Amazon Kinesis Veri Analizi akış verilerini gerçek zamanlı olarak dönüştürmeyi ve analiz etmeyi kolaylaştırır.
Bu gönderide, AWS'nin neden Kinesis Data Analytics for SQL Applications'tan şuna geçmeyi önerdiğini tartışacağız: Apache Flink için Amazon Kinesis Veri Analizi Apache Flink'in gelişmiş akış özelliklerinden yararlanmak için. Taşınan uygulamalarınızı dağıtmadan önce analizinizi test etmek ve ayarlamak için Kinesis Data Analytics Studio'yu nasıl kullanacağınızı da gösteriyoruz. Kinesis Data Analytics for SQL uygulamalarınız yoksa bu gönderi, veri analitiği kariyerinizde göreceğiniz birçok kullanım durumu ve Amazon Data Analytics hizmetlerinin hedeflerinize ulaşmanıza nasıl yardımcı olabileceği hakkında bir arka plan sağlamaya devam eder.
Apache Flink için Kinesis Data Analytics, tümüyle yönetilen bir Apache Flink hizmetidir. Yalnızca uygulama JAR'ınızı veya yürütülebilir dosyanızı yüklemeniz yeterlidir; altyapıyı ve Flink iş düzenlemesini AWS yönetir. İşleri kolaylaştırmak için Kinesis Data Analytics Studio, Apache Flink kullanan bir not defteri ortamıdır ve uygulamanızı dakikalar içinde üretime ölçeklendirmeden önce veri akışlarını sorgulamanıza ve SQL sorguları veya konsept kanıtı iş yükleri geliştirmenize olanak tanır.
Kinesis Data Analytics for Apache Flink veya Kinesis Data Analytics Studio yerine Kinesis Data Analytics for SQL kullanmanızı öneririz. Bunun nedeni, Apache Flink ve Kinesis Data Analytics Studio için Kinesis Data Analytics'in tam olarak bir kez işleme anlambilimi, olay zamanı pencereleri, kullanıcı tanımlı işlevler (UDF'ler) kullanılarak genişletilebilirlik ve özel entegrasyonlar, zorunlu dil desteği, dayanıklı dahil olmak üzere gelişmiş veri akışı işleme özellikleri sunmasıdır. uygulama durumu, yatay ölçeklendirme, birden çok veri kaynağı desteği ve daha fazlası. Bunlar, veri akışı işlemenin doğruluğunu, eksiksizliğini, tutarlılığını ve güvenilirliğini sağlamak için kritik öneme sahiptir ve Kinesis Data Analytics for SQL ile birlikte sunulmaz.
Çözüme genel bakış
Kullanım durumumuz için, Kinesis Data Analytics Studio'yu kullanarak örnek otomotiv sensörü verilerini gerçek zamanlı olarak yayınlamak, almak, dönüştürmek ve analiz etmek için birkaç AWS hizmeti kullanıyoruz. Kinesis Data Analytics Studio, web tabanlı bir geliştirme ortamı olan bir not defteri oluşturmamıza olanak tanır. Not defterleriyle, Apache Flink tarafından sağlanan gelişmiş yeteneklerle birleştirilmiş basit bir etkileşimli geliştirme deneyimi elde edersiniz. Kinesis Data Analytics Studio'nun kullandığı Apaçi Zeplin defter olarak ve kullanır Apache Flink'i akış işleme motoru olarak. Kinesis Data Analytics Studio dizüstü bilgisayarları, tüm beceri gruplarından geliştiricilerin erişebileceği veri akışları üzerinde gelişmiş analitiği yapmak için bu teknolojileri sorunsuz bir şekilde birleştirir. Not defterleri hızlı bir şekilde sağlanır ve akış verilerinizi anında görüntülemeniz ve analiz etmeniz için bir yol sağlar. Apache Zeppelin, Studio not defterlerinize aşağıdakiler de dahil olmak üzere eksiksiz bir analiz araçları paketi sağlar:
- Veri goruntuleme
- Verileri dosyalara aktarma
- Daha kolay analiz için çıktı formatını kontrol etme
- Dizüstü bilgisayarı ölçeklenebilir bir üretim uygulamasına dönüştürme yeteneği
SQL Uygulamaları için Kinesis Data Analytics'ten farklı olarak Kinesis Data Analytics for Apache Flink şunları ekler: aşağıdaki SQL desteği:
- Akış verilerini birden fazla Kinesis veri akışı arasında veya bir Kinesis veri akışı ile bir Kinesis veri akışı arasında birleştirme Apache Kafka için Amazon Tarafından Yönetilen Akış (Amazon MSK) konusu
- Bir veri akışında dönüştürülmüş verilerin gerçek zamanlı görselleştirilmesi
- Python betiklerini veya Scala programlarını aynı uygulama içinde kullanma
- Akış katmanının ofsetlerini değiştirme
Kinesis Data Analytics for Apache Flink'in diğer bir avantajı da, talebi karşılamak için temeldeki kaynakları ölçeklendirebileceğiniz için, konuşlandırıldıktan sonra çözümün geliştirilmiş ölçeklenebilirliğidir. SQL Uygulamaları için Kinesis Data Analytics'te ölçeklendirme, uygulamayı daha fazla kaynak eklemeye ikna etmek için daha fazla pompa eklenerek gerçekleştirilir.
Çözümümüzde, otomotiv sensör verilerine erişmek, verileri zenginleştirmek ve zenginleştirilmiş çıktıyı Kinesis Data Analytics Studio not defterinden bir dizüstü bilgisayara göndermek için bir not defteri oluşturuyoruz. Amazon Kinesis Veri İtfaiyesi bir yere teslimat için teslimat akışı Amazon Basit Depolama Hizmeti (Amazon S3) veri gölü. Bu boru hattı ayrıca şuraya veri göndermek için kullanılabilir: Amazon Açık Arama Hizmeti veya ek işleme ve görselleştirme için diğer hedefler.

