Amazon Sage Maker Multi-Modell-Endpunkte (MMEs) sind eine vollständig verwaltete Funktion der SageMaker-Inferenz, mit der Sie Tausende von Modellen auf einem einzigen Endpunkt bereitstellen können. Zuvor haben MMEs den Modellen statisch CPU-Rechenleistung zugewiesen, unabhängig von der Modellverkehrslast Multi-Model-Server (MMS) als Modellserver. In diesem Beitrag diskutieren wir eine Lösung, bei der ein MME die jedem Modell zugewiesene Rechenleistung basierend auf dem Verkehrsmuster des Modells dynamisch anpassen kann. Mit dieser Lösung können Sie die zugrunde liegende Rechenleistung von MMEs effizienter nutzen und Kosten sparen.
MMEs laden und entladen Modelle dynamisch basierend auf dem eingehenden Datenverkehr am Endpunkt. Bei Verwendung von MMS als Modellserver weisen MMEs jedem Modell eine feste Anzahl von Modellarbeitern zu. Weitere Informationen finden Sie unter Modellieren Sie Hosting-Muster in Amazon SageMaker, Teil 3: Führen Sie Multi-Modell-Inferenz mit Amazon SageMaker-Multi-Modell-Endpunkten aus und optimieren Sie sie.
Dies kann jedoch zu einigen Problemen führen, wenn Ihr Verkehrsmuster variabel ist. Nehmen wir an, Sie haben ein oder mehrere Modelle, die viel Traffic erhalten. Sie können MMS so konfigurieren, dass diesen Modellen eine hohe Anzahl von Workern zugewiesen wird. Dies wird jedoch allen Modellen hinter dem MME zugewiesen, da es sich um eine statische Konfiguration handelt. Dies führt dazu, dass eine große Anzahl von Mitarbeitern Hardware-Computing nutzt – sogar die Leerlaufmodelle. Das gegenteilige Problem kann auftreten, wenn Sie einen kleinen Wert für die Anzahl der Arbeiter festlegen. Die gängigen Modelle verfügen nicht über genügend Arbeitskräfte auf Modellserverebene, um diesen Modellen ausreichend Hardware hinter dem Endpunkt ordnungsgemäß zuzuweisen. Das Hauptproblem besteht darin, dass es schwierig ist, unabhängig von Verkehrsmustern zu bleiben, wenn Sie Ihre Worker nicht auf Modellserverebene dynamisch skalieren können, um die erforderliche Rechenmenge zuzuweisen.
Die Lösung, die wir in diesem Beitrag besprechen, verwendet DJLServing als Modellserver, der dazu beitragen kann, einige der von uns besprochenen Probleme zu mildern, eine Skalierung pro Modell zu ermöglichen und es MMEs zu ermöglichen, unabhängig von Verkehrsmustern zu sein.
MME-Architektur
Mit SageMaker-MMEs können Sie mehrere Modelle hinter einem einzelnen Inferenzendpunkt bereitstellen, der eine oder mehrere Instanzen enthalten kann. Jede Instanz ist darauf ausgelegt, mehrere Modelle bis zu ihrer Speicher- und CPU-/GPU-Kapazität zu laden und bereitzustellen. Mit dieser Architektur kann ein Software-as-a-Service-Unternehmen (SaaS) die linear steigenden Kosten für das Hosten mehrerer Modelle senken und eine Wiederverwendung der Infrastruktur im Einklang mit dem Mandantenfähigkeitsmodell erreichen, das an anderer Stelle im Anwendungsstapel angewendet wird. Das folgende Diagramm veranschaulicht diese Architektur.
