Viele Unternehmen migrieren ihre lokalen Datenspeicher in die AWS Cloud. Bei der Datenmigration besteht eine wichtige Anforderung darin, alle Daten zu validieren, die von der Quelle zum Ziel verschoben wurden. Diese Datenvalidierung ist ein kritischer Schritt und kann, wenn sie nicht korrekt durchgeführt wird, zum Scheitern des gesamten Projekts führen. Die Entwicklung benutzerdefinierter Lösungen zur Bestimmung der Migrationsgenauigkeit durch Vergleich der Daten zwischen Quelle und Ziel kann jedoch oft zeitaufwändig sein.
In diesem Beitrag gehen wir Schritt für Schritt durch einen Prozess zur Validierung großer Datensätze nach der Migration mithilfe eines konfigurationsbasierten Tools Amazon EMR und die Open-Source-Bibliothek Apache Griffin. Griffin ist eine Open-Source-Datenqualitätslösung für Big Data, die sowohl den Batch- als auch den Streaming-Modus unterstützt.
In der heutigen datengesteuerten Landschaft, in der Unternehmen mit Petabytes an Daten umgehen, wird der Bedarf an automatisierten Datenvalidierungs-Frameworks immer wichtiger. Manuelle Validierungsprozesse sind nicht nur zeitaufwändig, sondern auch fehleranfällig, insbesondere bei der Verarbeitung großer Datenmengen. Automatisierte Datenvalidierungs-Frameworks bieten eine optimierte Lösung, indem sie große Datensätze effizient vergleichen, Diskrepanzen identifizieren und die Datengenauigkeit im großen Maßstab sicherstellen. Mit solchen Frameworks können Unternehmen wertvolle Zeit und Ressourcen sparen und gleichzeitig das Vertrauen in die Integrität ihrer Daten aufrechterhalten, wodurch eine fundierte Entscheidungsfindung ermöglicht und die Gesamtbetriebseffizienz verbessert wird.
Die folgenden herausragenden Funktionen dieses Frameworks sind:
- Nutzt ein konfigurationsgesteuertes Framework
- Bietet Plug-and-Play-Funktionalität für eine nahtlose Integration
- Führt einen Zählvergleich durch, um eventuelle Unterschiede zu erkennen
- Implementiert robuste Datenvalidierungsverfahren
- Sichert die Datenqualität durch systematische Kontrollen
- Bietet Zugriff auf eine Datei mit nicht übereinstimmenden Datensätzen für eine eingehende Analyse
- Erstellt umfassende Berichte für Einblicke und Nachverfolgungszwecke
Lösungsüberblick
Diese Lösung verwendet die folgenden Dienste:
- Amazon Simple Storage-Service (Amazon S3) oder Hadoop Distributed File System (HDFS) als Quelle und Ziel.
- Amazon EMR um das PySpark-Skript auszuführen. Wir verwenden einen Python-Wrapper auf Griffin, um Daten zwischen Hadoop-Tabellen zu validieren, die über HDFS oder Amazon S3 erstellt wurden.
- AWS-Kleber um die technische Tabelle zu katalogisieren, in der die Ergebnisse des Griffin-Jobs gespeichert sind.
- Amazonas Athena um die Ausgabetabelle abzufragen und die Ergebnisse zu überprüfen.
Wir verwenden Tabellen, die die Anzahl für jede Quell- und Zieltabelle speichern und erstellen außerdem Dateien, die den Unterschied der Datensätze zwischen Quelle und Ziel anzeigen.
Das folgende Diagramm zeigt die Lösungsarchitektur.