SQL Uygulamaları için Kinesis Data Analytics ile Apache Flink için Kinesis Data Analytics karşılaştırması
Örneğimizde, akış verileri üzerinde aşağıdaki işlemleri gerçekleştiriyoruz:
- Bir Amazon Kinesis Veri Akışları veri akışı.
- Akış verilerini görüntüleyin.
- Verileri dönüştürün ve zenginleştirin.
- Verileri Python ile işleyin.
- Verileri bir Firehose teslim akışına yeniden aktarın.
Kinesis Data Analytics for SQL Applications ile Kinesis Data Analytics for Apache Flink'i karşılaştırmak için önce Kinesis Data Analytics for SQL Applications'ın nasıl çalıştığına bakalım.
Kinesis Data Analytics for SQL uygulamasının kökünde, uygulama içi akış kavramı bulunur. Uygulama içi akışı, üzerinde işlem yapabileceğiniz akış verilerini tutan bir tablo olarak düşünebilirsiniz. Uygulama içi akış, Kinesis veri akışı gibi bir akış kaynağına eşlenir. Verileri uygulama içi akışa almak için önce SQL için Kinesis Data Analytics uygulamanız için yönetim konsolunda bir kaynak ayarlayın. Ardından, kaynak akıştan veri okuyan ve tabloya yerleştiren bir pompa oluşturun. Pompa sorgusu sürekli olarak çalışır ve kaynak verileri uygulama içi akışa besler. Uygulama içi akışı beslemek için birden çok kaynaktan birden çok pompa oluşturabilirsiniz. Sorgular daha sonra uygulama içi akışta çalıştırılır ve sonuçlar yorumlanabilir veya daha fazla işlem veya depolama için başka hedeflere gönderilebilir.
Aşağıdaki SQL, bir uygulama içi akışın ve pompanın ayarlanmasını gösterir:
CREATE OR REPLACE STREAM "TEMPSTREAM" ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)); CREATE OR REPLACE PUMP "SAMPLEPUMP" AS INSERT INTO "TEMPSTREAM" ("column1", "column2", "column3") SELECT STREAM inputcolumn1, inputcolumn2, inputcolumn3
FROM "INPUTSTREAM";Veriler, bir SQL SELECT sorgusu kullanılarak uygulama içi akıştan okunabilir:
SELECT *
FROM "TEMPSTREAM"Kinesis Data Analytics Studio'da aynı kurulumu oluştururken, akış kaynağına bağlanmak için temeldeki Apache Flink ortamını kullanır ve bir bağlayıcı kullanarak veri akışını tek bir ifadede oluşturursunuz. Aşağıdaki örnek, daha önce kullandığımız aynı kaynağa bağlanmayı, ancak Apache Flink kullanarak gösterir:
CREATE TABLE `MY_TABLE` ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)
) WITH ( 'connector' = 'kinesis', 'stream' = sample-kinesis-stream', 'aws.region' = 'aws-kinesis-region', 'scan.stream.initpos' = 'LATEST', 'format' = 'json' );MY_TABLE artık sürekli olarak örnek Kinesis veri akışımızdan veri alacak bir veri akışıdır. Bir SQL SELECT deyimi kullanılarak sorgulanabilir:
SELECT column1, column2, column3
FROM MY_TABLE;SQL Uygulamaları için Kinesis Data Analytics bir SQL:2008 standardının alt kümesi akış verileri üzerinde işlemleri etkinleştirmek için uzantılarla, Apache Flink'in SQL desteği dayanır Apaçi KalsitSQL standardını uygulayan.
Kinesis Data Analytics Studio'nun SQL'in yanı sıra aynı dizüstü bilgisayarda PyFlink ve Scala'yı desteklediğini belirtmek de önemlidir. Bu, akış verileriniz üzerinde SQL ile mümkün olmayan karmaşık, programatik yöntemler gerçekleştirmenize olanak tanır.
