Giới thiệu
AI sáng tạo hiện đang được sử dụng rộng rãi trên toàn thế giới. Khả năng Mô hình ngôn ngữ lớn hiểu văn bản được cung cấp và tạo văn bản dựa trên đó đã dẫn đến nhiều ứng dụng từ Chatbots đến máy phân tích văn bản. Nhưng các Mô hình Ngôn ngữ Lớn này thường tạo ra văn bản nguyên gốc theo cách không có cấu trúc. Đôi khi, chúng tôi muốn đầu ra do LLM tạo ra ở định dạng cấu trúc, giả sử là định dạng JSON (Ký hiệu đối tượng JavaScript). Giả sử chúng ta đang phân tích một bài đăng trên mạng xã hội bằng cách sử dụng LLMvà chúng ta cần đầu ra do LLM tạo ra trong chính mã đó dưới dạng biến JSON/python để thực hiện một số tác vụ khác. Bạn có thể đạt được điều này với Rapid Engineering nhưng phải mất nhiều thời gian để mày mò các lời nhắc. Để giải quyết vấn đề này, LangChain đã giới thiệu Phân tích cú pháp đầu ra, có thể được sử dụng trong việc chuyển đổi bộ lưu trữ đầu ra LLM sang định dạng có cấu trúc.

Mục tiêu học tập
- Giải thích kết quả đầu ra được tạo ra bởi Mô hình ngôn ngữ lớn
- Tạo cấu trúc dữ liệu tùy chỉnh với Pydantic
- Hiểu tầm quan trọng của Mẫu lời nhắc và tạo một định dạng Đầu ra của LLM
- Tìm hiểu cách tạo hướng dẫn định dạng cho đầu ra LLM bằng LangChain
- Xem cách chúng tôi có thể phân tích dữ liệu JSON thành Đối tượng Pydantic
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
LangChain và phân tích đầu ra là gì?
LangChain là Thư viện Python cho phép bạn xây dựng các ứng dụng với Mô hình ngôn ngữ lớn ngay lập tức. Nó hỗ trợ nhiều mô hình khác nhau bao gồm OpenAI GPT LLM, PaLM của Googlevà thậm chí cả các mô hình nguồn mở có sẵn trong Ôm Mặt như Falcon, Llama, v.v. Với LangChain, việc tùy chỉnh Lời nhắc cho các Mô hình ngôn ngữ lớn thật dễ dàng và nó cũng đi kèm với một kho lưu trữ vectơ sẵn có, có thể lưu trữ các phần nhúng của đầu vào và đầu ra. Do đó, nó có thể được sử dụng để tạo các ứng dụng có thể truy vấn bất kỳ tài liệu nào trong vòng vài phút.
LangChain cho phép các Mô hình ngôn ngữ lớn truy cập thông tin từ internet thông qua các đại lý. Nó cũng cung cấp các trình phân tích cú pháp đầu ra, cho phép chúng tôi cấu trúc dữ liệu từ đầu ra do Mô hình ngôn ngữ lớn tạo ra. LangChain đi kèm với các Phân tích cú pháp đầu ra khác nhau như Trình phân tích cú pháp danh sách, Trình phân tích cú pháp ngày giờ, Trình phân tích cú pháp Enum, v.v. Trong bài viết này, chúng ta sẽ xem xét trình phân tích cú pháp JSON, cho phép chúng ta phân tích cú pháp đầu ra do LLM tạo ra thành định dạng JSON. Dưới đây, chúng ta có thể quan sát một luồng điển hình về cách phân tích cú pháp đầu ra LLM thành Đối tượng Pydantic, từ đó tạo ra dữ liệu sẵn sàng để sử dụng trong các biến Python

Bắt đầu – Thiết lập mô hình
Trong phần này, chúng tôi sẽ thiết lập mô hình với LangChain. Chúng tôi sẽ sử dụng PaLM làm Mô hình ngôn ngữ lớn trong suốt bài viết này. Chúng tôi sẽ sử dụng Google Colab cho môi trường của mình. Bạn có thể thay thế PaLM bằng bất kỳ Mô hình ngôn ngữ lớn nào khác. Trước tiên, chúng tôi sẽ bắt đầu bằng cách nhập các mô-đun được yêu cầu.
!pip install google-generativeai langchain- Thao tác này sẽ tải xuống thư viện LangChain và thư viện google-generativeai để làm việc với mô hình PaLM.
