Giriş
Büyük Dil Modelleri (Yüksek Lisans) ve Üretken Yapay Zeka, Yapay Zeka ve Doğal Dil İşleme alanında dönüştürücü bir atılımı temsil ediyor. İnsan dilini anlayıp üretebiliyorlar ve metin, görüntü, ses ve sentetik veriler gibi içerikler üretebiliyorlar; bu da onları çeşitli uygulamalarda oldukça çok yönlü hale getiriyor. Üretken yapay zeka, içerik oluşturmayı otomatikleştirip geliştirerek, kullanıcı deneyimlerini kişiselleştirerek, iş akışlarını düzene sokarak ve yaratıcılığı teşvik ederek gerçek dünya uygulamalarında büyük öneme sahiptir. Bu yazıda, Kurumsal Bilgi Grafiklerini kullanarak istemleri etkili bir şekilde temellendirerek Kuruluşların Open LLM'lerle nasıl entegre olabileceğine odaklanacağız.
Öğrenme hedefleri
- Yüksek Lisans/Gen-AI sistemleriyle etkileşimde bulunurken Topraklama ve Hızlı oluşturma hakkında bilgi edinin.
- Topraklamanın Kurumsal alaka düzeyini, açık Nesil Yapay Zeka sistemleriyle entegrasyonun iş değerini bir örnekle anlamak.
- İki temel, birbiriyle çatışan çözüm bilgi grafiğinin ve Vector deposunun çeşitli cephelerde analiz edilmesi ve hangisinin ne zaman uygun olduğunun anlaşılması.
- Kişiselleştirilmiş bir öneri müşteri senaryosu için JAVA'da temel oluşturma ve hızlı oluşturma, bilgi grafiklerinden yararlanma, öğrenme veri modellemesi ve grafik modellemeye ilişkin örnek bir kurumsal tasarımı inceleyin.
Bu makale, Veri Bilimi Blogathon.
İçindekiler
Büyük Dil Modelleri nelerdir?
Büyük Dil Modeli, büyük miktarlarda metin | yapılandırılmamış veriler üzerinde derin öğrenme teknikleri kullanılarak eğitilmiş gelişmiş bir yapay zeka modelidir. Bu modeller insan diliyle etkileşime girme, insana benzer metin, görüntü ve ses oluşturma ve çeşitli işlemleri gerçekleştirme yeteneğine sahiptir. doğal dil işleme görevler.
Buna karşılık, bir dil modelinin tanımı, metin bütünlerinin analizine dayalı olarak sözcük dizilerine olasılıkların atanmasını ifade eder. Bir dil modeli, basit n-gram modellerinden daha karmaşık sinir ağı modellerine kadar değişebilir. Ancak “büyük dil modeli” terimi genellikle derin öğrenme tekniklerini kullanan ve milyonlarcadan milyarlara kadar değişebilen çok sayıda parametreye sahip modelleri ifade eder. Bu modeller dildeki karmaşık kalıpları yakalayabilir ve genellikle insanlar tarafından yazılanlardan ayırt edilemeyen metinler üretebilir.
İstem nedir?
Herhangi bir LLM'ye veya benzer bir chatbot AI sistemine gönderilen bir istem, AI ile bir konuşma veya etkileşim başlatmak için sağladığınız metin tabanlı bir giriş veya mesajdır. LLM'ler çok yönlüdür, çok çeşitli büyük verilerle eğitilir ve çeşitli görevler için kullanılabilir; dolayısıyla isteminizin bağlamı, kapsamı, kalitesi ve netliği, LLM sistemlerinden aldığınız yanıtları önemli ölçüde etkiler.
Topraklama/RAG nedir?
Doğal dil LLM işleme bağlamında Temelleme, AKA Alma-Artırılmış Üretim (RAG), daha özelleştirilmiş ve doğru yanıtları iyileştirmek ve almak için LLM'lere sağladığımız bağlam, ek meta veriler ve kapsam ile istemin zenginleştirilmesi anlamına gelir. Bu bağlantı, yapay zeka sistemlerinin verileri gerekli kapsam ve bağlama uygun olacak şekilde anlamasına ve yorumlamasına yardımcı olur. Yüksek Lisans'lar üzerine yapılan araştırmalar, yanıtlarının kalitesinin, yönlendirmenin kalitesine bağlı olduğunu göstermektedir.
