Hayvanat Bahçesi Dijital orijinal TV ve film içeriklerinin farklı dil, bölge ve kültürlere uyarlanması için uçtan uca yerelleştirme ve medya hizmetleri sunmaktadır. Dünyanın en iyi içerik oluşturucuları için küreselleşmeyi kolaylaştırır. Eğlence sektörünün en büyük isimlerinin güvendiği ZOO Digital, dublaj, altyazı, komut dosyası oluşturma ve uyumluluk da dahil olmak üzere geniş ölçekte yüksek kaliteli yerelleştirme ve medya hizmetleri sunuyor.
Tipik yerelleştirme iş akışları, manuel konuşmacı günlüğü oluşturmayı gerektirir; burada bir ses akışı, konuşmacının kimliğine göre bölümlere ayrılır. İçeriğin başka bir dile dublajlanabilmesi için bu zaman alıcı sürecin tamamlanması gerekir. Manuel yöntemlerle 30 dakikalık bir bölümün yerelleştirilmesi 1-3 saat kadar sürebilir. ZOO Digital, otomasyon sayesinde yerelleştirmeyi 30 dakikadan kısa sürede gerçekleştirmeyi hedefliyor.
Bu yazıda, medya içeriğini günlükleştirmek için ölçeklenebilir makine öğrenimi (ML) modellerini dağıtmayı tartışıyoruz. Amazon Adaçayı Yapıcı, odaklanarak FısıltıX modeli.
Olayın Arka Planı
ZOO Digital'in vizyonu, yerelleştirilmiş içeriğin daha hızlı geri dönüşünü sağlamaktır. Bu hedef, içeriği manuel olarak yerelleştirebilen vasıflı kişilerden oluşan küçük işgücünün bir araya getirdiği çalışmanın manuel olarak yoğun doğası nedeniyle darboğaz oluşturuyor. ZOO Digital, 11,000'den fazla serbest çalışanla çalışıyor ve yalnızca 600'de 2022 milyondan fazla kelimeyi yerelleştiriyor. Bununla birlikte, artan içerik talebi nedeniyle vasıflı insan arzı yetersiz kalıyor ve yerelleştirme iş akışlarına yardımcı olmak için otomasyon gerekiyor.
ZOO Digital, makine öğrenimi yoluyla içerik iş akışlarının yerelleştirilmesini hızlandırmak amacıyla, AWS'nin müşterilerle iş yüklerini birlikte oluşturmaya yönelik bir yatırım programı olan AWS Prototyping'i devreye aldı. Katılım, yerelleştirme süreci için işlevsel bir çözüm sunmaya odaklanırken, ZOO Digital geliştiricilerine SageMaker hakkında uygulamalı eğitim sağladı. Amazon Yazısı, ve Amazon Tercüme.
Müşteri mücadelesi
Bir başlık (bir film veya bir TV dizisinin bir bölümü) yazıya geçirildikten sonra, karakterleri canlandırmak üzere seçilen ses sanatçılarına doğru şekilde atanabilmeleri için konuşmanın her bölümüne konuşmacılar atanmalıdır. Bu işleme konuşmacı günlüğü adı verilir. ZOO Digital, ekonomik açıdan uygun olmakla birlikte içeriği geniş ölçekte günlük tutma zorluğuyla karşı karşıyadır.
Çözüme genel bakış
Bu prototipte, orijinal medya dosyalarını belirtilen bir klasörde sakladık. Amazon Basit Depolama Hizmeti (Amazon S3) kovası. Bu S3 paketi, içinde yeni dosyalar algılandığında bir olay oluşturacak ve bir olayı tetikleyecek şekilde yapılandırılmıştır. AWS Lambda işlev. Bu tetikleyiciyi yapılandırmaya ilişkin talimatlar için eğitime bakın Lambda işlevini çağırmak için Amazon S3 tetikleyicisini kullanma. Daha sonra Lambda işlevi, aşağıdakileri kullanarak çıkarım için SageMaker uç noktasını çağırdı: Boto3 SageMaker Çalışma Zamanı istemcisi.