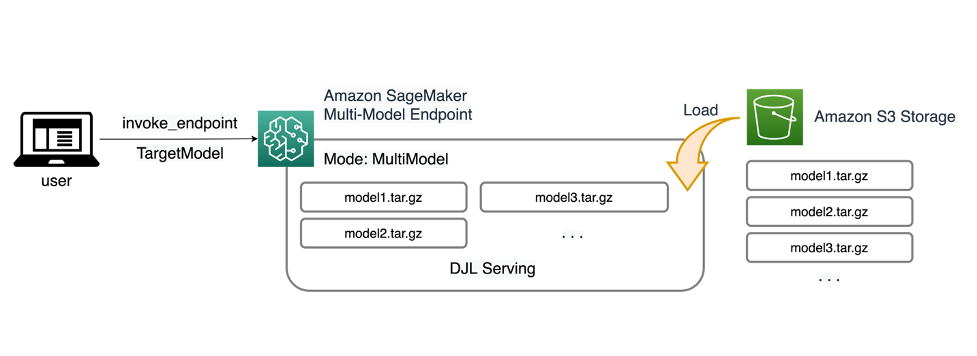
Ein SageMaker MME lädt Modelle dynamisch von Amazon Simple Storage-Service (Amazon S3) beim Aufruf, anstatt alle Modelle herunterzuladen, wenn der Endpunkt zum ersten Mal erstellt wird. Infolgedessen weist ein erster Aufruf eines Modells möglicherweise eine höhere Inferenzlatenz auf als die nachfolgenden Inferenzen, die mit geringer Latenz abgeschlossen werden. Wenn das Modell beim Aufruf bereits in den Container geladen ist, wird der Download-Schritt übersprungen und das Modell gibt die Schlussfolgerungen mit geringer Latenz zurück. Angenommen, Sie haben ein Modell, das nur ein paar Mal am Tag verwendet wird. Es wird bei Bedarf automatisch geladen, während Modelle, auf die häufig zugegriffen wird, im Speicher verbleiben und mit konstant geringer Latenz aufgerufen werden.
Hinter jeder MME befinden sich Modell-Hosting-Instanzen, wie im folgenden Diagramm dargestellt. Diese Instanzen laden und entfernen mehrere Modelle basierend auf den Datenverkehrsmustern zu den Modellen in den Speicher bzw. aus dem Speicher.
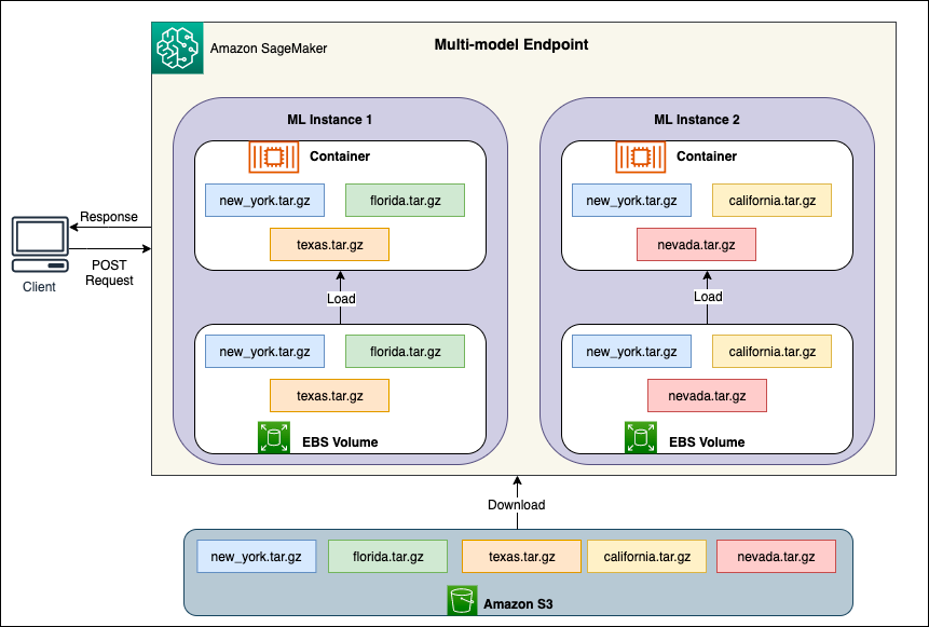
SageMaker leitet weiterhin Inferenzanfragen für ein Modell an die Instanz weiter, in der das Modell bereits geladen ist, sodass die Anfragen von einer zwischengespeicherten Modellkopie bedient werden (siehe das folgende Diagramm, das den Anfragepfad für die erste Vorhersageanfrage im Vergleich zur zwischengespeicherten Vorhersage zeigt). Anforderungspfad). Wenn das Modell jedoch viele Aufrufanfragen erhält und es zusätzliche Instanzen für die MME gibt, leitet SageMaker einige Anfragen an eine andere Instanz weiter, um der Zunahme Rechnung zu tragen. Stellen Sie sicher, dass Sie über die automatische Modellskalierung in SageMaker verfügen automatische Skalierung der Instanz eingerichtet um zusätzliche Instanzkapazität bereitzustellen. Richten Sie Ihre Skalierungsrichtlinie auf Endpunktebene entweder mit benutzerdefinierten Parametern oder mit Aufrufen pro Minute (empfohlen) ein, um der Endpunktflotte weitere Instanzen hinzuzufügen.

