In den letzten Jahren haben sich Data Lakes zu einer Mainstream-Architektur entwickelt, und die Validierung der Datenqualität ist ein entscheidender Faktor für die Verbesserung der Wiederverwendbarkeit und Konsistenz der Daten. AWS Glue-Datenqualität Reduziert den zur Datenvalidierung erforderlichen Aufwand von Tagen auf Stunden und bietet Rechenempfehlungen, Statistiken und Einblicke in die für die Datenvalidierung erforderlichen Ressourcen.
AWS Glue Data Quality basiert darauf DeeQu, ein Open-Source-Tool, das bei Amazon entwickelt und verwendet wird, um Datenqualitätsmetriken zu berechnen und Datenqualitätseinschränkungen und Änderungen in der Datenverteilung zu überprüfen, sodass Sie sich auf die Beschreibung konzentrieren können, wie Daten aussehen sollten, anstatt Algorithmen zu implementieren.
In diesem Beitrag stellen wir Benchmark-Ergebnisse der Ausführung immer komplexerer Datenqualitätsregelsätze über einen vordefinierten Testdatensatz bereit. Als Teil der Ergebnisse zeigen wir, wie AWS Glue Data Quality Informationen über die Laufzeit von Extraktions-, Transformations- und Ladejobs (ETL), die in Datenverarbeitungseinheiten (DPUs) gemessenen Ressourcen und wie Sie die Kosten verfolgen können, bereitstellt der Ausführung von AWS Glue Data Quality für ETL-Pipelines durch die Definition benutzerdefinierter Kostenberichte im AWS Cost Explorer.
Lösungsüberblick
Wir beginnen mit der Definition unseres Testdatensatzes, um zu untersuchen, wie AWS Glue Data Quality abhängig von den Eingabedatensätzen automatisch skaliert.
Datensatzdetails
Der Testdatensatz enthält 104 Spalten und 1 Million Zeilen, die im Parquet-Format gespeichert sind. Du kannst Laden Sie den Datensatz herunter oder erstellen Sie es lokal mit dem im bereitgestellten Python-Skript neu Quelle. Wenn Sie sich für die Ausführung des Generatorskripts entscheiden, müssen Sie das installieren Pandas und Mimesis Pakete in Ihrer Python-Umgebung:
Das Datensatzschema ist eine Kombination aus numerischen, kategorialen und Zeichenfolgenvariablen, um über genügend Attribute für die Verwendung einer Kombination der integrierten AWS Glue Data Quality zu verfügen Regeltypen. Das Schema repliziert einige der häufigsten Attribute, die in Finanzmarktdaten zu finden sind, wie z. B. Instrumententicker, gehandelte Volumina und Preisprognosen.
Regelsätze für die Datenqualität
Wir kategorisieren einige der integrierten AWS Glue Data Quality-Regeltypen, um die Benchmark-Struktur zu definieren. Die Kategorien berücksichtigen, ob die Regeln Spaltenprüfungen durchführen, die keine Inspektion auf Zeilenebene erfordern (einfache Regeln), eine zeilenweise Analyse (mittlere Regeln) oder Datentypprüfungen durchführen und schließlich Zeilenwerte mit anderen Datenquellen vergleichen (komplexe Regeln). ). Die folgende Tabelle fasst diese Regeln zusammen.
| Einfache Regeln | Mittlere Regeln | Komplexe Regeln |
| Spaltenanzahl | DistinctValuesCount | Spaltenwerte |
| ColumnDataType | Ist komplett | Vollständigkeit |
| ColumnExist | Sum | Referenzielle Integrität |
| ColumnNamesMatchPattern | Standardabweichung | ColumnCorrelation |
| Reihenanzahl | Bedeuten | RowCountMatch |
| ColumnLength | . | . |
Wir definieren acht verschiedene AWS Glue ETL-Jobs, in denen wir die Datenqualitätsregelsätze ausführen. Jedem Job ist eine unterschiedliche Anzahl von Datenqualitätsregeln zugeordnet. Zu jedem Job gehört auch ein Job Benutzerdefiniertes Kostenzuordnungs-Tag die wir später zum Erstellen eines Datenqualitätskostenberichts im AWS Cost Explorer verwenden.
In der folgenden Tabelle stellen wir die Klartextdefinition für jeden Regelsatz bereit.
| Berufsbezeichnung | Einfache Regeln | Mittlere Regeln | Komplexe Regeln | Anzahl der Regeln | Etikett | Definition |
| Regelsatz-0 | 0 | 0 | 0 | 0 | dqjob:rs0 | - |
| Regelsatz-1 | 0 | 0 | 1 | 1 | dqjob:rs1 | Link |
| Regelsatz-5 | 3 | 1 | 1 | 5 | dqjob:rs5 | Link |
| Regelsatz-10 | 6 | 2 | 2 | 10 | dqjob:rs10 | Link |
| Regelsatz-50 | 30 | 10 | 10 | 50 | dqjob:rs50 | Link |
| Regelsatz-100 | 50 | 30 | 20 | 100 | dqjob:rs100 | Link |
| Regelsatz-200 | 100 | 60 | 40 | 200 | dqjob:rs200 | Link |
| Regelsatz-400 | 200 | 120 | 80 | 400 | dqjob:rs400 | Link |
Erstellen Sie die AWS Glue ETL-Aufträge, die die Datenqualitätsregelsätze enthalten
Wir laden die hoch Testdatensatz zu Amazon Simple Storage-Service (Amazon S3) und auch zwei zusätzliche CSV-Dateien, die wir zur Bewertung der referenziellen Integritätsregeln in AWS Glue Data Quality verwenden werden (isocodes.csv und Exchanges.csv), nachdem sie dem AWS Glue-Datenkatalog hinzugefügt wurden. Führen Sie die folgenden Schritte aus:
- Erstellen Sie auf der Amazon S3-Konsole einen neuen S3-Bucket in Ihrem Konto und laden Sie ihn hoch Testdatensatz.
- Erstellen Sie im S3-Bucket einen Ordner mit dem Namen
isocodesund laden Sie die isocodes.csv Datei. - Erstellen Sie im S3-Bucket einen weiteren Ordner mit dem Namen „Exchange“ und laden Sie ihn hoch Exchanges.csv Datei.
- Führen Sie in der AWS Glue-Konsole zwei AWS Glue-Crawler aus, einen für jeden Ordner, um den CSV-Inhalt im AWS Glue Data Catalog zu registrieren (
data_quality_catalog). Anweisungen finden Sie unter Hinzufügen eines AWS Glue Crawlers.
Die AWS Glue-Crawler generieren zwei Tabellen (exchanges und isocodes) als Teil des AWS Glue Data Catalog.