- Cần có thư viện langchain để tạo lời nhắc tùy chỉnh và phân tích đầu ra do các mô hình ngôn ngữ lớn tạo ra
- Thư viện google-generativeai sẽ cho phép chúng ta tương tác với mô hình PaLM của Google.
Khóa API PaLM
Để làm việc với PaLM, chúng tôi sẽ cần khóa API mà chúng tôi có thể nhận được bằng cách đăng ký trang web MakerSuite. Tiếp theo, chúng tôi sẽ nhập tất cả các thư viện cần thiết và chuyển Khóa API để khởi tạo mô hình PaLM.
import os
import google.generativeai as palm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.llms import GooglePalm os.environ['GOOGLE_API_KEY']= 'YOUR API KEY'
palm.configure(api_key=os.environ['GOOGLE_API_KEY']) llm = GooglePalm()
llm.temperature = 0.1 prompts = ["Name 5 planets and line about them"]
llm_result = llm._generate(prompts)
print(llm_result.generations[0][0].text)- Ở đây, trước tiên chúng tôi đã tạo một phiên bản của Google PaLM (Mô hình ngôn ngữ đường dẫn) và gán nó cho biến tôi
- Trong bước tiếp theo, chúng tôi thiết lập nhiệt độ của mô hình của chúng tôi thành 0.1, đặt nó ở mức thấp vì chúng tôi không muốn mô hình bị ảo giác
- Sau đó, chúng tôi tạo Lời nhắc dưới dạng danh sách và chuyển nó vào biến nhắc nhở
- Để chuyển lời nhắc tới PaLM, chúng tôi gọi ._phát ra() phương thức rồi chuyển danh sách Nhắc cho nó và kết quả được lưu trong biến llm_kết quả
- Cuối cùng, chúng ta in kết quả ở bước cuối cùng bằng cách gọi .các thế hệ và chuyển đổi nó thành văn bản bằng cách gọi .chữ phương pháp
Đầu ra cho lời nhắc này có thể được nhìn thấy bên dưới
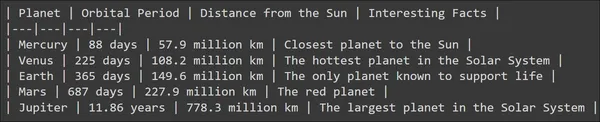
Chúng ta có thể thấy rằng Mô hình Ngôn ngữ Lớn đã tạo ra kết quả đầu ra hợp lý và LLM cũng đã cố gắng thêm một số cấu trúc vào đó bằng cách thêm một số dòng. Nhưng nếu tôi muốn lưu trữ thông tin của từng mô hình vào một biến thì sao? Điều gì sẽ xảy ra nếu tôi muốn lưu trữ tên hành tinh, chu kỳ quỹ đạo và khoảng cách từ mặt trời, tất cả những thứ này một cách riêng biệt trong một biến? Đầu ra do mô hình tạo ra không thể được xử lý trực tiếp để đạt được điều này. Do đó xuất hiện nhu cầu về Phân tích đầu ra.
Tạo mẫu nhắc nhở và trình phân tích cú pháp đầu ra Pydantic
Trong phần này, thảo luận về trình phân tích cú pháp đầu ra pydantic từ langchain. Ví dụ trước, đầu ra ở định dạng không có cấu trúc. Hãy xem cách chúng tôi có thể lưu trữ thông tin do Mô hình ngôn ngữ lớn tạo ra ở định dạng có cấu trúc.
Triển khai mã
Hãy bắt đầu bằng cách xem đoạn mã sau:
from pydantic import BaseModel, Field, validator
from langchain.output_parsers import PydanticOutputParser class PlanetData(BaseModel): planet: str = Field(description="This is the name of the planet") orbital_period: float = Field(description="This is the orbital period in the number of earth days") distance_from_sun: float = Field(description="This is a float indicating distance from sun in million kilometers") interesting_fact: str = Field(description="This is about an interesting fact of the planet")- Ở đây chúng tôi đang nhập Gói Pydantic để tạo Cấu trúc dữ liệu. Và trong Cấu trúc dữ liệu này, chúng tôi sẽ lưu trữ đầu ra bằng cách phân tích cú pháp đầu ra từ LLM.
- Ở đây chúng tôi đã tạo Cấu trúc dữ liệu bằng Pydantic được gọi là Dữ liệu hành tinh lưu trữ dữ liệu sau
- Hành tinh: Đây là tên hành tinh mà chúng tôi sẽ cung cấp làm đầu vào cho mô hình
- Chu kỳ quỹ đạo: Đây là giá trị nổi chứa chu kỳ quỹ đạo tính bằng ngày trên Trái đất của một hành tinh cụ thể.
