Herhangi bir üretken yapay zeka uygulaması oluşturmak için büyük dil modellerini (LLM'ler) yeni verilerle zenginleştirmek zorunludur. Alma Artırılmış Üretim (RAG) tekniğinin devreye girdiği yer burasıdır. RAG, bilgisini artırmak ve bilgi yoğun görevlerde en son teknolojiye sahip sonuçlara ulaşmak için harici belgeleri (Wikipedia gibi) kullanan bir makine öğrenimi (ML) mimarisidir. . Bu harici veri kaynaklarını almak için, veri kaynağının vektör yerleştirmelerini depolayabilen ve benzerlik aramalarına olanak tanıyan Vector veritabanları geliştirilmiştir.
Bu yazıda, büyük miktarda veriyi bir sunucuya almak için bir RAG ayıklama, dönüştürme ve yükleme (ETL) alma hattının nasıl oluşturulacağını gösteriyoruz. Amazon Açık Arama Hizmeti kümeleme ve kullanma PostgreSQL için Amazon İlişkisel Veritabanı Hizmeti (Amazon RDS) bir vektör veri deposu olarak pgvector uzantısıyla. Her hizmet, benzerliği hesaplamak için k-en yakın komşu (k-NN) veya yaklaşık en yakın komşu (ANN) algoritmalarını ve mesafe ölçümlerini uygular. Entegrasyonunu tanıtıyoruz ışın RAG bağlamsal belge alma mekanizmasına. Ray, açık kaynaklı, Python, genel amaçlı, dağıtılmış bir bilgi işlem kütüphanesidir. Dağıtılmış veri işlemenin, birden fazla GPU arasında paralelleşerek büyük miktarda veri için yerleştirmeler oluşturmasına ve depolamasına olanak tanır. Her hizmet için paralel alım ve sorgulamayı çalıştırmak amacıyla bu GPU'larla birlikte bir Ray kümesi kullanıyoruz.
Bu deneyde OpenSearch Hizmeti ve Amazon RDS'deki pgvector uzantısı için aşağıdaki hususları analiz etmeye çalışıyoruz:
- Bir vektör deposu olarak, RAG için on milyonlarca kayıttan oluşan büyük bir veri kümesini ölçeklendirme ve işleme yeteneği
- RAG için alma hattındaki olası darboğazlar
- OpenSearch Service ve Amazon RDS için alım ve sorgu alma sürelerinde optimum performansa nasıl ulaşılır?
Vektör veri depoları ve bunların üretken yapay zeka uygulamaları oluşturmadaki rolleri hakkında daha fazla bilgi edinmek için bkz. Üretken yapay zeka uygulamalarında vektör veri depolarının rolü.
OpenSearch Hizmetine Genel Bakış
OpenSearch Hizmeti, iş ve operasyonel verilerin güvenli analizi, aranması ve indekslenmesi için yönetilen bir hizmettir. OpenSearch Hizmeti, metin ve vektör verileri üzerinde birden fazla dizin oluşturma yeteneği ile petabayt ölçekli verileri destekler. Optimize edilmiş konfigürasyon ile sorguların yüksek hatırlanabilirliğini hedefler. OpenSearch Hizmeti, ANN'nin yanı sıra tam k-NN aramasını da destekler. OpenSearch Hizmeti, aşağıdaki algoritmalardan bir seçimini destekler: NMSLIB, FAİS, ve Lusen k-NN aramasını güçlendirecek kütüphaneler. OpenSearch için YSA dizinini Hiyerarşik Gezinilebilir Küçük Dünya (HNSW) algoritmasıyla oluşturduk çünkü bu, büyük veri kümeleri için daha iyi bir arama yöntemi olarak kabul ediliyor. İndeks algoritmasının seçimi hakkında daha fazla bilgi için bkz. OpenSearch ile milyar ölçekli kullanım durumunuz için k-NN algoritmasını seçin.
pgvector ile Amazon RDS for PostgreSQL'e genel bakış
pgvector uzantısı PostgreSQL'e açık kaynaklı bir vektör benzerlik araması ekler. PostgreSQL, pgvector uzantısını kullanarak vektör yerleştirmelerde benzerlik aramaları gerçekleştirerek işletmelere hızlı ve yetkin bir çözüm sağlayabilir. pgvector iki tür vektör benzerliği araması sağlar: %100 geri çağırmayla sonuçlanan tam en yakın komşu ve geri çağırma konusunda ödünleşimle tam aramadan daha iyi performans sağlayan yaklaşık en yakın komşu (ANN). Bir dizin üzerinden yapılan aramalar için, aramada kaç tane merkezin kullanılacağını seçebilirsiniz; daha fazla merkez, performanstan ödün vererek daha iyi hatırlama sağlar.
