KT Corporation ist einer der größten Telekommunikationsanbieter in Südkorea und bietet eine breite Palette von Diensten an, darunter Festnetztelefonie, Mobilkommunikation, Internet und KI-Dienste. AI Food Tag von KT ist eine KI-basierte Ernährungsmanagementlösung, die mithilfe eines Computer-Vision-Modells die Art und den Nährstoffgehalt von Lebensmitteln in Fotos identifiziert. Dieses von KT entwickelte Sehmodell basiert auf einem vorab trainierten Modell mit einer großen Menge unbeschrifteter Bilddaten, um den Nährwert und die Kalorieninformationen verschiedener Lebensmittel zu analysieren. Der AI Food Tag kann Patienten mit chronischen Krankheiten wie Diabetes bei der Bewältigung ihrer Ernährung helfen. KT nutzte AWS und Amazon Sage Maker um dieses AI Food Tag-Modell 29-mal schneller als zuvor zu trainieren und es mit einer Modelldestillationstechnik für den Produktionseinsatz zu optimieren. In diesem Beitrag beschreiben wir den Weg und Erfolg von KT zur Modellentwicklung mit SageMaker.
Vorstellung des KT-Projekts und Definition des Problems
Das von KT vorab trainierte AI Food Tag-Modell basiert auf der Vision Transformers (ViT)-Architektur und verfügt über mehr Modellparameter als das vorherige Vision-Modell, um die Genauigkeit zu verbessern. Um die Modellgröße für die Produktion zu verkleinern, verwendet KT eine Technik der Wissensdestillation (KD), um die Anzahl der Modellparameter ohne nennenswerte Auswirkungen auf die Genauigkeit zu reduzieren. Bei der Wissensdestillation wird das vorab trainierte Modell als a bezeichnet Lehrermodell, und ein leichtes Ausgabemodell wird als trainiert Studentenmodell, wie in der folgenden Abbildung dargestellt. Das leichtgewichtige Schülermodell verfügt über weniger Modellparameter als das Lehrermodell, was den Speicherbedarf reduziert und die Bereitstellung auf kleineren, kostengünstigeren Instanzen ermöglicht. Der Schüler behält eine akzeptable Genauigkeit bei, auch wenn diese geringer ist, indem er aus den Ergebnissen des Lehrermodells lernt.

Das Lehrermodell bleibt während KD unverändert, aber das Schülermodell wird trainiert, indem die Ausgabeprotokolle des Lehrermodells als Etiketten zur Verlustberechnung verwendet werden. Bei diesem KD-Paradigma müssen sich sowohl der Lehrer als auch der Schüler für das Training auf einem einzigen GPU-Speicher befinden. KT nutzte zunächst zwei GPUs (A100 80 GB) in seiner internen, lokalen Umgebung, um das Studentenmodell zu trainieren, aber der Prozess dauerte etwa 40 Tage, um 300 Epochen abzudecken. Um die Ausbildung zu beschleunigen und in kürzerer Zeit ein Studentenmodell zu erstellen, hat KT eine Partnerschaft mit AWS geschlossen. Gemeinsam konnten die Teams die Modellschulungszeit erheblich reduzieren. In diesem Beitrag wird beschrieben, wie das Team gearbeitet hat Amazon SageMaker-Schulung, der SageMaker-Datenparallelitätsbibliothek, Amazon SageMaker-Debugger und Amazon SageMaker Profiler erfolgreich ein leichtes AI Food Tag-Modell zu entwickeln.
Aufbau einer verteilten Schulungsumgebung mit SageMaker
SageMaker Training ist eine verwaltete Trainingsumgebung für maschinelles Lernen (ML) auf AWS, die eine Reihe von Funktionen und Tools zur Vereinfachung des Trainingserlebnisses bereitstellt und beim verteilten Rechnen nützlich sein kann, wie im folgenden Diagramm dargestellt.
