Bu blog yazısı Veoneer'dan Caroline Chung ile birlikte yazılmıştır.
Veoneer küresel bir otomotiv elektroniği şirketidir ve otomotiv elektronik güvenlik sistemlerinde dünya lideridir. Sınıfının en iyisi emniyet kontrol sistemlerini sunuyorlar ve dünya çapındaki otomobil üreticilerine 1 milyardan fazla elektronik kontrol ünitesi ve çarpışma sensörü teslim ettiler. Şirket, trafik olaylarını önleyen ve kazaları azaltan son teknoloji donanım ve sistemler konusunda uzmanlaşarak, otomotiv güvenliği alanındaki 70 yıllık gelişim geçmişini geliştirmeye devam ediyor.
Otomotiv kabin içi algılama (ICS), güvenliği artırmak ve sürüş deneyimini iyileştirmek için kameralar ve radar gibi çeşitli sensör türlerinin ve yapay zeka (AI) ve makine öğrenimi (ML) tabanlı algoritmaların bir kombinasyonunu kullanan, yeni ortaya çıkan bir alandır. Böyle bir sistemi oluşturmak karmaşık bir iş olabilir. Geliştiricilerin, eğitim ve test amacıyla büyük hacimli görüntülere manuel olarak açıklama eklemesi gerekir. Bu çok zaman alıcı ve kaynak yoğun bir işlemdir. Böyle bir görevin geri dönüş süresi birkaç haftadır. Ayrıca şirketler, insan hatalarından kaynaklanan tutarsız etiketler gibi sorunlarla da uğraşmak zorunda kalıyor.
AWS, makine öğrenimi gibi gelişmiş analizler aracılığıyla geliştirme hızınızı artırmanıza ve bu tür sistemler oluşturma maliyetlerinizi azaltmanıza yardımcı olmaya odaklanmıştır. Vizyonumuz, otomatik açıklama ekleme için ML'yi kullanmak, güvenlik modellerinin yeniden eğitilmesini sağlamak ve tutarlı ve güvenilir performans ölçümleri sağlamaktır. Bu yazıda, Amazon'un Dünya Çapındaki Uzman Organizasyonu ve Üretken Yapay Zeka İnovasyon Merkezi, kabin içi görüntü kafası sınırlayıcı kutular ve önemli noktalara ilişkin açıklamalar için aktif bir öğrenme hattı geliştirdik. Çözüm, maliyeti %90'ın üzerinde azaltır, geri dönüş süresi açısından açıklama sürecini haftalardan saatlere kadar hızlandırır ve benzer ML veri etiketleme görevleri için yeniden kullanılabilirliğe olanak tanır.
Çözüme genel bakış
Aktif öğrenme, bir modeli eğitmek için en bilgilendirici verileri seçme ve açıklama eklemeye yönelik yinelemeli bir süreci içeren bir makine öğrenimi yaklaşımıdır. Küçük bir etiketli veri kümesi ve büyük bir etiketlenmemiş veri kümesi göz önüne alındığında, aktif öğrenme model performansını artırır, etiketleme çabasını azaltır ve sağlam sonuçlar için insan uzmanlığını entegre eder. Bu yazıda AWS hizmetleriyle görüntü açıklamaları için aktif bir öğrenme hattı oluşturuyoruz.
Aşağıdaki şema aktif öğrenme sürecimizin genel çerçevesini göstermektedir. Etiketleme hattı görüntüleri bir Amazon Basit Depolama Hizmeti (Amazon S3) makine öğrenimi modelleri ve insan uzmanlığının işbirliğiyle açıklamalı görüntüleri paketler ve çıkarır. Eğitim hattı verileri önceden işler ve bunları makine öğrenimi modellerini eğitmek için kullanır. İlk model, manuel olarak etiketlenmiş küçük bir veri kümesi üzerinde kurulup eğitiliyor ve etiketleme hattında kullanılacak. Etiketleme hattı ve eğitim hattı, modelin performansını artırmak için daha fazla etiketli veriyle kademeli olarak yinelenebilir.
