基礎模型 (FM) 是在廣泛的未標記和廣義資料集上訓練的大型機器學習 (ML) 模型。顧名思義,FM 為建立更專業的下游應用程式提供了基礎,並且具有獨特的適應性。它們可以執行各種不同的任務,例如自然語言處理、影像分類、預測趨勢、分析情緒和回答問題。這種規模和通用適應性是 FM 與傳統 ML 模型的差異。 FM 是多模式的;它們處理不同的資料類型,例如文字、視訊、音訊和圖像。大型語言模型 (LLM) 是 FM 的一種,經過大量文字資料的預訓練,通常具有文字生成、智慧聊天機器人或摘要等應用用途。
流數據促進了多樣化和最新資訊的持續流動,增強了模型適應和產生更準確、與上下文相關的輸出的能力。這種流資料的動態整合使得 生成AI 應用程式能夠及時回應不斷變化的條件,提高其在各種任務中的適應性和整體性能。
為了更好地理解這一點,想像一個幫助旅行者預訂旅行的聊天機器人。在這種情況下,聊天機器人需要即時存取航空公司庫存、航班狀態、飯店庫存、最新價格變化等。這些數據通常來自第三方,開發人員需要找到一種方法來獲取這些數據並在數據發生變化時對其進行處理。
批次處理並不是最適合這種情況。當數據快速變化時,大量處理可能會導致聊天機器人使用過時的數據,向客戶提供不準確的信息,從而影響整體客戶體驗。然而,串流處理可以使聊天機器人存取即時數據並適應可用性和價格的變化,為客戶提供最佳指導並增強客戶體驗。
另一個例子是人工智慧驅動的可觀察性和監控解決方案,其中 FM 監控系統的即時內部指標並產生警報。當模型發現異常或異常指標值時,應立即產生警報並通知操作人員。然而,隨著時間的推移,這些重要數據的價值會顯著降低。理想情況下,這些通知應該在幾秒鐘內甚至在發生時收到。如果操作員在事件發生後幾分鐘或幾小時收到這些通知,則此類見解無法付諸實踐,並且可能失去其價值。您可以在其他行業(例如零售、汽車製造、能源和金融業)找到類似的用例。
在這篇文章中,我們討論為什麼資料流由於其實時性而成為生成式人工智慧應用程式的重要組成部分。我們討論 AWS 資料流服務的價值,例如 適用於Apache Kafka的Amazon託管流 (亞馬遜 MSK), Amazon Kinesis數據流, 適用於 Apache Flink 的 Amazon 託管服務和 亞馬遜 Kinesis 數據流水線 建構生成式人工智慧應用。
情境學習
法學碩士是用時間點資料進行訓練的,並且沒有在推理時存取新資料的固有能力。隨著新資料的出現,您將必須不斷微調或進一步訓練模型。這不僅是一個昂貴的操作,而且在實踐中也非常有限,因為新資料產生的速度遠遠超過了微調的速度。此外,法學碩士缺乏語境理解,僅依賴他們的訓練數據,因此容易產生幻覺。這意味著他們可以產生流暢、連貫、語法合理但實際上不正確的回應。它們也缺乏相關性、個性化和背景。
然而,法學碩士有能力從從上下文中收到的數據中學習,從而在不修改模型權重的情況下更準確地做出回應。這就是所謂的 情境學習,並可用於產生個人化答案或在組織策略的背景下提供準確的回應。
例如,在聊天機器人中,資料事件可能與不斷攝取流儲存引擎的航班和飯店庫存或價格變化有關。此外,使用串流處理器對資料事件進行過濾、豐富並轉換為可使用的格式。透過查詢最新快照,結果可供應用程式使用。快照透過串流處理不斷更新;因此,最新數據是在使用者提示模型的情況下提供的。這使得該模型能夠適應價格和可用性的最新變化。下圖說明了基本的情境學習工作流程。
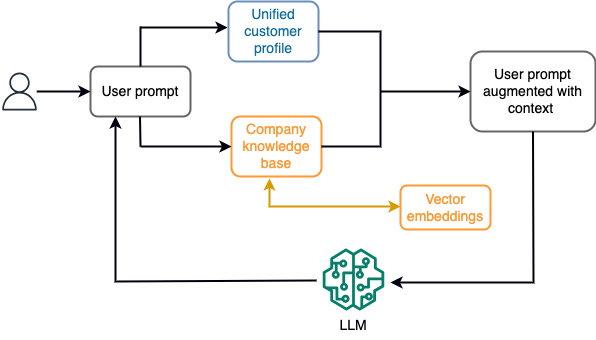
一種常用的情境學習方法是使用一種稱為檢索增強生成(RAG)的技術。在 RAG 中,您可以根據提示提供相關信息,例如最相關的政策和客戶記錄以及使用者問題。這樣,法學碩士可以使用作為上下文提供的附加資訊來產生使用者問題的答案。要了解有關 RAG 的更多信息,請參閱 在 Amazon SageMaker JumpStart 中使用帶有基礎模型的檢索增強生成來回答問題.
