Üretken yapay zeka, yapay zeka alanında birçok potansiyelin önünü açtı. Metin oluşturma, kod oluşturma, özetleme, çeviri, sohbet robotları ve daha fazlasını içeren çok sayıda kullanım görüyoruz. Gelişen alanlardan biri de, sezgisel SQL sorguları yoluyla verilere erişmeye yönelik yeni fırsatların kilidini açmak için doğal dil işlemenin (NLP) kullanılmasıdır. İş kullanıcıları ve veri analistleri, karmaşık teknik kodlarla uğraşmak yerine, veriler ve içgörülerle ilgili soruları sade bir dille sorabilirler. Birincil amaç, doğal dildeki metinden otomatik olarak SQL sorguları oluşturmaktır. Bunu yapmak için metin girişi yapılandırılmış bir gösterime dönüştürülür ve bu gösterimden bir veritabanına erişim için kullanılabilecek bir SQL sorgusu oluşturulur.
Bu yazıda, SQL'e metin (Text2SQL) konusuna bir giriş sağlıyoruz ve kullanım örneklerini, zorlukları, tasarım modellerini ve en iyi uygulamaları inceliyoruz. Özellikle aşağıdaki konuları tartışıyoruz:
- Neden Text2SQL'e ihtiyacımız var?
- Text to SQL için temel bileşenler
- Doğal dil veya Metinden SQL'e yönelik hızlı mühendislik hususları
- Optimizasyonlar ve en iyi uygulamalar
- Mimari desenler
Text2SQL'e neden ihtiyacımız var?
Günümüzde geleneksel veri analitiğinde, veri ambarında ve veritabanlarında büyük miktarda veri mevcuttur ve bunların sorgulanması veya kuruluş üyelerinin çoğunluğu için anlaşılması kolay olmayabilir. Text2SQL'in temel amacı, sorgulama veritabanlarını, sorgularını doğal dilde sağlayabilen, teknik bilgisi olmayan kullanıcılar için daha erişilebilir hale getirmektir.
NLP SQL, iş kullanıcılarının aşağıdaki gibi soruları doğal dilde yazarak veya konuşarak verileri analiz etmelerine ve yanıtlar almalarına olanak tanır:
- “Geçen ay her ürün için toplam satışları göster”
- “Hangi ürünler daha fazla gelir getirdi?”
- “Her bölgeden müşterilerin yüzde kaçı?”
Amazon Ana Kayası Tek bir API aracılığıyla çeşitli yüksek performanslı temel modelleri (FM'ler) sunan, tamamen yönetilen bir hizmettir ve Gen AI uygulamalarının kolayca oluşturulup ölçeklendirilmesine olanak tanır. Yukarıda listelenenlere benzer sorulara dayalı SQL sorguları oluşturmak, kurumsal yapılandırılmış verileri sorgulamak ve sorgu yanıt verilerinden doğal dil yanıtları oluşturmak için kullanılabilir.
Metinden SQL'e geçiş için temel bileşenler
Metinden SQL'e sistemler, doğal dil sorgularını çalıştırılabilir SQL'e dönüştürmek için birkaç aşama içerir:
- Doğal dil işleme:
- Kullanıcının giriş sorgusunu analiz edin
- Temel unsurları ve amacı çıkarın
- Yapılandırılmış bir formata dönüştürün
- SQL oluşturma:
- Çıkarılan ayrıntıları SQL sözdizimine eşleme
- Geçerli bir SQL sorgusu oluşturun
- Veritabanı sorgusu:
- Yapay zeka tarafından oluşturulan SQL sorgusunu veritabanında çalıştırın
- Sonuçları al
- Sonuçları kullanıcıya döndür
Büyük Dil Modellerinin (LLM'ler) dikkate değer bir yeteneği, veritabanları için Yapılandırılmış Sorgu Dili (SQL) de dahil olmak üzere kod üretmesidir. Bu LLM'lerden doğal dil sorusunu anlamak ve çıktı olarak karşılık gelen bir SQL sorgusu oluşturmak için yararlanılabilir. Yüksek Lisans'lar, daha fazla veri sağlandığında bağlam içi öğrenmeyi ve ince ayar ayarlarını benimseyerek fayda sağlayacaktır.
Aşağıdaki diyagramda temel bir Text2SQL akışı gösterilmektedir.

SQL'e doğal dil için hızlı mühendislik hususları
Doğal dili SQL sorgularına çevirmek için LLM'leri kullanırken bilgi istemi çok önemlidir ve istem mühendisliği için birkaç önemli husus vardır.
