Nhiều doanh nghiệp đang di chuyển kho dữ liệu tại chỗ của họ sang Đám mây AWS. Trong quá trình di chuyển dữ liệu, yêu cầu chính là xác thực tất cả dữ liệu đã được di chuyển từ nguồn sang đích. Xác thực dữ liệu này là một bước quan trọng và nếu không được thực hiện chính xác, có thể dẫn đến thất bại của toàn bộ dự án. Tuy nhiên, việc phát triển các giải pháp tùy chỉnh để xác định độ chính xác khi di chuyển bằng cách so sánh dữ liệu giữa nguồn và đích thường có thể tốn thời gian.
Trong bài đăng này, chúng tôi sẽ hướng dẫn quy trình từng bước để xác thực các tập dữ liệu lớn sau khi di chuyển bằng công cụ dựa trên cấu hình bằng cách sử dụng Amazon EMR và thư viện mã nguồn mở Apache Griffin. Griffin là một giải pháp chất lượng dữ liệu nguồn mở dành cho dữ liệu lớn, hỗ trợ cả chế độ hàng loạt và truyền phát.
Trong bối cảnh dựa trên dữ liệu ngày nay, nơi các tổ chức xử lý hàng petabyte dữ liệu, nhu cầu về khung xác thực dữ liệu tự động ngày càng trở nên quan trọng. Quá trình xác thực thủ công không chỉ tốn thời gian mà còn dễ xảy ra lỗi, đặc biệt khi xử lý khối lượng dữ liệu khổng lồ. Khung xác thực dữ liệu tự động cung cấp giải pháp hợp lý bằng cách so sánh hiệu quả các tập dữ liệu lớn, xác định sự khác biệt và đảm bảo độ chính xác của dữ liệu trên quy mô lớn. Với các khuôn khổ như vậy, các tổ chức có thể tiết kiệm thời gian và nguồn lực quý giá trong khi vẫn duy trì niềm tin vào tính toàn vẹn của dữ liệu, từ đó cho phép đưa ra quyết định sáng suốt và nâng cao hiệu quả hoạt động tổng thể.
Sau đây là các tính năng nổi bật của framework này:
- Sử dụng khung định hướng cấu hình
- Cung cấp chức năng plug-and-play để tích hợp liền mạch
- Tiến hành so sánh số lượng để xác định bất kỳ sự khác biệt nào
- Thực hiện các thủ tục xác thực dữ liệu mạnh mẽ
- Đảm bảo chất lượng dữ liệu thông qua kiểm tra có hệ thống
- Cung cấp quyền truy cập vào tệp chứa các bản ghi không khớp để phân tích chuyên sâu
- Tạo báo cáo toàn diện cho mục đích hiểu biết và theo dõi
Tổng quan về giải pháp
Giải pháp này sử dụng các dịch vụ sau:
- Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) hoặc Hệ thống tệp phân tán Hadoop (HDFS) làm nguồn và đích.
- Amazon EMR để chạy tập lệnh PySpark. Chúng tôi sử dụng trình bao bọc Python bên trên Griffin để xác thực dữ liệu giữa các bảng Hadoop được tạo qua HDFS hoặc Amazon S3.
- Keo AWS lập danh mục bảng kỹ thuật, nơi lưu trữ kết quả của công việc Griffin.
- amazon Athena để truy vấn bảng đầu ra để xác minh kết quả.
Chúng tôi sử dụng các bảng lưu trữ số lượng cho từng bảng nguồn và bảng đích, đồng thời tạo các tệp hiển thị sự khác biệt về số lượng bản ghi giữa nguồn và đích.
Sơ đồ sau minh họa kiến trúc giải pháp.