The FısıltıX dayalı model OpenAI'nin Fısıltısı, medya varlıkları için transkripsiyon ve günlük tutma işlemlerini gerçekleştirir. Bunun üzerine inşa edilmiştir Daha Hızlı Fısıltı Whisper'a kıyasla gelişmiş kelime düzeyinde zaman damgası hizalaması ile dört kata kadar daha hızlı transkripsiyon sunan yeniden uygulama. Ek olarak, orijinal Whisper modelinde bulunmayan konuşmacı günlük tutma özelliğini de sunar. WhisperX, transkripsiyonlar için Whisper modelini kullanır. Wav2Vec2 Zaman damgası hizalamasını geliştirmek için model (yazıya aktarılan metnin ses zaman damgalarıyla senkronizasyonunu sağlamak) ve nota günlük tutma modeli. FFmpeg kaynak ortamdan ses yüklemek için kullanılır ve çeşitli destekleri destekler medya formatları. Şeffaf ve modüler model mimarisi esneklik sağlar çünkü modelin her bir bileşeni gelecekte ihtiyaç duyulduğunda değiştirilebilir. Ancak WhisperX'in tam yönetim özelliklerinden yoksun olduğunu ve kurumsal düzeyde bir ürün olmadığını unutmamak gerekir. Bakım ve destek olmadan üretim dağıtımına uygun olmayabilir.
Bu işbirliğinde WhisperX'i SageMaker üzerinde dağıttık ve değerlendirdik. eşzamansız çıkarım uç noktası modele ev sahipliği yapmak. SageMaker eşzamansız uç noktaları, 1 GB'a kadar yükleme boyutlarını destekler ve trafik artışlarını etkili bir şekilde azaltan ve yoğun olmayan zamanlarda maliyetten tasarruf sağlayan otomatik ölçeklendirme özelliklerini içerir. Eşzamansız uç noktalar, kullanım durumumuzdaki filmler ve TV dizileri gibi büyük dosyaların işlenmesi için özellikle uygundur.
Aşağıdaki şema bu işbirliğinde yürüttüğümüz deneylerin temel unsurlarını göstermektedir.

Aşağıdaki bölümlerde WhisperX modelinin SageMaker'da dağıtımının ayrıntılarını inceleyeceğiz ve günlük tutma performansını değerlendireceğiz.
Modeli ve bileşenlerini indirin
WhisperX, transkripsiyon, zorunlu hizalama ve günlük oluşturma için birden fazla model içeren bir sistemdir. Çıkarım sırasında model yapıtlarını getirmeye gerek kalmadan SageMaker'ın sorunsuz çalışması için tüm model yapıtlarının önceden indirilmesi önemlidir. Bu yapılar daha sonra başlatma sırasında SageMaker servis konteynerine yüklenir. Bu modellere doğrudan erişilemediğinden, WhisperX kaynağından modelin ve bileşenlerinin indirilmesine ilişkin talimatlar sağlayan açıklamalar ve örnek kod sunuyoruz.
WhisperX altı model kullanır:
Bu modellerin çoğunu buradan temin edebilirsiniz. Sarılma Yüz huggingface_hub kütüphanesini kullanarak. Aşağıdakileri kullanıyoruz download_hf_model() Bu model yapıtlarını alma işlevi. Aşağıdaki pyannote modelleri için kullanıcı sözleşmeleri kabul edildikten sonra oluşturulan Hugging Face'ten bir erişim belirteci gereklidir:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
VAD modeli Amazon S3'ten alınır ve Wav2Vec2 modeli torchaudio.pipelines modülünden alınır. Aşağıdaki koda dayanarak, Hugging Face'tekiler de dahil olmak üzere tüm modellerin yapıtlarını alabilir ve bunları belirtilen yerel model dizinine kaydedebiliriz:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Modelin sunulması için uygun AWS Deep Learning Container'ı seçin
Model yapıları önceki örnek kod kullanılarak kaydedildikten sonra, önceden oluşturulmuş AWS Derin Öğrenme Kapları (DLC'ler) aşağıdakilerden GitHub repo. Docker görüntüsünü seçerken şu ayarları göz önünde bulundurun: çerçeve (Hugging Face), görev (çıkarım), Python sürümü ve donanım (örneğin GPU). Aşağıdaki görseli kullanmanızı öneririz: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Bu görüntüde ffmpeg gibi gerekli tüm sistem paketleri önceden yüklenmiştir. [REGION] kısmını kullandığınız AWS Bölgesi ile değiştirmeyi unutmayın.
