Das Vortraining moderner Modelle erfordert häufig eine größere Clusterbereitstellung, um Zeit und Kosten zu reduzieren. Auf Serverebene erfordern solche Trainingsworkloads eine schnellere Rechenleistung und eine erhöhte Speicherzuweisung. Da Modelle auf Hunderte von Milliarden von Parametern anwachsen, erfordern sie einen verteilten Trainingsmechanismus, der sich über mehrere Knoten (Instanzen) erstreckt.
Im Oktober 2022 haben wir gestartet Amazon EC2 Trn1-Instanceseinen schweren Verlauf verhindern kann. AWS-Training, der von AWS entwickelte Beschleuniger für maschinelles Lernen der zweiten Generation. Trn1-Instances wurden speziell für das leistungsstarke Training von Deep-Learning-Modellen entwickelt und bieten gleichzeitig bis zu 50 % Einsparungen bei den Schulungskosten gegenüber vergleichbaren GPU-basierten Instances. Um die Trainingszeit von Wochen auf Tage oder Tage auf Stunden zu verkürzen und den Trainingsjob eines großen Modells zu verteilen, können wir einen EC2 Trn1 UltraCluster verwenden, der aus dicht gepackten, nebeneinander angeordneten Racks von Trn1-Recheninstanzen besteht, die alle miteinander verbunden sind nicht blockierende Netzwerke im Petabyte-Maßstab. Es ist unser bisher größter UltraCluster und bietet 6 Exaflops Rechenleistung auf Abruf mit bis zu 30,000 Trainium-Chips.
In diesem Beitrag verwenden wir eine Vorschulungsarbeitslast für das Hugging Face BERT-Large-Modell als einfaches Beispiel, um zu erklären, wie Trn1 UltraClusters verwendet werden.
Trn1 UltraCluster