Übersicht über den Modellserver
Ein Modellserver ist eine Softwarekomponente, die eine Laufzeitumgebung für die Bereitstellung und Bereitstellung von Modellen für maschinelles Lernen (ML) bereitstellt. Es fungiert als Schnittstelle zwischen den trainierten Modellen und Clientanwendungen, die mithilfe dieser Modelle Vorhersagen treffen möchten.
Der Hauptzweck eines Modellservers besteht darin, eine mühelose Integration und effiziente Bereitstellung von ML-Modellen in Produktionssystemen zu ermöglichen. Anstatt das Modell direkt in eine Anwendung oder ein bestimmtes Framework einzubetten, bietet der Modellserver eine zentralisierte Plattform, auf der mehrere Modelle bereitgestellt, verwaltet und bereitgestellt werden können.
Modellserver bieten typischerweise die folgenden Funktionalitäten:
- Modell laden – Der Server lädt die trainierten ML-Modelle in den Speicher und macht sie für die Bereitstellung von Vorhersagen bereit.
- Inferenz-API – Der Server stellt eine API bereit, die es Clientanwendungen ermöglicht, Eingabedaten zu senden und Vorhersagen von den bereitgestellten Modellen zu empfangen.
- Skalierung – Modellserver sind für die Verarbeitung gleichzeitiger Anforderungen mehrerer Clients ausgelegt. Sie bieten Mechanismen für die parallele Verarbeitung und effiziente Ressourcenverwaltung, um einen hohen Durchsatz und eine geringe Latenz sicherzustellen.
- Integration mit Backend-Engines – Modellserver verfügen über Integrationen mit Backend-Frameworks wie DeepSpeed und FasterTransformer, um große Modelle zu partitionieren und hochoptimierte Inferenzen auszuführen.
DJL-Architektur
DJL serviert ist ein Open-Source-, leistungsstarker, universeller Modellserver. DJL Serving ist darauf aufgebaut Djl, eine Deep-Learning-Bibliothek, die in der Programmiersprache Java geschrieben ist. Es kann ein Deep-Learning-Modell, mehrere Modelle oder Workflows nutzen und diese über einen HTTP-Endpunkt verfügbar machen. DJL Serving unterstützt die Bereitstellung von Modellen aus mehreren Frameworks wie PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer und mehr.
DJL Serving bietet viele Funktionen, die es Ihnen ermöglichen, Ihre Modelle mit hoher Leistung bereitzustellen:
- Benutzerfreundlichkeit – DJL Serving kann die meisten Modelle sofort bedienen. Bringen Sie einfach die Modellartefakte mit und DJL Serving kann sie hosten.
- Unterstützung mehrerer Geräte und Beschleuniger – DJL Serving unterstützt die Bereitstellung von Modellen auf CPU, GPU und AWS-Inferenz.
