Dieser Blogbeitrag wurde gemeinsam mit Caroline Chung von Veoneer verfasst.
Veoneer ist ein weltweit tätiges Automobilelektronikunternehmen und ein weltweit führender Anbieter elektronischer Sicherheitssysteme für Kraftfahrzeuge. Sie bieten erstklassige Rückhaltesysteme und haben weltweit über 1 Milliarde elektronische Steuergeräte und Crash-Sensoren an Automobilhersteller geliefert. Das Unternehmen baut weiterhin auf einer 70-jährigen Geschichte der Entwicklung von Fahrzeugsicherheit auf und ist auf modernste Hardware und Systeme spezialisiert, die Verkehrsunfälle verhindern und Unfälle mildern.
Automotive In-Cabin Sensing (ICS) ist ein aufstrebender Bereich, der eine Kombination aus mehreren Arten von Sensoren wie Kameras und Radar sowie auf künstlicher Intelligenz (KI) und maschinellem Lernen (ML) basierenden Algorithmen nutzt, um die Sicherheit zu erhöhen und das Fahrerlebnis zu verbessern. Der Aufbau eines solchen Systems kann eine komplexe Aufgabe sein. Entwickler müssen zu Schulungs- und Testzwecken große Mengen an Bildern manuell mit Anmerkungen versehen. Dies ist sehr zeitaufwändig und ressourcenintensiv. Die Bearbeitungszeit für eine solche Aufgabe beträgt mehrere Wochen. Darüber hinaus müssen sich Unternehmen mit Problemen wie inkonsistenten Etiketten aufgrund menschlicher Fehler auseinandersetzen.
AWS konzentriert sich darauf, Ihnen dabei zu helfen, Ihre Entwicklungsgeschwindigkeit zu erhöhen und Ihre Kosten für den Aufbau solcher Systeme durch fortschrittliche Analysen wie ML zu senken. Unsere Vision ist es, ML für automatisierte Annotationen zu nutzen, um ein erneutes Training von Sicherheitsmodellen zu ermöglichen und konsistente und zuverlässige Leistungsmetriken sicherzustellen. In diesem Beitrag teilen wir mit, wie wir durch die Zusammenarbeit mit der Worldwide Specialist Organization von Amazon und dem Zentrum für generative KI-InnovationWir haben eine aktive Lernpipeline für Bildkopf-Begrenzungsrahmen in der Kabine und die Annotation von Schlüsselpunkten entwickelt. Die Lösung reduziert die Kosten um über 90 %, beschleunigt den Annotationsprozess hinsichtlich der Bearbeitungszeit von Wochen auf Stunden und ermöglicht die Wiederverwendbarkeit für ähnliche ML-Datenkennzeichnungsaufgaben.
Lösungsüberblick
Aktives Lernen ist ein ML-Ansatz, der einen iterativen Prozess der Auswahl und Kommentierung der informativsten Daten zum Trainieren eines Modells umfasst. Bei einem kleinen Satz gekennzeichneter Daten und einem großen Satz unbeschrifteter Daten verbessert aktives Lernen die Modellleistung, reduziert den Kennzeichnungsaufwand und integriert menschliches Fachwissen für belastbare Ergebnisse. In diesem Beitrag erstellen wir eine aktive Lernpipeline für Bildanmerkungen mit AWS-Diensten.
Das folgende Diagramm zeigt den Gesamtrahmen für unsere aktive Lernpipeline. Die Labeling-Pipeline nimmt Bilder von einem auf Amazon Simple Storage-Service (Amazon S3) Bucket und gibt mit der Zusammenarbeit von ML-Modellen und menschlichem Fachwissen kommentierte Bilder aus. Die Trainingspipeline verarbeitet Daten vor und nutzt sie zum Trainieren von ML-Modellen. Das anfängliche Modell wird anhand eines kleinen Satzes manuell gekennzeichneter Daten eingerichtet und trainiert und wird in der Kennzeichnungspipeline verwendet. Die Labeling-Pipeline und die Trainings-Pipeline können schrittweise mit mehr Label-Daten iteriert werden, um die Leistung des Modells zu verbessern.
