Dies ist ein Gastbeitrag, der gemeinsam mit Scott Gutterman von der PGA TOUR verfasst wurde.
Generative künstliche Intelligenz (generative KI) hat neue Möglichkeiten für den Aufbau intelligenter Systeme eröffnet. Jüngste Verbesserungen bei auf generativer KI basierenden großen Sprachmodellen (LLMs) haben deren Verwendung in einer Vielzahl von Anwendungen rund um den Informationsabruf ermöglicht. Angesichts der Datenquellen stellten LLMs Tools zur Verfügung, die es uns ermöglichten, innerhalb von Wochen einen Q&A-Chatbot zu erstellen, anstatt wie zuvor womöglich Jahre in Anspruch zu nehmen, und wahrscheinlich mit schlechterer Leistung. Wir haben eine Retrieval-Augmented-Generation (RAG)-Lösung entwickelt, die es der PGA TOUR ermöglichen würde, einen Prototyp für eine zukünftige Fan-Engagement-Plattform zu erstellen, die ihre Daten den Fans auf interaktive Weise in einem Konversationsformat zugänglich machen könnte.
Die Verwendung strukturierter Daten zur Beantwortung von Fragen erfordert eine Möglichkeit, Daten effektiv zu extrahieren, die für die Anfrage eines Benutzers relevant sind. Wir haben einen Text-zu-SQL-Ansatz formuliert, bei dem die Abfrage eines Benutzers in natürlicher Sprache mithilfe eines LLM in eine SQL-Anweisung umgewandelt wird. Das SQL wird von ausgeführt Amazonas Athena um die relevanten Daten zurückzugeben. Diese Daten werden wiederum einem LLM zur Verfügung gestellt, der gebeten wird, die Anfrage des Benutzers anhand der Daten zu beantworten.
Die Verwendung von Textdaten erfordert einen Index, der zum Durchsuchen und Bereitstellen relevanter Kontexte für ein LLM verwendet werden kann, um eine Benutzeranfrage zu beantworten. Um einen schnellen Informationsabruf zu ermöglichen, verwenden wir Amazon Kendra als Index für diese Dokumente. Wenn Benutzer Fragen stellen, durchsucht unser virtueller Assistent schnell den Amazon Kendra-Index, um relevante Informationen zu finden. Amazon Kendra nutzt Natural Language Processing (NLP), um Benutzeranfragen zu verstehen und die relevantesten Dokumente zu finden. Die relevanten Informationen werden dann dem LLM zur endgültigen Antwortgenerierung bereitgestellt. Unsere endgültige Lösung ist eine Kombination dieser Text-to-SQL- und Text-RAG-Ansätze.
In diesem Beitrag beleuchten wir, wie das AWS Generative AI Innovation Center arbeitete mit dem Professionelle AWS-Services und PGA TOUR einen Prototyp eines virtuellen Assistenten zu entwickeln Amazonas Grundgestein Dies könnte es den Fans ermöglichen, auf nahtlose interaktive Weise Informationen über jedes Ereignis, jeden Spieler, jedes Loch oder Details zur Schlagebene zu extrahieren. Amazon Bedrock ist ein vollständig verwalteter Dienst, der über eine einzige API eine Auswahl leistungsstarker Foundation-Modelle (FMs) von führenden KI-Unternehmen wie AI21 Labs, Anthropic, Cohere, Meta, Stability AI und Amazon sowie eine breite Palette von bietet Funktionen, die Sie zum Erstellen generativer KI-Anwendungen mit Sicherheit, Datenschutz und verantwortungsvoller KI benötigen.
Entwicklung: Bereitstellung der Daten
Wie bei jedem datengesteuerten Projekt ist die Leistung immer nur so gut wie die Daten. Wir haben die Daten verarbeitet, damit das LLM relevante Daten effektiv abfragen und abrufen kann.
