Data Engineering spielt eine zentrale Rolle im riesigen Datenökosystem, indem es Daten sammelt, umwandelt und bereitstellt, die für Analysen, Berichte und maschinelles Lernen unerlässlich sind. Angehende Dateningenieure suchen oft nach realen Projekten, um praktische Erfahrungen zu sammeln und ihr Fachwissen unter Beweis zu stellen. In diesem Artikel werden die 20 besten Data-Engineering-Projektideen mit ihrem Quellcode vorgestellt. Ganz gleich, ob Sie ein Anfänger, ein Ingenieur auf mittlerem Niveau oder ein fortgeschrittener Praktiker sind, diese Projekte bieten eine hervorragende Gelegenheit, Ihre Fähigkeiten im Bereich Data Engineering zu verbessern.
Inhaltsverzeichnis
Data-Engineering-Projekte für Anfänger
1. Intelligente IoT-Infrastruktur
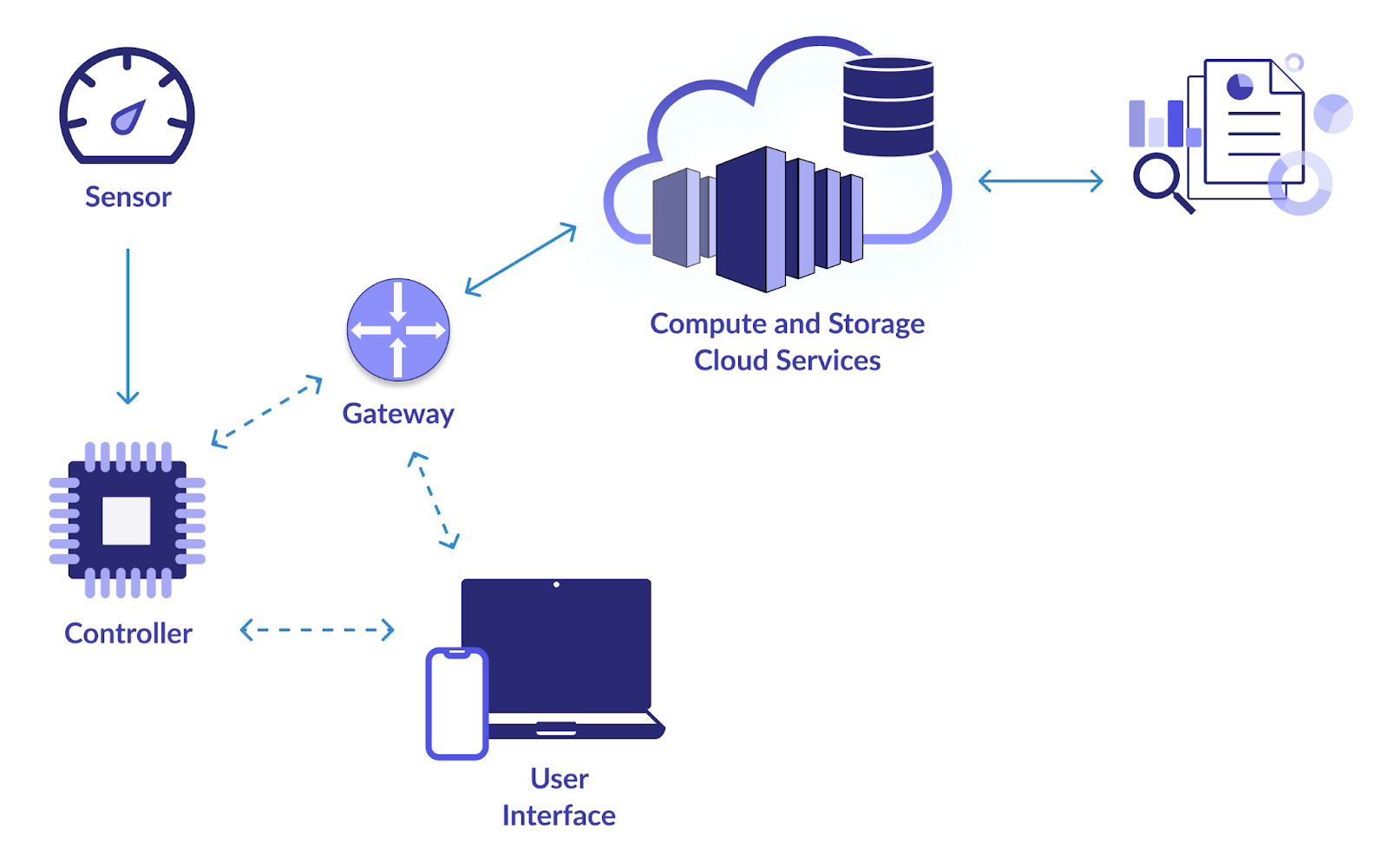
Ziel
Das Hauptziel dieses Projekts ist der Aufbau einer vertrauenswürdigen Datenpipeline zum Sammeln und Analysieren von Daten von IoT-Geräten (Internet der Dinge). Webcams, Temperatursensoren, Bewegungsmelder und andere IoT-Geräte erzeugen alle eine Menge Daten. Sie möchten ein System entwerfen, um diese Daten effektiv zu nutzen, zu speichern, zu verarbeiten und zu analysieren. Dadurch wird eine Echtzeitüberwachung und Entscheidungsfindung auf Grundlage der Erkenntnisse aus den IoT-Daten ermöglicht.
