nicht verfügbar, aber innerhalb einer Funktion innerhalb einer anderen Funktion.
Beispiel:
def first_func():
y = 100
def nested_func1():
print(y)
nested_func1()
first_func()
- Umfang auf Modulebene: Dies bezieht sich im Wesentlichen auf die globalen Objekte des aktuellen Moduls, auf die innerhalb des Programms zugegriffen werden kann.
- Äußerster Geltungsbereich: Dies ist ein Verweis auf alle eingebauten Namen, die Sie im Programm aufrufen können.
20. Die gängigen integrierten Datentypen in Python auflisten?
Nachfolgend sind die am häufigsten verwendeten integrierten Datentypen aufgeführt:
Zahlen: Besteht aus Ganzzahlen, Fließkommazahlen und komplexen Zahlen.
Liste: Wir haben bereits etwas über Listen gesehen, um eine formale Definition zu formulieren, ist eine Liste eine geordnete Folge von Elementen, die veränderlich sind, außerdem können die Elemente innerhalb von Listen zu verschiedenen Datentypen gehören.
Beispiel:
list = [100, “Great Learning”, 30]Tupel: Auch dies ist eine geordnete Folge von Elementen, aber im Gegensatz zu Listen sind Tupel unveränderlich, was bedeutet, dass sie nach der Deklaration nicht mehr geändert werden können.
Beispiel:
tup_2 = (100, “Great Learning”, 20) Zeichenfolge: Dies wird als die in einfachen oder doppelten Anführungszeichen deklarierte Zeichenfolge bezeichnet.
Beispiel:
“Hi, I work at great learning”
‘Hi, I work at great learning’Sätze: Sets sind im Grunde Sammlungen von Einzelstücken, bei denen die Reihenfolge nicht einheitlich ist.
Beispiel:
set = {1,2,3}Wörterbuch: Ein Wörterbuch speichert Werte immer in Schlüssel-Wert-Paaren, wobei auf jeden Wert über seinen speziellen Schlüssel zugegriffen werden kann.
Beispiel:
[12] harshit = {1:’video_games’, 2:’sports’, 3:’content’} Boolesch: Es gibt nur zwei boolesche Werte: Wahre und falsch
21. Was sind globale, geschützte und private Attribute in Python?
Die Attribute einer Klasse werden auch Variablen genannt. Es gibt drei Zugriffsmodifikatoren in Python für Variablen, nämlich
a. Öffentlichkeit - Die als öffentlich deklarierten Variablen sind überall zugänglich, innerhalb oder außerhalb der Klasse.
b. Privatgelände - Auf die als privat deklarierten Variablen kann nur innerhalb der aktuellen Klasse zugegriffen werden.
c. geschützt – Auf die als geschützt deklarierten Variablen kann nur innerhalb des aktuellen Pakets zugegriffen werden.
Attribute werden auch klassifiziert als:
– Lokale Attribute sind innerhalb eines Codeblocks/einer Methode definiert und können nur innerhalb dieses Codeblocks/dieser Methode aufgerufen werden.
– Globale Attribute werden außerhalb des Code-Blocks/der Methode definiert und können überall zugänglich sein.
class Mobile:
m1 = "Samsung Mobiles" //Global attributes
def price(self):
m2 = "Costly mobiles" //Local attributes
return m2
Sam_m = Mobile()
print(Sam_m.m1)22. Was sind Schlüsselwörter in Python?
Schlüsselwörter in Python sind reservierte Wörter, die als Bezeichner, Funktionsnamen oder Variablennamen verwendet werden. Sie helfen, die Struktur und Syntax der Sprache zu definieren.
Es gibt insgesamt 33 Schlüsselwörter in Python 3.7, die sich in der nächsten Version, dh Python 3.8, ändern können. Nachfolgend finden Sie eine Liste aller Schlüsselwörter:
Schlüsselwörter in Python:
| falsch | Klasse | endlich | is | Rückkehr |
| Andere | fortsetzen | für | Lambda | versuchen |
| Wahre | def | für | nicht lokal | während |
| und | des Restaurants | globale | nicht | mit |
| as | elif | if | or | Ausbeute |
| behaupten | sonst | importieren | passieren | |
| brechen | ausgeschlossen |
23. Was ist der Unterschied zwischen Listen und Tupeln in Python?
Liste und Tupel sind Datenstrukturen in Python die ein oder mehrere Objekte oder Werte speichern kann. Mit eckigen Klammern können Sie eine Liste erstellen, um mehrere Objekte in einer Variablen zu speichern. Tupel können wie Arrays zahlreiche Elemente in einer einzigen Variablen enthalten und werden mit Klammern definiert.
| Listen | Tupel |
| Listen sind veränderlich. | Tupel sind unveränderlich. |
| Die Auswirkungen von Iterationen sind zeitaufwändig. | Iterationen haben den Effekt, dass Dinge schneller gehen. |
| Die Liste ist bequemer für Aktionen wie Einfügen und Löschen. | Auf die Elemente kann unter Verwendung des Tupel-Datentyps zugegriffen werden. |
| Listen benötigen mehr Speicherplatz. | Im Vergleich zu einer Liste verbraucht ein Tupel weniger Speicher. |
| Es gibt zahlreiche Techniken, die in Listen eingebaut sind. | Es gibt nicht viele eingebaute Methoden in Tuple. |
| Unerwartete Änderungen und Fehler treten eher auf. | Es ist schwierig, in einem Tupel stattzufinden. |
| Aufgrund der Art dieser Datenstruktur verbrauchen sie viel Speicher | Sie verbrauchen weniger Speicher |
| Syntax: list = [100, „Großartiges Lernen“, 30] |
Syntax: tup_2 = (100, „Tolles Lernen“, 20) |
24. Wie können Sie zwei Tupel verketten?
Nehmen wir an, wir haben zwei solche Tupel ->
tup1 = (1, „a“, wahr)
tup2 = (4,5,6)
Die Verkettung von Tupeln bedeutet, dass wir die Elemente eines Tupels am Ende eines anderen Tupels hinzufügen.
Lassen Sie uns nun fortfahren und tuple2 mit tuple1 verketten:
Code:
tup1=(1,"a",True)
tup2=(4,5,6)
tup1+tup2Alles, was Sie tun müssen, ist, den '+'-Operator zwischen den beiden Tupeln zu verwenden, und Sie erhalten das verkettete Ergebnis.
Lassen Sie uns auf ähnliche Weise tuple1 mit tuple2 verketten:
Code:
tup1=(1,"a",True)
tup2=(4,5,6)
tup2+tup1
25. Was sind Funktionen in Python?
Antwort: Funktionen in Python beziehen sich auf Blöcke, die organisierte und wiederverwendbare Codes haben, um einzelne und verwandte Ereignisse auszuführen. Funktionen sind wichtig, um eine bessere Modularität für Anwendungen zu schaffen, die einen hohen Grad an Codierung wiederverwenden. Python hat eine Reihe von eingebauten Funktionen wie print(). Sie können jedoch auch benutzerdefinierte Funktionen erstellen.
26. Wie können Sie ein 5*5-numpy-Array nur mit Nullen initialisieren?
Wir werden das benutzen .nullen() Methode.
import numpy as np
n1=np.zeros((5,5))
n1
Verwenden Sie np.zeros() und übergeben Sie die Dimensionen darin. Da wir eine 5*5-Matrix wollen, übergeben wir (5,5) innerhalb der Methode .zeros().
27. Was sind Pandas?
Pandas ist eine Open-Source-Python-Bibliothek, die über einen sehr umfangreichen Satz von Datenstrukturen für datenbasierte Operationen verfügt. Pandas mit ihren coolen Funktionen passen in jede Rolle des Datenbetriebs, sei es Akademiker oder das Lösen komplexer Geschäftsprobleme. Pandas können mit einer Vielzahl von Dateien umgehen und sind eines der wichtigsten Werkzeuge, die man im Griff haben muss.
Erfahren Sie mehr über Python-Pandas
28. Was sind Datenrahmen?
Ein Pandas-Datenrahmen ist eine Datenstruktur in Pandas, die veränderbar ist. Pandas unterstützen heterogene Daten, die auf zwei Achsen angeordnet sind. ( Reihen und Spalten).
Dateien in Pandas lesen:-
| 12 | Importieren Sie Pandas als pdfdf=p.read_csv(“mydata.csv”) |
Hier ist df ein Pandas-Datenrahmen. read_csv() wird verwendet, um eine kommagetrennte Datei als Datenrahmen in Pandas zu lesen.
29. Was ist eine Pandas-Serie?
Series ist eine eindimensionale Panda-Datenstruktur, die Daten fast jeden Typs aufnehmen kann. Es ähnelt einer Excel-Spalte. Es unterstützt mehrere Operationen und wird für eindimensionale Datenoperationen verwendet.
Erstellen einer Serie aus Daten:
Code:
import pandas as pd
data=["1",2,"three",4.0]
series=pd.Series(data)
print(series)
print(type(series))
30. Was verstehst du über Pandas Groupby?
Ein Pandas-Gruppieren ist eine Funktion, die von Pandas unterstützt wird und zum Aufteilen und Gruppieren eines Objekts verwendet wird. Wie sql/mysql/oracle groupby wird es verwendet, um Daten nach Klassen und Entitäten zu gruppieren, die für die Aggregation weiter verwendet werden können. Ein Datenrahmen kann nach einer oder mehreren Spalten gruppiert werden.
Code:
df = pd.DataFrame({'Vehicle':['Etios','Lamborghini','Apache200','Pulsar200'], 'Type':["car","car","motorcycle","motorcycle"]})
df
Um groupby auszuführen, geben Sie den folgenden Code ein:
df.groupby('Type').count()31. Wie erstelle ich einen Datenrahmen aus Listen?
Um einen Datenrahmen aus Listen zu erstellen,
1) Erstellen Sie einen leeren Datenrahmen
2) Listen als einzelne Spalten zur Liste hinzufügen
Code:
df=pd.DataFrame()
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
df["cars"]=cars
df["bikes"]=bikes
df
32. Wie erstelle ich einen Datenrahmen aus einem Wörterbuch?
Ein Wörterbuch kann direkt als Argument an die Funktion DataFrame() übergeben werden, um den Datenrahmen zu erstellen.
Code:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
df
33. Wie kombiniert man Datenrahmen in Pandas?
Zwei verschiedene Datenrahmen können entweder horizontal oder vertikal durch die Funktionen concat(), append() und join() in Pandas gestapelt werden.
Concat funktioniert am besten, wenn die Datenrahmen die gleichen Spalten haben und kann für die Verkettung von Daten mit ähnlichen Feldern verwendet werden und ist im Grunde ein vertikales Stapeln von Datenrahmen zu einem einzigen Datenrahmen.
Append() wird zum horizontalen Stapeln von Datenrahmen verwendet. Wenn zwei Tabellen (Datenrahmen) zusammengeführt werden sollen, ist dies die beste Verkettungsfunktion.
Join wird verwendet, wenn wir Daten aus verschiedenen Datenrahmen extrahieren müssen, die eine oder mehrere gemeinsame Spalten haben. Die Stapelung erfolgt in diesem Fall horizontal.
Bevor Sie die Fragen durchgehen, finden Sie hier ein kurzes Video, das Ihnen hilft, Ihr Gedächtnis für Python aufzufrischen.
34. Welche Art von Joins bietet Pandas an?
Pandas haben einen linken Join, einen inneren Join, einen rechten Join und einen äußeren Join.
35. Wie werden Datenrahmen in Pandas zusammengeführt?
Das Zusammenführen hängt vom Typ und den Feldern verschiedener Datenrahmen ab, die zusammengeführt werden. Wenn Daten ähnliche Felder haben, werden die Daten entlang Achse 0 zusammengeführt, andernfalls werden sie entlang Achse 1 zusammengeführt.
36. Geben Sie dem folgenden Datenrahmen alle Zeilen mit Nan löschen.
Dazu kann die Funktion dropna verwendet werden.
df.dropna(inplace=True)
df37. Wie greife ich auf die ersten fünf Einträge eines Datenrahmens zu?