基於 RAG 的生成式人工智慧應用程式只能根據其訓練資料和知識庫中的相關文件產生通用回應。當期望應用程式提供近乎即時的個人化回應時,該解決方案就顯得不夠了。例如,旅行聊天機器人預計會考慮用戶當前的預訂、可用的飯店和航班庫存等。此外,相關客戶個人資料(俗稱 統一的客戶檔案)通常會發生變化。如果採用批次來更新產生人工智慧的使用者設定檔資料庫,客戶可能會收到基於舊資料的不滿意回應。
在這篇文章中,我們討論流程處理的應用,以增強 RAG 解決方案,該解決方案用於建立問答代理,其上下文來自即時存取統一的客戶資料和組織知識庫。
近乎即時的客戶資料更新
客戶記錄通常分佈在組織內的資料儲存中。為了讓您的生成式 AI 應用程式提供相關、準確且最新的客戶檔案,建立可以跨分散式資料儲存執行身分解析和檔案聚合的串流資料管道至關重要。流作業不斷攝取新資料以跨系統同步,並且可以更有效地跨時間視窗執行豐富、轉換、連接和聚合。變更資料擷取 (CDC) 事件包含有關來源記錄、更新和元資料的信息,例如時間、來源、分類(插入、更新或刪除)以及變更的發起者。
下圖說明了統一客戶設定檔的 CDC 串流擷取和處理的範例工作流程。

在本節中,我們將討論支援基於 RAG 的生成式 AI 應用程式所需的 CDC 流模式的主要元件。
CDC 流式攝取
CDC 複製器是一個從來源系統收集資料變更(通常透過讀取交易日誌或二進位日誌)並按照流資料流或主題中發生的完全相同的順序寫入 CDC 事件的進程。這涉及使用以下工具進行基於日誌的捕獲 AWS 數據庫遷移服務 (AWS DMS) 或開源連接器,例如用於 Apache Kafka 連接的 Debezium。 Apache Kafka Connect 是 Apache Kafka 環境的一部分,可從各種來源擷取資料並將資料傳送到各種目的地。您可以在以下位置執行 Apache Kafka 連接器 亞馬遜 MSK 連接 幾分鐘內即可完成,無需擔心設定、設定和執行 Apache Kafka 叢集。您只需要將連接器的編譯程式碼上傳到 亞馬遜簡單存儲服務 (Amazon S3) 並使用工作負載的特定配置設定連接器。
還有其他捕獲數據變化的方法。例如, 亞馬遜DynamoDB 提供將 CDC 資料串流傳輸到的功能 Amazon DynamoDB流 或 Kinesis 資料流。 Amazon S3 提供了一個觸發器來調用 AWS Lambda 儲存新文件時的功能。
串流儲存
流儲存充當中間緩衝區,用於在處理 CDC 事件之前對其進行儲存。串流儲存為串流資料提供可靠的儲存。根據設計,它具有高可用性,能夠適應硬體或節點故障,並在寫入事件時保持事件的順序。流儲存可以永久或在設定的時間段內儲存資料事件。這允許流處理器在發生故障或需要重新處理時讀取部分流。 Kinesis Data Streams 是一種無伺服器流資料服務,可輕鬆地大規模擷取、處理和儲存資料流。 Amazon MSK 是 AWS 提供的一項完全託管、高度可用且安全的服務,用於執行 Apache Kafka。
流處理
流處理系統應設計為並行性,以處理高資料吞吐量。他們應該在多個運算節點上運行的多個任務之間劃分輸入流。任務應該能夠透過網路將一項操作的結果傳送到下一項操作,從而可以在執行連接、過濾、豐富和聚合等操作時並行處理資料。對於事件可能延遲到達或正確計算依賴事件發生時間而不是系統時間的用例,流處理應用程式應該能夠根據事件時間來處理事件。欲了解更多信息,請參閱 時間概念:事件時間與處理時間.