Ein Trn1 UltraCluster ist eine Platzierungsgruppe von Trn1-Instances in einem Rechenzentrum. Als Teil eines einzelnen Cluster-Laufs können Sie einen Cluster von Trn1-Instances mit Trainium-Beschleunigern hochfahren. Das folgende Diagramm zeigt ein Beispiel.
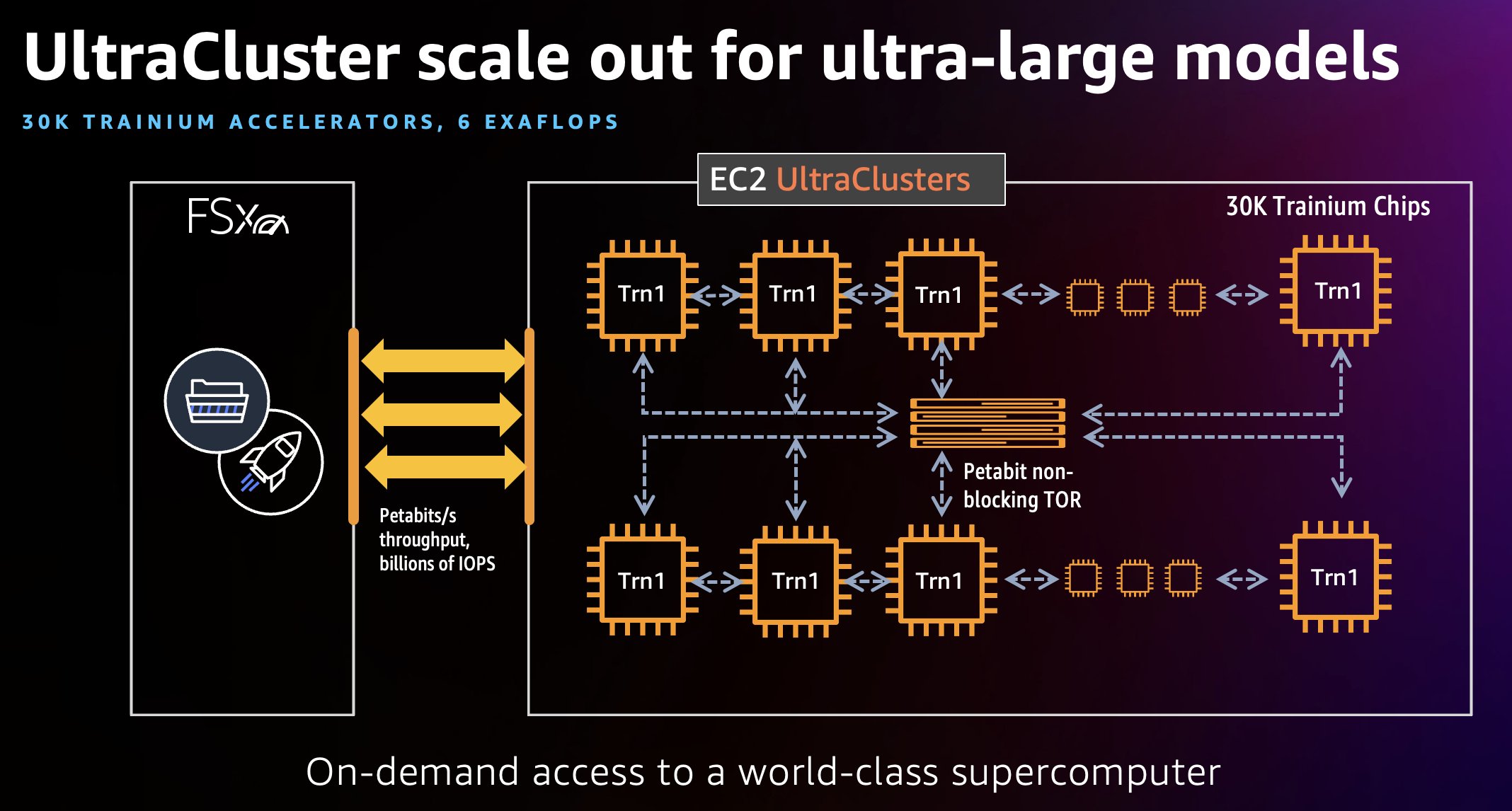
UltraCluster von Trn1-Instanzen befinden sich gemeinsam in einem Rechenzentrum und sind miteinander verbunden Elastischer Gewebeadapter (EFA), eine nicht blockierende Netzwerkschnittstelle im Petabyte-Maßstab mit bis zu 800 Gbit/s Netzwerkbandbreite, was der doppelten Bandbreite entspricht, die von AWS P4d-Instanzen unterstützt wird (1.6 Tbit/s, viermal mehr bei den kommenden Trn1n-Instanzen). Diese EFA-Schnittstellen helfen bei der Ausführung von Modelltrainings-Workloads, die Neuron Collective Communication Libraries im großen Maßstab verwenden. Trn1-UltraCluster umfassen auch am selben Ort befindliche Network Attached Storage-Dienste wie Amazon FSx für Lustre um den Zugriff auf große Datensätze mit hohem Durchsatz zu ermöglichen und sicherzustellen, dass Cluster effizient arbeiten. Trn1 UltraCluster können bis zu 30,000 Trainium-Geräte hosten und bis zu 6 Exaflops Rechenleistung in einem einzigen Cluster liefern. EC2 Trn1 UltraCluster liefern bis zu 6 Exaflops an Rechenleistung, buchstäblich ein On-Demand-Supercomputer, mit einem Pay-as-you-go-Nutzungsmodell. In diesem Beitrag verwenden wir einige HPC-Tools wie Slurm, um einen UltraCluster hochzufahren und Workloads zu verwalten.