Durch die Verwendung der Funktion head(5) können wir die obersten fünf Einträge eines Datenrahmens erhalten. Standardmäßig gibt df.head() die obersten 5 Zeilen zurück. Um die oberen n Zeilen zu erhalten, wird df.head(n) verwendet.
38. Wie greife ich auf die letzten fünf Einträge eines Datenrahmens zu?
Durch die Verwendung der Funktion tail(5) können wir die obersten fünf Einträge eines Datenrahmens erhalten. Standardmäßig gibt df.tail() die obersten 5 Zeilen zurück. Um die letzten n Zeilen zu erhalten, wird df.tail(n) verwendet.
39. Wie rufe ich einen Dateneintrag aus einem Pandas-Datenrahmen mit einem bestimmten Wert im Index ab?
Um eine Zeile aus einem Datenrahmen mit dem gegebenen Index x abzurufen, können wir loc verwenden.
Df.loc[10] wobei 10 der Wert des Indexes ist.
Code:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
a=[10,20,30,40,50]
df.index=a
df.loc[10]
40. Was sind Kommentare und wie können Sie Kommentare in Python hinzufügen?
Kommentare in Python beziehen sich auf einen Text, der zur Information bestimmt ist. Dies ist besonders relevant, wenn mehr als eine Person an einem Satz von Codes arbeitet. Es kann verwendet werden, um Code zu analysieren, Feedback zu hinterlassen und ihn zu debuggen. Es gibt zwei Arten von Kommentaren, darunter:
- Einzeiliger Kommentar
- Mehrzeiliger Kommentar
Codes, die zum Hinzufügen eines Kommentars benötigt werden
#Note – einzeiliger Kommentar
"""Notiz
Note
Hinweis”””—– mehrzeiliger Kommentar
41. Was ist ein Wörterbuch in Python? Gib ein Beispiel.
Ein Python-Wörterbuch ist eine Sammlung von Elementen in keiner bestimmten Reihenfolge. Python-Wörterbücher werden in geschweiften Klammern mit Schlüsseln und Werten geschrieben. Wörterbücher sind optimiert, um Werte für bekannte Schlüssel abzurufen.
Beispiel
d={“a”:1,”b”:2}42. Was ist der Unterschied zwischen a Tupel und a Wörterbuch?
Ein Hauptunterschied zwischen einem Tupel und einem Wörterbuch besteht darin, dass ein Wörterbuch änderbar ist, ein Tupel jedoch nicht. Das heißt, der Inhalt eines Wörterbuchs kann geändert werden, ohne seine Identität zu ändern, aber in einem Tupel ist das nicht möglich.
43. Finden Sie Mittelwert, Median und Standardabweichung dieses numpy-Arrays heraus -> np.array([1,5,3,100,4,48])
import numpy as np
n1=np.array([10,20,30,40,50,60])
print(np.mean(n1))
print(np.median(n1))
print(np.std(n1))
44. Was ist ein Klassifikator?
Ein Klassifikator wird verwendet, um die Klasse eines beliebigen Datenpunkts vorherzusagen. Klassifikatoren sind spezielle Hypothesen, die verwendet werden, um einem bestimmten Datenpunkt Klassenbezeichnungen zuzuweisen. Ein Klassifikator verwendet häufig Trainingsdaten, um die Beziehung zwischen Eingabevariablen und der Klasse zu verstehen. Die Klassifizierung ist eine Methode, die beim überwachten Lernen im maschinellen Lernen verwendet wird.
45. Wie konvertiert man in Python einen String in Kleinbuchstaben?
Alle Großbuchstaben in einem String können mit der Methode in Kleinbuchstaben umgewandelt werden: string.lower()
ex:
string = ‘GREATLEARNING’ print(string.lower())o/p: tolles Lernen
46. Wie bekommt man eine Liste aller Schlüssel in einem Wörterbuch?
Eine der Möglichkeiten, wie wir eine Liste von Schlüsseln erhalten können, ist die Verwendung von: dict.keys()
Diese Methode gibt alle verfügbaren Schlüssel im Wörterbuch zurück.
dict = {1:a, 2:b, 3:c} dict.keys()o/p: [1, 2, 3]
47. Wie können Sie den ersten Buchstaben einer Zeichenfolge groß schreiben?
Wir können das benutzen profitieren() Funktion zum Großschreiben des ersten Zeichens einer Zeichenfolge. Wenn das erste Zeichen bereits in Großbuchstaben steht, wird die ursprüngliche Zeichenfolge zurückgegeben.
Syntax:
string_name.capitalize()
ex:
n = “greatlearning” print(n.capitalize())o/p: Greatlearning
48. Wie können Sie in Python ein Element an einem bestimmten Index einfügen?
Python hat eine eingebaute Funktion namens insert()-Funktion.
Es kann verwendet werden, um ein Element an einem bestimmten Index einzufügen.
Syntax:
list_name.insert(index, element)
ex:
list = [ 0,1, 2, 3, 4, 5, 6, 7 ]
#insert 10 at 6th index
list.insert(6, 10)o/p: [0,1,2,3,4,5,10,6,7]
49. Wie werden Sie doppelte Elemente aus einer Liste entfernen?
Es gibt verschiedene Methoden, um doppelte Elemente aus einer Liste zu entfernen. Am gebräuchlichsten ist jedoch, die Liste mit der Funktion set() in eine Menge umzuwandeln und sie bei Bedarf mit der Funktion list() wieder in eine Liste umzuwandeln.
ex:
list0 = [2, 6, 4, 7, 4, 6, 7, 2]
list1 = list(set(list0)) print (“The list without duplicates : ” + str(list1))
o/p: Die Liste ohne Duplikate : [2, 4, 6, 7]
50. Was ist Rekursion?
Rekursion ist eine Funktion, die sich selbst einmal oder mehrmals in ihrem Körper aufruft. Eine sehr wichtige Bedingung, dass eine rekursive Funktion in einem Programm verwendet werden sollte, ist, dass sie terminieren sollte, sonst würde es ein Problem einer Endlosschleife geben.
51. Erklären Sie das Verständnis von Python-Listen.
List Comprehensions werden verwendet, um eine Liste in eine andere Liste umzuwandeln. Elemente können bedingt in die neue Liste aufgenommen werden und jedes Element kann nach Bedarf transformiert werden. Es besteht aus einem Ausdruck, der zu einer for-Klausel führt, die in Klammern eingeschlossen ist.
Zum Beispiel:
list = [i for i in range(1000)]
print list52. Was ist die Funktion bytes()?
Die Funktion bytes() gibt ein bytes-Objekt zurück. Es wird verwendet, um Objekte in Bytes-Objekte umzuwandeln oder leere Bytes-Objekte der angegebenen Größe zu erstellen.
53. Was sind die verschiedenen Arten von Operatoren in Python?
Python hat die folgenden grundlegenden Operatoren:
Arithmetik (Addition(+), Subtraktion(-), Multiplikation(*), Division(/), Modulus(%) ), Relational (<, >, <=, >=, ==, !=, ),
Zuordnung (=. +=, -=, /=, *=, %= ),
logisch (and, or not ), Mitgliedschaft, Identität und bitweise Operatoren
54. Was ist die „with-Anweisung“?
Die „with“-Anweisung in Python wird in der Ausnahmebehandlung verwendet. Eine Datei kann geöffnet und geschlossen werden, während ein Codeblock ausgeführt wird, der die „with“-Anweisung enthält, ohne die Funktion close() zu verwenden. Es macht den Code im Wesentlichen viel einfacher zu lesen.
55. Was ist eine map()-Funktion in Python?
Die Funktion map() in Python wird verwendet, um eine Funktion auf alle Elemente eines angegebenen Iterablen anzuwenden. Es besteht aus zwei Parametern, function und iterable. Die Funktion wird als Argument genommen und dann auf alle Elemente einer Iterable angewendet (als zweites Argument übergeben). Als Ergebnis wird eine Objektliste zurückgegeben.
def add(n):
return n + n number= (15, 25, 35, 45)
res= map(add, num)
print(list(res))
o/p: 30,50,70,90
56. Was ist __init__ in Python?
Die _init_-Methodik ist eine reservierte Methode in Python, auch bekannt als Konstruktor in OOP. Wenn ein Objekt aus einer Klasse erstellt wird und die _init_-Methodik aufgerufen wird, um auf die Klassenattribute zuzugreifen.
Lesen Sie auch: Python __init__- Ein Überblick
57. Welche Werkzeuge sind vorhanden, um statische Analysen durchzuführen?
Die beiden statischen Analysetools, die zum Auffinden von Fehlern in Python verwendet werden, sind Pychecker und Pylint. Pychecker erkennt Fehler im Quellcode und warnt vor dessen Stil und Komplexität. Während Pylint prüft, ob das Modul einem Codierungsstandard entspricht.
58. Was ist pass in Python?
Pass ist eine Anweisung, die nichts tut, wenn sie ausgeführt wird. Mit anderen Worten, es ist eine Null-Anweisung. Diese Anweisung wird vom Interpreter nicht ignoriert, aber die Anweisung führt zu keiner Operation. Es wird verwendet, wenn kein Befehl ausgeführt werden soll, aber eine Anweisung erforderlich ist.
59. Wie kann ein Objekt in Python kopiert werden?
Nicht alle Objekte können in Python kopiert werden, aber die meisten. Wir können den Operator „=“ verwenden, um ein Objekt in eine Variable zu kopieren.
ex:
var=copy.copy(obj)60. Wie kann eine Zahl in eine Zeichenfolge umgewandelt werden?
Die eingebaute Funktion str() kann verwendet werden, um eine Zahl in einen String umzuwandeln.
61. Was sind Module und Pakete in Python?
Module sind die Möglichkeit, ein Programm zu strukturieren. Jede Python-Programmdatei ist ein Modul, das andere Attribute und Objekte importiert. Der Ordner eines Programms ist ein Paket von Modulen. Ein Paket kann Module oder Unterordner haben.
62. Was ist die Funktion object() in Python?
In Python gibt die Funktion object() ein leeres Objekt zurück. Diesem Objekt können keine neuen Eigenschaften oder Methoden hinzugefügt werden.
63. Was ist der Unterschied zwischen NumPy und SciPy?
NumPy steht für Numerical Python, während SciPy für Scientific Python steht. NumPy ist die grundlegende Bibliothek zum Definieren von Arrays und einfachen mathematischen Problemen, während SciPy für komplexere Probleme wie numerische Integration und Optimierung sowie maschinelles Lernen usw. verwendet wird.
64. Was macht len()?
len() wird verwendet, um die Länge eines Strings, einer Liste, eines Arrays usw. zu bestimmen.
ex:
str = “greatlearning”
print(len(str))
o/p: 13
65. Kapselung in Python definieren?
Kapselung bedeutet, den Code und die Daten miteinander zu verbinden. Eine Python-Klasse zum Beispiel.
66. Was ist der Typ () in Python?
type() ist eine eingebaute Methode, die entweder den Typ des Objekts zurückgibt oder basierend auf den übergebenen Argumenten einen neuen Objekttyp zurückgibt.
ex:
a = 100
type(a)o/p: int
67. Wofür wird die Funktion split() verwendet?
Die Split-Funktion wird verwendet, um eine Zeichenfolge mithilfe definierter Trennzeichen in kürzere Zeichenfolgen aufzuteilen.
letters= ('' A, B, C”)
n = text.split(“,”)
print(n)o/p: ['A', 'B', 'C' ]
68. Welche eingebauten Typen bietet Python?
Python hat folgende eingebaute Datentypen:
Zahlen: Python identifiziert drei Arten von Zahlen:
- Ganzzahl: Alle positiven und negativen Zahlen ohne Nachkommastellen
- Float: Beliebige reelle Zahl mit Fließkommadarstellung
- Komplexe Zahlen: Eine Zahl mit einer reellen und einer imaginären Komponente, dargestellt als x+yj. x und y sind Floats und j ist -1 (Quadratwurzel von -1 wird als imaginäre Zahl bezeichnet)
Boolean: Der boolesche Datentyp ist ein Datentyp, der einen von zwei möglichen Werten hat, dh True oder False. Beachten Sie, dass „T“ und „F“ Großbuchstaben sind.
Zeichenfolge: Ein Zeichenfolgenwert ist eine Sammlung von einem oder mehreren Zeichen, die in einfache, doppelte oder dreifache Anführungszeichen gesetzt werden.
