Einleitung
Daten-Management Replikation wird auch als Datenbankreplikation bezeichnet, bei der Daten kopiert werden, um sicherzustellen, dass alle Informationen in Echtzeit über alle Datenressourcen hinweg konsistent bleiben. Die Datenreplikation ist wie ein Sicherheitsnetz, das Ihre Informationen davor bewahrt, zu verschwinden oder durch das Raster zu fallen. In den meisten Fällen ändern sich Daten. Es ändert sich ständig. Auch wenn sich ein Replikat am anderen Ende der Welt befindet, werden ständig Daten vom Primärspeicher dorthin kopiert.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was ist Datenreplikation?
Der Prozess, mehrere Kopien eines Datenelements zu erstellen und diese an verschiedenen Orten zu speichern, ermöglicht eine bessere Netzwerkzugänglichkeit, Fehlertoleranz und Sicherungskopien. Wie die Datenspiegelung kann die Datenreplikation auf Server und einzelne Computer angewendet werden. Datenduplikate können auf demselben System, auf Onsite- und Offsite-Servern und Cloud-basierten Hosts gespeichert werden.
Datenreplikation in einer verteilten Datenbank
Das Erstellen zahlreicher Kopien von Daten ist der Prozess der Datenreplikation. Einmal erstellt, werden diese Replikate – auch als Kopien bezeichnet – an einigen wenigen Orten für Backups, Fehlertoleranz und verbesserte Netzwerkzugänglichkeit gespeichert. Die replizierten Daten können auf regionalen und entfernten Servern, Cloud-basierten Hosts oder sogar auf allen Servern desselben Systems gespeichert werden.
Der Prozess der Verteilung von Daten von einem Quellserver auf andere Server in einem verteilten Datenbank wird als Datenreplikation bezeichnet. Dadurch wird sichergestellt, dass Benutzer auf die von ihnen benötigten Daten zugreifen können, ohne die Arbeit anderer zu stören.
Zweck der Datenreplikation
Aus den folgenden fünf Gründen sollten Sie Ihre Daten in der Cloud sichern:
- Wie bereits erwähnt, sorgt die Replikation in die Cloud dafür, dass Ihre Aufzeichnungen außerhalb des Unternehmensstandorts aufbewahrt werden. Selbst wenn ein Feuer, eine Überschwemmung oder ein Sturm Ihre primäre Instanz ernsthaft beschädigt usw., ist Ihre Backup-Instanz in der Cloud sicher.
- Es ist kostengünstiger, Informationen in die Cloud zu replizieren, als dies in Ihrem eigenen Eingabezentrum zu tun, und es kann verwendet werden, um verlorene Programme und Eingaben abzurufen. Möglicherweise müssen Sie keine Hardware-, Wartungs- oder Supportgebühren zahlen, die mit dem Betrieb eines zweiten Speicherzentrums verbunden sind.
- Die Skalierbarkeit nach Bedarf wird durch die Datenreplikation in die Cloud ermöglicht. Wenn Ihr Unternehmen expandiert, schrumpft oder wieder aufnimmt, müssen Sie kein Geld für neue Hardware ausgeben, um Ihre sekundäre Instanz zu warten. Außerdem binden Sie keine langwierigen Verträge.
- Abhängig von den Anforderungen Ihres Unternehmens haben Sie eine große Auswahl an geografischen Optionen für die Replikation von Daten in die Cloud, einschließlich einer Cloud-Instanz in der nächsten Stadt im ganzen Land.
Wie repliziert man eine Datenbank?
Replizierte Organismen können sich sporadisch oder häufig replizieren. Betroffen ist die verteilte Architektur der Datenquellen eines Unternehmens. Die Daten werden mithilfe des verteilten Verwaltungssystems der Organisation repliziert und gleichmäßig auf alle Quellen verteilt.
DDBMS oder verteilte Datenbankverwaltungssysteme stellen im Allgemeinen sicher, dass alle Änderungen, Ergänzungen oder Löschungen der an einem Standort gespeicherten Daten automatisch in den an allen anderen Standorten gespeicherten Daten widergespiegelt werden. Das System, das für die Steuerung des gemeinsam genutzten Speichers verantwortlich ist, der sich aus der Repository-Replikation ergibt, ist ein gemeinsam genutztes Datenbankverwaltungssystem oder DDBMS.
