Oyun, perakende ve finanstan üretime, sağlık hizmetlerine ve seyahate kadar küresel olarak üretilen veri hacmi artmaya devam ediyor. Kuruluşlar, işletmeleri ve müşterileri için yenilik yapmak amacıyla sürekli veri akışını hızla kullanmanın daha fazla yolunu arıyor. Verileri güvenilir bir şekilde gerçek zamanlı olarak yakalamaları, işlemeleri, analiz etmeleri ve sayısız veri deposuna yüklemeleri gerekiyor.
Apache Kafka, bu gerçek zamanlı akış ihtiyaçları için popüler bir seçimdir. Ancak uygulamanızın ihtiyaçlarına göre otomatik olarak ölçeklenen diğer veri işleme bileşenleriyle birlikte bir Kafka kümesi oluşturmak zor olabilir. Yoğun trafik için yetersiz kaynak sağlama riskiyle karşı karşıya kalırsınız, bu da kesinti süresine yol açabilir veya temel yük için aşırı kaynak ayırarak israfa yol açabilir. AWS, aşağıdakiler gibi birden fazla sunucusuz hizmet sunar: Apache Kafka için Amazon Tarafından Yönetilen Akış (Amazon MSK), Amazon Veri Firehose, Amazon DinamoDB, ve AWS Lambda ihtiyaçlarınıza göre otomatik olarak ölçeklenir.
Bu yazıda, bu hizmetlerden bazılarını nasıl kullanabileceğinizi açıklıyoruz: MSK Sunucusuz, gerçek zamanlı ihtiyaçlarınızı karşılayacak sunucusuz bir veri platformu oluşturmak için.
Çözüme genel bakış
Bir senaryo hayal edelim. Birden fazla coğrafyaya dağıtılan bir internet servis sağlayıcısının binlerce modemini yönetmek sizin sorumluluğunuzdadır. Müşteri verimliliği ve memnuniyeti üzerinde önemli etkisi olan modem bağlantı kalitesini izlemek istiyorsunuz. Dağıtımınız, minimum kesinti süresini sağlamak için izlenmesi ve bakımı yapılması gereken farklı modemler içerir. Her cihaz, CPU kullanımı, hafıza kullanımı, alarm ve bağlantı durumu gibi her saniye binlerce 1 KB kayıt iletir. Performansı gerçek zamanlı olarak izleyebilmek ve sorunları hızla tespit edip azaltabilmek için bu verilere gerçek zamanlı erişim istiyorsunuz. Tahmine dayalı bakım değerlendirmeleri yürütmek, optimizasyon fırsatlarını bulmak ve talebi tahmin etmek amacıyla makine öğrenimi (ML) modelleri için de bu verilere daha uzun vadeli erişime ihtiyacınız var.
Verileri yerinde toplayan istemcileriniz Python'da yazılmıştır ve tüm verileri Apache Kafka konuları olarak Amazon MSK'ya gönderebilirler. Uygulamanızın düşük gecikmeli ve gerçek zamanlı veri erişimi için şunları kullanabilirsiniz: Lambda ve DynamoDB. Daha uzun vadeli veri depolama için yönetilen sunucusuz bağlayıcı hizmetini kullanabilirsiniz Amazon Veri Firehose Veri gölünüze veri göndermek için.
Aşağıdaki şemada bu uçtan uca sunucusuz uygulamayı nasıl oluşturabileceğiniz gösterilmektedir.