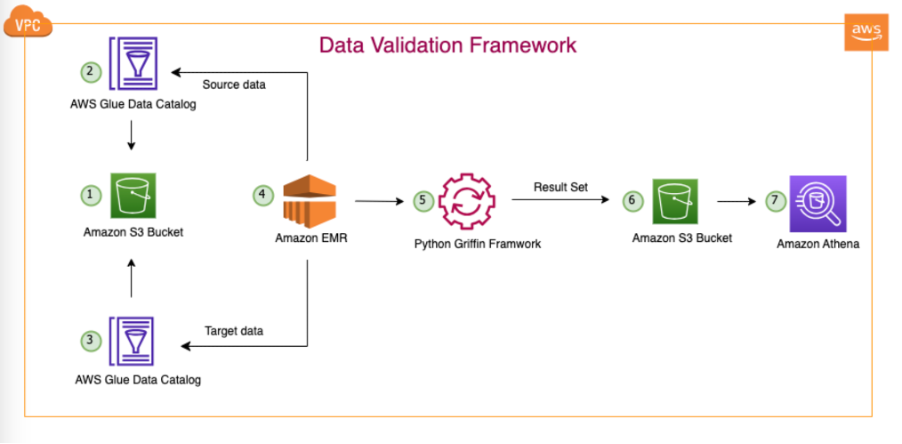
In der dargestellten Architektur und unserem typischen Data-Lake-Anwendungsfall befinden sich unsere Daten entweder in Amazon S3 oder werden mithilfe von Replikationstools wie z. B. von lokal nach Amazon S3 migriert AWS DataSync or AWS-Datenbankmigrationsservice (AWS DMS). Obwohl diese Lösung für die nahtlose Interaktion mit Hive Metastore und dem AWS Glue Data Catalog konzipiert ist, verwenden wir in diesem Beitrag den Data Catalog als Beispiel.
Dieses Framework arbeitet innerhalb von Amazon EMR und führt automatisch geplante Aufgaben täglich gemäß der definierten Häufigkeit aus. Es generiert und veröffentlicht Berichte in Amazon S3, die dann über Athena zugänglich sind. Ein bemerkenswertes Merkmal dieses Frameworks ist seine Fähigkeit, Zählungsinkongruenzen und Datendiskrepanzen zu erkennen. Darüber hinaus kann in Amazon S3 eine Datei mit vollständigen Datensätzen generiert werden, die nicht übereinstimmen, was die weitere Analyse erleichtert.
In diesem Beispiel verwenden wir drei Tabellen in einer lokalen Datenbank, um zwischen Quelle und Ziel zu validieren: balance_sheet, covid und survery_financial_report.
Voraussetzungen:
Stellen Sie vor dem Start sicher, dass Sie die folgenden Voraussetzungen haben:
Stellen Sie die Lösung bereit
Um Ihnen den Einstieg zu erleichtern, haben wir eine CloudFormation-Vorlage erstellt, die die Lösung automatisch für Sie konfiguriert und bereitstellt. Führen Sie die folgenden Schritte aus:
- Erstellen Sie in Ihrem AWS-Konto einen S3-Bucket mit dem Namen
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(Geben Sie Ihre AWS-Konto-ID und AWS-Region an). - Entpacken Sie Folgendes Datei zu Ihrem lokalen System.
- Nachdem Sie die Datei auf Ihr lokales System entpackt haben, ändern Sie sie zu der, die Sie in Ihrem Konto erstellt haben (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) in den folgenden Dateien:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Laden Sie alle Ordner und Dateien in Ihrem lokalen Ordner in Ihren S3-Bucket hoch:
- Führen Sie Folgendes aus CloudFormation-Vorlage in Ihrem Konto.
Die CloudFormation-Vorlage erstellt eine Datenbank namens griffin_datavalidation_blog und ein AWS Glue-Crawler namens griffin_data_validation_blog oben im Datenordner in der ZIP-Datei.
- Auswählen
Weiter.
