Bu yazıda, model performansını artırmak ve çıkarım sürelerini azaltmak amacıyla ince ayarlı bir BERT modelini sıkıştırmak için sinir mimarisi arama (NAS) tabanlı yapısal budamanın nasıl kullanılacağını gösteriyoruz. Önceden eğitilmiş dil modelleri (PLM'ler), üretkenlik araçları, müşteri hizmetleri, arama ve öneriler, iş süreci otomasyonu ve içerik oluşturma alanlarında ticari ve kurumsal olarak hızla benimsenmektedir. PLM çıkarım uç noktalarının konuşlandırılması, genellikle bilgi işlem gereksinimleri nedeniyle daha yüksek gecikme ve daha yüksek altyapı maliyetleriyle ve çok sayıda parametre nedeniyle azalan hesaplama verimliliğiyle ilişkilendirilir. Bir PLM'nin budanması, tahmin yeteneklerini korurken modelin boyutunu ve karmaşıklığını azaltır. Budanmış PLM'ler daha küçük bir bellek alanı ve daha düşük gecikme süresi elde eder. Bir PLM'yi budayarak ve belirli bir hedef görev için parametre sayımı ve doğrulama hatasından vazgeçerek, temel PLM modeliyle karşılaştırıldığında daha hızlı yanıt süreleri elde edebildiğimizi gösteriyoruz.
Çok amaçlı optimizasyon, bellek tüketimi, eğitim süresi ve bilgi işlem kaynakları gibi birden fazla amaç fonksiyonunun eş zamanlı olarak optimize edilmesini sağlayan bir karar verme alanıdır. Yapısal budama, model doğruluğunu korumaya çalışırken katmanları veya nöronları/düğümleri budayarak PLM'nin boyutunu ve hesaplama gereksinimlerini azaltan bir tekniktir. Yapısal budama, katmanları kaldırarak daha yüksek sıkıştırma oranlarına ulaşır ve bu da çalışma sürelerini ve yanıt sürelerini azaltan donanım dostu yapısal seyrekliğe yol açar. Bir PLM modeline yapısal budama tekniğinin uygulanması, SageMaker'da bir çıkarım uç noktası olarak barındırıldığında, orijinal ince ayarlı PLM ile karşılaştırıldığında gelişmiş kaynak verimliliği ve daha düşük maliyet sunan, daha düşük bellek ayak izine sahip daha hafif bir modelle sonuçlanır.
Bu yazıda gösterilen kavramlar, öneri sistemleri, duyarlılık analizi ve arama motorları gibi PLM özelliklerini kullanan uygulamalara uygulanabilir. Özellikle, etki alanına özgü veri kümelerini kullanarak kendi PLM modellerinde ince ayar yapan ve çok sayıda çıkarım uç noktasını dağıtan özel makine öğrenimi (ML) ve veri bilimi ekipleriniz varsa bu yaklaşımı kullanabilirsiniz. Amazon Adaçayı Yapıcı. Bunun bir örneği, metin özetleme, ürün kataloğu sınıflandırması ve ürün geri bildirim duyarlılığı sınıflandırması için çok sayıda çıkarım uç noktası dağıtan çevrimiçi bir perakendecidir. Başka bir örnek, klinik belge sınıflandırması, tıbbi raporlardan adlandırılmış varlık tanıma, tıbbi sohbet robotları ve hasta risk sınıflandırması için PLM çıkarım uç noktalarını kullanan bir sağlık hizmeti sağlayıcısı olabilir.