Jetzt erstellen wir das AWS Identity and Access Management and (ICH BIN) Rolle das wird von den ETL-Jobs zur Laufzeit übernommen:
- Erstellen Sie auf der IAM-Konsole eine neue IAM-Rolle mit dem Namen
AWSGlueDataQualityPerformanceRole - Aussichten für Vertrauenswürdiger EntitätstypWählen AWS-Service.
- Aussichten für Service oder Anwendungsfall, wählen Kleben.
- Auswählen Weiter.

- Aussichten für Berechtigungsrichtlinien, eingeben
AWSGlueServiceRole - Auswählen
Weiter.

- Erstellen Sie eine neue Inline-Richtlinie und hängen Sie sie an (
AWSGlueDataQualityBucketPolicy) mit folgendem Inhalt. Ersetzen Sie den Platzhalter durch den S3-Bucket-Namen, den Sie zuvor erstellt haben:
Als Nächstes erstellen wir einen der AWS Glue ETL-Jobs: ruleset-5.
- Auf der AWS Glue-Konsole unter ETL-Jobs Wählen Sie im Navigationsbereich Visuelles ETL.
- Im Job erstellen Wählen Sie im Abschnitt Visuelles ETL.x

- Fügen Sie im visuellen Editor eine hinzu Datenquelle – S3-Bucket Quellknoten:
- Aussichten für S3-URLGeben Sie den S3-Ordner ein, der den Testdatensatz enthält.
- Aussichten für Datei Format, wählen Parkett.

- Erstellen Sie einen neuen Aktionsknoten. Transformieren: Datenkatalog auswerten:
- Aussichten für Knoteneltern, wählen Sie den von Ihnen erstellten Knoten aus.
- Fügen Sie Regelsatz-5-Definition für Regelsatz-Editor.

- Scrollen Sie bis zum Ende und darunter Leistungskonfiguration, aktivieren Daten zwischenspeichern.