Çözüme genel bakış
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.

Temel bileşenlere daha ayrıntılı olarak bakalım.
Veri kümesi
Örnek sorular sağlamak için derlemiz olarak OSCAR verilerini ve SQUAD veri kümesini kullanıyoruz. Bu veri kümeleri öncelikle Parke dosyalarına dönüştürülür. Daha sonra Parke verilerini gömmelere dönüştürmek için bir Ray kümesi kullanıyoruz. Oluşturulan yerleştirmeler OpenSearch Service'e ve Amazon RDS'ye pgvector ile aktarılır.
OSCAR (Açık Süper Büyük Taramalı Toplu Derlem), dil sınıflandırması ve Ortak Tarama korpusu kullanarak inatçı mimari. Veriler dile göre hem orijinal hem de tekilleştirilmiş biçimde dağıtılır. Oscar Corpus veri kümesi yaklaşık 609 milyon kayıttan oluşur ve ham JSONL dosyaları olarak yaklaşık 4.5 TB yer kaplar. JSONL dosyaları daha sonra Parquet formatına dönüştürülür ve bu da toplam boyutun 1.8 TB'a indirilmesini sağlar. Besleme sırasında zamandan tasarruf etmek için veri kümesini 25 milyon kayda kadar ölçeklendirdik.
SQuAD (Stanford Soru Yanıtlama Veri Seti), her sorunun cevabının bir metin bölümü olduğu veya kalabalık çalışanların bir dizi Wikipedia makalesi üzerinde sorduğu sorulardan oluşan bir okuduğunu anlama veri kümesidir veya karış, karşılık gelen okuma pasajından veya soru cevaplanamayabilir. Kullanırız KADROolarak lisanslanmıştır CC-BY-SA Örnek sorular sağlamak için 4.0. Kalabalık çalışanlar tarafından cevaplanabilir sorulara benzer görünmek için yazılan 100,000'den fazla cevaplanamaz soruyla birlikte yaklaşık 50,000 soru içerir.
Alım ve vektör yerleştirmeleri oluşturmak için ışın kümesi
Testlerimizde, yerleştirmeleri oluştururken performans üzerinde en büyük etkiyi GPU'ların yaptığını gördük. Bu nedenle ham metnimizi dönüştürmek ve yerleştirmeleri oluşturmak için bir Ray kümesi kullanmaya karar verdik. ışın ML mühendislerinin ve Python geliştiricilerinin Python uygulamalarını ölçeklendirmesine ve ML iş yüklerini hızlandırmasına olanak tanıyan açık kaynaklı bir birleşik bilgi işlem çerçevesidir. Kümemiz 5 g4dn.12xlarge'den oluşuyordu Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) örnekleri. Her örnek 4 NVIDIA T4 Tensor Core GPU, 48 vCPU ve 192 GiB bellek ile yapılandırılmıştır. Metin kayıtlarımız için, her birini 1,000 parçalık örtüşmeyle 100 parçaya böldük. Bu, kayıt başına yaklaşık 200'e kadar çıkıyor. Gömmeler oluşturmak için kullanılan model için şuna karar verdik: tüm-mpnet-base-v2 768 boyutlu bir vektör uzayı oluşturmak için.
altyapı kurulumu
Altyapımızı kurmak için aşağıdaki RDS bulut sunucusu türlerini ve OpenSearch hizmet kümesi yapılandırmalarını kullandık.
Aşağıdakiler RDS bulut sunucusu tipi özelliklerimizdir:
- Bulut sunucusu türü: db.r7g.12xlarge
- Ayrılan depolama alanı: 20 TB
- Multi-AZ: Doğru
- Depolama şifrelendi: Doğru
- Performans Analizlerini Etkinleştir: Doğru
- Performans Analizlerini saklama: 7 gün
- Depolama türü: gp3
- Sağlanan IOPS: 64,000
- İndeks türü: IVF
- Liste sayısı: 5,000
- Mesafe fonksiyonu: L2
OpenSearch Hizmeti küme özelliklerimiz şunlardır:
- Sürüm: 2.5
- Veri düğümleri: 10
- Veri düğümü örnek türü: r6g.4xlarge
- Birincil düğümler: 3
- Birincil düğüm bulut sunucusu türü: r6g.xlarge
- Dizin: HNSW motoru:
nmslib - Yenileme aralığı: 30 saniye
ef_construction: 256- m: 16
- Mesafe fonksiyonu: L2
Performans darboğazlarını önlemek amacıyla hem OpenSearch Hizmeti kümesi hem de RDS örnekleri için büyük yapılandırmalar kullandık.