Liste: Ein Listenobjekt ist eine geordnete Sammlung von einem oder mehreren Datenelementen, die unterschiedlichen Typs sein können und in eckige Klammern gesetzt werden. Eine Liste ist veränderlich und kann somit geändert werden, wir können einzelne Elemente in einer Liste hinzufügen, bearbeiten oder löschen.
Set: Eine ungeordnete Sammlung einzigartiger Objekte, die in geschweiften Klammern eingeschlossen sind
Gefrorenes Set: Sie sind wie ein Satz, aber unveränderlich, was bedeutet, dass wir ihre Werte nicht ändern können, sobald sie erstellt wurden.
Wörterbuch: Ein Dictionary-Objekt ist ungeordnet, wobei jedem Wert ein Schlüssel zugeordnet ist und wir über seinen Schlüssel auf jeden Wert zugreifen können. Eine Sammlung solcher Paare ist in geschweiften Klammern eingeschlossen. Zum Beispiel {'Vorname': 'Tom', 'Nachname': 'Hardy'} Beachten Sie, dass Zahlenwerte, Zeichenfolgen und Tupel unveränderlich sind, während Listen- oder Wörterbuchobjekte veränderbar sind.
69. Was ist Docstring in Python?
Python-Docstrings sind die in dreifachen Anführungszeichen eingeschlossenen Zeichenfolgenliterale, die direkt nach der Definition einer Funktion, Methode, Klasse oder eines Moduls erscheinen. Diese werden im Allgemeinen verwendet, um die Funktionalität einer bestimmten Funktion, Methode, Klasse oder eines Moduls zu beschreiben. Wir können auf diese Docstrings mit dem Attribut __doc__ zugreifen.
Hier ist ein Beispiel:
def square(n): '''Takes in a number n, returns the square of n''' return n**2
print(square.__doc__)
Ausgabe: Nimmt eine Zahl n auf, gibt das Quadrat von n zurück.
70. Wie kehrt man eine Zeichenfolge in Python um?
In Python gibt es keine eingebauten Funktionen, die uns helfen, einen String umzukehren. Wir müssen dafür eine Array-Slicing-Operation verwenden.
| 1 | str_reverse = Zeichenfolge[::-1] |
Mehr erfahren: So kehren Sie eine Zeichenfolge in Python um
71. Wie überprüfe ich die Python-Version in CMD?
Um die Python-Version in CMD zu überprüfen, drücken Sie CMD + Leertaste. Dies öffnet Spotlight. Geben Sie hier „Terminal“ ein und drücken Sie die Eingabetaste. Um den Befehl auszuführen, geben Sie python –version oder python -V ein und drücken Sie die Eingabetaste. Dadurch wird die Python-Version in der nächsten Zeile unter dem Befehl zurückgegeben.
72. Wird in Python beim Umgang mit Bezeichnern zwischen Groß- und Kleinschreibung unterschieden?
Ja. Python unterscheidet beim Umgang mit Bezeichnern zwischen Groß- und Kleinschreibung. Es ist eine Sprache, die zwischen Groß- und Kleinschreibung unterscheidet. Variable und Variable wären also nicht dasselbe.
Python-Interviewfragen für Erfahrene
Dieser Abschnitt über Python-Interviewfragen für Erfahrene behandelt mehr als 20 Fragen, die häufig während des Vorstellungsgesprächs gestellt werden, um einen Job als erfahrener Python-Experte zu bekommen. Diese häufig gestellten Fragen können Ihnen helfen, Ihre Fähigkeiten aufzufrischen und zu wissen, was Sie in Ihren bevorstehenden Vorstellungsgesprächen erwartet.
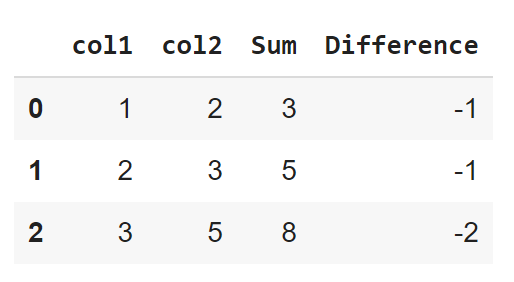
73. Wie erstelle ich eine neue Spalte in Pandas, indem ich Werte aus anderen Spalten verwende?
Wir können spaltenbasierte mathematische Operationen an einem Pandas-Datenrahmen durchführen. Pandas-Spalten, die numerische Werte enthalten, können von Operatoren bearbeitet werden.
Code:
import pandas as pd
a=[1,2,3]
b=[2,3,5]
d={"col1":a,"col2":b}
df=pd.DataFrame(d)
df["Sum"]=df["col1"]+df["col2"]
df["Difference"]=df["col1"]-df["col2"]
dfAusgang:
74. Was sind die verschiedenen Funktionen, die von grouby in Pandas verwendet werden können?
grouby() in Pandas kann mit mehreren Aggregatfunktionen verwendet werden. Einige davon sind sum(),mean(), count(),std().
Daten werden anhand von Kategorien in Gruppen eingeteilt, und dann können die Daten in diesen einzelnen Gruppen durch die oben genannten Funktionen aggregiert werden.
75. Wie lösche ich eine Spalte oder eine Gruppe von Spalten in Pandas? Angesichts der Drop-Spalte „col1“ des Datenrahmens unten.
Die Funktion drop () kann verwendet werden, um die Spalten aus einem Datenrahmen zu löschen.
d={"col1":[1,2,3],"col2":["A","B","C"]}
df=pd.DataFrame(d)
df=df.drop(["col1"],axis=1)
df
76. Angesichts des folgenden Datenrahmens werden Zeilen mit Spaltenwerten wie A gelöscht.
Code:
d={"col1":[1,2,3],"col2":["A","B","C"]}
df=pd.DataFrame(d)
df.dropna(inplace=True)
df=df[df.col1!=1]
df
77. Was ist Neuindizierung bei Pandas?
Bei der Neuindizierung wird der Index eines Pandas-Datenrahmens neu zugewiesen.
Code:
import pandas as pd
bikes=["bajaj","tvs","herohonda","kawasaki","bmw"]
cars=["lamborghini","masserati","ferrari","hyundai","ford"]
d={"cars":cars,"bikes":bikes}
df=pd.DataFrame(d)
a=[10,20,30,40,50]
df.index=a
df
78. Was verstehst du über die Lambda-Funktion? Erstellen Sie eine Lambda-Funktion, die die Summe aller Elemente in dieser Liste ausgibt -> [5, 8, 10, 20, 50, 100]
Lambda-Funktionen sind anonyme Funktionen in Python. Sie werden mit dem Schlüsselwort Lambda definiert. Lambda-Funktionen können eine beliebige Anzahl von Argumenten annehmen, aber sie können nur einen Ausdruck haben.
from functools import reduce
sequences = [5, 8, 10, 20, 50, 100]
sum = reduce (lambda x, y: x+y, sequences)
print(sum)
79. Was ist vstack() in numpy? Gib ein Beispiel.
vstack() ist eine Funktion zum vertikalen Ausrichten von Zeilen. Alle Zeilen müssen die gleiche Anzahl von Elementen haben.
Code:
import numpy as np
n1=np.array([10,20,30,40,50])
n2=np.array([50,60,70,80,90])
print(np.vstack((n1,n2)))
80. Wie entferne ich Leerzeichen aus einer Zeichenfolge in Python?
Leerzeichen können aus einer Zeichenfolge in Python entfernt werden, indem die Funktionen strip() oder replace() verwendet werden. Die Strip()-Funktion wird verwendet, um die führenden und abschließenden Leerzeichen zu entfernen, während die replace()-Funktion verwendet wird, um alle Leerzeichen in der Zeichenfolge zu entfernen:
string.replace(” “,””) ex1: str1= “great learning”
print (str.strip())
o/p: great learning
ex2: str2=”great learning”
print (str.replace(” “,””))
o/p: tolles Lernen
81. Erklären Sie die von Python unterstützten Dateiverarbeitungsmodi.
Es gibt drei Dateiverarbeitungsmodi in Python: Nur-Lesen (r), Nur-Schreiben (w), Lesen-Schreiben (rw) und Anhängen (a). Wenn Sie also eine Textdatei beispielsweise im Lesemodus öffnen. Die vorhergehenden Modi werden zu „rt“ für Nur-Lesen, „wt“ für Schreiben und so weiter. In ähnlicher Weise kann eine Binärdatei geöffnet werden, indem „b“ zusammen mit den vorangestellten Dateizugriffs-Flags („r“, „w“, „rw“ und „a“) angegeben wird.
82. Was ist Pökeln und Entpökeln?
Pickling ist der Prozess der Umwandlung einer Python-Objekthierarchie in einen Bytestrom, um ihn in einer Datenbank zu speichern. Dies wird auch als Serialisierung bezeichnet. Das Entpökeln ist die Umkehrung des Pökelns. Der Bytestrom wird zurück in eine Objekthierarchie umgewandelt.
83. Wie wird der Speicher in Python verwaltet?
Dies ist eine der am häufigsten gestellten Python-Interviewfragen
Die Speicherverwaltung in Python umfasst einen privaten Heap, der alle Objekte und Datenstrukturen enthält. Der Heap wird vom Interpreter verwaltet und der Programmierer hat überhaupt keinen Zugriff darauf. Der Python-Speichermanager übernimmt die gesamte Speicherzuweisung. Darüber hinaus gibt es einen eingebauten Garbage Collector, der Speicher für den Heap-Speicher recycelt und freigibt.
84. Was ist unittest in Python?
Unittest ist ein Unit-Testing-Framework in Python. Es unterstützt die gemeinsame Nutzung von Setup- und Shutdown-Code für Tests, die Aggregation von Tests in Sammlungen, die Testautomatisierung und die Unabhängigkeit der Tests vom Reporting-Framework.
85. Wie löscht man eine Datei in Python?
Dateien können in Python mit dem Befehl os.remove (Dateiname) oder os.unlink(Dateiname) gelöscht werden.
86. Wie erstellt man eine leere Klasse in Python?
Um eine leere Klasse zu erstellen, können wir den Pass-Befehl nach der Definition des Klassenobjekts verwenden. Ein Pass ist eine Anweisung in Python, die nichts bewirkt.
87. Was sind Python-Dekoratoren?
Decorators sind Funktionen, die eine andere Funktion als Argument verwenden, um ihr Verhalten zu ändern, ohne die Funktion selbst zu ändern. Diese sind nützlich, wenn wir die Funktionalität einer Funktion dynamisch erweitern möchten, ohne sie zu ändern.
Hier ist ein Beispiel:
def smart_divide(func): def inner(a, b): print("Dividing", a, "by", b) if b == 0: print("Make sure Denominator is not zero") return
return func(a, b) return inner
@smart_divide
def divide(a, b): print(a/b)
divide(1,0)
Hier ist smart_divide eine Decorator-Funktion, die verwendet wird, um der einfachen Divisionsfunktion Funktionalität hinzuzufügen.
88. Was ist eine dynamisch typisierte Sprache?
Die Typprüfung ist ein wichtiger Bestandteil jeder Programmiersprache, bei der es darum geht, minimale Typfehler sicherzustellen. Der für Variablen definierte Typ wird entweder zur Kompilierzeit oder zur Laufzeit überprüft. Wenn die Typprüfung zur Kompilierzeit durchgeführt wird, wird sie als statisch typisierte Sprache bezeichnet, und wenn die Typprüfung zur Laufzeit durchgeführt wird, wird sie als dynamisch typisierte Sprache bezeichnet.
- In der dynamisch typisierten Sprache werden die Objekte zur Laufzeit mit Typ-durch-Zuweisungen gebunden.
- Dynamisch typisierte Programmiersprachen produzieren vergleichsweise weniger optimierten Code
- In dynamisch typisierten Sprachen müssen Typen für Variablen nicht definiert werden, bevor sie verwendet werden. Daher kann es dynamisch zugewiesen werden.
89. Was ist Slicing in Python?
Slicing in Python bezieht sich auf den Zugriff auf Teile einer Sequenz. Die Sequenz kann ein beliebiges änderbares und iterierbares Objekt sein. Slice( ) ist eine Funktion, die in Python verwendet wird, um die gegebene Sequenz in erforderliche Segmente zu unterteilen.
