Son birkaç yılda Büyük Dil Modelleri (LLM'ler), metni benzeri görülmemiş bir yeterlilikle anlama, oluşturma ve değiştirme yeteneğine sahip olağanüstü araçlar olarak ön plana çıktı. Potansiyel uygulamaları, konuşma aracılarından içerik üretimine ve bilgi erişimine kadar uzanır ve tüm endüstrilerde devrim yaratma vaadini taşır. Ancak bu modellerin sorumlu ve etkili kullanımını sağlarken bu potansiyelden yararlanmak, LLM değerlendirmesinin kritik sürecine bağlıdır. Değerlendirme, bir Yüksek Lisans veya üretken yapay zeka hizmetinin çıktısının kalitesini ve sorumluluğunu ölçmek için kullanılan bir görevdir. LLM'lerin değerlendirilmesi yalnızca bir model performansını anlama arzusuyla değil, aynı zamanda sorumlu yapay zeka uygulama ihtiyacıyla ve yanlış bilgi veya önyargılı içerik sağlama riskini azaltma ve zararlı, güvensiz, kötü niyetli ve etik olmayan içeriklerin oluşumunu en aza indirme ihtiyacıyla da motive edilir. içerik. Ayrıca, Yüksek Lisans'ların değerlendirilmesi, özellikle hızlı veri tahrifatı bağlamında güvenlik risklerinin azaltılmasına da yardımcı olabilir. Yüksek Lisans tabanlı uygulamalar için, güvenlik açıklarını belirlemek ve potansiyel ihlallere ve verilerin yetkisiz manipülasyonuna karşı koruma sağlayan güvenlik önlemleri uygulamak çok önemlidir.
Yüksek Lisans'ları basit bir yapılandırma ve tek tıklama yaklaşımıyla değerlendirmek için gerekli araçları sağlayarak, Amazon SageMaker Netleştirin LLM değerlendirme yetenekleri, müşterilerin yukarıda belirtilen avantajların çoğuna erişmesini sağlar. Eldeki bu araçlarla bir sonraki zorluk, süreçte otomasyon ve ölçeklenebilirlik sağlamak için Yüksek Lisans değerlendirmesini Makine Öğrenimi ve Operasyon (MLOps) yaşam döngüsüne entegre etmektir. Bu yazıda, LLM değerlendirmesini geniş ölçekte etkinleştirmek için Amazon SageMaker Clarify LLM değerlendirmesini Amazon SageMaker Pipelines ile nasıl entegre edeceğinizi gösteriyoruz. Ek olarak, bunda kod örneği sağlıyoruz GitHub Llama2-7b-f, Falcon-7b ve ince ayarlı Llama2-7b modelleri gibi örnekleri kullanarak kullanıcıların geniş ölçekte paralel çoklu model değerlendirmesi yapmasına olanak tanıyan depo.
LLM değerlendirmesini kimin yapması gerekiyor?
Önceden eğitilmiş bir LLM'yi eğiten, ince ayar yapan veya basitçe kullanan herkesin, söz konusu LLM tarafından desteklenen uygulamanın davranışını değerlendirmek için onu doğru bir şekilde değerlendirmesi gerekir. Bu ilkeye dayanarak, LLM değerlendirme yeteneklerine ihtiyaç duyan üretken yapay zeka kullanıcılarını aşağıdaki şekilde gösterildiği gibi 3 gruba ayırabiliriz: model sağlayıcılar, ince ayarlayıcılar ve tüketiciler.

- Temel Model (FM) sağlayıcıları genel amaçlı tren modelleri. Bu modeller, özellik çıkarma veya içerik oluşturma gibi birçok alt görev için kullanılabilir. Eğitilen her modelin, yalnızca performansını değerlendirmek için değil, aynı zamanda diğer mevcut modellerle karşılaştırmak, iyileştirilmesi gereken alanları belirlemek ve son olarak bu alandaki gelişmeleri takip etmek için birçok görevle karşılaştırılması gerekir. Model sağlayıcıların ayrıca başlangıç veri setinin kalitesinden ve modellerinin doğru davranışından emin olmak için herhangi bir önyargının varlığını kontrol etmeleri gerekir. Değerlendirme verilerinin toplanması model sağlayıcılar için hayati öneme sahiptir. Ayrıca bu veriler ve ölçümler, gelecek düzenlemelere uyum sağlamak amacıyla toplanmalıdır. ISO 42001, Biden Yönetimi Yönetici Emri, ve AB Yapay Zeka Yasası Yapay zeka sistemlerinin emniyetli, emniyetli ve güvenilir olmasını sağlamaya yardımcı olacak standartlar, araçlar ve testler geliştirin. Örneğin, AB Yapay Zeka Yasası, eğitim için hangi veri kümelerinin kullanıldığı, modeli çalıştırmak için hangi bilgi işlem gücünün gerekli olduğu, model sonuçlarını kamu/sektör standardı kıyaslamalara göre raporlama ve iç ve dış test sonuçlarını paylaşma konusunda bilgi sağlamakla görevlendirilmiştir.
- Model ince ayarlayıcılar Alana özgü görevleri benimsemek için önceden eğitilmiş modellerin yanı sıra belirli görevleri (örn. duygu sınıflandırması, özetleme, soru yanıtlama) çözmek istiyorsanız. Başlangıç noktası olarak doğru önceden eğitilmiş modeli seçmek için model sağlayıcılar tarafından oluşturulan değerlendirme metriklerine ihtiyaçları vardır.
İnce ayarlı modellerini, göreve özgü veya etki alanına özgü veri kümeleriyle istenen kullanım durumuna göre değerlendirmeleri gerekir. Kamuya açık veri kümeleri, hatta belirli bir görev için tasarlanmış olanlar bile, kendi özel kullanım durumları için gereken nüansları yeterince yakalayamayabileceğinden, sıklıkla kendi özel veri kümelerini düzenlemeleri ve oluşturmaları gerekir.
İnce ayar, tam bir eğitimden daha hızlı ve daha ucuzdur ve genellikle birçok aday model oluşturulduğundan dağıtım ve test için daha hızlı operasyonel yineleme gerektirir. Bu modellerin değerlendirilmesi, sürekli model iyileştirmeye, kalibrasyona ve hata ayıklamaya olanak tanır. İnce ayar yapanların gerçek dünya uygulamalarını geliştirirken kendi modellerinin tüketicisi haline gelebileceğini unutmayın. - Model tüketiciler veya model dağıtıcıları, LLM'lerin benimsenmesi yoluyla uygulamalarını veya hizmetlerini geliştirmeyi hedefleyerek üretimdeki genel amaçlı veya ince ayarlı modellere hizmet eder ve bunları izler. Karşılaştıkları ilk zorluk, seçilen LLM'nin kendi özel ihtiyaçlarına, maliyetine ve performans beklentilerine uygun olmasını sağlamaktır. Modelin çıktılarının yorumlanması ve anlaşılması, özellikle mahremiyet ve veri güvenliği söz konusu olduğunda (örneğin, finans sektörü gibi düzenlenmiş sektörlerde risk ve uyumluluğun denetlenmesi için) sürekli bir endişe kaynağıdır. Önyargının veya zararlı içeriğin yayılmasını önlemek için modelin sürekli değerlendirilmesi kritik öneme sahiptir. Model tüketicileri, sağlam bir izleme ve değerlendirme çerçevesi uygulayarak, LLM'lerdeki gerilemeyi proaktif bir şekilde tanımlayıp ele alabilir ve bu modellerin zaman içinde etkinliğini ve güvenilirliğini korumasını sağlayabilir.