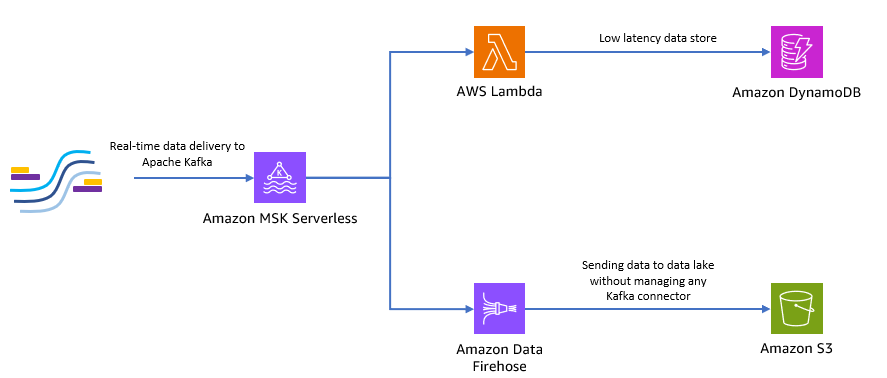
Bu mimariyi uygulamak için aşağıdaki bölümlerdeki adımları takip edelim.
Amazon MSK'da sunucusuz Kafka kümesi oluşturma
Modemlerden gerçek zamanlı telemetri verilerini almak için Amazon MSK'yı kullanıyoruz. Amazon MSK'da sunucusuz bir Kafka kümesi oluşturmak basittir. Kullanımı yalnızca birkaç dakika sürer AWS Yönetim Konsolu veya AWS SDK'sı. Konsolu kullanmak için bkz. MSK Sunucusuz kümelerini kullanmaya başlama. Sunucusuz bir küme oluşturursunuz, AWS Kimlik ve Erişim Yönetimi (IAM) rolü ve istemci makinesi.
Python kullanarak Kafka konusu oluşturma
Kümeniz ve istemci makineniz hazır olduğunda, istemci makinenize SSH uygulayın ve Kafka Python'u ve Python için MSK IAM kitaplığını yükleyin.
- Kafka Python'u yüklemek için aşağıdaki komutları çalıştırın ve MSK IAM kütüphanesi:
- Adlı yeni bir dosya oluşturun
createTopic.py. - Aşağıdaki kodu bu dosyaya kopyalayın ve yerine
bootstrap_serversveregionkümenizin ayrıntılarını içeren bilgiler. Geri alma talimatları içinbootstrap_serversMSK kümenize ilişkin bilgiler için bkz. Bir Amazon MSK kümesi için önyükleme aracılarını alma.
- Çalıştır
createTopic.pyadında yeni bir Kafka konusu oluşturmak için komut dosyasımytopicsunucusuz kümenizde:
Python kullanarak kayıtlar üretin
Bazı örnek modem telemetri verileri oluşturalım.
- Adlı yeni bir dosya oluşturun
kafkaDataGen.py. - Aşağıdaki kodu bu dosyaya kopyalayıp güncelleyin.
BROKERSveregionKümenizin ayrıntılarını içeren bilgiler:
- Çalıştır
kafkaDataGen.pysürekli olarak rastgele veriler oluşturmak ve bunları belirtilen Kafka konusuna yayınlamak için:
Etkinlikleri Amazon S3'te saklayın
Artık tüm ham olay verilerini bir Amazon Basit Depolama Hizmeti (Amazon S3) analitik için veri gölü. ML modellerini eğitmek için aynı verileri kullanabilirsiniz. Amazon Data Firehose ile entegrasyon Amazon MSK'nın Apache Kafka kümelerinizdeki verileri S3 veri gölüne sorunsuz bir şekilde yüklemesine olanak tanır. Kendi bağlayıcı uygulamalarınızı oluşturma veya yönetme ihtiyacını ortadan kaldırarak Kafka'dan Amazon S3'e sürekli veri akışı sağlamak için aşağıdaki adımları tamamlayın:
- Amazon S3 konsolunda yeni bir paket oluşturun. Mevcut bir paketi de kullanabilirsiniz.
- S3 paketinizde adı verilen yeni bir klasör oluşturun
streamingDataLake. - Amazon MSK konsolunda MSK Sunucusuz kümenizi seçin.
