You can ingest and integrate data from multiple Internet of Things (IoT) sensors to get insights. However, you may have to integrate data from multiple IoT sensor devices to derive analytics like equipment health information from all the sensors based on common data elements. Each of these sensor devices could be transmitting data with unique schemas and different attributes.
You can ingest data from all your IoT sensors to a central location on Amazon Simple Storage Service (Amazon S3). Schema evolution is a feature where a database table’s schema can evolve to accommodate for changes in the attributes of the files getting ingested. With the schema evolution functionality available in AWS Glue, Amazon Redshift Spectrum can automatically handle schema changes when new attributes get added or existing attributes get dropped. This is achieved with an AWS Glue crawler by reading schema changes based on the S3 file structures. The crawler creates a hybrid schema that works with both old and new datasets. You can read from all the ingested data files at a specified Amazon S3 location with different schemas through a single Amazon Redshift Spectrum table by referring to the AWS Glue metadata catalog.
In this post, we demonstrate how to use the AWS Glue schema evolution feature to read from multiple JSON formatted files with various schemas that are stored in a single Amazon S3 location. We also show how to query this data in Amazon S3 with Redshift Spectrum without redefining the schema or loading the data into Redshift tables.
Solution overview
The solution consists of the following steps:
- Create an Amazon Data Firehose delivery stream with Amazon S3 as its destination.
- Generate sample stream data from the Amazon Kinesis Data Generator (KDG) with the Firehose delivery stream as the destination.
- Upload the initial data files to the Amazon S3 location.
- Create and run an AWS Glue crawler to populate the Data Catalog with external table definition by reading the data files from Amazon S3.
- Create the external schema called
iotdb_extin Amazon Redshift and query the Data Catalog table. - Query the external table from Redshift Spectrum to read data from the initial schema.
- Add additional data elements to the KDG template and send the data to the Firehose delivery stream.
- Validate that the additional data files are loaded to Amazon S3 with additional data elements.
- Run an AWS Glue crawler to update the external table definitions.
- Query the external table from Redshift Spectrum again to read the combined dataset from two different schemas.
- Delete a data element from the template and send the data to the Firehose delivery stream.
- Validate that the additional data files are loaded to Amazon S3 with one less data element.
- Run an AWS Glue crawler to update the external table definitions.
- Query the external table from Redshift Spectrum to read the combined dataset from three different schemas.
This solution is depicted in the following architecture diagram.

Prerequisites
This solution requires the following prerequisites:
Implement the solution
Complete the following steps to build the solution:
- On the Kinesis console, create a Firehose delivery stream with the following parameters:
- For Source, choose Direct PUT.
- For Destination, choose Amazon S3.
- For S3 bucket, enter your S3 bucket.
- For Dynamic partitioning, select Enabled.

-
- Add the following dynamic partitioning keys:
- Key year with expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - Key month with expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - Key day with expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - Key hour with expression
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- Key year with expression
- Add the following dynamic partitioning keys:
-
- For S3 bucket prefix, enter
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- For S3 bucket prefix, enter

You can review your delivery stream details on the Kinesis Data Firehose console.
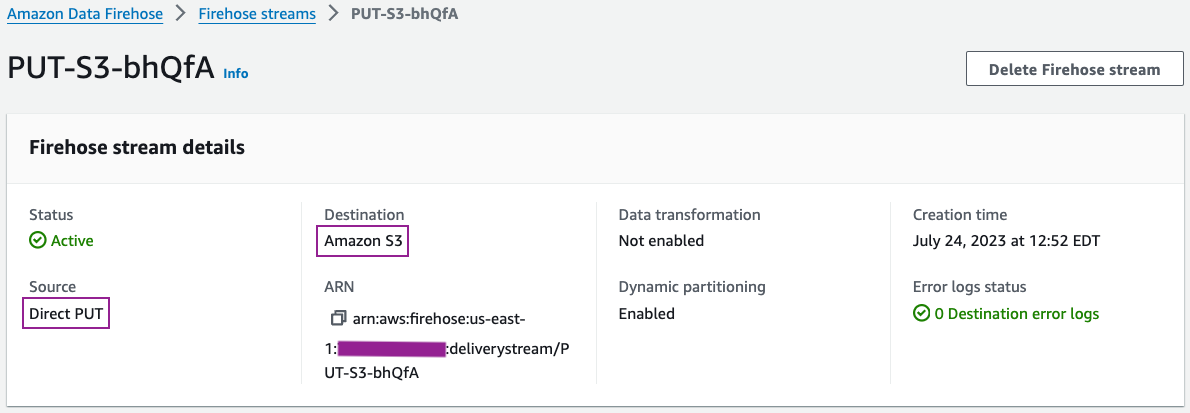
Your delivery stream configuration details should be similar to the following screenshot.