Etkili hızlı mühendislik SQL sistemlerine doğal dil geliştirmenin anahtarıdır. Açık ve anlaşılır yönlendirmeler, dil modeli için daha iyi talimatlar sağlar. Kullanıcının bir SQL sorgusu talep ettiği bağlamın ilgili veritabanı şeması ayrıntılarıyla birlikte sağlanması, modelin amacı doğru bir şekilde tercüme etmesini sağlar. Doğal dil istemlerinin ve bunlara karşılık gelen SQL sorgularının birkaç açıklamalı örneğinin eklenmesi, modelin sözdizimi uyumlu çıktı üretmesine rehberlik etmeye yardımcı olur. Ek olarak, modelin işleme sırasında benzer örnekleri aldığı Geri Alma Artırılmış Üretimin (RAG) dahil edilmesi, haritalama doğruluğunu daha da artırır. Modele yeterli talimat, bağlam, örnekler ve erişim artırma olanağı sağlayan iyi tasarlanmış istemler, doğal dilin SQL sorgularına güvenilir bir şekilde çevrilmesi için çok önemlidir.
Aşağıda, teknik incelemedeki veritabanının kod temsilini içeren temel bilgi isteminin bir örneği yer almaktadır. Büyük Dil Modellerinin Birkaç Adımda Metinden SQL'e Yeteneklerinin Geliştirilmesi: Hızlı Tasarım Stratejileri Üzerine Bir Araştırma.
Bu örnekte gösterildiği gibi, istem tabanlı birkaç adımlı öğrenme, modele istemin kendisinde bir avuç açıklamalı örnek sağlar. Bu, model için doğal dil ile SQL arasındaki hedef eşlemeyi gösterir. Tipik olarak bilgi istemi, doğal dil sorgusunu ve eşdeğer SQL ifadesini gösteren yaklaşık 2-3 çift içerir. Bu birkaç örnek, kapsamlı eğitim verileri gerektirmeden doğal dilden sözdizimi uyumlu SQL sorguları oluşturmak için modele rehberlik eder.
İnce ayar ve hızlı mühendislik karşılaştırması
SQL sistemleri için doğal dil oluştururken, genellikle modele ince ayar yapmanın doğru teknik olup olmadığı veya etkili hızlı mühendisliğin gidilecek yol olup olmadığı tartışmasına gireriz. Her iki yaklaşım da doğru gereksinimlere göre değerlendirilebilir ve seçilebilir:
-
- İnce ayar – Temel model, geniş bir genel metin külliyatı üzerinde önceden eğitilmiştir ve daha sonra kullanılabilir. talimat tabanlı ince ayarText-SQL'de önceden eğitilmiş bir temel modelin performansını artırmak için etiketli örnekleri kullanan . Bu, modeli hedef göreve uyarlar. İnce ayar, modeli doğrudan son görevde eğitir ancak birçok metin-SQL örneği gerektirir. Metinden SQL'e geçişin etkinliğini artırmak için LLM'nize dayalı denetimli ince ayarı kullanabilirsiniz. Bunun için aşağıdaki gibi çeşitli veri kümelerini kullanabilirsiniz: Örümcek, WikiSQL, KOVALAMAK, BIRD-SQLya da CoSQL.
- Hızlı mühendislik – Model, hedef SQL sözdizimini yönlendirmek için tasarlanmış istemleri tamamlamak üzere eğitilmiştir. Yüksek Lisans kullanarak doğal dilden SQL oluştururken, istemde net talimatlar sağlamak, modelin çıktısını kontrol etmek açısından önemlidir. Sütunlara, şemaya işaret etme gibi farklı bileşenlere açıklama ekleme ve ardından hangi SQL türünün oluşturulacağını bildirme isteminde. Bunlar, modele SQL çıktısının nasıl biçimlendirileceğini söyleyen talimatlar gibi davranır. Aşağıdaki istem, tablo sütunlarını işaret ettiğiniz ve MySQL sorgusu oluşturma talimatını verdiğiniz bir örneği gösterir:
Metinden SQL'e modeller için etkili bir yaklaşım, göreve özgü herhangi bir ince ayar yapmadan ilk önce temel bir LLM ile başlamaktır. Daha sonra iyi hazırlanmış bilgi istemleri, temel modeli metinden SQL'e eşlemeyi yönetecek şekilde uyarlamak ve yönlendirmek için kullanılabilir. Bu hızlı mühendislik, ince ayar yapmanıza gerek kalmadan yeteneği geliştirmenize olanak tanır. Temel model üzerinde hızlı mühendislik yeterli doğruluğu sağlayamazsa, küçük bir dizi metin-SQL örneği üzerinde ince ayar yapılması, daha fazla hızlı mühendislikle birlikte incelenebilir.
