Dieser Beitrag wurde gemeinsam mit Jayadeep Pabbisetty, Sr. Specialist Data Engineering bei Merck, und Prabakaran Mathaiyan, Sr. ML Engineer bei Tiger Analytics, verfasst.
Der große Lebenszyklus der Modellentwicklung für maschinelles Lernen (ML) erfordert einen skalierbaren Modellfreigabeprozess, der dem der Softwareentwicklung ähnelt. Modellentwickler arbeiten bei der Entwicklung von ML-Modellen häufig zusammen und benötigen eine robuste MLOps-Plattform zum Arbeiten. Eine skalierbare MLOps-Plattform muss einen Prozess zur Abwicklung des Workflows der Registrierung, Genehmigung und Beförderung von ML-Modellen auf die nächste Umgebungsebene (Entwicklung, Test) umfassen , UAT oder Produktion).
Ein Modellentwickler beginnt normalerweise mit der Arbeit in einer individuellen ML-Entwicklungsumgebung Amazon Sage Maker. Wenn ein Modell trainiert und einsatzbereit ist, muss es nach der Registrierung im genehmigt werden Amazon SageMaker-Modellregistrierung. In diesem Beitrag diskutieren wir, wie das AWS AI/ML-Team mit dem Merck Human Health IT MLOps-Team zusammengearbeitet hat, um eine Lösung zu entwickeln, die einen automatisierten Workflow für die Genehmigung und Förderung von ML-Modellen mit menschlichem Eingriff in der Mitte nutzt.
Lösungsübersicht
Dieser Beitrag konzentriert sich auf eine Workflow-Lösung, die der ML-Modellentwicklungslebenszyklus zwischen der Trainingspipeline und der Inferenzpipeline verwenden kann. Die Lösung bietet einen skalierbaren Workflow für MLOps zur Unterstützung des ML-Modellgenehmigungs- und -förderungsprozesses durch menschliches Eingreifen. Ein von einem Datenwissenschaftler registriertes ML-Modell muss von einem Genehmiger überprüft und genehmigt werden, bevor es für eine Inferenzpipeline und in der nächsten Umgebungsebene (Test, UAT oder Produktion) verwendet wird. Die Lösung verwendet AWS Lambda, Amazon API-Gateway, Amazon EventBridgeund SageMaker zur Automatisierung des Arbeitsablaufs mit menschlichem Genehmigungseingriff in der Mitte. Das folgende Architekturdiagramm zeigt das Gesamtsystemdesign, die verwendeten AWS-Services und den Workflow für die Genehmigung und Förderung von ML-Modellen mit menschlichem Eingreifen von der Entwicklung bis zur Produktion.
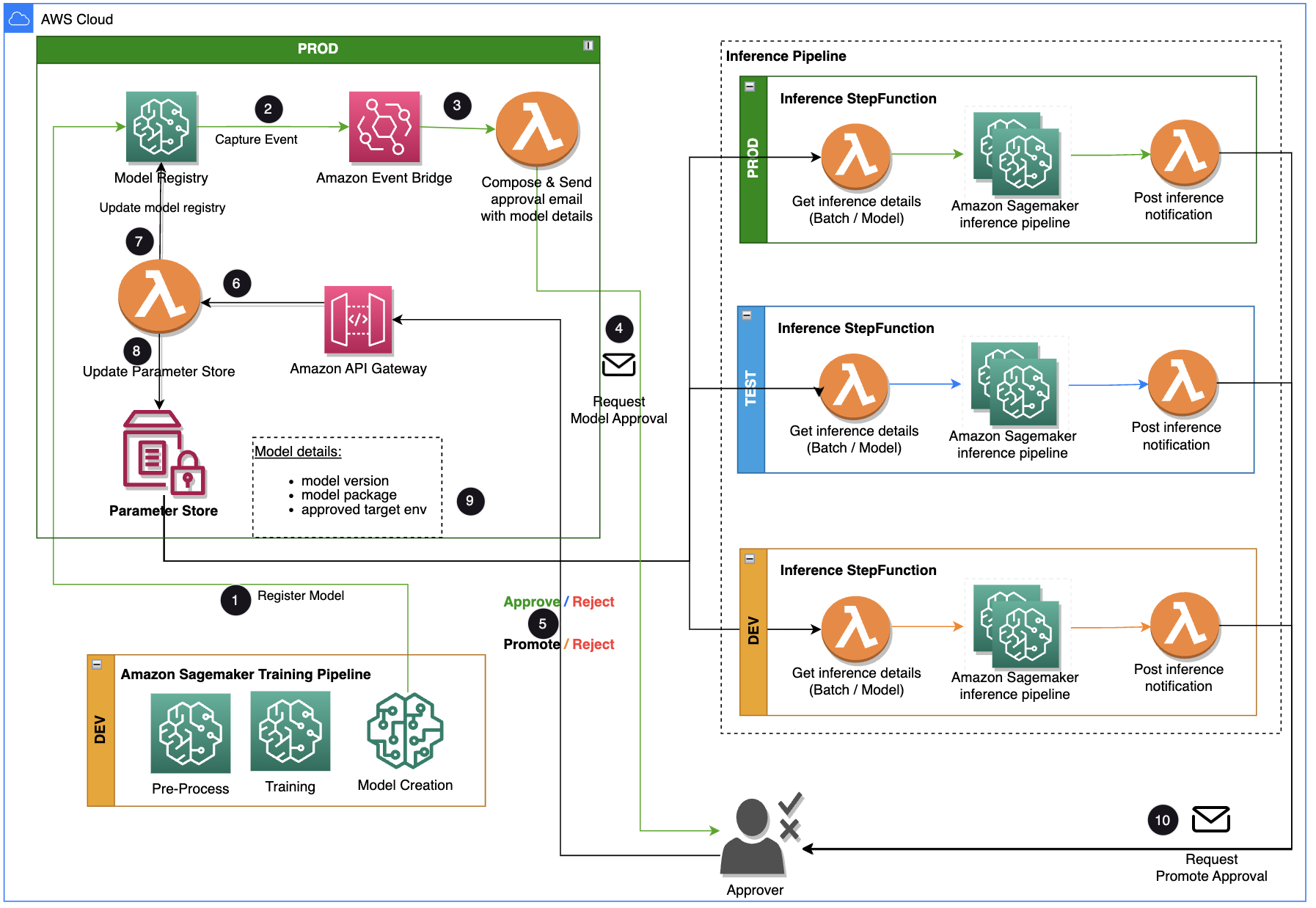
Der Workflow umfasst die folgenden Schritte:
- Die Trainingspipeline entwickelt und registriert ein Modell in der SageMaker-Modellregistrierung. Zu diesem Zeitpunkt ist der Modellstatus
PendingManualApproval. - EventBridge überwacht Statusänderungsereignisse, um anhand einfacher Regeln automatisch Maßnahmen zu ergreifen.