流進程以資料事件的形式不斷產生需要輸出到目標系統的結果。目標系統可以是任何可以直接與流程整合或透過串流儲存作為中介整合的系統。根據您選擇的串流處理框架,您將為目標系統提供不同的選項,具體取決於可用的接收器連接器。如果您決定將結果寫入中間流存儲,則可以建立一個單獨的進程來讀取事件並將變更應用到目標系統,例如執行 Apache Kafka 接收器連接器。無論您選擇哪個選項,CDC 資料由於其性質都需要額外的處理。由於 CDC 事件攜帶有關更新或刪除的信息,因此它們以正確的順序合併到目標系統中非常重要。如果以錯誤的順序套用更改,目標系統將與其來源系統不同步。
阿帕奇弗林克 是一個強大的串流處理框架,以其低延遲和高吞吐量能力而聞名。它支援事件時間處理、一次性處理語意和高容錯能力。此外,它還透過稱為 CDC 資料的特殊結構提供本機支持 動態表。動態表模仿來源資料庫表並提供流資料的柱狀表示。動態表中的資料隨著處理的每個事件而變化。可以隨時新增、更新或刪除新記錄。動態表抽象化了您需要分別為每個記錄操作(插入、更新、刪除)實現的額外邏輯。欲了解更多信息,請參閱 動態表.
這款獨特的敏感免洗唇膜採用 Moisture WrapTM 技術和 Berry Mix ComplexTM 成分, 適用於 Apache Flink 的 Amazon 託管服務,您可以執行 Apache Flink 作業並與其他 AWS 服務整合。無需管理伺服器和集群,也無需設定運算和儲存基礎架構。
AWS膠水 是一項完全託管的提取、轉換和載入 (ETL) 服務,這表示 AWS 會為您處理基礎架構配置、擴充和維護。儘管 AWS Glue 主要以其 ETL 功能而聞名,但它也可用於 Spark 串流應用程式。 AWS Glue 可以與 Kinesis Data Streams 和 Amazon MSK 等串流資料服務交互,以處理和轉換 CDC 資料。 AWS Glue 還可以與其他 AWS 服務無縫集成,例如 Lambda、 AWS步驟功能和 DynamoDB,為您提供用於建置和管理資料處理管道的全面生態系統。
統一的客戶檔案
克服各種來源系統中客戶資料的統一需要開發強大的資料管道。您需要能夠將所有記錄匯入並同步到一個資料儲存中的資料管道。此資料儲存為您的組織提供全面的客戶記錄視圖,這是提高基於 RAG 的生成式 AI 應用程式的營運效率所需的。為了建構這樣的資料存儲,非結構化資料存儲是最好的。
身份圖是創建統一客戶檔案的有用結構,因為它整合和整合了來自各種來源的客戶數據,確保數據準確性和重複數據刪除,提供即時更新,連接跨系統見解,實現個性化,增強客戶體驗,並支持監管合規性。這種統一的客戶檔案使生成式人工智慧應用程式能夠有效地了解客戶並與客戶互動,並遵守資料隱私法規,最終增強客戶體驗並推動業務成長。您可以使用以下方式建立您的身份圖解決方案 亞馬遜海王星,一種快速、可靠、完全託管的圖形資料庫服務。
AWS 為非結構化鍵值物件提供了一些其他託管和無伺服器 NoSQL 儲存服務產品。 亞馬遜DocumentDB (與 MongoDB 相容)是一個快速、可擴展、高度可用且完全託管的企業 文檔數據庫 支援本機 JSON 工作負載的服務。 DynamoDB 是一種完全託管的 NoSQL 資料庫服務,可提供快速且可預測的效能以及無縫的可擴充性。
近乎即時的組織知識庫更新
與客戶記錄類似,公司政策和組織文件等內部知識儲存庫在儲存系統中是孤立的。這通常是非結構化數據,並以非增量方式更新。使用向量嵌入可以有效地將非結構化資料用於人工智慧應用,向量嵌入是一種將文字檔案、圖像和音訊檔案等高維度資料表示為多維數位的技術。