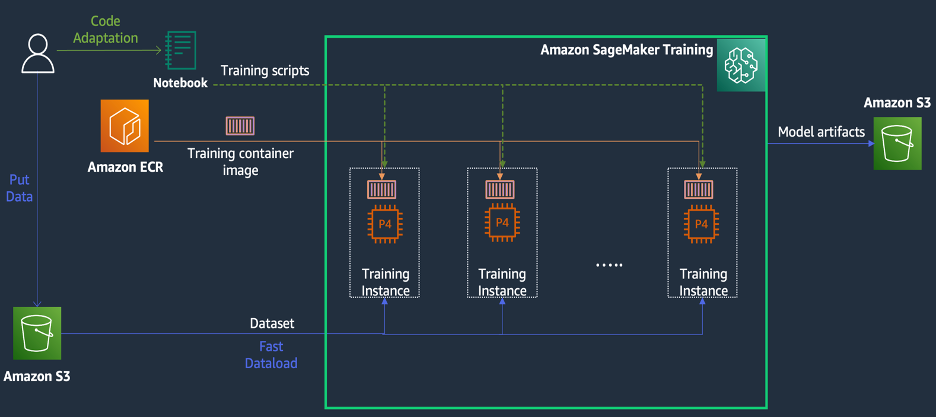
SageMaker-Kunden können außerdem auf integrierte Docker-Images mit verschiedenen vorinstallierten Deep-Learning-Frameworks und den erforderlichen Linux-, NCCL- und Python-Paketen für das Modelltraining zugreifen. Datenwissenschaftler oder ML-Ingenieure, die Modelltraining durchführen möchten, können dies tun, ohne die Trainingsinfrastruktur konfigurieren oder Docker und die Kompatibilität verschiedener Bibliotheken verwalten zu müssen.
Während eines eintägigen Workshops konnten wir eine verteilte Trainingskonfiguration auf Basis von SageMaker im AWS-Konto von KT einrichten, die Trainingsskripte von KT mithilfe der SageMaker Distributed Data Parallel (DDP)-Bibliothek beschleunigen und sogar einen Trainingsjob mit zwei ml testen. p1d.4xlarge-Instanzen. In diesem Abschnitt beschreiben wir die Erfahrungen von KT bei der Zusammenarbeit mit dem AWS-Team und der Verwendung von SageMaker zur Entwicklung ihres Modells.
Im Proof of Concept wollten wir einen Schulungsauftrag beschleunigen, indem wir die SageMaker DDP-Bibliothek verwenden, die für die AWS-Infrastruktur während verteilter Schulungen optimiert ist. Um von PyTorch DDP zu SageMaker DDP zu wechseln, müssen Sie lediglich das deklarieren torch_smddp Paket und ändern Sie das Backend in smddp, wie im folgenden Code gezeigt:
Weitere Informationen zur SageMaker DDP-Bibliothek finden Sie unter Die Datenparallelitätsbibliothek von SageMaker.
Analysieren Sie die Ursachen einer langsamen Trainingsgeschwindigkeit mit dem SageMaker Debugger und Profiler
Der erste Schritt zur Optimierung und Beschleunigung einer Schulungsarbeitsbelastung besteht darin, zu verstehen und zu diagnostizieren, wo Engpässe auftreten. Für den Trainingsjob von KT haben wir die Trainingszeit pro Iteration des Datenladers, Vorwärtsdurchlauf und Rückwärtsdurchlauf gemessen:
| 1 Iterzeit – Datenlader: 0.00053 Sek., Vorwärts: 7.77474 Sek., Rückwärts: 1.58002 Sek. |
| 2 Iterzeit – Datenlader: 0.00063 Sek., Vorwärts: 0.67429 Sek., Rückwärts: 24.74539 Sek. |
| 3 Iterzeit – Datenlader: 0.00061 Sek., Vorwärts: 0.90976 Sek., Rückwärts: 8.31253 Sek. |
| 4 Iterzeit – Datenlader: 0.00060 Sek., Vorwärts: 0.60958 Sek., Rückwärts: 30.93830 Sek. |
| 5 Iterzeit – Datenlader: 0.00080 Sek., Vorwärts: 0.83237 Sek., Rückwärts: 8.41030 Sek. |
| 6 Iterzeit – Datenlader: 0.00067 Sek., Vorwärts: 0.75715 Sek., Rückwärts: 29.88415 Sek. |
Als wir die Zeit in der Standardausgabe für jede Iteration betrachteten, stellten wir fest, dass die Laufzeit des Rückwärtsdurchlaufs von Iteration zu Iteration erheblich schwankte. Diese Variation ist ungewöhnlich und kann sich auf die gesamte Trainingszeit auswirken. Um die Ursache für diese inkonsistente Trainingsgeschwindigkeit zu finden, haben wir zunächst versucht, Ressourcenengpässe mithilfe des Systemmonitors (SageMaker Debugger UI) zu identifizieren, der es Ihnen ermöglicht, Trainingsjobs auf SageMaker Training zu debuggen und den Status von Ressourcen wie den verwalteten Trainingsplattformen anzuzeigen CPU, GPU, Netzwerk und E/A innerhalb einer festgelegten Anzahl von Sekunden.