Diğer gerekli Python paketleri için bir requirements.txt Paketlerin ve sürümlerinin listesini içeren dosya. Bu paketler AWS DLC oluşturulduğunda yüklenecektir. WhisperX modelini SageMaker'da barındırmak için gereken ek paketler aşağıdadır:
Modelleri yüklemek ve çıkarımı çalıştırmak için bir çıkarım komut dosyası oluşturun
Daha sonra özel bir tane oluşturuyoruz inference.py WhisperX modelinin ve bileşenlerinin kapsayıcıya nasıl yüklendiğini ve çıkarım sürecinin nasıl çalıştırılması gerektiğini ana hatlarıyla belirten komut dosyası. Komut dosyası iki işlev içerir: model_fn ve transform_fn. model_fn Modelleri ilgili konumlarından yüklemek için işlev çağrılır. Daha sonra bu modeller idareye aktarılır. transform_fn Transkripsiyon, hizalama ve günlük oluşturma işlemlerinin gerçekleştirildiği çıkarım sırasında işlev görür. Aşağıdakiler için bir kod örneğidir inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Modelin dizininde, yanında requirements.txt dosyanın varlığından emin olun inference.py bir kod alt dizininde. models dizin aşağıdakine benzemelidir:
Modellerin bir tarball'ını oluşturun
Modelleri ve kod dizinlerini oluşturduktan sonra modeli bir tarball'a (.tar.gz dosyası) sıkıştırmak ve Amazon S3'e yüklemek için aşağıdaki komut satırlarını kullanabilirsiniz. Bu yazının yazıldığı sırada, daha hızlı fısıltı özelliğine sahip Büyük V2 modeli kullanıldığında, SageMaker modelini temsil eden ortaya çıkan tarball'ın boyutu 3 GB'tır. Daha fazla bilgi için bkz. Amazon SageMaker'da model barındırma modelleri, 2. Bölüm: SageMaker'da gerçek zamanlı modeller dağıtmaya başlama.
Bir SageMaker modeli oluşturun ve eşzamansız bir tahminciyle bir uç nokta dağıtın
Artık SageMaker modelini, uç nokta yapılandırmasını ve eşzamansız uç noktayı şu şekilde oluşturabilirsiniz: AsyncPredictor önceki adımda oluşturulan model tarball'ı kullanarak. Talimatlar için bkz. Eşzamansız Çıkarsama Uç Noktası Oluşturun.
Günlük tutma performansını değerlendirin
WhisperX modelinin günlük tutma performansını çeşitli senaryolarda değerlendirmek için iki İngilizce başlıktan her biri üç bölüm seçtik: 30 dakikalık bölümlerden oluşan bir drama başlığı ve 45 dakikalık bölümlerden oluşan bir belgesel başlığı. Pyannote'un metrik araç setini kullandık, pyannote.metricshesaplamak için günlük tutma hata oranı (DER). Değerlendirmede, ZOO tarafından sağlanan manuel olarak yazıya geçirilen ve günlük haline getirilen transkriptler temel gerçek olarak hizmet etti.