Wie löst man?
- Nutzen Sie Technologien wie Apache Kafka oder MQTT für eine effiziente Datenerfassung von IoT-Geräten. Diese Technologien unterstützen Datenströme mit hohem Durchsatz.
- Nutzen Sie skalierbare Datenbanken wie Apache Cassandra oder MongoDB, um die eingehenden IoT-Daten zu speichern. Diese NoSQL-Datenbanken können das Volumen und die Vielfalt der IoT-Daten bewältigen.
- Implementieren Sie die Datenverarbeitung in Echtzeit mit Apache Spark Streaming oder Apache Flink. Mit diesen Frameworks können Sie Daten bei ihrem Eintreffen analysieren und umwandeln, sodass sie für die Echtzeitüberwachung geeignet sind.
- Verwenden Sie Visualisierungstools wie Grafana oder Kibana, um Dashboards zu erstellen, die Einblicke in die IoT-Daten bieten. Echtzeitvisualisierungen können Stakeholdern dabei helfen, fundierte Entscheidungen zu treffen.
Klicken Sie hier, um den Quellcode zu überprüfen
2. Luftfahrtdatenanalyse

Ziel
Um Luftfahrtdaten aus zahlreichen Quellen, darunter der Federal Aviation Administration (FAA), Fluggesellschaften und Flughäfen, zu sammeln, zu verarbeiten und zu analysieren, versucht dieses Projekt, eine Datenpipeline zu entwickeln. Zu den Luftfahrtdaten gehören Flüge, Flughäfen, Wetter und Passagierdemografie. Ihr Ziel ist es, aus diesen Daten aussagekräftige Erkenntnisse zu gewinnen, um die Flugplanung zu verbessern, Sicherheitsmaßnahmen zu verbessern und verschiedene Aspekte der Luftfahrtindustrie zu optimieren.
Wie löst man?
- Apache Nifi oder AWS Kinesis können für die Datenaufnahme aus verschiedenen Quellen verwendet werden.
- Speichern Sie die verarbeiteten Daten in Data Warehouses wie Amazon Redshift oder Google BigQuery für effiziente Abfragen und Analysen.
- Nutzen Sie Python mit Bibliotheken wie Pandas und Matplotlib, um detaillierte Luftfahrtdaten zu analysieren. Dies kann das Erkennen von Mustern bei Flugverspätungen, die Optimierung von Routen und die Bewertung von Passagiertrends umfassen.
- Mit Tools wie Tableau oder Power BI lassen sich aussagekräftige Visualisierungen erstellen, die Stakeholdern helfen, datengesteuerte Entscheidungen im Luftfahrtsektor zu treffen.
Klicken Sie hier, um den Quellcode anzuzeigen
3. Prognose der Versand- und Vertriebsnachfrage
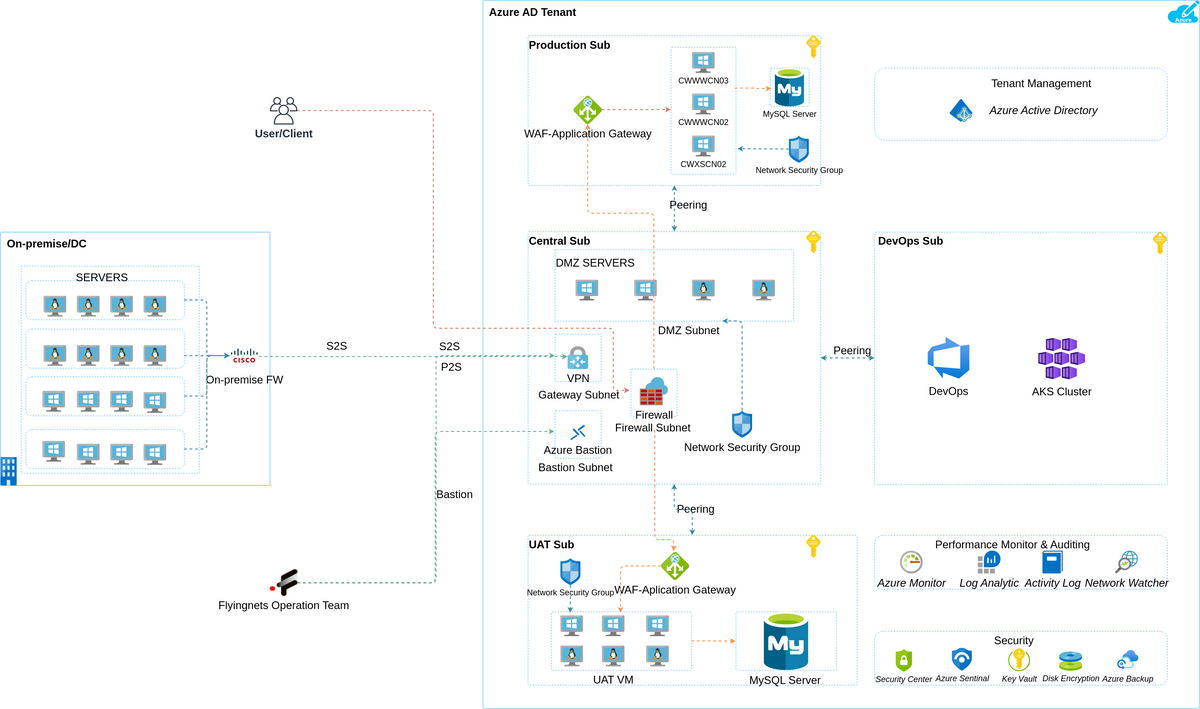
Ziel
In diesem Projekt besteht Ihr Ziel darin, eine robuste ETL-Pipeline (Extract, Transform, Load) zu erstellen, die Versand- und Vertriebsdaten verarbeitet. Mithilfe historischer Daten bauen Sie ein Nachfrageprognosesystem auf, das die zukünftige Produktnachfrage im Zusammenhang mit Versand und Vertrieb vorhersagt. Dies ist entscheidend für die Optimierung der Bestandsverwaltung, die Reduzierung der Betriebskosten und die Sicherstellung pünktlicher Lieferungen.