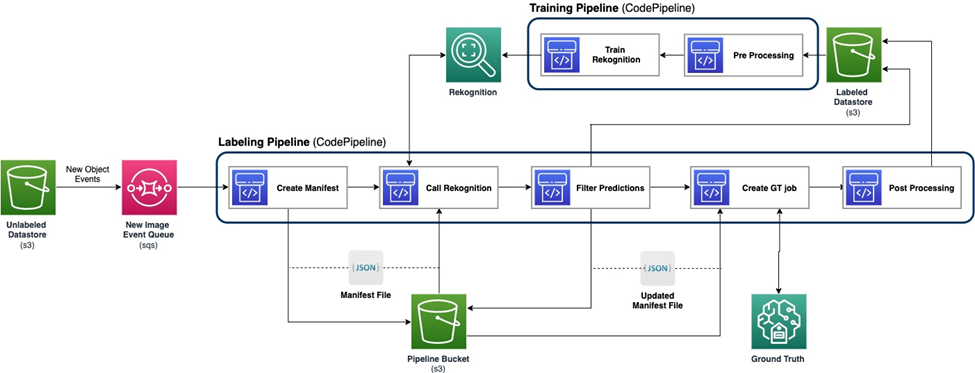
Etiketleme hattında, Amazon S3 Etkinlik Bildirimi Etiketlenmemiş Datastore S3 klasörüne yeni bir görüntü kümesi geldiğinde etiketleme ardışık düzenini etkinleştirerek çağrılır. Model, yeni görüntüler üzerinde çıkarım sonuçlarını üretir. Özelleştirilmiş bir değerlendirme işlevi, çıkarım güven puanına veya diğer kullanıcı tanımlı işlevlere dayalı olarak veri bölümlerini seçer. Bu veriler, çıkarım sonuçlarıyla birlikte, bir insan etiketleme işi için gönderilir. Amazon SageMaker Yer Gerçeği boru hattı tarafından oluşturulmuştur. İnsan etiketleme süreci, verilere açıklama eklenmesine yardımcı olur ve değiştirilen sonuçlar, daha sonra eğitim hattı tarafından kullanılabilecek, kalan otomatik açıklama eklenmiş verilerle birleştirilir.
Modelin yeniden eğitimi, modeli yeniden eğitmek için insan etiketli verileri içeren veri kümesini kullandığımız eğitim hattında gerçekleşir. Dosyaların nerede saklandığını açıklamak için bir bildirim dosyası oluşturulur ve aynı başlangıç modeli yeni veriler üzerinde yeniden eğitilir. Yeniden eğitimin ardından yeni model, ilk modelin yerini alır ve aktif öğrenme hattının bir sonraki yinelemesi başlar.
Model dağıtımı
Hem etiketleme hattı hem de eğitim hattı şuralarda konuşlandırılmıştır: AWS Kod Ardışık Düzeni. AWS Kod Oluşturma Küçük miktarda veri için esnek ve hızlı olan uygulama için örnekler kullanılır. Hız gerektiğinde kullanırız Amazon Adaçayı Yapıcı Süreci desteklemek ve hızlandırmak için daha fazla kaynak tahsis etmek üzere GPU örneğini temel alan uç noktalar.
Model yeniden eğitim hattı, yeni veri kümesi olduğunda veya modelin performansının iyileştirilmesi gerektiğinde çağrılabilir. Yeniden eğitim hattındaki kritik görevlerden biri, hem eğitim verileri hem de model için sürüm kontrol sistemine sahip olmaktır. Her ne kadar AWS hizmetleri gibi Amazon Rekognisyon İşlem hattının uygulanmasını kolaylaştıran entegre sürüm kontrolü özelliğine sahiptir; özelleştirilmiş modeller, meta veri kaydı veya ek sürüm kontrol araçları gerektirir.