Ham önceden eğitilmiş model üzerinde hızlı mühendislik tek başına gereksinimleri karşılamıyorsa, ince ayar ve hızlı mühendisliğin birleşimi gerekli olabilir. Bununla birlikte, başlangıçta ince ayar yapmadan hızlı mühendisliği denemek en iyisidir çünkü bu, veri toplamaya gerek kalmadan hızlı yinelemeye olanak tanır. Bunun yeterli performansı sağlayamaması durumunda, hızlı mühendisliğin yanı sıra ince ayar yapmak uygun bir sonraki adımdır. Bu genel yaklaşım verimliliği en üst düzeye çıkarırken, tamamen istem tabanlı yöntemlerin yetersiz olması durumunda özelleştirmeye de izin verir.
Optimizasyon ve en iyi uygulamalar
Etkinliği artırmak, kaynakların en iyi şekilde kullanılmasını ve doğru sonuçlara mümkün olan en iyi şekilde ulaşılmasını sağlamak için optimizasyon ve en iyi uygulamalar önemlidir. Teknikler performansı artırmaya, maliyetleri kontrol etmeye ve daha kaliteli bir sonuç elde etmeye yardımcı olur.
Yüksek Lisans kullanarak metinden SQL'e sistemler geliştirirken optimizasyon teknikleri performansı ve verimliliği artırabilir. Göz önünde bulundurulması gereken bazı önemli alanlar şunlardır:
- önbelleğe alma – Gecikmeyi, maliyet kontrolünü ve standardizasyonu geliştirmek için, ayrıştırılmış SQL'i ve tanınan sorgu istemlerini metinden SQL'e LLM'den önbelleğe alabilirsiniz. Bu, tekrarlanan sorguların yeniden işlenmesini önler.
- İzleme – Metinden SQL'e LLM sistemini izlemek için sorgu ayrıştırma, bilgi istemi tanıma, SQL oluşturma ve SQL sonuçlarına ilişkin günlükler ve ölçümler toplanmalıdır. Bu, optimizasyon örneğinin istemi güncellemesinde veya ince ayarın güncellenmiş bir veri kümesiyle yeniden ziyaret edilmesinde görünürlük sağlar.
- Gerçekleştirilmiş görünümler ve tablolar – Gerçekleştirilmiş görünümler, SQL oluşturmayı basitleştirebilir ve yaygın metinden SQL'e sorguların performansını artırabilir. Tabloları doğrudan sorgulamak karmaşık SQL ile sonuçlanabilir ve ayrıca dizinler gibi performans tekniklerinin sürekli oluşturulması da dahil olmak üzere performans sorunlarına yol açabilir. Ayrıca aynı tablonun diğer uygulama alanları için aynı anda kullanılması durumunda performans sorunlarının önüne geçebilirsiniz.
- Veriler yenileniyor – Metinden SQL'e sorgular için verileri güncel tutmak amacıyla, somutlaştırılmış görünümlerin bir zamanlamaya göre yenilenmesi gerekir. Ek yükü dengelemek için toplu veya artımlı yenileme yaklaşımlarını kullanabilirsiniz.
- Merkezi veri kataloğu – Merkezi bir veri kataloğu oluşturmak, bir kuruluşun veri kaynaklarına tek bir pencereden görünüm sağlar ve LLM'lerin daha doğru yanıtlar sağlamak için uygun tabloları ve şemaları seçmesine yardımcı olur. Vektör kalıplamaların Merkezi bir veri kataloğundan oluşturulan veriler, ilgili ve kesin SQL yanıtları oluşturmak için istenen bilgilerle birlikte bir LLM'ye sağlanabilir.
Önbelleğe alma, izleme, gerçekleştirilmiş görünümler, zamanlanmış yenileme ve merkezi katalog gibi en iyi optimizasyon uygulamalarını uygulayarak, LLM'leri kullanan metinden SQL'e sistemlerin performansını ve verimliliğini önemli ölçüde artırabilirsiniz.