- Die EventBridge-Modellregistrierungsereignisregel ruft eine Lambda-Funktion auf, die eine E-Mail mit einem Link zum Genehmigen oder Ablehnen des registrierten Modells erstellt.
- Der Genehmiger erhält eine E-Mail mit dem Link zum Überprüfen und Genehmigen oder Ablehnen des Modells.
- Der Genehmiger genehmigt das Modell, indem er dem Link in der E-Mail zu einem API Gateway-Endpunkt folgt.
- API Gateway ruft eine Lambda-Funktion auf, um Modellaktualisierungen zu initiieren.
- Die Modellregistrierung wird für den Modellstatus aktualisiert (
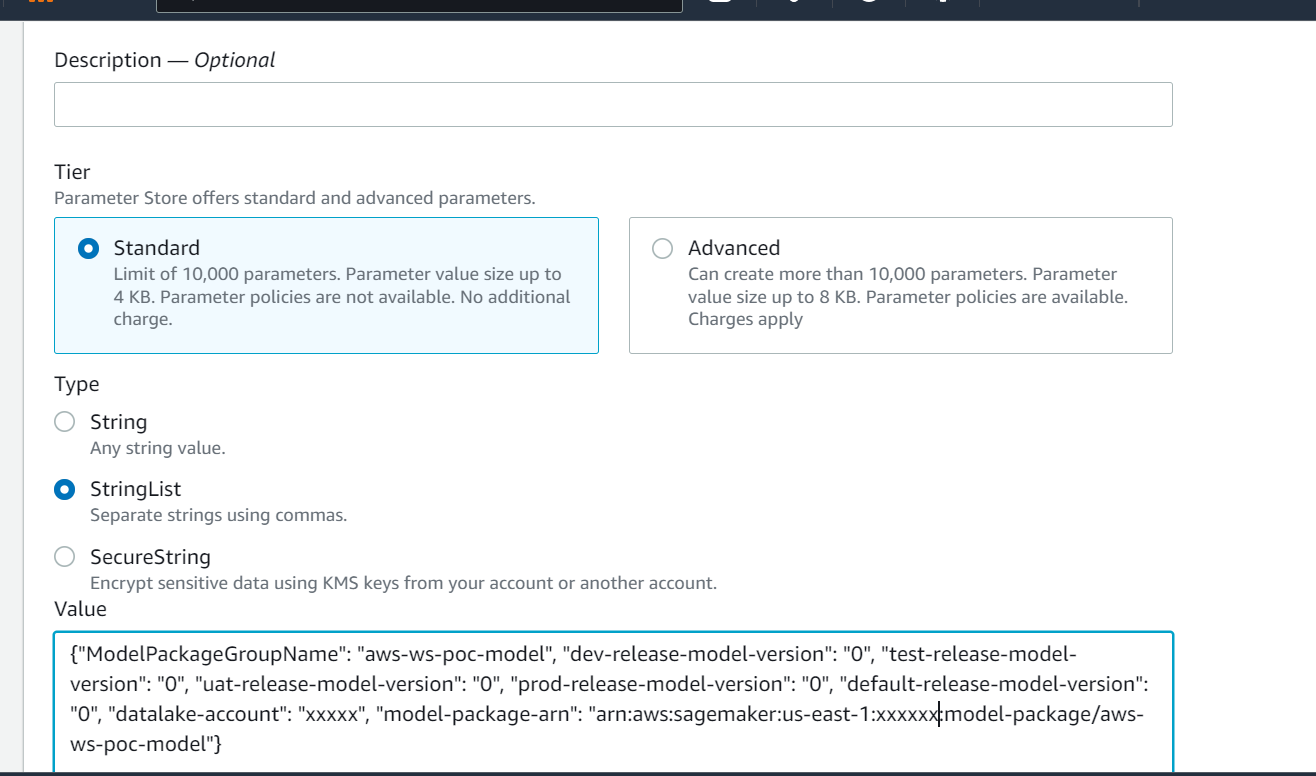
Approvedfür die Entwicklungsumgebung, aberPendingManualApprovalfür Test, UAT und Produktion). - Die Modelldetails werden in gespeichert AWS-Parameterspeicher, eine Fähigkeit von AWS-Systemmanager, einschließlich der Modellversion, der genehmigten Zielumgebung und des Modellpakets.
- Die Inferenzpipeline ruft das für die Zielumgebung genehmigte Modell aus dem Parameter Store ab.
- Die Post-Inference-Benachrichtigungs-Lambda-Funktion sammelt Batch-Inferenzmetriken und sendet eine E-Mail an den Genehmiger, um das Modell in die nächste Umgebung hochzustufen.
Voraussetzungen:
Der Arbeitsablauf in diesem Beitrag setzt voraus, dass die Umgebung für die Trainingspipeline zusammen mit anderen Ressourcen in SageMaker eingerichtet wird. Die Eingabe in die Trainingspipeline ist der Feature-Datensatz. Die Details zur Funktionsgenerierung sind in diesem Beitrag nicht enthalten, er konzentriert sich jedoch auf die Registrierung, Genehmigung und Förderung von ML-Modellen nach deren Schulung. Das Modell ist im Modellregister registriert und unterliegt einem Überwachungsrahmen in Amazon SageMaker-Modellmonitor um etwaige Abweichungen zu erkennen und im Falle einer Modellabweichung mit dem erneuten Training fortzufahren.
Workflow-Details
Der Genehmigungsworkflow beginnt mit einem Modell, das aus einer Trainingspipeline entwickelt wurde. Wenn Datenwissenschaftler ein Modell entwickeln, registrieren sie es im SageMaker Model Registry mit dem Modellstatus PendingManualApproval. EventBridge überwacht SageMaker auf das Modellregistrierungsereignis und löst eine Ereignisregel aus, die eine Lambda-Funktion aufruft. Die Lambda-Funktion erstellt dynamisch eine E-Mail zur Genehmigung des Modells mit einem Link zu einem API-Gateway-Endpunkt zu einer anderen Lambda-Funktion. Wenn der Genehmiger dem Link folgt, um das Modell zu genehmigen, leitet API Gateway die Genehmigungsaktion an die Lambda-Funktion weiter, die die SageMaker-Modellregistrierung und die Modellattribute im Parameter Store aktualisiert. Der Genehmiger muss authentifiziert und Teil der von Active Directory verwalteten Genehmigergruppe sein. Die Erstgenehmigung kennzeichnet das Modell als Approved für Entwickler aber PendingManualApproval für Test, UAT und Produktion. Zu den im Parameter Store gespeicherten Modellattributen gehören die Modellversion, das Modellpaket und die genehmigte Zielumgebung.
