Amazon Adaçayı Yapıcı çok modelli uç noktalar (MME'ler) binlerce modeli tek bir uç noktaya dağıtmanıza olanak tanıyan, SageMaker çıkarımının tam olarak yönetilen bir yeteneğidir. Daha önce MME'ler, CPU hesaplama gücünü model trafik yüküne bakılmaksızın statik olarak modellere önceden belirlenmiş olarak tahsis ediyordu. Çoklu Model Sunucu (MMS) model sunucusu olarak. Bu yazıda, bir MME'nin her modele atanan bilgi işlem gücünü, modelin trafik düzenine göre dinamik olarak ayarlayabildiği bir çözümü tartışıyoruz. Bu çözüm, MME'lerin temelinde yatan hesaplamayı daha verimli kullanmanızı ve maliyetlerden tasarruf etmenizi sağlar.
MME'ler, uç noktaya gelen trafiğe göre modelleri dinamik olarak yükler ve kaldırır. MMS'i model sunucusu olarak kullanırken, MME'ler her model için sabit sayıda model çalışanı tahsis eder. Daha fazla bilgi için bkz. Amazon SageMaker'da model barındırma kalıpları, Bölüm 3: Amazon SageMaker çoklu model uç noktaları ile çoklu model çıkarımını çalıştırın ve optimize edin.
Ancak trafik düzeniniz değişken olduğunda bu durum birkaç soruna yol açabilir. Diyelim ki büyük miktarda trafik alan tek bir veya birkaç modeliniz var. MMS'i bu modeller için yüksek sayıda çalışan tahsis edecek şekilde yapılandırabilirsiniz, ancak bu, statik bir yapılandırma olduğundan MME'nin arkasındaki tüm modellere atanır. Bu, çok sayıda çalışanın donanım hesaplamasını (hatta boşta olan modelleri bile) kullanmasına yol açar. Çalışan sayısı için küçük bir değer belirlerseniz tam tersi sorun yaşanabilir. Popüler modellerde, bu modeller için uç noktanın arkasına yeterli donanımı uygun şekilde tahsis etmek için model sunucusu düzeyinde yeterli sayıda çalışan bulunmayacaktır. Temel sorun, gerekli miktarda bilgi işlem tahsis etmek için çalışanlarınızı model sunucu düzeyinde dinamik olarak ölçekleyemezseniz, trafik düzeninden bağımsız kalmanın zor olmasıdır.
Bu yazıda tartıştığımız çözüm şunları kullanıyor: DJLSserving Model sunucusu olarak tartıştığımız sorunların bazılarını hafifletmeye yardımcı olabilir, model başına ölçeklendirmeyi etkinleştirebilir ve MME'lerin trafik modelinden bağımsız olmasını sağlayabilir.
MME mimarisi
SageMaker MME'ler, bir veya daha fazla örnek içerebilen tek bir çıkarım uç noktasının arkasında birden fazla modeli dağıtmanıza olanak tanır. Her örnek, belleğine ve CPU/GPU kapasitesine kadar birden fazla modeli yükleyecek ve hizmet verecek şekilde tasarlanmıştır. Bu mimariyle, bir hizmet olarak yazılım (SaaS) işletmesi, birden fazla modeli barındırmanın doğrusal olarak artan maliyetini ortadan kaldırabilir ve uygulama yığınının başka bir yerinde uygulanan çoklu kiracılı modelle tutarlı olarak altyapının yeniden kullanılmasını sağlayabilir. Aşağıdaki diyagram bu mimariyi göstermektedir.
