Bugün, Code Llama modellerine Meta tarafından ince ayar yapma olanağını duyurmanın heyecanını yaşıyoruz. Amazon SageMaker Hızlı Başlangıç. Büyük dil modellerinden (LLM'ler) oluşan Code Llama ailesi, ölçeği 7 milyardan 70 milyar parametreye kadar değişen, önceden eğitilmiş ve ince ayarlı kod oluşturma modellerinin bir koleksiyonudur. İnce ayarlı Code Llama modelleri, temel Code Llama modellerine göre daha iyi doğruluk ve açıklanabilirlik sağlar, bu da testlerde açıkça görülmektedir. İnsanDeğerlendirmesi ve MBPP veri kümeleri. Code Llama modellerinde SageMaker JumpStart ile ince ayar yapabilir ve dağıtabilirsiniz. Amazon SageMaker Stüdyosu Birkaç tıklamayla veya SageMaker Python SDK'yı kullanarak kullanıcı arayüzü. Lama modellerinin ince ayarı, burada sağlanan komut dosyalarına dayanmaktadır. lama tarifleri GitHub deposu PyTorch FSDP, PEFT/LoRA ve Int8 niceleme tekniklerini kullanarak Meta'dan.
Bu yazıda, aşağıda sunulan tek tıklamalı kullanıcı arayüzü ve SDK deneyimi aracılığıyla SageMaker JumpStart aracılığıyla Code Llama'nın önceden eğitilmiş modellerine nasıl ince ayar yapılacağını açıklıyoruz. GitHub deposu.
SageMaker JumpStart nedir?
SageMaker JumpStart ile makine öğrenimi (ML) uygulayıcıları, halka açık geniş bir temel model yelpazesi arasından seçim yapabilir. ML uygulayıcıları temel modelleri özel olarak dağıtabilir Amazon Adaçayı Yapıcı izole edilmiş bir ağ ortamından bulut sunucuları oluşturun ve model eğitimi ve konuşlandırma için SageMaker'ı kullanarak modelleri özelleştirin.
Kod Lama Nedir?
Code Llama, Code Llama'nın koda özel bir versiyonudur. Llama 2 Bu, Llama 2'nin koda özgü veri kümeleri üzerinde daha fazla eğitilmesi ve aynı veri kümesinden daha uzun süre daha fazla veri örneklenmesiyle oluşturuldu. Code Llama, gelişmiş kodlama yeteneklerine sahiptir. Hem koddan hem de doğal dil istemlerinden kod ve kod hakkında doğal dil oluşturabilir (örneğin, "Bana Fibonacci dizisinin çıktısını veren bir fonksiyon yaz"). Bunu kod tamamlama ve hata ayıklama için de kullanabilirsiniz. Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash ve daha fazlası dahil olmak üzere günümüzde kullanılan en popüler programlama dillerinin çoğunu destekler.
Code Llama modellerinde neden ince ayar yapılmalıdır?
Meta, Code Llama performans kıyaslamalarını yayınladı HumanEval ve MBPP Python, Java ve JavaScript gibi yaygın kodlama dilleri için. Code Llama Python modellerinin HumanEval üzerindeki performansı, farklı kodlama dilleri ve görevlerde 38B Python modelinde %7'den 57B Python modellerinde %70'ye kadar değişen performans sergiledi. Ek olarak, SQL programlama dilinde ince ayarlı Code Llama modelleri, SQL değerlendirme kıyaslamalarında açıkça görüldüğü gibi daha iyi sonuçlar vermiştir. Yayınlanan bu kıyaslamalar, Code Llama modellerinde ince ayar yapmanın potansiyel faydalarını vurgulayarak daha iyi performans, özelleştirme ve belirli kodlama alanlarına ve görevlerine uyum sağlamayı mümkün kılıyor.
SageMaker Studio Kullanıcı Arayüzü aracılığıyla kod gerektirmeden ince ayar yapma
SageMaker Studio'yu kullanarak Lama modellerinize ince ayar yapmaya başlamak için aşağıdaki adımları tamamlayın:
- SageMaker Studio konsolunda seçin HızlıBaşlangıç Gezinti bölmesinde.
Açık kaynaklı ve tescilli modellerden 350'den fazla modelin listesini bulacaksınız.
- Code Llama modellerini arayın.