Önkoşullar
Bu alıştırma sırasında çeşitli AWS kaynakları kuruyoruz ve analiz sorguları gerçekleştiriyoruz. Devam etmek için yönetici erişimine sahip bir AWS hesabına ihtiyacınız var. Yönetici erişimine sahip bir AWS hesabınız yoksa, şimdi bir tane oluştur. Bu yayında özetlenen hizmetler, AWS hesabınız için ücrete tabi olabilir. Bu yazının sonundaki temizleme talimatlarını uyguladığınızdan emin olun.
Akış verilerini yapılandırın
Akış alanında, genellikle Nesnelerin İnterneti (IoT) sensörlerinden gelen verileri keşfetmek, dönüştürmek ve zenginleştirmekle görevlendiriliriz. Gerçek zamanlı sensör verilerini oluşturmak için, AWS IoT Cihaz Simülatörü. Bu simülatör, AWS hesabınız içinde çalışır ve kullanıcıların sanal olarak bağlı cihaz filolarını kullanıcı tanımlı bir şablondan başlatmasına ve ardından bunları düzenli aralıklarla veri yayınlamak üzere simüle etmesine olanak tanıyan bir web arabirimi sağlar. AWS IoT Çekirdeği. Bu, bu alıştırma için örnek veriler oluşturmak üzere sanal bir cihaz filosu oluşturabileceğimiz anlamına gelir.
Aşağıdakileri kullanarak IoT Cihaz Simülatörünü devreye alıyoruz Amazon CloudFront şablon. Hesabınızda gerekli tüm kaynakları oluşturmayı yönetir.
- Üzerinde Yığın ayrıntılarını belirtme sayfasında, çözüm yığınınıza bir ad atayın.
- Altında parametreler, bu çözüm şablonunun parametrelerini gözden geçirin ve gerekirse değiştirin.
- İçin Kullanıcı e-postası, IoT Device Simulator Kullanıcı Arabiriminde oturum açmak için bir bağlantı ve parola almak üzere geçerli bir e-posta girin.
- Klinik Sonraki.
- Üzerinde Yığın seçeneklerini yapılandırma sayfasını seçin Sonraki.
- Üzerinde Değerlendirme sayfasında, ayarları gözden geçirin ve onaylayın. Şablonun oluşturduğunu kabul eden onay kutularını seçin. AWS Kimlik ve Erişim Yönetimi (IAM) kaynakları.
- Klinik Yığın oluştur.
Yığının yüklenmesi yaklaşık 10 dakika sürer.
- Davet e-postanızı aldığınızda CloudFront bağlantısını seçin ve e-postada verilen kimlik bilgilerini kullanarak IoT Device Simulator'da oturum açın.
Çözüm, sensör verilerini hızlı bir şekilde AWS'ye sunmaya başlamak için kullanabileceğimiz önceden oluşturulmuş bir otomotiv demosu içerir.
- Üzerinde Aygıt Türü sayfasını seçin Cihaz Türü Oluştur.
- Klinik Otomotiv Demosu.
- Yük otomatik olarak doldurulur. Cihazınız için bir ad girin ve
automotive-topickonu olarak.
- Klinik İndirim.
Şimdi bir simülasyon oluşturuyoruz.
- Üzerinde Simülasyonlar sayfasını seçin Simülasyon Oluştur.
- İçin Simülasyon türü, seçmek Otomotiv Demosu.
- İçin Bir cihaz türü seçin, oluşturduğunuz demo cihazını seçin.
- İçin Veri iletim aralığı ve Veri aktarım süresi, istediğiniz değerleri girin.
İstediğiniz değerleri girebilirsiniz, ancak her 10 saniyede bir iletim yapan en az 10 cihaz kullanın. Veri iletim sürenizi birkaç dakikaya ayarlamak isteyeceksiniz veya laboratuvar sırasında simülasyonunuzu birkaç kez yeniden başlatmanız gerekecek.
- Klinik İndirim.