- Leistung – DJL Serving führt Multithread-Inferenz in einer einzigen JVM aus, um den Durchsatz zu steigern.
- Dynamische Stapelverarbeitung – DJL Serving unterstützt dynamisches Batching, um den Durchsatz zu erhöhen.
- Automatische Skalierung – DJL Serving skaliert die Worker je nach Verkehrslast automatisch nach oben oder unten.
- Unterstützung mehrerer Engines – DJL Serving kann gleichzeitig Modelle mit verschiedenen Frameworks (wie PyTorch und TensorFlow) hosten.
- Ensemble- und Workflow-Modelle – DJL Serving unterstützt die Bereitstellung komplexer Workflows, die aus mehreren Modellen bestehen, und führt Teile des Workflows auf der CPU und Teile auf der GPU aus. Modelle innerhalb eines Workflows können unterschiedliche Frameworks verwenden.
Insbesondere die automatische Skalierungsfunktion von DJL Serving macht es einfach, sicherzustellen, dass die Modelle für den eingehenden Datenverkehr angemessen skaliert werden. Standardmäßig bestimmt DJL Serving die maximale Anzahl von Workern für ein Modell, die basierend auf der verfügbaren Hardware (CPU-Kerne, GPU-Geräte) unterstützt werden können. Sie können für jedes Modell Unter- und Obergrenzen festlegen, um sicherzustellen, dass immer ein minimales Datenverkehrsniveau bereitgestellt werden kann und dass ein einzelnes Modell nicht alle verfügbaren Ressourcen verbraucht.
DJL Serving verwendet a Netty Frontend über Backend-Worker-Thread-Pools. Das Frontend verwendet ein einzelnes Netty-Setup mit mehreren HttpRequestHandlers. Verschiedene Request-Handler bieten Unterstützung dafür Inferenz-API, Verwaltungs-APIoder andere APIs, die über verschiedene Plugins verfügbar sind.
Das Backend basiert auf dem WorkLoadManager (WLM)-Modul. Der WLM kümmert sich um mehrere Arbeitsthreads für jedes Modell sowie um die Stapelverarbeitung und Anforderungsweiterleitung an diese. Wenn mehrere Modelle bereitgestellt werden, prüft WLM zunächst die Größe der Inferenzanforderungswarteschlange jedes Modells. Wenn die Warteschlangengröße mehr als das Zweifache der Batchgröße eines Modells beträgt, erhöht WLM die Anzahl der diesem Modell zugewiesenen Worker.
Lösungsüberblick
Die Implementierung von DJL mit einem MME unterscheidet sich vom Standard-MMS-Setup. Für die DJL-Bereitstellung mit einem MME komprimieren wir die folgenden Dateien im model.tar.gz-Format, das SageMaker Inference erwartet:
- model.joblib – Für diese Implementierung übertragen wir die Modellmetadaten direkt in den Tarball. In diesem Fall arbeiten wir mit a
.joblibDaher stellen wir diese Datei in unserem Tarball bereit, damit unser Inferenzskript sie lesen kann. Wenn das Artefakt zu groß ist, können Sie es auch an Amazon S3 übertragen und in der Bereitstellungskonfiguration, die Sie für DJL definieren, darauf verweisen. - dienende.Eigenschaften – Hier können Sie jedes beliebige Modell serverbezogen konfigurieren Umgebungsvariablen. Die Stärke von DJL liegt darin, dass Sie es konfigurieren können
minWorkersundmaxWorkersfür jedes Modell-Tarball. Dadurch kann jedes Modell auf Modellserverebene vergrößert und verkleinert werden. Wenn beispielsweise ein einzelnes Modell den Großteil des Datenverkehrs für eine MME empfängt, skaliert der Modellserver die Worker dynamisch hoch. In diesem Beispiel konfigurieren wir diese Variablen nicht und lassen DJL die erforderliche Anzahl von Workern abhängig von unserem Verkehrsmuster bestimmen. - model.py – Dies ist das Inferenzskript für jede benutzerdefinierte Vorverarbeitung oder Nachverarbeitung, die Sie implementieren möchten. Die model.py erwartet, dass Ihre Logik standardmäßig in einer Handle-Methode gekapselt ist.