Die SageMaker Debugger-Benutzeroberfläche stellt detaillierte und wichtige Daten bereit, die bei der Identifizierung und Diagnose von Engpässen in einem Trainingsjob helfen können. Insbesondere fielen uns das Liniendiagramm zur CPU-Auslastung und die Heatmap-Tabellen zur CPU/GPU-Auslastung pro Instanz ins Auge.
Im Liniendiagramm der CPU-Auslastung haben wir festgestellt, dass einige CPUs zu 100 % ausgelastet waren.
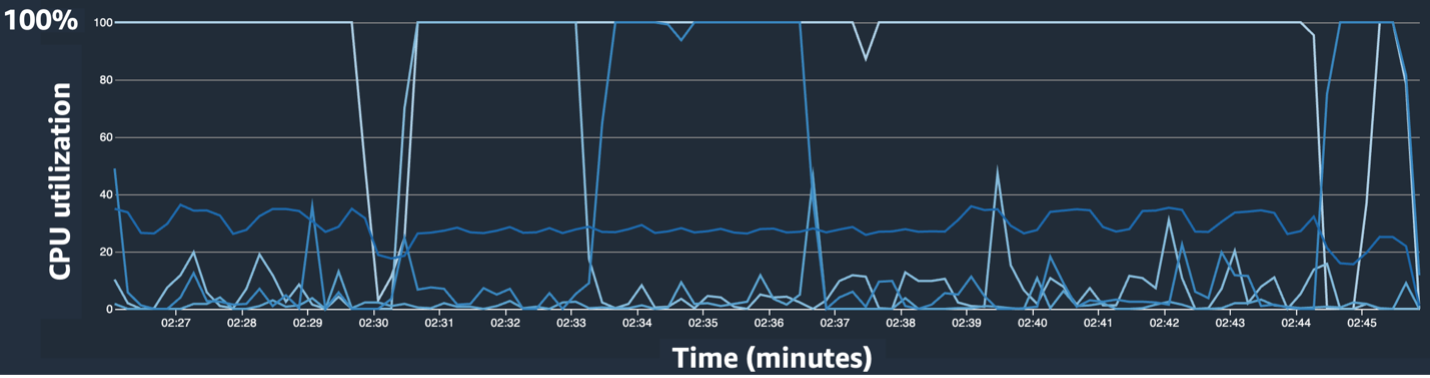
In der Heatmap (wo dunklere Farben eine höhere Auslastung anzeigen) haben wir festgestellt, dass einige CPU-Kerne während des gesamten Trainings eine hohe Auslastung aufwiesen, während die GPU-Auslastung im Laufe der Zeit nicht konstant hoch war.

Von da an begannen wir zu vermuten, dass einer der Gründe für die langsame Trainingsgeschwindigkeit ein CPU-Engpass war. Wir haben den Code des Trainingsskripts überprüft, um festzustellen, ob irgendetwas den CPU-Engpass verursacht hat. Der verdächtigste Teil war der hohe Wert num_workers im Datenlader, daher haben wir diesen Wert auf 0 oder 1 geändert, um die CPU-Auslastung zu reduzieren. Anschließend haben wir den Trainingsjob erneut ausgeführt und die Ergebnisse überprüft.
Die folgenden Screenshots zeigen das Liniendiagramm der CPU-Auslastung, die GPU-Auslastung und die Heatmap nach Beseitigung des CPU-Engpasses.