Wie löst man?
- Mit Apache NiFi oder Talend kann die ETL-Pipeline aufgebaut werden, die Daten aus verschiedenen Quellen extrahiert, umwandelt und in eine geeignete Datenspeicherlösung lädt.
- Nutzen Sie Tools wie Python oder Apache Spark für Datentransformationsaufgaben. Möglicherweise müssen Sie Daten bereinigen, aggregieren und vorverarbeiten, um sie für Prognosemodelle geeignet zu machen.
- Implementieren Sie Prognosemodelle wie ARIMA (AutoRegressive Integrated Moving Average) oder Prophet, um die Nachfrage genau vorherzusagen.
- Speichern Sie die bereinigten und transformierten Daten in Datenbanken wie PostgreSQL oder MySQL.
Klicken Sie hier, um den Quellcode für dieses Data-Engineering-Projekt anzuzeigen.
4. Ereignisdatenanalyse

Ziel
Erstellen Sie eine Datenpipeline, die Informationen von verschiedenen Veranstaltungen sammelt, darunter Konferenzen, Sportveranstaltungen, Konzerte und gesellschaftliche Zusammenkünfte. Teil des Projekts sind die Datenverarbeitung in Echtzeit, die Stimmungsanalyse von Social-Media-Beiträgen zu diesen Veranstaltungen und die Erstellung von Visualisierungen zur Darstellung von Trends und Erkenntnissen in Echtzeit.
Wie löst man?
- Abhängig von den Ereignisdatenquellen können Sie die Twitter-API zum Sammeln von Tweets, Web Scraping für ereignisbezogene Websites oder andere Datenerfassungsmethoden verwenden.
- Nutzen Sie NLP-Techniken (Natural Language Processing) in Python, um eine Stimmungsanalyse für Social-Media-Beiträge durchzuführen. Tools wie NLTK oder spaCy können wertvoll sein.
- Nutzen Sie Streaming-Technologien wie Apache Kafka oder Apache Flink für die Datenverarbeitung und -analyse in Echtzeit.
- Erstellen Sie interaktive Dashboards und Visualisierungen mit Frameworks wie Dash oder Plotly, um ereignisbezogene Erkenntnisse in einem benutzerfreundlichen Format darzustellen.
Klicken Sie hier, um den Quellcode zu überprüfen.
5. Log Analytics-Projekt
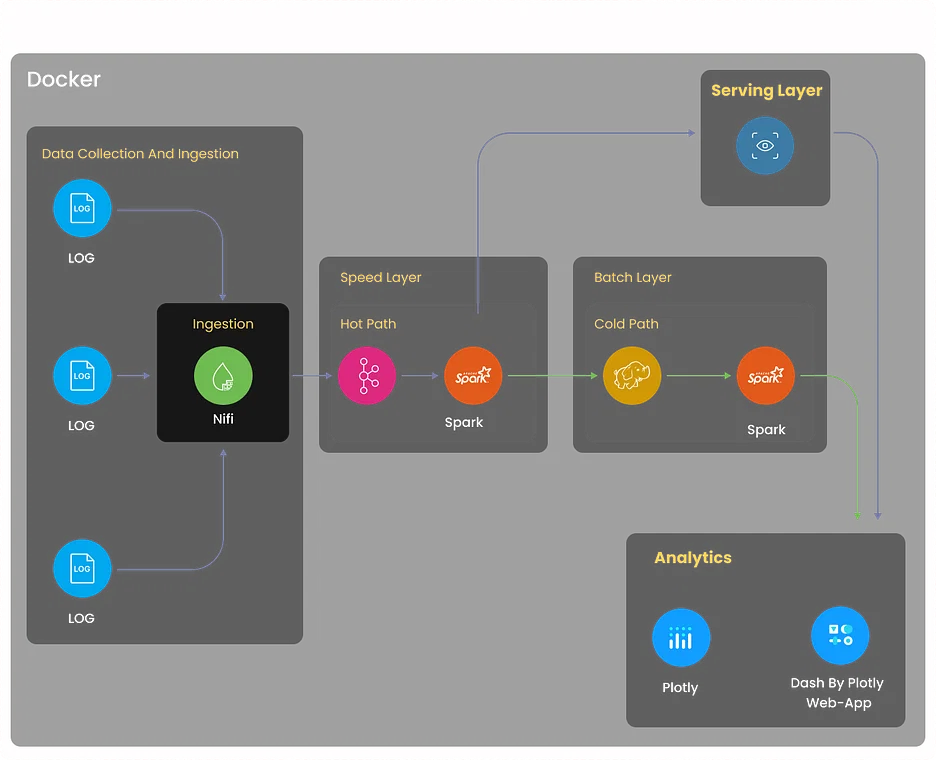
Ziel
Erstellen Sie ein umfassendes Protokollanalysesystem, das Protokolle aus verschiedenen Quellen sammelt, darunter Server, Anwendungen und Netzwerkgeräte. Das System sollte Protokolldaten zentralisieren, Anomalien erkennen, die Fehlerbehebung erleichtern und die Systemleistung durch protokollbasierte Erkenntnisse optimieren.