DER'i şu şekilde tanımladık:
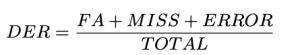
Toplam temel gerçek videosunun uzunluğudur. FA (Yanlış Alarm), tahminlerde konuşma olarak kabul edilen ancak temel gerçeklikte dikkate alınmayan bölümlerin uzunluğudur. Miss serisi temel gerçeklikte konuşma olarak kabul edilen ancak tahminde dikkate alınmayan bölümlerin uzunluğudur. HataOlarak da adlandırılan Karışıklık, tahmin ve temel gerçeklikte farklı konuşmacılara atanan bölümlerin uzunluğudur. Tüm birimler saniye cinsinden ölçülür. DER'in tipik değerleri, belirli uygulamaya, veri kümesine ve günlük tutma sisteminin kalitesine bağlı olarak değişebilir. DER'in 1.0'dan büyük olabileceğini unutmayın. Daha düşük bir DER daha iyidir.
Bir medya parçası için DER'yi hesaplayabilmek için, WhisperX'in kopyaladığı ve günlüğe aldığı çıktıların yanı sıra temel gerçek günlüğü de gereklidir. Bunların ayrıştırılması ve medyadaki her konuşma bölümü için bir konuşmacı etiketi, konuşma bölümü başlangıç zamanı ve konuşma bölümü bitiş zamanını içeren demet listeleriyle sonuçlanması gerekir. Konuşmacı etiketlerinin WhisperX ile temel gerçek günlükleri arasında eşleşmesi gerekmez. Sonuçlar çoğunlukla segmentlerin zamanına dayanmaktadır. pyannote.metrics bu temel gerçek günlüklerini ve çıktı günlüklerini alır (pyannote.metrics belgelerinde şu şekilde anılır): referans ve hipotezDER'yi hesaplamak için. Aşağıdaki tablo sonuçlarımızı özetlemektedir.
| Video Türü | DER | Doğru | Miss serisi | Hata | Yanlış alarm |
| Dram | 0.738 | %44.80 | %21.80 | %33.30 | %18.70 |
| Belgesel | 1.29 | %94.50 | %5.30 | %0.20 | %123.40 |
| Ortalama | 0.901 | %71.40 | %13.50 | %15.10 | %61.50 |
Bu sonuçlar, drama ve belgesel başlıkları arasında önemli bir performans farkını ortaya koyuyor; model, belgesel başlığıyla karşılaştırıldığında drama bölümleri için (DER'i toplu bir ölçüm olarak kullanarak) belirgin şekilde daha iyi sonuçlar elde ediyor. Başlıkların daha yakından incelenmesi, bu performans açığına katkıda bulunan potansiyel faktörlere ilişkin bilgiler sağlar. Önemli faktörlerden biri, belgeselin başlığındaki konuşmayla örtüşen arka plan müziğinin sıklıkla bulunması olabilir. Konuşmayı izole etmek için arka plan gürültüsünü ortadan kaldırmak gibi günlük tutma doğruluğunu artırmak için medyanın ön işlenmesi bu prototipin kapsamı dışında olmasına rağmen, WhisperX'in performansını potansiyel olarak artırabilecek gelecekteki çalışmalar için yollar açıyor.
Sonuç
Bu yazıda, günlük tutma iş akışını geliştirmek için SageMaker ve WhisperX modeliyle makine öğrenimi tekniklerini kullanarak AWS ve ZOO Digital arasındaki işbirliğine dayalı ortaklığı araştırdık. AWS ekibi, günlük oluşturma için özel olarak tasarlanmış özel makine öğrenimi modellerinin prototip oluşturma, değerlendirme ve etkili dağıtımını anlama konusunda ZOO'ya yardımcı olma konusunda çok önemli bir rol oynadı. Buna, SageMaker kullanılarak ölçeklenebilirlik için otomatik ölçeklendirmenin dahil edilmesi de dahildi.
Günlük tutma için yapay zekadan yararlanmak, ZOO için yerelleştirilmiş içerik oluştururken hem maliyet hem de zaman açısından önemli tasarruflara yol açacaktır. Bu teknoloji, transkripsiyon yapanların konuşmacıları hızlı ve hassas bir şekilde oluşturmasına ve tanımlamasına yardımcı olarak, görevin geleneksel olarak zaman alıcı ve hataya açık niteliğini ortadan kaldırır. Geleneksel süreç genellikle videonun birden fazla geçişini ve hataları en aza indirmek için ek kalite kontrol adımlarını içerir. Günlük tutma için yapay zekanın benimsenmesi, daha hedefe yönelik ve verimli bir yaklaşıma olanak tanır ve böylece daha kısa bir zaman dilimi içinde üretkenliği artırır.