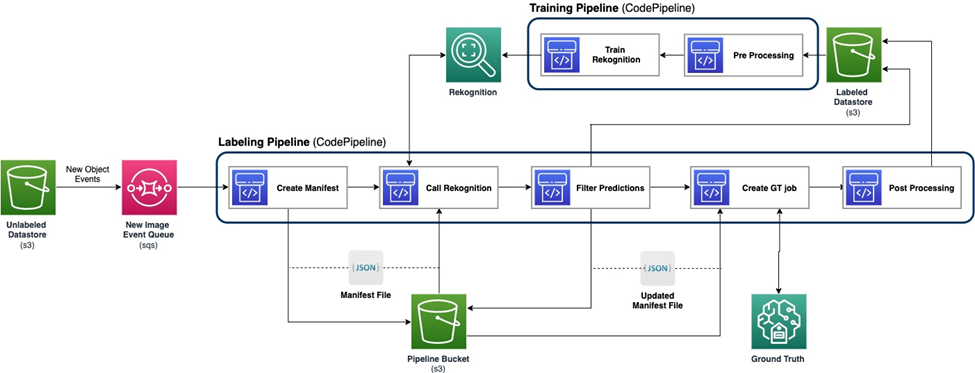
In der Labeling-Pipeline ein Amazon S3-Ereignisbenachrichtigung wird aufgerufen, wenn ein neuer Stapel von Bildern in den Unlabeled Datastore S3-Bucket gelangt, wodurch die Labeling-Pipeline aktiviert wird. Das Modell erzeugt die Inferenzergebnisse für die neuen Bilder. Eine benutzerdefinierte Beurteilungsfunktion wählt Teile der Daten basierend auf dem Inferenzkonfidenzwert oder anderen benutzerdefinierten Funktionen aus. Diese Daten werden zusammen mit ihren Schlussfolgerungsergebnissen an eine menschliche Kennzeichnungsaufgabe weitergegeben Amazon Sagemaker Ground Truth von der Pipeline erstellt. Der menschliche Kennzeichnungsprozess hilft dabei, die Daten mit Anmerkungen zu versehen, und die geänderten Ergebnisse werden mit den verbleibenden automatisch annotierten Daten kombiniert, die später von der Trainingspipeline verwendet werden können.
Die Neuschulung des Modells erfolgt in der Trainingspipeline, wo wir den Datensatz mit den vom Menschen markierten Daten verwenden, um das Modell neu zu trainieren. Es wird eine Manifestdatei erstellt, die beschreibt, wo die Dateien gespeichert sind, und dasselbe anfängliche Modell wird auf die neuen Daten umtrainiert. Nach dem erneuten Training ersetzt das neue Modell das ursprüngliche Modell und die nächste Iteration der aktiven Lernpipeline beginnt.
Modellbereitstellung
Sowohl die Labeling-Pipeline als auch die Trainings-Pipeline werden bereitgestellt AWS CodePipeline. AWS CodeBuild Für die Implementierung werden Instanzen verwendet, die für eine kleine Datenmenge flexibel und schnell sind. Wenn Geschwindigkeit gefragt ist, nutzen wir Amazon Sage Maker Endpunkte basierend auf der GPU-Instanz, um mehr Ressourcen zur Unterstützung und Beschleunigung des Prozesses zuzuweisen.
Die Modell-Retraining-Pipeline kann aufgerufen werden, wenn ein neuer Datensatz vorhanden ist oder wenn die Leistung des Modells verbessert werden muss. Eine wichtige Aufgabe in der Umschulungspipeline besteht darin, über ein Versionskontrollsystem sowohl für die Trainingsdaten als auch für das Modell zu verfügen. Obwohl AWS-Dienste wie Amazon-Anerkennung Da sie über eine integrierte Versionskontrollfunktion verfügen, die eine einfache Implementierung der Pipeline ermöglicht, erfordern benutzerdefinierte Modelle eine Metadatenprotokollierung oder zusätzliche Tools zur Versionskontrolle.