Code Llama modellerini göremiyorsanız SageMaker Studio sürümünüzü kapatıp yeniden başlatarak güncelleyebilirsiniz. Sürüm güncellemeleri hakkında daha fazla bilgi için bkz. Studio Uygulamalarını Kapatın ve Güncelleyin. Diğer model çeşitlerini de tercih ederek bulabilirsiniz. Tüm Kod Oluşturma Modellerini keşfedin veya arama kutusunda Code Lama'yı arayın.
SageMaker JumpStart şu anda Code Llama modelleri için talimat ince ayarını desteklemektedir. Aşağıdaki ekran görüntüsü Code Llama 2 70B modelinin ince ayar sayfasını göstermektedir.
- İçin Eğitim veri kümesi konumu, işaret edebilirsiniz Amazon Basit Depolama Hizmeti İnce ayar için eğitim ve doğrulama veri kümelerini içeren (Amazon S3) paketi.
- İnce ayar için dağıtım yapılandırmanızı, hiper parametrelerinizi ve güvenlik ayarlarınızı belirleyin.
- Klinik Tren SageMaker ML örneğinde ince ayar işini başlatmak için.
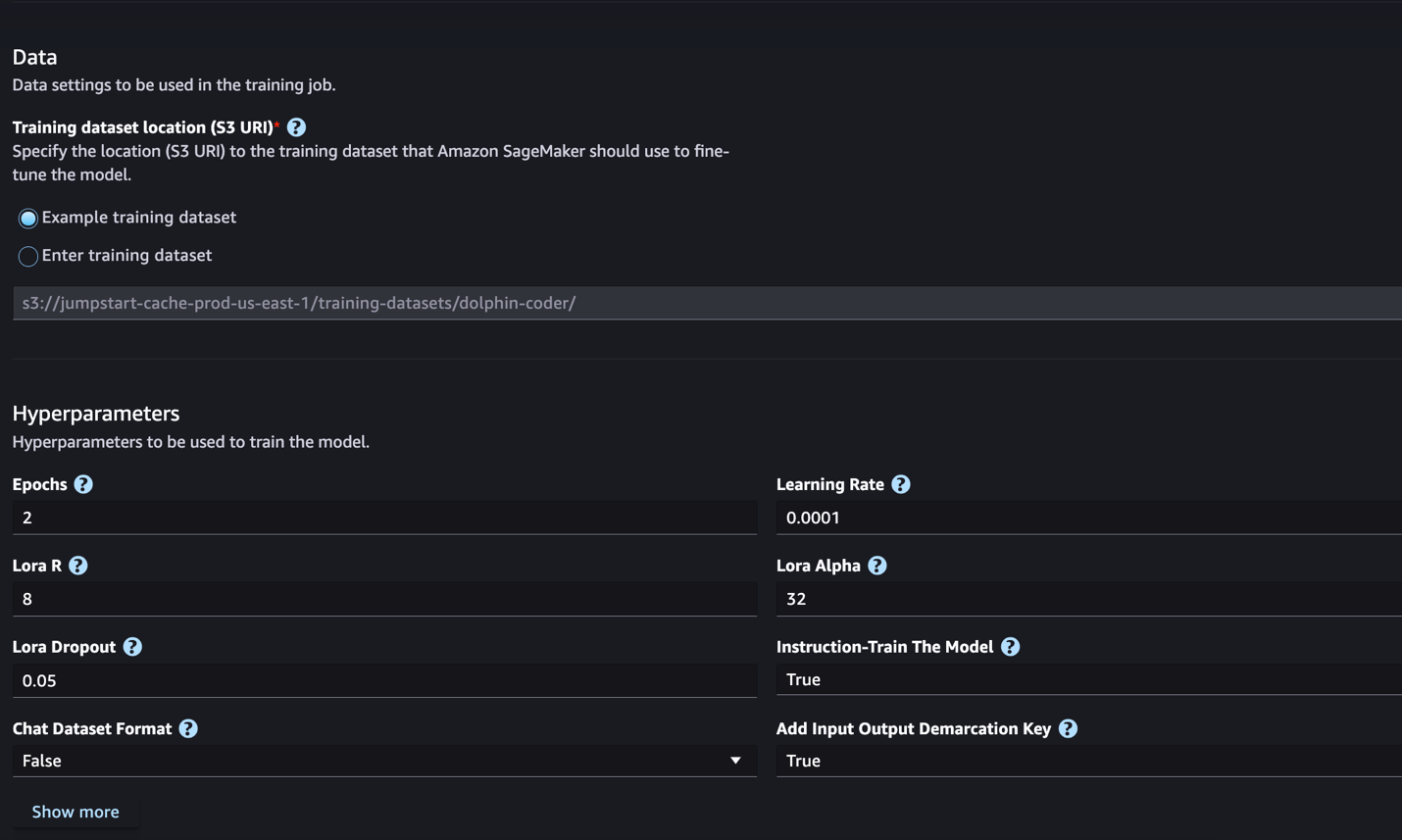
Bir sonraki bölümde talimat ince ayarı için hazırlamanız gereken veri kümesi formatını tartışacağız.