Çözüme genel bakış
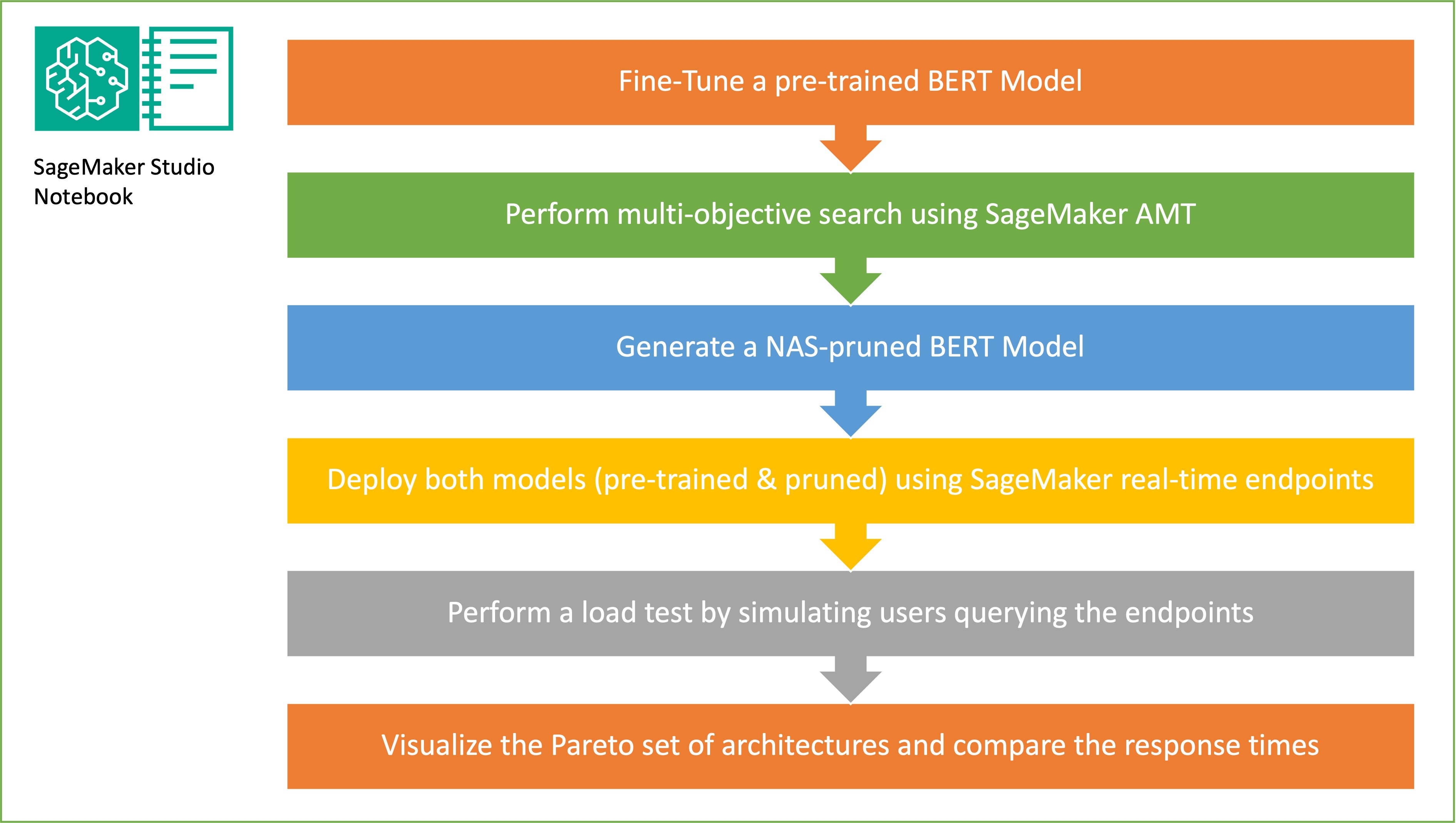
Bu bölümde genel iş akışını sunacağız ve yaklaşımı açıklayacağız. İlk önce bir kullanıyoruz Amazon SageMaker Stüdyosu defter Etki alanına özgü bir veri kümesi kullanarak önceden eğitilmiş bir BERT modeline hedef görevde ince ayar yapmak. Bert (Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri), aşağıdakileri temel alan önceden eğitilmiş bir dil modelidir: transformatör mimarisi doğal dil işleme (NLP) görevleri için kullanılır. Sinir mimarisi araması (NAS), yapay sinir ağlarının tasarımını otomatikleştirmeye yönelik bir yaklaşımdır ve makine öğrenimi alanında yaygın olarak kullanılan bir yaklaşım olan hiperparametre optimizasyonu ile yakından ilgilidir. NAS'ın amacı, gradyansız optimizasyon gibi teknikleri kullanarak geniş bir aday mimari kümesi üzerinde arama yaparak veya istenen ölçümleri optimize ederek belirli bir sorun için en uygun mimariyi bulmaktır. Mimarinin performansı genellikle doğrulama kaybı gibi ölçümler kullanılarak ölçülür. SageMaker Otomatik Model Ayarlama (AMT), en iyi model performansını sağlayan ML modelinin hiperparametrelerinin optimal kombinasyonlarını bulmaya yönelik sıkıcı ve karmaşık süreci otomatikleştirir. AMT, belirttiğiniz bir dizi hiper parametreyi kullanarak akıllı arama algoritmaları ve yinelemeli değerlendirmeler kullanır. Doğruluk ve F-1 puanı gibi performans ölçümleriyle ölçülen, en iyi performansı gösteren modeli oluşturan hiperparametre değerlerini seçer.
Bu yazıda açıklanan ince ayar yaklaşımı geneldir ve herhangi bir metin tabanlı veri kümesine uygulanabilir. BERT PLM'ye atanan görev; duygu analizi, metin sınıflandırma veya Soru-Cevap gibi metin tabanlı bir görev olabilir. Bu demoda hedef görev, metin parçası çiftlerinden oluşan bir veri kümesinden, bir metin parçasının anlamının diğer parçadan çıkarılıp çıkarılamayacağını belirlemek için BERT'in kullanıldığı ikili bir sınıflandırma problemidir. biz kullanıyoruz Metinsel Gereklilik veri kümesini tanıma GLUE kıyaslama paketinden. Hedef görev için parametre sayısı ve tahmin doğruluğu arasında en uygun dengeyi sunan alt ağları belirlemek için SageMaker AMT'yi kullanarak çok amaçlı bir arama gerçekleştiriyoruz. Çok amaçlı bir arama gerçekleştirirken, optimize etmeyi hedeflediğimiz hedefler olarak doğruluğu ve parametre sayısını tanımlamakla başlarız.