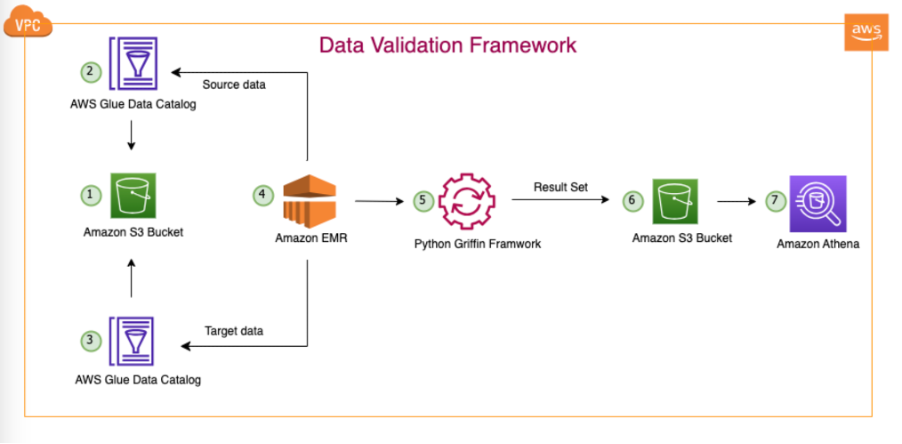
Trong kiến trúc được mô tả và trường hợp sử dụng hồ dữ liệu điển hình của chúng tôi, dữ liệu của chúng tôi nằm trên Amazon S3 hoặc được di chuyển từ cơ sở sang Amazon S3 bằng các công cụ sao chép như Đồng bộ dữ liệu AWS or Dịch vụ di chuyển cơ sở dữ liệu AWS (AWS DMS). Mặc dù giải pháp này được thiết kế để tương tác liền mạch với cả Hive Metastore và Danh mục dữ liệu AWS Glue, nhưng chúng tôi sử dụng Danh mục dữ liệu làm ví dụ trong bài đăng này.
Khung này hoạt động trong Amazon EMR, tự động chạy các tác vụ đã lên lịch hàng ngày theo tần suất đã xác định. Nó tạo và xuất bản các báo cáo trong Amazon S3, sau đó có thể truy cập được thông qua Athena. Một tính năng đáng chú ý của khung này là khả năng phát hiện số lượng không khớp và sự khác biệt về dữ liệu, ngoài việc tạo một tệp trong Amazon S3 chứa đầy đủ các bản ghi không khớp, tạo điều kiện thuận lợi cho việc phân tích sâu hơn.
Trong ví dụ này, chúng tôi sử dụng ba bảng trong cơ sở dữ liệu tại chỗ để xác thực giữa nguồn và đích: balance_sheet, covidvà survery_financial_report.
Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn có các điều kiện tiên quyết sau:
Triển khai giải pháp
Để giúp bạn bắt đầu dễ dàng, chúng tôi đã tạo mẫu CloudFormation tự động định cấu hình và triển khai giải pháp cho bạn. Hoàn thành các bước sau:
- Tạo nhóm S3 trong tài khoản AWS của bạn có tên là
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}(cung cấp ID tài khoản AWS và Khu vực AWS của bạn). - Giải nén phần sau hồ sơ đến hệ thống cục bộ của bạn.
- Sau khi giải nén tệp vào hệ thống cục bộ của bạn, hãy thay đổi vào tài khoản bạn đã tạo trong tài khoản của mình (
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}) trong các tệp sau:bootstrap-bdb-3070-datavalidation.shValidation_Metrics_Athena_tables.hqldatavalidation/totalcount/totalcount_input.txtdatavalidation/accuracy/accuracy_input.txt
- Tải tất cả các thư mục và tệp trong thư mục cục bộ lên vùng lưu trữ S3 của bạn:
- Chạy phần sau Mẫu CloudFormation vào tài khoản.
Mẫu CloudFormation tạo cơ sở dữ liệu có tên griffin_datavalidation_blog và trình thu thập thông tin AWS Glue có tên griffin_data_validation_blog ở đầu thư mục dữ liệu trong tệp .zip.
- Chọn Sau.