Wie löst man?
- Implementieren Sie die Protokollsammlung mit Tools wie Logstash oder Fluentd. Diese Tools können Protokolle aus verschiedenen Quellen aggregieren und für die weitere Verarbeitung normalisieren.
- Nutzen Sie Elasticsearch, eine leistungsstarke verteilte Such- und Analyse-Engine, um Protokolldaten effizient zu speichern und zu indizieren.
- Nutzen Sie Kibana, um Dashboards und Visualisierungen zu erstellen, die es Benutzern ermöglichen, Protokolldaten in Echtzeit zu überwachen.
- Richten Sie Warnmechanismen mit Elasticsearch Watcher oder Grafana Alerts ein, um relevante Stakeholder zu benachrichtigen, wenn bestimmte Protokollmuster oder Anomalien erkannt werden.
Klicken Sie hier, um dieses Data-Engineering-Projekt zu erkunden
6. Movielens-Datenanalyse für Empfehlungen

Ziel
- Entwerfen und entwickeln Sie eine Empfehlungs-Engine mithilfe des Movielens-Datensatzes.
- Erstellen Sie eine robuste ETL-Pipeline, um die Daten vorzuverarbeiten und zu bereinigen.
- Implementieren Sie kollaborative Filteralgorithmen, um Benutzern personalisierte Filmempfehlungen bereitzustellen.
Wie löst man?
- Nutzen Sie Apache Spark oder AWS Glue, um eine ETL-Pipeline zu erstellen, die Film- und Benutzerdaten extrahiert, in ein geeignetes Format umwandelt und in eine Datenspeicherlösung lädt.
- Implementieren Sie kollaborative Filtertechniken, wie z. B. benutzerbasierte oder elementbasierte kollaborative Filterung, mithilfe von Bibliotheken wie Scikit-learn oder TensorFlow.
- Speichern Sie die bereinigten und transformierten Daten in Datenspeicherlösungen wie Amazon S3 oder Hadoop HDFS.
- Entwickeln Sie eine webbasierte Anwendung (z. B. mit Flask oder Django), in der Benutzer ihre Präferenzen eingeben können und die Empfehlungsmaschine personalisierte Filmempfehlungen bereitstellt.
Klicken Sie hier, um dieses Data-Engineering-Projekt zu erkunden.
7. Retail Analytics-Projekt
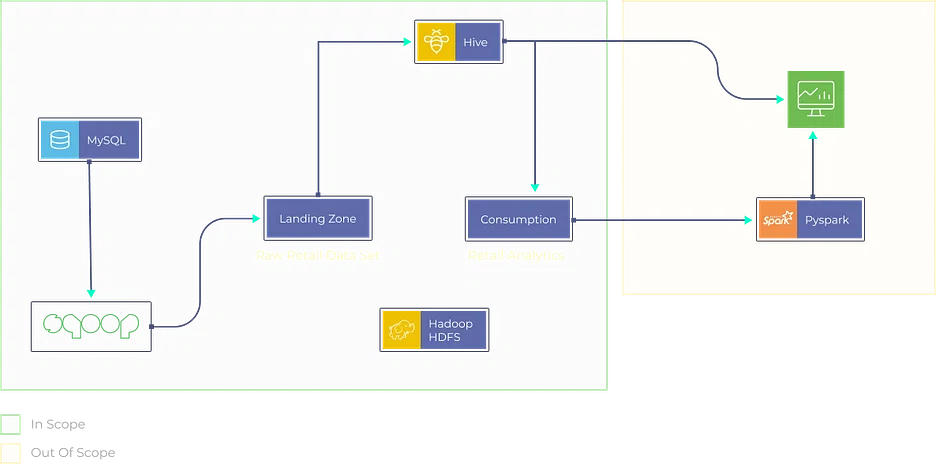
Ziel
Erstellen Sie eine Analyseplattform für den Einzelhandel, die Daten aus verschiedenen Quellen erfasst, darunter Point-of-Sale-Systeme, Bestandsdatenbanken und Kundeninteraktionen. Analysieren Sie Verkaufstrends, optimieren Sie die Bestandsverwaltung und generieren Sie personalisierte Produktempfehlungen für Kunden.
Wie löst man?
- Implementieren Sie ETL-Prozesse mit Tools wie Apache Beam oder AWS Data Pipeline, um Daten aus Einzelhandelsquellen zu extrahieren, umzuwandeln und zu laden.
- Nutzen Sie Algorithmen für maschinelles Lernen wie XGBoost oder Random Forest für Verkaufsprognosen und Bestandsoptimierung.
- Speichern und verwalten Sie Daten in Data-Warehousing-Lösungen wie Snowflake oder Azure Synapse Analytics für effiziente Abfragen.
- Erstellen Sie interaktive Dashboards mit Tools wie Tableau oder Looker, um Einblicke in die Einzelhandelsanalyse in einem optisch ansprechenden und verständlichen Format zu präsentieren.