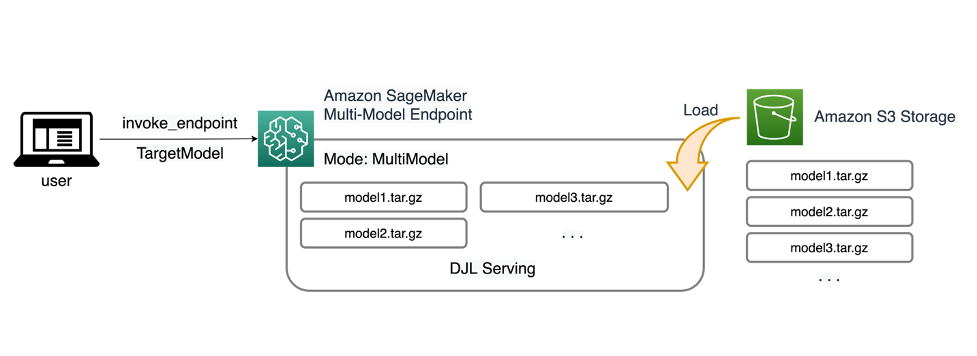
Bir SageMaker MME, modelleri dinamik olarak yükler. Amazon Basit Depolama Hizmeti (Amazon S3) çağrıldığında, uç nokta ilk oluşturulduğunda tüm modelleri indirmek yerine. Sonuç olarak, bir modele yapılan ilk çağrı, düşük gecikmeyle tamamlanan sonraki çıkarımlara göre daha yüksek çıkarım gecikmesine neden olabilir. Model çağrıldığında konteynere zaten yüklenmişse indirme adımı atlanır ve model, çıkarımları düşük gecikmeyle döndürür. Örneğin, günde yalnızca birkaç kez kullanılan bir modeliniz olduğunu varsayalım. Talep üzerine otomatik olarak yüklenirken, sık erişilen modeller bellekte tutulur ve tutarlı bir şekilde düşük gecikmeyle çağrılır.
Her MME'nin arkasında, aşağıdaki şemada gösterildiği gibi model barındırma örnekleri bulunur. Bu örnekler, modellere giden trafik modellerine göre birden fazla modeli belleğe yükler ve belleğe çıkarır.
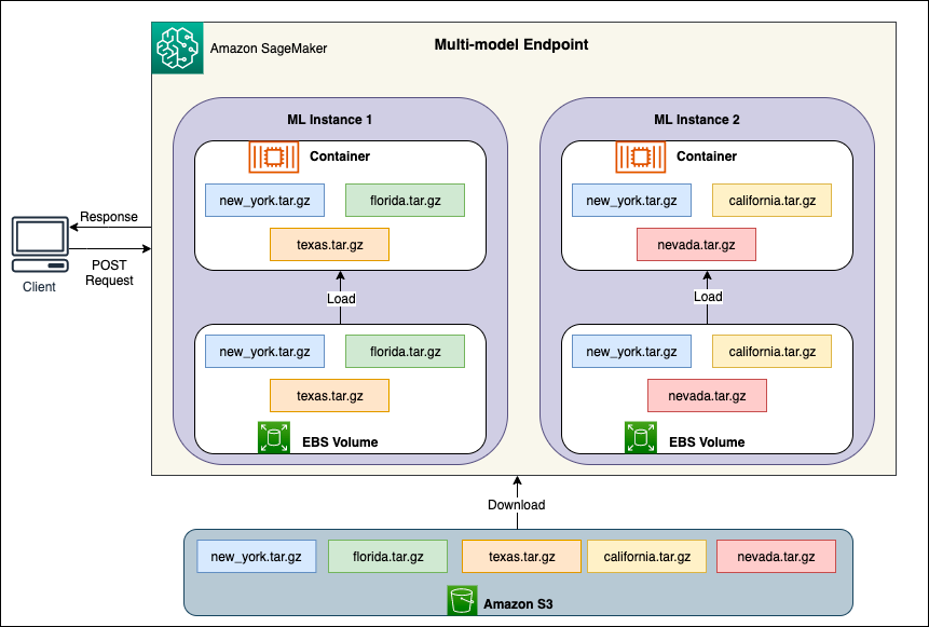
SageMaker, bir modele yönelik çıkarım isteklerini, istekler önbelleğe alınmış bir model kopyasından sunulacak şekilde modelin zaten yüklendiği örneğe yönlendirmeye devam eder (ilk tahmin isteği ile önbelleğe alınmış tahmin arasındaki istek yolunu gösteren aşağıdaki şemaya bakın) istek yolu). Ancak model çok sayıda çağırma isteği alırsa ve MME için ek örnekler varsa, SageMaker artışı karşılamak için bazı istekleri başka bir örneğine yönlendirir. SageMaker'da otomatik model ölçeklendirmenin avantajlarından yararlanmak için aşağıdaki özelliklere sahip olduğunuzdan emin olun: örnek otomatik ölçeklendirme kurulumu ek örnek kapasitesi sağlamak için. Uç nokta filosuna daha fazla örnek eklemek için özel parametreler veya dakika başına çağrı sayısı (önerilen) ile uç nokta düzeyinde ölçeklendirme politikanızı ayarlayın.

