Büyük dil modelleri (LLM'ler), karmaşık belgeleri analiz etmek ve özetler ve sorulara yanıtlar sağlamak için kullanılabilir. Posta Amazon SageMaker JumpStart'ta Finansal verilerde Temel Modellerin Etki Alanı Uyarlaması İnce Ayarı kendi veri kümenizi kullanarak bir LLM'de nasıl ince ayar yapacağınızı açıklar. Sağlam bir LLM'ye sahip olduğunuzda, yüzlerce sayfa uzunluğunda olabilen yeni belgeleri işlemek için bu LLM'yi iş kullanıcılarına göstermek isteyeceksiniz. Bu yazıda, iş kullanıcılarının keyfi uzunluktaki bir PDF belgesini işlemesine izin vermek için gerçek zamanlı bir kullanıcı arayüzünün nasıl oluşturulacağını gösteriyoruz. Dosya işlendikten sonra belgeyi özetleyebilir veya içerikle ilgili sorular sorabilirsiniz. Bu gönderide açıklanan örnek çözüm şu adreste mevcuttur: GitHub.
Mali belgelerle çalışma
Üç aylık kazanç raporları ve hissedarlara sunulan yıllık raporlar gibi mali tablolar genellikle onlarca veya yüzlerce sayfa uzunluğundadır. Bu belgeler, sorumluluk reddi beyanları ve yasal dil gibi birçok basmakalıp dil içerir. Bu belgelerden birinden önemli veri noktalarını çıkarmak istiyorsanız, ilginç gerçekleri tanımlayabilmeniz için hem zamana hem de basmakalıp dil hakkında biraz bilgi sahibi olmanız gerekir. Ve elbette, bir LLM'ye hiç görmediği bir belge hakkında soru soramazsınız.
Özetleme için kullanılan LLM'lerin, modele aktarılan belirteç (karakter) sayısında bir sınırı vardır ve bazı istisnalar dışında, bunlar tipik olarak birkaç bin belirteçten fazla değildir. Bu normalde daha uzun belgeleri özetleme yeteneğini engeller.
Çözümümüz, bir LLM'nin maksimum belirteç dizisi uzunluğunu aşan belgeleri işler ve bu belgeyi LLM'nin soruları yanıtlaması için kullanılabilir hale getirir.
Çözüme genel bakış
Tasarımımızın üç önemli parçası var:
- İş kullanıcılarının PDF'leri yüklemesi ve işlemesi için etkileşimli bir web uygulamasına sahiptir.
- Büyük bir PDF'yi daha yönetilebilir parçalara bölmek için langchain kitaplığını kullanır.
- Kullanıcıların LLM'nin daha önce görmediği yeni veriler hakkında sorular sormasına izin vermek için alma artırılmış oluşturma tekniğini kullanır.
Aşağıdaki diyagramda gösterildiği gibi, bir sunucuda barındırılan React JavaScript ile uygulanan bir ön uç kullanıyoruz. Amazon Basit Depolama Hizmeti (Amazon S3) kovası Amazon CloudFront. Ön uç uygulama, kullanıcıların PDF belgelerini Amazon S3'e yüklemesine olanak tanır. Yükleme tamamlandıktan sonra, tarafından desteklenen bir metin çıkarma işini tetikleyebilirsiniz. Amazon Metin Yazısı. Son işlemenin bir parçası olarak, bir AWS Lambda işlevi metne sayfa sınırlarını gösteren özel işaretler ekler. Bu iş bittiğinde, metni özetleyen veya onunla ilgili soruları yanıtlayan bir API'yi çağırabilirsiniz.