Mimari desenler
Metinden SQL'e iş akışı için uygulanabilecek bazı mimari modellerine bakalım.
Hızlı mühendislik
Aşağıdaki şemada, hızlı mühendislik kullanılarak bir Yüksek Lisans ile sorgular oluşturmaya yönelik mimari gösterilmektedir.
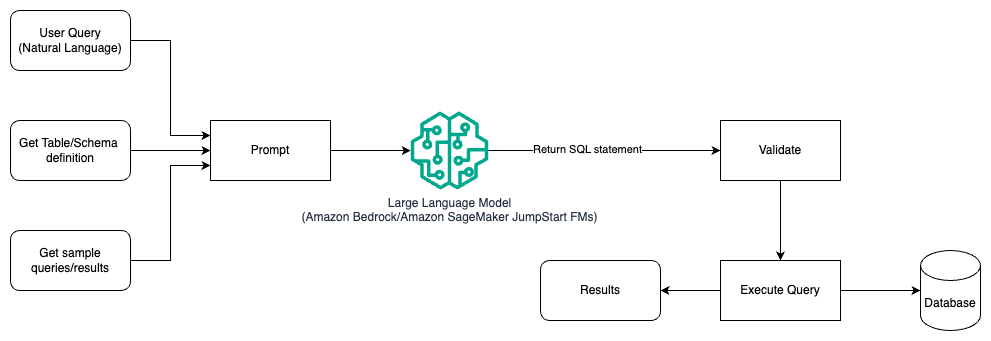
Bu modelde kullanıcı, modele bilgi isteminin kendisinde tablo ve şema ayrıntılarını ve sonuçlarıyla birlikte bazı örnek sorguları içeren açıklamalı örnekler sağlayan bilgi istemi tabanlı birkaç adımlı öğrenme oluşturur. LLM, AI tarafından oluşturulan SQL'i geri döndürmek için sağlanan istemi kullanır; bu SQL doğrulanır ve ardından sonuçları almak için veritabanında çalıştırılır. Bu, hızlı mühendisliği kullanmaya başlamanın en basit modelidir. Bunun için kullanabilirsiniz Amazon Ana Kayası or temel modelleri in Amazon SageMaker Hızlı Başlangıç.
Bu modelde kullanıcı, modele bilgi isteminin kendisinde tablo ve şema ayrıntılarını ve sonuçlarıyla birlikte bazı örnek sorguları içeren açıklamalı örnekler sağlayan bilgi istemi tabanlı birkaç adımlık bir öğrenme oluşturur. LLM, doğrulanan ve sonuçları almak için veritabanında çalıştırılan, AI tarafından oluşturulan SQL'i geri döndürmek için sağlanan istemi kullanır. Bu, hızlı mühendisliği kullanmaya başlamanın en basit modelidir. Bunun için kullanabilirsiniz Amazon Ana Kayası Bu, tek bir API aracılığıyla önde gelen AI şirketlerinin yüksek performanslı temel modellerinden (FM'ler) oluşan bir seçeneğin yanı sıra güvenlik, gizlilik ve sorumlu yapay zeka ile üretken yapay zeka uygulamaları oluşturmak için ihtiyacınız olan geniş bir yetenek kümesi sunan, tamamen yönetilen bir hizmettir veya JumpStart Temel Modelleri içerik yazma, kod oluşturma, soru yanıtlama, metin yazarlığı, özetleme, sınıflandırma, bilgi erişimi ve daha fazlası gibi kullanım durumları için en son teknolojiye sahip temel modeller sunan
Hızlı mühendislik ve ince ayar
Aşağıdaki şema, hızlı mühendislik ve ince ayar kullanarak bir LLM ile sorgular oluşturmaya yönelik mimariyi göstermektedir.