Model sunucusuna genel bakış
Model sunucusu, makine öğrenimi (ML) modellerinin dağıtılması ve sunulması için çalışma zamanı ortamı sağlayan bir yazılım bileşenidir. Eğitilmiş modeller ile bu modelleri kullanarak tahminlerde bulunmak isteyen istemci uygulamaları arasında bir arayüz görevi görür.
Model sunucusunun temel amacı, ML modellerinin üretim sistemlerine zahmetsiz entegrasyonunu ve verimli bir şekilde dağıtılmasını sağlamaktır. Model sunucusu, modeli doğrudan bir uygulamaya veya belirli bir çerçeveye gömmek yerine, birden fazla modelin dağıtılabileceği, yönetilebileceği ve sunulabileceği merkezi bir platform sağlar.
Model sunucular genellikle aşağıdaki işlevleri sunar:
- Model yükleme – Sunucu, eğitilen ML modellerini belleğe yükleyerek tahminleri sunmaya hazır hale getirir.
- Çıkarım API'si – Sunucu, istemci uygulamalarının giriş verileri göndermesine ve dağıtılan modellerden tahminler almasına olanak tanıyan bir API'yi kullanıma sunar.
- Ölçekleme – Model sunucular, birden fazla istemciden gelen eşzamanlı istekleri işleyecek şekilde tasarlanmıştır. Yüksek verim ve düşük gecikme sağlamak amacıyla paralel işleme ve kaynakları verimli bir şekilde yönetmeye yönelik mekanizmalar sağlarlar.
- Arka uç motorlarla entegrasyon – Model sunucuları, büyük modelleri bölümlemek ve yüksek düzeyde optimize edilmiş çıkarımlar gerçekleştirmek için DeepSpeed ve FasterTransformer gibi arka uç çerçeveleriyle entegrasyonlara sahiptir.
DJL mimarisi
DJL Sunumu açık kaynaklı, yüksek performanslı, evrensel model bir sunucudur. DJL Servis bunun üzerine inşa edilmiştir DjlJava programlama dilinde yazılmış bir derin öğrenme kütüphanesi. Derin bir öğrenme modelini, çeşitli modelleri veya iş akışlarını alıp bunları bir HTTP uç noktası aracılığıyla kullanılabilir hale getirebilir. DJL Serving, PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer ve daha fazlası gibi birden fazla çerçeveden modellerin dağıtılmasını destekler.
DJL Serving, modellerinizi yüksek performansla dağıtmanıza olanak tanıyan birçok özellik sunar:
- Kullanım kolaylığı – DJL Serving çoğu modele kutudan çıktığı haliyle hizmet verebilir. Sadece model eserlerini getirin ve DJL Serving onları barındırsın.
- Çoklu cihaz ve hızlandırıcı desteği – DJL Serving, modellerin CPU, GPU ve AWS Çıkarımları.
- Performans – DJL Serving, verimi artırmak için tek bir JVM'de çok iş parçacıklı çıkarımı çalıştırır.
- Dinamik gruplama – DJL Serving, verimi artırmak için dinamik gruplandırmayı destekler.