Bu adımlardan bazıları biraz zaman alabileceğinden, mimari ayrıştırılmış bir zaman uyumsuz yaklaşım kullanır. Örneğin, bir belgeyi özetleme çağrısı, bir belgeye mesaj gönderen bir Lambda işlevini çağırır. Amazon Basit Kuyruk Hizmeti (Amazon SQS) kuyruğu. Başka bir Lambda işlevi bu mesajı alır ve bir Amazon Elastik Konteyner Hizmeti (Amazon ECS'si) AWS Fargate görev. Fargate görevi şunu çağırır: Amazon Adaçayı Yapıcı çıkarım uç noktası. Burada bir Fargate görevi kullanıyoruz, çünkü çok uzun bir PDF'yi özetlemek bir Lambda işlevinden daha fazla zaman ve bellek gerektirebilir. Özetleme yapıldığında, ön uç uygulama sonuçları bir Amazon DinamoDB tablo.
Özetleme için, AI21'in temel modellerinden biri olan Summarize modelini kullanıyoruz. Amazon SageMaker Hızlı Başlangıç. Bu model 10,000 kelimeye kadar (yaklaşık 40 sayfa) belgeleri işliyor olsa da, LLM'ye yapılan her bir özetleme çağrısının 10,000 kelimeden uzun olmadığından emin olmak için langchain'in metin ayırıcısını kullanıyoruz. Metin oluşturma için Cohere'in Medium modelini kullanıyoruz ve her ikisi de JumpStart aracılığıyla yerleştirmeler için GPT-J kullanıyoruz.
Özetleme işlemi
Daha büyük belgeleri işlerken, belgeyi daha küçük parçalara nasıl böleceğimizi tanımlamamız gerekir. Amazon Textract'tan metin çıkarma sonuçlarını aldığımızda, daha büyük metin parçaları (yapılandırılabilir sayıda sayfa), tek tek sayfalar ve satır sonları için işaretçiler ekleriz. Langchain, bu belirteçlere göre bölünecek ve belirteç sınırının altında olan daha küçük belgeleri bir araya getirecektir. Aşağıdaki koda bakın:
Özetleme zincirindeki LLM, SageMaker uç noktamızın etrafındaki ince bir sarmalayıcıdır:
Soru cevaplama
Alma artırılmış oluşturma yönteminde, önce belgeyi daha küçük parçalara böleriz. Her segment için yerleştirmeler oluşturuyoruz ve bunları langchain'in arayüzü aracılığıyla açık kaynaklı Chroma vektör veritabanında saklıyoruz. Veritabanını bir dosyaya kaydediyoruz. Amazon Elastik Dosya Sistemi (Amazon EFS) dosya sistemi daha sonra kullanmak üzere. Aşağıdaki koda bakın:
Yerleştirmeler hazır olduğunda, kullanıcı bir soru sorabilir. Soruyla en yakından eşleşen metin parçalarını vektör veritabanında ararız:
En yakın eşleşen parçayı alıp soruyu cevaplamak için metin oluşturma modeli için bağlam olarak kullanıyoruz:
Kullanıcı deneyimi
LLM'ler gelişmiş veri bilimini temsil etse de, LLM'lerin kullanım durumlarının çoğu sonuçta teknik olmayan kullanıcılarla etkileşimi içerir. Örnek web uygulamamız, iş kullanıcılarının yeni bir PDF belgesini yükleyip işleyebildiği etkileşimli bir kullanım durumunu ele alır.