Es gibt zwei Varianten, die Slice-Funktion zu verwenden. Syntax zum Slicen in Python:
- Scheibe (Start, Stopp)
- Kieselsäure (Start, Stopp, Schritt)
Ex:
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
substr1 = slice(3, 5)
print(Str1[substr1])
//same code can be written in the following way also Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
print(Str1[3,5])
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
substr1 = slice(0, 14, 2)
print(Str1[substr1]) //same code can be written in the following way also
Str1 = ("g", "r", "e", "a", "t", "l", "e", "a", “r”, “n”, “i”, “n”, “g”)
print(Str1[0,14, 2])
90. Was ist der Unterschied zwischen Python-Arrays und Listen?
Python Arrays und List sind beide geordnete Sammlungen von Elementen und veränderbar, aber der Unterschied liegt in der Arbeit mit ihnen
Arrays speichern heterogene Daten, wenn sie aus dem Array-Modul importiert werden, aber Arrays können homogene Daten speichern, die aus dem numpy-Modul importiert werden. Aber Listen können heterogene Daten speichern, und um Listen zu verwenden, müssen sie nicht aus irgendeinem Modul importiert werden.
import array as a1
array1 = a1.array('i', [1 , 2 ,5] )
print (array1)
Oder,
import numpy as a2
array2 = a2.array([5, 6, 9, 2]) print(array2) - Arrays müssen vor der Verwendung deklariert werden, Listen müssen jedoch nicht deklariert werden.
- Numerische Operationen sind auf Arrays einfacher durchzuführen als auf Listen.
91. Was ist Bereichsauflösung in Python?
Die Zugänglichkeit der Variablen wird in Python gemäß der Position der Variablendeklaration definiert, die in Python als Gültigkeitsbereich von Variablen bezeichnet wird. Die Bereichsauflösung bezieht sich auf die Reihenfolge, in der diese Variablen nach einem Namen für die Variablenübereinstimmung gesucht werden. Im Folgenden ist der in Python definierte Bereich für die Variablendeklaration aufgeführt.
a. Lokaler Geltungsbereich – Die innerhalb einer Schleife deklarierte Variable, der Funktionsrumpf ist nur innerhalb dieser Funktion oder Schleife zugänglich.
b. Globaler Geltungsbereich – Die Variable wird außerhalb jedes anderen Codes auf der obersten Ebene deklariert und ist überall zugänglich.
c. Einschließender Geltungsbereich – Die Variable wird innerhalb einer einschließenden Funktion deklariert, auf die nur innerhalb dieser einschließenden Funktion zugegriffen werden kann.
d. Eingebauter Geltungsbereich – Die in den eingebauten Funktionen verschiedener Python-Module deklarierte Variable hat den eingebauten Geltungsbereich und ist nur innerhalb dieses bestimmten Moduls zugänglich.
Die Bereichsauflösung für jede Variable wird in Java in einer bestimmten Reihenfolge vorgenommen, und diese Reihenfolge ist
Lokaler Geltungsbereich -> umschließender Geltungsbereich -> globaler Geltungsbereich -> integrierter Geltungsbereich
92. Was sind Diktat- und Listenverständnis?
List Comprehensions bieten eine kompaktere und elegantere Möglichkeit, Listen zu erstellen als For-Schleifen, und auch eine neue Liste kann aus vorhandenen Listen erstellt werden.
Die verwendete Syntax lautet wie folgt:
a for a in iterator
Oder,
a for a in iterator if condition
Ex:
list1 = [a for a in range(5)]
print(list1)
list2 = [a for a in range(5) if a < 3]
print(list2)
Wörterbuchverständnisse bieten eine kompaktere und elegantere Möglichkeit, ein Wörterbuch zu erstellen, und außerdem kann ein neues Wörterbuch aus vorhandenen Wörterbüchern erstellt werden.
Die verwendete Syntax lautet:
{key: expression for an item in iterator}
Ex:
dict([(i, i*2) for i in range(5)])
93. Was ist der Unterschied zwischen xrange und range in Python?
range() und xrange() sind eingebaute Funktionen in Python, die zum Generieren von Ganzzahlen im angegebenen Bereich verwendet werden. Der Unterschied zwischen den beiden kann verstanden werden, wenn die Python-Version 2.0 verwendet wird, da die xrange()-Funktion der Python-Version 3.0 als die range()-Funktion selbst neu implementiert wird.
In Bezug auf Python 2.0 ist der Unterschied zwischen range- und xrange-Funktion wie folgt:
- range() benötigt vergleichsweise mehr Speicher
- xrange() ist die Ausführungsgeschwindigkeit vergleichsweise schneller
- range() gibt eine Liste von ganzen Zahlen zurück und xrange() gibt ein Generatorobjekt zurück.
Exreichlich:
for i in range(1,10,2): print(i) 94. Was ist der Unterschied zwischen .py- und .pyc-Dateien?
.py sind die Quellcodedateien in Python, die der Python-Interpreter interpretiert.
.pyc sind die kompilierten Dateien, die vom Python-Compiler generierte Bytecodes sind, aber .pyc-Dateien werden nur für eingebaute Module/Dateien erstellt.
Fragen in Vorstellungsgesprächen zur Python-Programmierung
Neben theoretischem Wissen sind praktische Erfahrungen und das Wissen um die Programmierung von Interviewfragen ein entscheidender Bestandteil des Interviewprozesses. Es hilft den Personalvermittlern, Ihre praktische Erfahrung zu verstehen. Dies sind über 45 der am häufigsten gestellten Fragen in Vorstellungsgesprächen zur Python-Programmierung.
Hier ist eine bildliche Darstellung, wie die Ausgabe der Python-Programmierung generiert wird.

95. Sie haben diesen Covid-19-Datensatz unten:
Dies ist eine der am häufigsten gestellten Python-Interviewfragen
Wie erstellen Sie aus diesem Datensatz ein Balkendiagramm für die 5 Bundesstaaten mit den meisten bestätigten Fällen vom 17?
Sol:
#keeping only required columns df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]] #renaming column names df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’] #current date today = df[df.date == ‘2020-07-17’] #Sorting data w.r.t number of confirmed cases max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False) max_confirmed_cases #Getting states with maximum number of confirmed cases top_states_confirmed=max_confirmed_cases[0:5] #Making bar-plot for states with top confirmed cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”) plt.show()
Code-Erklärung:
Wir beginnen damit, dass wir mit diesem Befehl nur die erforderlichen Spalten übernehmen:
df = df[[‘Date’, ‘State/UnionTerritory’,’Cured’,’Deaths’,’Confirmed’]]
Dann gehen wir weiter und benennen die Spalten um:
df.columns = [‘date’, ‘state’,’cured’,’deaths’,’confirmed’]
Danach extrahieren wir nur die Datensätze, bei denen das Datum gleich dem 17. Juli ist:
today = df[df.date == ‘2020-07-17’]
Dann gehen wir weiter und wählen die Top 5 Staaten mit maximaler Nr. von Covid-Fällen:
max_confirmed_cases=today.sort_values(by=”confirmed”,ascending=False)
max_confirmed_cases
top_states_confirmed=max_confirmed_cases[0:5]
Schließlich machen wir weiter und erstellen damit ein Balkendiagramm:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.barplot(x=”state”,y=”confirmed”,data=top_states_confirmed,hue=”state”)
plt.show()
Hier verwenden wir die Seaborn-Bibliothek, um das Balkendiagramm zu erstellen. Die Spalte „Zustand“ wird auf der x-Achse und die Spalte „bestätigt“ auf der y-Achse abgebildet. Die Farbe der Balken wird durch die Spalte „Zustand“ bestimmt.
96. Aus diesem Covid-19-Datensatz:
Wie können Sie ein Balkendiagramm für die 5 Bundesstaaten mit den meisten Todesfällen erstellen?
max_death_cases=today.sort_values(by=”deaths”,ascending=False) max_death_cases sns.set(rc={‘figure.figsize’:(15,10)}) sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”) plt.show()
Code-Erklärung:
Wir beginnen damit, dass wir unseren Datenrahmen in absteigender Reihenfolge nach der Spalte „Todesfälle“ sortieren:
max_death_cases=today.sort_values(by=”deaths”,ascending=False)
Max_death_cases
Dann machen wir weiter und erstellen das Balkendiagramm mit Hilfe der Seaborn-Bibliothek:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.barplot(x=”state”,y=”deaths”,data=top_states_death,hue=”state”)
plt.show()
Hier bilden wir die Spalte „Staat“ auf der x-Achse und die Spalte „Todesfälle“ auf der y-Achse ab.
97. Aus diesem Covid-19-Datensatz:
Wie können Sie ein Liniendiagramm erstellen, das die bestätigten Fälle in Bezug auf das Datum anzeigt?
Sol:
maha = df[df.state == ‘Maharashtra’] sns.set(rc={‘figure.figsize’:(15,10)}) sns.lineplot(x=”date”,y=”confirmed”,data=maha,color=”g”) plt.show()
Code-Erklärung:
Wir beginnen damit, alle Datensätze zu extrahieren, bei denen der Staat gleich „Maharashtra“ ist:
maha = df[df.state == ‘Maharashtra’]
Dann machen wir weiter und erstellen ein Liniendiagramm mit der Seaborn-Bibliothek:
sns.set(rc={‘figure.figsize’:(15,10)})
sns.lineplot(x=”date”,y=”confirmed”,data=maha,color=”g”)
plt.show()
Hier bilden wir die Spalte „Datum“ auf der x-Achse und die Spalte „bestätigt“ auf der y-Achse ab.
98. Zu diesem „Maharashtra“-Datensatz:
Wie implementieren Sie einen linearen Regressionsalgorithmus mit „Datum“ als unabhängiger Variable und „bestätigt“ als abhängiger Variable? Das heißt, Sie müssen die Anzahl der bestätigten Fälle zum Datum vorhersagen.
from sklearn.model_selection import train_test_split maha[‘date’]=maha[‘date’].map(dt.datetime.toordinal) maha.head() x=maha[‘date’] y=maha[‘confirmed’] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(np.array(x_train).reshape(-1,1),np.array(y_train).reshape(-1,1)) lr.predict(np.array([[737630]]))
Code-Lösung:
Wir beginnen mit der Konvertierung des Datums in den Ordinaltyp:
from sklearn.model_selection import train_test_split
maha[‘date’]=maha[‘date’].map(dt.datetime.toordinal)
Dies geschieht, weil wir den linearen Regressionsalgorithmus nicht auf der Datumsspalte aufbauen können.
Dann teilen wir den Datensatz in Trainings- und Testsätze auf:
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
Schließlich machen wir weiter und bauen das Modell:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(np.array(x_train).reshape(-1,1),np.array(y_train).reshape(-1,1))
lr.predict(np.array([[737630]]))
99. Zu diesem Datensatz „customer_churn“:
Dies ist eine der am häufigsten gestellten Python-Interviewfragen
Erstellen Sie ein sequenzielles Keras-Modell, um herauszufinden, wie viele Kunden auf der Grundlage der Betriebszugehörigkeit des Kunden abwandern werden.