- Otomatik ölçeklendirme – DJL Serving, trafik yüküne göre çalışanların ölçeğini otomatik olarak artırıp azaltacaktır.
- Çoklu motor desteği – DJL Serving, farklı çerçeveleri (PyTorch ve TensorFlow gibi) kullanan modelleri aynı anda barındırabilir.
- Topluluk ve iş akışı modelleri – DJL Serving, birden fazla modelden oluşan karmaşık iş akışlarının dağıtılmasını destekler ve iş akışının bazı kısımlarını CPU'da, bazı kısımlarını da GPU'da çalıştırır. Bir iş akışındaki modeller farklı çerçeveler kullanabilir.
Özellikle DJL Serving'in otomatik ölçeklendirme özelliği, modellerin gelen trafiğe uygun şekilde ölçeklendirilmesini kolaylaştırıyor. Varsayılan olarak DJL Serving, mevcut donanıma (CPU çekirdekleri, GPU aygıtları) bağlı olarak desteklenebilecek bir model için maksimum çalışan sayısını belirler. Minimum trafik düzeyinin her zaman sunulabildiğinden ve tek bir modelin mevcut tüm kaynakları tüketmediğinden emin olmak için her model için alt ve üst sınırlar ayarlayabilirsiniz.
DJL Hizmetinde bir Netty arka uç çalışan iş parçacığı havuzlarının üstünde ön uç. Ön uç, birden fazla özelliğe sahip tek bir Netty kurulumu kullanır. HttpRequestİşleyicileri. Farklı istek işleyicileri aşağıdakiler için destek sağlayacaktır: Çıkarım API'si, Yönetim API'siveya çeşitli eklentilerde bulunan diğer API'ler.
Arka uç, aşağıdakileri temel alır: İşYük Yöneticisi (WLM) modülü. WLM, toplu işleme ve bunlara yönlendirme isteğinin yanı sıra her model için birden fazla çalışan iş parçacığıyla ilgilenir. Birden fazla model sunulduğunda WLM, öncelikle her modelin çıkarım isteği kuyruğu boyutunu kontrol eder. Kuyruk boyutu bir modelin parti boyutunun iki katından büyükse WLM, o modele atanan çalışan sayısını artırır.
Çözüme genel bakış
DJL'nin bir MME ile uygulanması, varsayılan MMS kurulumundan farklıdır. Bir MME ile DJL Sunumu için aşağıdaki dosyaları SageMaker Inference'ın beklediği model.tar.gz formatında sıkıştırıyoruz:
- model.joblib – Bu uygulama için model meta verilerini doğrudan tarball'a aktarıyoruz. Bu durumda, bir ile çalışıyoruz.
.joblibdosyası, bu nedenle çıkarım betiğimizin okuması için bu dosyayı tarball'ımızda sağlıyoruz. Yapıt çok büyükse onu Amazon S3'e de aktarabilir ve DJL için tanımladığınız sunum yapılandırmasında buna yönlendirebilirsiniz. - porsiyon.özellikleri – Burada sunucuyla ilgili herhangi bir modeli yapılandırabilirsiniz Ortam Değişkenleri. DJL'nin gücü burada yapılandırabilmenizdir
minWorkersvemaxWorkersher model tarball için. Bu, her modelin model sunucusu düzeyinde ölçeklendirilmesine ve küçültülmesine olanak tanır. Örneğin, bir MME için trafiğin çoğunluğunu tek bir model alıyorsa, model sunucusu çalışanların ölçeğini dinamik olarak artıracaktır. Bu örnekte, bu değişkenleri yapılandırmayacağız ve DJL'nin trafik modelimize bağlı olarak gerekli çalışan sayısını belirlemesine izin vereceğiz. - model.py – Bu, uygulamak istediğiniz herhangi bir özel ön işleme veya son işleme için çıkarım komut dosyasıdır. model.py, mantığınızın varsayılan olarak bir tanıtıcı yönteminde kapsüllenmesini bekler.
