Hình ảnh của Tác giả
Việc sử dụng quy trình Scikit-learn có thể đơn giản hóa các bước tiền xử lý và lập mô hình của bạn, giảm độ phức tạp của mã, đảm bảo tính nhất quán trong quá trình tiền xử lý dữ liệu, trợ giúp điều chỉnh siêu tham số, đồng thời giúp quy trình làm việc của bạn có tổ chức hơn và dễ bảo trì hơn. Bằng cách tích hợp nhiều phép biến đổi và mô hình cuối cùng vào một thực thể duy nhất, Pipelines nâng cao khả năng tái tạo và làm cho mọi thứ hiệu quả hơn.
Trong hướng dẫn này, chúng ta sẽ làm việc với Ngân hàng rời bỏ tập dữ liệu từ Kaggle để huấn luyện Bộ phân loại rừng ngẫu nhiên. Chúng tôi sẽ so sánh cách tiếp cận thông thường về xử lý trước dữ liệu và đào tạo mô hình với một phương pháp hiệu quả hơn bằng cách sử dụng quy trình Scikit-learn và ColumnTransformers.
Trong quy trình xử lý dữ liệu, chúng ta sẽ tìm hiểu cách chuyển đổi cả cột phân loại và cột số riêng lẻ. Chúng tôi sẽ bắt đầu với kiểu mã truyền thống và sau đó trình bày cách tốt hơn để thực hiện quá trình xử lý tương tự.
Sau khi trích xuất dữ liệu từ tệp zip, hãy tải tệp `train.csv` có “id” làm cột chỉ mục. Bỏ các cột không cần thiết và xáo trộn tập dữ liệu.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()
Chúng tôi có các cột phân loại, số nguyên và float. Tập dữ liệu trông khá sạch sẽ.

Mã Scikit-learn đơn giản
Là một nhà khoa học dữ liệu, tôi đã viết mã này nhiều lần. Mục tiêu của chúng tôi là điền vào các giá trị còn thiếu cho cả đặc điểm phân loại và số. Để đạt được điều này, chúng tôi sẽ sử dụng `SimpleImputer` với các chiến lược khác nhau cho từng loại tính năng.
Sau khi điền các giá trị còn thiếu, chúng tôi sẽ chuyển đổi các đặc điểm phân loại thành số nguyên và áp dụng tỷ lệ tối thiểu-tối đa cho các đặc điểm số.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
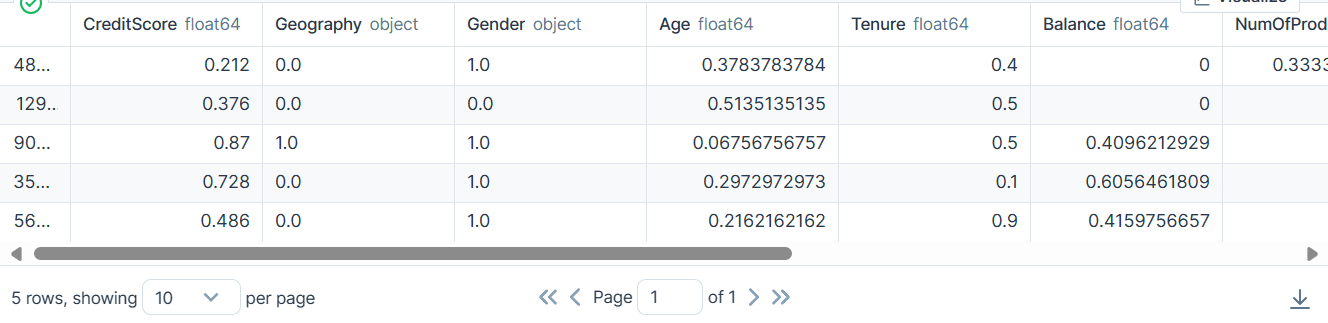
bank_df.head()
Kết quả là chúng tôi có được một tập dữ liệu sạch và được chuyển đổi chỉ với các giá trị số nguyên hoặc số float.
Mã quy trình Scikit-learn
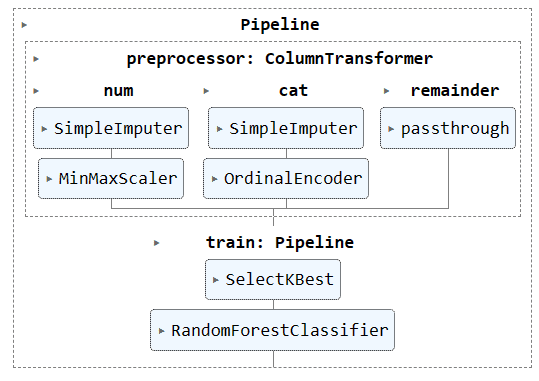
Hãy chuyển đổi đoạn mã trên bằng cách sử dụng `Pipeline` và `ColumnTransformer`. Thay vì áp dụng kỹ thuật tiền xử lý, chúng ta sẽ tạo hai đường ống. Một dành cho cột số và một dành cho cột phân loại.