Wenn eine Inferenzpipeline ein Modell abrufen muss, überprüft sie den Parameterspeicher auf die neueste für die Zielumgebung genehmigte Modellversion und ruft die Inferenzdetails ab. Wenn die Inferenzpipeline abgeschlossen ist, wird eine Post-Inferenz-Benachrichtigungs-E-Mail an einen Stakeholder gesendet, in der er um eine Genehmigung zum Heraufstufen des Modells auf die nächste Umgebungsebene bittet. Die E-Mail enthält Details zum Modell und zu den Metriken sowie einen Genehmigungslink zu einem API-Gateway-Endpunkt für eine Lambda-Funktion, die die Modellattribute aktualisiert.
Im Folgenden finden Sie die Abfolge von Ereignissen und Implementierungsschritten für den ML-Modellgenehmigungs-/-förderungsworkflow von der Modellerstellung bis zur Produktion. Das Modell wird von der Entwicklung in Test-, UAT- und Produktionsumgebungen gefördert, wobei in jedem Schritt eine ausdrückliche menschliche Genehmigung erfolgt.
Wir beginnen mit der Trainingspipeline, die für die Modellentwicklung bereit ist. Die Modellversion beginnt in der SageMaker-Modellregistrierung mit 0.
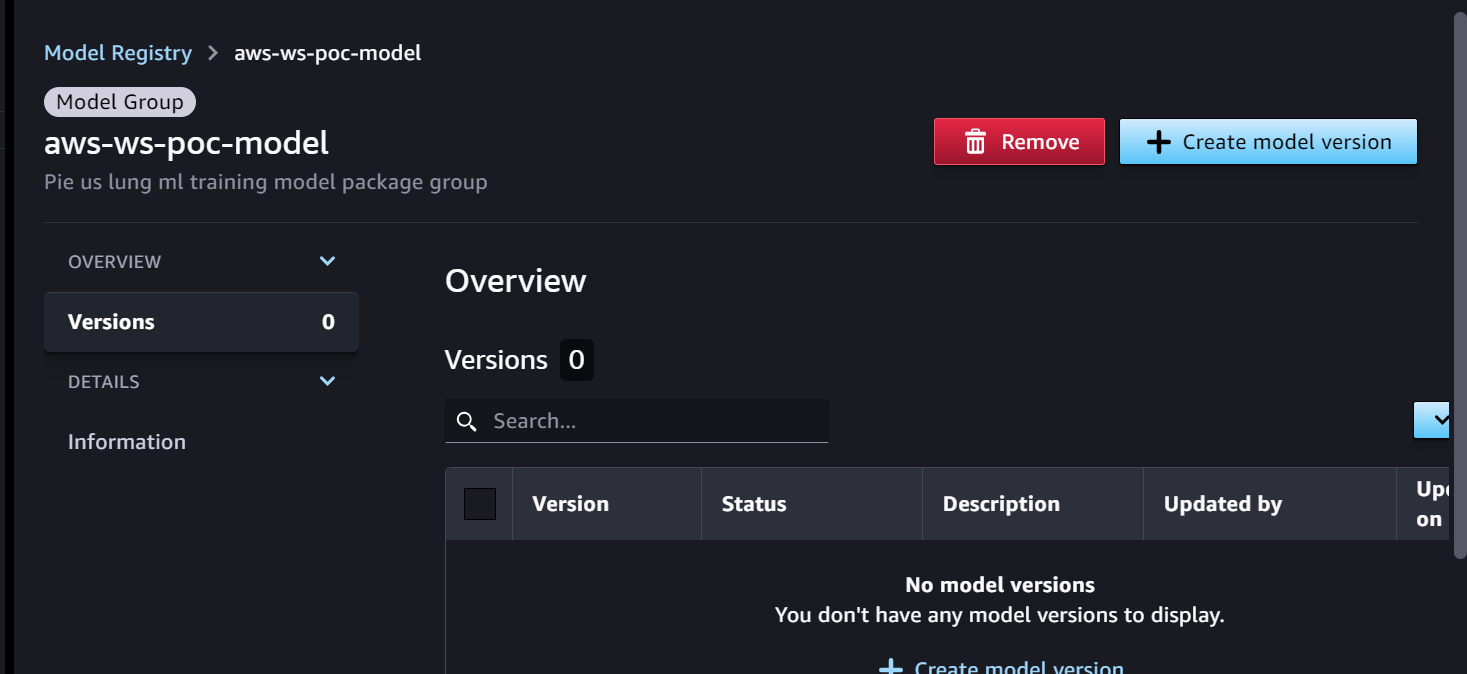
- Die SageMaker-Schulungspipeline entwickelt und registriert ein Modell in der SageMaker-Modellregistrierung. Modellversion 1 ist registriert und beginnt mit Ausstehende manuelle Genehmigung Status.