- Anforderungen.txt (optional) – Standardmäßig wird DJL mit PyTorch installiert, aber alle zusätzlichen Abhängigkeiten, die Sie benötigen, können hier gepusht werden.
In diesem Beispiel demonstrieren wir die Leistungsfähigkeit von DJL mit einem MME anhand eines SKLearn-Beispielmodells. Wir führen einen Trainingsjob mit diesem Modell durch und erstellen dann 1,000 Kopien dieses Modellartefakts zur Unterstützung unseres MME. Anschließend zeigen wir, wie DJL dynamisch skaliert werden kann, um alle Arten von Verkehrsmustern zu bewältigen, die Ihr MME möglicherweise empfängt. Dies kann eine gleichmäßige Verteilung des Datenverkehrs auf alle Modelle oder sogar einige wenige beliebte Modelle umfassen, die den Großteil des Datenverkehrs erhalten. Den gesamten Code finden Sie im Folgenden GitHub Repo.
Voraussetzungen:
Für dieses Beispiel verwenden wir eine SageMaker-Notebook-Instanz mit einem conda_python3-Kernel und einer ml.c5.xlarge-Instanz. Um die Auslastungstests durchzuführen, können Sie eine verwenden Amazon Elastic Compute-Cloud (Amazon EC2)-Instanz oder eine größere SageMaker-Notebook-Instanz. In diesem Beispiel skalieren wir auf über tausend Transaktionen pro Sekunde (TPS). Daher empfehlen wir den Test auf einer schwereren EC2-Instanz wie ml.c5.18xlarge, damit Sie mehr Rechenleistung zur Verfügung haben.
Erstellen Sie ein Modellartefakt
Zuerst müssen wir unser Modellartefakt und die Daten erstellen, die wir in diesem Beispiel verwenden. Für diesen Fall generieren wir einige künstliche Daten mit NumPy und trainieren mithilfe eines linearen SKLearn-Regressionsmodells mit dem folgenden Codeausschnitt:
Nachdem Sie den vorherigen Code ausgeführt haben, sollten Sie eine haben model.joblib Datei, die in Ihrer lokalen Umgebung erstellt wurde.
Rufen Sie das DJL-Docker-Image ab
Das Docker-Image djl-inference:0.23.0-cpu-full-v1.0 ist unser DJL-Serving-Container, der in diesem Beispiel verwendet wird. Sie können die folgende URL je nach Region anpassen:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
Optional können Sie dieses Image auch als Basis-Image verwenden und es erweitern, um darauf Ihr eigenes Docker-Image zu erstellen Amazon Elastic Container-Registrierung (Amazon ECR) mit allen anderen Abhängigkeiten, die Sie benötigen.
Erstellen Sie die Modelldatei
Zuerst erstellen wir eine Datei namens serving.properties. Dadurch wird DJLServing angewiesen, die Python-Engine zu verwenden. Wir definieren auch die max_idle_time eines Arbeiters 600 Sekunden betragen. Dadurch wird sichergestellt, dass es länger dauert, die Anzahl der Mitarbeiter pro Modell zu reduzieren. Wir passen uns nicht an minWorkers und maxWorkers die wir definieren können, und wir lassen DJL dynamisch die Anzahl der benötigten Worker berechnen, abhängig vom Datenverkehr, den jedes Modell empfängt. Die „serving.properties“ werden wie folgt angezeigt. Die vollständige Liste der Konfigurationsoptionen finden Sie unter Motorkonfiguration.
Als Nächstes erstellen wir unsere Datei model.py, die die Modelllade- und Inferenzlogik definiert. Bei MMEs ist jede model.py-Datei spezifisch für ein Modell. Modelle werden in ihren eigenen Pfaden unter dem Modellspeicher gespeichert (normalerweise). /opt/ml/model/). Beim Laden von Modellen werden diese unter dem Modellspeicherpfad in ihrem eigenen Verzeichnis geladen. Das vollständige model.py-Beispiel in dieser Demo finden Sie im GitHub Repo.