- Trong quy trình số, chúng tôi đã sử dụng một phép tính đơn giản với chiến lược “trung bình” và áp dụng bộ chia tỷ lệ tối thiểu-tối đa để chuẩn hóa.
- Trong quy trình phân loại, chúng tôi đã sử dụng máy tính đơn giản với chiến lược “most_frequent” và bộ mã hóa ban đầu để chuyển đổi các danh mục thành giá trị số.
Chúng tôi đã kết hợp hai quy trình bằng cách sử dụng ColumnTransformer và cung cấp chỉ mục cột cho mỗi quy trình. Nó sẽ giúp bạn áp dụng các đường ống này trên các cột nhất định. Ví dụ: đường ống biến áp phân loại sẽ chỉ được áp dụng cho cột 1 và 2.
Lưu ý: phần còn lại=”passthrough” có nghĩa là các cột chưa được xử lý sẽ được thêm vào cuối cùng. Trong trường hợp của chúng tôi, đó là cột mục tiêu.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Sau khi chuyển đổi, mảng kết quả chứa giá trị biến đổi số ở đầu và giá trị biến đổi phân loại ở cuối, dựa trên thứ tự của các đường ống trong máy biến áp cột.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
Bạn có thể chạy đối tượng đường ống trong Notebook Jupyter để trực quan hóa đường ống. Đảm bảo bạn có phiên bản Scikit-learn mới nhất.
preproc_pipe

Để đào tạo và đánh giá mô hình của chúng tôi, chúng tôi cần chia tập dữ liệu thành hai tập hợp con: đào tạo và thử nghiệm.
Để làm điều này, trước tiên chúng ta sẽ tạo các biến phụ thuộc và độc lập rồi chuyển đổi chúng thành mảng NumPy. Sau đó, chúng ta sẽ sử dụng hàm `train_test_split` để chia tập dữ liệu thành hai tập hợp con.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Mã Scikit-learn đơn giản
Cách viết mã đào tạo thông thường trước tiên là thực hiện lựa chọn tính năng bằng cách sử dụng `SelectKBest` và sau đó cung cấp tính năng mới cho mô hình Phân loại rừng ngẫu nhiên của chúng tôi.
Trước tiên, chúng tôi sẽ huấn luyện mô hình bằng tập huấn luyện và đánh giá kết quả bằng tập dữ liệu thử nghiệm.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
Chúng tôi đã đạt được điểm chính xác khá tốt.
0.8613035487063481Mã quy trình Scikit-learn
Hãy sử dụng chức năng `Pipeline` để kết hợp cả hai bước đào tạo thành một đường ống. Sau đó, chúng ta có thể điều chỉnh mô hình trên tập huấn luyện và đánh giá nó trên tập thử nghiệm.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
Chúng tôi đã đạt được kết quả tương tự nhưng mã có vẻ hiệu quả và đơn giản hơn. Việc thêm hoặc xóa các bước mới khỏi quy trình đào tạo khá dễ dàng.
0.8613035487063481
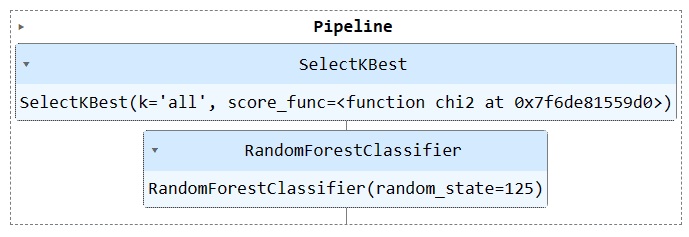
Chạy đối tượng đường ống để trực quan hóa đường ống.