Ham veriler ile yapay zekanın bu verileri insan anlayışı ve kapsamlı bağlamla tutarlı bir şekilde işleme ve yorumlama yeteneği arasındaki boşluğu kapattığı için yapay zekada temel bir kavramdır. Yapay zeka sistemlerinin kalitesini ve güvenilirliğini, doğru ve yararlı bilgiler veya yanıtlar sunma yeteneklerini artırır.
LLM'lerin Dezavantajları Nelerdir?
GPT-3 gibi Büyük Dil Modelleri (LLM'ler) önemli ölçüde ilgi görmüş ve çeşitli uygulamalarda kullanılmıştır, ancak aynı zamanda birçok dezavantaj veya dezavantaja da sahiptirler. Yüksek Lisans'ın ana eksilerinden bazıları şunlardır:
1. Önyargı ve Adalet: LLM'ler sıklıkla eğitim verilerinden önyargılar alırlar. Bu, zararlı stereotipleri güçlendirebilecek ve mevcut önyargıları sürdürebilecek önyargılı veya ayrımcı içeriklerin üretilmesine neden olabilir.
2. halüsinasyonlar: Yüksek Lisans'lar ürettikleri içeriği tam olarak anlamıyorlar; eğitim verilerindeki kalıplara dayalı olarak metin üretirler. Bu, gerçeklere dayalı olarak yanlış veya anlamsız bilgiler üretebilecekleri anlamına geliyor ve bu da onları tıbbi teşhis veya hukuki tavsiye gibi kritik uygulamalar için uygunsuz hale getiriyor.
3. Hesaplamalı Kaynaklar: LLM'lerin eğitimi ve çalıştırılması, GPU'lar ve TPU'lar gibi özel donanımlar da dahil olmak üzere çok büyük hesaplama kaynakları gerektirir. Bu onların geliştirilmesini ve bakımını pahalı hale getirir.
4. Veri Gizliliği ve Güvenliği: Yüksek Lisans'lar metin, resim ve ses gibi ikna edici sahte içerikler üretebilir. Bu, sahte içerik oluşturmak veya bireylerin kimliğine bürünmek için kullanılabildiğinden veri gizliliğini ve güvenliğini riske atar.
5. Etik kaygılar: Yüksek Lisans'ların deepfake veya otomatik içerik oluşturma gibi çeşitli uygulamalarda kullanılması, bunların kötüye kullanım potansiyeli ve toplum üzerindeki etkisi hakkında etik soruları gündeme getiriyor.
6. Düzenleyici Zorluklar: LLM teknolojisinin hızlı gelişimi, düzenleyici çerçeveleri geride bırakarak, LLM'lerle ilgili potansiyel riskleri ve zorlukları ele almak için uygun kılavuzların ve düzenlemelerin oluşturulmasını zorlaştırmıştır.
Bu olumsuzlukların birçoğunun Yüksek Lisans'a özgü olmadığını, bunların nasıl geliştirildiğini, dağıtıldığını ve kullanıldığını yansıttığını belirtmek önemlidir. Bu dezavantajları azaltmak ve Yüksek Lisans'ları toplum için daha sorumlu ve faydalı hale getirmek için çabalar devam etmektedir. İşte burada topraklama ve maskelemeden yararlanılabilir ve Kuruluşlara büyük avantaj sağlanabilir.
Topraklamanın Kurumsal Uygunluğu
İşletmeler, Büyük Dil Modellerini (LLM'ler) görev açısından kritik uygulamalarına dahil etme konusunda başarılı oluyorlar. Yüksek Lisans'ların çeşitli alanlarda yararlanabileceği potansiyel değeri anlıyorlar. LLM'ler oluşturmak, ön eğitim almak ve bunlara ince ayar yapmak onlar için oldukça pahalı ve hantaldır. Bunun yerine, kurumsal kullanım durumları etrafındaki istemleri temellendirmek ve maskelemek için sektörde mevcut olan açık yapay zeka sistemlerini kullanabilirler.
Bu nedenle, Topraklama, işletmeler için önde gelen bir husustur ve hem yanıtların kalitesini artırmada hem de halüsinasyonlar, Veri güvenliği ve uyumluluk endişelerinin üstesinden gelmede onlar için daha alakalı ve faydalıdır, çünkü şaşırtıcı iş değerini açıktan ortaya çıkarabilir. Piyasada çok sayıda kullanım senaryosu için mevcut olan LLM'ler, bugün otomasyona geçme konusunda zorluk yaşıyorlar.