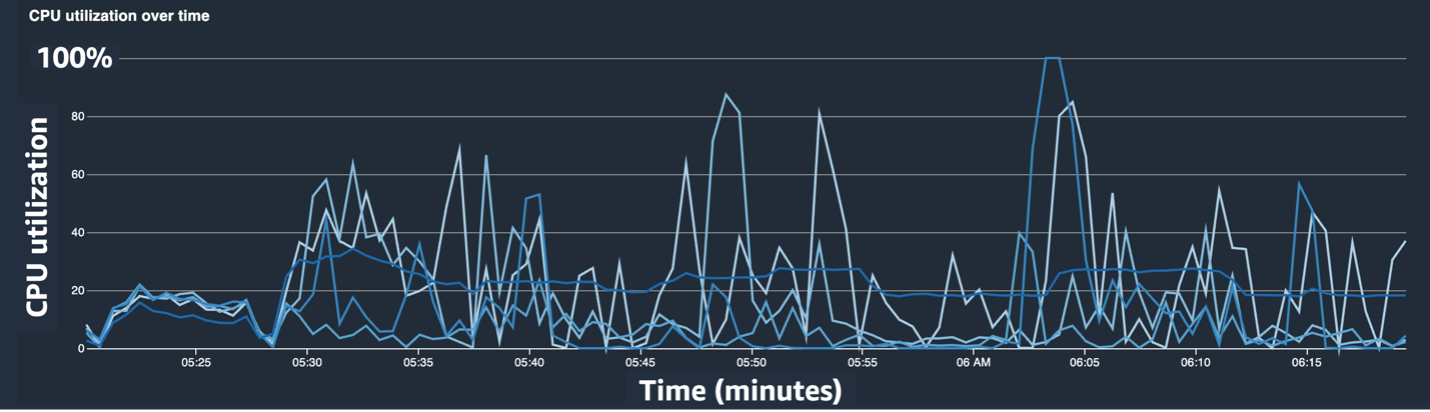


Durch einfaches Umstellen num_workers, konnten wir einen deutlichen Rückgang der CPU-Auslastung und einen allgemeinen Anstieg der GPU-Auslastung feststellen. Dies war eine wichtige Änderung, die die Trainingsgeschwindigkeit erheblich verbesserte. Dennoch wollten wir sehen, wo wir die GPU-Auslastung optimieren können. Hierfür haben wir SageMaker Profiler verwendet.
SageMaker Profiler hilft bei der Identifizierung von Optimierungshinweisen, indem es Einblicke in die Auslastung durch Vorgänge bietet, einschließlich der Verfolgung von GPU- und CPU-Auslastungsmetriken und des Kernelverbrauchs von GPU/CPU in Trainingsskripten. Es hilft Benutzern zu verstehen, welche Vorgänge Ressourcen verbrauchen. Um SageMaker Profiler verwenden zu können, müssen Sie zunächst Folgendes hinzufügen ProfilerConfig an die Funktion, die den Trainingsjob mithilfe des SageMaker SDK aufruft, wie im folgenden Code gezeigt:
Im SageMaker Python SDK haben Sie die Flexibilität, Folgendes hinzuzufügen annotate Funktionen für SageMaker Profiler, um Code oder Schritte im Trainingsskript auszuwählen, die eine Profilierung erfordern. Das Folgende ist ein Beispiel für den Code, den Sie für SageMaker Profiler in den Trainingsskripten deklarieren sollten:
Wenn Sie nach dem Hinzufügen des vorherigen Codes einen Trainingsjob mithilfe der Trainingsskripts ausführen, können Sie Informationen über die vom GPU-Kernel verbrauchten Vorgänge erhalten (wie in der folgenden Abbildung dargestellt), nachdem das Training über einen bestimmten Zeitraum ausgeführt wurde. Im Fall der KT-Trainingsskripte haben wir sie eine Epoche lang ausgeführt und die folgenden Ergebnisse erhalten.