WhisperX modelini SageMaker eşzamansız uç noktasında dağıtmaya yönelik temel adımları özetledik ve sağlanan kodu kullanarak bunu kendiniz denemenizi öneririz. ZOO Digital'in hizmetleri ve teknolojisi hakkında daha fazla bilgi için şu adresi ziyaret edin: ZOO Digital'in resmi sitesi. OpenAI Whisper modelinin SageMaker'da dağıtılmasına ve çeşitli çıkarım seçeneklerine ilişkin ayrıntılar için bkz. Whisper Model'i Amazon SageMaker'da barındırın: çıkarım seçeneklerini keşfetme. Düşüncelerinizi yorumlarda paylaşmaktan çekinmeyin.
Yazarlar Hakkında
 Ying Hou, Doktora, AWS'de Makine Öğrenimi Prototipleme Mimarıdır. Başlıca ilgi alanları GenAI, Bilgisayarla Görme, NLP ve zaman serisi veri tahminine odaklanarak Derin Öğrenmeyi kapsamaktadır. Boş zamanlarında ailesiyle kaliteli anlar geçirmekten, kendini romanlara kaptırmaktan ve Birleşik Krallık'taki milli parklarda yürüyüş yapmaktan hoşlanıyor.
Ying Hou, Doktora, AWS'de Makine Öğrenimi Prototipleme Mimarıdır. Başlıca ilgi alanları GenAI, Bilgisayarla Görme, NLP ve zaman serisi veri tahminine odaklanarak Derin Öğrenmeyi kapsamaktadır. Boş zamanlarında ailesiyle kaliteli anlar geçirmekten, kendini romanlara kaptırmaktan ve Birleşik Krallık'taki milli parklarda yürüyüş yapmaktan hoşlanıyor.
 Ethan Cumberland ZOO Digital'de Yapay Zeka Araştırma Mühendisidir ve burada konuşma, dil ve yerelleştirme iş akışlarını iyileştirmek için yapay zeka ve Makine Öğrenimini yardımcı teknolojiler olarak kullanmak üzerinde çalışmaktadır. Web'den yapılandırılmış bilgi çıkarmaya ve toplanan verileri analiz etmek ve zenginleştirmek için açık kaynaklı makine öğrenimi modellerinden yararlanmaya odaklanan, güvenlik ve polislik alanında yazılım mühendisliği ve araştırma konusunda bir geçmişi vardır.
Ethan Cumberland ZOO Digital'de Yapay Zeka Araştırma Mühendisidir ve burada konuşma, dil ve yerelleştirme iş akışlarını iyileştirmek için yapay zeka ve Makine Öğrenimini yardımcı teknolojiler olarak kullanmak üzerinde çalışmaktadır. Web'den yapılandırılmış bilgi çıkarmaya ve toplanan verileri analiz etmek ve zenginleştirmek için açık kaynaklı makine öğrenimi modellerinden yararlanmaya odaklanan, güvenlik ve polislik alanında yazılım mühendisliği ve araştırma konusunda bir geçmişi vardır.
 Gaurav Kaila Birleşik Krallık ve İrlanda için AWS Prototipleme ekibine liderlik ediyor. Ekibi, AWS hizmetlerinin benimsenmesini hızlandırma göreviyle iş açısından kritik iş yüklerini tasarlamak ve birlikte geliştirmek için farklı sektörlerdeki müşterilerle birlikte çalışıyor.
Gaurav Kaila Birleşik Krallık ve İrlanda için AWS Prototipleme ekibine liderlik ediyor. Ekibi, AWS hizmetlerinin benimsenmesini hızlandırma göreviyle iş açısından kritik iş yüklerini tasarlamak ve birlikte geliştirmek için farklı sektörlerdeki müşterilerle birlikte çalışıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