Lösungsüberblick
AWS bietet eine Vielzahl von Services für verteiltes Modelltraining oder Inferenz-Workloads in großem Maßstab, einschließlich AWS-Charge, Amazon Elastic Kubernetes-Service (Amazon EKS) und UltraClusters. Dieser Beitrag konzentriert sich auf das Modelltraining in einem UltraCluster. Unsere Lösung verwendet die AWS-ParallelCluster Verwaltungstool zum Erstellen der erforderlichen Infrastruktur und Umgebung zum Hochfahren eines Trn1 UltraCluster. Die Infrastruktur besteht aus einem Hauptknoten und mehreren Trn1-Rechenknoten innerhalb einer Virtual Private Cloud (VPC). Wir verwenden Slurm als Cluster-Management- und Job-Scheduling-System. Das folgende Diagramm veranschaulicht unsere Lösungsarchitektur.
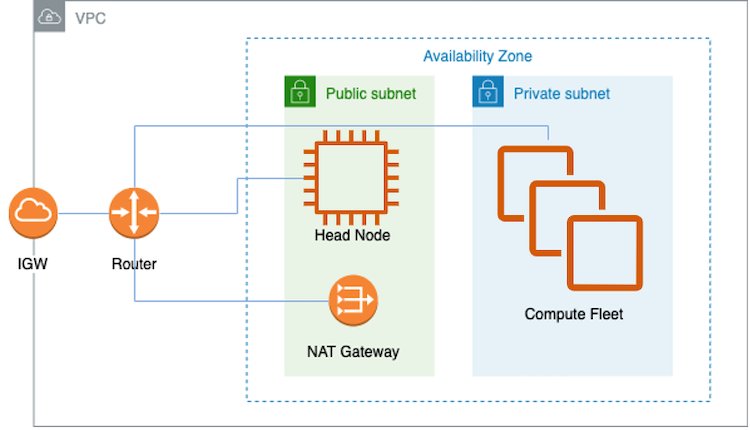
Weitere Einzelheiten und die Bereitstellung dieser Lösung finden Sie unter Trainieren Sie ein Modell auf AWS Trn1 ParallelCluster.
Sehen wir uns einige wichtige Schritte dieser Lösung an:
- Erstellen Sie eine VPC und Subnetze.
- Konfigurieren Sie die Compute-Flotte.
- Erstellen Sie den Cluster.
- Untersuchen Sie den Cluster.
- Starte deinen Ausbildungsjob.
Voraussetzungen:
Um diesem Beitrag zu folgen, ist eine breite Vertrautheit mit den wichtigsten AWS-Services wie z Amazon Elastic Compute-Cloud (Amazon EC2) ist impliziert, und grundlegende Vertrautheit mit Deep Learning und PyTorch wäre hilfreich.
VPC und Subnetze erstellen
Eine einfache Möglichkeit zum Erstellen der VPC und der Subnetze ist die Amazon Virtual Private Cloud (Amazon VPC)-Konsole. Eine vollständige Anleitung finden Sie unter GitHub. Nachdem die VPC und die Subnetze installiert sind, müssen Sie die Instances in der Rechenflotte konfigurieren. Kurz gesagt wird dies durch ein Installationsskript ermöglicht, das von CustomActions in der YAML-Datei angegeben wird, die zum Erstellen des ParallelClusters verwendet wird (siehe ParallelCluster erstellen). Ein ParallelCluster erfordert eine VPC mit zwei Subnetzen und einem NAT-Gateway (Network Address Translation), wie im vorherigen Architekturdiagramm gezeigt. Diese VPC muss sich in den Availability Zones befinden, in denen Trn1-Instances verfügbar sind. Außerdem benötigen Sie in dieser VPC ein öffentliches Subnetz und ein privates Subnetz für den Hauptknoten bzw. die Trn1-Rechenknoten. Sie benötigen außerdem einen NAT-Gateway-Internetzugang, damit Trn1-Rechenknoten herunterladen können AWS-Neuron Pakete. Im Allgemeinen erhalten die Rechenknoten Updates für die Betriebssystempakete, den Neuron-Treiber und die Laufzeit sowie den EFA-Treiber für das Multi-Instanz-Training.