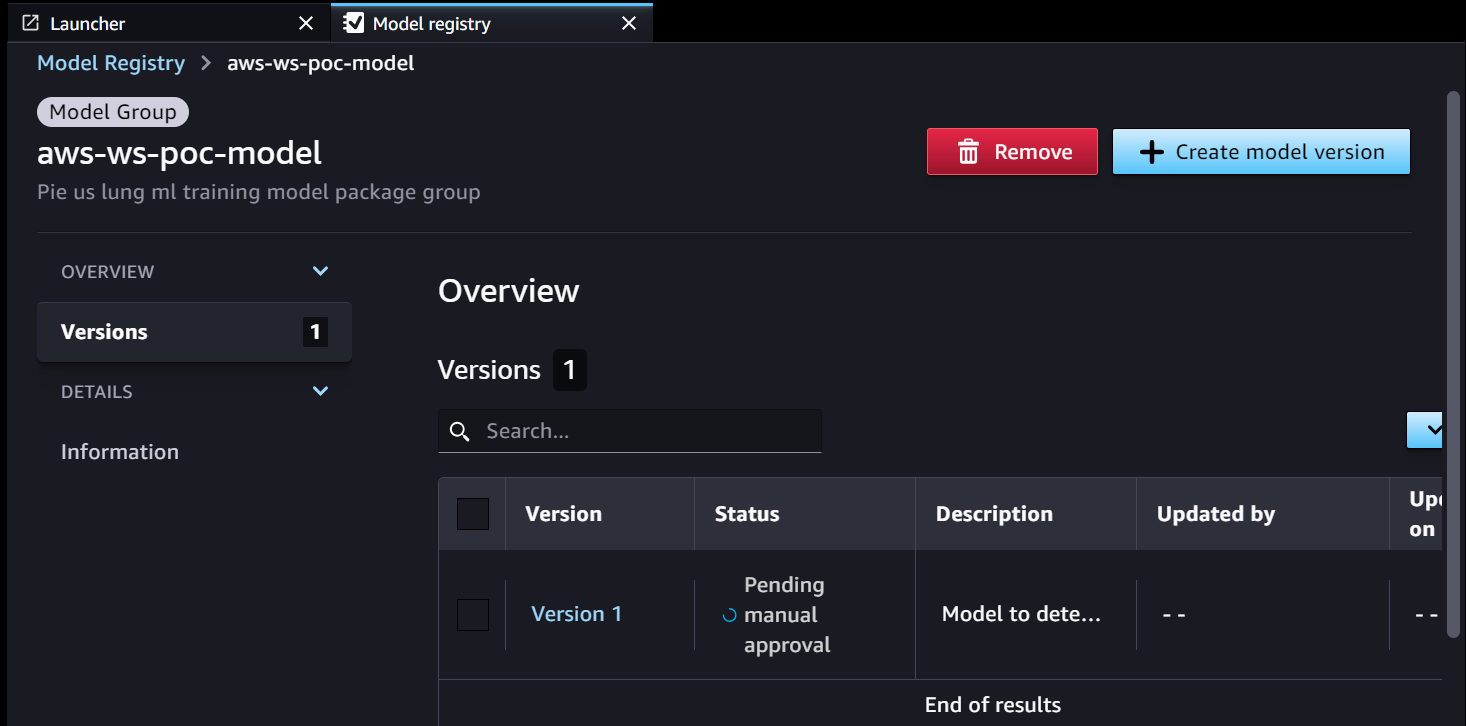 Die Model Registry-Metadaten verfügen über vier benutzerdefinierte Felder für die Umgebungen:
Die Model Registry-Metadaten verfügen über vier benutzerdefinierte Felder für die Umgebungen: dev, test, uatundprod.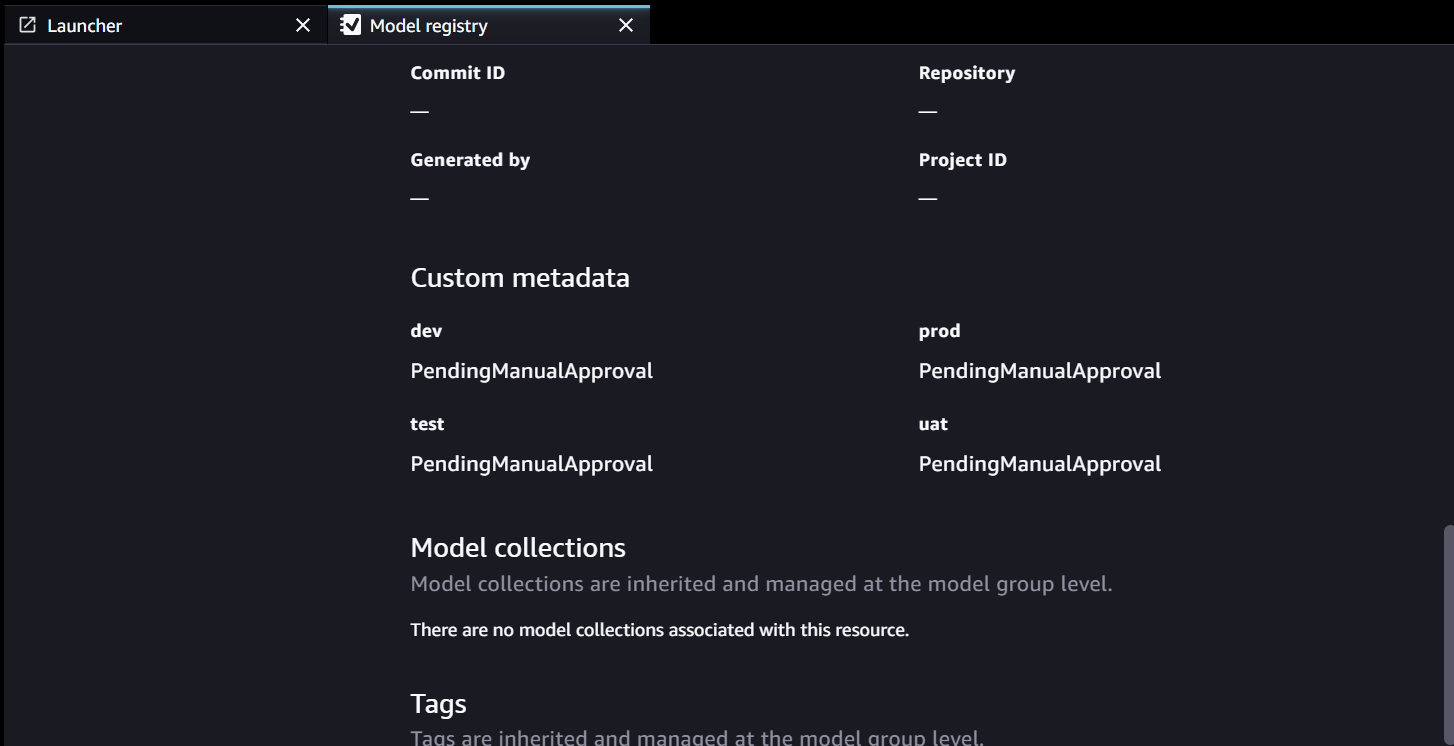
- EventBridge überwacht die SageMaker Model Registry auf Statusänderungen, um anhand einfacher Regeln automatisch Maßnahmen zu ergreifen.