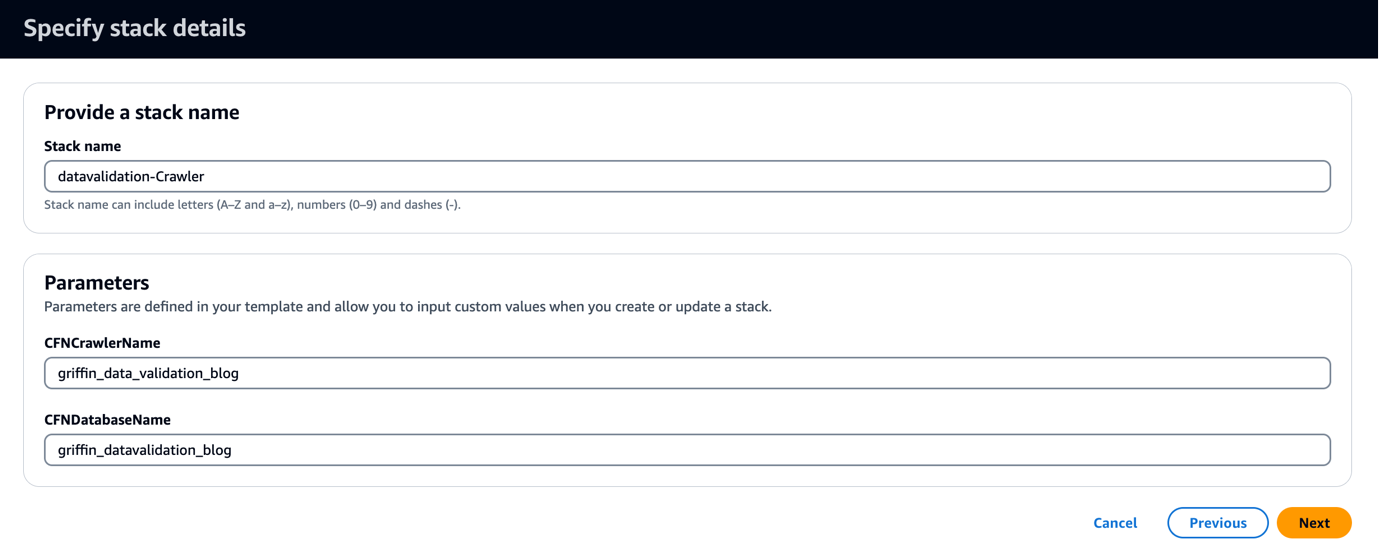
- Auswählen Weiter erneut.
- Auf dem Bewertung Seite auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen mit benutzerdefinierten Namen erstellt.
- Auswählen Stapel erstellen.
Du kannst dich Zeigen Sie die Stapelausgaben an auf die AWS-Managementkonsole oder indem Sie den folgenden AWS CLI-Befehl verwenden:
- Führen Sie den AWS Glue-Crawler aus und überprüfen Sie, ob im Datenkatalog sechs Tabellen erstellt wurden.
- Führen Sie Folgendes aus CloudFormation-Vorlage in Ihrem Konto.
Diese Vorlage erstellt einen EMR-Cluster mit einem Bootstrap-Skript zum Kopieren von Griffin-bezogenen JARs und Artefakten. Außerdem werden drei EMR-Schritte ausgeführt:
- Erstellen Sie zwei Athena-Tabellen und zwei Athena-Ansichten, um die vom Griffin-Framework erstellte Validierungsmatrix anzuzeigen
- Führen Sie eine Zählvalidierung für alle drei Tabellen durch, um die Quell- und Zieltabelle zu vergleichen
- Führen Sie Validierungen auf Datensatz- und Spaltenebene für alle drei Tabellen durch, um die Quell- und Zieltabelle zu vergleichen
- Aussichten für Subnetz-ID, geben Sie Ihre Subnetz-ID ein.
- Auswählen
Weiter.