Çözümü bir kullanarak dağıtıyoruz AWS Bulut Geliştirme Kiti (AWS CDK'sı) yığın, aşağıdaki bölümde anlatıldığı gibi.
AWS CDK yığınını dağıtın
AWS CDK yığını, verileri almak için OpenSearch Service'i veya Amazon RDS'yi seçmemize olanak tanır.
Önkoşullar
Kuruluma devam etmeden önce cdk, bin, src.tc altında Amazon RDS ve OpenSearch Service için Boolean değerlerini tercihinize bağlı olarak true veya false olarak değiştirin.
Ayrıca hizmet bağlantılı bir AWS Kimlik ve Erişim Yönetimi OpenSearch Hizmeti alanı için (IAM) rolü. Daha fazla ayrıntı için bkz. Amazon OpenSearch Hizmeti Yapı Kitaplığı. Rolü oluşturmak için aşağıdaki komutu da çalıştırabilirsiniz:
Bu AWS CDK yığını aşağıdaki altyapıyı dağıtacaktır:
- Bir VPC
- Bir atlama ana bilgisayarı (VPC'nin içinde)
- Bir OpenSearch Hizmeti kümesi (besleme için OpenSearch hizmeti kullanılıyorsa)
- Bir RDS örneği (besleme için Amazon RDS kullanılıyorsa)
- An AWS Sistem Yöneticisi Ray kümesinin dağıtımına ilişkin belge
- An Amazon Basit Depolama Hizmeti (Amazon S3) kova
- An AWS Tutkal OSCAR veri kümesi JSONL dosyalarını Parke dosyalarına dönüştürme işi
- Amazon Bulut İzleme gösterge tabloları
Verileri indirin
Atlama ana bilgisayarından aşağıdaki komutları çalıştırın:
Git deposunu klonlamadan önce Hugging Face profilinize sahip olduğunuzdan ve OSCAR veri kümesine erişiminiz olduğundan emin olun. OSCAR verilerini klonlamak için kullanıcı adını ve şifreyi kullanmanız gerekir:
JSONL dosyalarını Parke'ye dönüştürün
AWS CDK yığını, AWS Glue ETL işini oluşturdu oscar-jsonl-parquet OSCAR verilerini JSONL'den Parquet formatına dönüştürmek için.
Koştuktan sonra oscar-jsonl-parquet iş, Parquet formatındaki dosyaların S3 klasöründeki parke klasörü altında mevcut olması gerekir.
Soruları indirin
Jump sunucunuzdan soru verilerini indirin ve S3 klasörünüze yükleyin:
Ray kümesini ayarlama
AWS CDK yığın dağıtımının bir parçası olarak, adında bir Sistem Yöneticisi belgesi oluşturduk. CreateRayCluster.
Belgeyi çalıştırmak için aşağıdaki adımları tamamlayın:
- Systems Manager konsolunda, altında evraklar gezinme bölmesinde öğesini seçin. Bana ait.
- Açın
CreateRayClusterbelge. - Klinik koşmak.
Çalıştır komut sayfasında küme için doldurulmuş varsayılan değerler bulunur.
Varsayılan yapılandırma 5 g4dn.12xlarge ister. Hesabınızın bunu destekleyecek sınırlara sahip olduğundan emin olun. İlgili hizmet sınırı, İsteğe Bağlı G ve VT bulut sunucularının çalıştırılmasıdır. Bunun için varsayılan değer 64'tür ancak bu yapılandırma 240 CPUS gerektirir.
- Küme yapılandırmasını inceledikten sonra, çalıştırma komutunun hedefi olarak atlama ana bilgisayarını seçin.