Şimdi simülasyonu çalıştırabiliriz.
- Üzerinde Simülasyonlar sayfasında, istediğiniz simülasyonu seçin ve Simülasyonları başlat.
Alternatif olarak, Görüntüle Çalıştırmak istediğiniz simülasyonun yanındaki Başlama simülasyonu çalıştırmak için.
- Simülasyonu görüntülemek için seçin Görüntüle Görüntülemek istediğiniz simülasyonun yanındaki
Simülasyon çalışıyorsa, cihazların konumlarını ve IoT konusuna gönderilen en son 100 iletiyi içeren bir haritayı görüntüleyebilirsiniz.
Artık simülatörümüzün sensör verilerini AWS IoT Core'a gönderdiğinden emin olabiliriz.
- AWS IoT Core konsoluna gidin.
IoT Cihaz Simülatörünüzü devreye aldığınız Bölgede olduğunuzdan emin olun.
- Gezinti bölmesinde şunu seçin: MQTT Test İstemcisi.
- Konu filtresini girin
automotive-topicVe seç Üye olun.
Simülasyonunuz çalıştığı sürece IoT konusuna gönderilen mesajlar görüntülenecektir.

Son olarak, IoT mesajlarını bir Kinesis veri akışına yönlendirmek için bir kural belirleyebiliriz. Bu akış, Kinesis Data Analytics Studio not defteri için kaynak verilerimizi sağlayacaktır.
- AWS IoT Core konsolunda, Mesaj Yönlendirme ve kurallar.
- Kural için bir ad girin, örneğin
automotive_route_kinesis, Daha sonra seçmek Sonraki.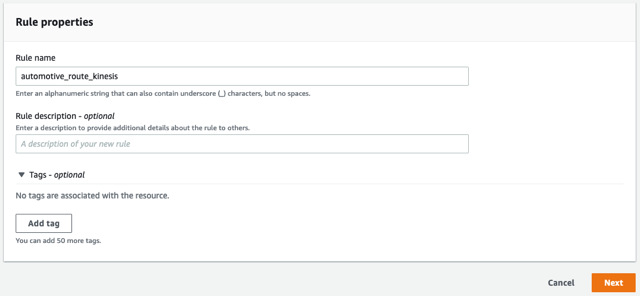
- Aşağıdaki SQL deyimini sağlayın. Bu SQL, tüm mesaj sütunlarını seçecektir.
automotive-topicIoT Device Simulator yayınlıyor:
- Klinik Sonraki.
- Altında Kural Eylemleriseçin Kinesis Akışı kaynak olarak.
- Klinik Yeni Kinesis Akışı Oluşturun.
Bu yeni bir pencere açar.
- İçin Veri akışı adı, girmek
automotive-data.
Bu alıştırma için sağlanan bir akış kullanıyoruz.
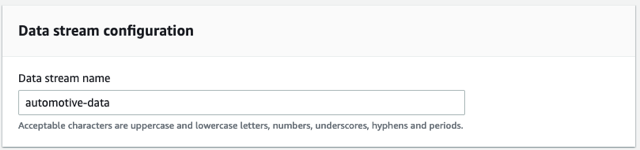
- Klinik Veri Akışı Oluştur.
Artık bu pencereyi kapatabilir ve AWS IoT Core konsoluna geri dönebilirsiniz.
- yanındaki yenile düğmesini seçin Akış adıve seçin
automotive-datadere.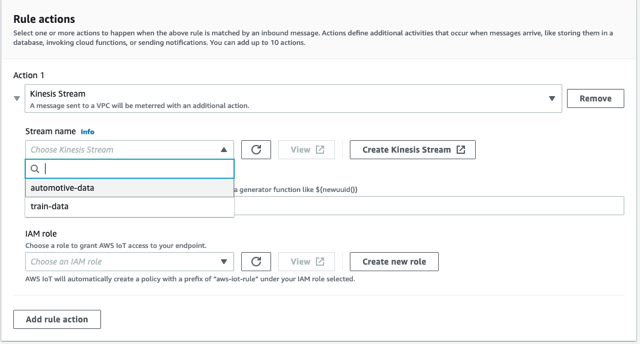
- Klinik Yeni rol oluştur ve rolü adlandırın
automotive-role. - Klinik Sonraki.
- Kural özelliklerini gözden geçirin ve seçin oluşturmak.
Kural, verileri yönlendirmeye hemen başlar.
Kinesis Data Analytics Studio'yu kurun
Artık verilerimizi AWS IoT Core aracılığıyla ve bir Kinesis veri akışına aktardığımıza göre, Kinesis Data Analytics Studio not defterimizi oluşturabiliriz.
- Amazon Kinesis konsolunda seçin Analitik uygulamaları Gezinti bölmesinde.
- Üzerinde Stüdyo sekmesini seçin Studio not defteri oluştur.
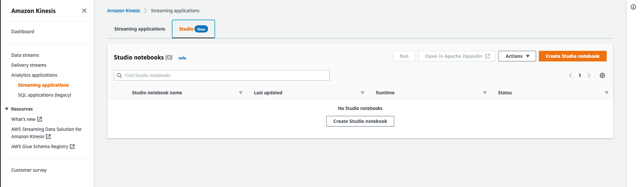
- Ayrılmak Örnek kodla hızlı oluşturma Seçilen.
- Not defterine ad verin
automotive-data-notebook.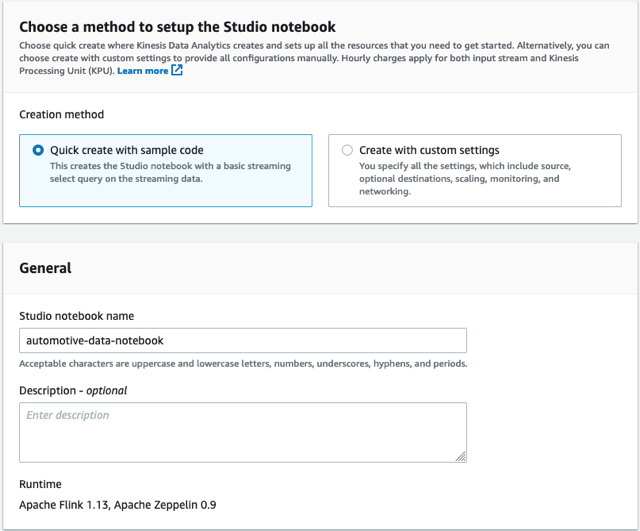
- Klinik oluşturmak yeni bir tane oluşturmak AWS Tutkal yeni bir pencerede veritabanı.
- Klinik Veritabanı ekle.