- Modelde ince ayar yapıldıktan sonra SageMaker JumpStart'taki model sayfasını kullanarak dağıtabilirsiniz.
Aşağıdaki ekran görüntüsünde gösterildiği gibi, ince ayar tamamlandığında ince ayarlı modeli dağıtma seçeneği görünecektir.

SageMaker Python SDK aracılığıyla ince ayar yapın
Bu bölümde, talimat formatlı bir veri kümesinde SageMaker Python SDK'yı kullanarak Code LIama modellerine nasıl ince ayar yapılacağını gösteriyoruz. Spesifik olarak model, talimatlar kullanılarak açıklanan bir dizi doğal dil işleme (NLP) görevi için ince ayarlanmıştır. Bu, sıfır atışlı istemlerle görünmeyen görevler için modelin performansının geliştirilmesine yardımcı olur.
İnce ayar işinizi tamamlamak için aşağıdaki adımları tamamlayın. İnce ayar kodunun tamamını şuradan alabilirsiniz: GitHub deposu.
İlk olarak, talimat ince ayarı için gereken veri seti formatına bakalım. Eğitim verileri, her satırın bir veri örneğini temsil eden bir sözlük olduğu JSON satırları (.jsonl) biçiminde biçimlendirilmelidir. Tüm eğitim verileri tek bir klasörde olmalıdır. Ancak birden fazla .jsonl dosyasına kaydedilebilir. Aşağıda JSON satırları biçiminde bir örnek verilmiştir:
Eğitim klasörü şunları içerebilir: template.json Giriş ve çıkış formatlarını açıklayan dosya. Aşağıda örnek bir şablon verilmiştir:
Şablonla eşleşmesi için JSON satır dosyalarındaki her örnek şunları içermelidir: system_prompt, question, ve response alanlar. Bu gösteride, şunu kullanıyoruz: Dolphin Coder veri kümesi Hugging Face'den.
Veri kümesini hazırlayıp S3 klasörüne yükledikten sonra aşağıdaki kodu kullanarak ince ayar yapmaya başlayabilirsiniz:
Aşağıdaki kodda gösterildiği gibi ince ayarlı modeli doğrudan tahminciden dağıtabilirsiniz. Ayrıntılar için, not defterine bakın. GitHub deposu.
İnce ayar teknikleri
Llama gibi dil modellerinin boyutu 10 GB'tan, hatta 100 GB'tan fazladır. Bu kadar büyük modellerde ince ayar yapmak, önemli ölçüde yüksek CUDA belleğine sahip örnekler gerektirir. Ayrıca bu modellerin eğitimi, modelin boyutundan dolayı çok yavaş olabilir. Bu nedenle verimli ince ayar için aşağıdaki optimizasyonları kullanıyoruz:
- Düşük Dereceli Uyarlama (LoRA) – Bu, büyük modellerin verimli ince ayarına yönelik bir tür parametre verimli ince ayardır (PEFT). Bu yöntemle tüm modeli dondurursunuz ve modele yalnızca küçük bir dizi ayarlanabilir parametre veya katman eklersiniz. Örneğin, Llama 7 2B için 7 milyar parametrenin tamamını eğitmek yerine parametrelerin %1'inden daha azına ince ayar yapabilirsiniz. Bu, bellek gereksiniminin önemli ölçüde azaltılmasına yardımcı olur çünkü parametrelerin yalnızca %1'i için degradeleri, optimize edici durumlarını ve eğitimle ilgili diğer bilgileri saklamanız gerekir. Ayrıca bu, eğitim süresinin ve maliyetin azaltılmasına yardımcı olur. Bu yöntemle ilgili daha fazla ayrıntı için bkz. LoRA: Büyük Dil Modellerinin Düşük Dereceli Uyarlaması.