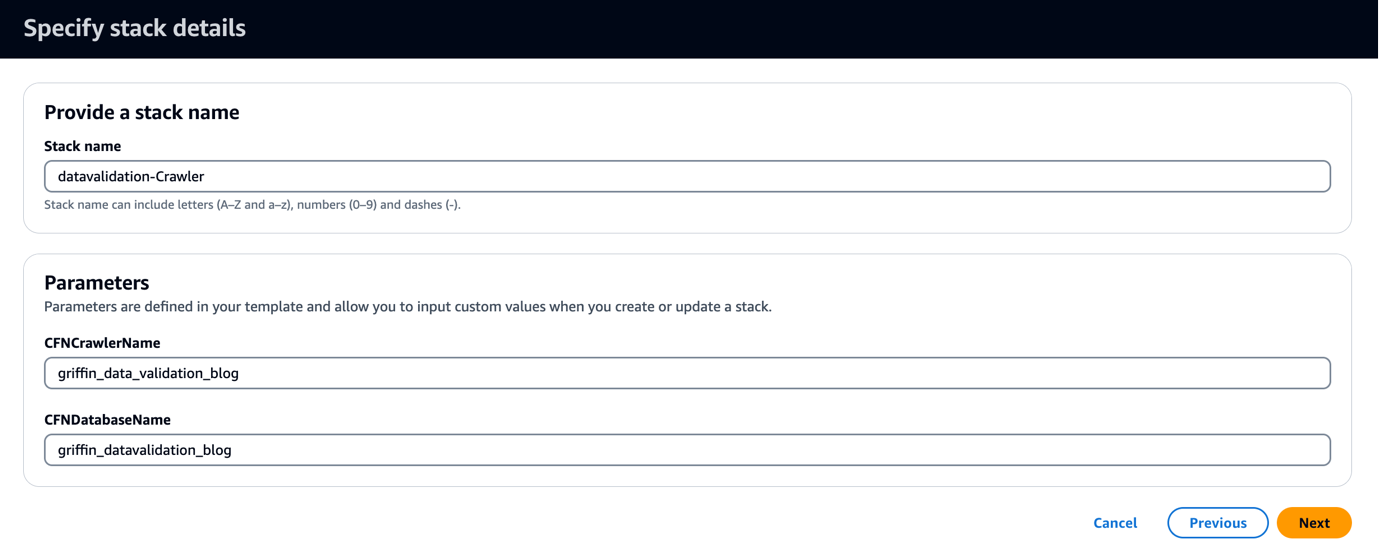
- Chọn Sau một lần nữa.
- trên Đánh giá trang, chọn Tôi xác nhận rằng AWS CloudFormation có thể tạo tài nguyên IAM với tên tùy chỉnh.
- Chọn Tạo ngăn xếp.
Bạn có thể xem đầu ra ngăn xếp trên Bảng điều khiển quản lý AWS hoặc bằng cách sử dụng lệnh AWS CLI sau:
- Chạy trình thu thập thông tin AWS Glue và xác minh rằng sáu bảng đã được tạo trong Danh mục dữ liệu.
- Chạy phần sau Mẫu CloudFormation vào tài khoản.
Mẫu này tạo một cụm EMR với tập lệnh khởi động để sao chép các JAR và tạo phẩm liên quan đến Griffin. Nó cũng chạy ba bước EMR:
- Tạo hai bảng Athena và hai chế độ xem Athena để xem ma trận xác thực do khung Griffin tạo ra
- Chạy xác thực số lượng cho cả ba bảng để so sánh bảng nguồn và bảng đích
- Chạy xác thực cấp bản ghi và cấp cột cho cả ba bảng để so sánh giữa bảng nguồn và bảng đích
- Trong ID mạng con, hãy nhập ID mạng con của bạn.
- Chọn Sau.