Vollständige Datenreplikation vs. Teilreplikation
Eine vollständige Datenbankreplikation findet statt, wenn eine primäre Datenbank vollständig über alle Instanzen verfügbarer Replikate repliziert wird. Diese gründliche Technik repliziert neu erworbene, aktuelle und zuvor erhaltene Daten an alle Ziele. Obwohl diese Methode sehr gründlich ist, erfordert die übertragene Datenmenge eine erhebliche Rechenleistung, die das Netzwerk belastet.
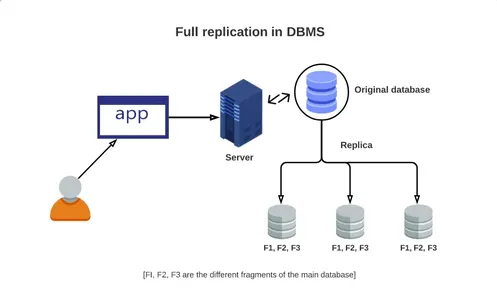
Im Gegensatz dazu spiegelt die partielle Replikation zur vollständigen Replikation nur eine Teilmenge der Daten wider, normalerweise die neuesten Aktualisierungen. Die teilweise Replikation isoliert bestimmte Datenelemente abhängig von der Wichtigkeit der Daten an einem bestimmten Punkt. Beispielsweise könnte ein großes Finanzunternehmen mit Hauptsitz in London zahlreiche Niederlassungen auf der ganzen Welt haben, darunter solche in Boston, Kuala Lumpur und so weiter.

Beispiele
Es gibt drei Hauptkategorien der Datenreplikation: Transaktional, Merge und Snapshot.
1. Transaktionsreplikation
Diese Art der Datenbankreplikation ermöglicht es Daten aus einer primären Datenbank, Daten in Echtzeit in einer Replikatinstanz zu duplizieren, indem diese Änderungen in der Reihenfolge wiedergegeben werden, in der sie in der primären Datenbank erstellt wurden. Es erhöht die Zuverlässigkeit. Die Replikation erstellt einen „Schnappschuss“ der Daten in der Primärdatenbank und verwendet diesen Schnappschuss als Referenz für das, was sonst noch kopiert werden muss. Transaktionsreplikation ermöglicht die Nachverfolgung und Verteilung von Änderungen.
Aufgrund der schrittweisen Natur dieses Prozesses ist die Transaktionsreplikation nicht die beste Wahl, wenn Sie nach einer Alternative für ein Backup-Repository suchen. Die Transaktionsreplikation ist eine gute Wahl, wenn sich Daten häufig von einem einzigen Standort aus ändern, wenn Echtzeitkonsistenz über alle Datenstandorte hinweg erforderlich ist, wenn jede kleinste Änderung zusätzlich zu den Gesamtfolgen der Änderung berücksichtigt werden muss und wenn Daten häufig verwendet werden Änderungen von einem einzigen Standort aus.
2. Snapshot-Replikation
Wie der Name schon sagt, kopiert die Snapshot-Replikation Daten von der primären auf die Replik, indem sie sie zu einem bestimmten Zeitpunkt „erfasst“. Wenn Daten vom primären zum Replikat gesendet werden, erfasst die Snapshot-Replikation wie ein Foto, wie die Daten zu diesem genauen Zeitpunkt aussehen, ignoriert jedoch spätere Änderungen. Vermeiden Sie daher die Snapshot-Replikation zum Erstellen eines Backups.
Die Snapshot-Replikation hat keinen Zugriff auf aktualisierte Daten, wenn ein Speicherfehler auftritt. Sie können mit einem Snapshot beginnen, um die Konsistenz zu wahren, aber stellen Sie sicher, dass alle Änderungen, die an der Primärdatenbank vorgenommen werden, an alle Replikate weitergegeben werden.
Auf der anderen Seite ist dieser Ansatz sehr nützlich für die Datenwiederherstellung nach einem unbeabsichtigten Löschen. Stellen Sie sich vor, es ähnelt Ihrem Versionsverlauf von Google Docs. Wäre es nicht schön, an Ihrer Präsentation so weiterzuarbeiten wie vor vier Stunden? Sie könnten auf diese Version oder den „Schnappschuss“ von vor vier Stunden zurückklicken und sehen, wie Ihre Informationen aussehen, wenn Google Docs in stündlichen Abständen einen Schnappschuss Ihrer Arbeit macht.