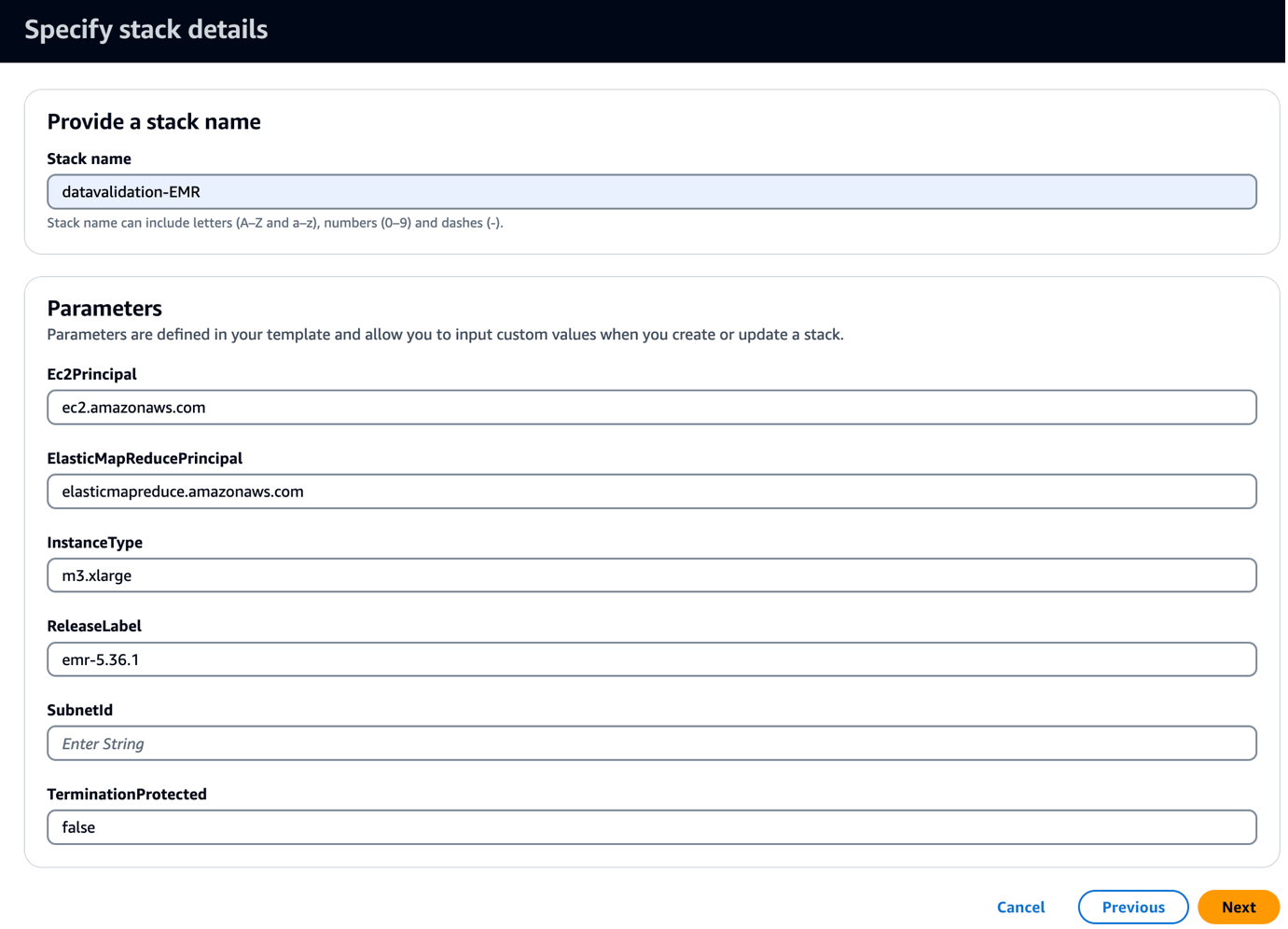
- Auswählen Weiter erneut.
- Auf dem Bewertung Seite auswählen Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen mit benutzerdefinierten Namen erstellt.
- Auswählen Stapel erstellen.
Sie können die Stack-Ausgaben auf der Konsole oder mit dem folgenden AWS CLI-Befehl anzeigen:
Es dauert etwa 5 Minuten, bis die Bereitstellung abgeschlossen ist. Wenn der Stapel vollständig ist, sollten Sie Folgendes sehen: EMRCluster Die Ressource wurde gestartet und ist in Ihrem Konto verfügbar.