Der gesamte Workflow wird mit dem implementiert AWS Cloud-Entwicklungskit (AWS CDK) zum Erstellen der erforderlichen AWS-Komponenten, einschließlich der folgenden:
- Zwei Rollen für CodePipeline- und SageMaker-Jobs
- Zwei CodePipeline-Jobs, die den Workflow orchestrieren
- Zwei S3-Buckets für die Codeartefakte der Pipelines
- Ein S3-Bucket zum Beschriften des Jobmanifests, der Datensätze und der Modelle
- Vor- und Nachbearbeitung AWS Lambda Funktionen für die Beschriftungsaufträge von SageMaker Ground Truth
Die AWS CDK-Stacks sind hochgradig modularisiert und für verschiedene Aufgaben wiederverwendbar. Das Training, der Inferenzcode und die SageMaker Ground Truth-Vorlage können für alle ähnlichen aktiven Lernszenarien ersetzt werden.
Modelltraining
Das Modelltraining umfasst zwei Aufgaben: Annotation des Kopfbegrenzungsrahmens und Annotation menschlicher Schlüsselpunkte. Wir stellen beide in diesem Abschnitt vor.
Anmerkung zum Begrenzungsrahmen des Kopfes
Bei der Annotation des Kopfbegrenzungsrahmens handelt es sich um eine Aufgabe zur Vorhersage der Position eines Begrenzungsrahmens des menschlichen Kopfes in einem Bild. Wir verwenden ein Benutzerdefinierte Etiketten von Amazon Rekognition Modell für Anmerkungen zum Kopfbegrenzungsrahmen. Die folgende Beispiel Notizbuch bietet eine Schritt-für-Schritt-Anleitung zum Trainieren eines Rekognition Custom Labels-Modells über SageMaker.
Wir müssen zunächst die Daten vorbereiten, um mit dem Training beginnen zu können. Wir generieren eine Manifestdatei für das Training und eine Manifestdatei für den Testdatensatz. Eine Manifestdatei enthält mehrere Elemente, von denen jedes für ein Bild bestimmt ist. Das Folgende ist ein Beispiel der Manifestdatei, die den Bildpfad, die Größe und Anmerkungsinformationen enthält:
Mithilfe der Manifestdateien können wir Datensätze zum Training und Testen in ein Rekognition Custom Labels-Modell laden. Wir haben das Modell mit unterschiedlichen Mengen an Trainingsdaten iteriert und es an denselben 239 unsichtbaren Bildern getestet. In diesem Test wurde die mAP_50 Die Punktzahl stieg von 0.33 bei 114 Trainingsbildern auf 0.95 bei 957 Trainingsbildern. Der folgende Screenshot zeigt die Leistungsmetriken des endgültigen Rekognition Custom Labels-Modells, das eine hervorragende Leistung in Bezug auf F1-Score, Präzision und Erinnerung liefert.

Wir haben das Modell weiter anhand eines zurückgehaltenen Datensatzes mit 1,128 Bildern getestet. Das Modell prognostiziert konsistent genaue Bounding-Box-Vorhersagen für die unsichtbaren Daten, was zu einem hohen Ergebnis führt mAP_50 von 94.9 %. Das folgende Beispiel zeigt ein automatisch mit Anmerkungen versehenes Bild mit einem Kopfbegrenzungsrahmen.

Anmerkung zu den wichtigsten Punkten
Durch die Anmerkung zu Schlüsselpunkten werden die Positionen wichtiger Punkte ermittelt, darunter Augen, Ohren, Nase, Mund, Nacken, Schultern, Ellbogen, Handgelenke, Hüften und Knöchel. Zusätzlich zur Standortvorhersage ist für die Vorhersage in dieser speziellen Aufgabe die Sichtbarkeit jedes Punkts erforderlich, für die wir eine neuartige Methode entwerfen.
Für die Anmerkung zu wichtigen Punkten verwenden wir a Yolo 8 Pose-Modell auf SageMaker als Ausgangsmodell. Wir bereiten zunächst die Daten für das Training vor, einschließlich der Generierung von Etikettendateien und einer Konfigurations-.yaml-Datei gemäß den Anforderungen von Yolo. Nach der Vorbereitung der Daten trainieren wir das Modell und speichern Artefakte, einschließlich der Modellgewichtsdatei. Mit der Datei mit den trainierten Modellgewichten können wir die neuen Bilder mit Anmerkungen versehen.