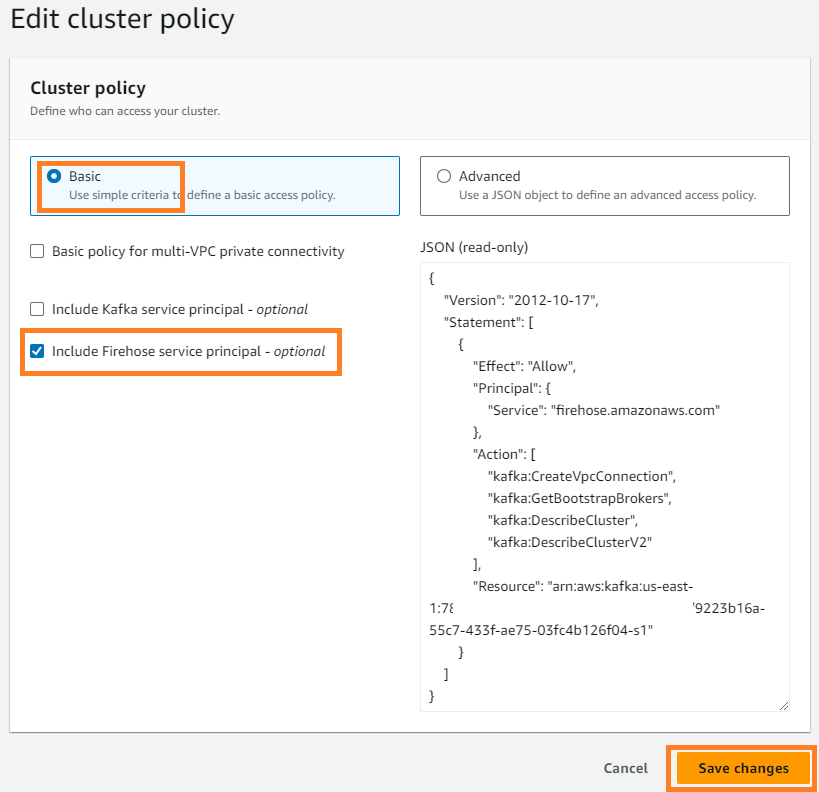
- Üzerinde İşlemler menü seç Küme politikasını düzenle.

- seç Firehose hizmet sorumlusunu dahil et Ve seç Değişiklikleri Kaydet.
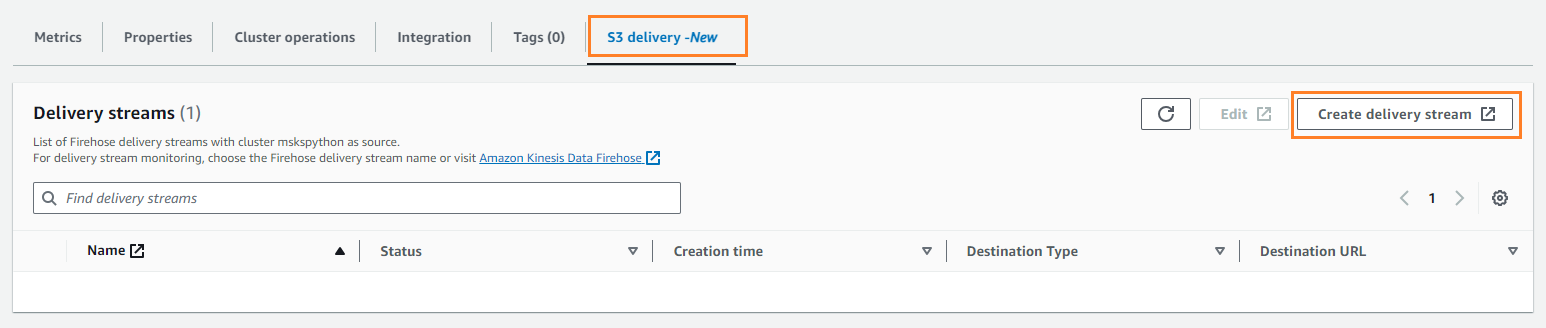
- Üzerinde S3 teslimatı sekmesini seçin Teslimat akışı oluştur.