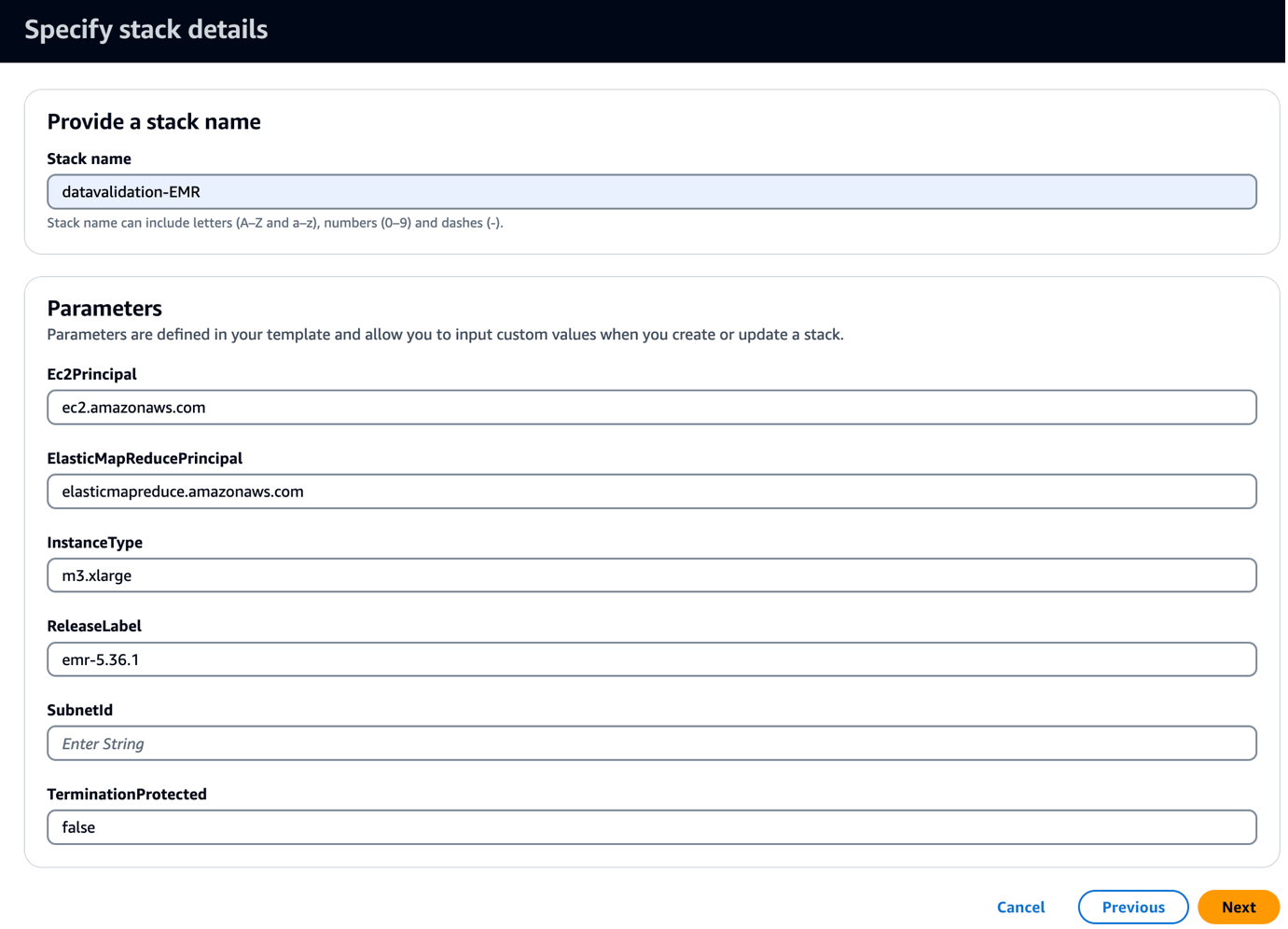
- Chọn Sau một lần nữa.
- trên Đánh giá trang, chọn Tôi xác nhận rằng AWS CloudFormation có thể tạo tài nguyên IAM với tên tùy chỉnh.
- Chọn Tạo ngăn xếp.
Bạn có thể xem kết quả đầu ra của ngăn xếp trên bảng điều khiển hoặc bằng cách sử dụng lệnh AWS CLI sau:
Mất khoảng 5 phút để quá trình triển khai hoàn tất. Khi ngăn xếp hoàn tất, bạn sẽ thấy EMRCluster tài nguyên được khởi chạy và có sẵn trong tài khoản của bạn.