- gereksinimleri.txt (isteğe bağlı) – Varsayılan olarak DJL, PyTorch ile birlikte kurulu olarak gelir, ancak ihtiyaç duyduğunuz ek bağımlılıklar buraya gönderilebilir.
Bu örnek için örnek bir SKLearn modeli alarak DJL'nin MME ile gücünü sergiliyoruz. Bu modelle bir eğitim işi yürütüyoruz ve ardından MME'mizi desteklemek için bu model yapısının 1,000 kopyasını oluşturuyoruz. Daha sonra DJL'nin, MME'nizin alabileceği her türlü trafik modelini işlemek için dinamik olarak nasıl ölçeklenebileceğini gösteriyoruz. Bu, trafiğin tüm modellere eşit olarak dağıtılmasını veya trafiğin çoğunluğunu alan birkaç popüler modeli bile içerebilir. Kodun tamamını aşağıda bulabilirsiniz GitHub repo.
Önkoşullar
Bu örnek için, conda_python3 çekirdeğine ve ml.c5.xlarge örneğine sahip bir SageMaker not defteri örneğini kullanıyoruz. Yük testlerini gerçekleştirmek için bir Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) örneği veya daha büyük bir SageMaker dizüstü bilgisayar örneği. Bu örnekte saniyede binden fazla işleme (TPS) ölçeklendiriyoruz; bu nedenle, üzerinde çalışabileceğiniz daha fazla işlem gücüne sahip olmanız için ml.c2xlarge gibi daha ağır bir EC5.18 bulut sunucusu üzerinde test etmenizi öneririz.
Model yapıtı oluşturma
Öncelikle bu örnekte kullandığımız model yapıtımızı ve verilerimizi oluşturmamız gerekiyor. Bu durumda, NumPy ile bazı yapay veriler üretiyoruz ve aşağıdaki kod parçacığıyla SKLearn doğrusal regresyon modelini kullanarak eğitim veriyoruz:
Önceki kodu çalıştırdıktan sonra bir model.joblib Yerel ortamınızda oluşturulan dosya.
DJL Docker görüntüsünü çekin
Docker görüntüsü djl-inference:0.23.0-cpu-full-v1.0, bu örnekte kullanılan DJL servis konteynerimizdir. Bölgenize bağlı olarak aşağıdaki URL'yi ayarlayabilirsiniz:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
İsteğe bağlı olarak, bu görüntüyü temel görüntü olarak da kullanabilir ve kendi Docker görüntünüzü oluşturmak için genişletebilirsiniz. Amazon Elastik Konteyner Kayıt Defteri (Amazon ECR) ihtiyacınız olan diğer bağımlılıklarla birlikte kullanın.
Model dosyasını oluşturun
İlk olarak adında bir dosya oluşturuyoruz. serving.properties. Bu, DJLServing'e Python motorunu kullanma talimatını verir. Ayrıca şunları da tanımlıyoruz: max_idle_time Bir işçinin 600 saniye olması. Bu, model başına sahip olduğumuz işçi sayısını azaltmamızın daha uzun sürmesini sağlar. Ayar yapmıyoruz minWorkers ve maxWorkers bunu tanımlayabiliriz ve DJL'nin her modelin aldığı trafiğe bağlı olarak ihtiyaç duyulan işçi sayısını dinamik olarak hesaplamasına izin veririz. Porsiyon.özellikleri aşağıdaki gibi gösterilmektedir. Yapılandırma seçeneklerinin tam listesini görmek için bkz. Motor konfigürasyonu.
Daha sonra model yükleme ve çıkarım mantığını tanımlayan model.py dosyamızı oluşturuyoruz. MME'ler için her model.py dosyası bir modele özeldir. Modeller, model deposu altında kendi yollarında saklanır (genellikle /opt/ml/model/). Modelleri yüklerken, kendi dizinlerindeki model deposu yoluna yükleneceklerdir. Bu demodaki tam model.py örneğini şurada görebilirsiniz: GitHub repo.
