Krones beliefert Brauereien, Getränkeabfüller und Lebensmittelhersteller auf der ganzen Welt mit Einzelmaschinen und kompletten Produktionslinien. Täglich laufen Millionen von Glasflaschen, Dosen und PET-Behältern durch eine Krones-Linie. Produktionslinien sind komplexe Systeme mit vielen möglichen Fehlern, die zum Stillstand der Linie und zu einer Verringerung der Produktionsausbeute führen können. Krones möchte den Fehler so früh wie möglich (manchmal sogar bevor er auftritt) erkennen und die Betreiber der Produktionslinie benachrichtigen, um die Zuverlässigkeit und den Output zu erhöhen. Wie erkennt man also einen Fehler? Krones stattet seine Linien mit Sensoren zur Datenerfassung aus, die dann anhand von Regeln ausgewertet werden können. Sowohl Krones als Anlagenhersteller als auch der Anlagenbetreiber haben die Möglichkeit, Überwachungsregeln für Maschinen zu erstellen. Daher können Getränkeabfüller und andere Betreiber ihre eigene Fehlertoleranz für die Linie definieren. Bisher nutzte Krones ein System, das auf einer Zeitreihendatenbank basierte. Die größten Herausforderungen bestanden darin, dass dieses System schwer zu debuggen war und außerdem Abfragen den aktuellen Zustand der Maschinen darstellten, nicht jedoch die Zustandsübergänge.
Dieser Beitrag zeigt, wie Krones eine Streaming-Lösung zur Überwachung ihrer Leitungen entwickelt hat Amazon Kinesis und Amazon Managed Service für Apache Flink. Diese vollständig verwalteten Dienste reduzieren die Komplexität der Erstellung von Streaming-Anwendungen mit Apache Flink. Managed Service für Apache Flink verwaltet die zugrunde liegenden Apache Flink-Komponenten, die dauerhaften Anwendungsstatus, Metriken, Protokolle und mehr bereitstellen, und Kinesis ermöglicht Ihnen die kostengünstige Verarbeitung von Streaming-Daten in jeder Größenordnung. Wenn Sie mit Ihrer eigenen Apache Flink-Anwendung beginnen möchten, schauen Sie sich die an GitHub-Repository für Beispiele, die die Java-, Python- oder SQL-APIs von Flink verwenden.
Lösungsübersicht
Dazu gehört auch die Anlagenüberwachung von Krones Krones Werkstattleitfaden System. Es unterstützt bei der Organisation, Priorisierung, Steuerung und Dokumentation aller Aktivitäten im Unternehmen. Damit können sie einen Bediener benachrichtigen, wenn die Maschine angehalten ist oder Materialien benötigt werden, unabhängig davon, wo sich der Bediener in der Linie befindet. Bewährte Zustandsüberwachungsregeln sind bereits integriert, können aber auch über die Benutzeroberfläche benutzerdefiniert werden. Verstößt beispielsweise ein bestimmter überwachter Datenpunkt gegen einen Schwellenwert, kann eine SMS oder ein Auslöser für einen Wartungsauftrag auf der Leitung erfolgen.
Das Zustandsüberwachungs- und Regelbewertungssystem basiert auf AWS und nutzt AWS-Analysedienste. Das folgende Diagramm veranschaulicht die Architektur.