Bu komut aşağıdaki adımları gerçekleştirecektir:
- Ray kümesi dosyalarını kopyalayın
- Ray kümesini ayarlama
- OpenSearch Hizmeti dizinlerini ayarlama
- RDS tablolarını ayarlama
Komutların çıktısını Systems Manager konsolunda izleyebilirsiniz. Bu işlem ilk başlatma için 10-15 dakika sürecektir.
Beslemeyi çalıştır
Atlama ana bilgisayarından Ray kümesine bağlanın:
Ana bilgisayara ilk kez bağlandığınızda gereksinimleri yükleyin. Bu dosyalar zaten baş düğümde mevcut olmalıdır.
Besleme yöntemlerinden herhangi birinde aşağıdakine benzer bir hata alırsanız bu, süresi dolmuş kimlik bilgileriyle ilgilidir. Mevcut geçici çözüm (bu yazının yazıldığı an itibariyle), kimlik bilgisi dosyalarını Ray kafası düğümüne yerleştirmektir. Güvenlik risklerinden kaçınmak için, amaca yönelik yazılım geliştirirken veya gerçek verilerle çalışırken kimlik doğrulama için IAM kullanıcılarını kullanmayın. Bunun yerine, aşağıdaki gibi bir kimlik sağlayıcıyla federasyonu kullanın: AWS IAM Identity Center (AWS Single Sign-On'un halefi).
Genellikle kimlik bilgileri dosyada saklanır ~/.aws/credentials Linux ve macOS sistemlerinde ve %USERPROFILE%.awscredentials Windows'ta, ancak bunlar oturum belirtecine sahip kısa vadeli kimlik bilgileridir. Ayrıca varsayılan kimlik bilgisi dosyasını geçersiz kılamazsınız ve bu nedenle, yeni bir IAM kullanıcısını kullanarak oturum belirteci olmadan uzun vadeli kimlik bilgileri oluşturmanız gerekir.
Uzun vadeli kimlik bilgileri oluşturmak için bir AWS erişim anahtarı ve AWS gizli erişim anahtarı oluşturmanız gerekir. Bunu IAM konsolundan yapabilirsiniz. Talimatlar için bkz. IAM kullanıcı kimlik bilgileriyle kimlik doğrulama.
Anahtarları oluşturduktan sonra atlama ana bilgisayarına şunu kullanarak bağlanın: Oturum YöneticisiSystems Manager'ın bir yeteneği olan .
Artık alım adımlarını yeniden çalıştırabilirsiniz.
Verileri OpenSearch Hizmetine aktarın
OpenSearch hizmetini kullanıyorsanız dosyaları almak için aşağıdaki komut dosyasını çalıştırın:
Tamamlandığında, simüle edilmiş sorguları çalıştıran betiği çalıştırın:
Verileri Amazon RDS'ye aktarın
Amazon RDS kullanıyorsanız dosyaları almak için aşağıdaki betiği çalıştırın:
Tamamlandığında, RDS örneğinde tam bir vakum çalıştırdığınızdan emin olun.
Daha sonra simüle edilmiş sorguları çalıştırmak için aşağıdaki betiği çalıştırın:
Ray kontrol panelini ayarlama
Ray kontrol panelini kurmadan önce, Ray kontrol panelini kurmanız gerekir. AWS Komut Satırı Arayüzü (AWS CLI) yerel makinenizde. Talimatlar için bkz. AWS CLI'nin en son sürümünü yükleyin veya güncelleyin.
Kontrol panelini ayarlamak için aşağıdaki adımları tamamlayın:
- kurmak Oturum Yöneticisi eklentisi AWS CLI için.
- Isengard hesabında bash/zsh için geçici kimlik bilgilerini kopyalayın ve yerel terminalinizde çalıştırın.
- Makinenizde bir session.sh dosyası oluşturun ve aşağıdaki içeriği dosyaya kopyalayın:
- Bu session.sh dosyasının depolandığı dizini değiştirin.
- Komutu çalıştır
Chmod +xDosyaya yürütülebilir izin vermek için. - Aşağıdaki komutu çalıştırın:
Örneğin:
Aşağıdaki gibi bir mesaj göreceksiniz:
Tarayıcınızda yeni bir sekme açın ve localhost:8265 yazın.
Ray kontrol panelini ve çalışan işlerin ve kümenin istatistiklerini göreceksiniz. Metrikleri buradan takip edebilirsiniz.