LLM değerlendirmesi nasıl yapılır?
Etkili model değerlendirmesi üç temel bileşeni içerir: giriş veri kümelerini (istemler, konuşmalar veya düzenli girişler) ve değerlendirme mantığını değerlendirmek için bir veya daha fazla FM veya ince ayarlı modeller.
Değerlendirmeye yönelik modelleri seçmek için veri özellikleri, problemin karmaşıklığı, mevcut hesaplama kaynakları ve istenen sonuç dahil olmak üzere farklı faktörlerin dikkate alınması gerekir. Giriş veri deposu, seçilen modelin eğitimi, ince ayarı ve test edilmesi için gerekli verileri sağlar. Modelin performansı büyük ölçüde öğrendiği verilere bağlı olduğundan, bu veri deposunun iyi yapılandırılmış, temsili ve yüksek kalitede olması hayati önem taşımaktadır. Son olarak değerlendirme mantıkları, modelin performansını değerlendirmek için kullanılan kriterleri ve ölçümleri tanımlar.
Bu üç bileşen birlikte, makine öğrenimi modellerinin titiz ve sistematik bir şekilde değerlendirilmesini sağlayan ve sonuçta bilinçli kararlara ve model etkinliğinde iyileştirmelere yol açan tutarlı bir çerçeve oluşturur.
Model değerlendirme teknikleri halen aktif bir araştırma alanıdır. Son birkaç yılda araştırmacılar topluluğu tarafından çok çeşitli görevleri ve senaryoları kapsayacak şekilde birçok kamuya açık kıyaslama ve çerçeve oluşturuldu: YAPIŞTIRICI, Süper yapıştırıcı, Miğfer, MMLU ve BÜYÜK tezgah. Bu kıyaslamalarda, değerlendirilen modelleri karşılaştırmak ve karşılaştırmak için kullanılabilecek lider tabloları bulunur. HELM gibi kıyaslamalar aynı zamanda hassasiyet veya F1 puanı gibi doğruluk ölçümlerinin ötesindeki ölçümleri de değerlendirmeyi amaçlamaktadır. HELM kriteri, genel model değerlendirme puanında eşit derecede önemli bir öneme sahip olan adalet, önyargı ve toksisiteye ilişkin ölçümleri içerir.
Tüm bu kıyaslamalar, modelin belirli bir görevde nasıl performans gösterdiğini ölçen bir dizi ölçüm içerir. En ünlü ve en yaygın metrikler şunlardır: ROUGE (Gisting Değerlendirmesi için Hatırlamaya Yönelik Yedek Çalışma), MAVİ (İki Dilli Değerlendirme Yedeği) veya METEOR (Açık Sıralamayla Çevirinin Değerlendirilmesine İlişkin Ölçüt). Bu ölçümler, oluşturulan metin ile referans metin arasındaki sözcüksel benzerliğin niceliksel ölçümlerini sağlayarak otomatik değerlendirme için yararlı bir araç görevi görür. Ancak anlamsal anlayış, bağlam veya üslup nüansları da dahil olmak üzere insan benzeri dil oluşumunun tam kapsamını yakalayamıyorlar. Örneğin HELM, belirli kullanım durumlarıyla ilgili değerlendirme ayrıntılarını, özel istemleri test etmeye yönelik çözümleri ve uzman olmayanlar tarafından kullanılan kolayca yorumlanabilen sonuçları sağlamaz; çünkü süreç maliyetli olabilir, ölçeklendirilmesi kolay olmayabilir ve yalnızca belirli görevler için olabilir.
Dahası, insan benzeri dil üretiminin sağlanması, otomatikleştirilmiş doğruluk ölçümlerini tamamlamak üzere niteliksel değerlendirmeler ve insan muhakemesi sağlamak için çoğu zaman döngüdeki insanın dahil edilmesini gerektirir. İnsan değerlendirmesi, LLM çıktılarını değerlendirmek için değerli bir yöntemdir ancak aynı zamanda subjektif olabilir ve önyargıya yatkın olabilir çünkü farklı insan değerlendiriciler, metin kalitesine ilişkin farklı görüş ve yorumlara sahip olabilir. Ayrıca, insan değerlendirmesi kaynak yoğun ve maliyetli olabilir ve önemli ölçüde zaman ve çaba gerektirebilir.
Amazon SageMaker Clarify'ın noktaları sorunsuz bir şekilde birleştirerek müşterilerin kapsamlı model değerlendirmesi ve seçimi yapmasına nasıl yardımcı olduğunu derinlemesine inceleyelim.
Amazon SageMaker Clarify ile Yüksek Lisans değerlendirmesi
Amazon SageMaker Clarify, LLM'leri değerlendirmek için bir çerçeve sağlayarak müşterilerin otomatikleştirilmiş doğruluk, sağlamlık, toksisite, basmakalıplaştırma ve gerçeklere dayalı bilgi ve insan temelli değerlendirme için stil, tutarlılık, uygunluk ve değerlendirme yöntemleri dahil ancak bunlarla sınırlı olmamak üzere metrikleri otomatikleştirmesine yardımcı olur. ve Amazon Bedrock gibi LLM tabanlı hizmetler. Tam olarak yönetilen bir hizmet olan SageMaker Clarify, Amazon SageMaker'da açık kaynaklı değerlendirme çerçevelerinin kullanımını basitleştirir. Müşteriler, senaryoları için ilgili değerlendirme veri kümelerini ve metriklerini seçebilir ve bunları kendi bilgi istemi veri kümeleri ve değerlendirme algoritmalarıyla genişletebilir. SageMaker Clarify, LLM iş akışındaki farklı rolleri desteklemek için değerlendirme sonuçlarını birden fazla formatta sunar. Veri bilimcileri, Defterlerdeki, SageMaker Model Kartlarındaki ve PDF raporlarındaki SageMaker Clarify görselleştirmeleriyle ayrıntılı sonuçları analiz edebilir. Bu arada operasyon ekipleri, SageMaker Clarify'ın tanımladığı yüksek riskli öğeleri incelemek ve bunlara açıklama eklemek için Amazon SageMaker GroundTruth'u kullanabilir. Örneğin stereotipleştirme, toksisite, kaçan PII veya düşük doğruluk.