train_pipe
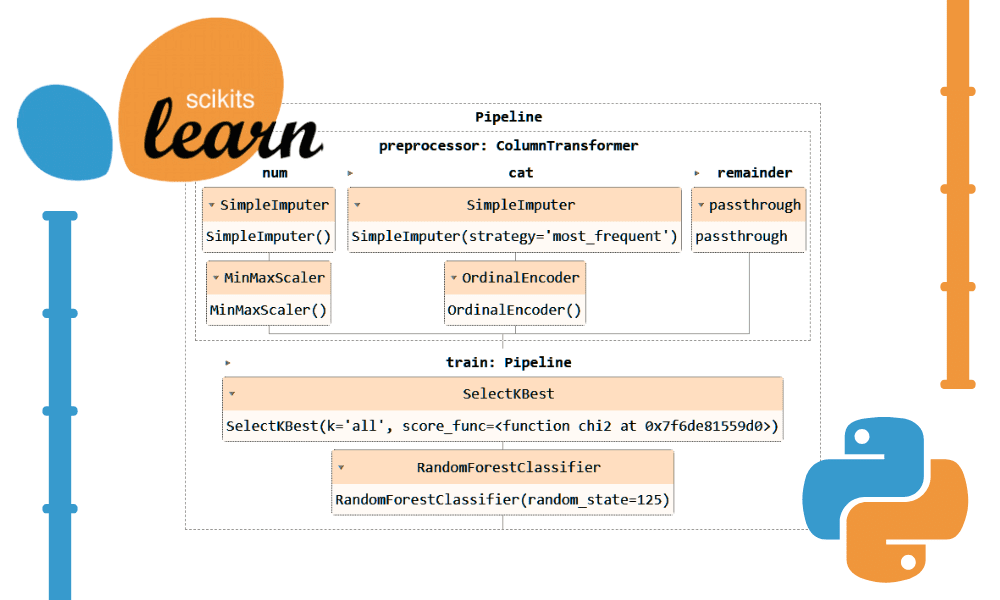
Bây giờ, chúng ta sẽ kết hợp cả quy trình tiền xử lý và quy trình đào tạo bằng cách tạo một quy trình khác và thêm cả hai quy trình.
Đây là mã hoàn chỉnh:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Đầu ra:
0.8592837955201874
Hình dung đường ống hoàn chỉnh.
complete_pipe

Một trong những ưu điểm chính của việc sử dụng đường ống là bạn có thể lưu đường ống bằng mô hình. Trong quá trình suy luận, bạn chỉ cần tải đối tượng đường ống, đối tượng này sẽ sẵn sàng xử lý dữ liệu thô và cung cấp cho bạn các dự đoán chính xác. Bạn không cần phải viết lại các chức năng xử lý và chuyển đổi trong tệp ứng dụng vì nó sẽ hoạt động tốt. Điều này làm cho quy trình học máy hiệu quả hơn và tiết kiệm thời gian.
Trước tiên hãy lưu đường dẫn bằng cách sử dụng skops-dev/skops thư viện.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Sau đó, tải đường dẫn đã lưu và hiển thị đường dẫn.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Như chúng ta có thể thấy, chúng ta đã tải đường ống thành công.
Để đánh giá quy trình đã tải của chúng tôi, chúng tôi sẽ đưa ra dự đoán trên bộ kiểm tra, sau đó tính toán độ chính xác và điểm F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
Hóa ra chúng ta cần tập trung vào các tầng lớp thiểu số để cải thiện điểm F1 của mình.
Accuracy: 86.0% F1: 0.76
Các tập tin dự án và mã có sẵn trên Không gian làm việc Deepnote. Không gian làm việc có hai Sổ ghi chép: Một có quy trình tìm hiểu Scikit và một không có quy trình này.
Trong hướng dẫn này, chúng ta đã tìm hiểu cách quy trình Scikit-learn có thể giúp hợp lý hóa quy trình công việc học máy bằng cách xâu chuỗi các chuỗi biến đổi dữ liệu và mô hình lại với nhau. Bằng cách kết hợp tiền xử lý và đào tạo mô hình vào một đối tượng Pipeline duy nhất, chúng tôi có thể đơn giản hóa mã, đảm bảo chuyển đổi dữ liệu nhất quán, đồng thời làm cho quy trình công việc của chúng tôi có tổ chức và có thể tái tạo hơn.
Abid Ali Awan (@ 1abidaliawan) là một nhà khoa học dữ liệu chuyên nghiệp được chứng nhận, người yêu thích việc xây dựng các mô hình học máy. Hiện tại, anh đang tập trung sáng tạo nội dung và viết blog kỹ thuật về công nghệ máy học và khoa học dữ liệu. Abid có bằng Thạc sĩ về Quản lý Công nghệ và bằng cử nhân về Kỹ thuật Viễn thông. Tầm nhìn của ông là xây dựng một sản phẩm AI bằng cách sử dụng mạng nơ-ron đồ thị cho những sinh viên đang chống chọi với bệnh tâm thần.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