Wir schaffen eine model.tar.gz Datei, die unser Modell enthält (model.joblib), model.py und serving.properties:
Zu Demonstrationszwecken fertigen wir davon 1,000 Exemplare an model.tar.gz Datei, um die große Anzahl der zu hostenden Modelle darzustellen. In der Produktion müssen Sie eine erstellen model.tar.gz Datei für jedes Ihrer Modelle.
Zuletzt laden wir diese Modelle auf Amazon S3 hoch.
Erstellen Sie ein SageMaker-Modell
Wir erstellen jetzt eine SageMaker-Modell. Wir verwenden das zuvor definierte ECR-Bild und das Modellartefakt aus dem vorherigen Schritt, um das SageMaker-Modell zu erstellen. Im Modell-Setup konfigurieren wir den Modus als MultiModel. Dies teilt DJLServing mit, dass wir eine MME erstellen.
Erstellen Sie einen SageMaker-Endpunkt
In dieser Demo verwenden wir 20 ml.c5d.18xlarge-Instanzen, um auf einen TPS im Tausenderbereich zu skalieren. Stellen Sie sicher, dass Sie bei Bedarf eine Limiterhöhung für Ihren Instance-Typ erhalten, um die angestrebte TPS zu erreichen.
Lastprüfung
Zum Zeitpunkt des Verfassens dieses Artikels das hauseigene Lasttest-Tool von SageMaker Amazon SageMaker Inference Recommender unterstützt Tests für MMEs nicht nativ. Daher verwenden wir das Open-Source-Tool Python Heuschrecke. Locust ist einfach einzurichten und kann Metriken wie TPS und End-to-End-Latenz verfolgen. Ausführliche Informationen zur Einrichtung mit SageMaker finden Sie unter Best Practices für Lasttests von Amazon SageMaker-Echtzeit-Inferenzendpunkten.
In diesem Anwendungsfall haben wir drei verschiedene Verkehrsmuster, die wir mit MMEs simulieren möchten, also haben wir die folgenden drei Python-Skripte, die sich an jedem Muster ausrichten. Unser Ziel hier ist es zu beweisen, dass wir unabhängig von unserem Verkehrsmuster das gleiche TPS-Ziel erreichen und angemessen skalieren können.
Wir können in unserem Locust-Skript eine Gewichtung angeben, um den Datenverkehr verschiedenen Teilen unserer Modelle zuzuweisen. Mit unserem Single-Hot-Modell implementieren wir beispielsweise zwei Methoden wie folgt:
Anschließend können wir jeder Methode eine bestimmte Gewichtung zuweisen, d. h., eine bestimmte Methode erhält einen bestimmten Prozentsatz des Datenverkehrs:
Für 20 ml.c5d.18xlarge-Instanzen sehen wir die folgenden Aufrufmetriken Amazon CloudWatch Konsole. Diese Werte bleiben über alle drei Verkehrsmuster hinweg ziemlich konsistent. Um die CloudWatch-Metriken für SageMaker-Echtzeitinferenz und MMEs besser zu verstehen, lesen Sie SageMaker-Endpunkt-Aufrufmetriken.
