Một bản ghi nhớ bị rò rỉ của Google cung cấp một bản tóm tắt từng điểm về lý do tại sao Google thua AI nguồn mở và gợi ý con đường trở lại sự thống trị và sở hữu nền tảng này.
Bản ghi nhớ mở đầu bằng cách thừa nhận đối thủ cạnh tranh của họ chưa bao giờ là OpenAI và sẽ luôn là Nguồn mở.
Không thể cạnh tranh với nguồn mở
Hơn nữa, họ thừa nhận rằng họ không có vị trí nào để cạnh tranh với nguồn mở, thừa nhận rằng họ đã thua trong cuộc đấu tranh giành sự thống trị của AI.
Họ viết:
“Chúng tôi đã xem xét rất nhiều về OpenAI. Ai sẽ vượt qua cột mốc tiếp theo? Động thái tiếp theo sẽ là gì?
Nhưng sự thật khó chịu là, chúng tôi không ở vị trí để giành chiến thắng trong cuộc chạy đua vũ trang này và OpenAI cũng vậy. Trong khi chúng tôi đang cãi nhau, một phe thứ ba đã lặng lẽ ăn bữa trưa của chúng tôi.
Tất nhiên, tôi đang nói về mã nguồn mở.
Nói một cách rõ ràng, họ đang đánh bại chúng tôi. Những thứ mà chúng tôi coi là “vấn đề mở lớn” đã được giải quyết và nằm trong tay mọi người ngày nay.”
Phần lớn bản ghi nhớ được dành để mô tả cách Google bị mã nguồn mở qua mặt.
Và mặc dù Google có một chút lợi thế so với nguồn mở, nhưng tác giả của bản ghi nhớ thừa nhận rằng nó đang tuột dốc và sẽ không bao giờ quay trở lại.
Quá trình tự phân tích các quân bài ẩn dụ mà họ đã tự xử lý là khá lạc quan:
“Mặc dù các mẫu xe của chúng tôi vẫn có lợi thế hơn một chút về chất lượng, nhưng khoảng cách đang được thu hẹp nhanh chóng một cách đáng kinh ngạc.
Các mô hình nguồn mở nhanh hơn, có thể tùy chỉnh nhiều hơn, riêng tư hơn và có nhiều khả năng hơn.
Họ đang làm mọi thứ với thông số 100 đô la và 13 tỷ đô la mà chúng tôi gặp khó khăn ở mức 10 triệu đô la và 540 tỷ đô la.
Và họ đang làm như vậy trong vài tuần chứ không phải vài tháng.”
Kích thước mô hình ngôn ngữ lớn không phải là một lợi thế
Có lẽ nhận thức ớn lạnh nhất được thể hiện trong bản ghi nhớ là quy mô của Google không còn là một lợi thế nữa.
Kích thước lớn bất thường của các mô hình của họ hiện được coi là nhược điểm chứ không phải là lợi thế không thể vượt qua mà họ nghĩ.
Bản ghi nhớ bị rò rỉ liệt kê một loạt các sự kiện báo hiệu quyền kiểm soát AI của Google (và OpenAI) có thể nhanh chóng kết thúc.
Nó kể lại rằng chỉ một tháng trước, vào tháng 2023 năm XNUMX, cộng đồng nguồn mở đã nhận được một mô hình ngôn ngữ lớn mô hình nguồn mở bị rò rỉ do Meta phát triển có tên là LLaMA.
Trong vòng vài ngày và vài tuần, cộng đồng nguồn mở toàn cầu đã phát triển tất cả các bộ phận xây dựng cần thiết để tạo các bản sao Bard và ChatGPT.
Các bước tinh vi như điều chỉnh hướng dẫn và học tăng cường từ phản hồi của con người (RLHF) đã nhanh chóng được cộng đồng nguồn mở toàn cầu nhân rộng với giá rẻ không hơn không kém.