- İçin Kaynak, seçmek Amazon MSK'sı.
- İçin Varış yeri, seçmek Amazon S3.

- İçin Amazon MSK kümesi bağlantısıseçin Özel önyükleme komisyoncuları.
- İçin konu, bir konu adı girin (bu gönderi için,
mytopic).
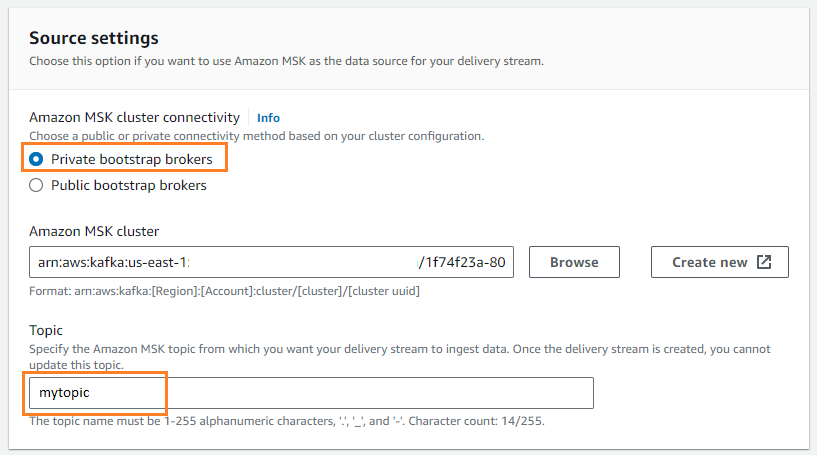
- İçin S3 kepçe, seçmek Araştır ve S3 kovanızı seçin.
- Keşfet
streamingDataLakeS3 kova önekiniz olarak. - Keşfet
streamingDataLakeErrS3 grup hatası çıktı önekiniz olarak.

- Klinik Teslimat akışı oluştur.
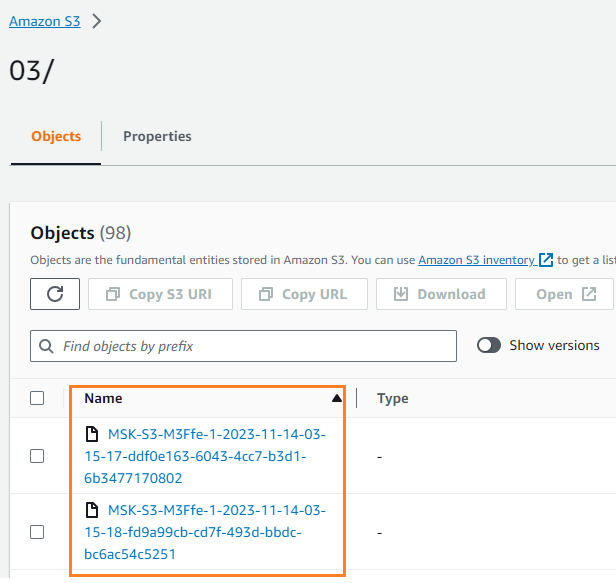
Verilerin S3 klasörünüze yazıldığını doğrulayabilirsiniz. Şunu görmelisiniz: streamingDataLake dizin oluşturuldu ve dosyalar bölümlerde saklandı.