Klicken Sie hier, um den Quellcode zu erkunden.
Data Engineering-Projekte auf GitHub
8. Echtzeit-Datenanalyse
Ziel
Tragen Sie zu einem Open-Source-Projekt bei, das sich auf Echtzeit-Datenanalysen konzentriert. Dieses Projekt bietet die Möglichkeit, die Datenverarbeitungsgeschwindigkeit, Skalierbarkeit und Echtzeit-Visualisierungsfähigkeiten des Projekts zu verbessern. Möglicherweise haben Sie die Aufgabe, die Leistung von Datenstreaming-Komponenten zu verbessern, die Ressourcennutzung zu optimieren oder neue Funktionen hinzuzufügen, um Anwendungsfälle für Echtzeitanalysen zu unterstützen.
Wie löst man?
Die Lösungsmethode hängt von dem Projekt ab, zu dem Sie beitragen, häufig handelt es sich jedoch um Technologien wie Apache Flink, Spark Streaming oder Apache Storm.
Klicken Sie hier, um den Quellcode für dieses Data-Engineering-Projekt zu erkunden.
9. Echtzeit-Datenanalyse mit Azure Stream Services

Ziel
Entdecken Sie Azure Stream Analytics, indem Sie zu einem Echtzeit-Datenverarbeitungsprojekt auf Azure beitragen oder ein solches erstellen. Dies kann die Integration von Azure-Diensten wie Azure Functions und Power BI beinhalten, um Erkenntnisse zu gewinnen und Echtzeitdaten zu visualisieren. Sie können sich darauf konzentrieren, die Echtzeitanalysefunktionen zu verbessern und das Projekt benutzerfreundlicher zu gestalten.
Wie löst man?
- Umreißen Sie klar die Ziele und Anforderungen des Projekts, einschließlich Datenquellen und gewünschter Erkenntnisse.
- Erstellen Sie eine Azure Stream Analytics-Umgebung, konfigurieren Sie Ein-/Ausgaben und integrieren Sie Azure Functions und Power BI.
- Erfassen Sie Echtzeitdaten und wenden Sie die erforderlichen Transformationen mithilfe von SQL-ähnlichen Abfragen an.
- Implementieren Sie benutzerdefinierte Logik für die Echtzeit-Datenverarbeitung mithilfe von Azure Functions.
- Richten Sie Power BI für die Echtzeit-Datenvisualisierung ein und sorgen Sie für ein benutzerfreundliches Erlebnis.
Klicken Sie hier, um den Quellcode für dieses Data-Engineering-Projekt zu erkunden.
10. Echtzeit-Finanzmarktdaten-Pipeline mit Finnhub API und Kafka
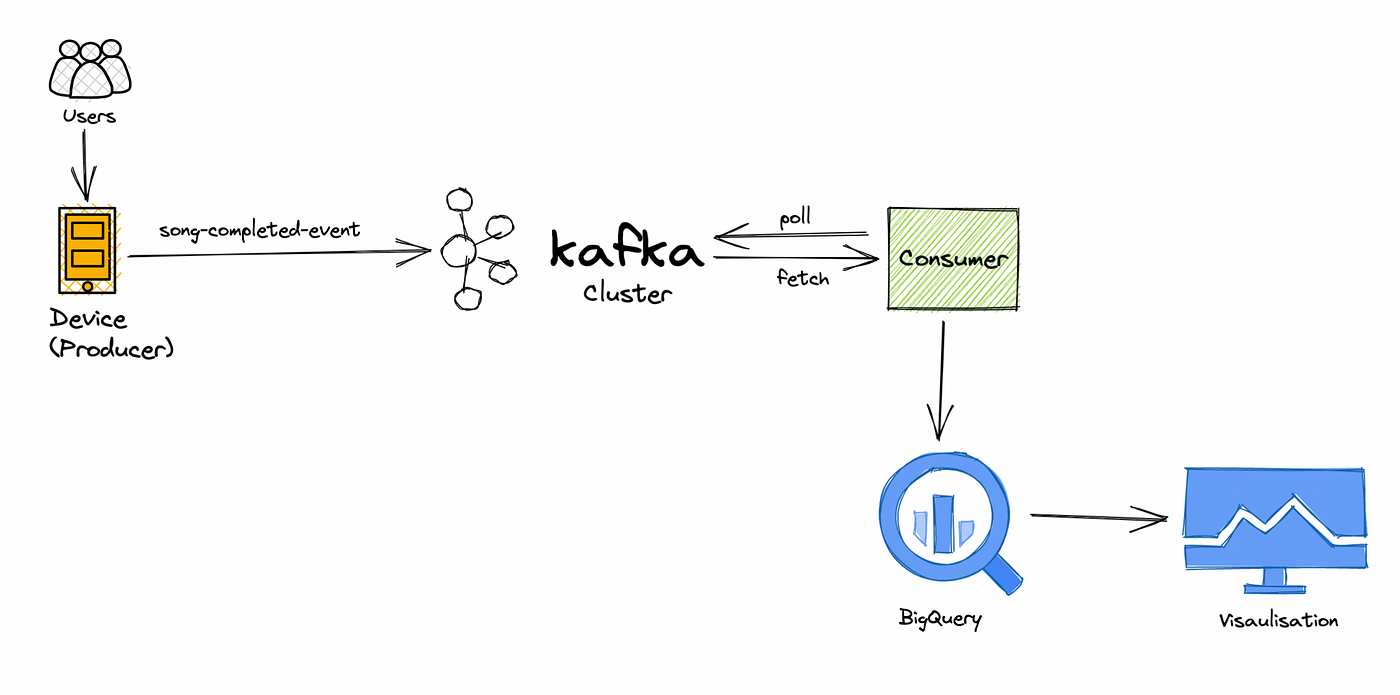
Ziel
Erstellen Sie eine Datenpipeline, die mithilfe der Finnhub-API und Apache Kafka Echtzeit-Finanzmarktdaten sammelt und verarbeitet. Dieses Projekt umfasst die Analyse von Aktienkursen, die Durchführung einer Stimmungsanalyse anhand von Nachrichtendaten und die Visualisierung von Markttrends in Echtzeit. Beiträge können die Optimierung der Datenaufnahme, die Verbesserung der Datenanalyse oder die Verbesserung der Visualisierungskomponenten umfassen.