Bei den tabellarischen Wettbewerbsdaten haben wir uns auf eine Teilmenge der Daten konzentriert, die für die meisten Benutzeranfragen relevant sind, und die Spalten intuitiv beschriftet, damit sie für LLMs leichter verständlich sind. Wir haben auch einige Hilfsspalten erstellt, um dem LLM zu helfen, Konzepte zu verstehen, mit denen er sonst möglicherweise Schwierigkeiten haben würde. Wenn ein Golfer zum Beispiel einen Schlag weniger als Par schießt (z. B. wenn er bei einem Par 3 mit 4 Schlägen oder bei einem Par 4 mit 5 Schlägen ins Loch gelangt), wird dies üblicherweise als a bezeichnet Vögelchen. Wenn ein Benutzer fragt: „Wie viele Birdies hat Spieler X letztes Jahr gemacht?“, reicht es nicht aus, nur den Punktestand und das Par in der Tabelle zu haben. Aus diesem Grund haben wir Spalten hinzugefügt, um gängige Golfbegriffe wie Bogey, Birdie und Eagle anzuzeigen. Darüber hinaus haben wir die Wettbewerbsdaten mit einer separaten Videosammlung verknüpft, indem wir eine Spalte für a zusammengefügt haben video_id, was es unserer App ermöglichen würde, das mit einer bestimmten Aufnahme verknüpfte Video in den Wettbewerbsdaten abzurufen. Wir haben auch die Verknüpfung von Textdaten mit den Tabellendaten ermöglicht, beispielsweise das Hinzufügen von Biografien für jeden Spieler als Textspalte. Die folgenden Abbildungen zeigen Schritt für Schritt, wie eine Abfrage für die Text-zu-SQL-Pipeline verarbeitet wird. Die Zahlen geben die Schrittfolge zur Beantwortung einer Anfrage an.
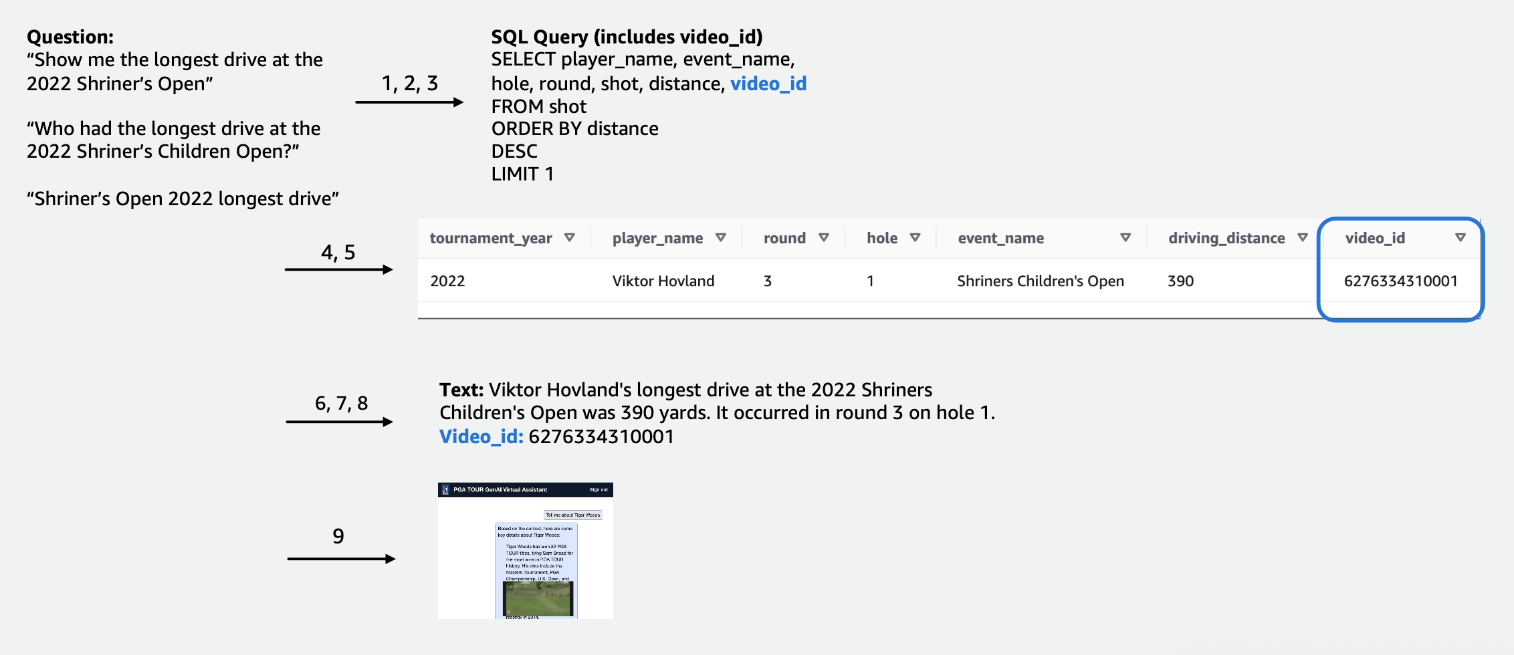
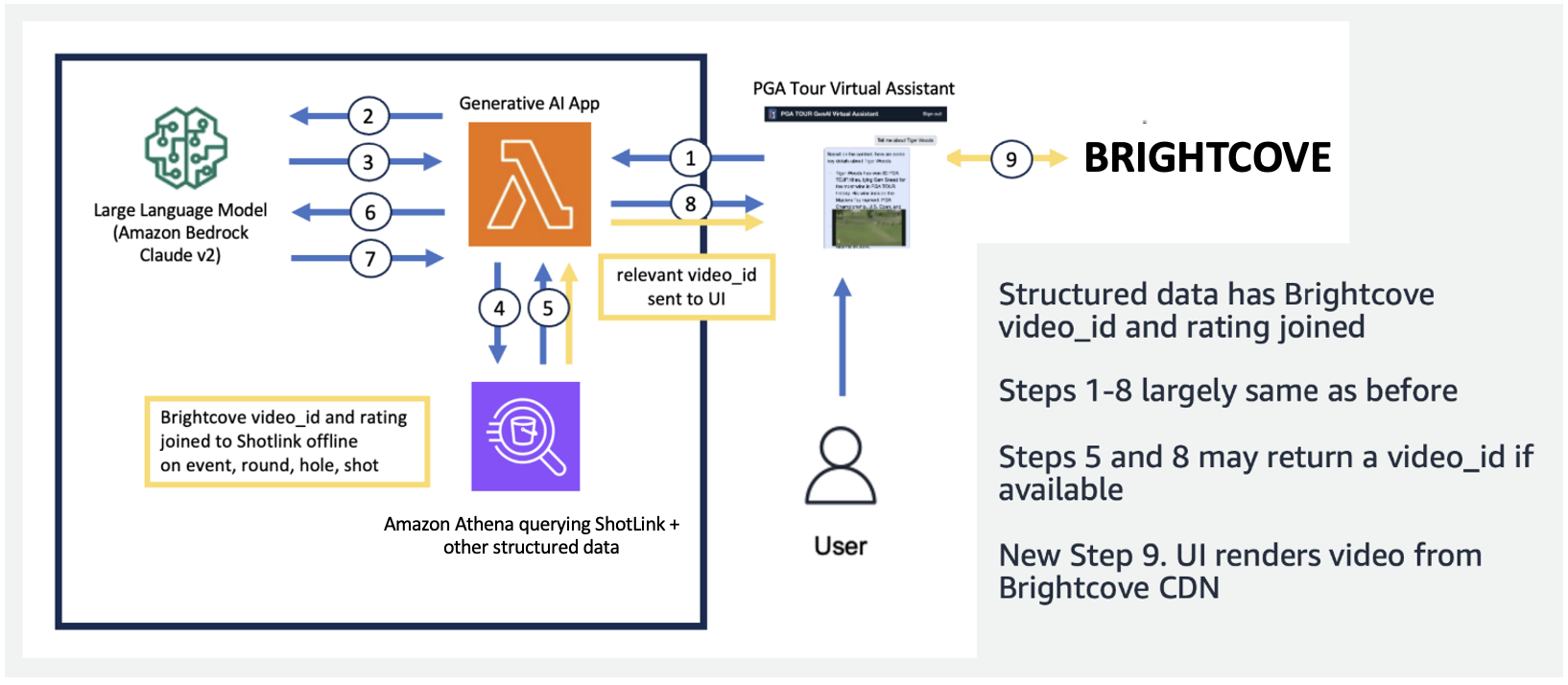
In der folgenden Abbildung demonstrieren wir unsere End-to-End-Pipeline. Wir gebrauchen AWS Lambda als unsere Orchestrierungsfunktion, die für die Interaktion mit verschiedenen Datenquellen, LLMs und die Fehlerkorrektur basierend auf der Benutzerabfrage verantwortlich ist. Die Schritte 1 bis 8 ähneln denen in der folgenden Abbildung. Für die unstrukturierten Daten gibt es geringfügige Änderungen, die wir als Nächstes besprechen.