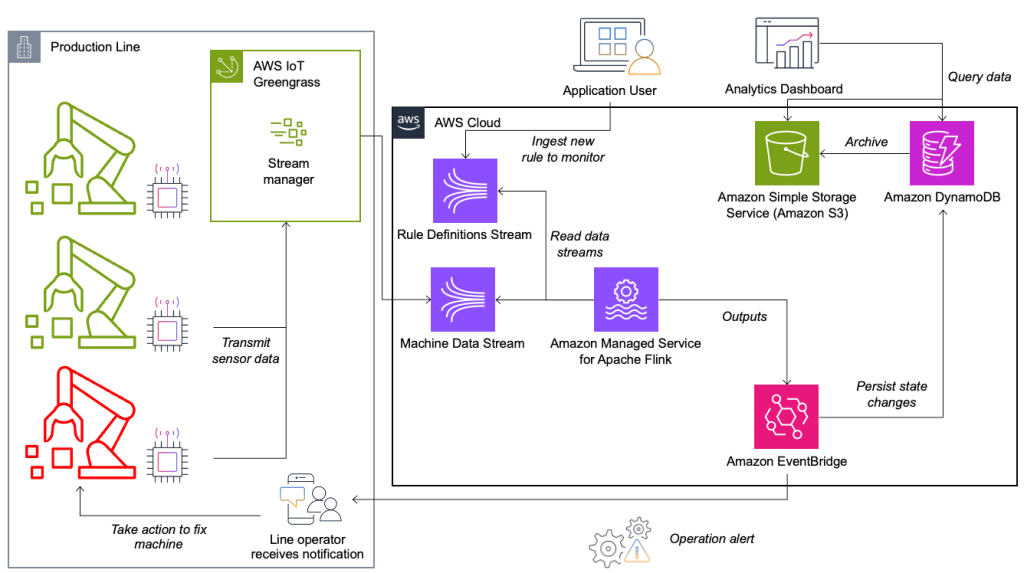
Fast jede Daten-Streaming-Anwendung besteht aus fünf Ebenen: Datenquelle, Stream-Aufnahme, Stream-Speicherung, Stream-Verarbeitung und einem oder mehreren Zielen. In den folgenden Abschnitten gehen wir tiefer auf die einzelnen Ebenen ein und erläutern, wie die von Krones entwickelte Leitungsüberwachungslösung im Detail funktioniert.
Datenquelle
Die Daten werden von einem Dienst gesammelt, der auf einem Edge-Gerät läuft und mehrere Protokolle wie Siemens S7 oder OPC/UA liest. Rohdaten werden vorverarbeitet, um eine einheitliche JSON-Struktur zu erstellen, die die spätere Verarbeitung in der Regel-Engine erleichtert. Eine in JSON konvertierte Beispielnutzlast könnte wie folgt aussehen:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Streamaufnahme
AWS IoT Greengrass ist ein Open-Source-Edge-Laufzeit- und Cloud-Dienst für das Internet der Dinge (IoT). Dadurch können Sie lokal auf Daten reagieren und Gerätedaten aggregieren und filtern. AWS IoT Greengrass bietet vorgefertigte Komponenten, die am Rand bereitgestellt werden können. Die Produktionslinienlösung nutzt die Stream-Manager-Komponente, die Daten verarbeiten und an AWS-Ziele wie z. B. übertragen kann AWS IoT-Analytics, Amazon Simple Storage-Service (Amazon S3) und Kinesis. Der Stream-Manager puffert und aggregiert Datensätze und sendet sie dann an einen Kinesis-Datenstream.
Stream-Speicher
Die Aufgabe des Stream-Speichers besteht darin, Nachrichten fehlertolerant zu puffern und für die Nutzung durch eine oder mehrere Verbraucheranwendungen verfügbar zu machen. Um dies auf AWS zu erreichen, sind Kinesis und die gängigsten Technologien Amazon Managed Streaming für Apache Kafka (Amazon MSK). Für die Speicherung unserer Sensordaten aus Produktionslinien wählt Krones Kinesis. Kinesis ist ein serverloser Streaming-Datendienst, der in jeder Größenordnung mit geringer Latenz funktioniert. Shards innerhalb eines Kinesis-Datenstroms sind eine eindeutig identifizierte Folge von Datensätzen, wobei ein Stream aus einem oder mehreren Shards besteht. Jeder Shard verfügt über eine Lesekapazität von 2 MB/s und eine Schreibkapazität von 1 MB/s (mit maximal 1,000 Datensätzen/s). Um zu vermeiden, dass diese Grenzen erreicht werden, sollten die Daten möglichst gleichmäßig auf die Shards verteilt werden. Jeder an Kinesis gesendete Datensatz verfügt über einen Partitionsschlüssel, der zum Gruppieren von Daten in einem Shard verwendet wird. Daher benötigen Sie eine große Anzahl an Partitionsschlüsseln, um die Last gleichmäßig zu verteilen. Der auf AWS IoT Greengrass laufende Stream-Manager unterstützt zufällige Partitionsschlüsselzuweisungen, was bedeutet, dass alle Datensätze in einem zufälligen Shard landen und die Last gleichmäßig verteilt wird. Ein Nachteil zufälliger Partitionsschlüsselzuweisungen besteht darin, dass Datensätze in Kinesis nicht in der richtigen Reihenfolge gespeichert werden. Wie Sie dieses Problem lösen können, erklären wir im nächsten Abschnitt, in dem wir über Wasserzeichen sprechen.