BERT PLM ağı içerisinde, modelin dil anlama ve bilgi temsili gibi özel yeteneklere sahip olmasına olanak tanıyan modüler, kendi kendine yeten alt ağlar bulunabilir. BERT PLM, çok başlı bir kişisel dikkat alt ağı ve ileri beslemeli bir alt ağ kullanır. Çok başlı, öz-dikkat katmanı, birden fazla kafanın birden fazla bağlam sinyaline katılmasına izin vererek dizinin bir temsilini hesaplamak amacıyla BERT'in tek bir dizinin farklı konumlarını ilişkilendirmesine olanak tanır. Girdi birden fazla alt alana bölünür ve kişisel dikkat alt alanların her birine ayrı ayrı uygulanır. Bir transformatör PLM'sindeki çoklu kafalar, modelin farklı temsil alt alanlarından gelen bilgilere ortaklaşa katılmasına olanak tanır. İleri beslemeli bir alt ağ, çok başlı öz dikkat alt ağından çıktıyı alan, verileri işleyen ve son kodlayıcı temsillerini döndüren basit bir sinir ağıdır.
Rastgele alt ağ örneklemesinin amacı, hedef görevlerde yeterince iyi performans gösterebilecek daha küçük BERT modellerini eğitmektir. İnce ayarlı temel BERT modelinden 100 rastgele alt ağı örnekliyoruz ve 10 ağı aynı anda değerlendiriyoruz. Eğitilen alt ağlar, objektif metrikler için değerlendirilir ve nihai model, objektif metrikler arasında bulunan dengelere göre seçilir. görselleştiriyoruz Pareto cephesi model doğruluğu ve model boyutu arasında en uygun dengeyi sunan budanmış modeli içeren örneklenmiş alt ağlar için. Aday alt ağı (NAS ile budanmış BERT modeli), ödün vermek istediğimiz model boyutuna ve model doğruluğuna göre seçiyoruz. Daha sonra uç noktaları, önceden eğitilmiş BERT temel modelini ve SageMaker'ı kullanarak NAS ile budanmış BERT modelini barındırıyoruz. Yük testi gerçekleştirmek için şunu kullanırız: keçiboynuzuPython kullanarak uygulayabileceğiniz açık kaynaklı bir yük test aracı. Locust'u kullanarak her iki uç noktada da yük testi yapıyoruz ve her iki model için yanıt süreleri ile doğruluk arasındaki dengeyi göstermek için Pareto cephesini kullanarak sonuçları görselleştiriyoruz. Aşağıdaki şema, bu yazıda açıklanan iş akışına genel bir bakış sunmaktadır.
Önkoşullar
Bu yazı için aşağıdaki önkoşullar gereklidir:
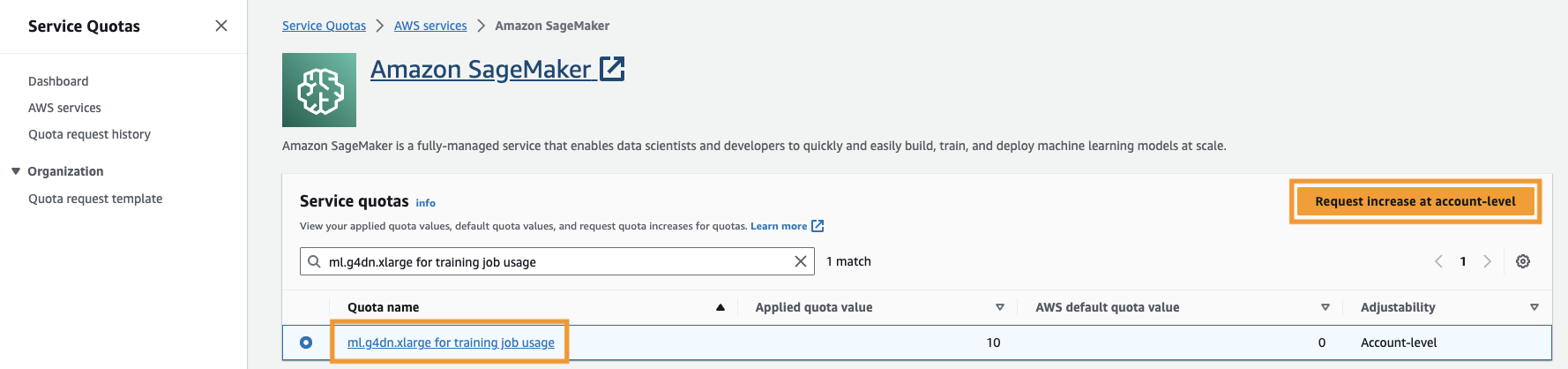
Ayrıca artırmanız gerekir hizmet kotası SageMaker'da en az üç ml.g4dn.xlarge örneğine erişmek için. ml.g4dn.xlarge örnek türü, PyTorch'u yerel olarak çalıştırmanıza olanak tanıyan uygun maliyetli GPU örneğidir. Hizmet kotasını artırmak için aşağıdaki adımları tamamlayın:
- Konsolda Hizmet Kotaları'na gidin.