Khi cụm EMR được khởi chạy, nó sẽ chạy các bước sau như một phần của quá trình khởi chạy sau cụm:
- Hành động khởi động – Nó cài đặt tệp và thư mục Griffin JAR cho khung này. Nó cũng tải xuống các tệp dữ liệu mẫu để sử dụng trong bước tiếp theo.
- Athena_Bảng_Sáng tạo – Nó tạo bảng trong Athena để đọc báo cáo kết quả.
- Đếm_Xác thực – Nó thực hiện công việc so sánh số lượng dữ liệu giữa dữ liệu nguồn và dữ liệu đích từ bảng Danh mục dữ liệu và lưu trữ kết quả trong bộ chứa S3, bộ chứa này sẽ được đọc qua bảng Athena.
- tính chính xác – Nó thực hiện công việc so sánh các hàng dữ liệu giữa dữ liệu nguồn và dữ liệu đích từ bảng Danh mục dữ liệu và lưu trữ kết quả trong bộ chứa S3, bộ chứa này sẽ được đọc qua bảng Athena.
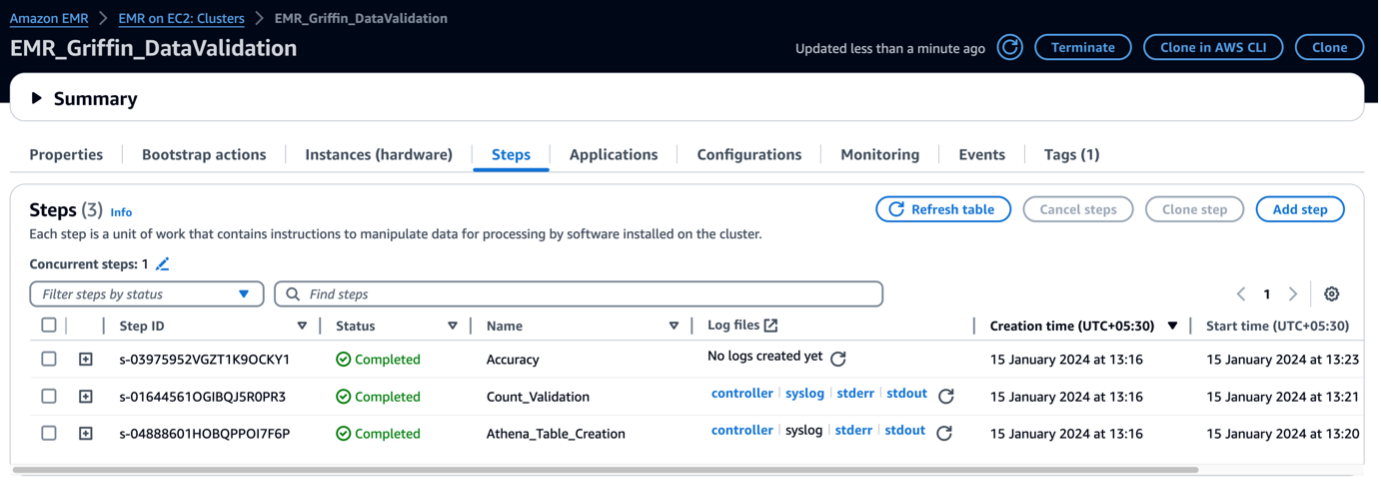
Khi các bước EMR hoàn tất, việc so sánh bảng của bạn đã hoàn tất và sẵn sàng tự động xem trong Athena. Không cần can thiệp thủ công để xác nhận.
Xác thực dữ liệu bằng Python Griffin
Khi cụm EMR của bạn đã sẵn sàng và tất cả công việc đã hoàn tất, điều đó có nghĩa là quá trình xác thực số lượng và xác thực dữ liệu đã hoàn tất. Kết quả đã được lưu trữ trong Amazon S3 và bảng Athena đã được tạo trên đó. Bạn có thể truy vấn các bảng Athena để xem kết quả, như minh họa trong ảnh chụp màn hình sau.