Textdaten erfordern einzigartige Verarbeitungsschritte, die lange Dokumente in für das LLM verdauliche Teile unterteilen (oder segmentieren) und gleichzeitig die Themenkohärenz wahren. Wir haben mit mehreren Ansätzen experimentiert und uns für ein Chunking-Schema auf Seitenebene entschieden, das gut zum Format der Media Guides passt. Wir haben Amazon Kendra verwendet, einen verwalteten Dienst, der sich um die Indizierung von Dokumenten kümmert, ohne dass die Angabe von Einbettungen erforderlich ist, und der gleichzeitig eine einfache API zum Abrufen bereitstellt. Die folgende Abbildung veranschaulicht diese Architektur.

Die von uns entwickelte einheitliche, skalierbare Pipeline ermöglicht die Skalierung der PGA TOUR auf ihre gesamte Datenhistorie, die teilweise bis ins 1800. Jahrhundert zurückreicht. Es ermöglicht zukünftige Anwendungen, die den Kurskontext live nutzen können, um reichhaltige Echtzeiterlebnisse zu schaffen.
Entwicklung: Evaluierung von LLMs und Entwicklung generativer KI-Anwendungen
Wir haben die in Amazon Bedrock verfügbaren Erst- und Drittanbieter-LLMs sorgfältig getestet und bewertet, um das Modell auszuwählen, das für unsere Pipeline und unseren Anwendungsfall am besten geeignet ist. Wir haben Claude v2 und Claude Instant von Anthropic auf Amazon Bedrock ausgewählt. Für unsere endgültige strukturierte und unstrukturierte Datenpipeline stellen wir fest, dass Claude 2 von Anthropic auf Amazon Bedrock bessere Gesamtergebnisse für unsere endgültige Datenpipeline erzielte.
Die Eingabeaufforderung ist ein entscheidender Aspekt, um LLMs dazu zu bringen, Text wie gewünscht auszugeben. Wir haben viel Zeit damit verbracht, mit unterschiedlichen Eingabeaufforderungen für jede Aufgabe zu experimentieren. Für die Text-zu-SQL-Pipeline hatten wir beispielsweise mehrere Fallback-Eingabeaufforderungen mit zunehmender Spezifität und schrittweise vereinfachten Tabellenschemata. Wenn eine SQL-Abfrage ungültig war und zu einem Fehler von Athena führte, haben wir eine Fehlerkorrekturaufforderung entwickelt, die den Fehler und die falsche SQL an das LLM weiterleitet und es auffordert, es zu beheben. Die letzte Eingabeaufforderung in der Text-zu-SQL-Pipeline fordert den LLM auf, die Athena-Ausgabe, die im Markdown- oder CSV-Format bereitgestellt werden kann, zu übernehmen und dem Benutzer eine Antwort bereitzustellen. Für den unstrukturierten Text haben wir allgemeine Eingabeaufforderungen entwickelt, um den von Amazon Kendra abgerufenen Kontext zur Beantwortung der Benutzerfrage zu verwenden. Die Eingabeaufforderung enthielt Anweisungen, nur die von Amazon Kendra abgerufenen Informationen zu verwenden und sich nicht auf Daten aus dem LLM-Vortraining zu verlassen.