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(12, input_dim=1, activation=’relu’)) model.add(Dense(8, activation=’relu’)) model.add(Dense(1, activation=’sigmoid’)) model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) model.fit(x_train, y_train, epochs=150,validation_data=(x_test,y_test)) y_pred = model.predict_classes(x_test) from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_pred)
Code-Erklärung:
Wir beginnen mit dem Importieren der erforderlichen Bibliotheken:
from Keras.models import Sequential
from Keras.layers import Dense
Dann machen wir weiter und bauen die Struktur des sequentiellen Modells auf:
model = Sequential()
model.add(Dense(12, input_dim=1, activation=’relu’))
model.add(Dense(8, activation=’relu’))
model.add(Dense(1, activation=’sigmoid’))
Schließlich werden wir fortfahren und die Werte vorhersagen:
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
model.fit(x_train, y_train, epochs=150,validation_data=(x_test,y_test))
y_pred = model.predict_classes(x_test)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_pred)
100. Auf diesem Iris-Datensatz:
Erstellen Sie ein Entscheidungsbaum-Klassifizierungsmodell, bei dem die abhängige Variable „Species“ und die unabhängige Variable „Sepal.Length“ ist.
y = iris[[‘Species’]] x = iris[[‘Sepal.Length’]] from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4) from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier() dtc.fit(x_train,y_train) y_pred=dtc.predict(x_test) from sklearn.metrics import confusion_matrix confusion_matrix(y_test,y_pred)
(22+7+9)/(22+2+0+7+7+11+1+1+9)
Code-Erklärung:
Wir beginnen mit dem Extrahieren der unabhängigen Variablen und der abhängigen Variablen:
y = iris[[‘Species’]]
x = iris[[‘Sepal.Length’]]
Dann gehen wir weiter und teilen die Daten in Zug und Testsatz auf:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.4)
Danach machen wir weiter und bauen das Modell:
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(x_train,y_train)
y_pred=dtc.predict(x_test)
Schließlich bauen wir die Konfusionsmatrix auf:
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_pred)
(22+7+9)/(22+2+0+7+7+11+1+1+9)
101. Auf diesem Iris-Datensatz:
Erstellen Sie ein Entscheidungsbaum-Regressionsmodell, bei dem die unabhängige Variable „Blütenblattlänge“ und die abhängige Variable „Sepallänge“ ist.
x= iris[[‘Petal.Length’]] y = iris[[‘Sepal.Length’]] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25) from sklearn.tree import DecisionTreeRegressor dtr = DecisionTreeRegressor() dtr.fit(x_train,y_train) y_pred=dtr.predict(x_test) y_pred[0:5] from sklearn.metrics import mean_squared_error mean_squared_error(y_test,y_pred)
102. Wie werden Sie Daten von der Website „Cricbuzz“ kratzen?
import sys import time from bs4 import BeautifulSoup import requests import pandas as pd try: #use the browser to get the url. This is suspicious command that might blow up. page=requests.get(‘cricbuzz.com’) # this might throw an exception if something goes wrong. except Exception as e: # this describes what to do if an exception is thrown error_type, error_obj, error_info = sys.exc_info() # get the exception information print (‘ERROR FOR LINK:’,url) #print the link that cause the problem print (error_type, ‘Line:’, error_info.tb_lineno) #print error info and line that threw the exception #ignore this page. Abandon this and go back. time.sleep(2) soup=BeautifulSoup(page.text,’html.parser’) links=soup.find_all(‘span’,attrs={‘class’:’w_tle’}) links for i in links: print(i.text) print(“n”)
103. Schreiben Sie eine benutzerdefinierte Funktion, um den zentralen Grenzwertsatz zu implementieren. Sie müssen den zentralen Grenzwertsatz auf diesem „Versicherungs“-Datensatz implementieren:
Sie müssen auch zwei Diagramme zu „Stichprobenverteilung des BMI“ und „Bevölkerungsverteilung des BMI“ erstellen.
df = pd.read_csv(‘insurance.csv’) series1 = df.charges series1.dtype def central_limit_theorem(data,n_samples = 1000, sample_size = 500, min_value = 0, max_value = 1338): “”” Use this function to demonstrate Central Limit Theorem. data = 1D array, or a pd.Series n_samples = number of samples to be created sample_size = size of the individual sample min_value = minimum index of the data max_value = maximum index value of the data “”” %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns b = {} for i in range(n_samples): x = np.unique(np.random.randint(min_value, max_value, size = sample_size)) # set of random numbers with a specific size b[i] = data[x].mean() # Mean of each sample c = pd.DataFrame() c[‘sample’] = b.keys() # Sample number c[‘Mean’] = b.values() # mean of that particular sample plt.figure(figsize= (15,5)) plt.subplot(1,2,1) sns.distplot(c.Mean) plt.title(f”Sampling Distribution of bmi. n u03bc = {round(c.Mean.mean(), 3)} & SE = {round(c.Mean.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.subplot(1,2,2) sns.distplot(data) plt.title(f”population Distribution of bmi. n u03bc = {round(data.mean(), 3)} & u03C3 = {round(data.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.show() central_limit_theorem(series1,n_samples = 5000, sample_size = 500)
Code-Erklärung:
Wir beginnen mit dem Importieren der Datei „insurance.csv“ mit diesem Befehl:
df = pd.read_csv(‘insurance.csv’)
Dann machen wir weiter und definieren die Methode des zentralen Grenzwertsatzes:
def central_limit_theorem(data,n_samples = 1000, sample_size = 500, min_value = 0, max_value = 1338):
Diese Methode umfasst die folgenden Parameter:
- Datum
- N_Beispiele
- Beispielgröße
- Min_Wert
- Max_Wert
Innerhalb dieser Methode importieren wir alle erforderlichen Bibliotheken:
mport pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Dann machen wir weiter und erstellen den ersten Teilplot für „Stichprobenverteilung von bmi“:
plt.subplot(1,2,1) sns.distplot(c.Mean) plt.title(f”Sampling Distribution of bmi. n u03bc = {round(c.Mean.mean(), 3)} & SE = {round(c.Mean.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’)
Schließlich erstellen wir den Subplot für „Bevölkerungsverteilung des BMI“:
plt.subplot(1,2,2) sns.distplot(data) plt.title(f”population Distribution of bmi. n u03bc = {round(data.mean(), 3)} & u03C3 = {round(data.std(),3)}”) plt.xlabel(‘data’) plt.ylabel(‘freq’) plt.show()
104. Schreiben Sie Code, um Stimmungsanalysen für Amazon-Rezensionen durchzuführen:
Dies ist eine der am häufigsten gestellten Python-Interviewfragen.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from tensorflow.python.keras import models, layers, optimizers import tensorflow from tensorflow.keras.preprocessing.text import Tokenizer, text_to_word_sequence from tensorflow.keras.preprocessing.sequence import pad_sequences import bz2 from sklearn.metrics import f1_score, roc_auc_score, accuracy_score import re %matplotlib inline def get_labels_and_texts(file): labels = [] texts = [] for line in bz2.BZ2File(file): x = line.decode(“utf-8”) labels.append(int(x[9]) – 1) texts.append(x[10:].strip()) return np.array(labels), texts train_labels, train_texts = get_labels_and_texts(‘train.ft.txt.bz2’) test_labels, test_texts = get_labels_and_texts(‘test.ft.txt.bz2’) Train_labels[0] Train_texts[0] train_labels=train_labels[0:500] train_texts=train_texts[0:500] import re NON_ALPHANUM = re.compile(r'[W]’) NON_ASCII = re.compile(r'[^a-z0-1s]’) def normalize_texts(texts): normalized_texts = [] for text in texts: lower = text.lower() no_punctuation = NON_ALPHANUM.sub(r’ ‘, lower) no_non_ascii = NON_ASCII.sub(r”, no_punctuation) normalized_texts.append(no_non_ascii) return normalized_texts train_texts = normalize_texts(train_texts) test_texts = normalize_texts(test_texts) from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(binary=True) cv.fit(train_texts) X = cv.transform(train_texts) X_test = cv.transform(test_texts) from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split X_train, X_val, y_train, y_val = train_test_split( X, train_labels, train_size = 0.75) for c in [0.01, 0.05, 0.25, 0.5, 1]: lr = LogisticRegression(C=c) lr.fit(X_train, y_train) print (“Accuracy for C=%s: %s” % (c, accuracy_score(y_val, lr.predict(X_val)))) lr.predict(X_test[29])
105. Implementieren Sie ein Wahrscheinlichkeitsnetz mit numpy und matplotlib:
Sol:
import numpy as np import pylab import scipy.stats as stats from matplotlib import pyplot as plt n1=np.random.normal(loc=0,scale=1,size=1000) np.percentile(n1,100) n1=np.random.normal(loc=20,scale=3,size=100) stats.probplot(n1,dist=”norm”,plot=pylab) plt.show()
106. Implementieren Sie eine multiple lineare Regression für diesen Iris-Datensatz:
Die unabhängigen Variablen sollten „Sepal.Width“, „Petal.Length“, „Petal.Width“ sein, während die abhängige Variable „Sepal.Length“ sein sollte.
Sol:
import pandas as pd iris = pd.read_csv(“iris.csv”) iris.head() x = iris[[‘Sepal.Width’,’Petal.Length’,’Petal.Width’]] y = iris[[‘Sepal.Length’]] from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.35) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(x_train, y_train) y_pred = lr.predict(x_test) from sklearn.metrics import mean_squared_error mean_squared_error(y_test, y_pred)
Code-Lösung:
Wir beginnen mit dem Importieren der erforderlichen Bibliotheken:
import pandas as pd
iris = pd.read_csv(“iris.csv”)
iris.head()
Dann werden wir fortfahren und die unabhängigen Variablen und die abhängige Variable extrahieren:
x = iris[[‘Sepal.Width’,’Petal.Length’,’Petal.Width’]]
y = iris[[‘Sepal.Length’]]
Anschließend unterteilen wir die Daten in Trainings- und Testdatensätze:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.35)
Dann machen wir weiter und bauen das Modell:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train, y_train)
y_pred = lr.predict(x_test)
Schließlich werden wir den mittleren quadratischen Fehler herausfinden:
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred)
107. Aus diesem Kreditbetrugsdatensatz:
Ermitteln Sie den Prozentsatz der Transaktionen, die betrügerisch und nicht betrügerisch sind. Erstellen Sie auch ein logistisches Regressionsmodell, um herauszufinden, ob die Transaktion betrügerisch ist oder nicht.
Sol:
nfcount=0 notFraud=data_df[‘Class’] for i in range(len(notFraud)): if notFraud[i]==0: nfcount=nfcount+1 nfcount per_nf=(nfcount/len(notFraud))*100 print(‘percentage of total not fraud transaction in the dataset: ‘,per_nf) fcount=0 Fraud=data_df[‘Class’] for i in range(len(Fraud)): if Fraud[i]==1: fcount=fcount+1 fcount per_f=(fcount/len(Fraud))*100 print(‘percentage of total fraud transaction in the dataset: ‘,per_f) x=data_df.drop([‘Class’], axis = 1)#drop the target variable y=data_df[‘Class’] xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size = 0.2, random_state = 42) logisticreg = LogisticRegression() logisticreg.fit(xtrain, ytrain) y_pred = logisticreg.predict(xtest) accuracy= logisticreg.score(xtest,ytest) cm = metrics.confusion_matrix(ytest, y_pred) print(cm)
108. Implementieren Sie ein einfaches CNN auf dem MNIST-Datensatz mit Keras. Im Anschluss daran, fügen Sie auch Drop-out hinzu Schichten.
