AWS Glue is a serverless data integrating service that you can use to catalog data and prepare for analytics. With AWS Glue, you can discover your data, develop scripts to transform sources into targets, and schedule and run extract, transform, and load (ETL) jobs in a serverless environment. AWS Glue jobs are responsible for running the data processing logic.
One important feature of AWS Glue jobs is the ability to use bookmark keys to process data incrementally. When an AWS Glue job is run, it reads data from a data source and processes it. One or more columns from the source table can be specified as bookmark keys. The column should have sequentially increasing or decreasing values without gaps. These values are used to mark the last processed record in a batch. The next run of the job resumes from that point. This allows you to process large amounts of data incrementally. Without job bookmark keys, AWS Glue jobs would have to reprocess all the data during every run. This can be time-consuming and costly. By using bookmark keys, AWS Glue jobs can resume processing from where they left off, saving time and reducing costs.
This post explains how to use multiple columns as job bookmark keys in an AWS Glue job with a JDBC connection to the source data store. It also demonstrates how to parameterize the bookmark key columns and table names in the AWS Glue job connection options.
This post is focused towards architects and data engineers who design and build ETL pipelines on AWS. You are expected to have a basic understanding of the AWS Management Console, AWS Glue, Amazon Relational Database Service (Amazon RDS), and Amazon CloudWatch logs.
Solution overview
To implement this solution, we complete the following steps:
- Create an Amazon RDS for PostgreSQL instance.
- Create two tables and insert sample data.
- Create and run an AWS Glue job to extract data from the RDS for PostgreSQL DB instance using multiple job bookmark keys.
- Create and run a parameterized AWS Glue job to extract data from different tables with separate bookmark keys
The following diagram illustrates the components of this solution.

Deploy the solution
For this solution, we provide an AWS CloudFormation template that sets up the services included in the architecture, to enable repeatable deployments. This template creates the following resources:
- An RDS for PostgreSQL instance
- An Amazon Simple Storage Service (Amazon S3) bucket to store the data extracted from the RDS for PostgreSQL instance
- An AWS Identity and Access Management (IAM) role for AWS Glue
- Two AWS Glue jobs with job bookmarks enabled to incrementally extract data from the RDS for PostgreSQL instance
To deploy the solution, complete the following steps:
- Choose
 to launch the CloudFormation stack:
to launch the CloudFormation stack: - Enter a stack name.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
- Wait until the creation of the stack is complete, as shown on the AWS CloudFormation console.

- When the stack is complete, copy the AWS Glue scripts to the S3 bucket
job-bookmark-keys-demo-<accountid>. - Open AWS CloudShell.
- Run the following commands and replace
<accountid>with your AWS account ID:
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2907/glue/scenario_1_job.py s3://job-bookmark-keys-demo-<accountid>/scenario_1_job.py
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-2907/glue/scenario_2_job.py s3://job-bookmark-keys-demo-<accountid>/scenario_2_job.py
Add sample data and run AWS Glue jobs
In this section, we connect to the RDS for PostgreSQL instance via AWS Lambda and create two tables. We also insert sample data into both the tables.
- On the Lambda console, choose Functions in the navigation pane.
- Choose the function
LambdaRDSDDLExecute.
- Choose Test and choose Invoke for the Lambda function to insert the data.

The two tables product and address will be created with sample data, as shown in the following screenshot.

Run the multiple_job_bookmark_keys AWS Glue job
We run the multiple_job_bookmark_keys AWS Glue job twice to extract data from the product table of the RDS for PostgreSQL instance. In the first run, all the existing records will be extracted. Then we insert new records and run the job again. The job should extract only the newly inserted records in the second run.
- On the AWS Glue console, choose Jobs in the navigation pane.
- Choose the job
multiple_job_bookmark_keys. - Choose Run to run the job and choose the Runs tab to monitor the job progress.
- Choose the Output logs hyperlink under CloudWatch logs after the job is complete.

- Choose the log stream in the next window to see the output logs printed.