Ek açıklamalar ve takviyeli öğrenme daha sonra potansiyel riskleri azaltmak için kullanılır. Belirlenen risklerin insan dostu açıklamaları, manuel inceleme sürecini hızlandırarak maliyetleri azaltır. Özet raporlar, iş paydaşlarına farklı modeller ve versiyonlar arasında karşılaştırmalı kıyaslamalar sunarak bilinçli karar almayı kolaylaştırır.
Aşağıdaki şekilde Yüksek Lisans ve Yüksek Lisans tabanlı hizmetleri değerlendirmeye yönelik çerçeve gösterilmektedir:
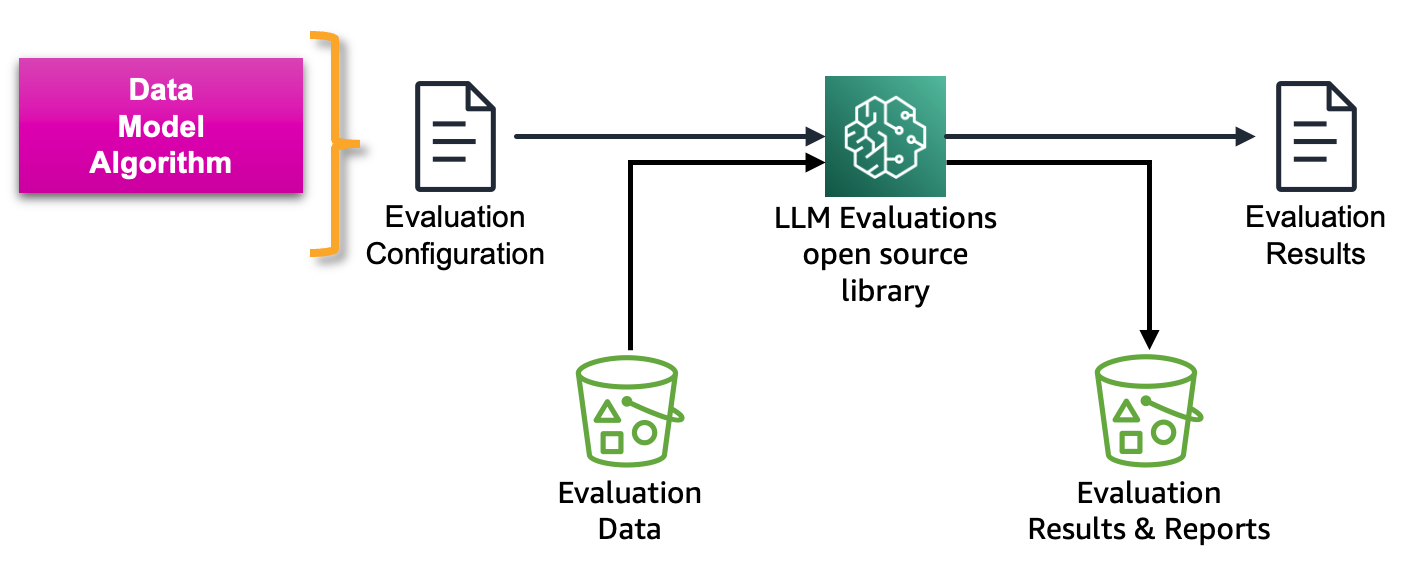
Amazon SageMaker Clarify LLM değerlendirmesi, müşterilerin LLM'leri kolayca değerlendirmesine yardımcı olmak için AWS tarafından geliştirilen açık kaynaklı bir Temel Model Değerlendirme (FMEval) kitaplığıdır. Kullanıcılarının LLM değerlendirmesini mümkün kılmak için tüm işlevler Amazon SageMaker Studio'ya da dahil edilmiştir. Aşağıdaki bölümlerde, MLOps ilkelerini kullanarak geniş ölçekte LLM değerlendirmesini mümkün kılmak için Amazon SageMaker Clarify LLM değerlendirme yeteneklerinin SageMaker Pipelines ile entegrasyonunu tanıtıyoruz.
Amazon SageMaker MLOps yaşam döngüsü
Yazı olarak “Amazon SageMaker'a sahip işletmeler için MLOps temel yol haritası" MLOps, ML kullanım durumlarını verimli bir şekilde üretmek için süreçlerin, insanların ve teknolojinin birleşimidir.
Aşağıdaki şekil uçtan uca MLOps yaşam döngüsünü göstermektedir:

Tipik bir yolculuk, bir veri bilimcinin makine öğreniminin bir iş sorununu çözebileceğini kanıtlamak için bir kavram kanıtlama (PoC) not defteri oluşturmasıyla başlar. Kavram Kanıtı (PoC) geliştirme süreci boyunca, işin Temel Performans Göstergelerini (KPI'ler) hassasiyet veya yanlış pozitif oranı gibi makine öğrenimi modeli ölçümlerine dönüştürmek ve bunları değerlendirmek için sınırlı bir test veri kümesinden yararlanmak veri bilimciye düşer. Metrikler. Veri bilimcileri, kodu not defterlerinden depolara geçirmek için makine öğrenimi mühendisleriyle iş birliği yaparak Amazon SageMaker İşlem Hatlarını kullanarak ön işleme, eğitim, değerlendirme ve işleme sonrası dahil olmak üzere çeşitli işleme adımlarını ve görevlerini birbirine bağlayan makine öğrenimi hatları oluştururken sürekli olarak yeni üretimleri de dahil eder. veri. Amazon SageMaker Pipelines'ın dağıtımı, depo etkileşimlerine ve CI/CD işlem hattı etkinleştirmesine dayanır. ML işlem hattı, en iyi performans gösteren modelleri, kapsayıcı görüntülerini, değerlendirme sonuçlarını ve durum bilgilerini bir model kaydında tutar; burada model paydaşları performansı değerlendirir ve performans sonuçlarına ve kıyaslamalara dayalı olarak üretime ilerlemeye karar verir ve ardından başka bir CI/CD işlem hattı etkinleştirilir. Aşama ve üretim dağıtımı için. Üretime geçtikten sonra, ML tüketicileri, sürekli performans değerlendirmesi için model sahiplerine geri bildirim döngüleri ile doğrudan çağırma veya API çağrıları yoluyla uygulama tarafından tetiklenen çıkarım yoluyla modeli kullanır.