- Der JobdetailsZ. IAM-Rolle, wählen
AWSGlueDataQualityPerformanceRole.
- Im Schlüsselwörter Abschnitt, definieren dqjob taggen als rs5.
Dieses Tag ist für jeden Datenqualitäts-ETL-Job unterschiedlich. Wir verwenden sie im AWS Cost Explorer, um die Kosten für ETL-Jobs zu überprüfen.

- Auswählen Speichern.
- Wiederholen Sie diese Schritte mit den restlichen Regelsätzen, um alle ETL-Jobs zu definieren.

Führen Sie die AWS Glue ETL-Jobs aus
Führen Sie die folgenden Schritte aus, um die ETL-Jobs auszuführen:
- Wählen Sie in der AWS Glue-Konsole aus Visuelles ETL für ETL-Jobs im Navigationsbereich.
- Wählen Sie den ETL-Job aus und wählen Sie Job ausführen.
- Wiederholen Sie diesen Vorgang für alle ETL-Jobs.

Wenn die ETL-Jobs abgeschlossen sind, wird die Überwachung der Jobausführung Auf der Seite werden die Auftragsdetails angezeigt. Wie im folgenden Screenshot gezeigt, a DPU-Stunden Für jeden ETL-Job wird eine Spalte bereitgestellt.

Überprüfen Sie die Leistung
Die folgende Tabelle fasst die Dauer, die DPU-Stunden und die geschätzten Kosten für die Ausführung der acht verschiedenen Datenqualitätsregelsätze für denselben Testdatensatz zusammen. Beachten Sie, dass alle Regelsätze mit dem gesamten zuvor beschriebenen Testdatensatz ausgeführt wurden (104 Spalten, 1 Million Zeilen).
| ETL-Jobname | Anzahl der Regeln | Etikett | Dauer (Sek.) | Anzahl der DPU-Stunden | Anzahl der DPUs | Kosten ($) |
| Regelsatz-400 | 400 | dqjob:rs400 | 445.7 | 1.24 | 10 | $0.54 |
| Regelsatz-200 | 200 | dqjob:rs200 | 235.7 | 0.65 | 10 | $0.29 |
| Regelsatz-100 | 100 | dqjob:rs100 | 186.5 | 0.52 | 10 | $0.23 |
| Regelsatz-50 | 50 | dqjob:rs50 | 155.2 | 0.43 | 10 | $0.19 |
| Regelsatz-10 | 10 | dqjob:rs10 | 152.2 | 0.42 | 10 | $0.18 |
| Regelsatz-5 | 5 | dqjob:rs5 | 150.3 | 0.42 | 10 | $0.18 |
| Regelsatz-1 | 1 | dqjob:rs1 | 150.1 | 0.42 | 10 | $0.18 |
| Regelsatz-0 | 0 | dqjob:rs0 | 53.2 | 0.15 | 10 | $0.06 |
Die Kosten für die Auswertung eines leeren Regelsatzes liegen nahe bei Null, wurden jedoch einbezogen, da er als Schnelltest zur Validierung der IAM-Rollen verwendet werden kann, die mit den AWS Glue Data Quality-Jobs und Leseberechtigungen für den Testdatensatz in Amazon S3 verknüpft sind. Die Kosten für Datenqualitätsjobs steigen erst nach der Auswertung von Regelsätzen mit mehr als 100 Regeln und bleiben unterhalb dieser Zahl konstant.
Wir können beobachten, dass die Kosten für die Ausführung der Datenqualität für den größten Regelsatz im Benchmark (400 Regeln) immer noch etwas über 0.50 $ liegen.
Datenqualitätskostenanalyse im AWS Cost Explorer
Um die Datenqualitäts-ETL-Job-Tags im AWS Cost Explorer anzuzeigen, müssen Sie Folgendes tun Aktivieren Sie die benutzerdefinierten Kostenzuordnungs-Tags zuerst.
Nachdem Sie benutzerdefinierte Tags erstellt und auf Ihre Ressourcen angewendet haben, kann es bis zu 24 Stunden dauern, bis die Tag-Schlüssel auf Ihrer Seite mit den Kostenzuordnungs-Tags zur Aktivierung angezeigt werden. Es kann dann bis zu 24 Stunden dauern, bis die Tag-Schlüssel aktiviert werden.
- Auf der AWS Kosten-Explorer Konsole wählen Gespeicherte Berichte im Cost Explorer im Navigationsbereich.
- Auswählen
Neuen Bericht erstellen.