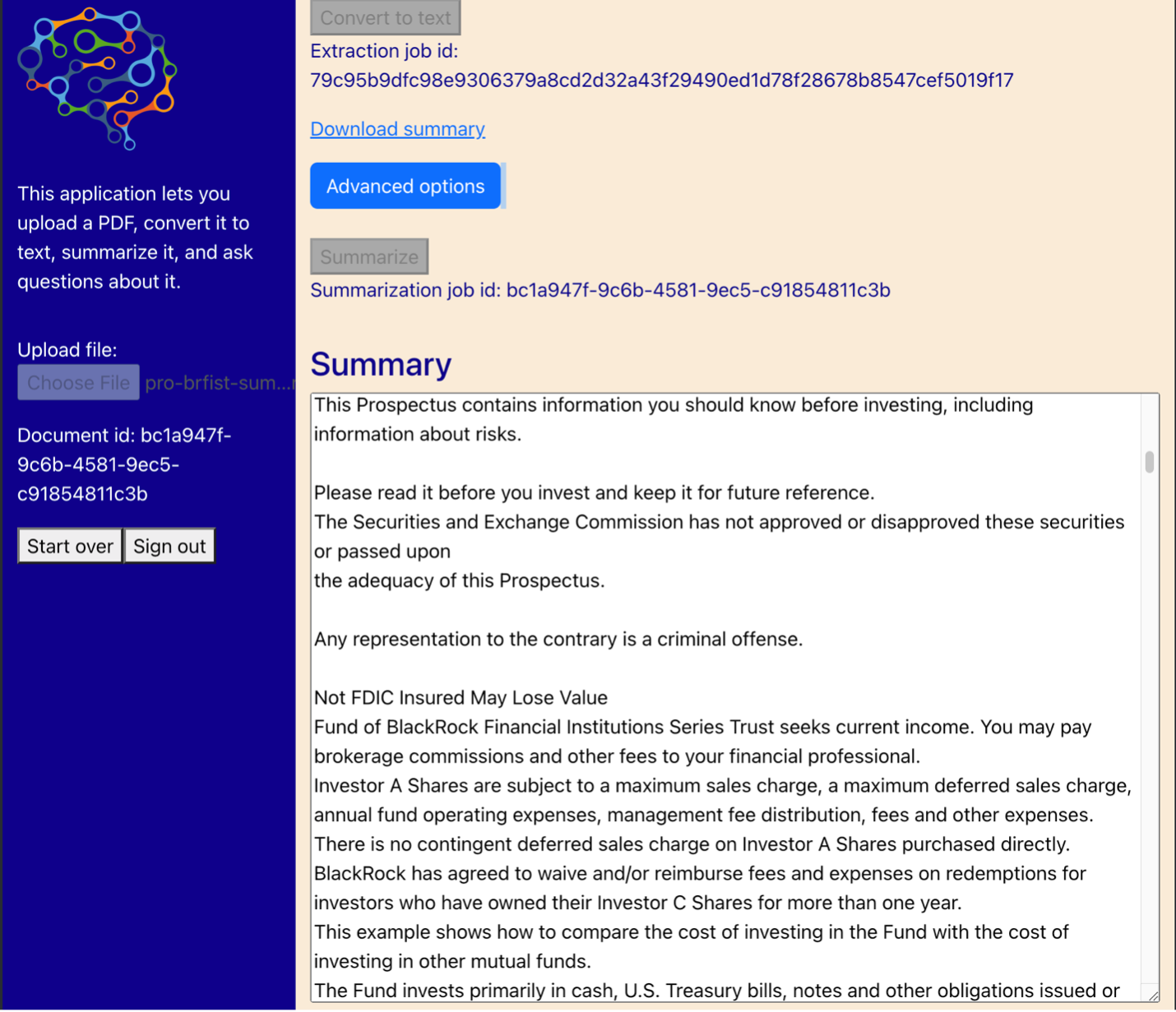
Aşağıdaki diyagram kullanıcı arayüzünü göstermektedir. Bir kullanıcı bir PDF yükleyerek başlar. Belge Amazon S3'te depolandıktan sonra, kullanıcı metin çıkarma işini başlatabilir. Bu tamamlandığında, kullanıcı özetleme görevini başlatabilir veya sorular sorabilir. Kullanıcı arabirimi, uygulamayı yeni belgeler üzerinde test eden ileri düzey kullanıcılar için yararlı olabilecek yığın boyutu ve yığın çakışması gibi bazı gelişmiş seçenekleri ortaya çıkarır.