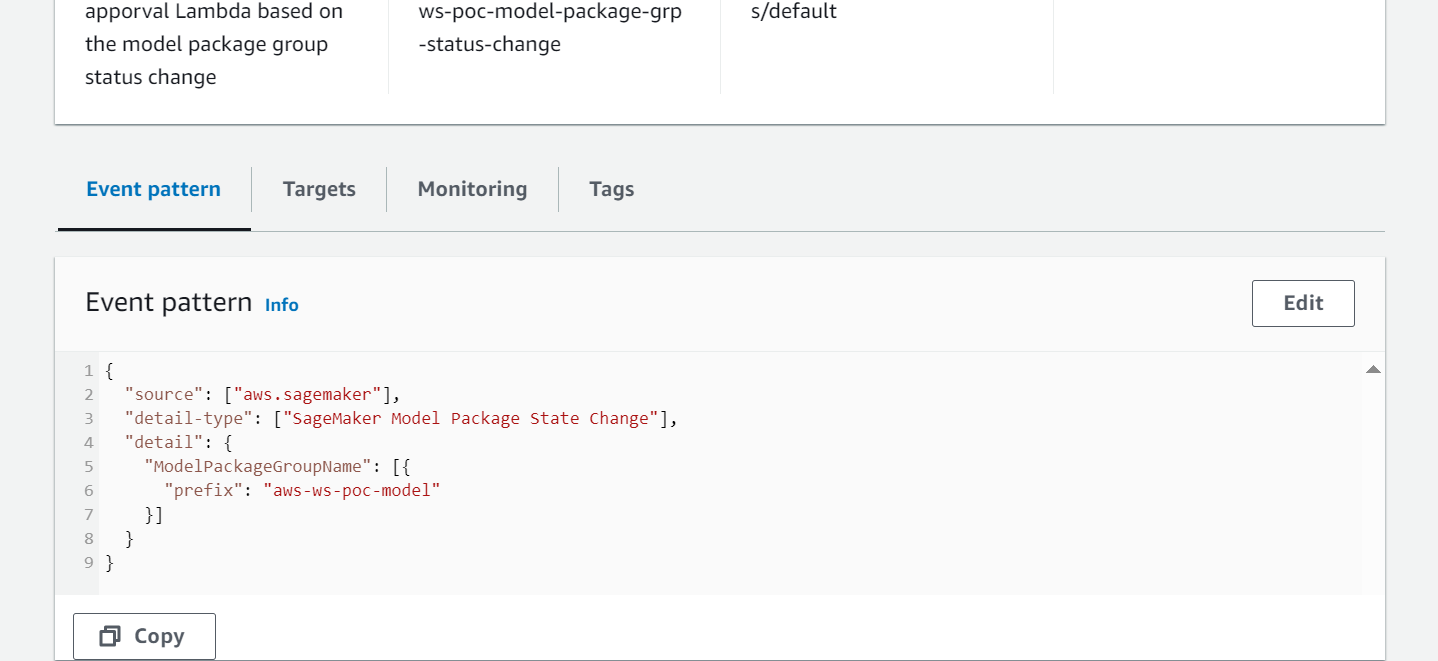
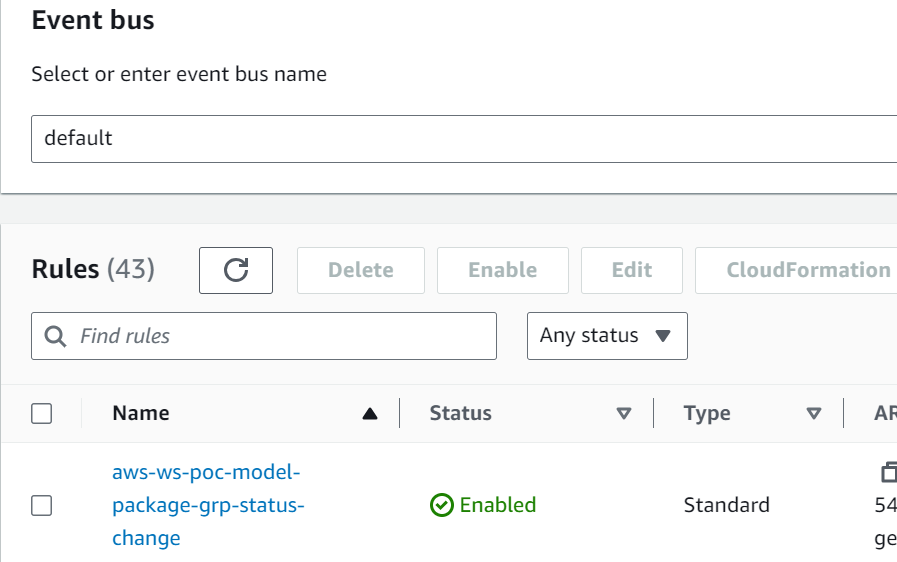
- Die Modellregistrierungsereignisregel ruft eine Lambda-Funktion auf, die eine E-Mail mit dem Link zum Genehmigen oder Ablehnen des registrierten Modells erstellt.
- Der Genehmiger erhält eine E-Mail mit dem Link zum Überprüfen und Genehmigen (oder Ablehnen) des Modells.

- Der Genehmiger genehmigt das Modell, indem er dem Link zum API Gateway-Endpunkt in der E-Mail folgt.