Der Kopfknoten erhält zusätzlich zu den oben genannten Komponenten für die Rechenknoten auch den PyTorch-NeuronX- und NeuronX-Compiler, der den Modellkompilierungsprozess in XLA-Geräten wie Trainium ermöglicht.
Konfigurieren Sie die Compute-Flotte
In der YAML-Datei zum Erstellen des Trn1 UltraCluster InstanceType ist als trn1.32xlarge angegeben. MaxCount und MinCount werden verwendet, um den Größenbereich Ihrer Compute-Flotte anzugeben. Sie dürfen verwenden MinCount um einige oder alle Trn1-Instanzen jederzeit verfügbar zu halten. MinCount kann auf Null gesetzt werden, sodass die Trn1-Instanzen von diesem Cluster freigegeben werden, wenn kein Job ausgeführt wird.
Trn1 kann auch in einem UltraCluster mit mehreren Warteschlangen bereitgestellt werden. Im folgenden Beispiel wird nur eine Warteschlange für die Übermittlung von Slurm-Jobs eingerichtet:
Wenn Sie mehr als eine Warteschlange benötigen, können Sie mehrere angeben InstanceType, jeder mit seinem eigenen MaxCount, MinCount und Name:
Hier werden zwei Warteschlangen eingerichtet, sodass der Benutzer die Ressourcen für seinen Slurm-Job flexibel auswählen kann.
Cluster erstellen
Verwenden Sie Folgendes, um einen Trn1 UltraCluster zu starten pcluster Befehl von wo aus Ihr ParallelCluster-Tool ist installiert:
Wir verwenden die folgenden Optionen in diesem Befehl:
--cluster-configuration– Diese Option erwartet eine YAML-Datei, die die Clusterkonfiguration beschreibt-n(oder--cluster-name) – Der Name dieses Clusters
Dieser Befehl erstellt einen Trn1-Cluster in Ihrem AWS-Konto. Sie können den Fortschritt der Cluster-Erstellung auf der Seite überprüfen AWS CloudFormation Konsole. Weitere Informationen finden Sie unter Verwenden der AWS CloudFormation-Konsole.
Alternativ können Sie den folgenden Befehl verwenden, um den Status Ihrer Anfrage anzuzeigen:
und der Befehl zeigt den Status an, zum Beispiel:
Die folgenden Parameter sind von Interesse aus der Ausgabe:
- Instanz-ID – Dies ist die Instanz-ID des Hauptknotens, die auf der Amazon EC2-Konsole aufgelistet wird
- berechnenFleetStatus – Dieses Attribut gibt die Bereitschaft der Rechenknoten an
- Schlüsselwörter – Dieses Attribut gibt die Version von an
pclusterTool zum Erstellen dieses Clusters
Untersuchen Sie den Cluster
Sie können die oben genannten verwenden pcluster describe-cluster Befehl zum Überprüfen des Clusters. Nachdem der Cluster erstellt wurde, sehen Sie in der Ausgabe Folgendes:
An diesem Punkt können Sie sich per SSH mit dem Hauptknoten verbinden (identifiziert durch die Instance-ID auf der Amazon EC2-Konsole). Das Folgende ist ein logisches Diagramm des Clusters.