- İçin Kotaları yönet, seçmek Amazon Adaçayı Yapıcı, Daha sonra seçmek Kotaları görüntüle.

- "ML-g4dn.xlarge for training job use" ifadesini arayın ve kota öğesini seçin.
- Klinik Hesap düzeyinde artış isteğinde bulunma.
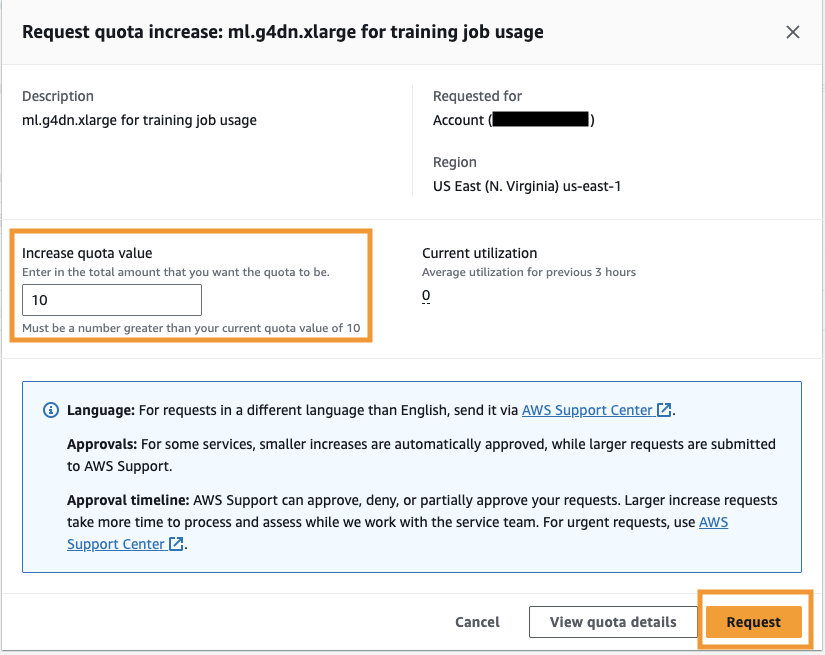
- İçin Kota değerini artırın5 veya daha yüksek bir değer girin.
- Klinik Talep et.
İstenilen kota onayının tamamlanması, hesap izinlerine bağlı olarak biraz zaman alabilir.
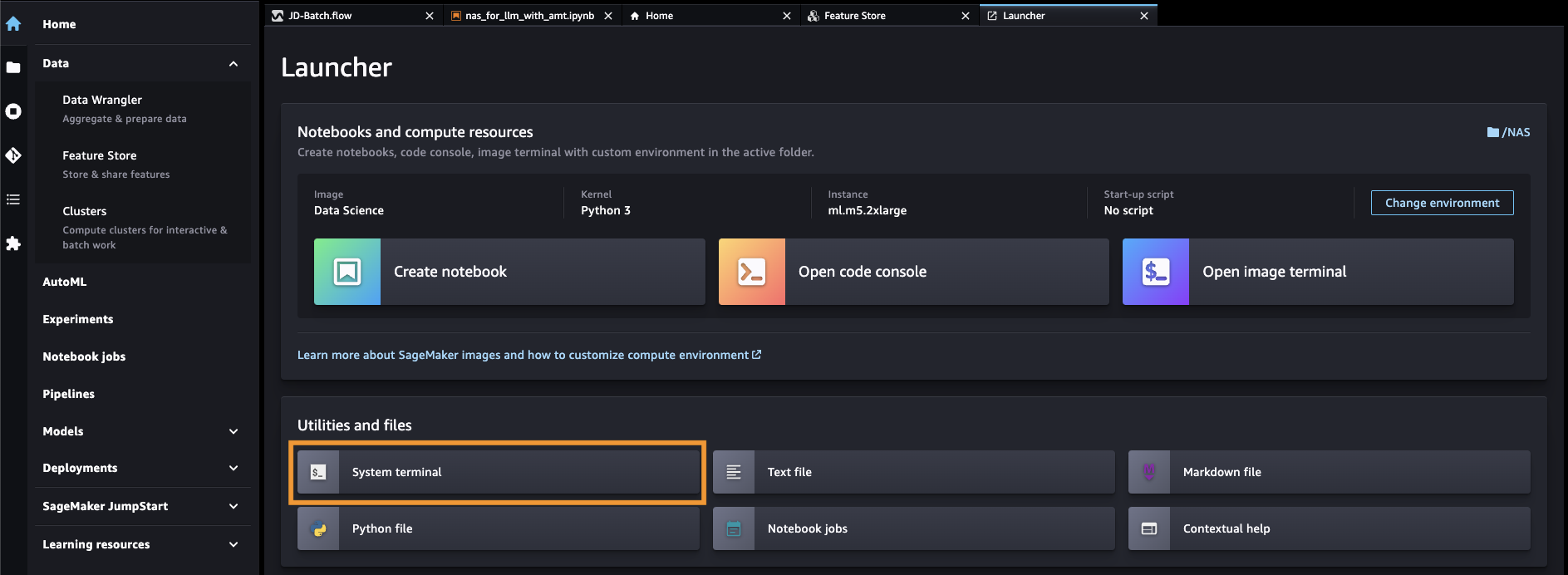
- SageMaker konsolundan SageMaker Studio'yu açın.