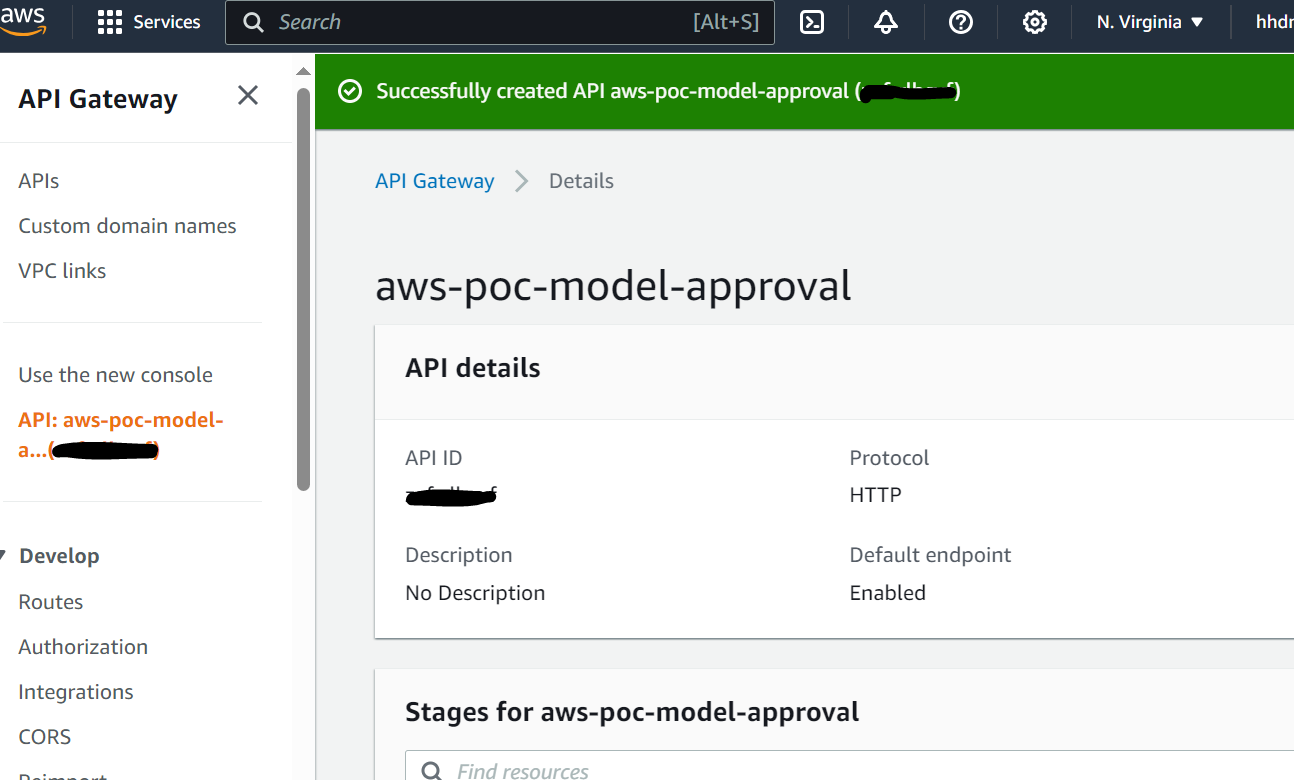
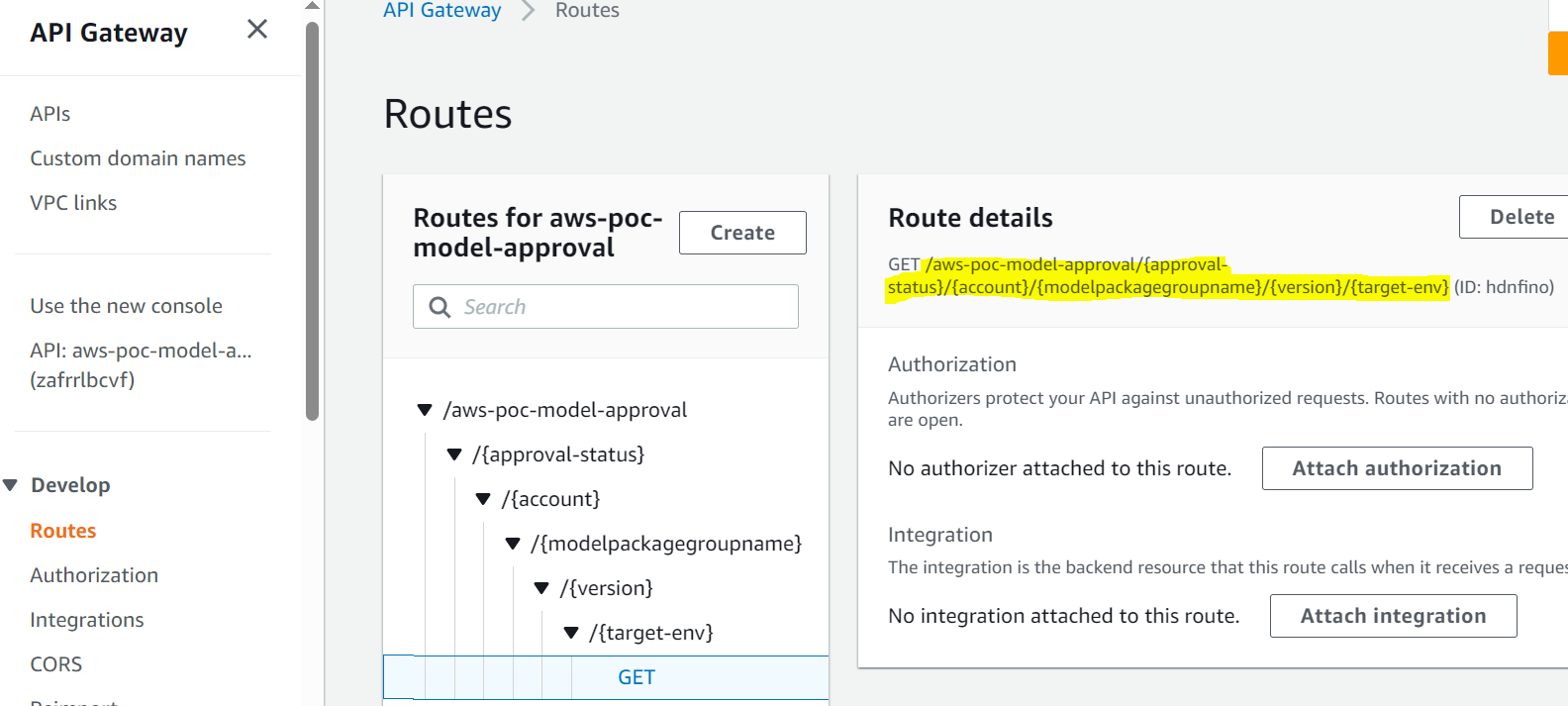
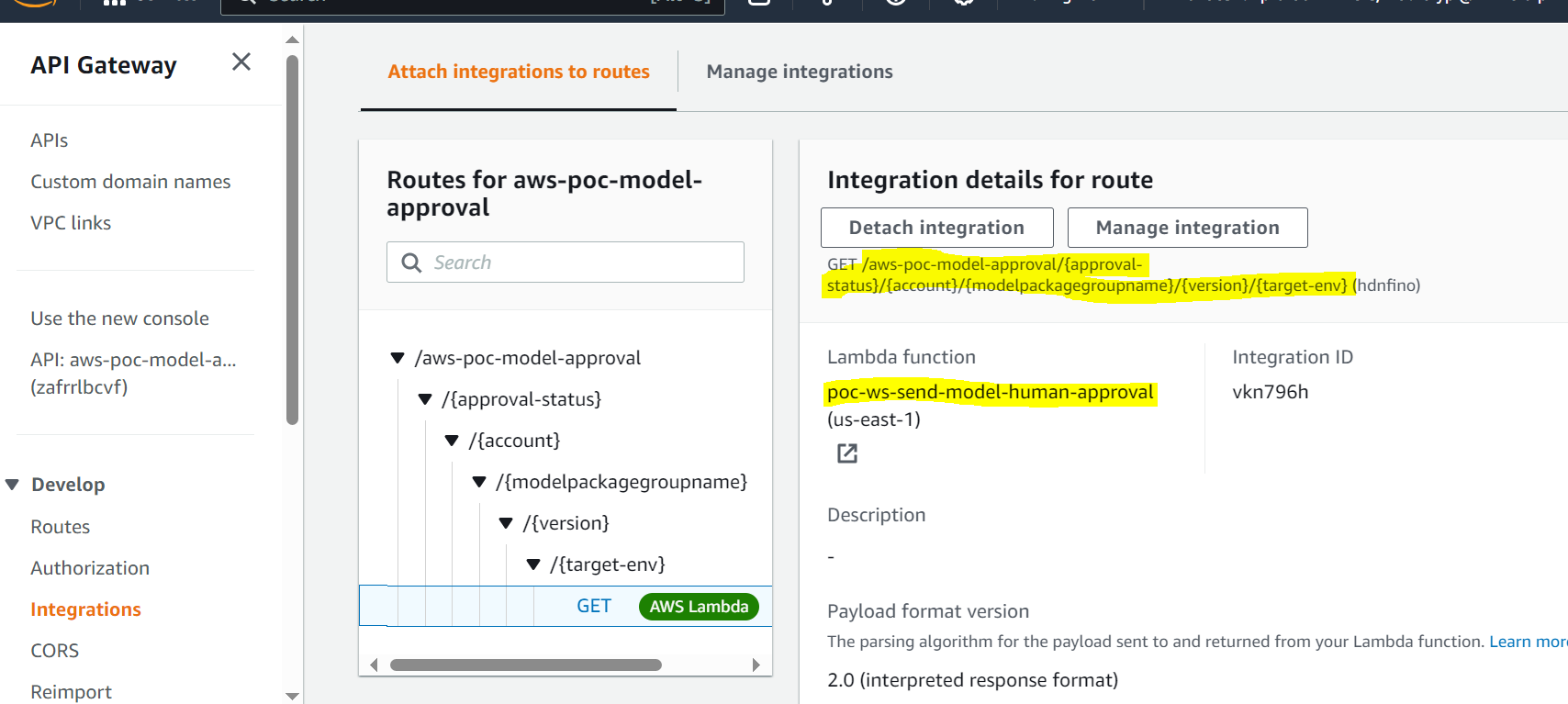
- API Gateway ruft die Lambda-Funktion auf, um Modellaktualisierungen zu initiieren.
- Die SageMaker-Modellregistrierung wird mit dem Modellstatus aktualisiert.

- Die Modelldetailinformationen werden im Parameter Store gespeichert, einschließlich der