- Int8 nicemleme – LoRA gibi optimizasyonlarla bile Llama 70B gibi modeller eğitilemeyecek kadar büyük. Eğitim sırasında bellek ayak izini azaltmak için eğitim sırasında Int8 nicelemesini kullanabilirsiniz. Niceleme genellikle kayan noktalı veri türlerinin kesinliğini azaltır. Bu, model ağırlıklarını depolamak için gereken belleği azaltsa da bilgi kaybı nedeniyle performansı düşürür. Int8 niceleme yalnızca çeyrek hassasiyet kullanır ancak bitleri düşürmediği için performansın düşmesine neden olmaz. Verileri bir türden diğerine yuvarlar. Int8 nicemleme hakkında bilgi edinmek için bkz. LLM.int8(): Uygun Ölçekte Transformatörler için 8-bit Matris Çarpımı.
- Tamamen Parçalanmış Veri Paralel (FSDP) – Bu, modelin parametrelerini veri paralel çalışanları arasında bölen ve isteğe bağlı olarak eğitim hesaplamasının bir kısmını CPU'lara aktarabilen bir tür veri paralel eğitim algoritmasıdır. Parametreler farklı GPU'lar arasında paylaştırılsa da, her bir mikro grubun hesaplanması GPU çalışanı için yereldir. Parametreleri daha düzgün bir şekilde parçalara ayırır ve eğitim sırasında iletişim ve hesaplamanın örtüşmesi yoluyla optimize edilmiş performansa ulaşır.
Aşağıdaki tablo, farklı ayarlara sahip her modelin ayrıntılarını özetlemektedir.
| Model | Varsayılan ayarlar | LORA + FSDP | LORA + FSDP Yok | Int8 Niceleme + LORA + FSDP Yok |
| Kod Lama 2 7B | LORA + FSDP | Evet | Evet | Evet |
| Kod Lama 2 13B | LORA + FSDP | Evet | Evet | Evet |
| Kod Lama 2 34B | INT8 + LORA + FSDP YOK | Yok hayır | Yok hayır | Evet |
| Kod Lama 2 70B | INT8 + LORA + FSDP YOK | Yok hayır | Yok hayır | Evet |
Lama modellerinin ince ayarı aşağıdakiler tarafından sağlanan komut dosyalarına dayanmaktadır: GitHub repo.
Eğitim için desteklenen hiperparametreler
Code Llama 2 ince ayarı, her biri ince ayarlı modelin bellek gereksinimini, eğitim hızını ve performansını etkileyebilen bir dizi hiper parametreyi destekler:
- çağ – İnce ayar algoritmasının eğitim veri kümesinde gerçekleştirdiği geçiş sayısı. 1'den büyük bir tam sayı olmalıdır. Varsayılan 5'tir.
- öğrenme oranı – Her eğitim örneği grubu üzerinde çalışıldıktan sonra model ağırlıklarının güncellenme hızı. 0'dan büyük bir pozitif kayan nokta olmalıdır. Varsayılan 1e-4'tür.
- talimat_tuned – Modeli eğitip eğitmeyeceği. Olmalıdır
TrueorFalse. VarsayılanFalse. - per_device_train_batch_size – Eğitim için GPU çekirdeği/CPU başına parti boyutu. Pozitif bir tam sayı olmalıdır. Varsayılan 4'tür.
- per_device_eval_batch_size – Değerlendirme için GPU çekirdeği/CPU başına parti boyutu. Pozitif bir tam sayı olmalıdır. Varsayılan 1'dir.
- max_train_samples – Hata ayıklama amacıyla veya daha hızlı eğitim için eğitim örneklerinin sayısını bu değere düşürün. Değer -1, tüm eğitim örneklerinin kullanılması anlamına gelir. Pozitif bir tam sayı veya -1 olmalıdır. Varsayılan -1'dir.
- max_val_samples – Hata ayıklama amacıyla veya daha hızlı eğitim için doğrulama örneklerinin sayısını bu değere düşürün. Değer -1, tüm doğrulama örneklerinin kullanılması anlamına gelir. Pozitif bir tam sayı veya -1 olmalıdır. Varsayılan -1'dir.