Latenz ist bei generativen KI-Anwendungen oft ein Problem, und das ist auch hier der Fall. Dies stellt insbesondere bei Text-to-SQL ein Problem dar, das zunächst einen LLM-Aufruf zur SQL-Generierung und anschließend einen LLM-Aufruf zur Antwortgenerierung erfordert. Wenn wir ein großes LLM wie Claude V2 von Anthropic verwenden, verdoppelt sich dadurch effektiv die Latenz von nur einem LLM-Aufruf. Wir haben mit mehreren Konfigurationen großer und kleinerer LLMs experimentiert, um sowohl die Laufzeit als auch die Korrektheit zu bewerten. Die folgende Tabelle zeigt ein Beispiel für eine Frage, die die Latenz sowie die generierten Antworten mit Claude V2 und Claude Instant von Anthropic auf Amazon Bedrock demonstriert.

Prototyp
In unserer Anwendung haben wir eine Lambda-Funktion verwendet, um die schnellen Entscheidungen und die Kommunikation zwischen Amazon Athena, Amazon Kendra und Amazon Bedrock zu orchestrieren. Der virtuelle Assistent verfügt über eine Konversationsschnittstelle, die mit React und dem Cloudscape Design System erstellt wurde und Text und Videos verwendet, um mit Benutzern in Kontakt zu treten.
Unser virtueller Assistent kann eine Vielzahl von Fragen zu PGA TOUR-Events, Spielern, Statistiken, Geschichte und mehr beantworten. Wenn der Assistent beispielsweise nach Tony Finaus längsten Drives bei den Shriners Children's Open (einem der Signature-Events der PGA TOUR) gefragt wird, kann er strukturierte Daten abfragen, um seine Schlagniveaudaten abzurufen. Mithilfe der Text-to-SQL-Pipeline kann er die genaue Distanz in Yards, die Rundenzahl und das Loch extrahieren, in dem er diesen Rekord erzielt hat. Der Assistent interpretiert diese numerischen Daten dann, um eine endgültige Antwort zu generieren. Die folgende Tabelle enthält einige Beispielantworten.
| Fragen (FAQ) | Antwort |
| Was war der längste Drive, den Tony Finau bei den Shriners Children's Open geschlagen hat? | Der längste von Tony Finau bei den Shriners Childrens Open geschlagene Drive betrug 382 Yards, den er 4 in der ersten Runde an Loch Nummer 2018 schlug. |
| Was war der längste Drive, den Collin Morikawa bei den Shriners Children's Open geschlagen hat? | Collin Morikawas längster Drive bei den Shriners Childrens Open betrug 334 Yards. Dies geschah im Jahr 2019 während der ersten Runde an Loch Nummer 15. |
| Hat irgendjemand bei den Shriners Children's Open 2022 ein Ass geschafft? | Ja, Adam Hadwin hat in Runde 14 der Shriners Children's Open 3 ein Hole-in-One an Loch 2022 geschafft |
Das folgende Erklärvideo zeigt einige Beispiele für die Interaktion mit dem virtuellen Assistenten.
In ersten Tests hat sich unser virtueller PGA TOUR-Assistent als vielversprechend für die Verbesserung des Fan-Erlebnisses erwiesen. Durch die Kombination von KI-Technologien wie Text-to-SQL, semantischer Suche und Generierung natürlicher Sprache liefert der Assistent informative, ansprechende Antworten. Fans werden in die Lage versetzt, mühelos auf Daten und Erzählungen zuzugreifen, die zuvor schwer zu finden waren.
Was hält die Zukunft bereit?
Im Zuge der weiteren Entwicklung werden wir die Palette der Fragen erweitern, die unser virtueller Assistent bearbeiten kann. Dies erfordert umfangreiche Tests in Zusammenarbeit zwischen AWS und der PGA TOUR. Mit der Zeit wollen wir den Assistenten zu einem personalisierten Omnichannel-Erlebnis weiterentwickeln, das über Web-, Mobil- und Sprachschnittstellen zugänglich ist.