- Klinik Sistem terminali altında Yardımcı programlar ve dosyalar.
- Klonlamak için aşağıdaki komutu çalıştırın GitHub repo SageMaker Studio örneğine:
- Şu yöne rotayı ayarla
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Dosyayı açın
nas_for_llm_with_amt.ipynb. - Ortamı bir şekilde ayarlayın
ml.g4dn.xlargeörnek ve seç seç.
Önceden eğitilmiş BERT modelini ayarlama
Bu bölümde, Recognizing Textual Entailment veri kümesini veri kümesi kitaplığından içe aktarıyoruz ve veri kümesini eğitim ve doğrulama kümelerine ayırıyoruz. Bu veri seti cümle çiftlerinden oluşur. BERT PLM'nin görevi, iki metin parçası verildiğinde, bir metin parçasının anlamının diğer parçadan çıkarılıp çıkarılamayacağını tespit etmektir. Aşağıdaki örnekte, ilk cümlenin anlamını ikinci cümleden çıkarabiliriz:
Metinsel tanıma zorunluluğu veri kümesini şuradan yüklüyoruz: YAPIŞTIRICI kıyaslama paketi aracılığıyla veri kümesi kitaplığı eğitim senaryomuzdaki Hugging Face'ten (./training.py). GLUE'dan gelen orijinal eğitim veri setini bir eğitim ve doğrulama setine ayırdık. Yaklaşımımızda, eğitim veri kümesini kullanarak temel BERT modeline ince ayar yapıyoruz, ardından hedef ölçümler arasında en iyi dengeyi sağlayan alt ağlar kümesini belirlemek için çok amaçlı bir arama gerçekleştiriyoruz. Eğitim veri kümesini yalnızca BERT modeline ince ayar yapmak için kullanıyoruz. Ancak, çok amaçlı arama için doğrulama verilerini, uzatma doğrulama veri kümesindeki doğruluğu ölçerek kullanırız.
Etki alanına özgü bir veri kümesi kullanarak BERT PLM'de ince ayar yapın
Ham bir BERT modelinin tipik kullanım durumları, sonraki cümle tahminini veya maskelenmiş dil modellemeyi içerir. Temel BERT modelini metin tanıma zorunluluğu gibi aşağı yönlü görevler için kullanmak için, alana özgü bir veri kümesi kullanarak modelde daha fazla ince ayar yapmamız gerekir. Sıra sınıflandırması, soru yanıtlama ve belirteç sınıflandırması gibi görevler için ince ayarlı bir BERT modelini kullanabilirsiniz. Ancak bu demoda ikili sınıflandırma için ince ayarlı modeli kullanıyoruz. Aşağıdaki hiperparametreleri kullanarak önceden hazırladığımız eğitim veri seti ile önceden eğitilmiş BERT modeline ince ayar yapıyoruz:
Model eğitiminin kontrol noktasını bir Amazon Basit Depolama Hizmeti (Amazon S3) kovası, böylece model NAS tabanlı çok amaçlı arama sırasında yüklenebiliyor. Modeli eğitmeden önce çağ, eğitim kaybı, parametre sayısı ve doğrulama hatası gibi metrikleri tanımlarız:
İnce ayar süreci başladıktan sonra eğitim işinin tamamlanması yaklaşık 15 dakika sürer.
Alt ağları seçmek ve sonuçları görselleştirmek için çok amaçlı bir arama gerçekleştirin
Bir sonraki adımda, SageMaker AMT kullanarak rastgele alt ağları örnekleyerek ince ayarlı temel BERT modelinde çok amaçlı bir arama gerçekleştiriyoruz. Süper ağ içindeki bir alt ağa erişmek için (ince ayarlı BERT modeli), PLM'nin alt ağın parçası olmayan tüm bileşenlerini maskeliyoruz. Bir PLM'de alt ağları bulmak için bir süper ağı maskelemek, modelin davranış kalıplarını izole etmek ve tanımlamak için kullanılan bir tekniktir. Hugging Face transformatörlerinin gizli boyutun kafa sayısının katı olması gerektiğini unutmayın. Transformatör PLM'sindeki gizli boyut, gizli durum vektör uzayının boyutunu kontrol eder; bu da modelin verilerdeki karmaşık gösterimleri ve kalıpları öğrenme yeteneğini etkiler. Bir BERT PLM'de gizli durum vektörü sabit boyuttadır (768). Gizli boyutu değiştiremiyoruz ve bu nedenle tura sayısının [1, 3, 6, 12] olması gerekiyor.
Tek hedefli optimizasyonun aksine, çok hedefli ortamda genellikle tüm hedefleri aynı anda optimize eden tek bir çözümümüz yoktur. Bunun yerine, en az bir amaçta (doğrulama hatası gibi) diğer tüm çözümlere hakim olan bir dizi çözümü toplamayı hedefliyoruz. Artık azaltmak istediğimiz metrikleri (doğrulama hatası ve parametre sayısı) ayarlayarak AMT üzerinden çok amaçlı aramaya başlayabiliriz. Rastgele alt ağlar parametre tarafından tanımlanır max_jobs ve eşzamanlı işlerin sayısı parametre ile tanımlanır max_parallel_jobs. Model kontrol noktasını yüklemek ve alt ağı değerlendirmek için gereken kod şu adreste mevcuttur: evaluate_subnetwork.py komut.