İşletmelere Faydaları
İşletmelerin Yüksek Lisans ile temellendirmeyi uygulamasının çeşitli faydaları vardır:
1. Artırılmış Güvenilirlik: İşletmeler, LLM'ler tarafından oluşturulan bilgi ve içeriğin doğrulanmış veri kaynaklarına dayanmasını sağlayarak iletişimlerinin, raporlarının ve içeriklerinin güvenilirliğini artırabilir. Bu, müşteriler, müşteriler ve paydaşlar arasında güven oluşturulmasına yardımcı olabilir.
2. Geliştirilmiş Karar Verme: Kurumsal uygulamalarda, özellikle veri analizi ve karar desteğiyle ilgili uygulamalarda, yüksek lisans eğitimlerinin veri temellendirmeyle kullanılması daha güvenilir içgörüler sağlayabilir. Bu, stratejik planlama ve iş büyümesi için çok önemli olan daha bilinçli karar almaya yol açabilir.
3. Mevzuata uygunluk: Birçok endüstri, veri doğruluğu ve uyumluluğu açısından düzenleyici gerekliliklere tabidir. Yüksek Lisans'larla veri temellendirme, bu uyumluluk standartlarının karşılanmasına yardımcı olarak yasal veya düzenleyici sorun riskini azaltabilir.
4. Kaliteli İçerik Üretimi: Yüksek Lisans'lar genellikle pazarlama, müşteri desteği ve ürün açıklamaları gibi içerik oluşturmada kullanılır. Veri topraklama, oluşturulan içeriğin gerçeklere dayalı olmasını sağlayarak yanlış veya yanıltıcı bilgi veya halüsinasyon yayma riskini azaltır.
5. Yanlış Bilgilerin Azaltılması: Sahte haber ve yanlış bilgi çağında veri temellendirme, işletmelerin ürettikleri veya paylaştığı içeriğin doğrulanmış veri kaynaklarına dayalı olmasını sağlayarak yanlış bilgilerin yayılmasıyla mücadele etmesine yardımcı olabilir.
6. Müşteri memnuniyeti: Müşterilere doğru ve güvenilir bilgi sağlamak, bir işletmenin ürün veya hizmetlerine olan memnuniyetlerini ve güvenlerini artırabilir.
7. Risk azaltma: Veri temellendirme, mali veya itibar kaybına yol açabilecek yanlış veya eksik bilgilere dayalı olarak karar verme riskinin azaltılmasına yardımcı olabilir.
Örnek: Müşteri Ürünü Tavsiye Senaryosu
OpenAI chatGPT kullanan kurumsal kullanım senaryosunda veri topraklamanın nasıl yardımcı olabileceğini görelim
Temel istemler
Generate a short email adding coupons on recommended products to customer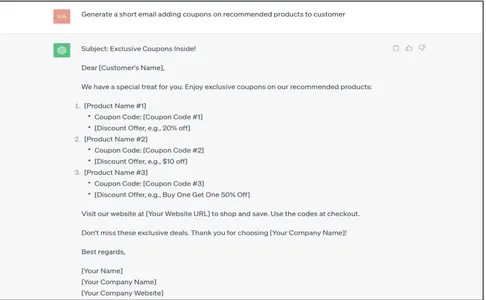
ChatGPT tarafından oluşturulan yanıt oldukça genel, bağlamsal olmayan ve hamdır. Bunun, pahalı olan, doğru kurumsal müşteri verileriyle manuel olarak güncellenmesi/eşlenmesi gerekir. Bunun veri topraklama teknikleriyle nasıl otomatikleştirilebileceğini görelim.
Diyelim ki, işletmenin halihazırda kurumsal müşteri verilerini ve müşteriler için kuponlar ve öneriler oluşturabilen akıllı bir öneri sistemini elinde bulundurduğunu varsayalım; ChatGPT'den oluşturulan e-posta metninin tam olarak olmasını istediğimiz gibi olmasını ve manuel müdahale olmadan müşteriye e-posta göndermek üzere otomatik hale getirilebilmesini sağlamak için yukarıdaki istemi doğru meta verilerle zenginleştirerek çok iyi bir şekilde temellendirebiliriz.
Temelleme motorumuzun müşteri verilerinden doğru zenginleştirme meta verilerini elde edeceğini ve aşağıdaki istemi güncelleyeceğini varsayalım. Temellendirilmiş istem için ChatGPT yanıtının nasıl olacağını görelim.