Bir yaratıyoruz model.tar.gz modelimizi içeren dosya (model.joblib), model.py, ve serving.properties:
Gösterim amaçlı olarak aynısının 1,000 kopyasını yapıyoruz model.tar.gz Barındırılacak çok sayıda modeli temsil eden dosya. Üretimde bir oluşturmanız gerekir. model.tar.gz modellerinizin her biri için dosya.
Son olarak bu modelleri Amazon S3’e yüklüyoruz.
SageMaker modeli oluşturun
şimdi bir tane oluşturuyoruz Adaçayı Yapıcı modeli. SageMaker modelini oluşturmak için daha önce tanımlanan ECR görüntüsünü ve önceki adımdaki model yapıtını kullanırız. Model kurulumunda Mode’u MultiModel olarak yapılandırıyoruz. Bu, DJLServing'e bir MME oluşturduğumuzu söyler.
SageMaker uç noktası oluşturun
Bu demoda, bin aralığında bir TPS'ye ölçeklendirmek için 20 ml.c5d.18xlarge bulut sunucusu kullanıyoruz. Hedeflediğiniz TPS'ye ulaşmak için gerekirse bulut sunucusu tipinizde limit artışı aldığınızdan emin olun.
Yük testi
Bu yazının yazıldığı sırada SageMaker'ın şirket içi yük testi aracı Amazon SageMaker Çıkarım Öneri Aracı MME'lere yönelik testleri yerel olarak desteklemez. Bu nedenle açık kaynaklı Python aracını kullanıyoruz keçiboynuzu. Locust'un kurulumu kolaydır ve TPS ve uçtan uca gecikme gibi ölçümleri izleyebilir. SageMaker ile nasıl kurulacağının tam olarak anlaşılması için bkz. Amazon SageMaker gerçek zamanlı çıkarım uç noktalarını yük testi için en iyi uygulamalar.
Bu kullanım durumunda, MME'lerle simüle etmek istediğimiz üç farklı trafik modelimiz var, dolayısıyla her bir modelle uyumlu olan aşağıdaki üç Python komut dosyasına sahibiz. Buradaki amacımız, trafik düzenimiz ne olursa olsun aynı hedef TPS'ye ulaşabildiğimizi ve uygun şekilde ölçeklenebildiğimizi kanıtlamaktır.
Modellerimizin farklı bölümlerine trafik atamak için Locust betiğimizde bir ağırlık belirtebiliriz. Örneğin tek sıcak modelimizle iki yöntemi şu şekilde uyguluyoruz:
Daha sonra her yönteme belirli bir ağırlık atayabiliriz; bu, belirli bir yöntemin trafiğin belirli bir yüzdesini alması anlamına gelir:
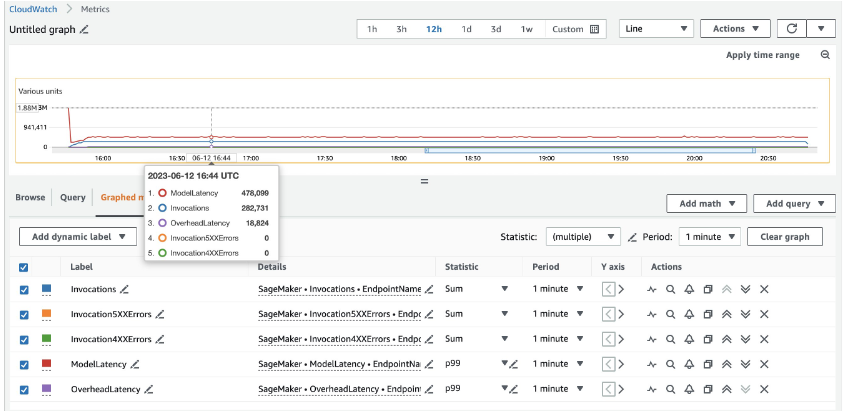
20 ml.c5d.18xlarge örnekleri için aşağıdaki çağrı metriklerini görüyoruz: Amazon Bulut İzleme konsol. Bu değerler her üç trafik modelinde de oldukça tutarlı kalır. SageMaker gerçek zamanlı çıkarım ve MME'lere yönelik CloudWatch ölçümlerini daha iyi anlamak için bkz. SageMaker Endpoint Çağırma Metrikleri.