3. Mergereplikation
Diese Methode beginnt normalerweise mit einem Snapshot der Informationen, verteilt sie auf ihre Repliken und hält die Datensynchronisierung im gesamten System aufrecht. Im Gegensatz zu anderen Replikationstypen ermöglicht die Mergereplikation individuelle Datenaktualisierungen von jedem Knoten, während diese Aktualisierungen in ein einziges, kohärentes Ganzes integriert werden.
Sie müssen die relevantesten Aspekte bestimmen, die in Ihrer Situation zu arrangieren sind. Repository-Replikationstechnologien können abhängig von Elementen wie Preis, Funktion und Zugänglichkeit ausgewählt werden. Ein Unternehmen sollte sich zur Zahlung verpflichten. Ziel ist es, innerhalb des zugewiesenen Budgets die besten Repository-Replikationslösungen für das Projekt zu finden.
Einige der besten Datenreplikationstools sind wie folgt:
4. Rubrik
Rubrik ist ein Service, der schnelle Sicherungen, Archivierung, sofortige Wiederherstellung, Analysen und Kopierverwaltung für die Verwaltung und Sicherung von Daten in der Cloud bietet. Es umfasst modernste Rechenzentrumstechnologien und bietet vereinfachte Backups. Eine benutzerfreundliche Benutzeroberfläche macht es einfach, jeder Benutzergruppe Aufgaben zuzuweisen. Je nach Anwendungsfall kann es erforderlich sein, verschiedene Cluster in ein einziges Dashboard zu integrieren. Dies hat jedoch einige Einschränkungen.
5. Shareplex
SharePlex ist eine andere Echtzeit-Replikations-Repository-Replikationstechnologie. Das Programm ist unglaublich anpassungsfähig und mit einer Vielzahl von Speichersystemen kompatibel. Eine Message-Queuing-Technik ermöglicht eine schnelle Datenübertragung und ist stark skalierbar. Sowohl die Methode des Tools zum Sammeln von Änderungsdaten als auch seine Überwachungsdienste haben einige Nachteile.
6. Hevo-Daten
Da sich die Fähigkeit von Unternehmen, Daten zu sammeln, enorm entwickelt, sind Datenteams von entscheidender Bedeutung, um datengesteuerte Entscheidungen zu treffen. Sie haben immer noch Probleme, aus den vielfältigen Daten in ihrem Warenlager eine einzige Quelle der Wahrheit zu erstellen. Aufgrund von defekten Pipelines, schlechter Datenqualität, Bugs, Fehlern und einem Mangel an Kontrolle und Transparenz über den Datenfluss ist die Datenintegration mühsam. Mehr als 1000 Datenteams nutzen die Datenpipeline-Plattform von Hevo, um Daten aus mehr als 150 Quellen schnell und effektiv zu aggregieren. Millionen von Datenereignissen aus SaaS-Apps, Repositories, Dateispeichern und Streaming-Quellen können aufgrund der fehlertoleranten Architektur von Hevo sofort kopiert werden.
Vorteile
Die Replikation der Daten kann den Benutzern einen konsistenten Zugriff auf die Informationen ermöglichen. Es erhöht auch die Anzahl gleichzeitiger Benutzer, die auf die Daten zugreifen. Datenredundanzen werden entfernt, indem Datenbanken kombiniert und Slave-Datenbanken mit Teildaten aktualisiert werden. Darüber hinaus beschleunigt die Datenreplikation den Datenbankzugriff.
1. Verfügbarkeit und Zuverlässigkeit von Daten
Die Datenreplikation stellt sicher, dass Daten zugänglich sind. Dies ist besonders hilfreich für multinationale Unternehmen mit Niederlassungen auf der ganzen Welt. Dadurch sind die Daten im Falle eines Hardwareausfalls oder eines anderen Problems an einem Ort weiterhin für andere Standorte zugänglich.
2. Servereffizienz
Die Replikation von Daten kann die Serverleistung verbessern und beschleunigen. Benutzer können Daten viel schneller erhalten, wenn Unternehmen verschiedene Datenkopien auf mehreren Servern betreiben. Darüber hinaus können Administratoren weniger Prozessorzyklen auf dem primären Server für ressourcenintensive Schreibaktivitäten verwenden, wenn alle Datenlesevorgänge an ein Replikat weitergeleitet werden.