Wenn der EMR-Cluster gestartet wird, führt er im Rahmen des Post-Cluster-Starts die folgenden Schritte aus:
- Bootstrap-Aktion – Es installiert die Griffin-JAR-Datei und die Verzeichnisse für dieses Framework. Außerdem werden Beispieldatendateien zur Verwendung im nächsten Schritt heruntergeladen.
- Athena_Table_Creation – Es erstellt Tabellen in Athena, um die Ergebnisberichte zu lesen.
- Count_Validation – Es führt den Job aus, um die Datenanzahl zwischen Quell- und Zieldaten aus der Datenkatalogtabelle zu vergleichen, und speichert die Ergebnisse in einem S3-Bucket, der über eine Athena-Tabelle gelesen wird.
- Genauigkeit – Es führt den Job aus, um die Datenzeilen zwischen den Quell- und Zieldaten aus der Data Catalog-Tabelle zu vergleichen und die Ergebnisse in einem S3-Bucket zu speichern, der über die Athena-Tabelle gelesen wird.
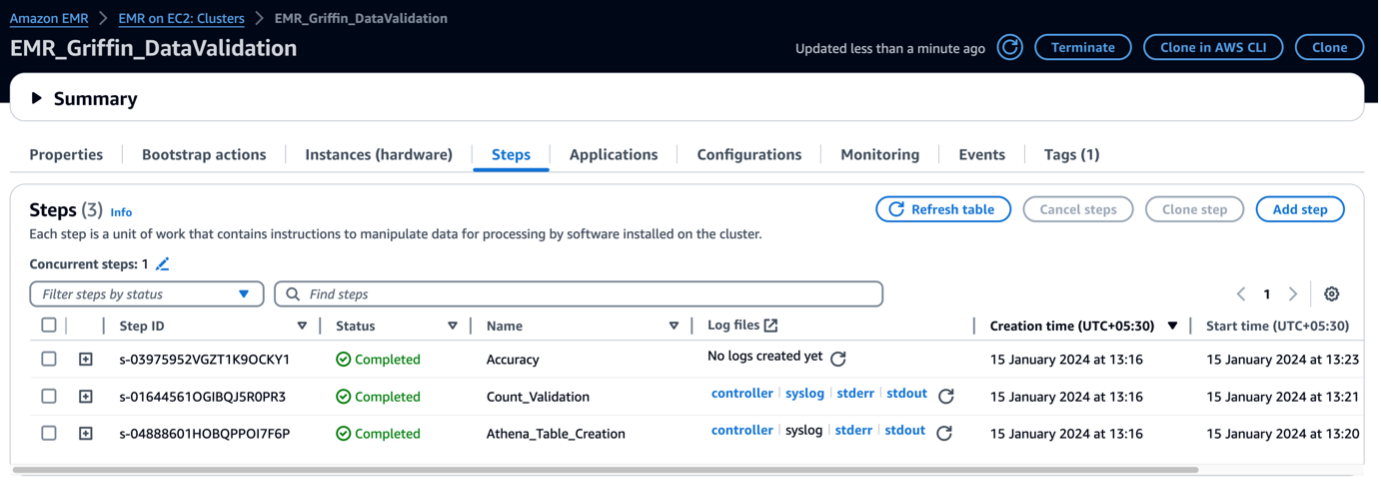
Wenn die EMR-Schritte abgeschlossen sind, ist Ihr Tabellenvergleich abgeschlossen und kann automatisch in Athena angezeigt werden. Für die Validierung ist kein manueller Eingriff erforderlich.
Validieren Sie Daten mit Python Griffin
Wenn Ihr EMR-Cluster bereit ist und alle Aufgaben abgeschlossen sind, bedeutet dies, dass die Zählungsvalidierung und die Datenvalidierung abgeschlossen sind. Die Ergebnisse wurden in Amazon S3 gespeichert und die Athena-Tabelle ist darauf bereits erstellt. Sie können die Athena-Tabellen abfragen, um die Ergebnisse anzuzeigen, wie im folgenden Screenshot gezeigt.