Etkinlikleri DynamoDB'de saklayın
Son adımda en güncel modem verilerini DynamoDB'de saklarsınız. Bu, istemci uygulamasının modem durumuna erişmesine ve düşük gecikme ve yüksek kullanılabilirlik ile her yerden modemle uzaktan etkileşime girmesine olanak tanır. Lambda, Amazon MSK ile sorunsuz bir şekilde çalışır. Lambda, olay kaynağından gelen yeni mesajları dahili olarak yoklar ve ardından eşzamanlı olarak hedef Lambda işlevini çağırır. Lambda, mesajları toplu olarak okur ve bunları bir olay yükü olarak fonksiyonunuza sunar.
Öncelikle DynamoDB'de bir tablo oluşturalım. Bakınız DynamoDB API izinleri: Eylemler, kaynaklar ve koşullar referansı istemci makinenizin gerekli izinlere sahip olduğunu doğrulamak için.
- Adlı yeni bir dosya oluşturun
createTable.py. - Aşağıdaki kodu güncelleyerek dosyaya kopyalayın.
regionbilgi:
- Çalıştır
createTable.pyadında bir tablo oluşturmak için komut dosyasıdevice_statusDynamoDB'de:
Şimdi Lambda fonksiyonunu yapılandıralım.
- Lambda konsolunda şunu seçin: fonksiyonlar Gezinti bölmesinde.
- Klinik İşlev oluştur.
- seç Sıfırdan yazar.
- İçin Fonksiyon adı¸ bir isim girin (örneğin,
my-notification-kafka). - İçin Süre, seçmek Python 3.11.
- İçin İzinlerseçin Mevcut bir rolü kullan ve bir rol seçin kümenizden okuma izinleri.
- Fonksiyonu oluşturun.
Lambda işlevi yapılandırma sayfasında artık kaynakları, hedefleri ve uygulama kodunuzu yapılandırabilirsiniz.
- Klinik Tetikleyici ekle.
- İçin Tetik yapılandırması, girmek
MSKAmazon MSK'yı Lambda kaynak işlevi için tetikleyici olarak yapılandırmak için. - İçin MSK kümesi, girmek
myCluster. - Kaldırın Tetiği etkinleştir, çünkü henüz Lambda işlevinizi yapılandırmadınız.
- İçin Parti boyutu, girmek
100. - İçin Başlangıç pozisyonu, seçmek En Son Eklenenler.
- İçin Konu adı¸ bir isim girin (örneğin,
mytopic). - Klinik Ekle.
- Lambda işlevi ayrıntıları sayfasında, Kod sekmesine aşağıdaki kodu girin:
- Lambda işlevini dağıtın.
- Üzerinde yapılandırma sekmesini seçin Düzenle Tetikleyiciyi düzenlemek için.
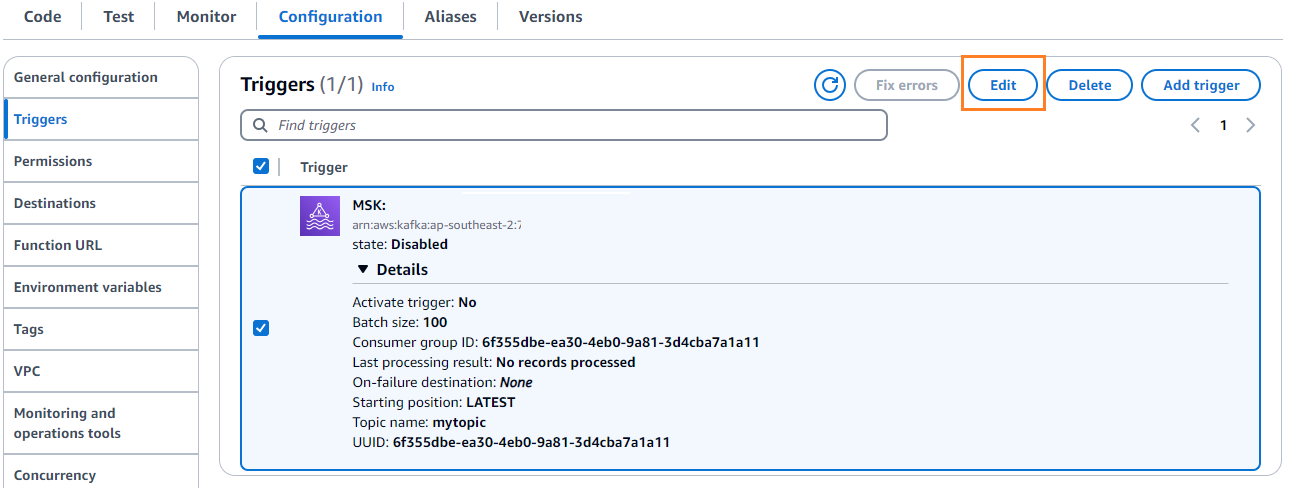
- Tetikleyiciyi seçin ve ardından İndirim.