Durch die Einrichtung eines cloudbasierten generativen KI-Assistenten kann die PGA TOUR ihre umfangreiche Datenquelle mehreren internen und externen Stakeholdern präsentieren. Während sich die generative KI-Landschaft im Sport weiterentwickelt, ermöglicht sie die Erstellung neuer Inhalte. Sie können beispielsweise KI und maschinelles Lernen (ML) verwenden, um Inhalte anzuzeigen, die Fans sehen möchten, während sie sich ein Event ansehen, oder wenn Produktionsteams nach Bildern aus früheren Turnieren suchen, die zu einem aktuellen Event passen. Wenn sich Max Homa beispielsweise darauf vorbereitet, seinen letzten Schlag bei der PGA TOUR Championship von einem Punkt aus zu machen, der 20 Fuß von der Markierung entfernt ist, kann die PGA TOUR KI und ML verwenden, um Clips von ihm zu identifizieren und mit KI-generierten Kommentaren zu präsentieren Ich habe zuvor fünf Mal einen ähnlichen Schuss versucht. Diese Art von Zugriff und Daten ermöglichen es einem Produktionsteam, der Sendung sofort einen Mehrwert zu verleihen oder einem Fan die Möglichkeit zu geben, die Art der Daten, die er sehen möchte, anzupassen.
„Die PGA TOUR ist branchenführend beim Einsatz modernster Technologie zur Verbesserung des Fanerlebnisses. KI steht an der Spitze unseres Technologie-Stacks und ermöglicht es uns, eine ansprechendere und interaktivere Umgebung für Fans zu schaffen. Dies ist der Beginn unserer generativen KI-Reise in Zusammenarbeit mit dem AWS Generative AI Innovation Center für ein transformatives End-to-End-Kundenerlebnis. Wir arbeiten daran, Amazon Bedrock und unsere proprietären Daten zu nutzen, um ein interaktives Erlebnis für PGA TOUR-Fans zu schaffen, bei dem sie auf interaktive Weise interessante Informationen zu einem Event, einem Spieler, Statistiken oder anderen Inhalten finden können.“
– Scott Gutterman, SVP of Broadcast and Digital Properties bei PGA TOUR.
Zusammenfassung
Das in diesem Beitrag besprochene Projekt veranschaulicht, wie strukturierte und unstrukturierte Datenquellen mithilfe von KI zusammengeführt werden können, um virtuelle Assistenten der nächsten Generation zu schaffen. Für Sportorganisationen ermöglicht diese Technologie eine intensivere Einbindung der Fans und setzt interne Effizienzsteigerungen frei. Die von uns aufgedeckten Dateninformationen helfen PGA TOUR-Stakeholdern wie Spielern, Trainern, Funktionären, Partnern und Medien, schneller fundierte Entscheidungen zu treffen. Über den Sport hinaus kann unsere Methodik auf jede Branche übertragen werden. Die gleichen Grundsätze gelten für Gebäudeassistenten, die Kunden, Mitarbeiter, Studenten, Patienten und andere Endnutzer einbeziehen. Mit durchdachtem Design und Tests kann praktisch jedes Unternehmen von einem KI-System profitieren, das seine strukturierten Datenbanken, Dokumente, Bilder, Videos und anderen Inhalte kontextualisiert.
Wenn Sie an der Implementierung ähnlicher Funktionen interessiert sind, sollten Sie die Verwendung in Betracht ziehen Agenten für Amazon Bedrock und Wissensdatenbanken für Amazon Bedrock als alternative, vollständig von AWS verwaltete Lösung. Dieser Ansatz könnte die Bereitstellung intelligenter Automatisierungs- und Datensuchfunktionen durch anpassbare Agenten weiter untersuchen. Diese Agenten könnten möglicherweise die Interaktionen mit Benutzeranwendungen natürlicher, effizienter und effektiver gestalten.
Über die Autoren
 Scott Gutterman ist SVP of Digital Operations für die PGA TOUR. Er ist für den gesamten digitalen Betrieb und die Produktentwicklung der TOUR verantwortlich und treibt deren GenAI-Strategie voran.
Scott Gutterman ist SVP of Digital Operations für die PGA TOUR. Er ist für den gesamten digitalen Betrieb und die Produktentwicklung der TOUR verantwortlich und treibt deren GenAI-Strategie voran.