- Veritabanını adlandırın
automotive-notebook-glue. - Klinik oluşturmak.
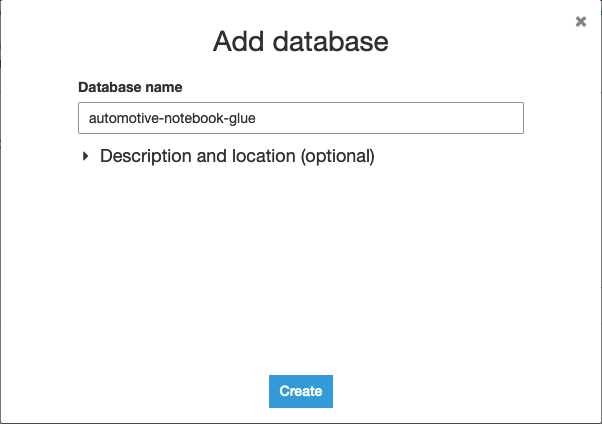
- Dönmek Studio not defteri oluştur Bölüm.
- Yenilemeyi seçin ve yeni AWS Glue veritabanınızı seçin.
- Klinik Studio not defteri oluştur.

- Studio not defterini başlatmak için koşmak ve onaylayın.

- Not defteri çalıştıktan sonra, not defterini seçin ve Apache Zeppelin'de aç.
- Klinik Notu içe aktar.
- Klinik URL'den ekle.

- Aşağıdaki URL'yi girin:
https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/BDB-2461/auto-notebook.ipynb. - Klinik İthalat Notu.

- Yeni notu açın.
Akış analizi gerçekleştirin
Bir Kinesis Data Analytics for SQL uygulamasında, akış kursumuzu yönetim konsolu aracılığıyla ekleriz ve ardından Kinesis veri akışımızdan veri akışı yapmak için bir uygulama içi akış ve pompa tanımlarız. Uygulama içi akış, verileri tutan ve sorgulamamız için kullanılabilir hale getiren bir tablo işlevi görür. Pompa, verileri kaynağımızdan alır ve uygulama içi akışımıza aktarır. Sorgular, herhangi bir SQL tablosunu sorguladığımız gibi, SQL kullanılarak uygulama içi akışa karşı çalıştırılabilir. Aşağıdaki koda bakın:
CREATE OR REPLACE STREAM "AUTOSTREAM" ( `trip_id` CHAR(36), `VIN` CHAR(17), `brake` FLOAT, `steeringWheelAngle` FLOAT, `torqueAtTransmission` FLOAT, `engineSpeed` FLOAT, `vehicleSpeed` FLOAT, `acceleration` FLOAT, `parkingBrakeStatus` BOOLEAN, `brakePedalStatus` BOOLEAN, `transmissionGearPosition` VARCHAR(10), `gearLeverPosition` VARCHAR(10), `odometer` FLOAT, `ignitionStatus` VARCHAR(4), `fuelLevel` FLOAT, `fuelConsumedSinceRestart` FLOAT, `oilTemp` FLOAT, `location` VARCHAR(100), `timestamp` TIMESTAMP(3)); CREATE OR REPLACE PUMP "MYPUMP" AS INSERT INTO "AUTOSTREAM" ("trip_id", "VIN", "brake", "steeringWheelAngle", "torqueAtTransmission", "engineSpeed", "vehicleSpeed", "acceleration", "parkingBrakeStatus", "brakePedalStatus", "transmissionGearPosition", "gearLeverPosition", "odometer", "ignitionStatus", "fuelLevel", "fuelConsumedSinceRestart", "oilTemp", "location", "timestamp")
SELECT VIN, brake, steeringWheelAngle, torqueAtTransmission, engineSpeed, vehicleSpeed, acceleration, parkingBrakeStatus, brakePedalStatus, transmissionGearPosition, gearLeverPosition, odometer, ignitionStatus, fuelLevel, fuelConsumedSinceRestart, oilTemp, location, timestamp
FROM "INPUT_STREAM"
Bir uygulama içi akışı ve pompayı Kinesis Data Analytics for SQL uygulamamızdan Kinesis Data Analytics Studio'ya taşımak için bunu pompa tanımını kaldırıp bir CREATE tanımlayarak tek bir CREATE ifadesine dönüştürüyoruz. kinesis konektör. Zeppelin not defterindeki ilk paragraf, tablo olarak sunulan bir bağlayıcı kurar. Gelen mesajdaki tüm öğeler veya bir alt küme için sütunlar tanımlayabiliriz.

İfadeyi çalıştırın ve not defterinize bir başarı sonucu yazdırın. Artık bu tabloyu SQL kullanarak sorgulayabilir veya PyFlink veya Scala kullanarak bu verilerle programlı işlemler gerçekleştirebiliriz.
Akış verileri üzerinde gerçek zamanlı analiz gerçekleştirmeden önce, verilerin şu anda nasıl biçimlendirildiğine bakalım. Bunun için az önce oluşturduğumuz tablo üzerinde basit bir Flink SQL sorgusu çalıştırıyoruz. Akış uygulamamızda kullanılan SQL, bir SQL uygulamasında kullanılanla aynıdır.