AMT ayarlama işinin yürütülmesi yaklaşık 2 saat 20 dakika sürer. AMT ayarlama işi başarılı bir şekilde çalıştırıldıktan sonra, işin geçmişini ayrıştırır ve kafa sayısı, katman sayısı, birim sayısı gibi alt ağın yapılandırmalarını ve doğrulama hatası ve parametre sayısı gibi karşılık gelen ölçümleri toplarız. Aşağıdaki ekran görüntüsü başarılı bir AMT tuner işinin özetini göstermektedir.
Daha sonra, sonuçları bir Pareto kümesi (Pareto sınırı veya Pareto optimal kümesi olarak da bilinir) kullanarak görselleştiririz; bu, nesnel metrikte (doğrulama hatası) diğer tüm alt ağlara hakim olan en uygun alt ağ kümelerini belirlememize yardımcı olur:
İlk olarak AMT ayarlama işinden verileri topluyoruz. Daha sonra Pareto kümesini kullanarak grafiğini çizeriz. matplotlob.pyplot x ekseninde parametre sayısı ve y ekseninde doğrulama hatası. Bu, Pareto kümesinin bir alt ağından diğerine geçtiğimizde ya performanstan ya da model boyutundan fedakarlık edip diğerini geliştirmemiz gerektiği anlamına gelir. Sonuçta Pareto seti bize tercihlerimize en uygun alt ağı seçme esnekliği sağlar. Ağımızın boyutunu ne kadar azaltmak istediğimize ve performanstan ne kadar feda etmeye hazır olduğumuza karar verebiliriz.

SageMaker'ı kullanarak ince ayarlı BERT modelini ve NAS için optimize edilmiş alt ağ modelini dağıtın
Daha sonra, Pareto kümemizdeki en küçük performans düşüşüne yol açan en büyük modeli konuşlandırıyoruz. SageMaker uç noktası. En iyi model, kullanım durumumuz için doğrulama hatası ile parametre sayısı arasında en uygun dengeyi sağlayan modeldir.
Model karşılaştırması
Önceden eğitilmiş bir temel BERT modelini aldık, etki alanına özgü bir veri kümesi kullanarak ince ayar yaptık, nesnel ölçümlere dayalı olarak baskın alt ağları belirlemek için bir NAS araması yürüttük ve budanmış modeli bir SageMaker uç noktasına yerleştirdik. Ek olarak, önceden eğitilmiş temel BERT modelini aldık ve temel modeli ikinci bir SageMaker uç noktasına yerleştirdik. Sonra koştuk yük testi Locust'u her iki çıkarım uç noktasında kullanarak ve performansı yanıt süresi açısından değerlendirdi.
Öncelikle gerekli Locust ve Boto3 kütüphanelerini import ediyoruz. Daha sonra bir istek meta verisi oluşturuyoruz ve yük testi için kullanılacak başlangıç zamanını kaydediyoruz. Daha sonra veri, gerçek kullanıcı isteklerini simüle etmek için BotoClient aracılığıyla SageMaker uç noktası çağırma API'sine aktarılır. İstekleri paralel olarak göndermek ve yük altındaki uç nokta performansını ölçmek üzere birden fazla sanal kullanıcı oluşturmak için Locust'u kullanıyoruz. Testler, sırasıyla iki uç noktanın her biri için kullanıcı sayısı artırılarak gerçekleştirilir. Testler tamamlandıktan sonra Locust, dağıtılan modellerin her biri için bir istek istatistikleri CSV dosyası çıkarır.
Daha sonra, testleri Locust ile çalıştırdıktan sonra indirilen CSV dosyalarından yanıt süresi grafiklerini oluşturuyoruz. Yanıt süresini kullanıcı sayısına göre çizmenin amacı, model uç noktalarının yanıt süresinin etkisini görselleştirerek yük testi sonuçlarını analiz etmektir. Aşağıdaki grafikte, NAS ile budanmış model uç noktasının, temel BERT modeli uç noktasına kıyasla daha düşük yanıt süresine ulaştığını görebiliriz.