Tüm iş akışı aşağıdakiler kullanılarak gerçekleştirilir: AWS Bulut Geliştirme Kiti (AWS CDK) ile aşağıdakiler de dahil olmak üzere gerekli AWS bileşenlerini oluşturun:
- CodePipeline ve SageMaker işleri için iki rol
- İş akışını düzenleyen iki CodePipeline işi
- İşlem hatlarının kod yapıları için iki S3 klasörü
- İş bildirimini, veri kümelerini ve modellerini etiketlemek için bir S3 klasörü
- Ön işleme ve son işleme AWS Lambda SageMaker Ground Truth etiketleme işlerine yönelik işlevler
AWS CDK yığınları son derece modülerdir ve farklı görevlerde yeniden kullanılabilir. Eğitim, çıkarım kodu ve SageMaker Ground Truth şablonu, benzer aktif öğrenme senaryoları için değiştirilebilir.
Model eğitimi
Model eğitimi iki görevi içerir: kafa sınırlayıcı kutu açıklaması ve insan anahtar noktaları açıklaması. Bu bölümde ikisini de tanıtıyoruz.
Kafa sınırlayıcı kutu açıklaması
Kafa sınırlayıcı kutu açıklaması, bir görüntüdeki insan kafasının sınırlayıcı kutusunun konumunu tahmin etmeye yönelik bir görevdir. Bir kullanıyoruz Amazon Rekognition Özel Etiketleri kafa sınırlayıcı kutu açıklamaları için model. Aşağıdaki örnek dizüstü Rekognition Özel Etiketler modelinin SageMaker aracılığıyla nasıl eğitileceğine ilişkin adım adım eğitim sağlar.
Eğitime başlamak için öncelikle verileri hazırlamamız gerekiyor. Eğitim için bir manifest dosyası ve test veri seti için bir manifest dosyası oluşturuyoruz. Bir bildirim dosyası, her biri bir görüntüye ait olan birden çok öğe içerir. Aşağıda görüntü yolu, boyutu ve ek açıklama bilgilerini içeren bildirim dosyasının bir örneği yer almaktadır:
Bildirim dosyalarını kullanarak, eğitim ve test için veri kümelerini Rekognition Özel Etiketler modeline yükleyebiliriz. Modeli farklı miktarlardaki eğitim verileriyle yineledik ve aynı 239 görünmeyen görüntü üzerinde test ettik. Bu testte, mAP_50 puan 0.33 eğitim görseli ile 114'ten 0.95 eğitim görseli ile 957'e yükseldi. Aşağıdaki ekran görüntüsü, F1 puanı, hassasiyet ve geri çağırma açısından mükemmel performans sağlayan son Rekognition Özel Etiketler modelinin performans ölçümlerini göstermektedir.

Modeli, 1,128 görüntüden oluşan gizli bir veri kümesi üzerinde de test ettik. Model, görünmeyen veriler üzerinde tutarlı bir şekilde doğru sınırlayıcı kutu tahminlerini tahmin ederek yüksek bir sonuç verir. mAP_50 %94.9. Aşağıdaki örnekte, kafa sınırlama kutusu bulunan, otomatik açıklama eklenmiş bir görüntü gösterilmektedir.

Önemli noktalar açıklaması
Anahtar noktalar açıklaması, gözler, kulaklar, burun, ağız, boyun, omuzlar, dirsekler, bilekler, kalçalar ve ayak bilekleri dahil olmak üzere anahtar noktaların konumlarını üretir. Yeni bir yöntem tasarladığımız bu özel görevde, konum tahminine ek olarak, her noktanın görünürlüğüne de ihtiyaç duyulmaktadır.
Önemli noktalara ilişkin açıklamalar için bir Yolo 8 Poz modeli İlk model olarak SageMaker'da. İlk olarak, Yolo'nun gereksinimlerine uygun olarak etiket dosyaları ve bir yapılandırma .yaml dosyası oluşturmak da dahil olmak üzere verileri eğitim için hazırlıyoruz. Verileri hazırladıktan sonra modeli eğitiyoruz ve model ağırlıkları dosyası da dahil olmak üzere yapıtları kaydediyoruz. Eğitilmiş model ağırlıkları dosyasıyla yeni görüntülere açıklama ekleyebiliriz.
