Kuruluşlar, günümüzün veri odaklı ortamında sürekli genişleyen veri formatları yelpazesiyle boğuşuyor. Avro'nun ikili serileştirmesinden Protobuf'un verimli ve kompakt yapısına kadar, veri formatlarının kapsamı geleneksel CSV ve JSON alanlarının çok ötesine genişledi. Kuruluşlar bu çeşitli veri akışlarından içgörü elde etmeye çalışırken zorluk, bunları sorunsuz bir şekilde ölçeklenebilir bir çözüme entegre etmektir.
Bu yazıda, konuyu ele alıyoruz Amazon Redshift Akış Alımı JSON olmayan veri formatlarını almak, işlemek ve analiz etmek için. Amazon Redshift Streaming Ingestion, aşağıdakilere bağlanmanıza olanak tanır: Amazon Kinesis Veri Akışları ve Apache Kafka için Amazon Tarafından Yönetilen Akış (Amazon MSK) doğrudan materyalleştirilmiş görünümler aracılığıyla, gerçek zamanlı olarak ve verilerin aşamalı olarak hazırlanmasıyla ilgili karmaşıklık olmadan Amazon Basit Depolama Hizmeti (Amazon S3) ve kümeye yükleniyor. Bu somutlaştırılmış görünümler yalnızca veri akışı için bir giriş bölgesi sağlamakla kalmaz, aynı zamanda gelişmiş işleme için SQL dönüşümlerini birleştirme ve çıkarma, yükleme ve dönüştürme (ELT) ardışık düzeninize birleştirme esnekliği de sunar. Akış alımını yapılandırma ve kullanma konusunda daha derin bir araştırma için Amazon Kırmızıya Kaydırmabakın Amazon Redshift akış alımıyla gerçek zamanlı analiz.
Amazon Redshift'teki JSON verileri
Amazon Redshift, SUPER veri türü, PartiQL dili, materyalleştirilmiş görünümler ve data lake sorguları aracılığıyla JSON verileri üzerinde depolama, işleme ve analize olanak tanır. Amazon Redshift'teki akış verilerine erişmeye yönelik temel yapı, kaynak akıştan meta veriler (akış zaman damgası, sıra numaraları, yenileme zaman damgası ve daha fazlası gibi özellikler) ve akışın kendisinden ham ikili veriler sağlar. JSON biçiminde kodlanmış ham ikili verileri içeren akışlar için Amazon Redshift, verilerin ayrıştırılmasına ve yönetilmesine yönelik çeşitli araçlar sağlar. Her akış formatının meta verileri hakkında daha fazla bilgi için bkz. Amazon Kinesis Data Streams'ten akış alımını kullanmaya başlama ve Apache Kafka için Amazon Managed Streaming'den akış alımını kullanmaya başlama.
Amazon Redshift, en temel düzeyde ham verilerin farklı sütunlara ayrıştırılmasına olanak tanır. JSON_EXTRACT_PATH_TEXT ve JSON_EXTRACT_ARRAY_ELEMENT_TEXT işlevler, JSON nesnelerinden ve dizilerinden belirli ayrıntıların çıkarılmasına olanak tanır ve bunları analiz için ayrı sütunlara dönüştürür. JSON belgelerinin yapısı ve belirli raporlama gereksinimleri tanımlandığında, bu yöntemler, analitik için iyileştirilmiş sıkıştırma ve sıralama ile raporlama için gereken tam yapıya sahip, somutlaştırılmış bir görünümün önceden hesaplanmasına olanak tanır.