- max_input_length – Tokenizasyondan sonra maksimum toplam giriş dizisi uzunluğu. Bundan daha uzun diziler kesilecektir. -1 ise,
max_input_lengthminimum 1024'e ve tokenizer tarafından tanımlanan maksimum model uzunluğuna ayarlanmıştır. Pozitif bir değere ayarlanırsa,max_input_lengthsağlanan değerin minimumuna ayarlanır vemodel_max_lengthtokenizer tarafından tanımlanır. Pozitif bir tam sayı veya -1 olmalıdır. Varsayılan -1'dir. - validation_split_ratio – Doğrulama kanalı ise
none, tren verilerinden tren doğrulama bölünmesinin oranı 0-1 arasında olmalıdır. Varsayılan 0.2'dir. - train_data_split_seed – Doğrulama verileri mevcut değilse, bu, giriş eğitim verilerinin algoritma tarafından kullanılan eğitim ve doğrulama verilerine rastgele bölünmesini düzeltir. Tam sayı olmak zorunda. Varsayılan 0'dır.
- preprocessing_num_workers – Ön işleme için kullanılacak işlemlerin sayısı. Eğer
None, ana işlem ön işleme için kullanılır. Varsayılan:None. - lora_r – Lora R. Pozitif bir tam sayı olmalıdır. Varsayılan 8'dir.
- lora_alpha - Lora Alfa. Pozitif bir tam sayı olmalıdır. Varsayılan 32'dir
- lora_dropout – Lora Bırakma. 0 ile 1 arasında pozitif bir kayan nokta olmalıdır. Varsayılan 0.05'tir.
- int8_kuantizasyon - Eğer
Truemodel, eğitim için 8 bit hassasiyetle yüklenir. 7B ve 13B için varsayılan:False. 70B için varsayılan:True. - etkinleştirme_fsdp – Doğruysa, eğitim FSDP'yi kullanır. 7B ve 13B için varsayılan Doğru'dur. 70B için varsayılan Yanlış'tır. Dikkat
int8_quantizationFSDP tarafından desteklenmez.
Hiperparametreleri seçerken aşağıdakileri göz önünde bulundurun:
- ayar
int8_quantization=TrueBellek gereksinimini azaltır ve daha hızlı eğitime yol açar. - Azalan
per_device_train_batch_sizevemax_input_lengthbellek gereksinimini azaltır ve bu nedenle daha küçük örneklerde çalıştırılabilir. Ancak değerlerin çok düşük ayarlanması eğitim süresini artırabilir. - Int8 nicelemesini kullanmıyorsanız (
int8_quantization=False), FSDP'yi kullanın (enable_fsdp=True) daha hızlı ve verimli eğitim için.
Eğitim için desteklenen örnek türleri
Aşağıdaki tablo, farklı modellerin eğitimi için desteklenen bulut sunucusu türlerini özetlemektedir.
| Model | Varsayılan Bulut Sunucusu Türü | Desteklenen Örnek Türleri |
| Kod Lama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Kod Lama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Kod Lama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
Bulut sunucusu tipini seçerken aşağıdakileri göz önünde bulundurun:
- G5 bulut sunucuları, desteklenen bulut sunucusu türleri arasında en verimli eğitimi sağlar. Bu nedenle G5 bulut sunucularınız varsa bunları kullanmalısınız.
- Eğitim süresi büyük ölçüde GPU sayısına ve mevcut CUDA belleğine bağlıdır. Bu nedenle, aynı sayıda GPU'ya (örneğin, ml.g5.2xlarge ve ml.g5.4xlarge) sahip bulut sunucuları üzerinde eğitim kabaca aynıdır. Bu nedenle eğitim için daha ucuz örneği kullanabilirsiniz (ml.g5.2xlarge).
- p3 örnekleri kullanıldığında bfloat32 bu örneklerde desteklenmediği için eğitim 16 bit hassasiyetle yapılacaktır. Bu nedenle eğitim işi, p3 bulut sunucuları üzerinde eğitim sırasında g5 bulut sunucularına kıyasla iki kat daha fazla CUDA belleği tüketecektir.
Örnek başına eğitim maliyeti hakkında bilgi edinmek için bkz. Amazon EC2 G5 Örnekleri.