Topraklanmış İstem
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off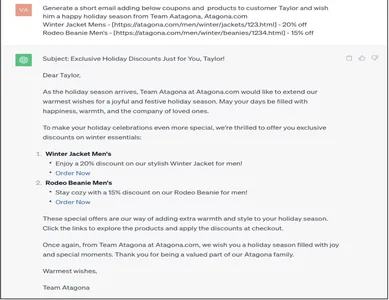
Yer bildirimiyle oluşturulan yanıt, işletmenin müşterinin bilgilendirilmesini tam olarak istediği şekildedir. Yapay zeka kuşağının e-posta yanıtına eklenen zenginleştirilmiş müşteri verileri, işletmelerin ölçeğini büyütmek ve sürdürmek için dikkate değer bir otomasyondur.
Yazılım Sistemleri için Kurumsal Yüksek Lisans Topraklama Çözümleri
Kurumsal sistemlerde verileri temellendirmenin birçok yolu vardır ve bu tekniklerin bir kombinasyonu, etkili veri temellendirme ve kullanım senaryosuna özel bilgi istemi oluşturma için kullanılabilir. Geri alma artırılmış üretimi (topraklama) uygulamaya yönelik potansiyel çözümler olarak iki ana yarışmacı şunlardır:
- Uygulama Verileri|Bilgi grafikleri
- Vektör yerleştirmeleri ve anlamsal arama
Bu çözümlerin kullanımı, kullanım durumuna ve uygulamak istediğiniz temele bağlı olacaktır. Örneğin, sağlanan yanıtların vektör depoları hatalı ve belirsiz olabilirken, bilgi grafikleri kesin, doğru ve insan tarafından okunabilir bir formatta saklanabilir.
Yukarıdakilere ek olarak harmanlanabilecek birkaç başka strateji de şunlar olabilir:
- Harici API'lere, Arama motorlarına bağlanma
- Veri Maskeleme ve uyumluluk uyum sistemleri
- Dahili veri depoları ve sistemlerle entegrasyon
- Gerçek Zamanlı Birden fazla kaynaktan gelen verileri birleştirme
Bu blogda kurumsal uygulama veri grafikleriyle nasıl başarıya ulaşabileceğinizi gösteren örnek bir yazılım tasarımına bakalım.
Kurumsal Bilgi Grafikleri
Bir bilgi grafiği, çeşitli varlıkların anlamsal bilgilerini ve bunlar arasındaki ilişkileri temsil edebilir. Kurumsal dünyada müşteriler, ürünler ve daha fazlası hakkındaki bilgileri depolarlar. Kurumsal müşteri grafikleri, verileri etkili bir şekilde temellendirmek ve zenginleştirilmiş istemler oluşturmak için güçlü bir araç olacaktır. Bilgi grafikleri, grafik tabanlı aramayı etkinleştirerek kullanıcıların bağlantılı kavramlar ve varlıklar aracılığıyla bilgileri keşfetmesine olanak tanır ve bu da daha kesin ve çeşitli arama sonuçlarına yol açabilir.
Vektör Veritabanlarıyla Karşılaştırma
Topraklama çözümünün seçimi kullanım durumuna özel olacaktır. Bununla birlikte, grafiklerin aşağıdaki gibi vektörlere göre birçok avantajı vardır:
| Kriterler | Grafik topraklama | Vektör topraklama |
| Analitik Sorgular | Veri grafikleri, yapılandırılmış veriler ve analitik sorgular için uygundur ve soyut grafik düzenleri nedeniyle doğru sonuçlar sağlar. | Vektör veri depoları, çoğunlukla yapılandırılmamış veriler üzerinde çalıştıkları, vektör yerleştirmelerle anlamsal arama yaptıkları ve benzerlik puanlamasına dayandıkları için analitik sorgularda iyi performans göstermeyebilir. |
| Doğruluk ve Güvenilirlik | Bilgi grafikleri, verileri depolamak için düğümleri ve ilişkileri kullanır ve yalnızca mevcut bilgiyi döndürür. Eksik veya alakasız sonuçlardan kaçınırlar. | Vektör veritabanları, esas olarak benzerlik puanlamasına ve önceden tanımlanmış sonuç sınırlarına dayanmaları nedeniyle eksik veya ilgisiz sonuçlar sağlayabilir. |
| Halüsinasyonları Düzeltmek | Bilgi grafikleri, verilerin insan tarafından okunabilir bir temsiliyle şeffaftır. Yanlış bilgilerin belirlenmesine ve düzeltilmesine, sorgunun yolunun geriye doğru izlenmesine ve düzeltmeler yapılmasına yardımcı olarak LLM (Büyük Dil Modeli) doğruluğunu artırırlar. | Vektör veritabanları genellikle okunabilir biçimde saklanmayan kara kutular olarak görülür ve yanlış bilgilerin kolayca tanımlanmasını ve düzeltilmesini kolaylaştırmayabilir. |
| Güvenlik ve Yönetim | Bilgi grafikleri, GDPR gibi düzenlemeler de dahil olmak üzere veri oluşturma, yönetişim ve uyumluluk uyumu üzerinde daha iyi kontrol sağlar. | Vektör veritabanları, şeffaf olmayan doğaları nedeniyle kısıtlamalar ve yönetim uygulama konusunda zorluklarla karşılaşabilir. |
Üst Düzey Tasarım
Sistemin, bilgi grafiklerini ve temellendirme için açık LLM'leri kullanan bir kuruluşu nasıl arayabileceğini çok yüksek bir düzeyde görelim.