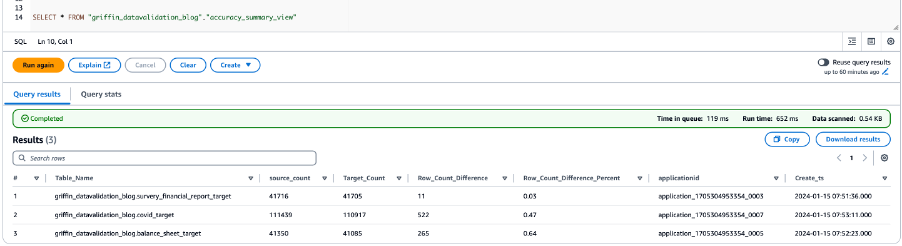
Ảnh chụp màn hình sau đây hiển thị kết quả đếm cho tất cả các bảng.
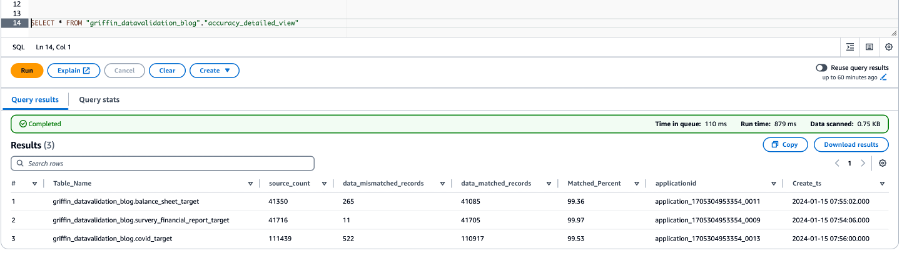
Ảnh chụp màn hình sau đây hiển thị kết quả độ chính xác của dữ liệu cho tất cả các bảng.
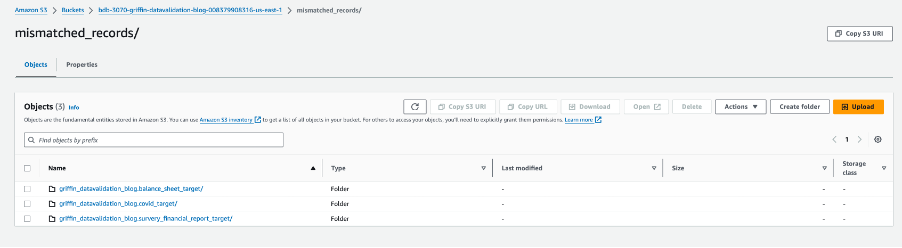
Ảnh chụp màn hình sau đây hiển thị các tệp được tạo cho mỗi bảng có bản ghi không khớp. Các thư mục riêng lẻ được tạo cho mỗi bảng trực tiếp từ công việc.
Mỗi thư mục bảng chứa một thư mục cho mỗi ngày công việc được thực hiện.
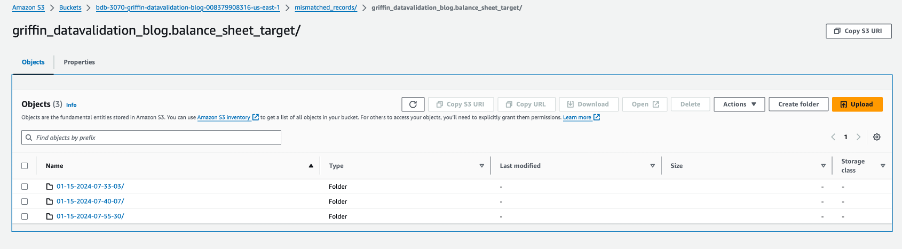
Trong ngày cụ thể đó, một tệp có tên __missRecords chứa các bản ghi không khớp.

Ảnh chụp màn hình sau đây hiển thị nội dung của __missRecords tập tin.

Làm sạch
Để tránh phát sinh thêm phí, hãy hoàn thành các bước sau để dọn sạch tài nguyên của bạn khi bạn thực hiện xong giải pháp:
- Xóa cơ sở dữ liệu AWS Glue
griffin_datavalidation_blogvà thả cơ sở dữ liệugriffin_datavalidation_blogthác. - Xóa tiền tố và đối tượng bạn đã tạo khỏi nhóm
bdb-3070-griffin-datavalidation-blog-${AWS::AccountId}-${AWS::Region}. - Xóa ngăn xếp CloudFormation, thao tác này sẽ xóa các tài nguyên bổ sung của bạn.