In der Trainingsphase werden alle markierten Punkte mit Standorten, einschließlich sichtbarer Punkte und verdeckter Punkte, für das Training verwendet. Daher liefert dieses Modell standardmäßig den Ort und die Zuverlässigkeit der Vorhersage. In der folgenden Abbildung ist ein großer Konfidenzschwellenwert (Hauptschwellenwert) in der Nähe von 0.6 in der Lage, die sichtbaren oder verdeckten Punkte von den Punkten außerhalb des Blickwinkels der Kamera zu unterscheiden. Allerdings werden verdeckte und sichtbare Punkte nicht durch die Konfidenz getrennt, was bedeutet, dass die vorhergesagte Konfidenz für die Vorhersage der Sichtbarkeit nicht nützlich ist.

Um eine Vorhersage der Sichtbarkeit zu erhalten, führen wir ein zusätzliches Modell ein, das auf dem Datensatz trainiert wurde, der nur sichtbare Punkte enthält, wobei sowohl verdeckte Punkte als auch Punkte außerhalb des Blickwinkels der Kamera ausgeschlossen sind. Die folgende Abbildung zeigt die Verteilung von Punkten mit unterschiedlicher Sichtbarkeit. Sichtbare Punkte und andere Punkte können im Zusatzmodell getrennt werden. Wir können einen Schwellenwert (zusätzlichen Schwellenwert) nahe 0.6 verwenden, um die sichtbaren Punkte zu erhalten. Durch die Kombination dieser beiden Modelle entwerfen wir eine Methode zur Vorhersage des Standorts und der Sichtbarkeit.

Ein Schlüsselpunkt wird zunächst vom Hauptmodell mit Standort und Hauptkonfidenz vorhergesagt, dann erhalten wir die zusätzliche Konfidenzvorhersage vom Zusatzmodell. Seine Sichtbarkeit wird dann wie folgt klassifiziert:
- Sichtbar, wenn seine Hauptkonfidenz größer als sein Hauptschwellenwert ist und seine zusätzliche Konfidenz größer als der zusätzliche Schwellenwert ist
- Verdeckt, wenn sein Hauptkonfidenzwert größer als sein Hauptschwellenwert ist und sein zusätzlicher Konfidenzwert kleiner oder gleich dem zusätzlichen Schwellenwert ist
- Sofern nicht anders angegeben, liegt das außerhalb der Kamerabewertung
Ein Beispiel für die Annotation von Schlüsselpunkten ist in der folgenden Abbildung dargestellt, wobei durchgezogene Markierungen sichtbare Punkte und hohle Markierungen verdeckte Punkte sind. Außerhalb der Kamera werden Überprüfungspunkte nicht angezeigt.

Basierend auf dem Standard OKS Durch die Definition des MS-COCO-Datensatzes kann unsere Methode einen mAP_50 von 98.4 % auf dem ungesehenen Testdatensatz erreichen. In Bezug auf die Sichtbarkeit ergibt die Methode eine Klassifizierungsgenauigkeit von 79.2 % für denselben Datensatz.
Kennzeichnung und Umschulung von Menschen
Obwohl die Modelle bei Testdaten eine hervorragende Leistung erzielen, besteht bei neuen realen Daten immer noch die Möglichkeit, Fehler zu machen. Bei der menschlichen Kennzeichnung handelt es sich um den Prozess zur Korrektur dieser Fehler, um die Modellleistung durch Umschulung zu verbessern. Wir haben eine Beurteilungsfunktion entworfen, die den von den ML-Modellen ausgegebenen Konfidenzwert für die Ausgabe aller Kopfbegrenzungsrahmen oder Schlüsselpunkte kombiniert. Anhand des Endergebnisses identifizieren wir diese Fehler und die daraus resultierenden schlecht beschrifteten Bilder, die an den menschlichen Beschriftungsprozess gesendet werden müssen.
Zusätzlich zu schlecht beschrifteten Bildern wird ein kleiner Teil der Bilder zufällig für die menschliche Beschriftung ausgewählt. Diese von Menschen beschrifteten Bilder werden zur Neuschulung in die aktuelle Version des Trainingssatzes eingefügt, wodurch die Modellleistung und die allgemeine Annotationsgenauigkeit verbessert werden.