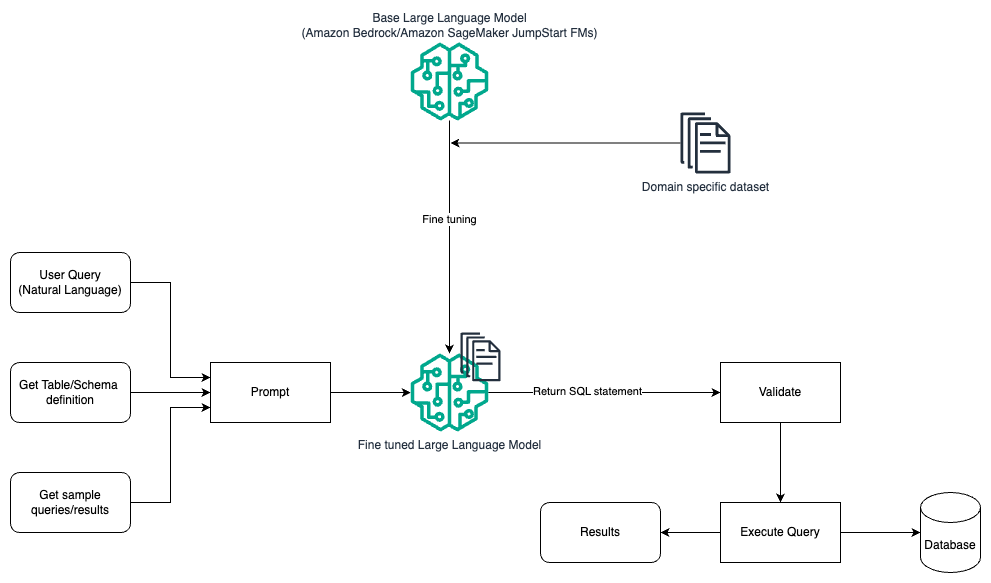
Bu akış, çoğunlukla hızlı mühendisliğe dayanan ancak alana özgü veri kümesinde ek bir ince ayar akışına sahip olan önceki modele benzer. İnce ayarlı LLM, bilgi istemi için minimum bağlam içi değere sahip SQL sorguları oluşturmak için kullanılır. Bunun için, SageMaker JumpStart'ı, etki alanına özgü bir veri kümesindeki herhangi bir modeli eğitip dağıttığınız şekilde bir LLM'ye ince ayar yapmak için kullanabilirsiniz. Amazon Adaçayı Yapıcı.
Hızlı mühendislik ve RAG
Aşağıdaki şemada, hızlı mühendislik ve RAG kullanılarak bir Yüksek Lisans ile sorgular oluşturmaya yönelik mimari gösterilmektedir.
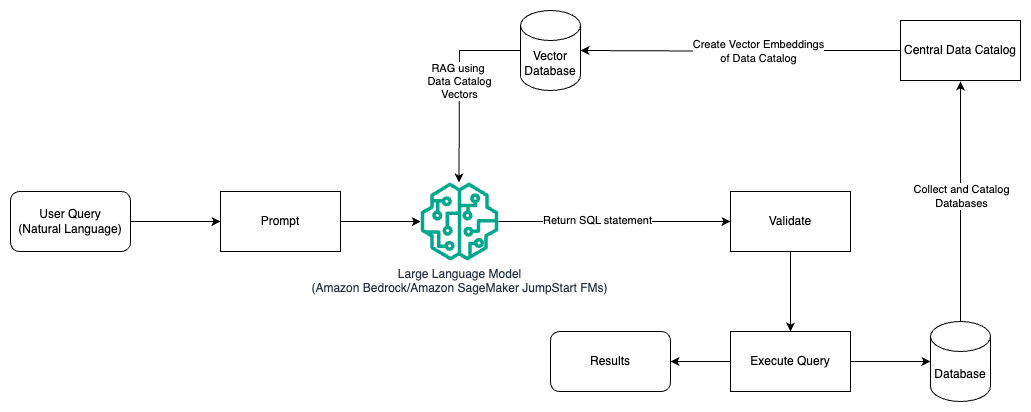
Bu desende kullandığımız Alma Artırılmış Nesil vektör yerleştirme depolarını kullanma, örneğin Amazon Titan Gömmeleri or Tutarlı Yerleştirme, Üzerinde Amazon Ana Kayası merkezi bir veri kataloğundan AWS Tutkal Veri Kataloğu, bir kuruluş içindeki veritabanlarının. Vektör yerleştirmeleri aşağıdaki gibi vektör veritabanlarında depolanır: Amazon OpenSearch Sunucusuz için Vektör Motoru, PostgreSQL için Amazon İlişkisel Veritabanı Hizmeti (Amazon RDS) ile pgvektör uzatma veya Amazon Kendrası. Yüksek Lisans'lar, SQL sorguları oluştururken tablolardan doğru veritabanını, tabloları ve sütunları daha hızlı seçmek için vektör yerleştirmelerini kullanır. Yüksek Lisans'lar tarafından alınması gereken veriler ve ilgili bilgiler birden fazla ayrı veritabanı sisteminde depolandığında ve Yüksek Lisans'ın tüm bu farklı sistemlerden veri arayabilmesi veya sorgulayabilmesi gerektiğinde RAG'ı kullanmak faydalıdır. Bu, LLM'lere merkezi veya birleşik bir veri kataloğunun vektör yerleştirmelerinin sağlanması, LLM'ler tarafından döndürülen daha doğru ve kapsamlı bilgilerin elde edilmesiyle sonuçlanır.