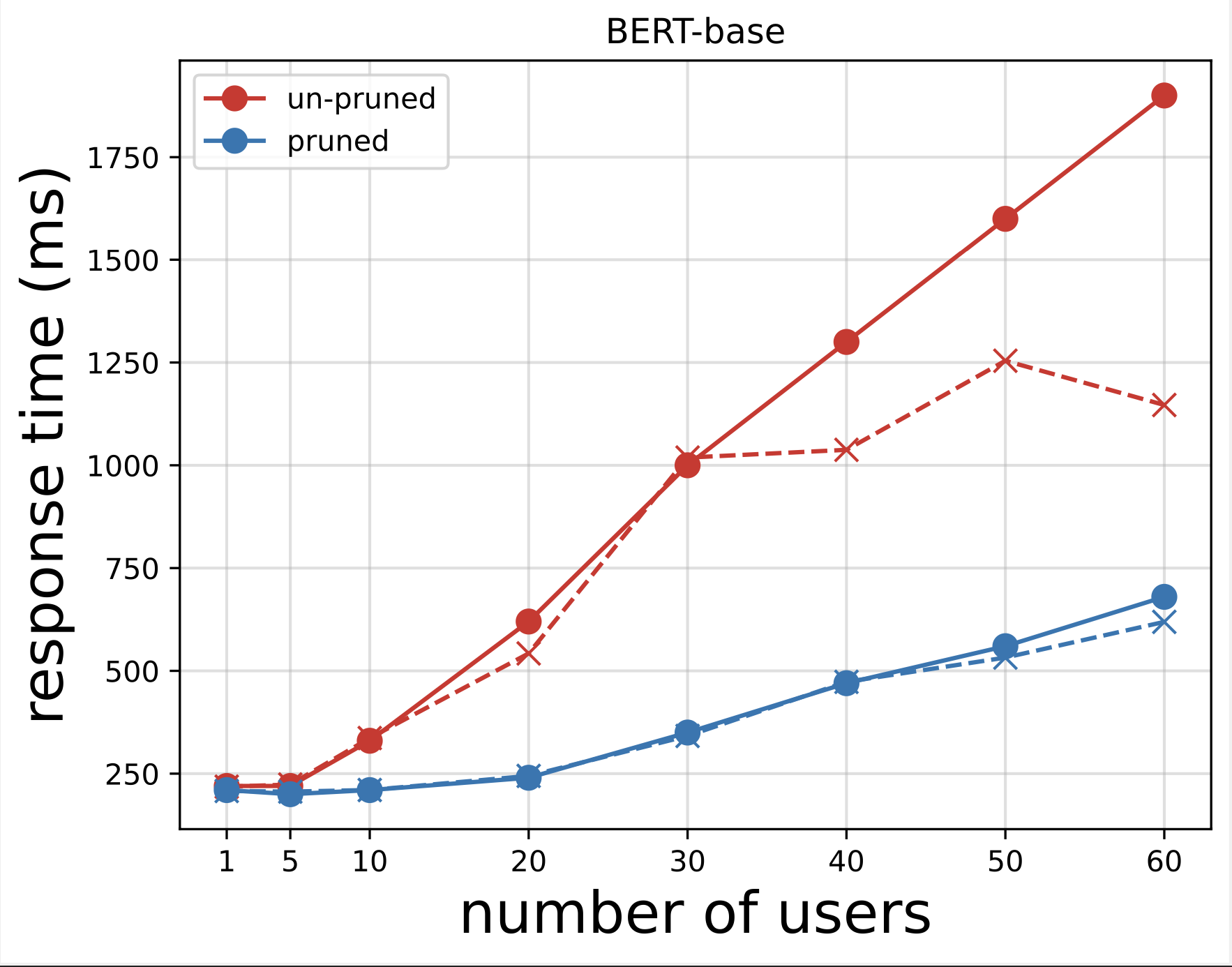
Birinci grafiğin uzantısı olan ikinci grafikte, yaklaşık 70 kullanıcıdan sonra SageMaker'ın temel BERT modeli uç noktasını kısıtlamaya başladığını ve bir istisna attığını gözlemliyoruz. Ancak NAS ile budanan model uç noktası için kısıtlama 90-100 kullanıcı arasında ve daha düşük yanıt süresiyle gerçekleşir.

İki grafikten budanmış modelin budanmamış modele göre daha hızlı tepki süresine sahip olduğunu ve daha iyi ölçeklendiğini gözlemliyoruz. Çıkarım uç noktalarının sayısını ölçeklendirdikçe, PLM uygulamaları için çok sayıda çıkarım uç noktası dağıtan kullanıcılarda olduğu gibi, maliyet avantajları ve performans artışı oldukça önemli hale gelmeye başlar.
Temizlemek
İnce ayarlı temel BERT modeli ve NAS ile budanmış model için SageMaker uç noktalarını silmek için aşağıdaki adımları tamamlayın:
- SageMaker konsolunda, sonuç ve Uç noktalar Gezinti bölmesinde.
- Uç noktayı seçin ve silin.
Alternatif olarak, SageMaker Studio not defterinden uç nokta adlarını sağlayarak aşağıdaki komutları çalıştırın:
Sonuç
Bu yazıda, ince ayarlı bir BERT modelini budamak için NAS'ın nasıl kullanılacağını tartıştık. İlk önce etki alanına özgü verileri kullanarak temel bir BERT modelini eğittik ve bunu bir SageMaker uç noktasına yerleştirdik. Bir hedef görev için SageMaker AMT'yi kullanarak ince ayarlı temel BERT modelinde çok amaçlı bir arama gerçekleştirdik. Pareto cephesini görselleştirdik ve Pareto optimum NAS ile budanmış BERT modelini seçtik ve modeli ikinci bir SageMaker uç noktasına yerleştirdik. Her iki uç noktayı da sorgulayan kullanıcıları simüle etmek için Locust'u kullanarak yük testi gerçekleştirdik ve yanıt sürelerini ölçüp bir CSV dosyasına kaydettik. Her iki model için yanıt süresi ile kullanıcı sayısını karşılaştırdık.