Bei der Umsetzung nutzen wir SageMaker Ground Truth für die menschliche Kennzeichnung Verfahren. SageMaker Ground Truth bietet eine benutzerfreundliche und intuitive Benutzeroberfläche für die Datenkennzeichnung. Der folgende Screenshot zeigt einen SageMaker Ground Truth-Beschriftungsauftrag für die Annotation des Kopfbegrenzungsrahmens.

Der folgende Screenshot zeigt einen SageMaker Ground Truth-Beschriftungsauftrag für die Annotation wichtiger Punkte.

Kosten, Geschwindigkeit und Wiederverwendbarkeit
Kosten und Geschwindigkeit sind die Hauptvorteile unserer Lösung im Vergleich zur Etikettierung durch Menschen, wie in den folgenden Tabellen dargestellt. Mithilfe dieser Tabellen stellen wir die Kosteneinsparungen und Geschwindigkeitsbeschleunigungen dar. Mit der beschleunigten GPU-SageMaker-Instanz ml.g4dn.xlarge sind die gesamten Schulungs- und Inferenzkosten für 100,000 Bilder um 99 % geringer als die Kosten für die menschliche Kennzeichnung, während die Geschwindigkeit je nach Modell 10–10,000 Mal schneller ist als die menschliche Kennzeichnung Aufgabe.
Die erste Tabelle fasst die Kosten-Leistungs-Kennzahlen zusammen.
| Modell | mAP_50 basierend auf 1,128 Testbildern | Schulungskosten basierend auf 100,000 Bildern | Inferenzkosten basierend auf 100,000 Bildern | Kostenreduzierung im Vergleich zur menschlichen Annotation | Inferenzzeit basierend auf 100,000 Bildern | Zeitbeschleunigung im Vergleich zur menschlichen Annotation |
| Erkennungskopf-Begrenzungsrahmen | 0.949 | $4 | $22 | 99% weniger | 5.5 Stunden | Tage |
| Yolo Wichtige Punkte | 0.984 | $27.20 | * 10 USD | 99.9% weniger | Minuten | Wochen |
Die folgende Tabelle fasst die Leistungsmetriken zusammen.
| Anmerkungsaufgabe | Karte_50 (%) | Schulungskosten ($) | Inferenzkosten ($) | Inferenzzeit |
| Kopfbegrenzungsbox | 94.9 | 4 | 22 | 5.5 Stunden |
| Wichtige Punkte | 98.4 | 27 | 10 | 5 Мinuten |
Darüber hinaus bietet unsere Lösung Wiederverwendbarkeit für ähnliche Aufgaben. Auch Kamerawahrnehmungsentwicklungen für andere Systeme wie fortschrittliche Fahrerassistenzsysteme (ADAS) und Kabinensysteme können unsere Lösung übernehmen.
Zusammenfassung
In diesem Beitrag haben wir gezeigt, wie man mithilfe von AWS-Diensten eine aktive Lernpipeline für die automatische Annotation von Bildern in der Kabine aufbaut. Wir demonstrieren die Leistungsfähigkeit von ML, mit der Sie den Annotationsprozess automatisieren und beschleunigen können, sowie die Flexibilität des Frameworks, das Modelle verwendet, die entweder von AWS-Diensten unterstützt oder auf SageMaker angepasst werden. Mit Amazon S3, SageMaker, Lambda und SageMaker Ground Truth können Sie die Datenspeicherung, Annotation, Schulung und Bereitstellung optimieren, Wiederverwendbarkeit erreichen und gleichzeitig die Kosten erheblich senken. Durch die Implementierung dieser Lösung können Automobilunternehmen agiler und kosteneffizienter werden, indem sie ML-basierte erweiterte Analysen wie automatisierte Bildanmerkungen nutzen.
Beginnen Sie noch heute und nutzen Sie die Kraft von AWS-Services und maschinelles Lernen für Ihre Anwendungsfälle im Bereich der Fahrzeuginnenraumsensorik!