Kết luận
Bài đăng này cho thấy cách bạn có thể sử dụng Python Griffin để đẩy nhanh quá trình xác thực dữ liệu sau di chuyển. Python Griffin giúp bạn tính toán số lượng và xác thực cấp hàng và cột, xác định các bản ghi không khớp mà không cần viết bất kỳ mã nào.
Để biết thêm thông tin về các trường hợp sử dụng chất lượng dữ liệu, hãy tham khảo Bắt đầu với Chất lượng dữ liệu AWS Glue từ Danh mục dữ liệu AWS Glue và Chất lượng dữ liệu keo AWS.
Về các tác giả
 Dipal Mahajan đóng vai trò là Tư vấn chính tại Amazon Web Services, cung cấp hướng dẫn chuyên môn cho khách hàng toàn cầu trong việc phát triển các ứng dụng đám mây có độ bảo mật cao, có thể mở rộng, đáng tin cậy và tiết kiệm chi phí. Với bề dày kinh nghiệm trong phát triển phần mềm, kiến trúc và phân tích trên nhiều lĩnh vực khác nhau như tài chính, viễn thông, bán lẻ và chăm sóc sức khỏe, anh ấy đã mang đến những hiểu biết sâu sắc vô giá cho vai trò của mình. Ngoài lĩnh vực chuyên môn, Dipal thích khám phá những điểm đến mới, anh đã đến thăm 14 trên 30 quốc gia trong danh sách mong muốn của mình.
Dipal Mahajan đóng vai trò là Tư vấn chính tại Amazon Web Services, cung cấp hướng dẫn chuyên môn cho khách hàng toàn cầu trong việc phát triển các ứng dụng đám mây có độ bảo mật cao, có thể mở rộng, đáng tin cậy và tiết kiệm chi phí. Với bề dày kinh nghiệm trong phát triển phần mềm, kiến trúc và phân tích trên nhiều lĩnh vực khác nhau như tài chính, viễn thông, bán lẻ và chăm sóc sức khỏe, anh ấy đã mang đến những hiểu biết sâu sắc vô giá cho vai trò của mình. Ngoài lĩnh vực chuyên môn, Dipal thích khám phá những điểm đến mới, anh đã đến thăm 14 trên 30 quốc gia trong danh sách mong muốn của mình.
 Akhil là Chuyên gia tư vấn chính tại AWS Professional Services. Anh giúp khách hàng thiết kế và xây dựng các giải pháp phân tích dữ liệu có thể mở rộng cũng như di chuyển các đường dẫn dữ liệu và kho dữ liệu sang AWS. Khi rảnh rỗi, anh thích đi du lịch, chơi game và xem phim.
Akhil là Chuyên gia tư vấn chính tại AWS Professional Services. Anh giúp khách hàng thiết kế và xây dựng các giải pháp phân tích dữ liệu có thể mở rộng cũng như di chuyển các đường dẫn dữ liệu và kho dữ liệu sang AWS. Khi rảnh rỗi, anh thích đi du lịch, chơi game và xem phim.
 Ramesh Raghupathy là Kiến trúc sư dữ liệu cao cấp của WWCO ProServe tại AWS. Anh ấy làm việc với khách hàng AWS để kiến trúc, triển khai và di chuyển đến kho dữ liệu và hồ dữ liệu trên Đám mây AWS. Khi không làm việc, Ramesh thích đi du lịch, dành thời gian cho gia đình và tập yoga.
Ramesh Raghupathy là Kiến trúc sư dữ liệu cao cấp của WWCO ProServe tại AWS. Anh ấy làm việc với khách hàng AWS để kiến trúc, triển khai và di chuyển đến kho dữ liệu và hồ dữ liệu trên Đám mây AWS. Khi không làm việc, Ramesh thích đi du lịch, dành thời gian cho gia đình và tập yoga.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/automate-large-scale-data-validation-using-amazon-emr-and-apache-griffin/