Sol:
from __future__ import absolute_import, division, print_function import numpy as np # import keras from tensorflow.keras.datasets import cifar10, mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Reshape from tensorflow.keras.layers import Convolution2D, MaxPooling2D from tensorflow.keras import utils import pickle from matplotlib import pyplot as plt import seaborn as sns plt.rcParams[‘figure.figsize’] = (15, 8) %matplotlib inline # Load/Prep the Data (x_train, y_train_num), (x_test, y_test_num) = mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype(‘float32’) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype(‘float32’) x_train /= 255 x_test /= 255 y_train = utils.to_categorical(y_train_num, 10) y_test = utils.to_categorical(y_test_num, 10) print(‘— THE DATA —‘) print(‘x_train shape:’, x_train.shape) print(x_train.shape[0], ‘train samples’) print(x_test.shape[0], ‘test samples’) TRAIN = False BATCH_SIZE = 32 EPOCHS = 1 # Define the Type of Model model1 = tf.keras.Sequential() # Flatten Imgaes to Vector model1.add(Reshape((784,), input_shape=(28, 28, 1))) # Layer 1 model1.add(Dense(128, kernel_initializer=’he_normal’, use_bias=True)) model1.add(Activation(“relu”)) # Layer 2 model1.add(Dense(10, kernel_initializer=’he_normal’, use_bias=True)) model1.add(Activation(“softmax”)) # Loss and Optimizer model1.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) # Store Training Results early_stopping = keras.callbacks.EarlyStopping(monitor=’val_acc’, patience=10, verbose=1, mode=’auto’) callback_list = [early_stopping]# [stats, early_stopping] # Train the model model1.fit(x_train, y_train, nb_epoch=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), callbacks=callback_list, verbose=True) #drop-out layers: # Define Model model3 = tf.keras.Sequential() # 1st Conv Layer model3.add(Convolution2D(32, (3, 3), input_shape=(28, 28, 1))) model3.add(Activation(‘relu’)) # 2nd Conv Layer model3.add(Convolution2D(32, (3, 3))) model3.add(Activation(‘relu’)) # Max Pooling model3.add(MaxPooling2D(pool_size=(2,2))) # Dropout model3.add(Dropout(0.25)) # Fully Connected Layer model3.add(Flatten()) model3.add(Dense(128)) model3.add(Activation(‘relu’)) # More Dropout model3.add(Dropout(0.5)) # Prediction Layer model3.add(Dense(10)) model3.add(Activation(‘softmax’)) # Loss and Optimizer model3.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’]) # Store Training Results early_stopping = tf.keras.callbacks.EarlyStopping(monitor=’val_acc’, patience=7, verbose=1, mode=’auto’) callback_list = [early_stopping] # Train the model model3.fit(x_train, y_train, batch_size=BATCH_SIZE, nb_epoch=EPOCHS, validation_data=(x_test, y_test), callbacks=callback_list)
109. Implementieren Sie ein auf Popularität basierendes Empfehlungssystem für diesen Filmobjektiv-Datensatz:
import os import numpy as np import pandas as pd ratings_data = pd.read_csv(“ratings.csv”) ratings_data.head() movie_names = pd.read_csv(“movies.csv”) movie_names.head() movie_data = pd.merge(ratings_data, movie_names, on=’movieId’) movie_data.groupby(‘title’)[‘rating’].mean().head() movie_data.groupby(‘title’)[‘rating’].mean().sort_values(ascending=False).head() movie_data.groupby(‘title’)[‘rating’].count().sort_values(ascending=False).head() ratings_mean_count = pd.DataFrame(movie_data.groupby(‘title’)[‘rating’].mean()) ratings_mean_count.head() ratings_mean_count[‘rating_counts’] = pd.DataFrame(movie_data.groupby(‘title’)[‘rating’].count()) ratings_mean_count.head() 110. Implementieren Sie den naiven Bayes-Algorithmus zusätzlich zum Diabetes-Datensatz:
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import matplotlib.pyplot as plt # matplotlib.pyplot plots data %matplotlib inline import seaborn as sns pdata = pd.read_csv(“pima-indians-diabetes.csv”) columns = list(pdata)[0:-1] # Excluding Outcome column which has only pdata[columns].hist(stacked=False, bins=100, figsize=(12,30), layout=(14,2)); # Histogram of first 8 columns
Wir möchten jedoch eine Korrelation in der grafischen Darstellung sehen, also ist unten die Funktion dafür:
def plot_corr(df, size=11): corr = df.corr() fig, ax = plt.subplots(figsize=(size, size)) ax.matshow(corr) plt.xticks(range(len(corr.columns)), corr.columns) plt.yticks(range(len(corr.columns)), corr.columns) plot_corr(pdata)
from sklearn.model_selection import train_test_split X = pdata.drop(‘class’,axis=1) # Predictor feature columns (8 X m) Y = pdata[‘class’] # Predicted class (1=True, 0=False) (1 X m) x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=1) # 1 is just any random seed number x_train.head() from sklearn.naive_bayes import GaussianNB # using Gaussian algorithm from Naive Bayes # creatw the model diab_model = GaussianNB() diab_model.fit(x_train, y_train.ravel()) diab_train_predict = diab_model.predict(x_train) from sklearn import metrics print(“Model Accuracy: {0:.4f}”.format(metrics.accuracy_score(y_train, diab_train_predict))) print() diab_test_predict = diab_model.predict(x_test) from sklearn import metrics print(“Model Accuracy: {0:.4f}”.format(metrics.accuracy_score(y_test, diab_test_predict))) print() print(“Confusion Matrix”) cm=metrics.confusion_matrix(y_test, diab_test_predict, labels=[1, 0]) df_cm = pd.DataFrame(cm, index = [i for i in [“1″,”0”]], columns = [i for i in [“Predict 1″,”Predict 0”]]) plt.figure(figsize = (7,5)) sns.heatmap(df_cm, annot=True)
111. Wie können Sie die minimalen und maximalen Werte finden, die in einem Tupel vorhanden sind?
Lösung ->
Wir können die Funktion min() über dem Tupel verwenden, um den im Tupel vorhandenen Mindestwert herauszufinden:
tup1=(1,2,3,4,5)
min(tup1)
Output
1
Wir sehen, dass der im Tupel vorhandene Mindestwert 1 ist.
Analog zur min()-Funktion ist die max()-Funktion, die uns hilft, den im Tupel vorhandenen Maximalwert herauszufinden:
tup1=(1,2,3,4,5)
max(tup1)
Output
5
Wir sehen, dass der im Tupel vorhandene Maximalwert 5 ist.
112. Wenn Sie eine Liste wie diese haben -> [1,”a”,2,”b”,3,”c”]. Wie können Sie auf das 2., 4. und 5. Element dieser Liste zugreifen?
Lösung ->
Wir beginnen mit der Erstellung eines Tupels, das die Indizes der Elemente enthält, auf die wir zugreifen möchten.
Dann verwenden wir eine for-Schleife, um die Indexwerte durchzugehen und sie auszugeben.
Unten ist der gesamte Code für den Prozess:
indices = (1,3,4)
for i in indices: print(a[i])
113. Wenn Sie eine Liste wie diese haben -> [„sparta“,Wahr,3+4j,Falsch]. Wie würden Sie die Elemente dieser Liste umkehren?
Lösung ->
Wir können die Funktion reverse() für die Liste verwenden:
a.reverse()
a
114. Wenn Sie ein Wörterbuch wie dieses haben – > fruit={"Apple":10","Orange":20","Banana":30","Guava":40}. Wie würden Sie den Wert von „Apple“ von 10 auf 100 aktualisieren?
Lösung ->
So kannst du es machen:
fruit["Apple"]=100
fruit
Geben Sie den Namen des Schlüssels in der Klammer ein und weisen Sie ihm einen neuen Wert zu.
115. Wenn Sie zwei solche Sätze haben -> s1 = {1,2,3,4,5,6}, s2 = {5,6,7,8,9}. Wie würden Sie die gemeinsamen Elemente in diesen Sets finden?
Lösung ->
Sie können die Funktion crossing() verwenden, um die gemeinsamen Elemente zwischen den beiden Sätzen zu finden:
s1 = {1,2,3,4,5,6}
s2 = {5,6,7,8,9}
s1.intersection(s2)
Wir sehen, dass die gemeinsamen Elemente zwischen den beiden Mengen 5 & 6 sind.
116. Schreiben Sie ein Programm, um die 2-Tabelle mit einer While-Schleife auszudrucken.
Lösung ->
Unten ist der Code zum Ausdrucken der 2-Tabelle:
Code
i=1
n=2
while i<=10: print(n,"*", i, "=", n*i) i=i+1
Output
Wir beginnen mit der Initialisierung von zwei Variablen 'i' und 'n'. 'i' wird auf 1 initialisiert und 'n' wird auf '2' initialisiert.
Innerhalb der While-Schleife wird die Schleife 1 Mal durchlaufen, da der 'i'-Wert von 10 bis 10 geht.
Anfangs ist n*i gleich 2*1, und wir geben den Wert aus.
Dann wird der 'i'-Wert erhöht und n*i wird 2*2. Wir machen weiter und drucken es aus.
Dieser Vorgang wird fortgesetzt, bis der i-Wert 10 wird.
117. Schreiben Sie eine Funktion, die einen Wert aufnimmt und ausgibt, ob er gerade oder ungerade ist.
Lösung ->
Der folgende Code erledigt die Aufgabe:
def even_odd(x): if x%2==0: print(x," is even") else: print(x, " is odd")
Hier beginnen wir damit, eine Methode mit dem Namen „even_odd()“ zu erstellen. Diese Funktion nimmt einen einzelnen Parameter und gibt aus, ob die genommene Zahl gerade oder ungerade ist.
Rufen wir nun die Funktion auf:
even_odd(5)
Wir sehen, dass, wenn 5 als Parameter in die Funktion übergeben wird, wir die Ausgabe erhalten -> '5 ist ungerade'.
118. Schreiben Sie ein Python-Programm, um die Fakultät einer Zahl auszugeben.
Dies ist eine der am häufigsten gestellten Python-Interviewfragen
Lösung ->
Unten ist der Code zum Drucken der Fakultät einer Zahl:
factorial = 1
#check if the number is negative, positive or zero
if num<0: print("Sorry, factorial does not exist for negative numbers")
elif num==0: print("The factorial of 0 is 1")
else for i in range(1,num+1): factorial = factorial*i print("The factorial of",num,"is",factorial)
Wir beginnen mit einer Eingabe, die in 'num' gespeichert ist. Dann prüfen wir, ob 'num' kleiner als 0 ist, und wenn es tatsächlich kleiner als XNUMX ist, geben wir 'Entschuldigung, Fakultät existiert nicht für negative Zahlen' aus.
Danach prüfen wir, ob 'num' gleich Null ist, und wenn das der Fall ist, geben wir 'Die Fakultät von 0 ist 1' aus.
Wenn andererseits 'num' größer als 1 ist, treten wir in die for-Schleife ein und berechnen die Fakultät der Zahl.
119. Schreiben Sie ein Python-Programm, um zu prüfen, ob die angegebene Zahl ein Palindrom ist oder nicht
Lösung ->
Unten ist der Code, um zu überprüfen, ob die angegebene Zahl ein Palindrom ist oder nicht:
n=int(input("Enter number:"))
temp=n
rev=0
while(n>0) dig=n%10 rev=rev*10+dig n=n//10
if(temp==rev): print("The number is a palindrome!")
else: print("The number isn't a palindrome!")
Wir beginnen damit, eine Eingabe zu nehmen und sie in 'n' zu speichern und ein Duplikat davon in 'temp' zu erstellen. Wir werden auch eine andere Variable „rev“ auf 0 initialisieren.
Dann treten wir in eine While-Schleife ein, die so lange fortgesetzt wird, bis 'n' 0 wird.
Innerhalb der Schleife beginnen wir mit der Division von 'n' durch 10 und speichern dann den Rest in 'dig'.
Dann multiplizieren wir „rev“ mit 10 und fügen dann „dig“ hinzu. Dieses Ergebnis wird wieder in 'rev' gespeichert.
Im Folgenden teilen wir 'n' durch 10 und speichern das Ergebnis wieder in 'n'
Sobald die for-Schleife endet, vergleichen wir die Werte von „rev“ und „temp“. Wenn sie gleich sind, werden wir „Die Zahl ist ein Palindrom“ ausgeben, andernfalls werden wir „Die Zahl ist kein Palindrom“ ausgeben.
120. Schreiben Sie ein Python-Programm, um das folgende Muster auszugeben ->
Dies ist eine der am häufigsten gestellten Python-Interviewfragen:
1
2 2
3 3 3
4 4 4 4
+5 5 5 5
Lösung ->
Unten ist der Code zum Drucken dieses Musters:
#10 is the total number to print
for num in range(6): for i in range(num): print(num,end=" ")#print number #new line after each row to display pattern correctly print("n")
Wir lösen das Problem mit Hilfe einer verschachtelten for-Schleife. Wir haben eine äußere for-Schleife, die von 1 bis 5 geht. Dann haben wir eine innere for-Schleife, die die entsprechenden Zahlen ausgeben würde.