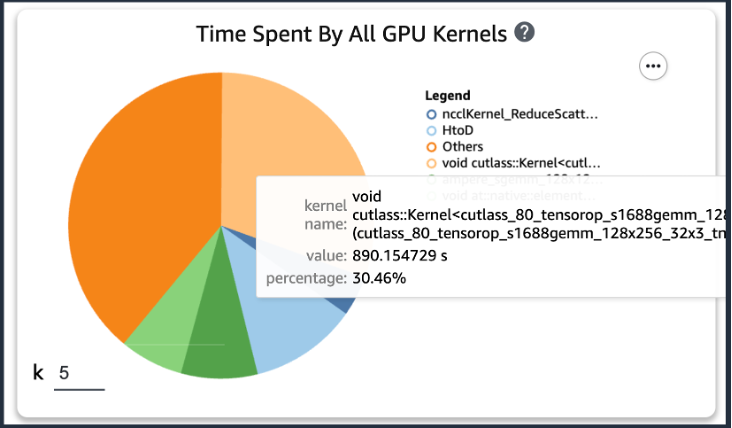
Als wir die fünf höchsten Betriebsverbrauchszeiten des GPU-Kernels in den Ergebnissen von SageMaker Profiler überprüften, stellten wir fest, dass für das KT-Trainingsskript die Matrixproduktoperation, bei der es sich um eine allgemeine Matrixmultiplikationsoperation (GEMM) handelt, die meiste Zeit verbraucht auf GPUs. Mit dieser wichtigen Erkenntnis aus dem SageMaker Profiler begannen wir mit der Suche nach Möglichkeiten, diese Vorgänge zu beschleunigen und die GPU-Auslastung zu verbessern.
Verkürzung der Trainingszeit
Wir haben verschiedene Möglichkeiten zur Reduzierung der Rechenzeit der Matrixmultiplikation untersucht und zwei PyTorch-Funktionen angewendet.
Shard-Optimiererstatus mit ZeroRedundancyOptimizer
Wenn man sich die Zero Redundancy Optimizer (ZeRO)Die DeepSpeed/ZeRO-Technik ermöglicht das effiziente Training eines großen Modells mit höherer Trainingsgeschwindigkeit, indem die Redundanzen im vom Modell verwendeten Speicher beseitigt werden. ZeroRedundancyOptimizer in PyTorch verwendet die Technik des Shardings des Optimiererstatus, um die Speichernutzung pro Prozess in Distributed Data Parallel (DDP) zu reduzieren. DDP verwendet synchronisierte Gradienten im Rückwärtsdurchlauf, sodass alle Replikate des Optimierers über dieselben Parameter und Gradientenwerte iterieren. Anstatt jedoch über alle Modellparameter zu verfügen, wird jeder Optimiererstatus durch Sharding nur für verschiedene DDP-Prozesse beibehalten, um die Speichernutzung zu reduzieren.
Um es zu verwenden, können Sie Ihren vorhandenen Optimierer drin lassen optimizer_class und deklarieren a ZeroRedundancyOptimizer mit den restlichen Modellparametern und der Lernrate als Parameter.
Automatische gemischte Präzision
Automatische gemischte Präzision (AMP) verwendet für einige Vorgänge den Datentyp Torch.float32 und Torch.bfloat16 oder Torch.float16 für andere, um schnelle Berechnungen zu ermöglichen und den Speicherverbrauch zu reduzieren. Da Deep-Learning-Modelle in ihren Berechnungen typischerweise empfindlicher auf Exponentenbits reagieren als auf Bruchbits, entspricht Torch.bfloat16 den Exponentenbits von Torch.float32, sodass sie schnell und mit minimalem Verlust lernen können. Torch.bfloat16 läuft nur auf Instanzen mit A100 NVIDIA-Architektur (Ampere) oder höher, wie z. B. ml.p4d.24xlarge, ml.p4de.24xlarge und ml.p5.48xlarge.
Um AMP anzuwenden, können Sie eine Erklärung abgeben torch.cuda.amp.autocast in den Trainingsskripten wie im obigen Code gezeigt und deklarieren dtype als Torch.bfloat16.
Ergebnisse im SageMaker Profiler
Nachdem wir die beiden Funktionen auf die Trainingsskripte angewendet und erneut einen Trainingsauftrag für eine Epoche ausgeführt hatten, überprüften wir die fünf höchsten Betriebsverbrauchszeiten für den GPU-Kernel in SageMaker Profiler. Die folgende Abbildung zeigt unsere Ergebnisse.