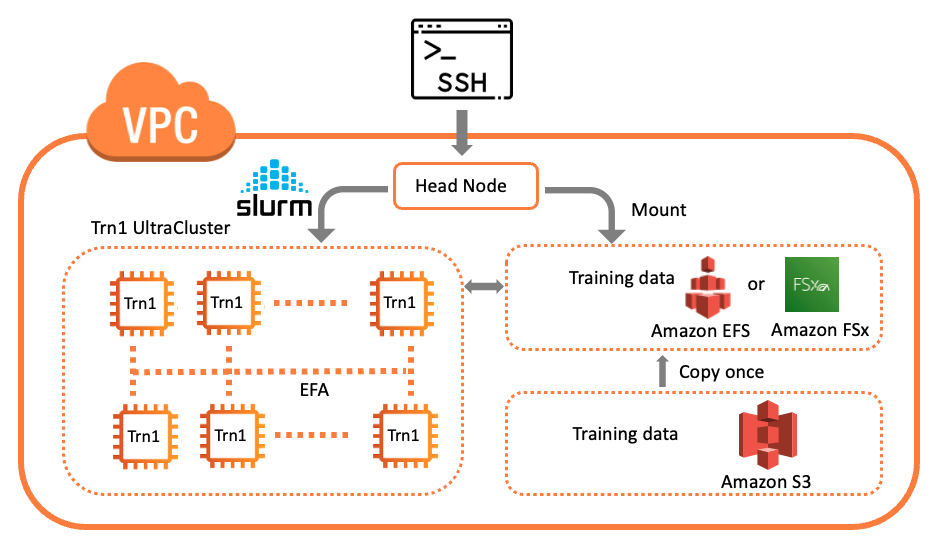
Nachdem Sie eine SSH-Verbindung zum Hauptknoten hergestellt haben, können Sie die Rechnerflotte und ihren Status mit einem Slurm-Befehl wie z sinfo , um die Knoteninformationen für das System anzuzeigen. Das Folgende ist eine Beispielausgabe:
Dies zeigt an, dass es eine Warteschlange gibt, wie durch eine einzelne Partition gezeigt. Es sind 16 Knoten verfügbar und Ressourcen werden zugewiesen. Vom Hauptknoten aus können Sie SSH in jeden beliebigen Compute-Knoten einbinden:
Verwenden Sie die exit um zum Hauptknoten zurückzukehren.
Ebenso können Sie von einem anderen Compute-Knoten aus eine SSH-Verbindung zu einem Compute-Knoten herstellen. Auf jedem Rechenknoten sind Neuron-Tools installiert, z neuron-top. Sie können aufrufen neuron-top während der Ausführung des Trainingsskripts, um die NeuronCore-Auslastung an jedem Knoten zu überprüfen.
Starte deinen Ausbildungsjob
Wir nutzen die Hugging Face BERT-Large Pretraining Tutorial als Beispiel für die Ausführung auf diesem Cluster. Nachdem die Trainingsdaten und Skripte in den Cluster heruntergeladen wurden, verwenden wir den Slurm-Controller, um unsere Arbeitslast zu verwalten und zu orchestrieren. Wir übermitteln den Ausbildungsauftrag mit der sbatch Befehl. Das Shell-Skript ruft das Python-Skript über die auf neuron_parallel_compile API zum Kompilieren des Modells in Diagramme ohne einen vollständigen Trainingslauf. Siehe folgenden Code:
Wir verwenden die folgenden Optionen in diesem Befehl:
--exclusive– Dieser Job verwendet alle Knoten und teilt keine Knoten mit anderen Jobs, während der aktuelle Job ausgeführt wird.--nodes– Die Anzahl der Knoten für diesen Job.--wrap– Dies definiert eine Befehlszeichenfolge, die vom Slurm-Controller ausgeführt wird. In diesem Fall kompiliert es das Modell einfach parallel unter Verwendung aller Knoten.
Nachdem das Modell erfolgreich kompiliert wurde, können Sie den vollständigen Trainingsjob mit dem folgenden Befehl starten:
Dieser Befehl startet den Trainingsjob für das Hugging Face BERT-Large-Modell. Mit 16 Trn1.32xlarge-Knoten können Sie damit rechnen, dass es in weniger als 8 Stunden abgeschlossen ist.
An dieser Stelle können Sie einen Slurm-Befehl wie z squeue um den eingereichten Job zu überprüfen. Eine Beispielausgabe sieht wie folgt aus:
Diese Ausgabe zeigt, dass der Job ausgeführt wird (R) auf 16 Rechenknoten.