Birkaç saniye sonra kayıtları görmezseniz IoT Cihaz Simülatörünüzün hala çalışmakta olduğundan emin olun.
Kinesis Data Analytics for SQL kodunu da çalıştırıyorsanız, biraz farklı bir sonuç kümesi görebilirsiniz. Bu, Kinesis Data Analytics for Apache Flink'teki diğer bir önemli farktır, çünkü ikincisi tam olarak bir kez teslimat kavramına sahiptir. Bu uygulama üretime dağıtılırsa ve yeniden başlatılırsa veya ölçeklendirme eylemleri gerçekleşirse, Kinesis Data Analytics for Apache Flink her mesajı yalnızca bir kez almanızı sağlarken, Kinesis Data Analytics for SQL uygulamasında, emin olmak için gelen akışı daha fazla işlemeniz gerekir. sonuçlarınızı etkileyebilecek tekrarlanan mesajları görmezden gelirsiniz.
Duraklat simgesini seçerek mevcut paragrafı durdurabilirsiniz. Sorguyu durdurduğunuzda not defterinizde görüntülenen bir hata görebilirsiniz, ancak bu göz ardı edilebilir. Sadece sürecin iptal edildiğini bilmenizi sağlıyor.

Flink SQL, SQL standardını uygular ve tıpkı bir veritabanı tablosunu sorgularken yaptığınız gibi akış verileri üzerinde hesaplamalar gerçekleştirmenin kolay bir yolunu sağlar. Verileri zenginleştirirken sık yapılan bir görev, bir hesaplamayı veya dönüştürmeyi (örneğin Fahrenhayt'tan Santigrat'a) depolamak için yeni bir alan oluşturmak veya aşağı akışta daha basit sorgular veya iyileştirilmiş görselleştirmeler sağlamak için yeni veriler oluşturmaktır. adlı bir Boole değerini nasıl ekleyebileceğimizi görmek için sonraki paragrafı çalıştırın. accelerating, sensörün okunduğu sırada bir otomobilin o anda hızlanıp hızlanmadığını öğrenmek için lavabomuzda kolayca kullanabileceğimiz. Buradaki süreç Kinesis Data Analytics for SQL ve Kinesis Data Analytics for Apache Flink arasında farklılık göstermez.

Yeni Boole değerimizi FLOAT ile karşılaştırarak yeni sütunu incelediğinizde paragrafın çalışmasını durdurabilirsiniz. acceleration sütun.
Gecikmeyi ve performansı iyileştirmek için bir sensörden gönderilen veriler genellikle kompakttır. Veri akışını harici verilerle zenginleştirebilmek ve ek araç bilgileri veya güncel hava durumu verileri gibi akışı zenginleştirmek çok yararlı olabilir. Bu örnekte, şu anda Amazon S3'te bir CSV'de depolanan verileri getirmek ve mevcut motor hızı bandını yansıtan color adlı bir sütun eklemek istediğimizi varsayalım.
Apache Flink SQL birkaç sağlar kaynak konektörleri AWS hizmetleri ve diğer kaynaklar için. İlk paragrafta yaptığımız gibi yeni bir tablo oluşturmak, bunun yerine dosya sistemi bağlayıcısını kullanmak, Flink'in doğrudan Amazon S3'e bağlanmasına ve kaynak verilerimizi okumasına izin verir. Daha önce SQL Uygulamaları için Kinesis Data Analytics'te satır içi yeni referanslar ekleyemiyordunuz. Senin yerine tanımlı S3 referans verileri ve daha sonra bir SQL JOIN'de referans olarak kullanabileceğiniz uygulama yapılandırmanıza ekledi.
NOT: us-east-1 bölgesini kullanmıyorsanız, csv'yi indir ve nesneyi kendi S3 kovanıza yerleştirin. csv dosyasına şu şekilde başvuruda bulunun: s3a://<bucket-name>/<key-name>

Son sorguyu temel alan bir sonraki paragraf, mevcut verilerimiz ve oluşturduğumuz yeni arama kaynak tablosu üzerinde bir SQL JOIN gerçekleştirir.

Artık zenginleştirilmiş bir veri akışımız olduğuna göre, bu verileri yeniden yayınlıyoruz. Gerçek dünya senaryosunda, verileri bir S3 veri gölüne, daha fazla analiz için başka bir Kinesis veri akışına göndermek veya görselleştirme için OpenSearch Hizmetinde depolamak gibi verilerimizle ne yapacağımız konusunda birçok seçeneğimiz vardır. Kolaylık sağlamak için verileri, veri gölümüz görevi gören bir S3 klasörüne aktaran Kinesis Data Firehose'a gönderiyoruz.
Kinesis Data Firehose, verileri Amazon S3'e, OpenSearch Service'e aktarabilir, Amazon Kırmızıya Kaydırma veri ambarları ve Splunk yalnızca birkaç tıklamayla.
Kinesis Data Firehose teslim akışını oluşturun
Teslimat akışımızı oluşturmak için aşağıdaki adımları tamamlayın:
- Kinesis Data Firehose konsolunda, Teslimat akışı oluştur.
- Klinik Doğrudan PUT akış kaynağı için ve Amazon S3 hedef olarak.

- Teslimat akışınızı otomotiv-yangın hortumu olarak adlandırın.