AWS 提供了多種 向量引擎服務如 亞馬遜 OpenSearch 無服務器, 亞馬遜肯德拉和 Amazon Aurora PostgreSQL 兼容版 使用 pgvector 擴充功能來儲存向量嵌入。生成式人工智慧應用程式可以透過將使用者提示轉換為向量並使用它來查詢向量引擎以檢索上下文相關資訊來增強用戶體驗。然後,提示和檢索到的向量資料都會傳遞給法學碩士,以接收更精確和個人化的回應。
下圖說明了向量嵌入的流程處理工作流程範例。
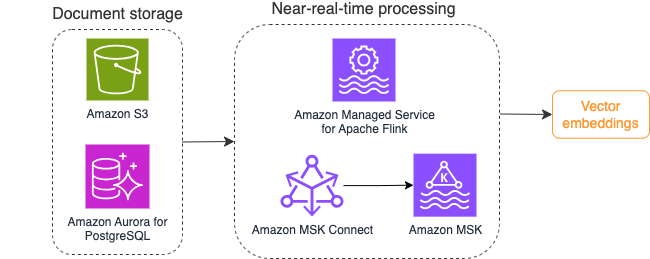
知識庫內容在寫入向量資料儲存之前需要轉換為向量嵌入。 亞馬遜基岩 or 亞馬遜SageMaker 可以幫助您存取您選擇的模型並公開此轉換的專用端點。此外,您可以使用 LangChain 等庫來與這些端點整合。建立批次處理可以幫助您將知識庫內容轉換為向量數據,並將其最初儲存在向量資料庫中。但是,您需要依靠一段時間間隔來重新處理文檔,以將向量資料庫與知識庫內容的變更同步。對於大量文檔,此過程可能效率低下。在這些時間間隔之間,您的生成式 AI 應用程式使用者將根據舊內容收到答案,或因為新內容尚未向量化而收到不準確的答案。
流處理是應對這些挑戰的理想解決方案。它最初根據現有文件產生事件,並進一步監視來源系統,並在文件變更事件發生時立即建立文件變更事件。這些事件可以儲存在串流儲存中並等待串流作業處理。流作業讀取這些事件,載入文件的內容,並將內容轉換為相關單字標記的陣列。每個令牌透過對嵌入 FM 的 API 呼叫進一步轉換為向量資料。結果透過接收器操作符傳送到向量記憶體進行儲存。
如果您使用 Amazon S3 儲存文檔,則可以基於 Lambda 的 S3 物件變更觸發器來建立事件來源架構。 Lambda 函數可以以所需的格式建立事件並將其寫入您的流儲存。
您也可以使用 Apache Flink 作為串流作業來執行。 Apache Flink 提供本機檔案系統來源連接器,它可以發現現有檔案並最初讀取其內容。之後,它可以持續監視您的檔案系統中的新檔案並捕獲其內容。此連接器支援從分散式檔案系統(例如 Amazon S3 或 HDFS)讀取純文字、Avro、CSV、Parquet 等格式的一組文件,並產生流記錄。作為一項完全託管的服務,Apache Flink 託管服務消除了部署和維護 Flink 作業的營運開銷,使您能夠專注於建置和擴展串流應用程式。透過無縫整合到 Amazon MSK 或 Kinesis Data Streams 等 AWS 串流服務中,它提供自動擴展、安全性和彈性等功能,為處理即時串流資料提供可靠且高效的 Flink 應用程式。
根據您的 DevOps 偏好,您可以選擇 Kinesis Data Streams 或 Amazon MSK 來儲存流記錄。 Kinesis Data Streams 簡化了建置和管理自訂串流資料應用程式的複雜性,讓您能夠專注於從資料中取得見解,而不是基礎架構維護。使用 Apache Kafka 的客戶通常會選擇 Amazon MSK,因為它在監控 AWS 環境中的 Apache Kafka 叢集方面具有簡單性、可擴展性和可靠性。作為一項完全託管的服務,Amazon MSK 承擔了與部署和維護 Apache Kafka 叢集相關的操作複雜性,使您能夠專注於建置和擴展流應用程式。
由於 RESTful API 整合適合此過程的性質,因此您需要一個框架,該框架透過 RESTful API 呼叫支援有狀態豐富模式,以追蹤故障並重試失敗的請求。 Apache Flink 又是一個可以以記憶體速度執行有狀態操作的框架。若要了解透過 Apache Flink 進行 API 呼叫的最佳方法,請參閱 適用於 Apache Flink 的 Amazon Kinesis Data Analytics 中的常見流數據豐富模式.