- Auswählen Kosten und Nutzung als Berichtstyp.
- Auswählen
Bericht erstellen.
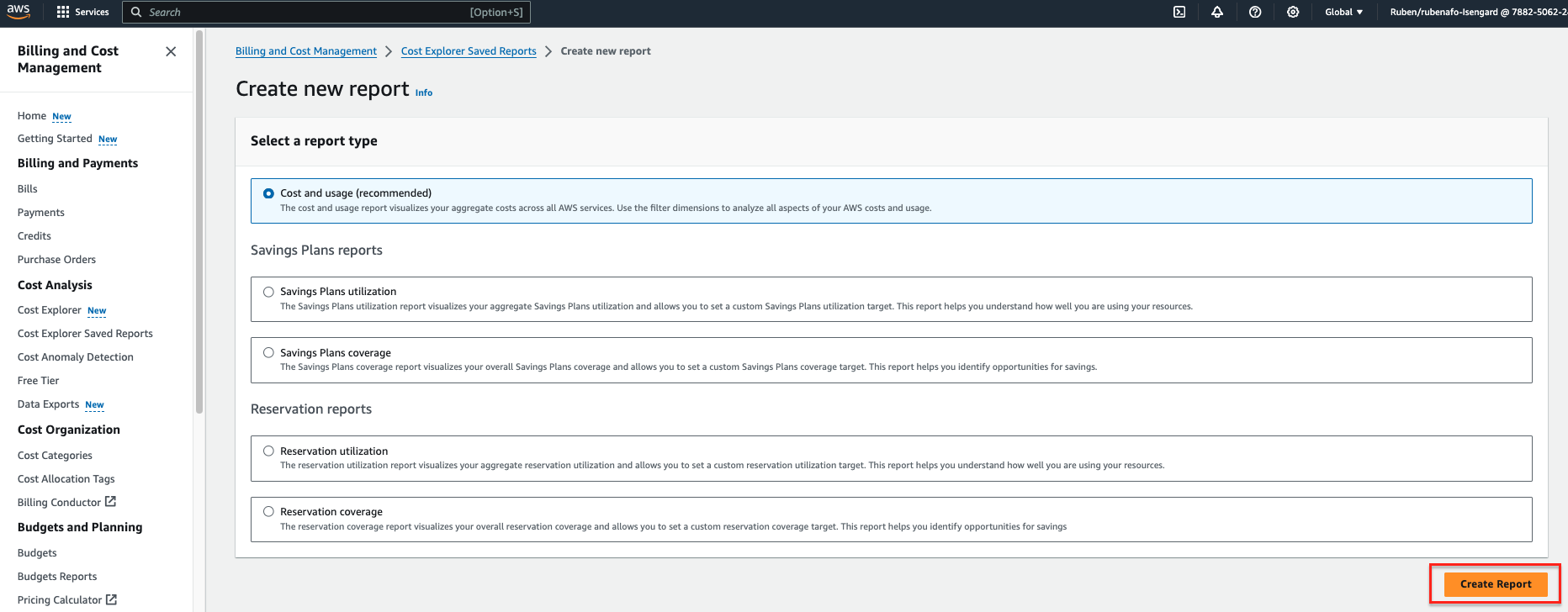
- Aussichten für Datumsbereich, geben Sie einen Datumsbereich ein.
- Aussichten für Körnungwählen Daily.
- Aussichten für Abmessungen, wählen Etikett, dann wähle die
dqjob-Tag.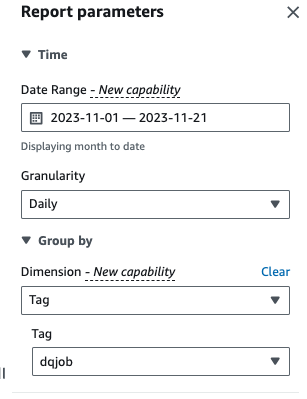
- Der Angewandte Filter, wählen Sie das
dqjobTag und die acht Tags, die in den Datenqualitätsregelsätzen verwendet werden (rs0, rs1, rs5, rs10, rs50, rs100, rs200 und rs400).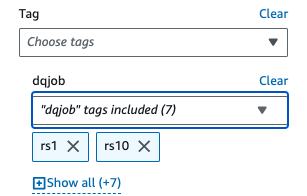
- Auswählen Jetzt bewerben.
Der Kosten- und Nutzungsbericht wird aktualisiert. Die X-Achse zeigt die Tags des Datenqualitätsregelsatzes als Kategorien. Der Kosten und Nutzung Das Diagramm im AWS Cost Explorer wird aktualisiert und zeigt die monatlichen Gesamtkosten der zuletzt ausgeführten Datenqualitäts-ETL-Jobs an, aggregiert nach ETL-Job.