121. Musterfragen. Drucken Sie das folgende Muster
#
# #
# # #
# # # #
# # # # #
Lösung –>
def pattern_1(num): # outer loop handles the number of rows # inner loop handles the number of columns # n is the number of rows. for i in range(0, n): # value of j depends on i for j in range(0, i+1): # printing hashes print("#",end="") # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_1(num)
122. Drucken Sie das folgende Muster.
#
# #
# # #
# # # #
# # # # #
Lösung –>
Code:
def pattern_2(num): # define the number of spaces k = 2*num - 2 # outer loop always handles the number of rows # let us use the inner loop to control the number of spaces # we need the number of spaces as maximum initially and then decrement it after every iteration for i in range(0, num): for j in range(0, k): print(end=" ") # decrementing k after each loop k = k - 2 # reinitializing the inner loop to keep a track of the number of columns # similar to pattern_1 function for j in range(0, i+1): print("# ", end="") # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_2(num)
123. Drucken Sie das folgende Muster:
0
0 1
0 1 2
0 1 2 3
+0 1 2 3
Lösung –>
Code:
def pattern_3(num): # initialising starting number number = 1 # outer loop always handles the number of rows # let us use the inner loop to control the number for i in range(0, num): # re assigning number after every iteration # ensure the column starts from 0 number = 0 # inner loop to handle number of columns for j in range(0, i+1): # printing number print(number, end=" ") # increment number column wise number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_3(num)
124. Drucken Sie das folgende Muster:
1
2 3
4 5 6
7 8 9 10
+11 12 13 14
Lösung –>
Code:
def pattern_4(num): # initialising starting number number = 1 # outer loop always handles the number of rows # let us use the inner loop to control the number for i in range(0, num): # commenting the reinitialization part ensure that numbers are printed continuously # ensure the column starts from 0 number = 0 # inner loop to handle number of columns for j in range(0, i+1): # printing number print(number, end=" ") # increment number column wise number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_4(num)
125. Drucken Sie das folgende Muster:
A
BB
CCC
DDDD
Lösung –>
def pattern_5(num): # initializing value of A as 65 # ASCII value equivalent number = 65 # outer loop always handles the number of rows for i in range(0, num): # inner loop handles the number of columns for j in range(0, i+1): # finding the ascii equivalent of the number char = chr(number) # printing char value print(char, end=" ") # incrementing number number = number + 1 # ending line after each row print("r") num = int(input("Enter the number of rows in pattern: "))
pattern_5(num)
126. Drucken Sie das folgende Muster:
A
BC
DEF
GHIJ
KLMNO
PQRSTU
Lösung –>
def pattern_6(num): # initializing value equivalent to 'A' in ASCII # ASCII value number = 65 # outer loop always handles the number of rows for i in range(0, num): # inner loop to handle number of columns # values changing acc. to outer loop for j in range(0, i+1): # explicit conversion of int to char
# returns character equivalent to ASCII. char = chr(number) # printing char value print(char, end=" ") # printing the next character by incrementing number = number +1 # ending line after each row print("r") num = int(input("enter the number of rows in the pattern: "))
pattern_6(num)
127. Drucken Sie das folgende Muster
#
# #
# # #
# # # #
# # # # #
Lösung –>
Code:
def pattern_7(num): # number of spaces is a function of the input num k = 2*num - 2 # outer loop always handle the number of rows for i in range(0, num): # inner loop used to handle the number of spaces for j in range(0, k): print(end=" ") # the variable holding information about number of spaces # is decremented after every iteration k = k - 1 # inner loop reinitialized to handle the number of columns for j in range(0, i+1): # printing hash print("# ", end="") # ending line after each row print("r") num = int(input("Enter the number of rows: "))
pattern_7(n)
128. Wenn Sie ein Wörterbuch wie dieses haben -> d1={“k1″:10,”k2″:20,”k3”:30}. Wie würden Sie die Werte aller Schlüssel erhöhen?
d1={"k1":10,"k2":20,"k3":30} for i in d1.keys(): d1[i]=d1[i]+1
129. Wie kann man in Python eine Zufallszahl bekommen?
Antwort. Um einen Zufall zu generieren, verwenden wir ein Zufallsmodul von Python. Hier sind einige Beispiele, um eine Fließkommazahl von 0-1 zu generieren
import random
n = random.random()
print(n)
To generate a integer between a certain range (say from a to b):
import random
n = random.randint(a,b)
print(n)
130. Erklären Sie, wie Sie die Datenbank in Django einrichten können.
Alle Einstellungen des Projekts sowie Informationen zur Datenbankverbindung sind in der Datei settings.py enthalten. Django arbeitet standardmäßig mit der SQLite-Datenbank, kann aber auch für den Betrieb mit anderen Datenbanken konfiguriert werden.
Für die Datenbankkonnektivität sind vollständige Verbindungsinformationen erforderlich, darunter unter anderem der Datenbankname, die Anmeldeinformationen des Benutzers, der Hostname und der Laufwerksname.
Um eine Verbindung zu MySQL herzustellen und eine Verbindung zwischen der Anwendung und der Datenbank herzustellen, verwenden Sie den Treiber django.db.backends.mysql.
Alle Verbindungsinformationen müssen in der Einstellungsdatei enthalten sein. Die Datei settings.py unseres Projekts enthält den folgenden Code für die Datenbank.
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'djangoApp', 'USER':'root', 'PASSWORD':'mysql', 'HOST':'localhost', 'PORT':'3306' } } Dieser Befehl erstellt Tabellen für Admin, Authentifizierung, Inhaltstypen und Sitzungen. Sie können sich jetzt mit der MySQL-Datenbank verbinden, indem Sie sie aus dem Datenbank-Dropdown-Menü auswählen.
131. Geben Sie ein Beispiel dafür, wie Sie eine VIEW in Django schreiben können?
Die Django-MVT-Struktur ist ohne Django-Ansichten unvollständig. Eine Ansichtsfunktion ist eine Python-Funktion, die eine Webanforderung empfängt und eine Webantwort gemäß dem Django-Handbuch liefert. Diese Antwort kann der HTML-Inhalt einer Webseite, eine Weiterleitung, ein 404-Fehler, ein XML-Dokument, ein Bild oder irgendetwas anderes sein, das ein Webbrowser anzeigen kann.
Das HTML/CSS/JavaScript in Ihren Vorlagendateien wird in das konvertiert, was Sie in Ihrem Browser sehen, wenn Sie eine Webseite mit Django-Ansichten anzeigen, die Teil der Benutzeroberfläche sind. (Kombinieren Sie Django-Ansichten nicht mit MVC-Ansichten, wenn Sie andere MVC-Frameworks (Model-View-Controller) verwendet haben.) In Django sind die Ansichten ähnlich.
# import Http Response from django
from django.http import HttpResponse
# get datetime
import datetime
# create a function
def geeks_view(request): # fetch date and time now = datetime.datetime.now() # convert to string html = "Time is {}".format(now) # return response return HttpResponse(html)
132 Erklären Sie die Verwendung von Sitzungen im Django-Framework?
Django (und ein Großteil des Internets) verwendet Sitzungen, um den „Status“ einer bestimmten Website und eines bestimmten Browsers zu verfolgen. Sitzungen ermöglichen es Ihnen, eine beliebige Datenmenge pro Browser zu speichern und bei jeder Verbindung des Browsers auf der Website verfügbar zu machen. Die Datenelemente der Sitzung werden dann durch einen „Schlüssel“ gekennzeichnet, mit dem die Daten gespeichert und wiederhergestellt werden können.
Django verwendet ein Cookie mit einer Einzelzeichen-ID, um jeden Browser und seine mit der Website verknüpfte Website zu identifizieren. Sitzungsdaten werden standardmäßig in der Datenbank der Website gespeichert (dies ist sicherer, als die Daten in einem Cookie zu speichern, wo sie anfälliger für Angreifer sind).
Mit Django können Sie Sitzungsdaten an verschiedenen Orten speichern (Cache, Dateien, „sichere“ Cookies), aber der Standardspeicherort ist eine solide und sichere Wahl.
Sitzungen aktivieren
Als wir die Skelett-Website erstellten, waren Sitzungen standardmäßig aktiviert.
Die Konfiguration wird in der Projektdatei (locallibrary/locallibrary/settings.py) unter den Abschnitten INSTALLED_APPS und MIDDLEWARE eingerichtet, wie unten gezeigt:
INSTALLED_APPS = [ ... 'django.contrib.sessions', ....
MIDDLEWARE = [ ... 'django.contrib.sessions.middleware.SessionMiddleware', …
Sitzungen verwenden
Der Anforderungsparameter gibt Ihnen Zugriff auf die Sitzungseigenschaft der Ansicht (eine HttpRequest, die als erstes Argument an die Ansicht übergeben wird). Die Sitzungs-ID im Cookie des Browsers für diese Website identifiziert die jeweilige Verbindung zum aktuellen Benutzer (oder genauer gesagt die Verbindung zum aktuellen Browser).
Das Sitzungs-Asset ist ein wörterbuchähnliches Element, das Sie in Ihrer Ansicht so oft wie nötig untersuchen und schreiben können, um es laufend zu aktualisieren. Sie können alle Standardwörterbuchaktionen ausführen, wie z. B. alle Daten löschen, auf das Vorhandensein eines Schlüssels prüfen, Daten durchlaufen und so weiter. Meistens erhalten und setzen Sie Werte jedoch nur mit der üblichen „Wörterbuch“-API.
Die folgenden Codesegmente demonstrieren, wie mit der aktuellen Sitzung verknüpfte Daten mit dem Schlüssel „my bike“ (Browser) abgerufen, geändert und entfernt werden können.
Hinweis: Eines der besten Dinge an Django ist, dass Sie sich keine Gedanken über die Mechanismen machen müssen, von denen Sie glauben, dass sie die Sitzung mit der aktuellen Anfrage verbinden. Wenn wir die folgenden Fragmente in unserer Ansicht verwenden würden, wüssten wir, dass die Informationen über my_bike nur mit dem Browser verknüpft sind, der die aktuelle Anfrage gesendet hat.
# Get a session value via its key (for example ‘my_bike’), raising a KeyError if the key is not present my_bike= request.session[‘my_bike’]
# Get a session value, setting a default value if it is not present ( ‘mini’)
my_bike= request.session.get(‘my_bike’, ‘mini’)
# Set a session value
request.session[‘my_bike’] = ‘mini’
# Delete a session value
del request.session[‘my_bike’]
In der API stehen verschiedene Methoden zur Verfügung, von denen die meisten zur Steuerung des verknüpften Sitzungscookies verwendet werden. Es gibt Möglichkeiten, um beispielsweise zu überprüfen, ob der Client-Browser Cookies unterstützt, Ablaufdaten für Cookies festzulegen und zu überprüfen und abgelaufene Sitzungen aus dem Datenspeicher zu löschen. Wie Sitzungen verwendet werden, enthält weitere Informationen zur gesamten API (Django-Dokumentation).
133. Listen Sie die Vererbungsstile in Django auf.
Abstrakte Basisklassen: Dieses Vererbungsmuster wird von Entwicklern verwendet, wenn sie möchten, dass die übergeordnete Klasse Daten behält, die sie nicht für jedes untergeordnete Modell eingeben möchten.
models.py
from django.db import models # Create your models here. class ContactInfo(models.Model): name=models.CharField(max_length=20) email=models.EmailField(max_length=20) address=models.TextField(max_length=20) class Meta: abstract=True class Customer(ContactInfo): phone=models.IntegerField(max_length=15) class Staff(ContactInfo): position=models.CharField(max_length=10) admin.py
admin.site.register(Customer)
admin.site.register(Staff)
Wenn wir diese Änderungen übertragen, werden in der Datenbank zwei Tabellen gebildet. Wir haben Felder für Name, E-Mail, Adresse und Telefon in der Kundentabelle. Wir haben Felder für Name, E-Mail, Adresse und Position in der Personaltabelle. Tabelle ist keine Basisklasse, die in diese Vererbung eingebaut wird.
Vererbung mehrerer Tabellen: Sie wird verwendet, wenn Sie ein vorhandenes Modell in Unterklassen umwandeln möchten und jede der Unterklassen ihre eigene Datenbanktabelle haben soll.
model.py
from django.db import models # Create your models here. class Place(models.Model): name=models.CharField(max_length=20) address=models.TextField(max_length=20) def __str__(self): return self.name class Restaurants(Place): serves_pizza=models.BooleanField(default=False) serves_pasta=models.BooleanField(default=False) def __str__(self): return self.serves_pasta admin.py from django.contrib import admin
from .models import Place,Restaurants
# Register your models here. admin.site.register(Place)
admin.site.register(Restaurants)
Proxy-Modelle: Dieser Vererbungsansatz ermöglicht es dem Benutzer, das Verhalten auf der Basisebene zu ändern, ohne das Feld des Modells zu ändern.