The AWS Glue job extracted all records from the source table product. It keeps track of the last combination of values in the columnsproduct_idandversion.Next, we run another Lambda function to insert a new record. Theproduct_id45 already exists, but the inserted record will have a new version as 2, making the combination sequentially increasing. - Run the
LambdaRDSDDLExecute_incrementalLambda function to insert the new record in theproducttable.
- Run the AWS Glue job
multiple_job_bookmark_keysagain after you insert the record and wait for it to succeed. - Choose the Output logs hyperlink under CloudWatch logs.
- Choose the log stream in the next window to see only the newly inserted record printed.
The job extracts only those records that have a combination greater than the previously extracted records.

Run the parameterised_job_bookmark_keys AWS Glue job
We now run the parameterized AWS Glue job that takes the table name and bookmark key column as parameters. We run this job to extract data from different tables maintaining separate bookmarks.
The first run will be for the address table with bookmarkkey as address_id. These are already populated with the job parameters.
- On the AWS Glue console, choose Jobs in the navigation pane.
- Choose the job
parameterised_job_bookmark_keys. - Choose Run to run the job and choose the Runs tab to monitor the job progress.
- Choose the Output logs hyperlink under CloudWatch logs after the job is complete.

- Choose the log stream in the next window to see all records from the address table printed.

- On the Actions menu, choose Run with parameters.
- Expand the Job parameters section.
- Change the job parameter values as follows:
- Key
--bookmarkkeywith valueproduct_id - Key
--table_namewith valueproduct - The S3 bucket name is unchanged (
job-bookmark-keys-demo-<accountnumber>)
- Key
- Choose Run job to run the job and choose the Runs tab to monitor the job progress.
- Choose the Output logs hyperlink under CloudWatch logs after the job is complete.
- Choose the log stream to see all the records from the product table printed.
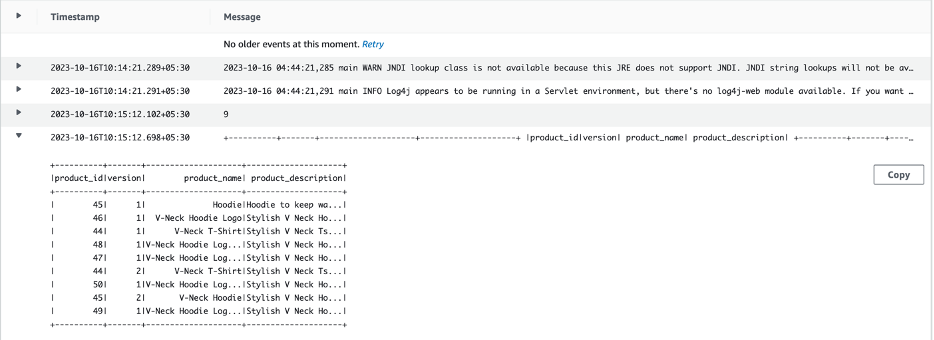
The job maintains separate bookmarks for each of the tables when extracting the data from the source data store. This is achieved by adding the table name to the job name and transformation contexts in the AWS Glue job script.
Clean up
To avoid incurring future charges, complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Select the bucket with job-bookmark-keys in its name.
- Choose Empty to delete all the files and folders in it.
- On the CloudFormation console, choose Stacks in the navigation pane.
- Select the stack you created to deploy the solution and choose Delete.
Conclusion
This post demonstrated passing more than one column of a table as jobBookmarkKeys in a JDBC connection to an AWS Glue job. It also explained how you can a parameterized AWS Glue job to extract data from multiple tables while keeping their respective bookmarks. As a next step, you can test the incremental data extract by changing data in the source tables.
About the Authors
 Durga Prasad is a Sr Lead Consultant enabling customers build their Data Analytics solutions on AWS. He is a coffee lover and enjoys playing badminton.
Durga Prasad is a Sr Lead Consultant enabling customers build their Data Analytics solutions on AWS. He is a coffee lover and enjoys playing badminton.
 Murali Reddy is a Lead Consultant at Amazon Web Services (AWS), helping customers build and implement data analytics solution. When he’s not working, Murali is an avid bike rider and loves exploring new places.
Murali Reddy is a Lead Consultant at Amazon Web Services (AWS), helping customers build and implement data analytics solution. When he’s not working, Murali is an avid bike rider and loves exploring new places.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/use-multiple-bookmark-keys-in-aws-glue-jdbc-jobs/