- Khoảng cách từ mặt trời: Đây là một chiếc phao biểu thị khoảng cách từ một hành tinh đến Mặt trời
- Sự thật thú vị: Đây là một chuỗi chứa một thông tin thú vị về hành tinh được hỏi
Bây giờ, chúng tôi đặt mục tiêu truy vấn Mô hình ngôn ngữ lớn để biết thông tin về một hành tinh và lưu trữ tất cả dữ liệu này trong Cấu trúc dữ liệu hành tinh bằng cách phân tích cú pháp đầu ra LLM. Để phân tích đầu ra LLM thành Cấu trúc dữ liệu Pydantic, LangChain cung cấp một trình phân tích cú pháp có tên PydanticOutputParser. Chúng tôi chuyển Lớp PlanetData cho trình phân tích cú pháp này, có thể được định nghĩa như sau:
planet_parser = PydanticOutputParser(pydantic_object=PlanetData)Chúng tôi lưu trữ trình phân tích cú pháp trong một biến có tên hành tinh phân tích cú pháp. Đối tượng phân tích cú pháp có một phương thức gọi là get_format_instructions() cho LLM biết cách tạo đầu ra. Hãy thử in nó
from pprint import pp
pp(planet_parser.get_format_instructions())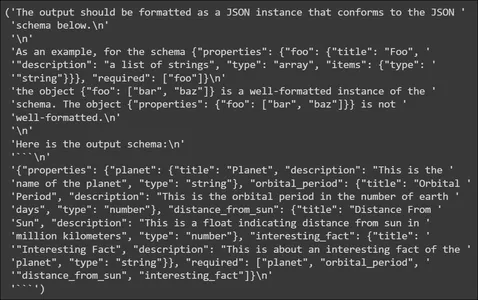
Ở phần trên, chúng ta thấy rằng các hướng dẫn định dạng chứa thông tin về cách định dạng đầu ra do LLM tạo ra. Nó yêu cầu LLM xuất dữ liệu theo lược đồ JSON, do đó JSON này có thể được phân tích cú pháp thành Cấu trúc dữ liệu Pydantic. Nó cũng cung cấp một ví dụ về lược đồ đầu ra. Tiếp theo, chúng ta sẽ tạo Mẫu nhắc nhở.
Mẫu lời nhắc
from langchain import PromptTemplate, LLMChain template_string = """You are an expert when it comes to answering questions about planets You will be given a planet name and you will output the name of the planet, it's orbital period in days Also it's distance from sun in million kilometers and an interesting fact ```{planet_name}``` {format_instructions} """ planet_prompt = PromptTemplate( template=template_string, input_variables=["planet_name"], partial_variables={"format_instructions": planet_parser
.get_format_instructions()}
)
- Trong Mẫu lời nhắc của chúng tôi, chúng tôi cho biết rằng chúng tôi sẽ đặt tên hành tinh làm đầu vào và LLM phải tạo đầu ra bao gồm thông tin như Chu kỳ quỹ đạo, Khoảng cách từ Mặt trời và một thông tin thú vị về hành tinh này
- Sau đó chúng tôi gán mẫu này cho Lời nhắcTemplate() và sau đó cung cấp tên biến đầu vào cho đầu vào_biến tham số, trong trường hợp của chúng tôi đó là tên_hành tinh
- Chúng tôi cũng cung cấp các hướng dẫn theo định dạng mà chúng tôi đã thấy trước đây, hướng dẫn này cho LLM biết cách tạo đầu ra ở định dạng JSON
Hãy thử đặt tên hành tinh và quan sát Lời nhắc trông như thế nào trước khi được gửi đến Mô hình Ngôn ngữ Lớn
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
pp(input_prompt.to_string())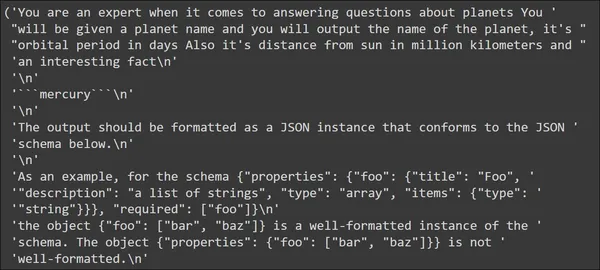
Trong đầu ra, chúng ta thấy rằng mẫu mà chúng ta đã xác định xuất hiện đầu tiên với đầu vào là “thủy ngân”. Tiếp theo đó là hướng dẫn định dạng. Các hướng dẫn định dạng này chứa các hướng dẫn mà LLM có thể sử dụng để tạo dữ liệu JSON.