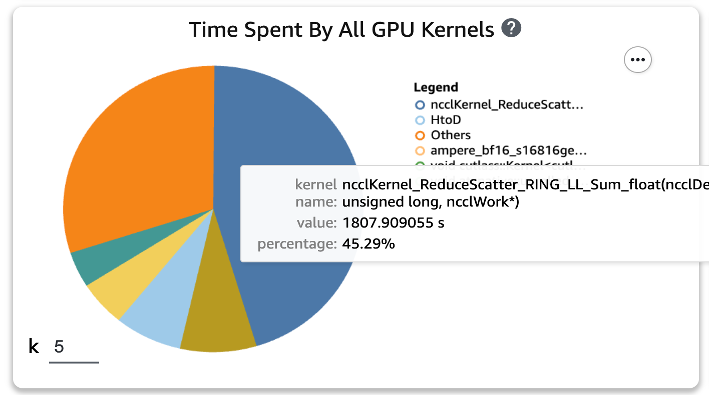
Wir können sehen, dass die GEMM-Operation, die vor der Anwendung der beiden Torch-Funktionen ganz oben auf der Liste stand, aus den Top-XNUMX-Operationen verschwunden ist und durch die ReduceScatter-Operation ersetzt wurde, die typischerweise bei verteiltem Training auftritt.
Trainingsgeschwindigkeitsergebnisse des KT-destillierten Modells
Wir haben die Trainingsbatchgröße um weitere 128 erhöht, um die Speichereinsparungen durch die Anwendung der beiden Torch-Funktionen zu berücksichtigen, was zu einer endgültigen Batchgröße von 1152 statt 1024 führte. Das Training des endgültigen Studentenmodells konnte 210 Epochen pro Tag ausführen ; Die Trainingszeit und die Beschleunigung zwischen der internen Trainingsumgebung von KT und SageMaker sind in der folgenden Tabelle zusammengefasst.
| Trainingsumgebung | GPU-Spezifikation trainieren. | Anzahl der GPU | Trainingszeit (Stunden) | Epoch | Stunden pro Epoche | Untersetzung |
| KTs interne Schulungsumgebung | A100 (80 GB) | 2 | 960 | 300 | 3.20 | 29 |
| Amazon Sage Maker | A100 (40 GB) | 32 | 24 | 210 | 0.11 | 1 |
Die Skalierbarkeit von AWS ermöglichte es uns, den Trainingsauftrag 29-mal schneller als zuvor abzuschließen, indem wir 32 GPUs anstelle von 2 vor Ort verwendeten. Infolgedessen hätte die Verwendung von mehr GPUs auf SageMaker die Schulungszeit erheblich verkürzt, ohne dass sich die gesamten Schulungskosten verändert hätten.
Zusammenfassung
Park Sang-min (Vision AI Serving Technology Team Leader) vom AI2XL Lab im Convergence Technology Center von KT kommentierte die Zusammenarbeit mit AWS bei der Entwicklung des AI Food Tag-Modells:
„Da es in letzter Zeit immer mehr transformatorbasierte Modelle im Vision-Bereich gibt, nehmen die Modellparameter und der erforderliche GPU-Speicher zu. Wir verwenden Leichtbautechnologie, um dieses Problem zu lösen, und es dauert sehr lange, etwa einen Monat, um es einmal zu lernen. Durch diesen PoC mit AWS konnten wir die Ressourcenengpässe mit Hilfe von SageMaker Profiler und Debugger identifizieren, beheben und dann die Datenparallelitätsbibliothek von SageMaker nutzen, um das Training in etwa einem Tag mit optimiertem Modellcode auf vier ml.p4d abzuschließen. 24xgroße Instanzen.“
SageMaker hat dazu beigetragen, dass Sang-mins Team Wochen bei der Modellschulung und -entwicklung eingespart hat.
Basierend auf dieser Zusammenarbeit am Visionsmodell werden AWS und das SageMaker-Team weiterhin mit KT an verschiedenen KI/ML-Forschungsprojekten zusammenarbeiten, um die Modellentwicklung und Serviceproduktivität durch den Einsatz von SageMaker-Funktionen zu verbessern.
Weitere Informationen zu verwandten Funktionen in SageMaker finden Sie hier:
Über die Autoren
 Youngjoon Choi, AI/ML Expert SA, hat als Entwickler, Architekt und Datenwissenschaftler Erfahrungen mit Unternehmens-IT in verschiedenen Branchen wie Fertigung, Hightech und Finanzen gesammelt. Er forschte zu maschinellem Lernen und Deep Learning, insbesondere zu Themen wie Hyperparameteroptimierung und Domänenanpassung, und stellte Algorithmen und Artikel vor. Bei AWS ist er auf branchenübergreifende KI/ML spezialisiert und bietet technische Validierung mithilfe von AWS-Services für verteiltes Training/groß angelegte Modelle und den Aufbau von MLOps. Er schlägt Architekturen vor und prüft sie, um zur Erweiterung des KI/ML-Ökosystems beizutragen.