Temel katman, kurumsal müşteri verilerinin ve meta verilerinin çeşitli veritabanlarında, veri ambarlarında ve veri göllerinde depolandığı yerdir. Bu verilerden veri bilgisi grafikleri oluşturan ve bunu bir grafik veritabanında saklayan bir hizmet olabilir. Dağıtılmış bulut yerel dünyasında bu veri depolarıyla etkileşime girecek çok sayıda kurumsal hizmet/mikro hizmet bulunabilir. Bu hizmetlerin üstünde, temel altyapıyı güçlendirecek çeşitli uygulamalar olabilir.
Uygulamalar, yapay zekayı kendi senaryolarına veya akıllı otomatik müşteri akışlarına dahil etmek için dahili ve harici yapay zeka sistemleriyle etkileşimi gerektiren çok sayıda kullanım senaryosuna sahip olabilir. Üretken yapay zeka senaryolarında, bir işletmenin tatil sezonunda kişiselleştirilmiş önerilen ürünlerde birkaç indirim sunan bir e-posta aracılığıyla müşterileri hedeflemek istediği basit bir iş akışı örneğini ele alalım. Bunu birinci sınıf otomasyonla başarabilirler ve yapay zekayı daha etkili bir şekilde kullanabilirler.
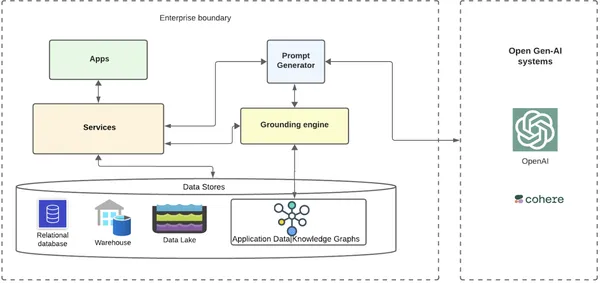
İş Akışı
- Bir e-posta göndermek isteyen iş akışı, müşterinin bağlamsallaştırılmış verileriyle temelli bir istem göndererek açık Gen-AI sistemlerinden yardım alabilir.
- İş akışı uygulaması, GenAI sistemlerini kullanan e-posta metnini almak için arka uç hizmetine bir istek gönderecektir.
- Arka uç hizmeti, hizmeti topraklama motoruna yönlendiren hızlı bir jeneratör hizmetine yönlendirecektir.
- Topraklama motoru, hizmetlerinden birinden tüm müşteri meta verilerini alır ve müşteri verileri bilgi grafiğini alır.
- Topraklama motoru, grafiği düğümler arasında dolaştırır ve ilgili ilişkiler, gereken nihai bilgiyi çıkarır ve onu istem oluşturucuya geri gönderir.
- Bilgi istemi oluşturucu, topraklanmış verileri kullanım senaryosu için önceden var olan bir şablonla ekler ve topraklanmış istemi kuruluşun entegre etmeyi seçtiği açık yapay zeka sistemlerine (örneğin, OpenAI/Cohere) gönderir.
- Açık GenAI sistemleri, müşteriye e-posta yoluyla gönderilen, kuruluşa çok daha alakalı ve bağlamsal bir yanıt verir.