Değerlendirme
Değerlendirme, ince ayarlı modellerin performansını değerlendirmek için önemli bir adımdır. İnce ayarlı modellerin ince ayarlı olmayan modellere göre gelişimini göstermek için hem niteliksel hem de niceliksel değerlendirmeler sunuyoruz. Niteliksel değerlendirmede, hem ince ayarlı hem de ince ayarlı olmayan modellerden örnek bir yanıt gösteriyoruz. Niceliksel değerlendirmede şunları kullanırız: İnsanDeğerlendirmesiDoğru ve doğru sonuçlar üretme yeteneklerini test etmek amacıyla Python kodu oluşturmak için OpenAI tarafından geliştirilen bir test paketi. HumanEval deposu MIT lisansı altındadır. Tüm Code LIama modellerinin Python varyantlarına farklı boyutlarda ince ayar yaptık (Code LIama Python 7B, 13B, 34B ve 70B Dolphin Coder veri kümesi) ve değerlendirme sonuçlarını aşağıdaki bölümlerde sunun.
Niteliksel değerlendirme
İnce ayarlı modeliniz dağıtıldığında, kod oluşturmak için uç noktayı kullanmaya başlayabilirsiniz. Aşağıdaki örnekte, bir test örneğinde hem temel hem de ince ayarlı Code LIama 34B Python varyantlarından yanıtlar sunuyoruz. Dolphin Coder veri kümesi:
İnce ayarlı Code Llama modeli, önceki sorgunun kodunu sağlamanın yanı sıra, yaklaşımın ayrıntılı bir açıklamasını ve bir sözde kod üretir.
Code Llama 34b Python İnce Ayarlı Olmayan Yanıt:
Code Llama 34B Python İnce Ayarlı Yanıt
Zemin gerçeği
İlginç bir şekilde, Code Llama 34B Python'un ince ayarlı sürümü, en uzun palindromik alt diziye dinamik programlama tabanlı bir çözüm sağlar; bu, seçilen test örneğindeki temel gerçeklikte sağlanan çözümden farklıdır. İnce ayarlı modelimiz, dinamik programlama tabanlı çözümü ayrıntılı olarak açıklıyor ve açıklıyor. Öte yandan, ince ayar yapılmamış model, potansiyel çıktıları, üretimden hemen sonra halüsinasyona uğratır. print deyimi (sol hücrede gösterilmektedir) çünkü çıktı axyzzyx verilen dizedeki en uzun palindrom değil. Zaman karmaşıklığı açısından dinamik programlama çözümü genellikle ilk yaklaşımdan daha iyidir. Dinamik programlama çözümünün zaman karmaşıklığı O(n^2)'dir; burada n, giriş dizesinin uzunluğudur. Bu, aynı zamanda O(n^2) ikinci dereceden zaman karmaşıklığına sahip olan ancak daha az optimize edilmiş bir yaklaşıma sahip olan, ince ayar yapılmamış modelin ilk çözümünden daha verimlidir.
Bu umut verici görünüyor! Unutmayın, Code LIama Python varyantında yalnızca %10 oranında ince ayar yaptık. Dolphin Coder veri kümesi. Keşfedilecek daha çok şey var!
Yanıttaki kapsamlı talimatlara rağmen yine de çözümde sağlanan Python kodunun doğruluğunu incelememiz gerekiyor. Daha sonra, adı verilen bir değerlendirme çerçevesi kullanırız. İnsan Değerlendirmesi Kalitesini sistematik olarak incelemek için Code LIama'dan oluşturulan yanıt üzerinde entegrasyon testleri yürütmek.
HumanEval ile niceliksel değerlendirme
HumanEval, makalede açıklandığı gibi, bir Yüksek Lisans'ın Python tabanlı kodlama problemlerinde problem çözme yeteneklerini değerlendirmek için kullanılan bir değerlendirme aracıdır. Kod Eğitimi Alan Büyük Dil Modellerinin Değerlendirilmesi. Spesifik olarak, bir dil modelinin işlev imzası, docstring, gövde ve birim testleri gibi sağlanan bilgilere dayalı olarak kod üretme yeteneğini değerlendiren 164 orijinal Python tabanlı programlama probleminden oluşur.