Apache Flink 提供本機接收器連接器,用於將資料寫入向量資料存儲,例如帶有 pgvector 的 Amazon Aurora for PostgreSQL 或 亞馬遜開放搜索服務 與VectorDB。或者,您可以將 Flink 作業的輸出(向量化資料)暫存在 MSK 主題或 Kinesis 資料流中。 OpenSearch 服務支援從 Kinesis 資料流或 MSK 主題進行本機擷取。欲了解更多信息,請參閱 引入 Amazon MSK 作為 Amazon OpenSearch 攝取的來源 和 從 Amazon Kinesis Data Streams 載入串流數據.
回饋分析與微調
對於資料營運經理和 AI/ML 開發人員來說,深入了解生成式 AI 應用程式和正在使用的 FM 的效能非常重要。為此,您需要建立資料管道,根據使用者回饋以及各種應用程式日誌和指標來計算重要的關鍵績效指標 (KPI) 資料。這些資訊有助於利害關係人即時了解 FM、應用程式的性能以及用戶對從您的應用程式獲得的支援品質的整體滿意度。您還需要收集並儲存對話歷史記錄,以便進一步微調您的 FM,以提高其執行特定領域任務的能力。
該用例非常適合流分析領域。您的應用程式應將每個對話儲存在串流儲存中。您的應用程式可以提示使用者對每個答案的準確性及其整體滿意度的評分。此數據可以採用二進制選擇或自由格式文字的格式。這些資料可以儲存在 Kinesis 資料流或 MSK 主題中,並進行處理以即時產生 KPI。您可以使用 FM 來進行使用者情緒分析。 FM 可以分析每個答案並分配使用者滿意度類別。
Apache Flink 的架構允許在時間視窗內進行複雜的資料聚合。它還提供對資料事件流上的 SQL 查詢的支援。因此,透過使用 Apache Flink,您可以透過撰寫熟悉的 SQL 查詢來快速分析原始使用者輸入並即時產生 KPI。欲了解更多信息,請參閱 表 API 和 SQL.
這款獨特的敏感免洗唇膜採用 Moisture WrapTM 技術和 Berry Mix ComplexTM 成分, 適用於 Apache Flink Studio 的 Amazon 託管服務,您可以在互動筆記本中使用標準 SQL、Python 和 Scala 建置和執行 Apache Flink 流程處理應用程式。 Studio Notebook 由 Apache Zeppelin 提供支持,並使用 Apache Flink 作為串流處理引擎。 Studio Notebook 無縫地結合了這些技術,使所有技能的開發人員都可以對資料流進行高級分析。透過支援使用者定義函數 (UDF),Apache Flink 允許建立自訂運算子來與 FM 等外部資源集成,以執行情緒分析等複雜任務。您可以使用 UDF 來計算各種指標或透過使用者情緒等其他見解來豐富使用者回饋原始資料。要了解有關此模式的更多信息,請參閱 使用 GenAI、Flink、Apache Kafka 和 Kinesis 主動即時解決客戶問題.