Wasserzeichen
A Wasserzeichen ist ein Mechanismus zum Verfolgen und Messen des Fortschritts der Ereigniszeit in einem Datenstrom. Die Ereigniszeit ist der Zeitstempel seit der Erstellung des Ereignisses an der Quelle. Das Wasserzeichen zeigt den zeitlichen Fortschritt der Stream-Verarbeitungsanwendung an, sodass alle Ereignisse mit einem früheren oder gleichen Zeitstempel als verarbeitet gelten. Diese Informationen sind für Flink unerlässlich, um die Ereigniszeit voranzutreiben und relevante Berechnungen, wie z. B. Fensterauswertungen, auszulösen. Die zulässige Verzögerung zwischen Ereigniszeit und Wasserzeichen kann konfiguriert werden, um zu bestimmen, wie lange auf verspätete Daten gewartet werden soll, bevor ein Fenster als abgeschlossen betrachtet und das Wasserzeichen vorgezogen wird.
Krones verfügt über Systeme auf der ganzen Welt und musste verspätete Ankünfte aufgrund von Verbindungsverlusten oder anderen Netzwerkbeschränkungen bewältigen. Sie begannen damit, verspätete Ankünfte zu überwachen und die standardmäßige Flink-Verspätungsbehandlung auf den Maximalwert zu setzen, den sie in dieser Metrik sahen. Sie hatten Probleme mit der Zeitsynchronisierung der Edge-Geräte, was sie dazu veranlasste, eine ausgefeiltere Methode zur Wasserzeichenmarkierung zu verwenden. Sie erstellten ein globales Wasserzeichen für alle Absender und verwendeten den niedrigsten Wert als Wasserzeichen. Die Zeitstempel werden für alle eingehenden Ereignisse in einer HashMap gespeichert. Wenn die Wasserzeichen regelmäßig ausgegeben werden, wird der kleinste Wert dieser HashMap verwendet. Um zu verhindern, dass Wasserzeichen aufgrund fehlender Daten ins Stocken geraten, haben sie eine konfiguriert idleTimeOut Parameter, der Zeitstempel ignoriert, die älter als ein bestimmter Schwellenwert sind. Dies erhöht die Latenz, sorgt aber für eine starke Datenkonsistenz.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Stream-Verarbeitung
Nachdem die Daten von Sensoren gesammelt und in Kinesis aufgenommen wurden, müssen sie von einer Regel-Engine ausgewertet werden. Eine Regel in diesem System stellt den Zustand einer einzelnen Metrik (z. B. Temperatur) oder einer Sammlung von Metriken dar. Um eine Metrik zu interpretieren, wird mehr als ein Datenpunkt verwendet, es handelt sich um eine zustandsbehaftete Berechnung. In diesem Abschnitt befassen wir uns eingehender mit dem Schlüsselstatus und dem Broadcast-Status in Apache Flink und wie diese zum Aufbau der Krones-Regel-Engine verwendet werden.