Während der Job ausgeführt wird, werden Ausgaben erfasst und an eine Slurm-Protokolldatei angehängt. Vom Terminal des Hauptknotens aus können Sie ihn in Echtzeit inspizieren.
Außerdem gibt es im selben Verzeichnis wie die Slurm-Protokolldatei ein entsprechendes Verzeichnis für diesen Job. Dieses Verzeichnis enthält beispielsweise Folgendes:
Dieses Verzeichnis ist für alle Rechenknoten zugänglich. results.json erfasst die Metadaten dieses bestimmten Auftragslaufs, z. B. die Konfiguration des Modells, die Stapelgröße, die Gesamtschritte, die Gradientenakkumulationsschritte und den Namen des Trainingsdatensatzes. Der Modellprüfpunkt und das Ausgabeprotokoll für jeden Rechenknoten werden ebenfalls in diesem Verzeichnis erfasst.
Berücksichtigen Sie die Skalierbarkeit des Clusters
In einem Trn1 UltraCluster führen mehrere miteinander verbundene Trn1-Instanzen parallel eine große Modelltrainingslast aus und reduzieren die Gesamtberechnungszeit oder die Zeit bis zur Konvergenz. Es gibt zwei Maßstäbe für die Skalierbarkeit eines Clusters: starke Skalierung und schwache Skalierung. Typischerweise besteht beim Modelltraining die Notwendigkeit, den Trainingslauf zu beschleunigen, da die Nutzungskosten durch den Probendurchsatz für Runden von Gradientenaktualisierungen bestimmt werden. Starke Skalierung bezieht sich auf das Szenario, in dem die Gesamtproblemgröße gleich bleibt, wenn die Anzahl der Prozessoren zunimmt. Starke Skalierung ist ein wichtiges Maß für die Skalierbarkeit für das Modelltraining. Bei der Bewertung der starken Skalierung (dh der Auswirkungen der Parallelisierung) möchten wir die globale Stapelgröße gleich halten und sehen, wie viel Zeit bis zur Konvergenz benötigt wird. In einem solchen Szenario müssen wir den Mikroschritt der Gradientenakkumulation entsprechend der Anzahl der Rechenknoten anpassen. Dies wird mit dem folgenden im Trainings-Shell-Skript erreicht run_dp_bert_large_hf_pretrain_bf16_s128.sh:
Wenn Sie andererseits auswerten möchten, wie viele weitere Workloads zu einem festgelegten Zeitpunkt ausgeführt werden können, indem Sie weitere Knoten hinzufügen, verwenden Sie schwache Skalierung, um die Skalierbarkeit zu messen. Bei schwacher Skalierung wächst die Problemgröße mit der gleichen Rate wie die Anzahl der NeuronCores, wodurch der Arbeitsaufwand pro NeuronCores gleich bleibt. Um eine schwache Skalierung oder die Auswirkung des Hinzufügens weiterer Knoten auf die erhöhte Arbeitslast zu bewerten, entfernen Sie einfach die obige Zeile aus dem Trainingsskript und halten Sie die Anzahl der Schritte für die Gradientenakkumulation mit einem im Trainingsskript bereitgestellten Standardwert (32) konstant.
Werten Sie Ihre Ergebnisse aus
Wir stellen einige Benchmark-Ergebnisse in der zur Verfügung Seite Neuronleistung um den Skalierungseffekt zu demonstrieren. Die Daten demonstrieren den Vorteil der Verwendung mehrerer Instanzen zur Parallelisierung des Trainingsjobs für viele verschiedene große Modelle zum Training im großen Maßstab.