Wie löst man?
- Beschreiben Sie klar und deutlich die Ziele des Projekts, zu denen die Erfassung und Verarbeitung von Finanzmarktdaten in Echtzeit sowie die Durchführung von Aktien- und Stimmungsanalysen gehören.
- Erstellen Sie mit Apache Kafka und der Finnhub-API eine Datenpipeline, um Marktdaten in Echtzeit zu sammeln und zu verarbeiten.
- Analysieren Sie Aktienkurse und führen Sie eine Stimmungsanalyse der Nachrichtendaten in der Pipeline durch.
- Visualisieren Sie Markttrends in Echtzeit und erwägen Sie Optimierungen für die Datenerfassung und -analyse.
- Entdecken Sie Möglichkeiten zur Optimierung der Datenverarbeitung, zur Verbesserung der Analyse und zur Verbesserung der Visualisierungskomponenten während des gesamten Projekts.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
11. Datenverarbeitungspipeline für Musikanwendungen in Echtzeit
Ziel
Arbeiten Sie an einem Echtzeit-Musik-Streaming-Datenprojekt mit, das sich auf die Verarbeitung und Analyse von Benutzerverhaltensdaten in Echtzeit konzentriert. Sie erkunden Benutzerpräferenzen, verfolgen die Beliebtheit und verbessern das Musikempfehlungssystem. Zu den Beiträgen können die Verbesserung der Datenverarbeitungseffizienz, die Implementierung fortschrittlicher Empfehlungsalgorithmen oder die Entwicklung von Echtzeit-Dashboards gehören.
Wie löst man?
- Definieren Sie klar die Projektziele und konzentrieren Sie sich dabei auf die Analyse des Benutzerverhaltens in Echtzeit und die Verbesserung der Musikempfehlungen.
- Arbeiten Sie bei der Echtzeit-Datenverarbeitung zusammen, um Benutzerpräferenzen zu erkunden, die Beliebtheit zu verfolgen und das Empfehlungssystem zu verfeinern.
- Identifizieren und implementieren Sie Effizienzverbesserungen innerhalb der Datenverarbeitungspipeline.
- Entwickeln und integrieren Sie erweiterte Empfehlungsalgorithmen, um das System zu verbessern.
- Erstellen Sie Echtzeit-Dashboards zur Überwachung und Visualisierung von Benutzerverhaltensdaten und denken Sie über laufende Verbesserungen nach.
Klicken Sie hier, um den Quellcode zu erkunden.
Fortgeschrittene Data-Engineering-Projekte für den Lebenslauf
12. Website-Überwachung

Ziel
Entwickeln Sie ein umfassendes Website-Überwachungssystem, das Leistung, Betriebszeit und Benutzererfahrung verfolgt. Dieses Projekt umfasst die Verwendung von Tools wie Selenium für Web Scraping, um Daten von Websites zu sammeln und Warnmechanismen für Echtzeitbenachrichtigungen zu erstellen, wenn Leistungsprobleme erkannt werden.
Wie löst man?
- Definieren Sie Projektziele, zu denen der Aufbau eines Website-Überwachungssystems zur Verfolgung von Leistung und Betriebszeit sowie zur Verbesserung der Benutzererfahrung gehört.
- Nutzen Sie Selenium für Web Scraping, um Daten von Zielwebsites zu sammeln.
- Implementieren Sie Echtzeit-Warnmechanismen, um zu benachrichtigen, wenn Leistungsprobleme oder Ausfallzeiten erkannt werden.
- Erstellen Sie ein umfassendes System zur Verfolgung der Website-Leistung, Betriebszeit und Benutzererfahrung.
- Planen Sie eine laufende Wartung und Optimierung des Überwachungssystems, um dessen Wirksamkeit im Laufe der Zeit sicherzustellen.
Klicken Sie hier, um den Quellcode dieses Data-Engineering-Projekts zu erkunden.
13. Bitcoin-Mining

Ziel
Tauchen Sie ein in die Welt der Kryptowährungen, indem Sie eine Bitcoin-Mining-Datenpipeline erstellen. Analysieren Sie Transaktionsmuster, erkunden Sie das Blockchain-Netzwerk und gewinnen Sie Einblicke in das Bitcoin-Ökosystem. Dieses Projekt erfordert die Datenerfassung über Blockchain-APIs, die Analyse und die Visualisierung.
Wie löst man?