Steuern Sie Stream- und Broadcast-Statusmuster
Bei Apache Flink, Zustand bezieht sich auf die Fähigkeit des Systems, Informationen dauerhaft über Zeit und Vorgänge hinweg zu speichern und zu verwalten und so die Verarbeitung von Streaming-Daten mit Unterstützung für zustandsbehaftete Berechnungen zu ermöglichen.
Das Broadcast-Statusmuster ermöglicht die Verteilung eines Zustands auf alle parallelen Instanzen eines Operators. Daher haben alle Operatoren denselben Status und Daten können mit demselben Status verarbeitet werden. Diese schreibgeschützten Daten können mithilfe eines Steuerstroms erfasst werden. Ein Steuerstrom ist ein regulärer Datenstrom, jedoch normalerweise mit einer viel geringeren Datenrate. Mit diesem Muster können Sie den Status aller Operatoren dynamisch aktualisieren, sodass der Benutzer den Status und das Verhalten der Anwendung ändern kann, ohne dass eine erneute Bereitstellung erforderlich ist. Genauer gesagt erfolgt die Verteilung des Zustands mithilfe eines Kontrollstroms. Durch das Hinzufügen eines neuen Datensatzes zum Kontrollstrom erhalten alle Operatoren diese Aktualisierung und verwenden den neuen Status für die Verarbeitung neuer Nachrichten.
Dadurch können Benutzer der Krones-Anwendung neue Regeln in die Flink-Anwendung aufnehmen, ohne diese neu starten zu müssen. Dies vermeidet Ausfallzeiten und sorgt für ein großartiges Benutzererlebnis, da Änderungen in Echtzeit erfolgen. Eine Regel deckt ein Szenario ab, um eine Prozessabweichung zu erkennen. Manchmal sind die Maschinendaten nicht so einfach zu interpretieren, wie es auf den ersten Blick erscheinen mag. Wenn ein Temperatursensor hohe Werte sendet, kann dies auf einen Fehler hinweisen, aber auch auf eine laufende Wartung zurückzuführen sein. Es ist wichtig, Metriken in einen Kontext zu stellen und einige Werte zu filtern. Dies wird durch ein Konzept namens erreicht Gruppierung.
Gruppierung von Metriken
Durch die Gruppierung von Daten und Metriken können Sie die Relevanz eingehender Daten definieren und genaue Ergebnisse erzielen. Gehen wir das Beispiel in der folgenden Abbildung durch.
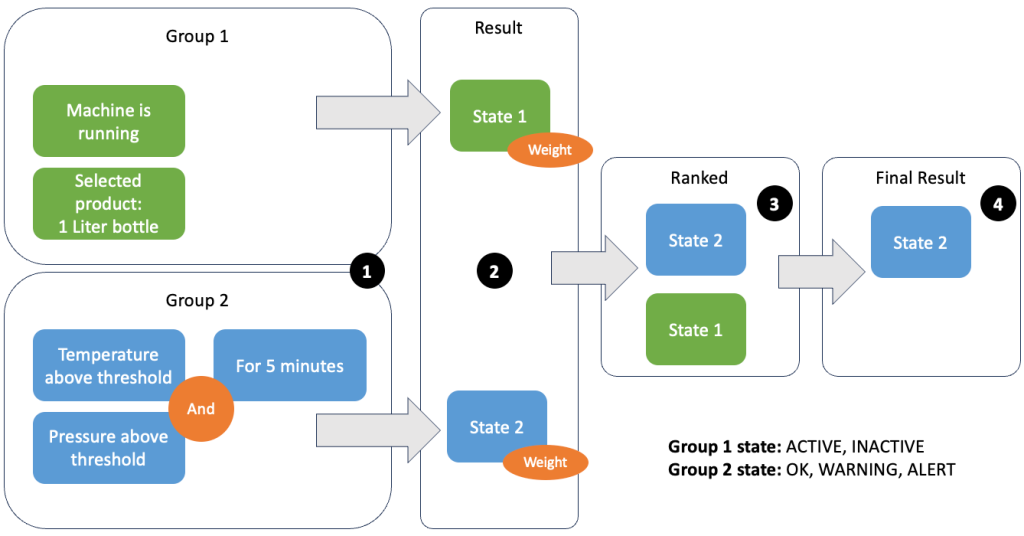
In Schritt 1 definieren wir zwei Bedingungsgruppen. Gruppe 1 erfasst den Maschinenzustand und welches Produkt die Linie durchläuft. Gruppe 2 verwendet den Wert der Temperatur- und Drucksensoren. Eine Bedingungsgruppe kann abhängig von den empfangenen Werten unterschiedliche Zustände haben. In diesem Beispiel erhält Gruppe 1 die Daten, dass die Maschine läuft, und als Produkt wird die XNUMX-Liter-Flasche ausgewählt; Dadurch erhält diese Gruppe den Status ACTIVE. Gruppe 2 verfügt über Messwerte für Temperatur und Druck; Beide Messwerte liegen länger als 5 