Bereinigen Sie Ihre Infrastruktur
Um die gesamte Infrastruktur dieses UltraClusters zu löschen, verwenden Sie die pcluster Befehl zum Löschen des Clusters und seiner Ressourcen:
Zusammenfassung
In diesem Beitrag haben wir besprochen, wie die Skalierung Ihres Trainingsjobs über einen Trn1-UltraCluster, der von Trainium-Beschleunigern in AWS betrieben wird, die Zeit zum Trainieren eines Modells verkürzt. Wir haben auch einen Link zu der bereitgestellt Repositorium für Neuron-Beispiele, das Anweisungen zum Bereitstellen eines verteilten Trainingsjobs für ein BERT-Large-Modell enthält. Trn1-UltraCluster führt verteilte Trainingsworkloads aus, um extrem große Deep-Learning-Modelle im großen Maßstab zu trainieren. Ein verteiltes Trainingssetup führt zu einer viel schnelleren Modellkonvergenz im Vergleich zum Training auf einer einzelnen Trn1-Instance.
Um mehr über die ersten Schritte mit Trainium-betriebenen Trn1-Instanzen zu erfahren, besuchen Sie die Neuron-Dokumentation.
Über die Autoren
 KC Tung ist Senior Solution Architect bei AWS Annapurna Labs. Er ist spezialisiert auf das Training großer Deep-Learning-Modelle und die Bereitstellung in großem Maßstab in der Cloud. Er hat einen Ph.D. in molekularer Biophysik vom University of Texas Southwestern Medical Center in Dallas. Er hat auf AWS Summits und AWS Reinvent gesprochen. Heute hilft er Kunden beim Trainieren und Bereitstellen großer PyTorch- und TensorFlow-Modelle in der AWS-Cloud. Er ist Autor zweier Bücher: Lernen Sie TensorFlow Enterprise kennen und TensorFlow 2 Pocket-Referenz.
KC Tung ist Senior Solution Architect bei AWS Annapurna Labs. Er ist spezialisiert auf das Training großer Deep-Learning-Modelle und die Bereitstellung in großem Maßstab in der Cloud. Er hat einen Ph.D. in molekularer Biophysik vom University of Texas Southwestern Medical Center in Dallas. Er hat auf AWS Summits und AWS Reinvent gesprochen. Heute hilft er Kunden beim Trainieren und Bereitstellen großer PyTorch- und TensorFlow-Modelle in der AWS-Cloud. Er ist Autor zweier Bücher: Lernen Sie TensorFlow Enterprise kennen und TensorFlow 2 Pocket-Referenz.
 Jeffrey Huynh ist leitender Ingenieur bei AWS Annapurna Labs. Er ist leidenschaftlich daran interessiert, Kunden dabei zu helfen, ihre Trainings- und Inferenz-Workloads auf Trainium- und Inferentia-Beschleunigergeräten auszuführen AWS Neuron-SDK. Er ist ein Caltech/Stanford-Alumni mit Abschlüssen in Physik und EE. Er läuft gerne, spielt Tennis, kocht und liest gerne über Wissenschaft und Technologie.
Jeffrey Huynh ist leitender Ingenieur bei AWS Annapurna Labs. Er ist leidenschaftlich daran interessiert, Kunden dabei zu helfen, ihre Trainings- und Inferenz-Workloads auf Trainium- und Inferentia-Beschleunigergeräten auszuführen AWS Neuron-SDK. Er ist ein Caltech/Stanford-Alumni mit Abschlüssen in Physik und EE. Er läuft gerne, spielt Tennis, kocht und liest gerne über Wissenschaft und Technologie.
 Shruti Koparkar ist Senior Product Marketing Manager bei AWS. Sie hilft Kunden bei der Erkundung, Bewertung und Einführung der beschleunigten EC2-Computing-Infrastruktur für ihre Anforderungen an maschinelles Lernen.
Shruti Koparkar ist Senior Product Marketing Manager bei AWS. Sie hilft Kunden bei der Erkundung, Bewertung und Einführung der beschleunigten EC2-Computing-Infrastruktur für ihre Anforderungen an maschinelles Lernen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/scaling-large-language-model-llm-training-with-amazon-ec2-trn1-ultraclusters/