Eğitim aşamasında, görünür noktalar ve kapalı noktalar da dahil olmak üzere konumları olan tüm etiketli noktalar eğitim için kullanılır. Bu nedenle, bu model varsayılan olarak tahminin konumunu ve güvenirliğini sağlar. Aşağıdaki şekilde, 0.6'ya yakın büyük bir güven eşiği (ana eşik), kameranın bakış açılarının dışındaki görünür veya kapalı noktaları bölme yeteneğine sahiptir. Ancak, kapalı noktalar ve görünen noktalar güven ile ayrılmamaktadır; bu, tahmin edilen güvenin görünürlüğü tahmin etmede kullanışlı olmadığı anlamına gelmektedir.

Görünürlük tahminini elde etmek için, hem kapalı noktaları hem de kameranın bakış açılarının dışını hariç tutarak, yalnızca görünür noktaları içeren veri kümesi üzerinde eğitilmiş ek bir model sunuyoruz. Aşağıdaki şekil farklı görünürlüğe sahip noktaların dağılımını göstermektedir. Ek modelde görünen noktalar ve diğer noktalar ayrılabilir. Görünür noktaları elde etmek için 0.6'ya yakın bir eşik (ek eşik) kullanabiliriz. Bu iki modeli birleştirerek konum ve görünürlüğü tahmin edecek bir yöntem tasarlıyoruz.

Bir anahtar nokta ilk önce konum ve ana güven ile ana model tarafından tahmin edilir, daha sonra ek modelden ek güven tahmini elde edilir. Görünürlüğü daha sonra aşağıdaki şekilde sınıflandırılır:
- Ana güveni ana eşiğinden büyükse ve ek güveni ek eşikten büyükse görünür
- Ana güveni ana eşiğinden büyükse ve ek güveni ek eşiğe eşit veya ondan küçükse tıkalı
- Aksi takdirde kamera incelemesi dışında
Temel noktalar açıklamasının bir örneği aşağıdaki görüntüde gösterilmektedir; burada katı işaretler görünür noktalardır ve içi boş işaretler kapalı noktalardır. Kameranın dışındaki inceleme noktaları gösterilmez.

Standarda göre OKS MS-COCO veri kümesindeki tanımdan yola çıkarak yöntemimiz, görünmeyen test veri kümesinde %50 mAP_98.4 değerine ulaşabilmektedir. Görünürlük açısından yöntem, aynı veri kümesinde %79.2'lik bir sınıflandırma doğruluğu sağlar.
İnsan etiketleme ve yeniden eğitim
Her ne kadar modeller test verileri üzerinde mükemmel performans gösterse de yeni gerçek dünya verilerinde hata yapma olasılıkları hala mevcut. İnsan etiketleme, yeniden eğitim kullanarak model performansını artırmak için bu hataları düzeltme sürecidir. Tüm kafa sınırlayıcı kutu veya anahtar noktaların çıktısı için ML modellerinden çıkan güven değerini birleştiren bir değerlendirme fonksiyonu tasarladık. Bu hataları ve sonuçta ortaya çıkan, insan etiketleme sürecine gönderilmesi gereken kötü etiketlenmiş görüntüleri tanımlamak için son puanı kullanırız.
Kötü etiketlenmiş görsellerin yanı sıra, görsellerin küçük bir kısmı da insanlar tarafından etiketlenmek üzere rastgele seçilmektedir. İnsan etiketli bu görüntüler, yeniden eğitim, model performansının ve genel açıklama doğruluğunun artırılması amacıyla eğitim setinin mevcut sürümüne eklenir.
Uygulamada SageMaker Ground Truth'u kullanıyoruz. insan etiketleme işlem. SageMaker Ground Truth, veri etiketleme için kullanıcı dostu ve sezgisel bir kullanıcı arayüzü sağlar. Aşağıdaki ekran görüntüsü, kafa sınırlayıcı kutu açıklaması için SageMaker Ground Truth etiketleme işini göstermektedir.

Aşağıdaki ekran görüntüsü, önemli noktalara ilişkin açıklamalara yönelik bir SageMaker Ground Truth etiketleme işini göstermektedir.