Amazon SageMaker Clarify ve MLOps entegrasyonu
MLOps yaşam döngüsünün ardından, açık kaynak modellerin ince ayarlayıcıları veya kullanıcıları, şurada açıklandığı gibi Amazon SageMaker Jumpstart ve MLOps hizmetlerini kullanarak ince ayarlı modeller veya FM üretirler. Amazon SageMaker JumpStart önceden eğitilmiş modelleriyle MLOps uygulamalarını uygulama. Bu, temel model işlemleri (FMOps) ve LLM İşlemleri (LLMOps) için yeni bir alana yol açmıştır. FMOps/LLMOps: MLOps ile üretken yapay zekayı ve farklılıkları operasyonel hale getirin.
Aşağıdaki şekilde uçtan uca LLMOps yaşam döngüsü gösterilmektedir:
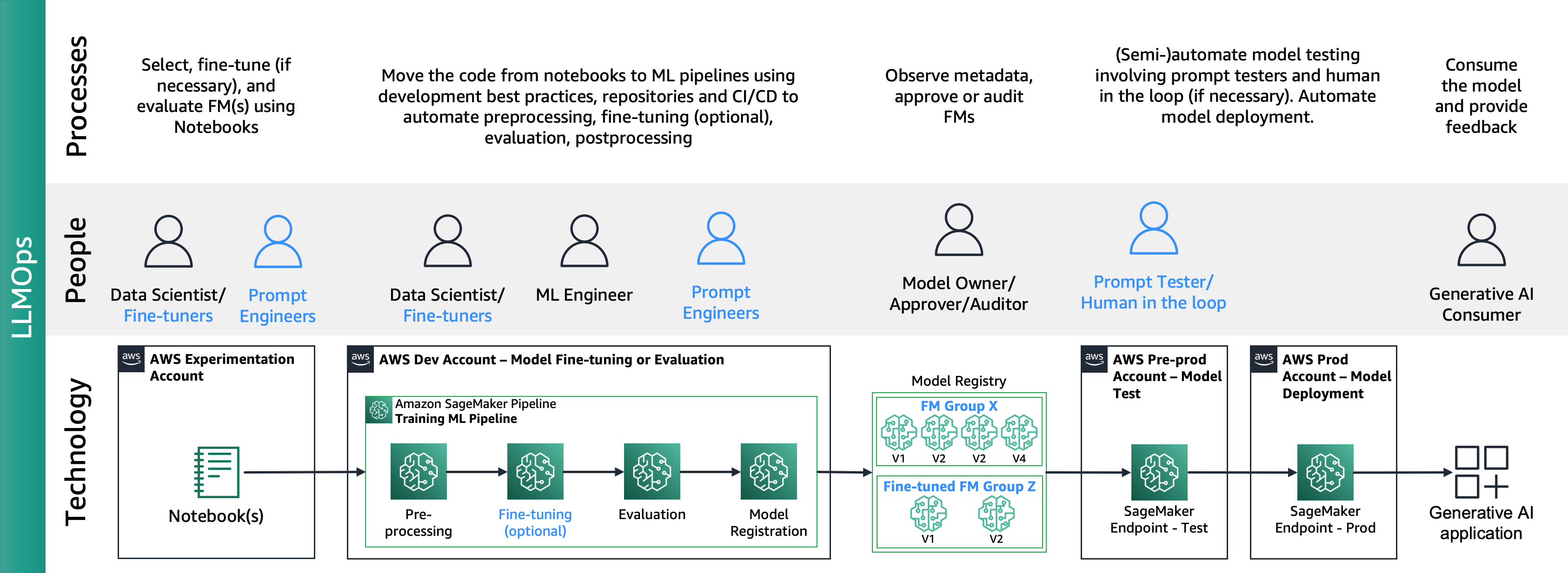
LLMOps'ta MLOps'a kıyasla temel farklar, farklı süreçleri ve ölçümleri içeren model seçimi ve model değerlendirmesidir. İlk deney aşamasında, veri bilimcileri (veya ince ayarlayıcılar), belirli bir Üretken Yapay Zeka kullanım durumu için kullanılacak FM'yi seçerler.
Bu genellikle birden fazla FM'nin test edilmesi ve ince ayarlanmasıyla sonuçlanır; bunlardan bazıları karşılaştırılabilir sonuçlar verebilir. Model(ler)in seçiminden sonra, uzman mühendisler değerlendirme için gerekli girdi verilerini ve beklenen çıktıyı hazırlamaktan (örneğin, girdi verilerini ve sorguyu içeren girdi istemleri) ve benzerlik ve zehirlilik gibi ölçümleri tanımlamaktan sorumludur. Bu ölçümlere ek olarak, veri bilimcileri veya ince ayarlayıcılar sonuçları doğrulamalı ve yalnızca hassas ölçümlere göre değil aynı zamanda gecikme ve maliyet gibi diğer yeteneklere göre de uygun FM'yi seçmelidir. Daha sonra bir modeli SageMaker uç noktasına dağıtabilir ve performansını küçük ölçekte test edebilirler. Deneme aşaması basit bir süreç içerse de üretime geçiş, müşterilerin süreci otomatikleştirmesini ve çözümün sağlamlığını artırmasını gerektirir. Bu nedenle, değerlendirmenin nasıl otomatikleştirileceği, test uzmanlarının geniş ölçekte verimli değerlendirme yapmasına olanak sağlanması ve model girdisi ve çıktısının gerçek zamanlı izlenmesinin nasıl uygulanacağı konularına derinlemesine dalmamız gerekiyor.