- Generate sample stream data from the KDG with the Firehose delivery stream as the destination with the following template:

- On the Amazon S3 console, validate that the initial set of files got loaded into the S3 bucket.
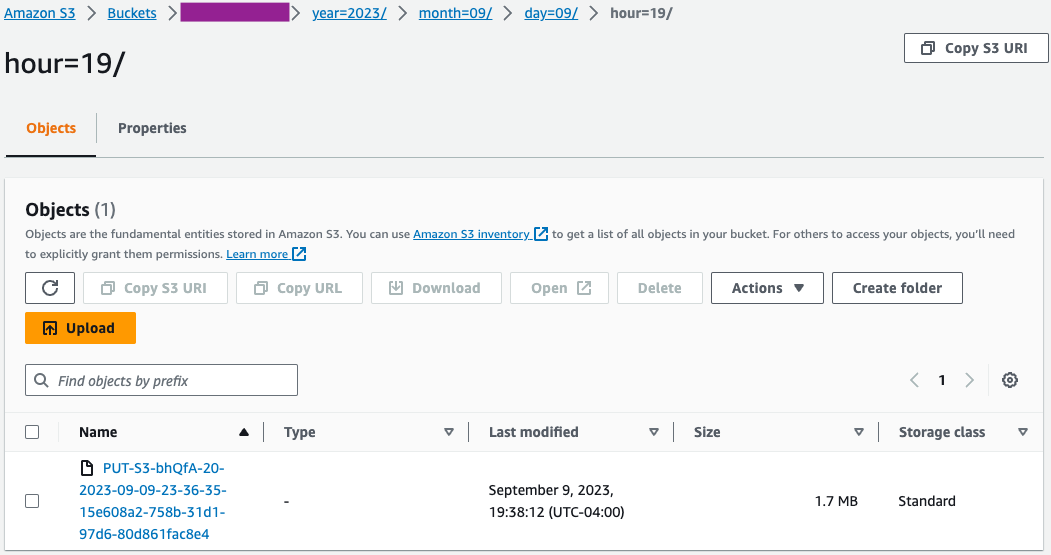
- On the AWS Glue console, create and run an AWS Glue Crawler with the data source as the S3 bucket that you used in the earlier step.
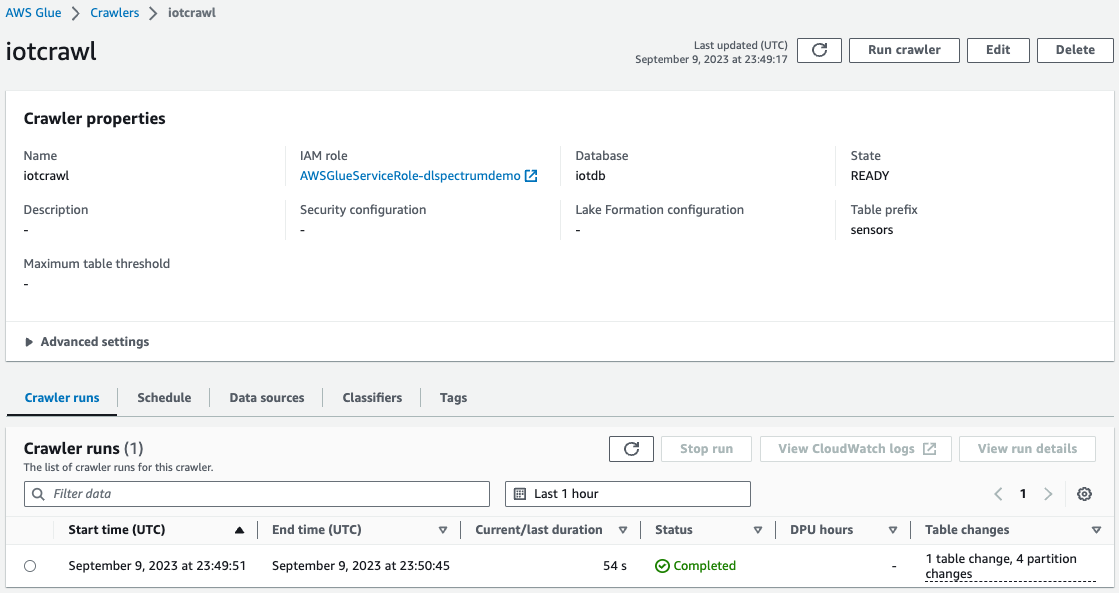
When the crawler is complete, you can validate that the table was created on the AWS Glue console.

Troubleshooting
If data is not loaded into Amazon S3 after sending it from the KDG template to the Firehose delivery stream, refresh and make sure you are logged in to the KDG.
Clean up
You may want to delete your S3 data and Redshift cluster if you are not planning to use it further to avoid unnecessary cost to your AWS account.
Conclusion
With the emergence of requirements for predictive and prescriptive analytics based on big data, there is a growing demand for data solutions that integrate data from multiple heterogeneous data models with minimal effort. In this post, we showcased how you can derive metrics from common atomic data elements from different data sources with unique schemas. You can store data from all the data sources in a common S3 location, either in the same folder or multiple subfolders by each data source. You can define and schedule an AWS Glue crawler to run at the same frequency as the data refresh requirements for your data consumption. With this solution, you can create a Redshift Spectrum table to read from an S3 location with varying file structures using the AWS Glue Data Catalog and schema evolution functionality.
If you have any questions or suggestions, please leave your feedback in the comment section. If you need further assistance with building analytics solutions with data from various IoT sensors, please contact your AWS account team.
About the Authors
 Swapna Bandla is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. Swapna has a passion towards understanding customers data and analytics needs and empowering them to develop cloud-based well-architected solutions. Outside of work, she enjoys spending time with her family.
Swapna Bandla is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. Swapna has a passion towards understanding customers data and analytics needs and empowering them to develop cloud-based well-architected solutions. Outside of work, she enjoys spending time with her family.
 Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