Maliyet, hız ve yeniden kullanılabilirlik
Aşağıdaki tablolarda da gösterildiği gibi, insan etiketlemeye kıyasla çözümümüzü kullanmanın en önemli avantajları maliyet ve hızdır. Bu tabloları maliyet tasarruflarını ve hızlanmaları temsil etmek için kullanıyoruz. Hızlandırılmış GPU SageMaker örneği ml.g4dn.xlarge kullanıldığında, 100,000 görüntünün tüm yaşam eğitimi ve çıkarım maliyeti, insan etiketleme maliyetinden %99 daha azdır; hız ise, insan etiketlemesinden 10-10,000 kat daha yüksektir. görev.
İlk tablo maliyet performansı ölçümlerini özetlemektedir.
| Model | mAP_50, 1,128 test görüntüsüne dayanmaktadır | Eğitim maliyeti 100,000 görüntüye dayanmaktadır | 100,000 görsele dayalı çıkarım maliyeti | İnsan açıklamasına kıyasla maliyet düşüşü | 100,000 görüntüye dayalı çıkarım süresi | İnsan açıklamasına kıyasla zaman ivmesi |
| Tanıma başlığı sınırlayıcı kutusu | 0.949 | $4 | $22 | 99% daha düşük | 5.5 pm | Günler |
| Yolo Anahtar noktalar | 0.984 | $27.20 | * 10$ | 99.9% daha düşük | dakika | Haftalar |
Aşağıdaki tabloda performans ölçümleri özetlenmektedir.
| Ek Açıklama Görevi | mAP_50 (%) | Eğitim Maliyeti ($) | Çıkarım Maliyeti ($) | Çıkarım Süresi |
| Kafa Sınırlama Kutusu | 94.9 | 4 | 22 | 5.5 saat |
| Anahtar Noktalar | 98.4 | 27 | 10 | 5 dakikadır. |
Üstelik çözümümüz benzer görevler için yeniden kullanılabilirlik sağlıyor. Gelişmiş sürücü destek sistemi (ADAS) ve kabin içi sistemler gibi diğer sistemlere yönelik kamera algılama geliştirmeleri de çözümümüzü benimseyebilir.
Özet
Bu yazıda, AWS hizmetlerini kullanarak kabin içi görüntülere otomatik açıklama eklemek için aktif bir öğrenme hattının nasıl oluşturulacağını gösterdik. Ek açıklama sürecini otomatikleştirmenize ve hızlandırmanıza olanak tanıyan ML'nin gücünü ve AWS hizmetleri tarafından desteklenen veya SageMaker'da özelleştirilmiş modelleri kullanan çerçevenin esnekliğini gösteriyoruz. Amazon S3, SageMaker, Lambda ve SageMaker Ground Truth ile veri depolamayı, açıklama eklemeyi, eğitimi ve dağıtımı kolaylaştırabilir ve maliyetleri önemli ölçüde azaltırken yeniden kullanılabilirlik elde edebilirsiniz. Bu çözümü uygulayarak otomotiv şirketleri, otomatik görüntü açıklaması gibi makine öğrenimi tabanlı gelişmiş analizleri kullanarak daha çevik ve uygun maliyetli hale gelebilir.
Bugün başlayın ve gücün kilidini açın AWS hizmetleri ve otomotiv kabin içi algılama kullanım senaryolarınız için makine öğrenimi!
Yazarlar Hakkında
 Yanxiang Yu Amazon Generative AI İnovasyon Merkezi'nde Uygulamalı Bilim Adamıdır. Endüstriyel uygulamalara yönelik yapay zeka ve makine öğrenimi çözümleri geliştirmede 9 yılı aşkın deneyimiyle üretken yapay zeka, bilgisayarlı görme ve zaman serisi modelleme konularında uzmanlaşmıştır.
Yanxiang Yu Amazon Generative AI İnovasyon Merkezi'nde Uygulamalı Bilim Adamıdır. Endüstriyel uygulamalara yönelik yapay zeka ve makine öğrenimi çözümleri geliştirmede 9 yılı aşkın deneyimiyle üretken yapay zeka, bilgisayarlı görme ve zaman serisi modelleme konularında uzmanlaşmıştır.