透過 Apache Flink Studio 託管服務,您可以一鍵將 Studio Notebook 部署為串流作業。您可以使用 Apache Flink 提供的本機接收器連接器將輸出傳送到您選擇的儲存空間或將其暫存在 Kinesis 資料流或 MSK 主題中。 亞馬遜Redshift 和 OpenSearch Service 都是儲存分析資料的理想選擇。這兩個引擎都透過單獨的流管道到資料湖或資料倉儲進行分析,提供從 Kinesis Data Streams 和 Amazon MSK 的本機提取支援。
Amazon Redshift 使用 SQL 分析資料倉儲和資料湖中的結構化和半結構化數據,並使用 AWS 設計的硬體和機器學習來大規模提供最佳性價比。 OpenSearch 服務提供由 OpenSearch Dashboards 和 Kibana(1.5 至 7.10 版本)支援的視覺化功能。
您可以將此類分析的結果與使用者提示資料結合起來,以便在需要時微調 FM。 SageMaker 是微調 FM 最直接的方法。將 Amazon S3 與 SageMaker 結合使用可提供強大且無縫的集成,以微調您的模型。 Amazon S3 是一種可擴展且持久的物件儲存解決方案,支援直接儲存和擷取大型資料集、訓練資料和模型工件。 SageMaker 是一項完全託管的 ML 服務,可簡化整個 ML 生命週期。透過使用 Amazon S3 作為 SageMaker 的儲存後端,您可以從 Amazon S3 的可擴充性、可靠性和成本效益,同時受益於 SageMaker 訓練和部署功能無縫整合。這種組合可實現高效的資料管理,促進協作模型開發,並確保機器學習工作流程的簡化和可擴展,最終增強機器學習流程的整體敏捷性和效能。欲了解更多信息,請參閱 使用 @remote 裝飾器在 Amazon SageMaker 上微調 Falcon 7B 和其他 LLM.
透過檔案系統接收器連接器,Apache Flink 作業可以將開放格式(例如 JSON、Avro、Parquet 等)檔案的資料作為資料物件傳送到 Amazon S3。如果您喜歡使用事務性資料湖框架(例如 Apache Hudi、Apache Iceberg 或 Delta Lake)來管理資料湖,所有這些框架都為 Apache Flink 提供了自訂連接器。如欲了解更多詳情,請參閱 使用 Amazon MSK Connect、Apache Flink 和 Apache Hudi 創建低延遲的源到數據湖管道.
總結
對於基於 RAG 模型的生成式 AI 應用程序,您需要考慮建立兩個資料儲存系統,並且需要建立資料操作以使它們與所有來源系統保持同步。傳統的批次作業不足以處理與生成式 AI 應用程式整合所需的資料的大小和多樣性。處理來源系統中的變更的延遲會導致回應不準確,並降低生成式 AI 應用程式的效率。資料流使您能夠從各種系統的各種資料庫中取得資料。它還允許您近乎即時地高效地轉換、豐富、連接和聚合多個來源的資料。資料流提供了簡化的資料架構來收集和轉換使用者對應用程式回應的即時反應或評論,幫助您交付結果並將其儲存在資料湖中以進行模型微調。資料流還可以透過僅處理變更事件來幫助您優化資料管道,使您能夠更快、更有效率地回應資料變更。
進一步了解 AWS資料流服務 並開始建立您自己的資料流解決方案。
關於作者
 阿里·阿萊米 是 AWS 的流媒體專家解決方案架構師。 Ali 為 AWS 客戶提供架構最佳實踐建議,並幫助他們設計可靠、安全、高效且具有成本效益的實時分析數據系統。 他從客戶的用例出發,設計數據解決方案來解決他們的業務問題。 在加入 AWS 之前,Ali 支持了多個公共部門客戶和 AWS 諮詢合作夥伴的應用程序現代化之旅和向雲的遷移。
阿里·阿萊米 是 AWS 的流媒體專家解決方案架構師。 Ali 為 AWS 客戶提供架構最佳實踐建議,並幫助他們設計可靠、安全、高效且具有成本效益的實時分析數據系統。 他從客戶的用例出發,設計數據解決方案來解決他們的業務問題。 在加入 AWS 之前,Ali 支持了多個公共部門客戶和 AWS 諮詢合作夥伴的應用程序現代化之旅和向雲的遷移。
 Imtiaz (Taz) 賽義德 是 AWS 的全球分析技術領導者。他喜歡與社區就所有數據和分析問題進行交流。可以透過以下方式聯絡他 LinkedIn.
Imtiaz (Taz) 賽義德 是 AWS 的全球分析技術領導者。他喜歡與社區就所有數據和分析問題進行交流。可以透過以下方式聯絡他 LinkedIn.