FM değerlendirmesini otomatikleştirin
Amazon SageMaker Pipelines, ön işlemenin, FM ince ayarının (isteğe bağlı olarak) ve değerlendirmenin tüm aşamalarını geniş ölçekte otomatikleştirir. Deney sırasında seçilen modeller göz önüne alındığında, bilgi istemi mühendislerinin birçok bilgi istemi hazırlayarak ve bunları bilgi istemi kataloğu adı verilen belirlenmiş bir depolama deposunda saklayarak daha büyük bir vaka kümesini kapsaması gerekir. Daha fazla bilgi için bkz. FMOps/LLMOps: MLOps ile üretken yapay zekayı ve farklılıkları operasyonel hale getirin. Daha sonra Amazon SageMaker İşlem Hatları aşağıdaki gibi yapılandırılabilir:
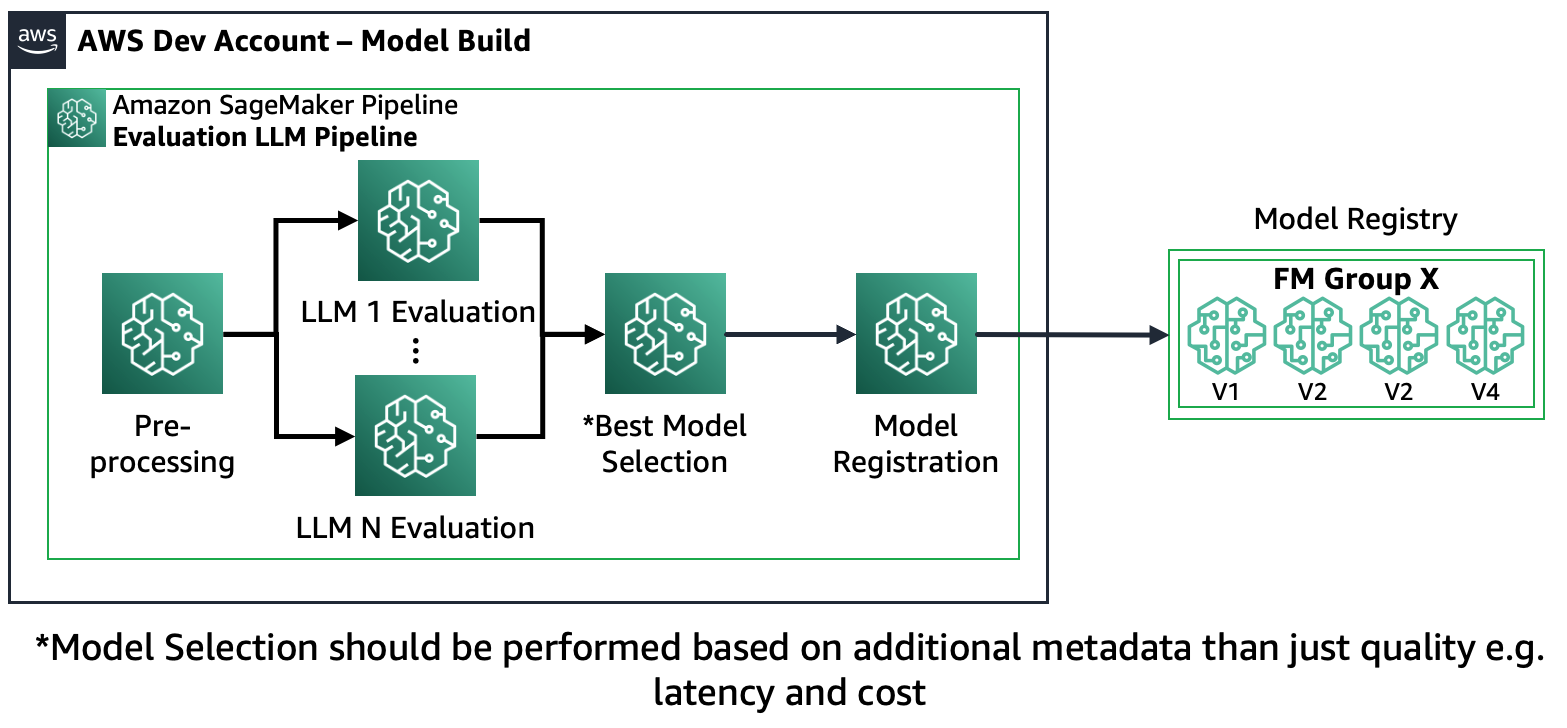
Senaryo 1 – Birden fazla FM'yi değerlendirin: Bu senaryoda FM'ler, ince ayar yapmadan iş kullanım senaryosunu kapsayabilir. Amazon SageMaker Pipeline şu adımlardan oluşur: verilerin ön işlenmesi, birden fazla FM'nin paralel değerlendirilmesi, model karşılaştırması ve doğruluk ile maliyet veya gecikme gibi diğer özelliklere göre seçim, seçilen model yapılarının kaydı ve meta veriler.
Aşağıdaki şema bu mimariyi göstermektedir.
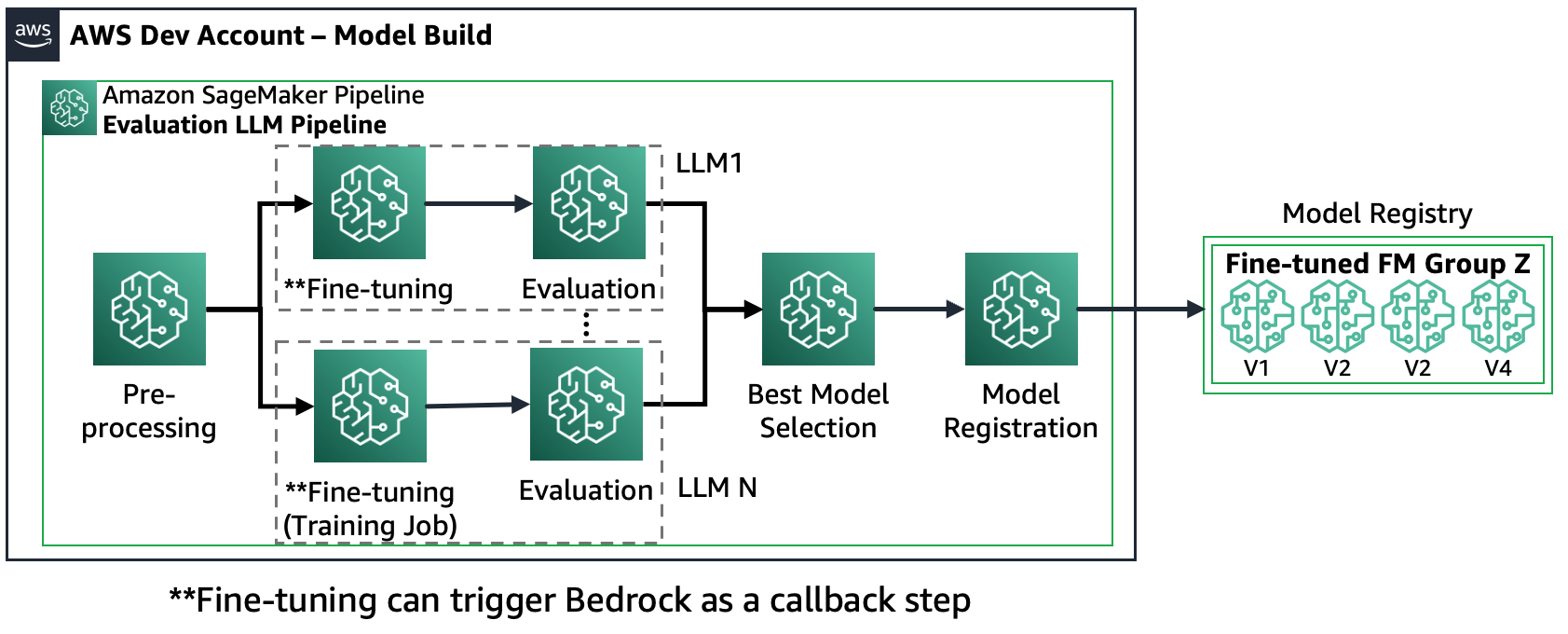
Senaryo 2 – Birden fazla FM'de ince ayar yapın ve değerlendirin: Bu senaryoda Amazon SageMaker Pipeline, Senaryo 1'e benzer şekilde yapılandırılmıştır ancak her FM için hem ince ayar hem de değerlendirme adımları paralel olarak yürütülür. En iyi ince ayarlı model, Model Siciline kaydedilecektir.