3. Effizientere Netzwerkleistung
Durch das Abrufen der erforderlichen Daten von der Website, an der die Transaktion abgeschlossen wird, kann das Aufbewahren von Kopien derselben Daten an vielen Orten die Datenzugriffslatenz verringern.
4. Unterstützung bei der Datenanalyse
Unternehmen, die sich stark auf Daten konzentrieren, replizieren normalerweise Informationen aus verschiedenen Quellen in ihre Datenspeicher, einschließlich Data Warehouses oder Data Lakes. Dies erleichtert die Durchführung gemeinsamer Projekte durch das auf zahlreiche Standorte verteilte Analytics-Team.
5. Verbesserte Testsystemleistung
Die Datenverteilung und -synchronisierung für Testsysteme, die eine schnelle Verfügbarkeit für eine schnellere Entscheidungsfindung erfordern, wird durch Duplizierung vereinfacht.
Nachteile
Die Aufrechterhaltung der Datenreplikation erfordert viel Hardware und Speicherplatz. Die Replikation ist teuer, und die Wartung der Infrastruktur zur Wahrung der Datenkonsistenz ist eine Herausforderung. Es macht auch mehr Softwarekomponenten anfällig für Sicherheits- und Datenschutzprobleme.
Die Replikation bietet zahlreiche Vorteile, aber es sollte auch ein Gleichgewicht zwischen ihnen in einer Organisation geben. Das größte Hindernis für die Aufrechterhaltung konsistenter Daten in einem Unternehmen ist der Mangel an Ressourcen:
1. Höhere Preise
Größere Speicher- und Verarbeitungsaufwände resultieren aus der Verwaltung doppelter Kopien derselben Daten an mehreren Stellen und verteilten Datenbanksystemen.
2. Zeitliche Beschränkungen
Interne Mitarbeiter müssen Zeit für die Verwaltung des Duplizierungsprozesses aufwenden, um sicherzustellen, dass die kopierten Daten mit den Originaldaten kompatibel sind.
3. Bandbreite
Der Netzwerkverkehr kann als Ergebnis der Aufrechterhaltung der Konsistenz zwischen Datenreplikaten ansteigen.
4. Unzuverlässige Daten
Dies ist möglicherweise nur für ein paar Stunden ein Problem, oder Ihre Daten verlieren möglicherweise vollständig die Synchronisierung. Datenbankadministratoren sollten kontinuierlich sicherstellen, dass die Daten aktualisiert werden, um dieses Problem zu beheben. Die Methode zur Replikation von Daten sollte gründlich durchdacht, in die Tat umgesetzt, bewertet und bei Bedarf ausgefeilt werden.
Zusammenfassung
Dieser Artikel erklärt ausführlich jede Datenreplikationsstrategie und liefert alle Informationen, die Sie wissen müssen. Es gibt einen schnellen Überblick über eine Vielzahl verwandter Ideen, die den Benutzern helfen, sie besser zu verstehen und sie auf die effektivste Weise für die Datenreplikation und -wiederherstellung einzusetzen. Die Schwierigkeiten vieler Dateningenieure wurden ebenfalls diskutiert und vor allem, wie ein Datenreplikationstool Datenteams dabei helfen kann, ihre Zeit und Ressourcen besser zu nutzen. Die Replikation von Daten hat offensichtliche Vorteile. Unternehmen müssen auf die Schwierigkeiten vorbereitet sein, die durch die wachsende Zahl von Quellen und Zielen entstehen. Daher ist es entscheidend, einen skalierbaren und zuverlässigen Datenreplikationsmechanismus zu implementieren.
Die wichtigsten Erkenntnisse dieses Artikels lauten wie folgt:
- Da Daten an vielen Orten gespeichert werden, können Benutzer sie von den Servern abrufen, die ihnen am nächsten sind, und erleben eine geringere Latenz.
- Dank der Datenreplikation können Unternehmen den Datenverkehr auf mehrere Server verteilen, was die Serverleistung verbessert und die Belastung einzelner Server verringert.
- Effektive Notfallwiederherstellung und Datenschutz werden durch Datenreplikation bereitgestellt. Aufgrund der Datenverfügbarkeit könnten jede Stunde, in der eine wichtige Datenquelle ausfällt, Millionen von Dollar verschwendet werden.
- Unternehmen können je nach Anwendungsfall und vorhandener Datenarchitektur verschiedene Techniken einsetzen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/02/a-deep-dive-into-data-replication-most-effective-way-to-protect-your-data/