- Definieren Sie die Ziele des Projekts und konzentrieren Sie sich dabei auf die Erstellung einer Bitcoin-Mining-Datenpipeline für die Transaktionsanalyse und Blockchain-Exploration.
- Implementieren Sie Datenerfassungsmechanismen von Blockchain-APIs für bergbaubezogene Daten.
- Tauchen Sie ein in die Blockchain-Analyse, um Transaktionsmuster zu erkunden und Einblicke in das Bitcoin-Ökosystem zu gewinnen.
- Entwickeln Sie Datenvisualisierungskomponenten, um Einblicke in das Bitcoin-Netzwerk effektiv darzustellen.
- Erstellen Sie eine umfassende Datenpipeline, die Datenerfassung, -analyse und -visualisierung umfasst, um eine ganzheitliche Sicht auf die Bitcoin-Mining-Aktivitäten zu erhalten.
Klicken Sie hier, um den Quellcode für dieses Data-Engineering-Projekt zu erkunden.
14. GCP-Projekt zur Erkundung von Cloud-Funktionen

Ziel
Entdecken Sie die Google Cloud Platform (GCP), indem Sie ein Data-Engineering-Projekt entwerfen und implementieren, das GCP-Dienste wie Cloud Functions, BigQuery und Dataflow nutzt. Dieses Projekt kann Datenverarbeitungs-, Transformations- und Visualisierungsaufgaben umfassen, wobei der Schwerpunkt auf der Optimierung der Ressourcennutzung und der Verbesserung der Data-Engineering-Workflows liegt.
Wie löst man?
- Definieren Sie den Umfang des Projekts klar und legen Sie den Schwerpunkt auf die Verwendung von GCP-Diensten für die Datenentwicklung, einschließlich Cloud Functions, BigQuery und Dataflow.
- Entwerfen und implementieren Sie die Integration von GCP-Diensten und stellen Sie so eine effiziente Nutzung von Cloud Functions, BigQuery und Dataflow sicher.
- Führen Sie Datenverarbeitungs- und Transformationsaufgaben als Teil des Projekts aus und richten Sie sich dabei nach den übergeordneten Zielen.
- Konzentrieren Sie sich auf die Optimierung der Ressourcennutzung innerhalb der GCP-Umgebung, um die Effizienz zu steigern.
- Suchen Sie nach Möglichkeiten zur Verbesserung der Data-Engineering-Workflows während des gesamten Projektlebenszyklus und streben Sie nach optimierten und effektiven Prozessen.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
15. Visualisierung von Reddit-Daten
Ziel
Sammeln und analysieren Sie Daten von Reddit, einer der beliebtesten Social-Media-Plattformen. Erstellen Sie interaktive Visualisierungen und gewinnen Sie Einblicke in das Benutzerverhalten, Trendthemen und Stimmungsanalysen auf der Plattform. Dieses Projekt erfordert Web Scraping, Datenanalyse und kreative Datenvisualisierungstechniken.
Wie löst man?
- Definieren Sie die Ziele des Projekts und legen Sie dabei den Schwerpunkt auf die Datenerfassung und -analyse von Reddit, um Einblicke in das Benutzerverhalten, Trendthemen und Stimmungsanalysen zu gewinnen.
- Implementieren Sie Web-Scraping-Techniken, um Daten von der Reddit-Plattform zu sammeln.
- Tauchen Sie ein in die Datenanalyse, um das Benutzerverhalten zu erkunden, Trendthemen zu identifizieren und Stimmungsanalysen durchzuführen.
- Erstellen Sie interaktive Visualisierungen, um Erkenntnisse aus den Reddit-Daten effektiv zu vermitteln.
- Nutzen Sie innovative Datenvisualisierungstechniken, um die Präsentation der Ergebnisse während des gesamten Projekts zu verbessern.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
Azure Data Engineering-Projekte
16. Yelp-Datenanalyse

Ziel
In diesem Projekt ist es Ihr Ziel, Yelp-Daten umfassend zu analysieren. Sie bauen eine Datenpipeline auf, um Yelp-Daten zu extrahieren, umzuwandeln und in eine geeignete Speicherlösung zu laden. Die Analyse kann Folgendes umfassen:
- Identifizieren beliebter Unternehmen.
- Analysieren Sie die Stimmung der Benutzerbewertungen.
- Bereitstellung von Erkenntnissen für lokale Unternehmen zur Verbesserung ihrer Dienstleistungen.
Wie löst man?
- Verwenden Sie Web-Scraping-Techniken oder die Yelp-API, um Daten zu extrahieren.
- Bereinigen und vorverarbeiten Sie Daten mit Python oder Azure Data Factory.
- Speichern Sie Daten in Azure Blob Storage oder Azure SQL Data Warehouse.
- Führen Sie Datenanalysen mit Python-Bibliotheken wie Pandas und Matplotlib durch.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
17. Datenverwaltung
Ziel
Data Governance ist entscheidend für die Gewährleistung von Datenqualität, Compliance und Sicherheit. In diesem Projekt entwerfen und implementieren Sie ein Data-Governance-Framework mithilfe von Azure-Diensten. Dies kann die Definition von Datenrichtlinien, die Erstellung von Datenkatalogen und die Einrichtung von Datenzugriffskontrollen umfassen, um sicherzustellen, dass Daten verantwortungsbewusst und in Übereinstimmung mit den Vorschriften verwendet werden.