Kiểm tra mô hình ngôn ngữ lớn
Trong phần này, chúng tôi sẽ gửi đầu vào của mình tới LLM và quan sát dữ liệu được tạo. Trong phần trước, hãy xem chuỗi đầu vào của chúng ta sẽ như thế nào khi được gửi đến LLM.
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
output = llm(input_prompt.to_string())
pp(output)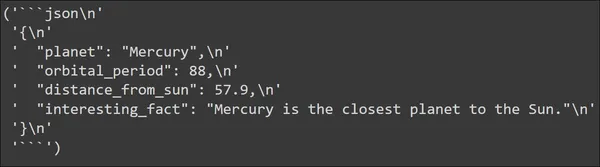
Chúng ta có thể thấy kết quả đầu ra do Mô hình ngôn ngữ lớn tạo ra. Đầu ra thực sự được tạo ở định dạng JSON. Dữ liệu JSON chứa tất cả các khóa mà chúng tôi đã xác định trong Cấu trúc dữ liệu PlanetData của mình. Và mỗi khóa có một giá trị mà chúng ta mong đợi nó có.
Bây giờ chúng ta phải phân tích dữ liệu JSON này thành Cấu trúc dữ liệu mà chúng ta đã thực hiện. Điều này có thể được thực hiện dễ dàng với PydanticOutputParser mà chúng ta đã xác định trước đó. Hãy nhìn vào mã đó:
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun(in Million KM): ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)Việc gọi phương thức phân tích cú pháp () cho hành tinh_parser, sẽ lấy đầu ra, sau đó phân tích cú pháp và chuyển đổi nó thành Đối tượng Pydantic, trong trường hợp của chúng ta là Đối tượng của PlanetData. Vì vậy, đầu ra, tức là JSON do Mô hình ngôn ngữ lớn tạo ra sẽ được phân tích cú pháp thành Cấu trúc dữ liệu PlannetData và giờ đây chúng ta có thể truy cập dữ liệu riêng lẻ từ nó. Đầu ra cho ở trên sẽ là

Chúng tôi thấy rằng các cặp khóa-giá trị từ dữ liệu JSON đã được phân tích cú pháp chính xác thành Dữ liệu Pydantic. Hãy thử với hành tinh khác và quan sát kết quả
input_prompt = planet_prompt.format_prompt(planet_name='venus')
output = llm(input_prompt.to_string()) parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun: ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)
Chúng tôi thấy rằng đối với đầu vào “Venus”, LLM có thể tạo JSON làm đầu ra và nó đã được phân tích thành công thành Dữ liệu Pydantic. Bằng cách này, thông qua phân tích cú pháp đầu ra, chúng tôi có thể sử dụng trực tiếp thông tin do Mô hình ngôn ngữ lớn tạo ra
Các ứng dụng tiềm năng và trường hợp sử dụng
Trong phần này, chúng ta sẽ xem xét một số ứng dụng/trường hợp sử dụng tiềm năng trong thế giới thực, nơi chúng ta có thể sử dụng các kỹ thuật phân tích cú pháp đầu ra này. Sử dụng Parsing trong trích xuất / sau khi trích xuất, tức là khi chúng ta trích xuất bất kỳ loại dữ liệu nào, chúng ta muốn phân tích cú pháp đó để thông tin được trích xuất có thể được sử dụng bởi các ứng dụng khác. Một số ứng dụng bao gồm:
- Khai thác và phân tích khiếu nại sản phẩm: Khi một thương hiệu mới tung ra thị trường và tung ra sản phẩm mới, điều đầu tiên họ muốn làm là kiểm tra xem sản phẩm đang hoạt động như thế nào và một trong những cách tốt nhất để đánh giá điều này là phân tích các bài đăng trên mạng xã hội của người tiêu dùng đang sử dụng các sản phẩm này. Trình phân tích cú pháp đầu ra và LLM cho phép trích xuất thông tin, chẳng hạn như tên thương hiệu và sản phẩm, thậm chí cả khiếu nại từ các bài đăng trên mạng xã hội của người tiêu dùng. Các Mô hình ngôn ngữ lớn này lưu trữ dữ liệu này trong các biến Pythonic thông qua phân tích cú pháp đầu ra, cho phép bạn sử dụng nó để trực quan hóa dữ liệu.