Modellversion, der genehmigten Zielumgebung und des Modellpakets.
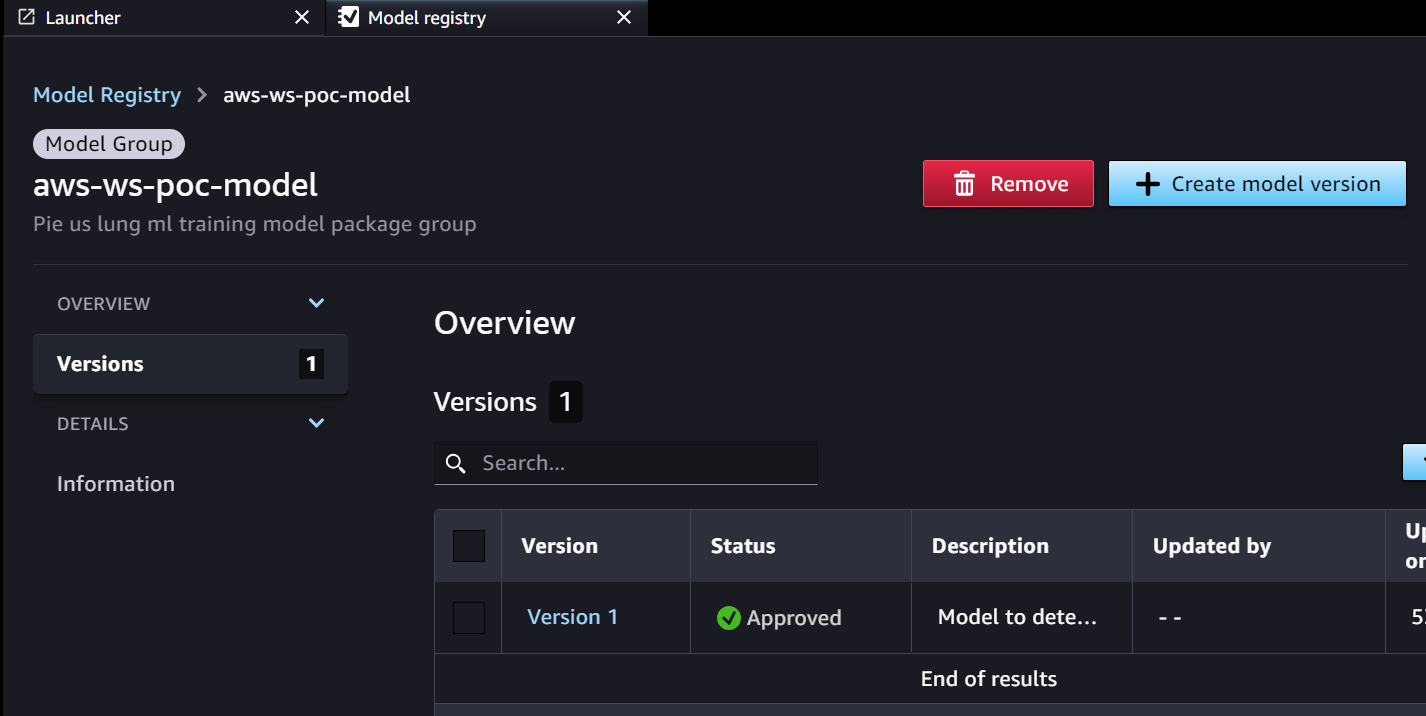

- Die Inferenzpipeline ruft das für die Zielumgebung genehmigte Modell aus dem Parameter Store ab.
- Die Post-Inference-Benachrichtigungs-Lambda-Funktion sammelt Batch-Inferenzmetriken und sendet eine E-Mail an den Genehmiger, um das Modell in die nächste Umgebung hochzustufen.