Örneğin, kümedeki yükü gözlemlemek için Ray kontrol panelini kullanabilirsiniz. Aşağıdaki ekran görüntüsünde gösterildiği gibi, alım sırasında GPU'lar %100'e yakın kullanımla çalışıyor.
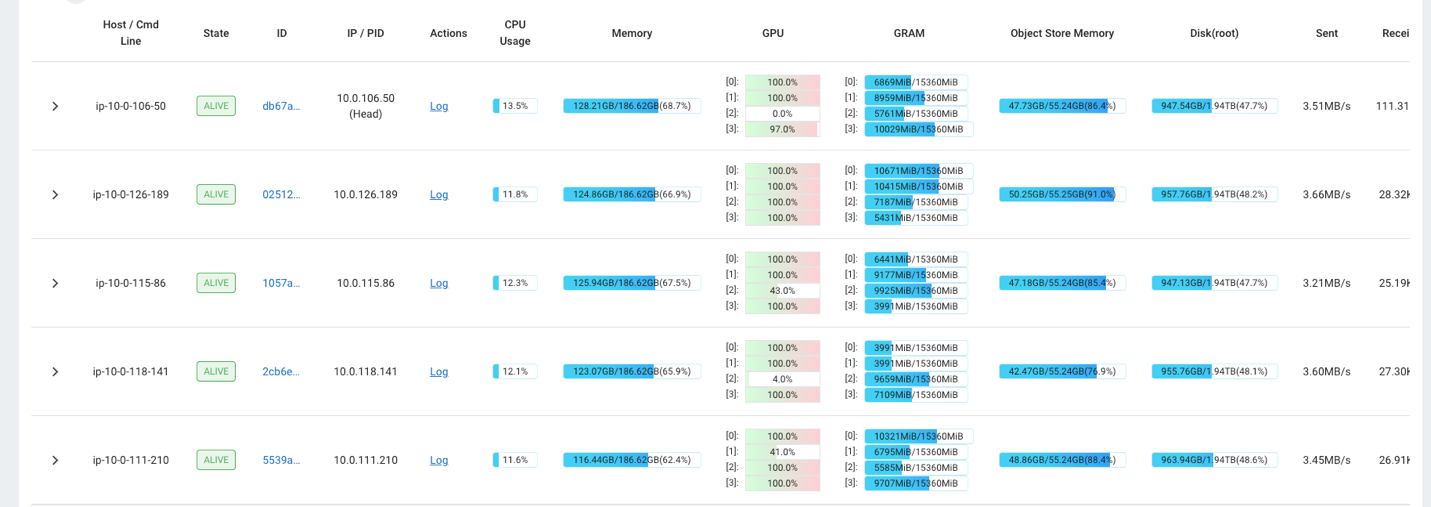
Ayrıca kullanabilirsiniz RAG_Benchmarks Besleme oranını ve sorgu yanıt sürelerini görmek için CloudWatch kontrol paneli.
Çözümün genişletilebilirliği
Bu çözümü diğer AWS veya üçüncü taraf vektör mağazalarını takacak şekilde genişletebilirsiniz. Her yeni vektör deposu için veri deposunu yapılandırmanın yanı sıra verileri almak için komut dosyaları oluşturmanız gerekecektir. Boru hattının geri kalanı gerektiğinde yeniden kullanılabilir.
Sonuç
Bu gönderide, vektörleştirilmiş RAG verilerini hem OpenSearch Service'e hem de Amazon RDS'ye pgvector uzantısıyla vektör veri depoları olarak yerleştirmek için kullanabileceğiniz bir ETL işlem hattını paylaştık. Çözüm, büyük bir veri kümesini almak için gerekli paralelliği sağlamak amacıyla bir Ray kümesi kullandı. RAG işlem hatları oluşturmak amacıyla seçtiğiniz herhangi bir vektör veritabanını entegre etmek için bu metodolojiyi kullanabilirsiniz.
Yazarlar Hakkında
 Randy DeFauw AWS'de Kıdemli Baş Çözüm Mimarıdır. Otonom araçlar için bilgisayarlı görme üzerinde çalıştığı Michigan Üniversitesi'nden MSEE derecesine sahiptir. Aynı zamanda Colorado Eyalet Üniversitesi'nden MBA derecesine sahiptir. Randy, teknoloji alanında yazılım mühendisliğinden ürün yönetimine kadar çeşitli pozisyonlarda bulunmuştur. 2013 yılında büyük veri alanına girdi ve bu alanı keşfetmeye devam ediyor. Aktif olarak ML alanındaki projeler üzerinde çalışıyor ve Strata ve GlueCon da dahil olmak üzere çok sayıda konferansta sunum yaptı.