Budanmış BERT modelinin hem yanıt süresinde hem de örnek azaltma eşiğinde önemli ölçüde daha iyi performans gösterdiğini gözlemledik. NAS ile budanmış modelin, uç noktadaki artan yüke karşı daha dayanıklı olduğu ve temel BERT modeline kıyasla daha fazla kullanıcı sistemi strese soksa bile daha düşük yanıt süresini koruduğu sonucuna vardık. Hedef görevi önemli ölçüde daha düşük yanıt süresiyle gerçekleştirebilecek budanmış bir model bulmak için bu yazıda açıklanan NAS tekniğini herhangi bir büyük dil modeline uygulayabilirsiniz. Doğrulama kaybına ek olarak gecikmeyi parametre olarak kullanarak yaklaşımı daha da optimize edebilirsiniz.
Bu yazıda NAS kullanıyor olsak da, niceleme, PLM modellerini optimize etmek ve sıkıştırmak için kullanılan başka bir yaygın yaklaşımdır. Niceleme, eğitimli bir ağdaki ağırlıkların ve aktivasyonların hassasiyetini 32 bit kayan noktadan 8 bit veya 16 bit tamsayılar gibi daha düşük bit genişliklerine azaltır, bu da daha hızlı çıkarım üreten sıkıştırılmış bir modelle sonuçlanır. Niceleme parametrelerin sayısını azaltmaz; bunun yerine sıkıştırılmış bir model elde etmek için mevcut parametrelerin kesinliğini azaltır. NAS budama, PLM'deki yedekli ağları kaldırır ve bu da daha az parametreye sahip seyrek bir model oluşturur. Tipik olarak, NAS budama ve niceleme, model doğruluğunu korumak, doğrulama kayıplarını azaltmak, performansı artırırken ve model boyutunu küçültmek amacıyla büyük PLM'leri sıkıştırmak için birlikte kullanılır. PLM'lerin boyutunu azaltmak için yaygın olarak kullanılan diğer teknikler şunları içerir: bilgi damıtma, matris çarpanlara ayırma, ve damıtma basamakları.
Blog gönderisinde önerilen yaklaşım, alana özgü verileri kullanarak modelleri eğitmek ve ince ayar yapmak ve çıkarım oluşturmak için uç noktaları dağıtmak için SageMaker'ı kullanan ekipler için uygundur. Üretken yapay zeka uygulamaları oluşturmak için gereken yüksek performanslı temel model seçenekleri sunan, tam olarak yönetilen bir hizmet arıyorsanız, kullanmayı düşünün Amazon Ana Kayası. Çok çeşitli iş kullanım örnekleri için önceden eğitilmiş, açık kaynaklı modeller arıyorsanız ve çözüm şablonlarına ve örnek not defterlerine erişmek istiyorsanız şunu kullanmayı düşünün: Amazon SageMaker Hızlı Başlangıç. Bu yazıda kullandığımız Hugging Face BERT taban kasalı modelinin önceden eğitilmiş bir versiyonu da SageMaker JumpStart'ta mevcuttur.
Yazarlar Hakkında
 Aparajithan Vaidyanathan AWS'de Baş Kurumsal Çözüm Mimarıdır. Kurumsal, büyük ölçekli ve dağıtılmış yazılım sistemleri tasarlama ve geliştirme konusunda 24 yıldan fazla deneyime sahip bir Bulut Mimarıdır. Üretken Yapay Zeka ve Makine Öğrenimi Veri Mühendisliği alanında uzmanlaşmıştır. Kendisi hevesli bir maraton koşucusu ve hobileri arasında yürüyüş yapmak, bisiklete binmek ve karısı ve iki oğluyla vakit geçirmek yer alıyor.
Aparajithan Vaidyanathan AWS'de Baş Kurumsal Çözüm Mimarıdır. Kurumsal, büyük ölçekli ve dağıtılmış yazılım sistemleri tasarlama ve geliştirme konusunda 24 yıldan fazla deneyime sahip bir Bulut Mimarıdır. Üretken Yapay Zeka ve Makine Öğrenimi Veri Mühendisliği alanında uzmanlaşmıştır. Kendisi hevesli bir maraton koşucusu ve hobileri arasında yürüyüş yapmak, bisiklete binmek ve karısı ve iki oğluyla vakit geçirmek yer alıyor.
 Harun Klein AWS'de derin sinir ağları için otomatik makine öğrenimi yöntemleri üzerinde çalışan Kıdemli Uygulamalı Bilim Adamıdır.
Harun Klein AWS'de derin sinir ağları için otomatik makine öğrenimi yöntemleri üzerinde çalışan Kıdemli Uygulamalı Bilim Adamıdır.
 Jacek Golebiowski AWS'de Sr Applied Scientist.
Jacek Golebiowski AWS'de Sr Applied Scientist.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/