Der folgende Screenshot zeigt die Zählergebnisse für alle Tabellen.
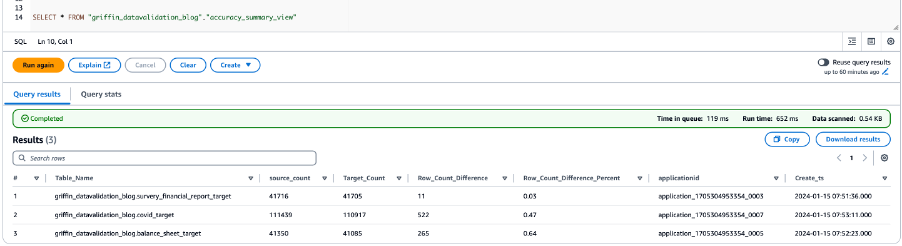
Der folgende Screenshot zeigt die Datengenauigkeitsergebnisse für alle Tabellen.
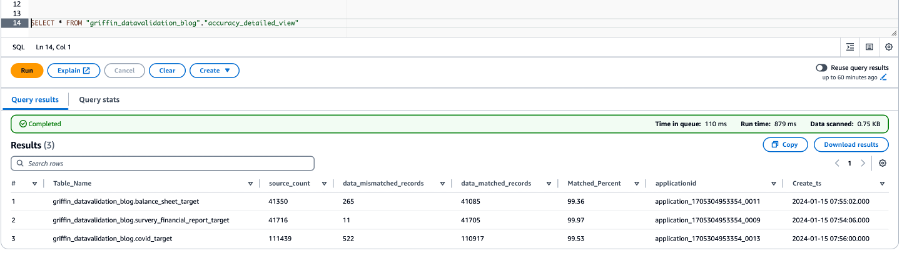
Der folgende Screenshot zeigt die für jede Tabelle erstellten Dateien mit nicht übereinstimmenden Datensätzen. Für jede Tabelle werden direkt aus dem Job heraus individuelle Ordner generiert.
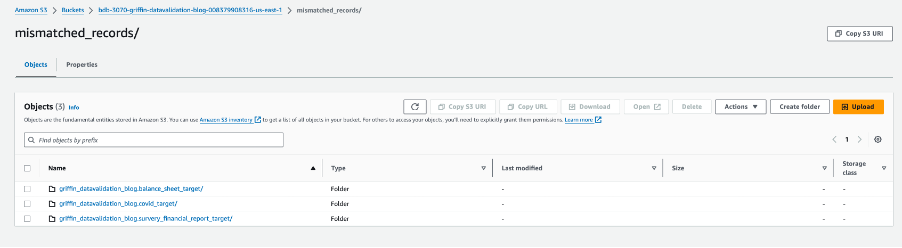
Jeder Tabellenordner enthält ein Verzeichnis für jeden Tag, an dem der Job ausgeführt wird.
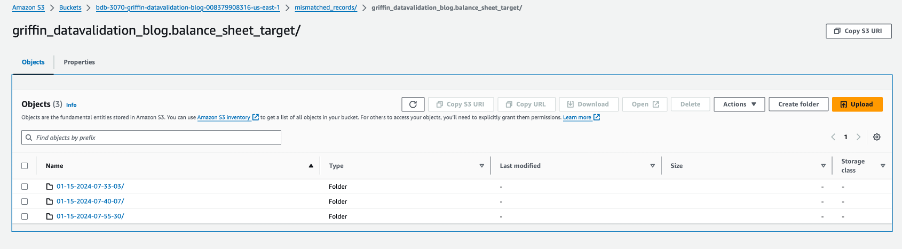
Innerhalb dieses bestimmten Datums wird eine Datei mit dem Namen __missRecords enthält Datensätze, die nicht übereinstimmen.

Der folgende Screenshot zeigt den Inhalt des __missRecords Datei.