- DynamoDB konsolunda, Öğeleri keşfedin Gezinti bölmesinde.
- tabloyu seçin
device_status.
Lambda'nın Kafka konusunda oluşturulan olayları DynamoDB'ye yazdığını göreceksiniz.

Özet
Akış veri hatları, gerçek zamanlı uygulamalar oluşturmak için kritik öneme sahiptir. Ancak altyapıyı kurmak ve yönetmek göz korkutucu olabilir. Bu yazıda Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose ve diğer hizmetleri kullanarak AWS'de sunucusuz bir akış hattının nasıl oluşturulacağını anlattık. Temel avantajlar, yönetilecek sunucuların olmaması, altyapının otomatik ölçeklenebilirliği ve tamamen yönetilen hizmetleri kullanan kullandıkça öde modelidir.
Kendi gerçek zamanlı işlem hattınızı oluşturmaya hazır mısınız? Ücretsiz bir AWS hesabıyla bugün başlayın. Sunucusuzluğun gücüyle siz uygulama mantığınıza odaklanabilir, AWS ise farklı olmayan ağır işleri halleder. AWS'de muhteşem bir şey inşa edelim!
Yazarlar Hakkında
 Masudur Rahaman Sayem AWS'de Akış Veri Mimarıdır. Gerçek dünyadaki iş sorunlarını çözmek için veri akışı mimarileri tasarlamak ve oluşturmak için dünyanın her yerindeki AWS müşterileriyle birlikte çalışır. Akışlı veri hizmetleri ve NoSQL kullanan çözümleri optimize etme konusunda uzmandır. Sayem, dağıtılmış bilgi işlem konusunda çok tutkulu.
Masudur Rahaman Sayem AWS'de Akış Veri Mimarıdır. Gerçek dünyadaki iş sorunlarını çözmek için veri akışı mimarileri tasarlamak ve oluşturmak için dünyanın her yerindeki AWS müşterileriyle birlikte çalışır. Akışlı veri hizmetleri ve NoSQL kullanan çözümleri optimize etme konusunda uzmandır. Sayem, dağıtılmış bilgi işlem konusunda çok tutkulu.
 Michael Oguike Amazon MSK'nın Ürün Yöneticisidir. Eylemi teşvik eden içgörüleri ortaya çıkarmak için verileri kullanma konusunda tutkulu. Çok çeşitli sektörlerden müşterilerin veri akışını kullanarak işlerini geliştirmelerine yardımcı olmaktan hoşlanıyor. Michael ayrıca kitaplardan ve podcast'lerden davranış bilimi ve psikoloji hakkında bilgi almayı da seviyor.
Michael Oguike Amazon MSK'nın Ürün Yöneticisidir. Eylemi teşvik eden içgörüleri ortaya çıkarmak için verileri kullanma konusunda tutkulu. Çok çeşitli sektörlerden müşterilerin veri akışını kullanarak işlerini geliştirmelerine yardımcı olmaktan hoşlanıyor. Michael ayrıca kitaplardan ve podcast'lerden davranış bilimi ve psikoloji hakkında bilgi almayı da seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