Locust komut dosyalarının geri kalanını şurada bulabilirsiniz: locust-utils dizini GitHub deposunda.
Özet
Bu yazıda, bir MME'nin her modele atanan bilgi işlem gücünü, modelin trafik düzenine göre dinamik olarak nasıl ayarlayabileceğini tartıştık. Yeni başlatılan bu özellik, SageMaker'ın mevcut olduğu tüm AWS Bölgelerinde mevcuttur. Duyuru sırasında yalnızca CPU örneklerinin desteklendiğini unutmayın. Daha fazla bilgi edinmek için bkz. Desteklenen algoritmalar, çerçeveler ve örnekler.
Yazarlar Hakkında
 Ram Vegiraju SageMaker Servis ekibine sahip bir ML Mimarıdır. Müşterilerin AI/ML çözümlerini Amazon SageMaker'da oluşturmasına ve optimize etmesine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmeyi ve yazmayı sever.
Ram Vegiraju SageMaker Servis ekibine sahip bir ML Mimarıdır. Müşterilerin AI/ML çözümlerini Amazon SageMaker'da oluşturmasına ve optimize etmesine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmeyi ve yazmayı sever.
 Qingwei Li Amazon Web Services'te Makine Öğrenimi Uzmanıdır. Doktora derecesini aldı. Danışmanının araştırma bursu hesabını bozduktan ve söz verdiği Nobel Ödülü'nü teslim edemedikten sonra Yöneylem Araştırması'nda. Şu anda finansal hizmet ve sigorta sektöründeki müşterilerin AWS'de makine öğrenimi çözümleri oluşturmasına yardımcı oluyor. Boş zamanlarında okumayı ve öğretmeyi sever.
Qingwei Li Amazon Web Services'te Makine Öğrenimi Uzmanıdır. Doktora derecesini aldı. Danışmanının araştırma bursu hesabını bozduktan ve söz verdiği Nobel Ödülü'nü teslim edemedikten sonra Yöneylem Araştırması'nda. Şu anda finansal hizmet ve sigorta sektöründeki müşterilerin AWS'de makine öğrenimi çözümleri oluşturmasına yardımcı oluyor. Boş zamanlarında okumayı ve öğretmeyi sever.
 James Wu AWS'de Kıdemli AI/ML Uzman Çözüm Mimarıdır. müşterilerin AI/ML çözümleri tasarlamasına ve oluşturmasına yardımcı olur. James'in çalışması, bilgisayar vizyonu, derin öğrenme ve kurum genelinde ML'yi ölçeklendirmeye ilgi duyan çok çeşitli ML kullanım durumlarını kapsar. AWS'ye katılmadan önce James, 10 yılı mühendislik ve 6 yılı pazarlama ve reklamcılık sektörlerinde olmak üzere 4 yılı aşkın bir süredir mimar, geliştirici ve teknoloji lideriydi.
James Wu AWS'de Kıdemli AI/ML Uzman Çözüm Mimarıdır. müşterilerin AI/ML çözümleri tasarlamasına ve oluşturmasına yardımcı olur. James'in çalışması, bilgisayar vizyonu, derin öğrenme ve kurum genelinde ML'yi ölçeklendirmeye ilgi duyan çok çeşitli ML kullanım durumlarını kapsar. AWS'ye katılmadan önce James, 10 yılı mühendislik ve 6 yılı pazarlama ve reklamcılık sektörlerinde olmak üzere 4 yılı aşkın bir süredir mimar, geliştirici ve teknoloji lideriydi.