Bu yaklaşıma ek olarak Amazon Redshift JSON işlevleri, uyarlanabilir SUPER veri türünü kullanarak JSON verilerinin orijinal durumunda saklanmasına ve analiz edilmesine olanak tanır. İşlev JSON_PARSE akıştaki ikili verileri çıkarmanıza ve SUPER veri türüne dönüştürmenize olanak tanır. SUPER veri türü ve PartiQL dili ile Amazon Redshift, yarı yapılandırılmış veri analizi yeteneklerini genişletiyor. JSON veri depolaması için SUPER veri türünü kullanarak bir sütun içinde şema esnekliği sunar. SUPER veri tipini kullanma hakkında daha fazla bilgi için bkz. Amazon Redshift'te yarı yapılandırılmış verileri alma ve sorgulama. Bu dinamik yetenek, yarı yapılandırılmış verilerin veri alımını, depolanmasını, dönüştürülmesini ve analizini basitleştirerek Redshift ortamındaki çeşitli kaynaklardan gelen içgörüleri zenginleştirir.
Akış veri formatları
Alternatif serileştirme formatlarını kullanan kuruluşların farklı seri durumdan çıkarma yöntemlerini keşfetmesi gerekir. Bir sonraki bölümde seri durumdan çıkarma için en uygun yaklaşımı ele alacağız. Bu bölümde kuruluşların verilerini etkili bir şekilde yönetmek için kullandıkları çeşitli formatlara ve stratejilere daha yakından bakacağız. Bu anlayış, Amazon Redshift'teki veri ayrıştırma yaklaşımını belirlemede kilit öneme sahiptir.
Birçok kuruluş, akış kullanım durumları için JSON dışında bir format kullanır. JSON, veri şemasının gerçek verinin yanında depolandığı, kendini tanımlayan bir serileştirme formatıdır. Bu, JSON'u uygulamalar için esnek hale getirir ancak bu yaklaşım, JSON anahtarlarında ve söz diziminde yer alan ek veriler nedeniyle uygulamalar arasında veri aktarımının artmasına yol açabilir. Serileştirme ve seri durumdan çıkarma performanslarını ve uygulamalar arasındaki ağ iletişimini optimize etmek isteyen kuruluşlar, aşağıdaki gibi bir format kullanmayı tercih edebilir: Avro, protobuf, hatta uygulama verilerini optimize edilmiş bir şekilde ikili formatta serileştirmek için özel bir özel format. Bu, yalnızca mesaj değerlerinin ikili mesaja paketlendiği verimli bir serileştirme avantajı sağlar. Ancak bu, veri tüketicisinin, mesajı seri durumdan çıkarmak amacıyla verileri seri hale getirmek için hangi şema ve protokolün kullanıldığını bilmesini gerektirir. Aşağıdaki şekilde gösterildiği gibi kuruluşların bu sorunu çözmesinin birkaç yolu vardır.
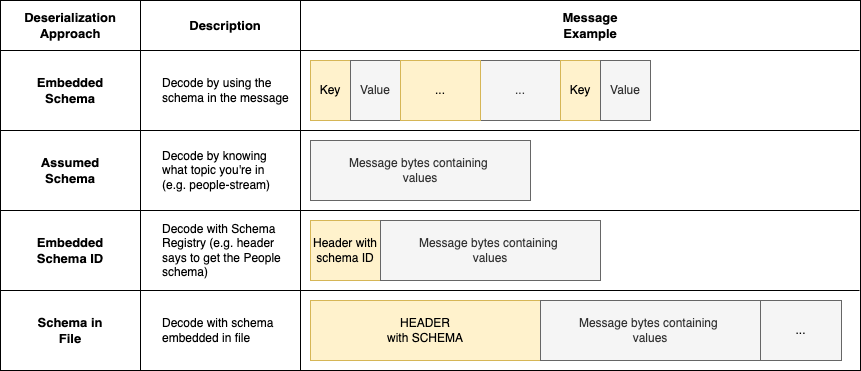
Gömülü şema
Gömülü şema yaklaşımında veri formatının kendisi, gerçek verilerin yanı sıra şema bilgilerini de içerir. Bu, bir mesaj serileştirildiğinde hem şema tanımını hem de veri değerlerini içerdiği anlamına gelir. Bu, mesajı alan herkesin, şema bilgisi için harici bir kaynağa başvurmaya gerek kalmadan, mesaj yapısını doğrudan yorumlamasına ve anlamasına olanak tanır. JSON,MessagePack ve YAML gibi formatlar gömülü şema formatlarına örnektir. Bu formatta bir mesaj aldığınızda, mesajı hemen ayrıştırabilir ve hiçbir ek adıma gerek kalmadan verilere erişebilirsiniz.