Bunu iki parçaya ayıralım ve ayrıntılı olarak anlayalım:
1. Müşteri Bilgisi grafikleri oluşturma
Aşağıdaki tasarım yukarıdaki örneğe uygundur, ihtiyaca göre çeşitli şekillerde modelleme yapılabilir.
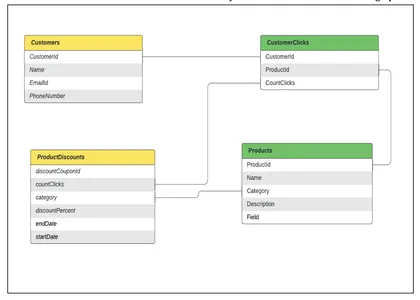
Veri Modelleme: Bir grafikte düğümler olarak modellenen çeşitli tablolarımız olduğunu ve tablolar arasında düğümler arasındaki ilişkiler olarak birleştiğimizi varsayalım. Yukarıdaki örnek için ihtiyacımız var
- Müşterinin verilerini tutan bir tablo,
- ürün verilerini tutan bir tablo,
- kişiselleştirilmiş öneriler için Müşteri İlgi Alanları (Tıklamalar) verilerini tutan bir tablo
- ProductDiscounts verilerini tutan bir tablo
Tüm bu verilerin birden fazla veri kaynağından alınması ve müşterilere etkili bir şekilde ulaşması için düzenli olarak güncellenmesi kuruluşun sorumluluğundadır.
Bu tabloların nasıl modellenebileceğini ve müşteri grafiğine nasıl dönüştürülebileceğini görelim.
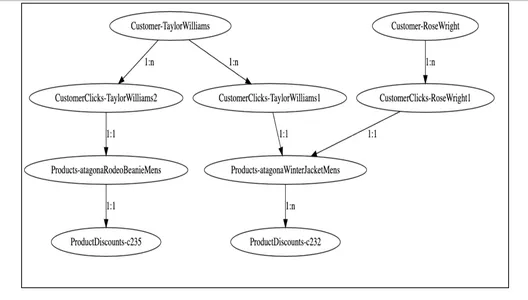
2. Grafik Modelleme
Yukarıdaki grafik görselleştiricisinden, müşteri düğümlerinin tıklama etkileşimi verilerine göre çeşitli ürünlerle ve ayrıca indirim düğümleriyle nasıl ilişkili olduğunu görebiliriz. Temel hizmetin bu müşteri grafiklerini sorgulaması, bu düğümler arasında ilişkiler yoluyla geçiş yapması ve ilgili müşterilere uygun indirimler hakkında gerekli bilgileri elde etmesi kolaydır.
Yukarıdakiler için örnek bir grafik düğümü ve ilişki JAVA POJO'ları aşağıdakine benzer görünebilir
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Bu senaryodaki örnek bir ham grafik aşağıdaki gibi görünebilir
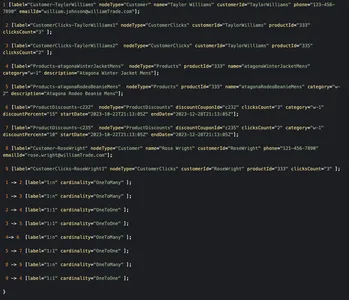
'Taylor Williams' müşteri düğümünden grafiğin üzerinden geçmek bizim için sorunu çözecek ve doğru ürün önerilerini ve uygun indirimleri getirecektir.
3. Sektördeki popüler Graph mağazaları
Piyasada kurumsal mimarilere uygun çok sayıda grafik mağazası bulunmaktadır. Neo4j, TigerGraph, Amazon Neptune ve OrientDB, grafik veritabanları olarak yaygın şekilde benimsenmektedir.
Tablo verileri (göller, depolar ve göl evlerindeki yapılandırılmış veriler) üzerinde grafik sorgularına olanak tanıyan yeni Grafik Veri Gölleri paradigmasını tanıtıyoruz. Bu, Zero-ETL'den yararlanarak grafik veri depolarındaki verileri nemlendirmeye veya kalıcı hale getirmeye gerek kalmadan aşağıda listelenen yeni çözümlerle gerçekleştirilir.