Wie löst man?
- Nutzen Sie Azure Purview, um einen Katalog zu erstellen, der Datenbestände dokumentiert und klassifiziert.
- Implementieren Sie Datenrichtlinien mithilfe von Azure Policy und Azure Blueprints.
- Richten Sie rollenbasierte Zugriffskontrolle (RBAC) und Azure Active Directory-Integration ein, um den Datenzugriff zu verwalten.
Klicken Sie hier, um den Quellcode für dieses Data-Engineering-Projekt zu erkunden.
18. Datenaufnahme in Echtzeit

Ziel
Entwerfen Sie eine Echtzeit-Datenerfassungspipeline auf Azure mithilfe von Diensten wie Azure Data Factory, Azure Stream Analytics und Azure Event Hubs. Ziel ist es, Daten aus verschiedenen Quellen aufzunehmen und in Echtzeit zu verarbeiten, um sofortige Erkenntnisse für die Entscheidungsfindung zu liefern.
Wie löst man?
- Verwenden Sie Azure Event Hubs für die Datenerfassung.
- Implementieren Sie Echtzeit-Datenverarbeitung mit Azure Stream Analytics.
- Speichern Sie verarbeitete Daten in Azure Data Lake Storage oder Azure SQL-Datenbank.
- Visualisieren Sie Echtzeiteinblicke mit Power BI oder Azure Dashboards.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
Ideen für AWS Data Engineering-Projekte
19. ETL-Pipeline

Ziel
Erstellen Sie eine End-to-End-ETL-Pipeline (Extract, Transform, Load) auf AWS. Die Pipeline sollte Daten aus verschiedenen Quellen extrahieren, Transformationen durchführen und die verarbeiteten Daten in ein Data Warehouse oder einen Lake laden. Dieses Projekt ist ideal zum Verständnis der Grundprinzipien des Data Engineering.
Wie löst man?
- Verwenden Sie AWS Glue oder AWS Data Pipeline zur Datenextraktion.
- Implementieren Sie Transformationen mit Apache Spark auf Amazon EMR oder AWS Glue.
- Speichern Sie verarbeitete Daten in Amazon S3 oder Amazon Redshift.
- Richten Sie die Automatisierung mithilfe von AWS Step Functions oder AWS Lambda für die Orchestrierung ein.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
20. ETL- und ELT-Operationen

Ziel
Entdecken Sie die Datenintegrationsansätze ETL (Extract, Transform, Load) und ELT (Extract, Load, Transform) auf AWS. Vergleichen Sie ihre Stärken und Schwächen in verschiedenen Szenarien. Dieses Projekt wird Erkenntnisse darüber liefern, wann die einzelnen Ansätze basierend auf spezifischen Data-Engineering-Anforderungen verwendet werden sollten.
Wie löst man?
- Implementieren Sie ETL-Prozesse mit AWS Glue für die Datentransformation und das Laden. Nutzen Sie AWS Data Pipeline oder AWS DMS (Database Migration Service) für ELT-Vorgänge.
- Speichern Sie Daten je nach Ansatz in Amazon S3, Amazon Redshift oder Amazon Aurora.
- Automatisieren Sie Datenworkflows mit AWS Step Functions oder AWS Lambda-Funktionen.
Klicken Sie hier, um den Quellcode für dieses Projekt zu erkunden.
Zusammenfassung
Data-Engineering-Projekte bieten eine unglaubliche Gelegenheit, in die Welt der Daten einzutauchen, ihre Leistungsfähigkeit zu nutzen und aussagekräftige Erkenntnisse zu gewinnen. Ganz gleich, ob Sie Pipelines für Echtzeit-Streaming-Daten aufbauen oder Lösungen für die Verarbeitung riesiger Datensätze entwickeln – diese Projekte schärfen Ihre Fähigkeiten und öffnen Türen zu spannenden Karriereaussichten.
Aber hören Sie hier nicht auf; Wenn Sie Ihre Data-Engineering-Reise auf die nächste Stufe bringen möchten, sollten Sie sich für unsere anmelden BlackBelt Plus-Programm. Mit BB+ erhalten Sie Zugang zu fachkundiger Anleitung, praktischer Erfahrung und einer unterstützenden Community und bringen Ihre Fähigkeiten im Bereich Data Engineering auf ein neues Niveau. Melde dich jetzt an!
Häufig gestellte Fragen
A. Data Engineering umfasst das Entwerfen, Konstruieren und Warten von Datenpipelines. Beispiel: Erstellen einer Pipeline zum Sammeln, Bereinigen und Speichern von Kundendaten zur Analyse.
A. Zu den Best Practices im Data Engineering gehören robuste Datenqualitätsprüfungen, effiziente ETL-Prozesse, Dokumentation und Skalierbarkeit für zukünftiges Datenwachstum.
A. Dateningenieure arbeiten an Aufgaben wie der Entwicklung von Datenpipelines, der Sicherstellung der Datengenauigkeit, der Zusammenarbeit mit Datenwissenschaftlern und der Fehlerbehebung bei datenbezogenen Problemen.
A. Um Data-Engineering-Projekte in einem Lebenslauf vorzustellen, Schlüsselprojekte hervorzuheben, verwendete Technologien zu erwähnen und die Auswirkungen auf Datenverarbeitungs- oder Analyseergebnisse zu quantifizieren.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/09/data-engineering-project/