Aşağıdaki şema bu mimariyi göstermektedir.
Senaryo 3 – Birden fazla FM'yi ve ince ayarlı FM'leri değerlendirin: Bu senaryo, genel amaçlı FM'lerin ve ince ayarlı FM'lerin değerlendirilmesinin bir birleşimidir. Bu durumda müşteriler, ince ayarlı bir modelin genel amaçlı bir FM'den daha iyi performans gösterip gösteremeyeceğini kontrol etmek ister.
Aşağıdaki şekil sonuçta ortaya çıkan SageMaker Pipeline adımlarını göstermektedir.
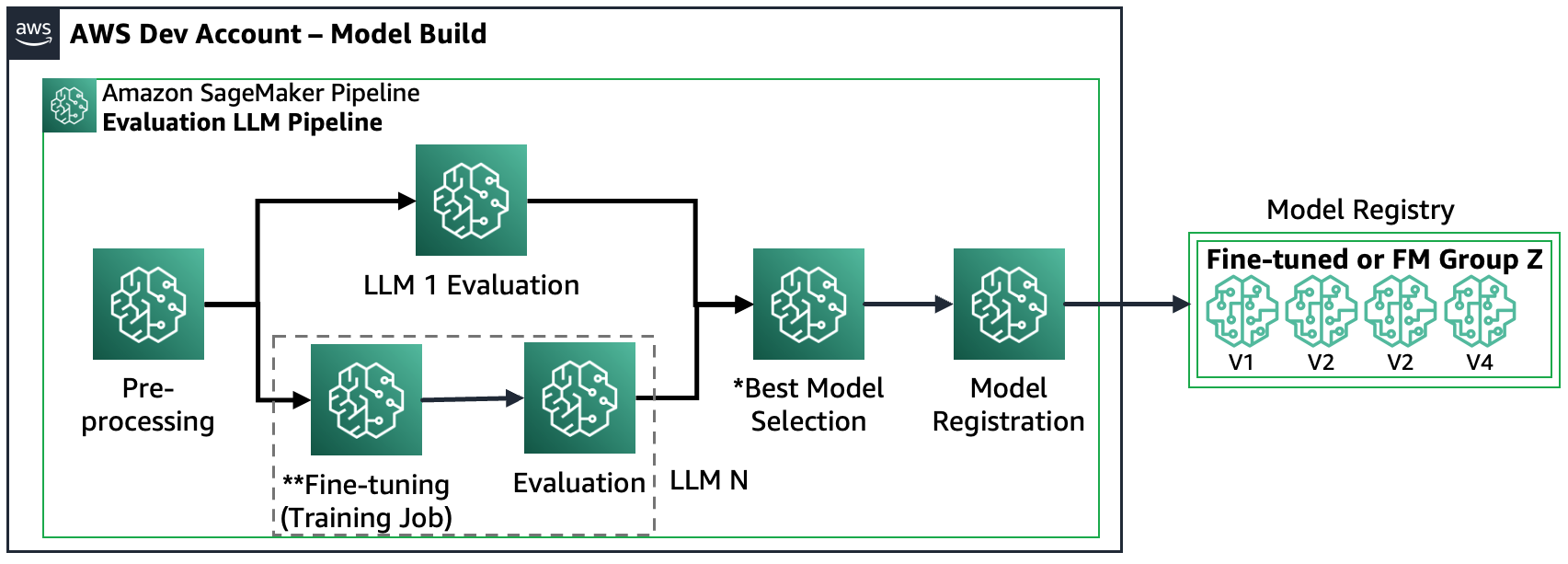
Model kaydının iki modeli takip ettiğini unutmayın: (a) açık kaynaklı bir modeli ve yapıtları saklayın veya (b) özel bir FM'ye referansı saklayın. Daha fazla bilgi için bkz. FMOps/LLMOps: MLOps ile üretken yapay zekayı ve farklılıkları operasyonel hale getirin.
Çözüme genel bakış
Yüksek Lisans değerlendirme yolculuğunuzu geniş ölçekte hızlandırmak için hem Amazon SageMaker Clarify'ı hem de yeni Amazon SageMaker Pipelines SDK'yı kullanarak senaryoları uygulayan bir çözüm oluşturduk. Veri kümeleri, kaynak not defterleri ve SageMaker İşlem Hatları (adımlar ve ML işlem hattı) dahil olmak üzere kod örneğine şuradan ulaşılabilir: GitHub. Bu örnek çözümü geliştirmek için iki FM kullandık: Llama2 ve Falcon-7B. Bu yazıda öncelikli odak noktamız SageMaker Pipeline çözümünün değerlendirme süreciyle ilgili temel unsurlarıdır.
Değerlendirme yapılandırması: Değerlendirme prosedürünü standartlaştırmak amacıyla, veri kümesi, model(ler) ve değerlendirme sırasında çalıştırılacak algoritmalar da dahil olmak üzere değerlendirme süreci için gerekli ayrıntıları içeren bir YAML yapılandırma dosyası (evaluation_config.yaml) oluşturduk. SageMaker Pipeline'ın değerlendirme adımı. Aşağıdaki örnek yapılandırma dosyasını göstermektedir:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Değerlendirme adımı: Yeni SageMaker Pipeline SDK, kullanıcılara '@step' Python dekoratörünü kullanarak makine öğrenimi iş akışında özel adımlar tanımlama esnekliği sağlar. Bu nedenle kullanıcıların değerlendirmeyi yürüten temel bir Python betiği oluşturması gerekir:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker Boru Hattı: Veri ön işleme, model dağıtımı ve model değerlendirmesi gibi gerekli adımları oluşturduktan sonra kullanıcının SageMaker Pipeline SDK'yı kullanarak adımları birbirine bağlaması gerekir. Yeni SDK, aşağıdaki örnekte gösterildiği gibi bir SageMaker Pipeline oluşturma API'si çağrıldığında farklı adımlar arasındaki bağımlılıkları yorumlayarak iş akışını otomatik olarak oluşturur:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
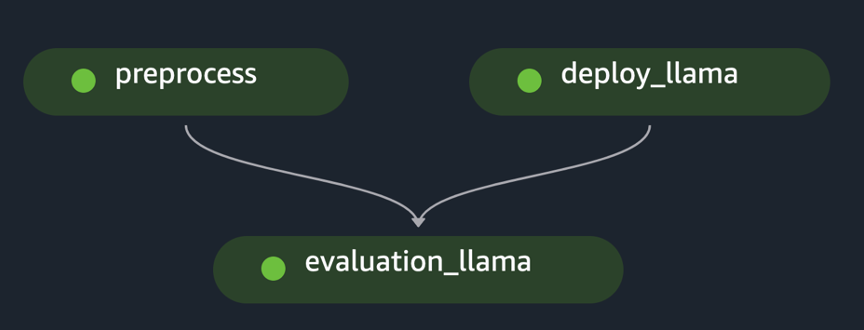
pipeline.start()Örnek, ilk veri kümesini ön işleme tabi tutarak, modeli dağıtarak ve değerlendirmeyi çalıştırarak tek bir FM'nin değerlendirmesini uygular. Oluşturulan boru hattına yönelik çevrimsel olmayan grafik (DAG) aşağıdaki şekilde gösterilmektedir.