 Ahsan Ali ist angewandter Wissenschaftler am Amazon Generative AI Innovation Center, wo er mit Kunden aus verschiedenen Bereichen zusammenarbeitet, um ihre dringenden und teuren Probleme mithilfe generativer KI zu lösen.
Ahsan Ali ist angewandter Wissenschaftler am Amazon Generative AI Innovation Center, wo er mit Kunden aus verschiedenen Bereichen zusammenarbeitet, um ihre dringenden und teuren Probleme mithilfe generativer KI zu lösen.
 Tahin Syed ist angewandter Wissenschaftler beim Amazon Generative AI Innovation Center, wo er mit Kunden zusammenarbeitet, um mit generativen KI-Lösungen Geschäftsergebnisse zu erzielen. Außerhalb der Arbeit probiert er gerne neues Essen aus, reist und unterrichtet Taekwondo.
Tahin Syed ist angewandter Wissenschaftler beim Amazon Generative AI Innovation Center, wo er mit Kunden zusammenarbeitet, um mit generativen KI-Lösungen Geschäftsergebnisse zu erzielen. Außerhalb der Arbeit probiert er gerne neues Essen aus, reist und unterrichtet Taekwondo.
 Grace Lang ist Associate Data & ML Engineer bei AWS Professional Services. Angetrieben von der Leidenschaft, schwierige Herausforderungen zu meistern, hilft Grace seinen Kunden, ihre Ziele zu erreichen, indem es Lösungen entwickelt, die auf maschinellem Lernen basieren.
Grace Lang ist Associate Data & ML Engineer bei AWS Professional Services. Angetrieben von der Leidenschaft, schwierige Herausforderungen zu meistern, hilft Grace seinen Kunden, ihre Ziele zu erreichen, indem es Lösungen entwickelt, die auf maschinellem Lernen basieren.
 Jae Lee ist Senior Engagement Manager im M&E-Bereich von ProServe. Sie leitet und liefert komplexe Projekte, verfügt über ausgeprägte Fähigkeiten zur Problemlösung, verwaltet die Erwartungen der Stakeholder und kuratiert Präsentationen auf Führungsebene. Sie arbeitet gerne an Projekten mit den Schwerpunkten Sport, generative KI und Kundenerlebnis.
Jae Lee ist Senior Engagement Manager im M&E-Bereich von ProServe. Sie leitet und liefert komplexe Projekte, verfügt über ausgeprägte Fähigkeiten zur Problemlösung, verwaltet die Erwartungen der Stakeholder und kuratiert Präsentationen auf Führungsebene. Sie arbeitet gerne an Projekten mit den Schwerpunkten Sport, generative KI und Kundenerlebnis.
 Karn Chahar ist Sicherheitsberater im Shared Delivery-Team bei AWS. Er ist ein Technologie-Enthusiast, der gerne mit Kunden zusammenarbeitet, um ihre Sicherheitsherausforderungen zu lösen und ihre Sicherheitslage in der Cloud zu verbessern.
Karn Chahar ist Sicherheitsberater im Shared Delivery-Team bei AWS. Er ist ein Technologie-Enthusiast, der gerne mit Kunden zusammenarbeitet, um ihre Sicherheitsherausforderungen zu lösen und ihre Sicherheitslage in der Cloud zu verbessern.
 Mike Amjadi ist ein Daten- und ML-Ingenieur bei AWS ProServe, der sich darauf konzentriert, Kunden zu ermöglichen, den Wert ihrer Daten zu maximieren. Er ist auf das Entwerfen, Erstellen und Optimieren von Datenpipelines nach gut durchdachten Prinzipien spezialisiert. Mike setzt sich leidenschaftlich für den Einsatz von Technologie zur Lösung von Problemen ein und setzt sich dafür ein, die besten Ergebnisse für unsere Kunden zu liefern.
Mike Amjadi ist ein Daten- und ML-Ingenieur bei AWS ProServe, der sich darauf konzentriert, Kunden zu ermöglichen, den Wert ihrer Daten zu maximieren. Er ist auf das Entwerfen, Erstellen und Optimieren von Datenpipelines nach gut durchdachten Prinzipien spezialisiert. Mike setzt sich leidenschaftlich für den Einsatz von Technologie zur Lösung von Problemen ein und setzt sich dafür ein, die besten Ergebnisse für unsere Kunden zu liefern.