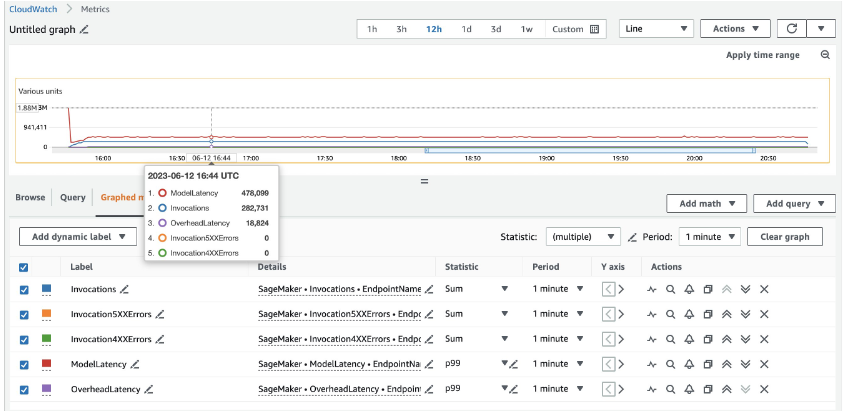
Die restlichen Locust-Skripte finden Sie im Verzeichnis „locust-utils“. im GitHub-Repository.
Zusammenfassung
In diesem Beitrag haben wir besprochen, wie ein MME die jedem Modell zugewiesene Rechenleistung basierend auf dem Verkehrsmuster des Modells dynamisch anpassen kann. Diese neu eingeführte Funktion ist in allen AWS-Regionen verfügbar, in denen SageMaker verfügbar ist. Beachten Sie, dass zum Zeitpunkt der Ankündigung nur CPU-Instanzen unterstützt werden. Weitere Informationen finden Sie unter Unterstützte Algorithmen, Frameworks und Instanzen.
Über die Autoren
 Widder Vegiraju ist ML-Architekt im SageMaker-Serviceteam. Er konzentriert sich darauf, Kunden bei der Erstellung und Optimierung ihrer KI/ML-Lösungen auf Amazon SageMaker zu unterstützen. In seiner Freizeit liebt er es zu reisen und zu schreiben.
Widder Vegiraju ist ML-Architekt im SageMaker-Serviceteam. Er konzentriert sich darauf, Kunden bei der Erstellung und Optimierung ihrer KI/ML-Lösungen auf Amazon SageMaker zu unterstützen. In seiner Freizeit liebt er es zu reisen und zu schreiben.
 Qingwei Li ist Spezialist für maschinelles Lernen bei Amazon Web Services. Er erhielt seinen Ph.D. in Operations Research, nachdem er das Konto seines Beraters für Forschungsstipendien aufgelöst und den versprochenen Nobelpreis nicht geliefert hatte. Derzeit hilft er Kunden in der Finanzdienstleistungs- und Versicherungsbranche beim Aufbau von Lösungen für maschinelles Lernen auf AWS. In seiner Freizeit liest und unterrichtet er gerne.
Qingwei Li ist Spezialist für maschinelles Lernen bei Amazon Web Services. Er erhielt seinen Ph.D. in Operations Research, nachdem er das Konto seines Beraters für Forschungsstipendien aufgelöst und den versprochenen Nobelpreis nicht geliefert hatte. Derzeit hilft er Kunden in der Finanzdienstleistungs- und Versicherungsbranche beim Aufbau von Lösungen für maschinelles Lernen auf AWS. In seiner Freizeit liest und unterrichtet er gerne.
 James Wu ist Senior AI/ML Specialist Solution Architect bei AWS. Unterstützung von Kunden bei der Entwicklung und Erstellung von KI/ML-Lösungen. Die Arbeit von James deckt ein breites Spektrum von ML-Anwendungsfällen ab, wobei sein Hauptinteresse auf Computer Vision, Deep Learning und der Skalierung von ML im gesamten Unternehmen liegt. Bevor er zu AWS kam, war James über 10 Jahre lang Architekt, Entwickler und Technologieführer, davon 6 Jahre im Ingenieurwesen und 4 Jahre in der Marketing- und Werbebranche.
James Wu ist Senior AI/ML Specialist Solution Architect bei AWS. Unterstützung von Kunden bei der Entwicklung und Erstellung von KI/ML-Lösungen. Die Arbeit von James deckt ein breites Spektrum von ML-Anwendungsfällen ab, wobei sein Hauptinteresse auf Computer Vision, Deep Learning und der Skalierung von ML im gesamten Unternehmen liegt. Bevor er zu AWS kam, war James über 10 Jahre lang Architekt, Entwickler und Technologieführer, davon 6 Jahre im Ingenieurwesen und 4 Jahre in der Marketing- und Werbebranche.