- điều chỉnh hướng dẫn
Một quá trình tinh chỉnh một mô hình ngôn ngữ để làm cho nó thực hiện điều gì đó cụ thể mà ban đầu nó không được huấn luyện để làm. - Học tăng cường từ phản hồi của con người (RLHF)
Một kỹ thuật trong đó con người đánh giá đầu ra của một mô hình ngôn ngữ để nó biết được đầu ra nào làm hài lòng con người.
RLHF là kỹ thuật được OpenAI sử dụng để tạo InstructGPT, là một mô hình nằm dưới ChatGPT và cho phép các mô hình GPT-3.5 và GPT-4 nhận hướng dẫn và hoàn thành tác vụ.
RLHF là ngọn lửa mà nguồn mở đã lấy từ
Quy mô nguồn mở khiến Google sợ hãi
Điều đặc biệt khiến Google lo sợ là thực tế là phong trào Nguồn mở có thể mở rộng quy mô các dự án của họ theo cách mà nguồn đóng không thể.
Bộ dữ liệu câu hỏi và câu trả lời được sử dụng để tạo bản sao ChatGPT mã nguồn mở, Dolly 2.0, được tạo hoàn toàn bởi hàng nghìn nhân viên tình nguyện.
Google và OpenAI dựa một phần vào câu hỏi và câu trả lời từ các trang web như Reddit.
Bộ dữ liệu Q&A mã nguồn mở do Databricks tạo ra được cho là có chất lượng cao hơn vì những người góp phần tạo ra nó là các chuyên gia và câu trả lời họ cung cấp dài hơn và quan trọng hơn những gì tìm thấy trong bộ dữ liệu câu hỏi và câu trả lời thông thường được lấy từ một diễn đàn công khai.
Bản ghi nhớ bị rò rỉ được quan sát:
“Vào đầu tháng XNUMX, cộng đồng nguồn mở đã có trong tay mô hình nền tảng thực sự có khả năng đầu tiên của họ, khi LLaMA của Meta bị rò rỉ ra công chúng.
Nó không có hướng dẫn hoặc điều chỉnh cuộc trò chuyện và không có RLHF.
Tuy nhiên, cộng đồng ngay lập tức hiểu được tầm quan trọng của những gì họ đã được đưa ra.
Tiếp theo là một làn sóng đổi mới to lớn, chỉ cách nhau vài ngày giữa các bước phát triển chính…
Chúng tôi ở đây, chỉ một tháng sau, và có các biến thể với điều chỉnh hướng dẫn, lượng tử hóa, cải tiến chất lượng, đánh giá con người, đa phương thức, RLHF, v.v., nhiều trong số đó được xây dựng dựa trên nhau.
Quan trọng nhất, họ đã giải quyết vấn đề mở rộng quy mô đến mức mà bất kỳ ai cũng có thể mày mò.
Nhiều ý tưởng mới là từ những người bình thường.
Rào cản gia nhập đào tạo và thử nghiệm đã giảm từ tổng sản lượng của một tổ chức nghiên cứu lớn xuống còn một người, một buổi tối và một chiếc máy tính xách tay mạnh mẽ.”
Nói cách khác, Google và OpenAI đã mất hàng tháng trời để đào tạo và xây dựng chỉ mất vài ngày đối với cộng đồng nguồn mở.
Đó phải là một kịch bản thực sự đáng sợ đối với Google.
Đó là một trong những lý do tại sao tôi đã viết rất nhiều về phong trào AI nguồn mở vì nó thực sự giống như tương lai của AI sáng tạo sẽ ở đâu trong một khoảng thời gian tương đối ngắn.
Nguồn mở đã vượt qua nguồn đóng trong lịch sử
Bản ghi nhớ trích dẫn trải nghiệm gần đây với OpenAI's DALL-E, mô hình học sâu được sử dụng để tạo hình ảnh so với Stable Diffusion nguồn mở như một điềm báo về những gì hiện đang xảy ra với AI Sáng tạo như Bard và ChatGPT.