Minuten über ihren Schwellenwerten. Dies führt dazu, dass Gruppe 2 in a ist WARNING Zustand. Das heißt, Gruppe 1 meldet, dass alles in Ordnung ist, Gruppe 2 jedoch nicht. In Schritt 2 werden den Gruppen Gewichte hinzugefügt. Dies ist in manchen Situationen erforderlich, da Gruppen möglicherweise widersprüchliche Informationen melden. In diesem Szenario meldet sich Gruppe 1 ACTIVE und Gruppe 2-Berichte WARNINGDaher ist dem System nicht klar, wie der Status der Leitung ist. Nach dem Hinzufügen der Gewichte können die Bundesstaaten in eine Rangfolge gebracht werden, wie in Schritt 3 gezeigt. Schließlich wird der Staat mit dem höchsten Rang als Sieger ausgewählt, wie in Schritt 4 gezeigt.
Nachdem die Regeln ausgewertet und der endgültige Maschinenzustand definiert wurde, werden die Ergebnisse weiterverarbeitet. Die ergriffene Aktion hängt von der Regelkonfiguration ab; Dies kann eine Benachrichtigung an den Linienbetreiber sein, um Materialien aufzufüllen, Wartungsarbeiten durchzuführen oder einfach nur eine visuelle Aktualisierung auf dem Dashboard. Dieser Teil des Systems, der Metriken und Regeln auswertet und auf der Grundlage der Ergebnisse Maßnahmen ergreift, wird als a bezeichnet Regel-Engine.
Skalieren der Regel-Engine
Indem Benutzer ihre eigenen Regeln erstellen können, kann die Regel-Engine über eine große Anzahl von Regeln verfügen, die ausgewertet werden müssen, und einige Regeln verwenden möglicherweise dieselben Sensordaten wie andere Regeln. Flink ist ein verteiltes System, das sich horizontal sehr gut skalieren lässt. Um einen Datenstrom auf mehrere Aufgaben zu verteilen, können Sie die verwenden keyBy() Methode. Dadurch können Sie einen Datenstrom logisch unterteilen und Teile der Daten an verschiedene Task-Manager senden. Dies geschieht häufig durch die Wahl eines beliebigen Schlüssels, sodass eine gleichmäßig verteilte Last erzielt wird. In diesem Fall fügte Krones a ruleId zum Datenpunkt und nutzte ihn als Schlüssel. Andernfalls werden benötigte Datenpunkte von einer anderen Aufgabe verarbeitet. Der verschlüsselte Datenstrom kann wie eine reguläre Variable regelübergreifend verwendet werden.
Reiseziele
Wenn eine Regel ihren Status ändert, werden die Informationen an einen Kinesis-Stream und dann über gesendet Amazon EventBridge an Verbraucher. Einer der Verbraucher erstellt aus dem Ereignis eine Benachrichtigung, die an die Produktionslinie übermittelt wird und das Personal zum Handeln auffordert. Um die Regelzustandsänderungen analysieren zu können, schreibt ein anderer Dienst die Daten in einen Amazon DynamoDB Tabelle für schnellen Zugriff und eine TTL ist vorhanden, um den Langzeitverlauf zur weiteren Berichterstattung an Amazon S3 auszulagern.