 Saurabh Trikande Amazon SageMaker Inference için Kıdemli Ürün Yöneticisidir. Müşterilerle çalışma konusunda tutkulu ve makine öğrenimini demokratikleştirme hedefiyle motive oluyor. Karmaşık makine öğrenimi uygulamaları, çok kiracılı makine öğrenimi modelleri, maliyet optimizasyonları ve derin öğrenme modellerinin dağıtımını daha erişilebilir hale getirmeyle ilgili temel zorluklara odaklanıyor. Saurabh boş zamanlarında yürüyüş yapmaktan, yenilikçi teknolojiler hakkında bilgi edinmekten, TechCrunch'ı takip etmekten ve ailesiyle vakit geçirmekten hoşlanıyor.
Saurabh Trikande Amazon SageMaker Inference için Kıdemli Ürün Yöneticisidir. Müşterilerle çalışma konusunda tutkulu ve makine öğrenimini demokratikleştirme hedefiyle motive oluyor. Karmaşık makine öğrenimi uygulamaları, çok kiracılı makine öğrenimi modelleri, maliyet optimizasyonları ve derin öğrenme modellerinin dağıtımını daha erişilebilir hale getirmeyle ilgili temel zorluklara odaklanıyor. Saurabh boş zamanlarında yürüyüş yapmaktan, yenilikçi teknolojiler hakkında bilgi edinmekten, TechCrunch'ı takip etmekten ve ailesiyle vakit geçirmekten hoşlanıyor.
 Xu Deng SageMaker ekibinde Yazılım Mühendisi Yöneticisidir. Müşterilerin Amazon SageMaker'da AI/ML çıkarım deneyimlerini oluşturmalarına ve optimize etmelerine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmeyi ve snowboard yapmayı seviyor.
Xu Deng SageMaker ekibinde Yazılım Mühendisi Yöneticisidir. Müşterilerin Amazon SageMaker'da AI/ML çıkarım deneyimlerini oluşturmalarına ve optimize etmelerine yardımcı olmaya odaklanıyor. Boş zamanlarında seyahat etmeyi ve snowboard yapmayı seviyor.
 Siddharth Venkatesan AWS Deep Learning'de Yazılım Mühendisidir. Şu anda büyük model çıkarımına yönelik çözümler oluşturmaya odaklanıyor. AWS'den önce Amazon Grocery organizasyonunda dünya çapındaki müşteriler için yeni ödeme özellikleri oluşturmada çalışıyordu. İş dışında kayak yapmaktan, açık havada olmaktan ve spor müsabakalarını izlemekten hoşlanıyor.
Siddharth Venkatesan AWS Deep Learning'de Yazılım Mühendisidir. Şu anda büyük model çıkarımına yönelik çözümler oluşturmaya odaklanıyor. AWS'den önce Amazon Grocery organizasyonunda dünya çapındaki müşteriler için yeni ödeme özellikleri oluşturmada çalışıyordu. İş dışında kayak yapmaktan, açık havada olmaktan ve spor müsabakalarını izlemekten hoşlanıyor.
 Rohith Nallamaddi AWS'de Yazılım Geliştirme Mühendisi. GPU'larda derin öğrenme iş yüklerini optimize etme, yüksek performanslı makine öğrenimi çıkarımı oluşturma ve çözümler sunmaya çalışıyor. Bundan önce, Amazon F3 işi için AWS'ye dayalı mikro hizmetler oluşturmaya çalıştı. İş dışında spor yapmaktan ve izlemekten hoşlanır.
Rohith Nallamaddi AWS'de Yazılım Geliştirme Mühendisi. GPU'larda derin öğrenme iş yüklerini optimize etme, yüksek performanslı makine öğrenimi çıkarımı oluşturma ve çözümler sunmaya çalışıyor. Bundan önce, Amazon F3 işi için AWS'ye dayalı mikro hizmetler oluşturmaya çalıştı. İş dışında spor yapmaktan ve izlemekten hoşlanır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