Youngjoon Choi, AI/ML Expert SA, hat als Entwickler, Architekt und Datenwissenschaftler Erfahrungen mit Unternehmens-IT in verschiedenen Branchen wie Fertigung, Hightech und Finanzen gesammelt. Er forschte zu maschinellem Lernen und Deep Learning, insbesondere zu Themen wie Hyperparameteroptimierung und Domänenanpassung, und stellte Algorithmen und Artikel vor. Bei AWS ist er auf branchenübergreifende KI/ML spezialisiert und bietet technische Validierung mithilfe von AWS-Services für verteiltes Training/groß angelegte Modelle und den Aufbau von MLOps. Er schlägt Architekturen vor und prüft sie, um zur Erweiterung des KI/ML-Ökosystems beizutragen.
 Jung Hoon Kim ist eine Konto-SA von AWS Korea. Basierend auf Erfahrungen im Design, der Entwicklung und der Systemmodellierung von Anwendungsarchitekturen in verschiedenen Branchen wie High-Tech, Fertigung, Finanzen und öffentlicher Sektor arbeitet er an der AWS-Cloud-Reise und der Workload-Optimierung auf AWS für Unternehmenskunden.
Jung Hoon Kim ist eine Konto-SA von AWS Korea. Basierend auf Erfahrungen im Design, der Entwicklung und der Systemmodellierung von Anwendungsarchitekturen in verschiedenen Branchen wie High-Tech, Fertigung, Finanzen und öffentlicher Sektor arbeitet er an der AWS-Cloud-Reise und der Workload-Optimierung auf AWS für Unternehmenskunden.
 Rock Sakong ist Forscher bei KT R&D. Er hat Forschung und Entwicklung für die visuelle KI in verschiedenen Bereichen durchgeführt und sich hauptsächlich mit Gesichtsattributen (Geschlecht/Brille, Hüte usw.)/Gesichtserkennungstechnologie im Zusammenhang mit dem Gesicht beschäftigt. Derzeit arbeitet er an der Leichtbautechnologie für die Vision-Modelle.
Rock Sakong ist Forscher bei KT R&D. Er hat Forschung und Entwicklung für die visuelle KI in verschiedenen Bereichen durchgeführt und sich hauptsächlich mit Gesichtsattributen (Geschlecht/Brille, Hüte usw.)/Gesichtserkennungstechnologie im Zusammenhang mit dem Gesicht beschäftigt. Derzeit arbeitet er an der Leichtbautechnologie für die Vision-Modelle.
 Manoj Ravi ist Senior Product Manager für Amazon SageMaker. Er ist begeistert von der Entwicklung von KI-Produkten der nächsten Generation und arbeitet an Software und Tools, um Kunden maschinelles Lernen im großen Maßstab zu erleichtern. Er besitzt einen MBA der Haas School of Business und einen Master in Information Systems Management der Carnegie Mellon University. In seiner Freizeit spielt Manoj gerne Tennis und beschäftigt sich mit der Landschaftsfotografie.
Manoj Ravi ist Senior Product Manager für Amazon SageMaker. Er ist begeistert von der Entwicklung von KI-Produkten der nächsten Generation und arbeitet an Software und Tools, um Kunden maschinelles Lernen im großen Maßstab zu erleichtern. Er besitzt einen MBA der Haas School of Business und einen Master in Information Systems Management der Carnegie Mellon University. In seiner Freizeit spielt Manoj gerne Tennis und beschäftigt sich mit der Landschaftsfotografie.
 Robert Van Dusen ist Senior Product Manager bei Amazon SageMaker. Er leitet Frameworks, Compiler und Optimierungstechniken für Deep-Learning-Training.
Robert Van Dusen ist Senior Product Manager bei Amazon SageMaker. Er leitet Frameworks, Compiler und Optimierungstechniken für Deep-Learning-Training.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