Benzer bir yaklaşımı takip ederek ve örneği kullanarak ve uyarlayarak SageMaker JumpStart'ta LLaMA 2 modellerine ince ayar yapın, aşağıdaki şekilde gösterildiği gibi ince ayarlı bir modeli değerlendirmek için işlem hattını oluşturduk.

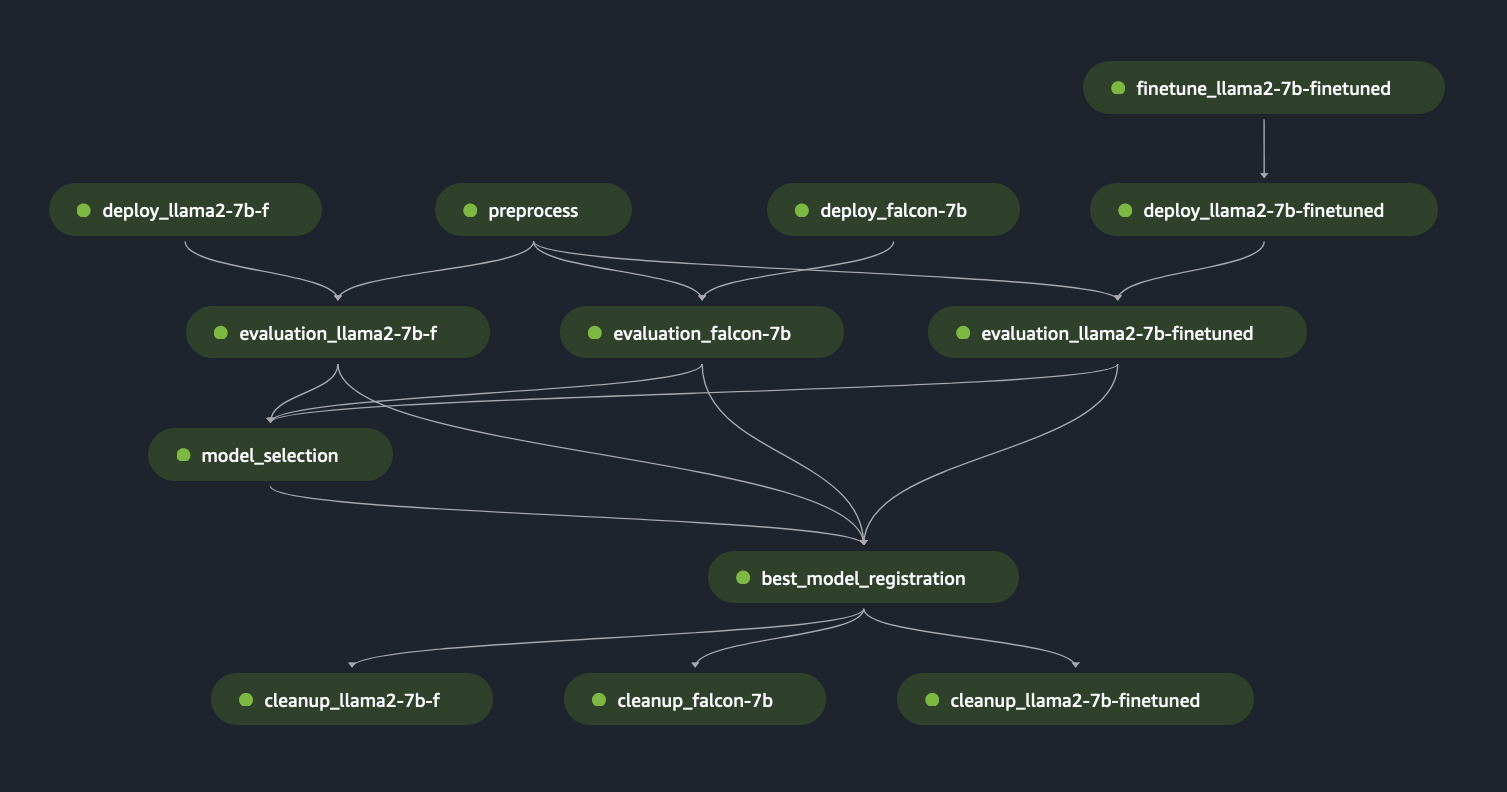
Önceki SageMaker Pipeline adımlarını “Lego” blokları olarak kullanarak, aşağıdaki şekillerde gösterildiği gibi Senaryo 1 ve Senaryo 3 için çözüm geliştirdik. Özellikle, GitHub depo, kullanıcının birden fazla FM'yi paralel olarak değerlendirmesine veya hem temel hem de ince ayarlı modellerin değerlendirmesini birleştirerek daha karmaşık değerlendirme gerçekleştirmesine olanak tanır.


Depoda bulunan ek işlevler aşağıdakileri içerir:
- Dinamik değerlendirme adımı oluşturma: Çözümümüz, kullanıcıların herhangi bir sayıda modeli değerlendirmesine olanak sağlamak için gerekli tüm değerlendirme adımlarını yapılandırma dosyasına dayalı olarak dinamik olarak oluşturur. Hugging Face veya Amazon Bedrock gibi yeni model türlerinin kolay entegrasyonunu desteklemek için çözümü genişlettik.
- Uç noktanın yeniden dağıtımını önleyin: Bir uç nokta zaten mevcutsa dağıtım sürecini atlarız. Bu, kullanıcının değerlendirme için FM'li uç noktaları yeniden kullanmasına olanak tanıyarak maliyet tasarrufu sağlar ve dağıtım süresini kısaltır.
- Son nokta temizliği: Değerlendirmenin tamamlanmasının ardından SageMaker Pipeline, konuşlandırılan uç noktaların kullanımdan kaldırılmasını sağlar. Bu işlevsellik, en iyi model uç noktasını canlı tutacak şekilde genişletilebilir.
- Model seçim adımı: Maliyet veya gecikme gibi kriterleri de içeren, son model seçiminin iş mantığını gerektiren bir model seçim adımı yer tutucusu ekledik.