- Hỗ trợ khách hàng: Khi tạo chatbot bằng LLM để hỗ trợ khách hàng, một nhiệm vụ quan trọng sẽ là trích xuất thông tin từ lịch sử trò chuyện của khách hàng. Thông tin này chứa các chi tiết chính như những vấn đề mà người tiêu dùng gặp phải đối với sản phẩm/dịch vụ. Bạn có thể dễ dàng trích xuất các chi tiết này bằng trình phân tích cú pháp đầu ra LangChain thay vì tạo mã tùy chỉnh để trích xuất thông tin này
- Thông tin đăng tuyển: Khi phát triển các nền tảng tìm kiếm việc làm như Indeed, LinkedIn, v.v., chúng tôi có thể sử dụng LLM để trích xuất thông tin chi tiết từ các tin tuyển dụng, bao gồm chức danh, tên công ty, số năm kinh nghiệm và mô tả công việc. Phân tích cú pháp đầu ra có thể lưu thông tin này dưới dạng dữ liệu JSON có cấu trúc để khớp công việc và đề xuất. Việc phân tích cú pháp thông tin này từ đầu ra LLM trực tiếp thông qua Bộ phân tích cú pháp đầu ra LangChain sẽ loại bỏ nhiều mã dư thừa cần thiết để thực hiện thao tác phân tích cú pháp riêng biệt này.
Kết luận
Mô hình ngôn ngữ lớn rất tuyệt vời vì chúng có thể phù hợp với mọi trường hợp sử dụng theo đúng nghĩa đen nhờ khả năng tạo văn bản đặc biệt của chúng. Nhưng hầu hết họ thường thiếu sót khi thực sự sử dụng đầu ra được tạo ra, trong đó chúng ta phải dành một lượng thời gian đáng kể để phân tích cú pháp đầu ra. Trong bài viết này, chúng tôi đã xem xét vấn đề này và cách chúng tôi có thể giải quyết nó bằng cách sử dụng Trình phân tích cú pháp đầu ra từ LangChain, đặc biệt là trình phân tích cú pháp JSON có thể phân tích dữ liệu JSON được tạo từ LLM và chuyển đổi nó thành Đối tượng Pydantic.
Chìa khóa chính
Một số điểm chính rút ra từ bài viết này bao gồm:
- LangChain là Thư viện Python có thể tạo các ứng dụng với Mô hình ngôn ngữ lớn hiện có.
- LangChain cung cấp Trình phân tích cú pháp đầu ra cho phép chúng tôi phân tích đầu ra do Mô hình ngôn ngữ lớn tạo ra.
- Pydantic cho phép chúng tôi xác định Cấu trúc dữ liệu tùy chỉnh, có thể được sử dụng trong khi phân tích cú pháp đầu ra từ LLM.
- Ngoài trình phân tích cú pháp JSON Pydantic, LangChain còn cung cấp các Trình phân tích cú pháp đầu ra khác nhau như Trình phân tích cú pháp danh sách, Trình phân tích cú pháp ngày giờ, Trình phân tích cú pháp Enum, v.v.
Những câu hỏi thường gặp
A. JSON, từ viết tắt của Ký hiệu đối tượng JavaScript, là một định dạng cho dữ liệu có cấu trúc. Nó chứa dữ liệu ở dạng cặp khóa-giá trị.
A. Pydantic là thư viện Python tạo cấu trúc dữ liệu tùy chỉnh và thực hiện xác thực dữ liệu. Nó xác minh xem mỗi phần dữ liệu có khớp với loại được chỉ định hay không, từ đó xác thực dữ liệu được cung cấp.
A. Thực hiện việc này với Nhắc kỹ thuật, trong đó việc sửa đổi Lời nhắc có thể khiến chúng tôi tạo ra LLM tạo dữ liệu JSON làm đầu ra. Để đơn giản hóa quá trình này, LangChain có Trình phân tích cú pháp đầu ra và bạn có thể sử dụng cho tác vụ này.
A. Trình phân tích cú pháp đầu ra trong LangChain cho phép chúng tôi định dạng đầu ra do Mô hình ngôn ngữ lớn tạo ra theo cách có cấu trúc. Điều này cho phép chúng tôi dễ dàng truy cập thông tin từ Mô hình ngôn ngữ lớn cho các tác vụ khác.
A. LangChain đi kèm với các trình phân tích cú pháp đầu ra khác nhau như Pydantic Parser, List Parsr, Enum Parser, Datetime Parser, v.v.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/11/structured-llm-output-storage-and-parsing-in-python/