Dall-e được OpenAI phát hành vào tháng 2021 năm 2022. Stable Diffusion, phiên bản nguồn mở, được phát hành một năm rưỡi sau đó vào tháng XNUMX năm XNUMX và chỉ trong vài tuần ngắn ngủi đã vượt qua mức độ phổ biến của Dall-E.
Biểu đồ dòng thời gian này cho thấy Tốc độ khuếch tán ổn định đã vượt qua Dall-E nhanh như thế nào:
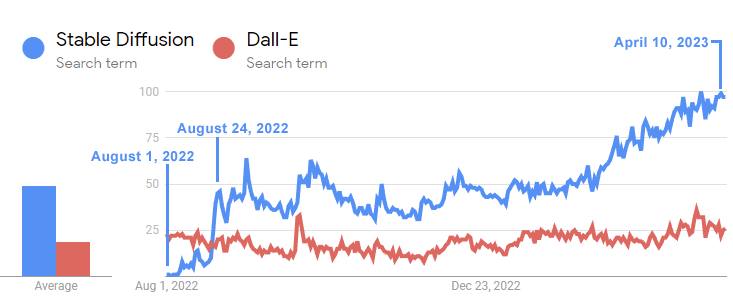
Dòng thời gian của Google Xu hướng ở trên cho thấy mức độ quan tâm đến mô hình Khuếch tán ổn định mã nguồn mở đã vượt xa Dall-E như thế nào trong vòng ba tuần kể từ khi phát hành.
Và mặc dù Dall-E đã ra mắt được một năm rưỡi, nhưng sự quan tâm đến Khuếch tán ổn định vẫn tiếp tục tăng theo cấp số nhân trong khi Dall-E của OpenAI vẫn trì trệ.
Mối đe dọa hiện hữu của các sự kiện tương tự vượt qua Bard (và OpenAI) đang khiến Google gặp ác mộng.
Quá trình tạo ra mô hình mã nguồn mở là vượt trội
Một yếu tố khác khiến các kỹ sư tại Google lo lắng là quy trình tạo và cải tiến các mô hình nguồn mở diễn ra nhanh chóng, không tốn kém và bản thân nó hoàn toàn phù hợp với phương pháp cộng tác toàn cầu phổ biến đối với các dự án nguồn mở.
Bản ghi nhớ nhận thấy rằng các kỹ thuật mới như LoRA (Thích ứng cấp thấp của các mô hình ngôn ngữ lớn), cho phép tinh chỉnh các mô hình ngôn ngữ chỉ trong vài ngày với chi phí cực kỳ thấp, với LLM cuối cùng có thể so sánh với các LLM cực kỳ đắt tiền được tạo bởi Google và OpenAI.
Một lợi ích khác là các kỹ sư nguồn mở có thể xây dựng dựa trên công việc trước đó, lặp đi lặp lại, thay vì phải bắt đầu lại từ đầu.
Việc xây dựng các mô hình ngôn ngữ lớn với hàng tỷ tham số theo cách mà OpenAI và Google đã và đang làm hiện nay là không cần thiết.
Đó có thể là điểm mà Sam Alton gần đây đã ám chỉ khi gần đây ông nói rằng thời đại của các mô hình ngôn ngữ lớn đồ sộ đã qua.
Tác giả của bản ghi nhớ Google đã đối chiếu cách tiếp cận LoRA rẻ và nhanh để tạo LLM với cách tiếp cận AI lớn hiện tại.
Tác giả bản ghi nhớ phản ánh về thiếu sót của Google:
“Ngược lại, đào tạo các mô hình khổng lồ từ đầu không chỉ loại bỏ quá trình đào tạo trước mà còn loại bỏ bất kỳ cải tiến lặp đi lặp lại nào đã được thực hiện từ đầu. Trong thế giới nguồn mở, không mất nhiều thời gian trước khi những cải tiến này chiếm ưu thế, khiến cho việc đào tạo lại toàn bộ trở nên cực kỳ tốn kém.
Chúng ta nên cân nhắc xem liệu mỗi ứng dụng hoặc ý tưởng mới có thực sự cần một mô hình hoàn toàn mới hay không.