- PuppyGraph(Grafik Veri Gölü)
- Timbr.ai
Uyumluluk ve Etik Hususlar
Veri Koruma: Kuruluşlar, müşteri verilerinin GDPR ve diğer PII uyumluluğuna uygun olarak saklanması ve kullanılmasından sorumlu olmalıdır. Saklanan verilerin, işlenmeden ve içgörüler için yeniden kullanılmadan veya yapay zeka uygulanmadan önce yönetilmesi ve temizlenmesi gerekir.
Halüsinasyonlar ve Uzlaşma: Şirketler ayrıca verilerdeki yanlış bilgileri tanımlayacak, sorgunun yolunu izleyecek ve üzerinde düzeltmeler yapacak uzlaştırma hizmetleri de ekleyebilir; bu da LLM doğruluğunun iyileştirilmesine yardımcı olabilir. Bilgi grafikleri ile depolanan veriler şeffaf ve insan tarafından okunabilir olduğundan, bunu başarmak nispeten kolay olmalıdır.
Kısıtlayıcı Saklama politikaları: Açık LLM sistemleriyle etkileşimde bulunurken veri korumasına uymak ve müşteri verilerinin kötüye kullanımını önlemek için sıfır saklama politikalarına sahip olmak çok önemlidir; böylece işletmelerin etkileşimde bulunduğu harici sistemler, talep edilen anlık verileri herhangi bir başka analitik veya ticari amaç için tutmaz.
Sonuç
Sonuç olarak, Büyük Dil Modelleri (LLM'ler) yapay zeka ve doğal dil işlemede dikkate değer bir ilerlemeyi temsil etmektedir. Doğal dilin anlaşılması ve oluşturulmasından karmaşık görevlere yardımcı olmaya kadar çeşitli endüstrileri ve uygulamaları dönüştürebilirler. Bununla birlikte, Yüksek Lisans Programlarının başarısı ve sorumlu kullanımı, çeşitli kilit alanlarda güçlü bir temel ve temel gerektirir.
Önemli Noktalar
- Kuruluşlar, çeşitli senaryolar için Yüksek Lisans'ları kullanırken etkili temellendirme ve yönlendirmeden büyük ölçüde yararlanabilir.
- Bilgi grafikleri ve Vektör depoları popüler Topraklama çözümleridir ve bunlardan birinin seçilmesi çözümün amacına bağlı olacaktır.
- Bilgi grafikleri, vektör depoları üzerinden daha doğru ve güvenilir bilgilere sahip olabilir; bu da, ek güvenlik ve uyumluluk katmanları eklemek zorunda kalmadan Kurumsal kullanım örnekleri için avantaj sağlar.
- Varlıklar ve ilişkiler içeren geleneksel veri modellemeyi, düğümler ve kenarlar içeren Bilgi grafiklerine dönüştürün.
- Kurumsal bilgi Grafiklerini mevcut büyük veri depolama kuruluşlarıyla çeşitli veri kaynaklarıyla entegre edin.
- Bilgi grafikleri analitik sorgular için idealdir. Grafik veri gölleri, kurumsal veri depolamada tablo halindeki verilerin grafik olarak sorgulanmasına olanak tanır.
Sık Sorulan Sorular
C. LLM, yeni içeriği anlamak, özetlemek, oluşturmak ve tahmin etmek için DL tekniklerini ve çok büyük veri kümelerini kullanan bir yapay zeka algoritmasıdır.
A. Uygulama veri grafiği, verileri düğümler ve kenarlar biçiminde depolayan bir veri yapısıdır. Bunları farklı veri düğümleri arasındaki ilişkiler olarak modelleyin.
A. Bir vektör veritabanı, metin, ses ve video gibi yapılandırılmamış verileri saklar ve yönetir. Öneri motorları, makine öğrenimi ve Yapay Zeka gibi uygulamalar için hızlı indeksleme ve alma konusunda mükemmeldir.
A. Bir vektör deposunda yerleştirmeler, nesnelerin, kelimelerin veya veri noktalarının yüksek boyutlu bir vektör uzayındaki sayısal temsilleridir. Bu yerleştirmeler, öğeler arasındaki anlamsal ilişkileri ve benzerlikleri yakalayarak verimli veri analizine, benzerlik aramalarına ve makine öğrenimi görevlerine olanak tanır.
A. Yapılandırılmış veriler, tanımlanmış tablolar ve şemalarla iyi organize edilmiştir. Metin, resim, ses veya video gibi yapılandırılmamış verilerin, format eksikliğinden dolayı analiz edilmesi daha zordur.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/