Zusammenfassung
In diesem Beitrag haben wir Ihnen gezeigt, wie Krones ein Echtzeit-Produktionslinienüberwachungssystem auf AWS aufgebaut hat. Managed Service für Apache Flink ermöglichte dem Krones-Team einen schnellen Einstieg, indem es sich auf die Anwendungsentwicklung statt auf die Infrastruktur konzentrierte. Durch die Echtzeitfähigkeiten von Flink konnte Krones die Maschinenstillstandszeiten um 10 % reduzieren und die Effizienz um bis zu 5 % steigern.
Wenn Sie Ihre eigenen Streaming-Anwendungen erstellen möchten, sehen Sie sich die verfügbaren Beispiele auf der an GitHub-Repository. Wenn Sie Ihre Flink-Anwendung mit benutzerdefinierten Connectors erweitern möchten, lesen Sie Vereinfachtes Erstellen von Connectors mit Apache Flink: Einführung der Async-Senke. Die Async-Senke ist in Apache Flink Version 1.15.1 und höher verfügbar.
Über die Autoren
 Florian Mair ist Senior Solutions Architect und Daten-Streaming-Experte bei AWS. Er ist ein Technologe, der Kunden in Europa zum Erfolg und zur Innovation verhilft, indem er geschäftliche Herausforderungen mithilfe von AWS Cloud-Diensten löst. Neben seiner Tätigkeit als Lösungsarchitekt ist Florian ein leidenschaftlicher Bergsteiger und hat einige der höchsten Berge Europas bestiegen.
Florian Mair ist Senior Solutions Architect und Daten-Streaming-Experte bei AWS. Er ist ein Technologe, der Kunden in Europa zum Erfolg und zur Innovation verhilft, indem er geschäftliche Herausforderungen mithilfe von AWS Cloud-Diensten löst. Neben seiner Tätigkeit als Lösungsarchitekt ist Florian ein leidenschaftlicher Bergsteiger und hat einige der höchsten Berge Europas bestiegen.
 Emil Dietl ist Senior Tech Lead bei Krones mit Spezialisierung auf Data Engineering, mit einem Schwerpunkt auf Apache Flink und Microservices. Seine Arbeit umfasst häufig die Entwicklung und Wartung geschäftskritischer Software. Außerhalb seines Berufslebens legt er großen Wert darauf, Zeit mit seiner Familie zu verbringen.
Emil Dietl ist Senior Tech Lead bei Krones mit Spezialisierung auf Data Engineering, mit einem Schwerpunkt auf Apache Flink und Microservices. Seine Arbeit umfasst häufig die Entwicklung und Wartung geschäftskritischer Software. Außerhalb seines Berufslebens legt er großen Wert darauf, Zeit mit seiner Familie zu verbringen.
 Simon Peyer ist Lösungsarchitekt bei AWS mit Sitz in der Schweiz. Er ist ein praktischer Macher und setzt sich leidenschaftlich für die Verbindung von Technologie und Menschen ein, die AWS Cloud-Dienste nutzen. Ein besonderer Schwerpunkt liegt für ihn auf Datenstreaming und Automatisierungen. Neben der Arbeit genießt Simon seine Familie, die Natur und das Wandern in den Bergen.
Simon Peyer ist Lösungsarchitekt bei AWS mit Sitz in der Schweiz. Er ist ein praktischer Macher und setzt sich leidenschaftlich für die Verbindung von Technologie und Menschen ein, die AWS Cloud-Dienste nutzen. Ein besonderer Schwerpunkt liegt für ihn auf Datenstreaming und Automatisierungen. Neben der Arbeit genießt Simon seine Familie, die Natur und das Wandern in den Bergen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