- Model kayıt adımı: En iyi model, Amazon SageMaker Model Kaydına belirli bir model grubunun yeni bir sürümü olarak kaydedilebilir.
- Sıcak havuz: SageMaker tarafından yönetilen sıcak havuzlar, tekrarlanan iş yükleri için gecikmeyi azaltmak amacıyla bir işin tamamlanmasından sonra tedarik edilen altyapıyı korumanıza ve yeniden kullanmanıza olanak tanır
Aşağıdaki şekil bu yetenekleri ve kullanıcıların bu konuda çözümümüzü kullanarak kolayca ve dinamik bir şekilde oluşturabilecekleri çok modelli bir değerlendirme örneğini göstermektedir. GitHub deposu.
Bilgi istemi kataloğu tasarımları, bilgi istemi şablonları, bilgi istemi optimizasyonu da dahil olmak üzere farklı bir gönderide derinlemesine açıklanacağı için veri hazırlamayı bilinçli olarak kapsam dışında tuttuk. Daha fazla bilgi ve ilgili bileşen tanımları için bkz. FMOps/LLMOps: MLOps ile üretken yapay zekayı ve farklılıkları operasyonel hale getirin.
Sonuç
Bu yazıda, Amazon SageMaker Clarify LLM değerlendirme yeteneklerini ve Amazon SageMaker Pipelines'ı kullanarak LLM değerlendirmesini geniş ölçekte nasıl otomatikleştireceğimize ve operasyonel hale getireceğimize odaklandık. Bunda teorik mimari tasarımların yanı sıra örnek kodlarımız da var. GitHub Müşterilerin kendi ölçeklenebilir değerlendirme mekanizmalarını geliştirmelerine olanak tanıyan depo (Llama2 ve Falcon-7B FM'leri içerir).
Aşağıdaki çizim model değerlendirme mimarisini göstermektedir.

Bu yazıda, LLM değerlendirmesini resmin sol tarafında gösterildiği gibi ölçekte işlevselleştirmeye odaklandık. Gelecekte, FM'lerin uçtan uca yaşam döngüsünü üretime kadar yerine getiren örnekler geliştirmeye odaklanacağız. FMOps/LLMOps: MLOps ile üretken yapay zekayı ve farklılıkları operasyonel hale getirin. Bu, LLM sunumunu, izlenmesini, sonunda otomatik yeniden değerlendirmeyi ve ince ayarı tetikleyecek çıktı derecelendirmesinin depolanmasını ve son olarak etiketli veriler veya bilgi istemleri kataloğu üzerinde çalışmak için döngüdeki insanların kullanılmasını içerir.
yazarlar hakkında
 Dr. Sokratis Kartakis Amazon Web Services'in Baş Makine Öğrenimi ve Operasyon Uzmanı Çözüm Mimarıdır. Sokratis, kurumsal müşterilerin AWS hizmetlerinden yararlanarak ve MLOps/FMOps/LLMOps temelleri gibi işletim modellerini ve en iyi geliştirme uygulamalarından yararlanarak dönüşüm yol haritasını şekillendirerek Makine Öğrenimi (ML) ve üretken yapay zeka çözümlerini sanayileştirmelerine olanak sağlamaya odaklanıyor. Enerji, perakende, sağlık, finans, motor sporları vb. alanlarda yenilikçi uçtan uca üretim düzeyinde makine öğrenimi ve yapay zeka çözümlerini icat etmek, tasarlamak, yönetmek ve uygulamak için 15 yıldan fazla zaman harcadı.
Dr. Sokratis Kartakis Amazon Web Services'in Baş Makine Öğrenimi ve Operasyon Uzmanı Çözüm Mimarıdır. Sokratis, kurumsal müşterilerin AWS hizmetlerinden yararlanarak ve MLOps/FMOps/LLMOps temelleri gibi işletim modellerini ve en iyi geliştirme uygulamalarından yararlanarak dönüşüm yol haritasını şekillendirerek Makine Öğrenimi (ML) ve üretken yapay zeka çözümlerini sanayileştirmelerine olanak sağlamaya odaklanıyor. Enerji, perakende, sağlık, finans, motor sporları vb. alanlarda yenilikçi uçtan uca üretim düzeyinde makine öğrenimi ve yapay zeka çözümlerini icat etmek, tasarlamak, yönetmek ve uygulamak için 15 yıldan fazla zaman harcadı.
 Jagdeep Singh Soni Hollanda merkezli AWS'de Kıdemli Ortak Çözüm Mimarıdır. Hem sistem entegratörlerine hem de teknoloji ortaklarına yardımcı olmak için DevOps, GenAI ve oluşturucu araçlarına olan tutkusunu kullanıyor. Jagdeep, ekibi içinde yenilikçiliği teşvik etmek ve yeni teknolojileri teşvik etmek için uygulama geliştirme ve mimari geçmişini kullanıyor.
Jagdeep Singh Soni Hollanda merkezli AWS'de Kıdemli Ortak Çözüm Mimarıdır. Hem sistem entegratörlerine hem de teknoloji ortaklarına yardımcı olmak için DevOps, GenAI ve oluşturucu araçlarına olan tutkusunu kullanıyor. Jagdeep, ekibi içinde yenilikçiliği teşvik etmek ve yeni teknolojileri teşvik etmek için uygulama geliştirme ve mimari geçmişini kullanıyor.
 Dr. Riccardo Gatti İtalya merkezli Kıdemli Startup Çözüm Mimarıdır. Müşterilerin teknik danışmanıdır; yenilik yapmak, hızla ölçeklenmek ve dakikalar içinde küreselleşmek için doğru araçları ve teknolojileri seçerek işlerini büyütmelerine yardımcı olur. Makine öğrenimi ve üretken yapay zeka konusunda her zaman tutkulu olmuştur; çalışma kariyeri boyunca bu teknolojileri farklı alanlarda incelemiş ve uygulamıştır. Startup kurucularının hikayelerine ve yeni teknolojik trendlere adanmış AWS İtalyanca podcast'i "Casa Startup"ın sunucusu ve editörüdür.
Dr. Riccardo Gatti İtalya merkezli Kıdemli Startup Çözüm Mimarıdır. Müşterilerin teknik danışmanıdır; yenilik yapmak, hızla ölçeklenmek ve dakikalar içinde küreselleşmek için doğru araçları ve teknolojileri seçerek işlerini büyütmelerine yardımcı olur. Makine öğrenimi ve üretken yapay zeka konusunda her zaman tutkulu olmuştur; çalışma kariyeri boyunca bu teknolojileri farklı alanlarda incelemiş ve uygulamıştır. Startup kurucularının hikayelerine ve yeni teknolojik trendlere adanmış AWS İtalyanca podcast'i "Casa Startup"ın sunucusu ve editörüdür.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/