- Altında Hedef ayarları, yeni bir grup oluşturun veya mevcut bir grubu kullanın.
- S3 grup URL'sini not edin.
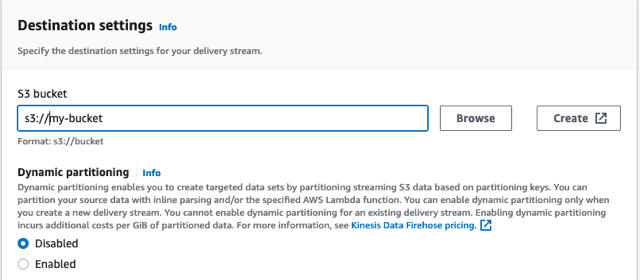
- Klinik Teslimat akışı oluştur.
Akışın oluşturulması birkaç saniye sürer.
- Kinesis Data Analytics konsoluna dönün ve seçin Akış uygulamaları.
- Üzerinde Stüdyo sekmesine gidin ve Studio not defterinizi seçin.

- altındaki bağlantıyı seçin IAM rolü.

- IAM penceresinde, İzin ekle ve Politikaları ekleyin.
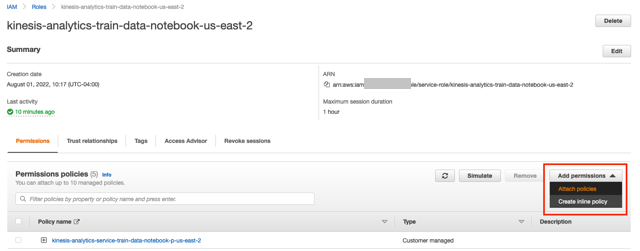
- AmazonKinesisFullAccess ve CloudWatchFullAccess'i arayın ve seçin, ardından seçin Politika ekleyin.
- Zeppelin defterinize geri dönebilirsiniz.
Verileri Kinesis Data Firehose'a aktarın
Apache Flink v1.15'ten itibaren, Firehose teslim akışına bağlayıcı oluşturmak, herhangi bir Kinesis veri akışına bağlayıcı oluşturmaya benzer şekilde çalışmaktadır. İki fark olduğunu unutmayın: bağlayıcı firehoseve akış özniteliği şu hale gelir: delivery-stream.

Bağlayıcı oluşturulduktan sonra bağlayıcıya herhangi bir SQL tablosu gibi yazabiliriz.

Teslim akışı aracılığıyla veri aldığımızı doğrulamak için Amazon S3 konsolunu açın ve oluşturulan dosyaları gördüğünüzü onaylayın. Yeni verileri incelemek için dosyayı açın.
Kinesis Data Analytics for SQL Applications'ta, SQL uygulama panosunda yeni bir hedef oluşturmuş olurduk. Mevcut bir hedefi taşımak için, not defterinize yeni hedefi doğrudan kodun içinde tanımlayan bir SQL deyimi eklersiniz. Yeni tablo adına atıfta bulunurken bir INSERT ile yaptığınız gibi yeni hedefe yazmaya devam edebilirsiniz.
Zaman verileri
Kinesis Data Analytics Studio not defterlerinde gerçekleştirebileceğiniz başka bir yaygın işlem, belirli bir zaman aralığında toplama işlemidir. Bu tür veriler, anormallikleri belirlemek, uyarılar göndermek veya daha sonraki işlemler için saklanmak üzere başka bir Kinesis veri akışına göndermek için kullanılabilir. Bir sonraki paragraf, yuvarlanan bir pencere kullanan ve otomotiv filosu için tüketilen toplam yakıtı 30 saniyelik dönemler için toplayan bir SQL sorgusu içerir. Son örneğimizde olduğu gibi, başka bir veri akışına bağlanabilir ve bu verileri daha fazla analiz için ekleyebiliriz.

Scala ve PyFlink
Veri akışınızda gerçekleştireceğiniz bir işlevin hem basitlik hem de bakım açısından SQL yerine bir programlama dilinde yazılmasının daha iyi olduğu zamanlar vardır. Bazı örnekler, SQL işlevlerinin yerel olarak desteklemediği karmaşık hesaplamaları, belirli dize manipülasyonlarını, verilerin birden çok akışa bölünmesini ve diğer AWS hizmetleriyle etkileşimi (metin çevirisi veya duyarlılık analizi gibi) içerir. Apache Flink için Kinesis Data Analytics, birden çok Flink tercümanları SQL Uygulamaları için Kinesis Data Analytics'te bulunmayan Zeppelin not defteri içinde.
Verilerimize yakından dikkat ettiyseniz, konum alanının bir JSON dizesi olduğunu göreceksiniz. Kinesis Data Analytics for SQL'de, dize işlevlerini kullanabilir ve bir SQL işlevi ve JSON dizesini parçalara ayırın. Bu, mesaj verilerinin kararlılığına bağlı olarak kırılgan bir yaklaşımdır, ancak bu, birkaç SQL işleviyle geliştirilebilir. Kinesis Data Analytics for SQL'de bir işlev oluşturmaya yönelik sözdizimi şu kalıbı izler:
CREATE FUNCTION ''<function_name>'' ( ''<parameter_list>'' ) RETURNS ''<data type>'' LANGUAGE SQL [ SPECIFIC ''<specific_function_name>'' | [NOT] DETERMINISTIC ] CONTAINS SQL [ READS SQL DATA ] [ MODIFIES SQL DATA ] [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ] RETURN ''<SQL-defined function body>''
AWS, Apache Flink için Kinesis Data Analytics'te yakın zamanda Apache Flink ortamını v1.15'e yükseltti; bu, Apache Flink SQL'in SQL tablosunu şu şekilde genişletir: JSON işlevleri ekle JSON Yolu sözdizimine benzer. Bu, JSON dizesini doğrudan SQL'imizde sorgulamamızı sağlar. Aşağıdaki koda bakın:
%flink.ssql(type=update)
SELECT JSON_STRING(location, ‘$.latitude) AS latitude,
JSON_STRING(location, ‘$.longitude) AS longitude
FROM my_tableAlternatif olarak ve Apache Flink v1.15'ten önce gerekli olan alanı dönüştürmek ve verileri yeniden akışa almak için not defterimizde Scala veya PyFlink kullanabiliriz. Her iki dil de sağlam JSON dizesi işleme sağlar.
Aşağıdaki PyFlink kodu iki tane tanımlar kullanıcı tanımlı fonksiyonlar, mesajımızın konum alanından enlem ve boylamı ayıklar. Bu UDF'ler daha sonra Flink SQL kullanılarak çağrılabilir. St_env ortam değişkenine başvuruyoruz. PyFlink oluşturur altı değişken Zeppelin defterinizde sizin için. Zeppelin ayrıca bir bağlam z değişkeni olarak sizin için.