Her Python tabanlı programlama sorusunu k yanıt almak üzere SageMaker uç noktasında konuşlandırılan Code LIama modeline gönderiyoruz. Daha sonra, HumanEval deposundaki entegrasyon testlerinde k yanıtın her birini çalıştırıyoruz. K yanıtın herhangi bir yanıtı entegrasyon testlerini geçerse, o test senaryosunu başarılı sayarız; aksi takdirde başarısız oldu. Daha sonra başarılı vakaların oranını nihai değerlendirme puanı olarak hesaplamak için işlemi tekrarlıyoruz. pass@k. Standart uygulamayı takiben, soru başına yalnızca bir yanıt oluşturmak ve entegrasyon testini geçip geçmediğini test etmek için değerlendirmemizde k'yi 1 olarak belirledik.
Aşağıda HumanEval deposunu kullanmak için örnek bir kod bulunmaktadır. SageMaker uç noktasını kullanarak veri kümesine erişebilir ve tek bir yanıt oluşturabilirsiniz. Ayrıntılar için, not defterine bakın. GitHub deposu.
Aşağıdaki tablo, farklı model boyutlarında ince ayarlı Code LIama Python modellerinin ince ayarlı olmayan modellere göre iyileştirmelerini göstermektedir. Doğruluğu sağlamak için, ince ayar yapılmamış Code LIama modellerini de SageMaker uç noktalarına dağıtıyoruz ve İnsan Değerlendirmesi değerlendirmelerinden geçiyoruz. pas@1 sayılar (aşağıdaki tabloda ilk satır), raporda bildirilen sayılarla eşleşiyor Kod Lama araştırma makalesi. Çıkarım parametreleri tutarlı bir şekilde şu şekilde ayarlanır: "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Sonuçlardan da görebileceğimiz gibi, tüm ince ayarlı Code LIama Python varyantları, ince ayar yapılmamış modellere göre önemli bir gelişme göstermektedir. Özellikle Code LIama Python 70B, ince ayar yapılmayan modelden yaklaşık %12 oranında daha iyi performans göstermektedir.
| . | 7B Python | 13B Python | 34B | 34B Python | 70B Python |
| Önceden eğitilmiş model performansı (geçiş@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| İnce ayarlı model performansı (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Artık Code LIama modellerine kendi veri kümenizde ince ayar yapmayı deneyebilirsiniz.
Temizlemek
SageMaker uç noktasını artık çalışır durumda tutmak istemediğinize karar verirseniz, şunu kullanarak silebilirsiniz: Python için AWS SDK (Boto3), AWS Komut Satırı Arayüzü (AWS CLI) veya SageMaker konsolu. Daha fazla bilgi için bakınız Uç Noktaları ve Kaynakları Sil. Ayrıca şunları yapabilirsiniz: SageMaker Studio kaynaklarını kapatın artık gerekli değil.
Sonuç
Bu yazıda, SageMaker JumpStart'ı kullanarak Meta'nın Code Llama 2 modellerine ince ayar yapmayı tartıştık. Bu modellere ince ayar yapmak ve dağıtmak için SageMaker Studio'daki SageMaker JumpStart konsolunu veya SageMaker Python SDK'yı kullanabileceğinizi gösterdik. Ayrıca ince ayar tekniğini, örnek türlerini ve desteklenen hiperparametreleri de tartıştık. Ayrıca, yürüttüğümüz çeşitli testlere dayanarak optimize edilmiş eğitim önerilerinin ana hatlarını çizdik. İki veri kümesi üzerinde üç modele ince ayar yapılmasının bu sonuçlarından da görebileceğimiz gibi, ince ayar, ince ayar yapılmayan modellere kıyasla özetlemeyi geliştirir. Bir sonraki adım olarak, kullanım senaryolarınız için sonuçları test etmek ve kıyaslamak amacıyla GitHub deposunda sağlanan kodu kullanarak bu modellere kendi veri kümenizde ince ayar yapmayı deneyebilirsiniz.
Yazarlar Hakkında
 Doktor Xin Huang Amazon SageMaker JumpStart ve Amazon SageMaker yerleşik algoritmaları için Kıdemli Uygulamalı Bilim İnsanıdır. Ölçeklenebilir makine öğrenimi algoritmaları geliştirmeye odaklanıyor. Araştırma ilgi alanları, doğal dil işleme, tablo verileri üzerinde açıklanabilir derin öğrenme ve parametrik olmayan uzay-zaman kümelemenin sağlam analizi alanındadır. ACL, ICDM, KDD konferanslarında ve Royal Statistical Society: Series A'da birçok makale yayınladı.