Sonuç
Bu yazımızda doğal dili kullanarak kurumsal verilerden SQL oluşturmaya kadar nasıl değer üretebileceğimizi tartıştık. Temel bileşenleri, optimizasyonu ve en iyi uygulamaları inceledik. Ayrıca temel istem mühendisliğinden ince ayar ve RAG'a kadar mimari kalıpları da öğrendik. Daha fazla bilgi edinmek için bkz. Amazon Ana Kayası Temel modellerle üretken yapay zeka uygulamalarını kolayca oluşturmak ve ölçeklendirmek için
Yazarlar Hakkında
 Randy DeFauw AWS'de Kıdemli Baş Çözüm Mimarıdır. Otonom araçlar için bilgisayar görüşü üzerinde çalıştığı Michigan Üniversitesi'nden bir MSEE sahibidir. Ayrıca Colorado Eyalet Üniversitesi'nden MBA derecesine sahiptir. Randy, teknoloji alanında yazılım mühendisliğinden ürün yönetimine kadar çeşitli pozisyonlarda bulundu. 2013 yılında Büyük Veri alanına girdi ve bu alanı keşfetmeye devam ediyor. Makine öğrenimi alanındaki projeler üzerinde aktif olarak çalışıyor ve Strata ve GlueCon dahil olmak üzere çok sayıda konferansta sunum yaptı.
Randy DeFauw AWS'de Kıdemli Baş Çözüm Mimarıdır. Otonom araçlar için bilgisayar görüşü üzerinde çalıştığı Michigan Üniversitesi'nden bir MSEE sahibidir. Ayrıca Colorado Eyalet Üniversitesi'nden MBA derecesine sahiptir. Randy, teknoloji alanında yazılım mühendisliğinden ürün yönetimine kadar çeşitli pozisyonlarda bulundu. 2013 yılında Büyük Veri alanına girdi ve bu alanı keşfetmeye devam ediyor. Makine öğrenimi alanındaki projeler üzerinde aktif olarak çalışıyor ve Strata ve GlueCon dahil olmak üzere çok sayıda konferansta sunum yaptı.
 Nitin Eusebios AWS'de Kıdemli Kurumsal Çözümler Mimarıdır ve Yazılım Mühendisliği, Kurumsal Mimari ve AI/ML konularında deneyimlidir. Üretken yapay zekanın olanaklarını keşfetme konusunda son derece tutkulu. AWS platformunda iyi tasarlanmış uygulamalar oluşturmalarına yardımcı olmak için müşterilerle işbirliği yapıyor ve kendisini teknolojik zorlukları çözmeye ve bulut yolculuklarına yardımcı olmaya adamıştır.
Nitin Eusebios AWS'de Kıdemli Kurumsal Çözümler Mimarıdır ve Yazılım Mühendisliği, Kurumsal Mimari ve AI/ML konularında deneyimlidir. Üretken yapay zekanın olanaklarını keşfetme konusunda son derece tutkulu. AWS platformunda iyi tasarlanmış uygulamalar oluşturmalarına yardımcı olmak için müşterilerle işbirliği yapıyor ve kendisini teknolojik zorlukları çözmeye ve bulut yolculuklarına yardımcı olmaya adamıştır.
 Arghya Banerjee San Francisco Körfez Bölgesi'ndeki AWS'de müşterilerin AWS Cloud'u benimsemesine ve kullanmasına yardımcı olmaya odaklanmış Kıdemli Çözüm Mimarıdır. Arghya, Büyük Veri, Veri Gölleri, Akış, Toplu Analitik ve AI/ML hizmetleri ve teknolojilerine odaklanmıştır.
Arghya Banerjee San Francisco Körfez Bölgesi'ndeki AWS'de müşterilerin AWS Cloud'u benimsemesine ve kullanmasına yardımcı olmaya odaklanmış Kıdemli Çözüm Mimarıdır. Arghya, Büyük Veri, Veri Gölleri, Akış, Toplu Analitik ve AI/ML hizmetleri ve teknolojilerine odaklanmıştır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