Diese Technik wird verwendet, wenn Sie nur das Verhalten der Python-Ebene des Modells und nicht die Felder des Modells ändern möchten. Mit Ausnahme von Feldern erben Sie von der Basisklasse und können Ihre eigenen Eigenschaften hinzufügen.
- Abstrakte Klassen sollten nicht als Basisklassen verwendet werden.
- Mehrfachvererbung ist in Proxy-Modellen nicht möglich.
Hauptzweck ist es, die Schlüsselfunktionen des Vorgängermodells zu ersetzen. Es verwendet immer überschriebene Methoden, um das ursprüngliche Modell abzufragen.
134 Wie können Sie das Google-Cache-Alter einer beliebigen URL oder Webseite ermitteln?
Verwenden Sie die URL
https://webcache.googleusercontent.com/search?q=cache:<your url without “http://”>
Beispiel:
Es enthält einen Header wie diesen:
Dies ist Googles Cache von https://stackoverflow.com/. Es ist ein Screenshot der Seite, wie sie am 11. August 33 um 38:21:2012 GMT aussah. In der Zwischenzeit kann sich die aktuelle Seite geändert haben.
Tipp: Verwenden Sie die Suchleiste und drücken Sie Strg+F oder ⌘+F (Mac), um Ihr Suchwort auf dieser Seite schnell zu finden.
Sie müssen die resultierende Seite kratzen, aber die aktuellste Cache-Seite finden Sie unter dieser URL:
http://webcache.googleusercontent.com/search?q=cache:www.something.com/path
Das erste div im Body-Tag enthält Google-Informationen.
Sie können die CachedPages-Website verwenden
Große Unternehmen mit ausgeklügelten Webservern bewahren und bewahren normalerweise zwischengespeicherte Seiten auf. Da solche Server oft recht schnell sind, kann eine zwischengespeicherte Seite häufig schneller abgerufen werden als die Live-Website:
- Eine aktuelle Kopie der Seite wird im Allgemeinen von Google aufbewahrt (1 bis 15 Tage alt).
- Coral behält auch eine aktuelle Kopie, obwohl sie nicht so aktuell ist wie die von Google.
- Mit Archive.org können Sie auf mehrere Versionen einer Webseite zugreifen, die im Laufe der Zeit aufbewahrt wurden.
Wenn Sie also das nächste Mal nicht auf eine Website zugreifen können, sie aber trotzdem ansehen möchten, könnte die Cache-Version von Google eine gute Option sein. Stellen Sie zunächst fest, ob das Alter wichtig ist oder nicht.
135 Erklären Sie kurz etwas über Python-Namespaces?
Ein Namensraum in Python spricht über den Namen, der jedem Objekt in Python zugewiesen wird. Namensräume werden in Python wie ein Wörterbuch aufbewahrt, wobei der Schlüssel des Wörterbuchs der Namensraum und der Wert die Adresse dieses Objekts ist.
Verschiedene Arten sind wie folgt:
- Integrierter Namespace – Namespaces, die alle integrierten Objekte in Python enthalten.
- Globaler Namensraum – Namensräume, die aus allen Objekten bestehen, die erstellt werden, wenn Sie Ihr Hauptprogramm aufrufen.
- Einschließender Namensraum – Namensräume auf der höheren Ebene.
- Lokaler Namespace – Namespaces innerhalb lokaler Funktionen.
136 Erklären Sie kurz Break-, Pass- und Continue-Anweisungen in Python ?
Break: Wenn wir eine Break-Anweisung in einem Python-Code/Programm verwenden, wird die Schleife sofort unterbrochen/beendet und der Kontrollfluss wird an die Anweisung nach dem Schleifenkörper zurückgegeben.
Continue: Wenn wir eine Continue-Anweisung in einem Python-Code/Programm verwenden, unterbricht/beendet sie sofort die aktuelle Iteration der Anweisung und überspringt auch den Rest des Programms in der aktuellen Iteration und steuert den Fluss zur nächsten Iteration der Schleife.
Pass: Wenn wir eine Pass-Anweisung in einem Python-Code/Programm verwenden, füllt sie die leeren Stellen im Programm aus.
Beispiel:
GL = [10, 30, 20, 100, 212, 33, 13, 50, 60, 70]
for g in GL:
pass
if (g == 0):
current = g
break
elif(g%2==0):
continue
print(g) # output => 1 3 1 3 1 print(current)
137 Geben Sie mir ein Beispiel, wie Sie eine Liste in einen String umwandeln können?
Das folgende Beispiel zeigt, wie eine Liste in eine Zeichenfolge konvertiert wird. Wenn wir eine Liste in einen String konvertieren, können wir die Funktion „.join“ verwenden, um dasselbe zu tun.
fruits = [ ‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
listAsString = ‘ ‘.join(fruits)
print(listAsString)
Apfel Orange Mango Papaya Guave
138. Geben Sie mir ein Beispiel, wo Sie eine Liste in ein Tupel umwandeln können?
Das unten angegebene Beispiel zeigt, wie eine Liste in ein Tupel konvertiert wird. Wenn wir eine Liste in ein Tupel konvertieren, können wir die verwenden Funktion, aber denken Sie daran, da Tupel unveränderlich sind, können wir sie nicht zurück in eine Liste konvertieren.
fruits = [‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
listAsTuple = tuple(fruits)
print(listAsTuple)
('Apfel', 'Orange', 'Mango', 'Papaya', 'Guave')
139. Wie zählt man die Vorkommen eines bestimmten Elements in der Liste?
In der Listendatenstruktur von Python zählen wir die Anzahl der Vorkommen eines Elements mithilfe der Funktion count().
fruits = [‘apple’, ‘orange’, ‘mango’, ‘papaya’, ‘guava’]
print(fruits.count(‘apple’))
Ausgabe: 1
140. Wie debuggen Sie ein Python-Programm?
Es gibt mehrere Möglichkeiten, ein Python-Programm zu debuggen:
- Verwendung der
print-Anweisung, um Variablen und Zwischenergebnisse auf der Konsole auszugeben - Mit einem Debugger wie z
pdboripdb - Hinzufügen
assertAnweisungen an den Code, um bestimmte Bedingungen zu überprüfen
141. Was ist der Unterschied zwischen einer Liste und einem Tupel in Python?
Eine Liste ist ein veränderlicher Datentyp, d. h. sie kann nach ihrer Erstellung geändert werden. Ein Tupel ist unveränderlich, d. h. es kann nach seiner Erstellung nicht mehr geändert werden. Dadurch werden Tupel schneller und sicherer als Listen, da sie nicht versehentlich von anderen Teilen des Codes geändert werden können.
142. Wie behandeln Sie Ausnahmen in Python?
Ausnahmen in Python können mit a behandelt werden try-except Block. Beispielsweise:
Code kopierentry: # code that may raise an exception
except SomeExceptionType: # code to handle the exception
143. Wie kehrt man einen String in Python um?
Es gibt mehrere Möglichkeiten, einen String in Python umzukehren:
- Verwenden eines Slice mit einem Schritt von -1:
Code kopierenstring = "abcdefg"
reversed_string = string[::-1]
- Verwendung der
reversedFunktion:
Code kopierenstring = "abcdefg"
reversed_string = "".join(reversed(string))
- Verwenden einer for-Schleife:
Code kopierenstring = "abcdefg"
reversed_string = ""
for char in string: reversed_string = char + reversed_string
144. Wie sortiert man eine Liste in Python?
Es gibt mehrere Möglichkeiten, eine Liste in Python zu sortieren:
- Verwendung der
sortVerfahren:
Code kopierenmy_list = [3, 4, 1, 2]
my_list.sort()
- Verwendung der
sortedFunktion:
Code kopierenmy_list = [3, 4, 1, 2]
sorted_list = sorted(my_list)
- Verwendung der
sortFunktion von deroperatorModul:
Code kopierenfrom operator import itemgetter my_list = [{"a": 3}, {"a": 1}, {"a": 2}]
sorted_list = sorted(my_list, key=itemgetter("a"))
145. Wie erstellt man ein Wörterbuch in Python?
Es gibt mehrere Möglichkeiten, ein Wörterbuch in Python zu erstellen:
- Verwenden von geschweiften Klammern und Doppelpunkten zum Trennen von Schlüsseln und Werten:
Code kopierenmy_dict = {"key1": "value1", "key2": "value2"}
- Verwendung der
dictFunktion:
Code kopierenmy_dict = dict(key1="value1", key2="value2")
- Verwendung der
dictKonstrukteur:
Code kopierenmy_dict = dict({"key1": "value1", "key2": "value2"})
Fragen 1. Wie heben Sie sich in einem Python-Coding-Interview ab?
Jetzt, da Sie in Bezug auf Ihre technischen Fähigkeiten bereit für ein Python-Interview sind, fragen Sie sich sicherlich, wie Sie sich von der Masse abheben können, damit Sie der ausgewählte Kandidat sind. Sie müssen nachweisen können, dass Sie sauberen Produktionscode schreiben können und Kenntnisse über die erforderlichen Bibliotheken und Tools haben. Wenn Sie an früheren Projekten gearbeitet haben, hilft Ihnen das Präsentieren dieser Projekte in Ihrem Vorstellungsgespräch auch dabei, sich vom Rest der Masse abzuheben.
Lesen Sie auch: Die häufigsten Interviewfragen
Frage 2. Wie bereite ich mich auf ein Python-Interview vor?
Um sich auf ein Python-Interview vorzubereiten, müssen Sie Syntax, Schlüsselwörter, Funktionen und Klassen, Datentypen, grundlegende Codierung und Ausnahmebehandlung kennen. Grundlegende Kenntnisse aller verwendeten Bibliotheken und IDEs und das Lesen von Blogs zum Python-Tutorial werden Ihnen helfen. Präsentieren Sie Ihre Beispielprojekte, frischen Sie Ihre Grundkenntnisse über Algorithmen auf und nehmen Sie vielleicht an einem kostenlosen Kurs teil Tutorial für Python-Datenstrukturen. Dies wird Ihnen helfen, vorbereitet zu bleiben.
Fragen 3. Sind Python-Programmierungsinterviews sehr schwierig?
Der Schwierigkeitsgrad eines Python-Interviews hängt von der Stelle ab, für die Sie sich bewerben, dem Unternehmen, dessen Anforderungen und Ihren Fähigkeiten und Kenntnissen/Arbeitserfahrungen. Wenn Sie ein Anfänger auf diesem Gebiet sind und sich Ihrer Programmierfähigkeiten noch nicht sicher sind, haben Sie möglicherweise das Gefühl, dass das Vorstellungsgespräch schwierig ist. Wenn Sie vorbereitet sind und wissen, welche Art von Python-Interviewfragen Sie erwarten, können Sie sich gut vorbereiten und das Interview meistern.
Fragen 4. Wie bestehe ich das Python-Programmierinterview?
Ausreichende Kenntnisse in Bezug auf Object Relational Mapper (ORM)-Bibliotheken, Django oder Flask, Komponententests und Debugging-Fähigkeiten, grundlegende Designprinzipien hinter einer skalierbaren Anwendung, Python-Pakete wie NumPy, Scikit Learn sind für Sie äußerst wichtig, um ein Programmierinterview zu bestehen. Sie können Ihre bisherige Berufserfahrung oder Programmierfähigkeiten durch Projekte unter Beweis stellen, dies ist ein zusätzlicher Vorteil.
Lesen Sie auch: So erstellen Sie einen Lebenslauf für Python-Entwickler
Fragen 5. Wie debuggen Sie ein Python-Programm?
Mit diesem Befehl können wir das Programm im Python-Terminal debuggen.
$ python -m pdb python-script.py
Fragen 6. Welche Kurse oder Zertifizierungen können helfen, das Wissen in Python zu erweitern?
Damit sind wir am Ende des Blogs zu den Top-Python-Interviewfragen angelangt. Wenn Sie sich weiterbilden möchten, hilft Ihnen die Teilnahme an einem Zertifikatslehrgang dabei, die erforderlichen Kenntnisse zu erwerben. Sie können eine aufnehmen Python-Programmierkurs und starten Sie Ihre Karriere in Python.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.mygreatlearning.com/blog/python-interview-questions/