 Saurabh Trikande ist Senior Product Manager für Amazon SageMaker Inference. Er arbeitet leidenschaftlich gerne mit Kunden zusammen und ist motiviert von dem Ziel, maschinelles Lernen zu demokratisieren. Er konzentriert sich auf die Kernherausforderungen im Zusammenhang mit der Bereitstellung komplexer ML-Anwendungen, mandantenfähigen ML-Modellen, Kostenoptimierungen und der leichteren Bereitstellung von Deep-Learning-Modellen. In seiner Freizeit wandert Saurabh gerne, lernt etwas über innovative Technologien, folgt TechCrunch und verbringt Zeit mit seiner Familie.
Saurabh Trikande ist Senior Product Manager für Amazon SageMaker Inference. Er arbeitet leidenschaftlich gerne mit Kunden zusammen und ist motiviert von dem Ziel, maschinelles Lernen zu demokratisieren. Er konzentriert sich auf die Kernherausforderungen im Zusammenhang mit der Bereitstellung komplexer ML-Anwendungen, mandantenfähigen ML-Modellen, Kostenoptimierungen und der leichteren Bereitstellung von Deep-Learning-Modellen. In seiner Freizeit wandert Saurabh gerne, lernt etwas über innovative Technologien, folgt TechCrunch und verbringt Zeit mit seiner Familie.
 Xu Deng ist Software Engineer Manager im SageMaker-Team. Er konzentriert sich darauf, Kunden beim Aufbau und der Optimierung ihrer KI/ML-Inferenzerfahrung auf Amazon SageMaker zu unterstützen. In seiner Freizeit liebt er Reisen und Snowboarden.
Xu Deng ist Software Engineer Manager im SageMaker-Team. Er konzentriert sich darauf, Kunden beim Aufbau und der Optimierung ihrer KI/ML-Inferenzerfahrung auf Amazon SageMaker zu unterstützen. In seiner Freizeit liebt er Reisen und Snowboarden.
 Siddharth Venkatesan ist Software Engineer bei AWS Deep Learning. Derzeit konzentriert er sich auf die Entwicklung von Lösungen für die Inferenz großer Modelle. Vor AWS arbeitete er in der Amazon Grocery-Organisation am Aufbau neuer Zahlungsfunktionen für Kunden auf der ganzen Welt. Außerhalb der Arbeit fährt er gerne Ski, ist in der Natur und schaut sich Sport an.
Siddharth Venkatesan ist Software Engineer bei AWS Deep Learning. Derzeit konzentriert er sich auf die Entwicklung von Lösungen für die Inferenz großer Modelle. Vor AWS arbeitete er in der Amazon Grocery-Organisation am Aufbau neuer Zahlungsfunktionen für Kunden auf der ganzen Welt. Außerhalb der Arbeit fährt er gerne Ski, ist in der Natur und schaut sich Sport an.
 Rohith Nalamaddi ist Softwareentwicklungsingenieur bei AWS. Er arbeitet an der Optimierung von Deep-Learning-Workloads auf GPUs, dem Aufbau von leistungsstarken ML-Inferenz- und Bereitstellungslösungen. Zuvor arbeitete er am Aufbau von Microservices auf Basis von AWS für Amazon F3 Business. Außerhalb der Arbeit spielt und schaut er gerne Sport.
Rohith Nalamaddi ist Softwareentwicklungsingenieur bei AWS. Er arbeitet an der Optimierung von Deep-Learning-Workloads auf GPUs, dem Aufbau von leistungsstarken ML-Inferenz- und Bereitstellungslösungen. Zuvor arbeitete er am Aufbau von Microservices auf Basis von AWS für Amazon F3 Business. Außerhalb der Arbeit spielt und schaut er gerne Sport.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