Doktor Xin Huang Amazon SageMaker JumpStart ve Amazon SageMaker yerleşik algoritmaları için Kıdemli Uygulamalı Bilim İnsanıdır. Ölçeklenebilir makine öğrenimi algoritmaları geliştirmeye odaklanıyor. Araştırma ilgi alanları, doğal dil işleme, tablo verileri üzerinde açıklanabilir derin öğrenme ve parametrik olmayan uzay-zaman kümelemenin sağlam analizi alanındadır. ACL, ICDM, KDD konferanslarında ve Royal Statistical Society: Series A'da birçok makale yayınladı.
 Vişaal Yalamanchali erken aşamadaki üretken yapay zeka, robot teknolojisi ve otonom araç şirketleriyle çalışan bir Startup Solutions Architect'tir. Vishaal, en son teknoloji makine öğrenimi çözümleri sunmak için müşterileriyle birlikte çalışıyor ve kişisel olarak takviyeli öğrenme, LLM değerlendirmesi ve kod oluşturmayla ilgileniyor. AWS'den önce Vishaal, UCI'da biyoinformatik ve akıllı sistemlere odaklanan bir lisans öğrencisiydi.
Vişaal Yalamanchali erken aşamadaki üretken yapay zeka, robot teknolojisi ve otonom araç şirketleriyle çalışan bir Startup Solutions Architect'tir. Vishaal, en son teknoloji makine öğrenimi çözümleri sunmak için müşterileriyle birlikte çalışıyor ve kişisel olarak takviyeli öğrenme, LLM değerlendirmesi ve kod oluşturmayla ilgileniyor. AWS'den önce Vishaal, UCI'da biyoinformatik ve akıllı sistemlere odaklanan bir lisans öğrencisiydi.
 Meenakshisundaram Thandavarayan AWS'de AI/ML Uzmanı olarak çalışıyor. İnsan odaklı veri ve analitik deneyimlerini tasarlama, yaratma ve tanıtma tutkusuna sahiptir. Meena, AWS'nin stratejik müşterilerine ölçülebilir, rekabet avantajı sağlayan sürdürülebilir sistemler geliştirmeye odaklanıyor. Meena bir bağlayıcı ve tasarım düşünürüdür ve işletmeleri inovasyon, kuluçka ve demokratikleşme yoluyla yeni çalışma yöntemlerine yönlendirmeye çalışmaktadır.
Meenakshisundaram Thandavarayan AWS'de AI/ML Uzmanı olarak çalışıyor. İnsan odaklı veri ve analitik deneyimlerini tasarlama, yaratma ve tanıtma tutkusuna sahiptir. Meena, AWS'nin stratejik müşterilerine ölçülebilir, rekabet avantajı sağlayan sürdürülebilir sistemler geliştirmeye odaklanıyor. Meena bir bağlayıcı ve tasarım düşünürüdür ve işletmeleri inovasyon, kuluçka ve demokratikleşme yoluyla yeni çalışma yöntemlerine yönlendirmeye çalışmaktadır.
 Ashish Khetan Amazon SageMaker yerleşik algoritmalarına sahip Kıdemli Uygulamalı Bilim Adamıdır ve makine öğrenimi algoritmalarının geliştirilmesine yardımcı olur. Doktora derecesini University of Illinois Urbana-Champaign'den almıştır. Makine öğrenimi ve istatistiksel çıkarım alanlarında aktif bir araştırmacıdır ve NeurIPS, ICML, ICLR, JMLR, ACL ve EMNLP konferanslarında birçok makale yayınlamıştır.
Ashish Khetan Amazon SageMaker yerleşik algoritmalarına sahip Kıdemli Uygulamalı Bilim Adamıdır ve makine öğrenimi algoritmalarının geliştirilmesine yardımcı olur. Doktora derecesini University of Illinois Urbana-Champaign'den almıştır. Makine öğrenimi ve istatistiksel çıkarım alanlarında aktif bir araştırmacıdır ve NeurIPS, ICML, ICLR, JMLR, ACL ve EMNLP konferanslarında birçok makale yayınlamıştır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