Randy DeFauw AWS'de Kıdemli Baş Çözüm Mimarıdır. Otonom araçlar için bilgisayarlı görme üzerinde çalıştığı Michigan Üniversitesi'nden MSEE derecesine sahiptir. Aynı zamanda Colorado Eyalet Üniversitesi'nden MBA derecesine sahiptir. Randy, teknoloji alanında yazılım mühendisliğinden ürün yönetimine kadar çeşitli pozisyonlarda bulunmuştur. 2013 yılında büyük veri alanına girdi ve bu alanı keşfetmeye devam ediyor. Aktif olarak ML alanındaki projeler üzerinde çalışıyor ve Strata ve GlueCon da dahil olmak üzere çok sayıda konferansta sunum yaptı.
 David Hıristiyan Güney Kaliforniya merkezli bir Baş Çözüm Mimarıdır. Lisans eğitimini Bilgi Güvenliği alanında tamamladı ve otomasyona tutkuyla bağlı. Odaklandığı alanlar DevOps kültürü ve dönüşümü, kod olarak altyapı ve esnekliktir. AWS'ye katılmadan önce güvenlik, DevOps ve sistem mühendisliği alanlarında görev alarak büyük ölçekli özel ve genel bulut ortamlarını yönetti.
David Hıristiyan Güney Kaliforniya merkezli bir Baş Çözüm Mimarıdır. Lisans eğitimini Bilgi Güvenliği alanında tamamladı ve otomasyona tutkuyla bağlı. Odaklandığı alanlar DevOps kültürü ve dönüşümü, kod olarak altyapı ve esnekliktir. AWS'ye katılmadan önce güvenlik, DevOps ve sistem mühendisliği alanlarında görev alarak büyük ölçekli özel ve genel bulut ortamlarını yönetti.
 Prachi Kulkarni AWS'de Kıdemli Çözüm Mimarıdır. Uzmanlığı makine öğrenimidir ve çeşitli AWS ML, büyük veri ve analiz tekliflerini kullanarak çözümler tasarlamak üzerinde aktif olarak çalışmaktadır. Prachi, sağlık hizmetleri, sosyal haklar, perakende ve eğitim dahil olmak üzere birçok alanda deneyime sahiptir ve ürün mühendisliği ve mimarisi, yönetim ve müşteri başarısı alanlarında çeşitli pozisyonlarda çalışmıştır.
Prachi Kulkarni AWS'de Kıdemli Çözüm Mimarıdır. Uzmanlığı makine öğrenimidir ve çeşitli AWS ML, büyük veri ve analiz tekliflerini kullanarak çözümler tasarlamak üzerinde aktif olarak çalışmaktadır. Prachi, sağlık hizmetleri, sosyal haklar, perakende ve eğitim dahil olmak üzere birçok alanda deneyime sahiptir ve ürün mühendisliği ve mimarisi, yönetim ve müşteri başarısı alanlarında çeşitli pozisyonlarda çalışmıştır.
 Richa Gupta AWS'de Çözüm Mimarıdır. Müşteriler için uçtan uca çözümler tasarlama konusunda tutkulu. Uzmanlık alanı makine öğrenimi ve bunun operasyonel mükemmelliğe yol açan ve iş gelirini artıran yeni çözümler oluşturmak için nasıl kullanılabileceğidir. AWS'ye katılmadan önce Yazılım Mühendisi ve Çözüm Mimarı olarak büyük telekom operatörleri için çözümler üreterek çalıştı. İş dışında yeni yerler keşfetmeyi ve macera dolu aktiviteleri seviyor.
Richa Gupta AWS'de Çözüm Mimarıdır. Müşteriler için uçtan uca çözümler tasarlama konusunda tutkulu. Uzmanlık alanı makine öğrenimi ve bunun operasyonel mükemmelliğe yol açan ve iş gelirini artıran yeni çözümler oluşturmak için nasıl kullanılabileceğidir. AWS'ye katılmadan önce Yazılım Mühendisi ve Çözüm Mimarı olarak büyük telekom operatörleri için çözümler üreterek çalıştı. İş dışında yeni yerler keşfetmeyi ve macera dolu aktiviteleri seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