İletiler beklenmeyen veriler içerdiğinde de hatalar oluşabilir. Kinesis Data Analytics for SQL Applications, bir uygulama içi hata akışı sağlar. Bu hatalar daha sonra ayrı ayrı işlenebilir ve yeniden yayınlanabilir veya bırakılabilir. Kinesis Data Analytics Streaming uygulamalarında PyFlink ile karmaşık hata işleme stratejileri yazabilir ve verileri hemen kurtarıp işlemeye devam edebilirsiniz. JSON dizesi UDF'ye iletildiğinde hatalı biçimlendirilmiş, eksik veya boş olabilir. Python, UDF'deki hatayı yakalayarak, bir hata oluşmuş olsa bile her zaman bir değer döndürür.
Aşağıdaki örnek kod, iki alanda bölme hesaplaması yapan başka bir PyFlink parçacığını göstermektedir. Sıfıra bölme hatasıyla karşılaşılırsa, akışın mesajı işlemeye devam edebilmesi için varsayılan bir değer sağlar.
%flink.pyflink
@udf(input_types=[DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def DivideByZero(price): try: price / 0 except: return -1
st_env.register_function("DivideByZero", DivideByZero)
Sonraki adımlar
Bu gönderide yaptığımız gibi bir ardışık düzen oluşturmak, bize AWS'de ek hizmetleri test etmek için temel sağlar. Oluşturduğunuz akışları parçalamadan önce akış analizi öğreniminize devam etmenizi tavsiye ederim. Aşağıdakileri göz önünde bulundur:
Temizlemek
Bu alıştırmada oluşturulan hizmetleri temizlemek için aşağıdaki adımları tamamlayın:
- CloudFormation Konsoluna gidin ve IoT Device Simulator yığınını silin.
- AWS IoT Core konsolunda, Mesaj Yönlendirme ve Kurallar'ı seçin ve kuralı silin
automotive_route_kinesis. - Kinesis veri akışını silin
automotive-dataKinesis Veri Akışı konsolunda. - IAM rolünü kaldır
automotive-roleIAM Konsolunda. - AWS Glue konsolunda şunu silin:
automotive-notebook-glueveri tabanı. - Kinesis Data Analytics Studio not defterini silin
automotive-data-notebook. - Firehose teslim akışını silin
automotive-firehose.
Sonuç
Kinesis Data Analytics Studio'daki bu öğreticiyi takip ettiğiniz için teşekkür ederiz. Şu anda eski bir Kinesis Data Analytics Studio SQL uygulaması kullanıyorsanız, AWS teknik hesap yöneticiniz veya Çözüm Mimarı ile iletişime geçmenizi ve Kinesis Data Analytics Studio'ya geçiş konusunu görüşmenizi tavsiye ederim. Öğrenme yolunuza devam edebilirsiniz. Amazon Kinesis Veri Akışları Geliştirici Kılavuzuve bizim GitHub'daki kod örnekleri.
Yazar Hakkında
 Nicholas Tüney AWS'de Dünya Çapında Kamu Sektörü için İş Ortağı Çözümleri Mimarıdır. Devlet, kar amacı gütmeyen sağlık, kamu hizmeti ve eğitim sektörlerindeki müşteriler için AWS üzerinde mimariler geliştirmek üzere küresel SI iş ortaklarıyla birlikte çalışır.
Nicholas Tüney AWS'de Dünya Çapında Kamu Sektörü için İş Ortağı Çözümleri Mimarıdır. Devlet, kar amacı gütmeyen sağlık, kamu hizmeti ve eğitim sektörlerindeki müşteriler için AWS üzerinde mimariler geliştirmek üzere küresel SI iş ortaklarıyla birlikte çalışır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/migrate-from-amazon-kinesis-data-analytics-for-sql-applications-to-amazon-kinesis-data-analytics-studio/