Aufräumen
Führen Sie die folgenden Schritte aus, um die Infrastruktur zu bereinigen und zusätzliche Gebühren zu vermeiden:
- Leeren Sie den S3-Bucket, der ursprünglich zum Speichern des Testdatensatzes erstellt wurde.
- Löschen Sie die ETL-Aufträge, die Sie in AWS Glue erstellt haben.
- Löschen Sie die
AWSGlueDataQualityPerformanceRoleIAM-Rolle. - Löschen Sie den in AWS Cost Explorer erstellten benutzerdefinierten Bericht.
Zusammenfassung
AWS Glue Data Quality bietet eine effiziente Möglichkeit, die Validierung der Datenqualität als Teil von ETL-Pipelines zu integrieren und automatisch zu skalieren, um steigende Datenmengen zu bewältigen. Die integrierten Datenqualitätsregeltypen bieten eine Vielzahl von Optionen, um die Datenqualitätsprüfungen anzupassen und sich darauf zu konzentrieren, wie Ihre Daten aussehen sollen, anstatt undifferenzierte Logik zu implementieren.
In dieser Benchmark-Analyse haben wir gezeigt, dass AWS Glue Data Quality-Regelsätze in üblicher Größe nur einen geringen oder keinen Overhead verursachen, wohingegen in komplexen Fällen die Kosten linear ansteigen. Wir haben auch untersucht, wie Sie AWS Glue Data Quality-Jobs markieren können, um Kosteninformationen in AWS Cost Explorer für eine schnelle Berichterstellung verfügbar zu machen.
Die Datenqualität von AWS Glue ist allgemein erhältlich in allen AWS-Regionen, in denen AWS Glue verfügbar ist. Erfahren Sie mehr über AWS Glue Data Quality und AWS Glue Data Catalog in Erste Schritte mit AWS Glue Data Quality aus dem AWS Glue Data Catalog.
Über die Autoren
 Ruben Afonso ist ein Global Financial Services Solutions Architect bei AWS. Er arbeitet gerne an Analyse- und KI/ML-Herausforderungen, mit einer Leidenschaft für Automatisierung und Optimierung. Wenn er nicht bei der Arbeit ist, findet er gerne versteckte Orte abseits der ausgetretenen Pfade in Barcelona.
Ruben Afonso ist ein Global Financial Services Solutions Architect bei AWS. Er arbeitet gerne an Analyse- und KI/ML-Herausforderungen, mit einer Leidenschaft für Automatisierung und Optimierung. Wenn er nicht bei der Arbeit ist, findet er gerne versteckte Orte abseits der ausgetretenen Pfade in Barcelona.
 Kalyan Kumar Neelampudi (KK) ist Specialist Partner Solutions Architect (Datenanalyse und generative KI) bei AWS. Er fungiert als technischer Berater und arbeitet mit verschiedenen AWS-Partnern zusammen, um Praktiken rund um Datenanalysen und KI/ML-Workloads zu entwerfen, zu implementieren und aufzubauen. Außerhalb der Arbeit ist er ein Badminton-Enthusiast und kulinarischer Abenteurer, erkundet die lokale Küche und reist mit seinem Partner, um neue Geschmäcker und Erfahrungen zu entdecken.
Kalyan Kumar Neelampudi (KK) ist Specialist Partner Solutions Architect (Datenanalyse und generative KI) bei AWS. Er fungiert als technischer Berater und arbeitet mit verschiedenen AWS-Partnern zusammen, um Praktiken rund um Datenanalysen und KI/ML-Workloads zu entwerfen, zu implementieren und aufzubauen. Außerhalb der Arbeit ist er ein Badminton-Enthusiast und kulinarischer Abenteurer, erkundet die lokale Küche und reist mit seinem Partner, um neue Geschmäcker und Erfahrungen zu entdecken.

Gonzalo herreros ist Senior Big Data Architect im AWS Glue-Team.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/measure-performance-of-aws-glue-data-quality-for-etl-pipelines/