- Der Genehmiger genehmigt die Modellheraufstufung auf die nächste Ebene, indem er dem Link zum API-Gateway-Endpunkt folgt, der die Lambda-Funktion auslöst, um die SageMaker-Modellregistrierung und den Parameterspeicher zu aktualisieren.
Der vollständige Verlauf der Modellversionierung und -genehmigung wird zur Überprüfung im Parameter Store gespeichert.

Zusammenfassung
Der lange Lebenszyklus der ML-Modellentwicklung erfordert einen skalierbaren ML-Modellgenehmigungsprozess. In diesem Beitrag haben wir eine Implementierung eines ML-Modellregistrierungs-, Genehmigungs- und Promotion-Workflows mit menschlichem Eingreifen unter Verwendung von SageMaker Model Registry, EventBridge, API Gateway und Lambda vorgestellt. Wenn Sie einen skalierbaren ML-Modellentwicklungsprozess für Ihre MLOps-Plattform in Betracht ziehen, können Sie die Schritte in diesem Beitrag befolgen, um einen ähnlichen Workflow zu implementieren.
Über die Autoren
 Tom Kim ist Senior Solution Architect bei AWS, wo er seinen Kunden hilft, ihre Geschäftsziele durch die Entwicklung von Lösungen auf AWS zu erreichen. Er verfügt über umfangreiche Erfahrung in der Architektur und dem Betrieb von Unternehmenssystemen in verschiedenen Branchen – insbesondere im Gesundheitswesen und in den Biowissenschaften. Tom lernt ständig neue Technologien kennen, die zum gewünschten Geschäftsergebnis für Kunden führen – z. KI/ML, GenAI und Datenanalyse. Außerdem reist er gerne an neue Orte und spielt neue Golfplätze, wann immer er Zeit dafür hat.
Tom Kim ist Senior Solution Architect bei AWS, wo er seinen Kunden hilft, ihre Geschäftsziele durch die Entwicklung von Lösungen auf AWS zu erreichen. Er verfügt über umfangreiche Erfahrung in der Architektur und dem Betrieb von Unternehmenssystemen in verschiedenen Branchen – insbesondere im Gesundheitswesen und in den Biowissenschaften. Tom lernt ständig neue Technologien kennen, die zum gewünschten Geschäftsergebnis für Kunden führen – z. KI/ML, GenAI und Datenanalyse. Außerdem reist er gerne an neue Orte und spielt neue Golfplätze, wann immer er Zeit dafür hat.
 Shamika Ariyawansa, der als Senior AI/ML Solutions Architect in der Abteilung Healthcare and Life Sciences bei Amazon Web Services (AWS) tätig ist, ist auf generative KI spezialisiert, mit Schwerpunkt auf Large Language Model (LLM)-Training, Inferenzoptimierungen und MLOps (Machine Learning). Operationen). Er unterstützt Kunden bei der Einbettung fortschrittlicher generativer KI in ihre Projekte und stellt robuste Trainingsprozesse, effiziente Inferenzmechanismen und optimierte MLOps-Praktiken für effektive und skalierbare KI-Lösungen sicher. Über seine beruflichen Verpflichtungen hinaus verfolgt Shamika leidenschaftlich Ski- und Offroad-Abenteuer.
Shamika Ariyawansa, der als Senior AI/ML Solutions Architect in der Abteilung Healthcare and Life Sciences bei Amazon Web Services (AWS) tätig ist, ist auf generative KI spezialisiert, mit Schwerpunkt auf Large Language Model (LLM)-Training, Inferenzoptimierungen und MLOps (Machine Learning). Operationen). Er unterstützt Kunden bei der Einbettung fortschrittlicher generativer KI in ihre Projekte und stellt robuste Trainingsprozesse, effiziente Inferenzmechanismen und optimierte MLOps-Praktiken für effektive und skalierbare KI-Lösungen sicher. Über seine beruflichen Verpflichtungen hinaus verfolgt Shamika leidenschaftlich Ski- und Offroad-Abenteuer.
 Jayadeep Pabbisetty ist Senior ML/Data Engineer bei Merck, wo er ETL- und MLOps-Lösungen entwirft und entwickelt, um Data Science und Analytics für das Unternehmen zu erschließen. Er ist stets begeistert davon, neue Technologien zu erlernen, neue Wege zu erkunden und sich die Fähigkeiten anzueignen, die erforderlich sind, um sich mit der sich ständig verändernden IT-Branche weiterzuentwickeln. In seiner Freizeit geht er seiner Leidenschaft für Sport nach und reist gerne und erkundet neue Orte.
Jayadeep Pabbisetty ist Senior ML/Data Engineer bei Merck, wo er ETL- und MLOps-Lösungen entwirft und entwickelt, um Data Science und Analytics für das Unternehmen zu erschließen. Er ist stets begeistert davon, neue Technologien zu erlernen, neue Wege zu erkunden und sich die Fähigkeiten anzueignen, die erforderlich sind, um sich mit der sich ständig verändernden IT-Branche weiterzuentwickeln. In seiner Freizeit geht er seiner Leidenschaft für Sport nach und reist gerne und erkundet neue Orte.
 Prabakaran Mathaiyan ist Senior Machine Learning Engineer bei Tiger Analytics LLC, wo er seinen Kunden hilft, ihre Geschäftsziele zu erreichen, indem er Lösungen für die Modellbildung, Schulung, Validierung, Überwachung, CICD und Verbesserung von Machine-Learning-Lösungen auf AWS bereitstellt. Prabakaran lernt ständig neue Technologien kennen, die zu den gewünschten Geschäftsergebnissen für Kunden führen – z. KI/ML, GenAI, GPT und LLM. Er spielt auch gerne Cricket, wann immer er Zeit findet.
Prabakaran Mathaiyan ist Senior Machine Learning Engineer bei Tiger Analytics LLC, wo er seinen Kunden hilft, ihre Geschäftsziele zu erreichen, indem er Lösungen für die Modellbildung, Schulung, Validierung, Überwachung, CICD und Verbesserung von Machine-Learning-Lösungen auf AWS bereitstellt. Prabakaran lernt ständig neue Technologien kennen, die zu den gewünschten Geschäftsergebnissen für Kunden führen – z. KI/ML, GenAI, GPT und LLM. Er spielt auch gerne Cricket, wann immer er Zeit findet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-an-amazon-sagemaker-model-registry-approval-and-promotion-workflow-with-human-intervention/