 Tianyi Mao Chicago bölgesi dışında bulunan AWS'de Uygulamalı Bilim Adamıdır. Makine öğrenimi ve derin öğrenme çözümleri oluşturma konusunda 5 yıldan fazla deneyime sahiptir ve insan geri bildirimleriyle bilgisayarlı görme ve takviyeli öğrenmeye odaklanmaktadır. AWS hizmetlerini kullanarak yenilikçi çözümler yaratarak karşılaştıkları zorlukları anlamak ve bunları çözmek için müşterilerle birlikte çalışmaktan hoşlanıyor.
Tianyi Mao Chicago bölgesi dışında bulunan AWS'de Uygulamalı Bilim Adamıdır. Makine öğrenimi ve derin öğrenme çözümleri oluşturma konusunda 5 yıldan fazla deneyime sahiptir ve insan geri bildirimleriyle bilgisayarlı görme ve takviyeli öğrenmeye odaklanmaktadır. AWS hizmetlerini kullanarak yenilikçi çözümler yaratarak karşılaştıkları zorlukları anlamak ve bunları çözmek için müşterilerle birlikte çalışmaktan hoşlanıyor.
 Yanru Xiao Amazon Generative AI İnovasyon Merkezi'nde Uygulamalı Bilim Adamıdır ve burada müşterilerin gerçek dünyadaki iş sorunlarına yönelik AI/ML çözümleri geliştirmektedir. İmalat, enerji ve tarım dahil olmak üzere birçok alanda çalıştı. Yanru doktora derecesini aldı. Old Dominion Üniversitesi'nden Bilgisayar Bilimleri alanında.
Yanru Xiao Amazon Generative AI İnovasyon Merkezi'nde Uygulamalı Bilim Adamıdır ve burada müşterilerin gerçek dünyadaki iş sorunlarına yönelik AI/ML çözümleri geliştirmektedir. İmalat, enerji ve tarım dahil olmak üzere birçok alanda çalıştı. Yanru doktora derecesini aldı. Old Dominion Üniversitesi'nden Bilgisayar Bilimleri alanında.
 Paul George otomotiv teknolojilerinde 15 yılı aşkın deneyime sahip başarılı bir ürün lideridir. Ürün yönetimi, strateji, Pazara Çıkış ve sistem mühendisliği ekiplerine liderlik etme konusunda uzmandır. Küresel çapta birçok yeni algılama ve algılama ürününü kuluçkaya yatırdı ve piyasaya sürdü. AWS'de otonom araç iş yüklerine yönelik stratejilere ve pazara açılmaya liderlik ediyor.
Paul George otomotiv teknolojilerinde 15 yılı aşkın deneyime sahip başarılı bir ürün lideridir. Ürün yönetimi, strateji, Pazara Çıkış ve sistem mühendisliği ekiplerine liderlik etme konusunda uzmandır. Küresel çapta birçok yeni algılama ve algılama ürününü kuluçkaya yatırdı ve piyasaya sürdü. AWS'de otonom araç iş yüklerine yönelik stratejilere ve pazara açılmaya liderlik ediyor.
 Caroline Chung Veoneer'de (Magna International tarafından satın alındı) mühendislik müdürüdür ve algılama ve algılama sistemleri geliştirmede 14 yıldan fazla deneyime sahiptir. Şu anda Magna International'da iç mekan algılama ön geliştirme programlarını yönetiyor ve bilgisayarlı görüntü mühendisleri ve veri bilimcilerden oluşan bir ekibi yönetiyor.
Caroline Chung Veoneer'de (Magna International tarafından satın alındı) mühendislik müdürüdür ve algılama ve algılama sistemleri geliştirmede 14 yıldan fazla deneyime sahiptir. Şu anda Magna International'da iç mekan algılama ön geliştirme programlarını yönetiyor ve bilgisayarlı görüntü mühendisleri ve veri bilimcilerden oluşan bir ekibi yönetiyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