Sonraki adımlar
LLM'ler önemli yeni bilgi alma yetenekleri sağlar. İş kullanıcılarının bu yeteneklere kolay erişime ihtiyacı vardır. Gelecekteki çalışmalar için dikkate alınması gereken iki yön vardır:
- Jumpstart temel modellerinde zaten mevcut olan güçlü LLM'lerden yararlanın. Yalnızca birkaç satır kodla, örnek uygulamamız metin özetleme ve oluşturma için AI21 ve Cohere'den gelişmiş LLM'leri dağıtabilir ve bunlardan yararlanabilir.
- Bu yetenekleri teknik olmayan kullanıcılar için erişilebilir hale getirin. PDF belgelerini işlemenin ön koşulu, belgeden metin çıkarmaktır ve özetleme işlerinin çalıştırılması birkaç dakika sürebilir. Bu, Lambda ve Fargate gibi bulutta yerel hizmetler kullanılarak kolayca tasarlanabilen, eşzamansız arka uç işleme özelliklerine sahip basit bir kullanıcı arabirimi gerektirir.
Ayrıca bir PDF belgesinin yarı yapılandırılmış bilgi olduğunu da not ediyoruz. Bölüm başlıkları gibi önemli ipuçlarını, yazı tipi boyutlarına ve diğer görsel göstergelere dayandıkları için programlı olarak belirlemek zordur. Bilginin temel yapısını belirlemek, en azından LLM'lerin sınırsız uzunluktaki girdileri işleyebildiği zamana kadar, LLM'nin verileri daha doğru bir şekilde işlemesine yardımcı olur.
Sonuç
Bu gönderide, iş kullanıcılarının özetleme ve soru yanıtlama için PDF belgelerini yüklemesine ve işlemesine olanak tanıyan etkileşimli bir web uygulamasının nasıl oluşturulacağını gösterdik. Gelişmiş LLM'lere erişmek için Jumpstart temel modellerinden nasıl yararlanacağımızı ve daha uzun belgeleri işlemek ve bunları LLM'ye bilgi olarak sunmak için metin bölme ve alma artırılmış oluşturma tekniklerini kullanmayı gördük.
Bu noktada, bu güçlü yetenekleri kullanıcılarınıza sunmamak için hiçbir neden yok. kullanmaya başlamanızı öneririz. Hızlı başlangıç temel modelleri bugün.
Yazar hakkında
 Randy DeFauw AWS'de Kıdemli Baş Çözüm Mimarıdır. Otonom araçlar için bilgisayar görüşü üzerinde çalıştığı Michigan Üniversitesi'nden bir MSEE sahibidir. Ayrıca Colorado Eyalet Üniversitesi'nden MBA derecesine sahiptir. Randy, teknoloji alanında yazılım mühendisliğinden ürün yönetimine kadar çeşitli pozisyonlarda bulundu. 2013 yılında Büyük Veri alanına girdi ve bu alanı keşfetmeye devam ediyor. Makine öğrenimi alanındaki projeler üzerinde aktif olarak çalışıyor ve Strata ve GlueCon dahil olmak üzere çok sayıda konferansta sunum yaptı.
Randy DeFauw AWS'de Kıdemli Baş Çözüm Mimarıdır. Otonom araçlar için bilgisayar görüşü üzerinde çalıştığı Michigan Üniversitesi'nden bir MSEE sahibidir. Ayrıca Colorado Eyalet Üniversitesi'nden MBA derecesine sahiptir. Randy, teknoloji alanında yazılım mühendisliğinden ürün yönetimine kadar çeşitli pozisyonlarda bulundu. 2013 yılında Büyük Veri alanına girdi ve bu alanı keşfetmeye devam ediyor. Makine öğrenimi alanındaki projeler üzerinde aktif olarak çalışıyor ve Strata ve GlueCon dahil olmak üzere çok sayıda konferansta sunum yaptı.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/use-a-generative-ai-foundation-model-for-summarization-and-question-answering-using-your-own-data/