Aufräumen
Um zu vermeiden, dass zusätzliche Kosten anfallen, führen Sie die folgenden Schritte aus, um Ihre Ressourcen zu bereinigen, wenn Sie mit der Lösung fertig sind:
- Löschen Sie die AWS Glue-Datenbank
griffin_datavalidation_blogund löschen Sie die Datenbankgriffin_datavalidation_blogKaskade. - Löschen Sie die von Ihnen erstellten Präfixe und Objekte aus dem Bucket
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Löschen Sie den CloudFormation-Stapel, wodurch Ihre zusätzlichen Ressourcen entfernt werden.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie Sie Python Griffin verwenden können, um den Datenvalidierungsprozess nach der Migration zu beschleunigen. Mit Python Griffin können Sie die Anzahl sowie die Validierung auf Zeilen- und Spaltenebene berechnen und nicht übereinstimmende Datensätze identifizieren, ohne Code schreiben zu müssen.
Weitere Informationen zu Anwendungsfällen für die Datenqualität finden Sie unter Erste Schritte mit AWS Glue Data Quality aus dem AWS Glue Data Catalog und AWS Glue-Datenqualität.
Über die Autoren
 Dipal Mahajan fungiert als leitender Berater bei Amazon Web Services und bietet globalen Kunden fachkundige Beratung bei der Entwicklung hochsicherer, skalierbarer, zuverlässiger und kosteneffizienter Cloud-Anwendungen. Mit seiner umfangreichen Erfahrung in den Bereichen Softwareentwicklung, Architektur und Analyse in verschiedenen Sektoren wie Finanzen, Telekommunikation, Einzelhandel und Gesundheitswesen bringt er unschätzbare Erkenntnisse in seine Rolle ein. Über den beruflichen Bereich hinaus erkundet Dipal gerne neue Reiseziele und hat bereits 14 der 30 Länder auf seiner Wunschliste besucht.
Dipal Mahajan fungiert als leitender Berater bei Amazon Web Services und bietet globalen Kunden fachkundige Beratung bei der Entwicklung hochsicherer, skalierbarer, zuverlässiger und kosteneffizienter Cloud-Anwendungen. Mit seiner umfangreichen Erfahrung in den Bereichen Softwareentwicklung, Architektur und Analyse in verschiedenen Sektoren wie Finanzen, Telekommunikation, Einzelhandel und Gesundheitswesen bringt er unschätzbare Erkenntnisse in seine Rolle ein. Über den beruflichen Bereich hinaus erkundet Dipal gerne neue Reiseziele und hat bereits 14 der 30 Länder auf seiner Wunschliste besucht.
 Achil ist leitender Berater bei AWS Professional Services. Er unterstützt Kunden beim Entwurf und Aufbau skalierbarer Datenanalyselösungen sowie bei der Migration von Datenpipelines und Data Warehouses zu AWS. In seiner Freizeit reist er gerne, spielt Spiele und schaut sich Filme an.
Achil ist leitender Berater bei AWS Professional Services. Er unterstützt Kunden beim Entwurf und Aufbau skalierbarer Datenanalyselösungen sowie bei der Migration von Datenpipelines und Data Warehouses zu AWS. In seiner Freizeit reist er gerne, spielt Spiele und schaut sich Filme an.
 Ramesh Raghupathy ist Senior Data Architect bei WWCO ProServe bei AWS. Er arbeitet mit AWS-Kunden zusammen, um Data Warehouses und Data Lakes in der AWS Cloud zu entwerfen, bereitzustellen und zu migrieren. Wenn er nicht bei der Arbeit ist, reist Ramesh gerne, verbringt Zeit mit der Familie und macht Yoga.
Ramesh Raghupathy ist Senior Data Architect bei WWCO ProServe bei AWS. Er arbeitet mit AWS-Kunden zusammen, um Data Warehouses und Data Lakes in der AWS Cloud zu entwerfen, bereitzustellen und zu migrieren. Wenn er nicht bei der Arbeit ist, reist Ramesh gerne, verbringt Zeit mit der Familie und macht Yoga.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