 Vrushali Sawant ist Front-End-Ingenieur bei Proserve. Sie ist hochqualifiziert in der Erstellung responsiver Websites. Sie liebt es, mit Kunden zusammenzuarbeiten, ihre Anforderungen zu verstehen und ihnen skalierbare, einfach zu implementierende UI/UX-Lösungen bereitzustellen.
Vrushali Sawant ist Front-End-Ingenieur bei Proserve. Sie ist hochqualifiziert in der Erstellung responsiver Websites. Sie liebt es, mit Kunden zusammenzuarbeiten, ihre Anforderungen zu verstehen und ihnen skalierbare, einfach zu implementierende UI/UX-Lösungen bereitzustellen.
 Neelam Patel ist Customer Solutions Manager bei AWS und leitet wichtige Initiativen zur generativen KI und Cloud-Modernisierung. Neelam arbeitet mit wichtigen Führungskräften und Technologieeigentümern zusammen, um ihre Herausforderungen bei der Cloud-Transformation anzugehen, und hilft Kunden, die Vorteile der Cloud-Einführung zu maximieren. Sie hat einen MBA der Warwick Business School, Großbritannien, und einen Bachelor in Computertechnik, Indien.
Neelam Patel ist Customer Solutions Manager bei AWS und leitet wichtige Initiativen zur generativen KI und Cloud-Modernisierung. Neelam arbeitet mit wichtigen Führungskräften und Technologieeigentümern zusammen, um ihre Herausforderungen bei der Cloud-Transformation anzugehen, und hilft Kunden, die Vorteile der Cloud-Einführung zu maximieren. Sie hat einen MBA der Warwick Business School, Großbritannien, und einen Bachelor in Computertechnik, Indien.
 Dr. Murali Baktha ist Global Golf Solution Architect bei AWS und leitet entscheidende Initiativen zu generativer KI, Datenanalyse und modernsten Cloud-Technologien. Murali arbeitet mit wichtigen Führungskräften und Technologieeigentümern zusammen, um die geschäftlichen Herausforderungen der Kunden zu verstehen und Lösungen zur Bewältigung dieser Herausforderungen zu entwickeln. Er hat einen MBA in Finanzen von UConn und einen Doktortitel von der Iowa State University.
Dr. Murali Baktha ist Global Golf Solution Architect bei AWS und leitet entscheidende Initiativen zu generativer KI, Datenanalyse und modernsten Cloud-Technologien. Murali arbeitet mit wichtigen Führungskräften und Technologieeigentümern zusammen, um die geschäftlichen Herausforderungen der Kunden zu verstehen und Lösungen zur Bewältigung dieser Herausforderungen zu entwickeln. Er hat einen MBA in Finanzen von UConn und einen Doktortitel von der Iowa State University.
 Mehdi Noor ist Manager für angewandte Wissenschaft am Generative Ai Innovation Center. Mit einer Leidenschaft für die Verbindung von Technologie und Innovation unterstützt er AWS-Kunden dabei, das Potenzial generativer KI auszuschöpfen, potenzielle Herausforderungen in Chancen für schnelle Experimente und Innovationen umzuwandeln, indem er sich auf skalierbare, messbare und wirkungsvolle Anwendungen fortschrittlicher KI-Technologien konzentriert und den Weg rationalisiert zur Produktion.
Mehdi Noor ist Manager für angewandte Wissenschaft am Generative Ai Innovation Center. Mit einer Leidenschaft für die Verbindung von Technologie und Innovation unterstützt er AWS-Kunden dabei, das Potenzial generativer KI auszuschöpfen, potenzielle Herausforderungen in Chancen für schnelle Experimente und Innovationen umzuwandeln, indem er sich auf skalierbare, messbare und wirkungsvolle Anwendungen fortschrittlicher KI-Technologien konzentriert und den Weg rationalisiert zur Produktion.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/the-journey-of-pga-tours-generative-ai-virtual-assistant-from-concept-to-development-to-prototype/