Über die Autoren
 Yanxiang Yu ist angewandter Wissenschaftler am Amazon Generative AI Innovation Center. Mit über 9 Jahren Erfahrung in der Entwicklung von KI- und maschinellen Lernlösungen für industrielle Anwendungen ist er auf generative KI, Computer Vision und Zeitreihenmodellierung spezialisiert.
Yanxiang Yu ist angewandter Wissenschaftler am Amazon Generative AI Innovation Center. Mit über 9 Jahren Erfahrung in der Entwicklung von KI- und maschinellen Lernlösungen für industrielle Anwendungen ist er auf generative KI, Computer Vision und Zeitreihenmodellierung spezialisiert.
 Tianyi Mao ist ein angewandter Wissenschaftler bei AWS mit Sitz im Großraum Chicago. Er verfügt über mehr als 5 Jahre Erfahrung in der Entwicklung von Lösungen für maschinelles Lernen und Deep Learning und konzentriert sich auf Computer Vision und Reinforcement Learning mit menschlichem Feedback. Er genießt es, mit Kunden zusammenzuarbeiten, um deren Herausforderungen zu verstehen und sie durch die Entwicklung innovativer Lösungen mithilfe von AWS-Services zu lösen.
Tianyi Mao ist ein angewandter Wissenschaftler bei AWS mit Sitz im Großraum Chicago. Er verfügt über mehr als 5 Jahre Erfahrung in der Entwicklung von Lösungen für maschinelles Lernen und Deep Learning und konzentriert sich auf Computer Vision und Reinforcement Learning mit menschlichem Feedback. Er genießt es, mit Kunden zusammenzuarbeiten, um deren Herausforderungen zu verstehen und sie durch die Entwicklung innovativer Lösungen mithilfe von AWS-Services zu lösen.
 Yanru Xiao ist angewandter Wissenschaftler am Amazon Generative AI Innovation Center, wo er KI/ML-Lösungen für die realen Geschäftsprobleme der Kunden entwickelt. Er hat in verschiedenen Bereichen gearbeitet, darunter Fertigung, Energie und Landwirtschaft. Yanru erhielt seinen Ph.D. in Informatik von der Old Dominion University.
Yanru Xiao ist angewandter Wissenschaftler am Amazon Generative AI Innovation Center, wo er KI/ML-Lösungen für die realen Geschäftsprobleme der Kunden entwickelt. Er hat in verschiedenen Bereichen gearbeitet, darunter Fertigung, Energie und Landwirtschaft. Yanru erhielt seinen Ph.D. in Informatik von der Old Dominion University.
 Paul George ist ein versierter Produktführer mit über 15 Jahren Erfahrung in der Automobiltechnologie. Er ist versiert in der Leitung von Produktmanagement-, Strategie-, Go-to-Market- und Systementwicklungsteams. Er hat weltweit mehrere neue Sensor- und Wahrnehmungsprodukte entwickelt und auf den Markt gebracht. Bei AWS leitet er die Strategie und Markteinführung für autonome Fahrzeug-Workloads.
Paul George ist ein versierter Produktführer mit über 15 Jahren Erfahrung in der Automobiltechnologie. Er ist versiert in der Leitung von Produktmanagement-, Strategie-, Go-to-Market- und Systementwicklungsteams. Er hat weltweit mehrere neue Sensor- und Wahrnehmungsprodukte entwickelt und auf den Markt gebracht. Bei AWS leitet er die Strategie und Markteinführung für autonome Fahrzeug-Workloads.
 Caroline Chung ist technische Leiterin bei Veoneer (von Magna International übernommen) und verfügt über mehr als 14 Jahre Erfahrung in der Entwicklung von Sensor- und Wahrnehmungssystemen. Derzeit leitet sie Vorentwicklungsprogramme für Innenraumsensoren bei Magna International und leitet ein Team von Computer-Vision-Ingenieuren und Datenwissenschaftlern.
Caroline Chung ist technische Leiterin bei Veoneer (von Magna International übernommen) und verfügt über mehr als 14 Jahre Erfahrung in der Entwicklung von Sensor- und Wahrnehmungssystemen. Derzeit leitet sie Vorentwicklungsprogramme für Innenraumsensoren bei Magna International und leitet ein Team von Computer-Vision-Ingenieuren und Datenwissenschaftlern.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