…Thật vậy, xét về số giờ làm việc của kỹ sư, tốc độ cải tiến từ các mô hình này vượt xa những gì chúng tôi có thể làm với các biến thể lớn nhất của mình và những biến thể tốt nhất hầu như không thể phân biệt được với ChatGPT.”
Tác giả kết luận với nhận thức rằng những gì họ nghĩ là lợi thế của họ, các mô hình khổng lồ và chi phí cao đi kèm, thực ra lại là một bất lợi.
Bản chất hợp tác toàn cầu của Nguồn mở hiệu quả hơn và các mệnh lệnh cường độ đổi mới nhanh hơn.
Làm thế nào một hệ thống nguồn đóng có thể cạnh tranh với vô số kỹ sư áp đảo trên khắp thế giới?
Tác giả kết luận rằng họ không thể cạnh tranh và cạnh tranh trực tiếp, theo cách nói của họ, là một “sự thua cuộc”.
Đó là cuộc khủng hoảng, cơn bão đang phát triển bên ngoài Google.
Nếu bạn không thể đánh bại mã nguồn mở, hãy tham gia cùng họ
Điều an ủi duy nhất mà tác giả bản ghi nhớ tìm thấy trong mã nguồn mở là vì các đổi mới mã nguồn mở là miễn phí nên Google cũng có thể tận dụng lợi thế của nó.
Cuối cùng, tác giả kết luận rằng cách tiếp cận duy nhất dành cho Google là sở hữu nền tảng giống như cách họ thống trị nền tảng mã nguồn mở Chrome và Android.
Họ chỉ ra cách Meta được hưởng lợi từ việc phát hành mô hình ngôn ngữ lớn LLaMA của họ để nghiên cứu và cách họ hiện có hàng nghìn người làm công việc của họ miễn phí.
Có lẽ điểm rút ra lớn nhất từ bản ghi nhớ là trong tương lai gần, Google có thể cố gắng tái tạo sự thống trị nguồn mở của họ bằng cách phát hành các dự án của họ trên cơ sở nguồn mở và do đó sở hữu nền tảng này.
Bản ghi nhớ kết luận rằng sử dụng nguồn mở là tùy chọn khả thi nhất:
“Google nên tự khẳng định mình là người dẫn đầu trong cộng đồng nguồn mở, đi đầu bằng cách hợp tác với, thay vì bỏ qua, cuộc trò chuyện rộng lớn hơn.
Điều này có thể có nghĩa là thực hiện một số bước không thoải mái, chẳng hạn như xuất bản trọng số mô hình cho các biến thể ULM nhỏ. Điều này nhất thiết có nghĩa là từ bỏ một số quyền kiểm soát đối với các mô hình của chúng tôi.
Nhưng sự thỏa hiệp này là không thể tránh khỏi.
Chúng ta không thể hy vọng vừa thúc đẩy sự đổi mới vừa kiểm soát nó.”
Nguồn mở bỏ đi với ngọn lửa AI
Tuần trước, tôi đã ám chỉ đến thần thoại Hy Lạp về người anh hùng Prometheus đánh cắp ngọn lửa từ các vị thần trên đỉnh Olympus, khiến nguồn mở Prometheus đọ sức với “các vị thần Olympus” của Google và OpenAI:
I tweeted:
“Trong khi Google, Microsoft và Open AI tranh cãi với nhau và quay lưng lại với nhau, liệu Nguồn mở có dập tắt ngọn lửa của họ không?”
Việc rò rỉ bản ghi nhớ của Google xác nhận quan sát đó nhưng nó cũng chỉ ra một sự thay đổi chiến lược có thể xảy ra tại Google để tham gia phong trào nguồn mở và do đó đồng ý và thống trị nó giống như cách họ đã làm với Chrome và Android.
Đọc bản ghi nhớ bị rò rỉ của Google tại đây:
Google “Chúng tôi không có hào, và OpenAI cũng vậy”
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/