Varsayılan şema
Varsayılan bir şema yaklaşımında, mesaj serileştirmesi yalnızca veri değerlerini içerir ve herhangi bir şema bilgisi dahil edilmez. Verileri doğru bir şekilde yorumlamak için, alıcı uygulamanın mesajı serileştirmek için kullanılan şema hakkında önceden bilgi sahibi olması gerekir. Bu genellikle şemanın bir akış adı gibi bir tanımlayıcı veya bağlamla ilişkilendirilmesiyle elde edilir. Alıcı uygulama bir mesajı okuduğunda, karşılık gelen şemayı almak için bu bağlamı kullanır ve ardından ikili verilerin kodunu buna göre çözer. Bu yaklaşım, bağlama dayalı olarak şema alma ve kod çözme konusunda ek bir adım gerektirir. Bu genellikle kod içi veya harici bir veritabanında bir eşlemenin kurulmasını gerektirir, böylece tüketiciler akış meta verilerine (örneğin, AWS Tutkal Şeması Kayıt Defteri).
Bu yaklaşımın bir dezavantajı şema versiyonlarının izlenmesidir. Tüketiciler ilgili şemayı akış adından tanımlayabilseler de kullanılan şemanın belirli sürümünü tanımlayamazlar. Üreticilerin, tüketicilerin farklı bir şema sürümü kullanırken rahatsız edilmemelerini sağlamak için şemalarda geriye dönük uyumlu değişiklikler yaptıklarından emin olmaları gerekir.
Gömülü şema kimliği
Bu durumda üretici, varsayılan şema yaklaşımına benzer şekilde verileri ikili formatta (Avro veya Protobuf gibi) serileştirmeye devam eder. Ancak ek bir adım daha vardır: Üretici, mesaj başlığının başına bir şema kimliği ekler. Bir tüketici mesajı işlediğinde, şema kimliğini başlıktan çıkararak başlar. Bu şema kimliğiyle tüketici daha sonra ilgili şemayı bir kayıt defterinden alır. Alınan şemayı kullanarak tüketici mesajın geri kalanını etkili bir şekilde ayrıştırabilir. Örneğin, AWS Glue Schema Registry şunları sağlar: Java SDK SerDe kitaplıkları, yerleşik şema kimliklerini kullanarak bir akıştaki iletileri yerel olarak seri hale getirebilir ve seri durumdan kaldırabilir. Bakınız Şema kayıt defteri nasıl çalışır? Kayıt defterini kullanma hakkında daha fazla bilgi için.
Tüketicilere ve geliştiricilere birçok avantaj sağladığı için akış uygulamalarında harici şema kayıt defterinin kullanımı yaygındır. Bu kayıt defteri, uygulamalara ilişkin tüm mesaj şemalarını içerir ve şema alımını kolaylaştırmak için bunları benzersiz bir tanımlayıcıyla ilişkilendirir. Ayrıca kayıt defteri, uygulama geliştirmeyi kolaylaştırmak için şema sürümü değişikliği yönetimi ve belgeleme gibi diğer işlevleri de sağlayabilir.
Mesaj yükündeki yerleşik şema kimliği, sürüm bilgilerini içerebilir ve böylece yayıncıların ve tüketicilerin verileri yönetmek için her zaman aynı şema sürümünü kullanmasını sağlar. Şema sürümü bilgisi mevcut olmadığında şema kayıtları, tüketicilerde sorunlara yol açmamak için üreticilerin geriye dönük uyumlu değişiklikler yapmasına yardımcı olabilir. Bu, üreticilerin ve tüketicilerin ayrılmasına yardımcı olur, hem yayıncı hem de tüketici aşamasında şema doğrulaması sağlar ve çeşitli uygulama gereksinimlerine izin vermek için akış kullanımında daha fazla esneklik sağlar. Mesajlar, akış başına bir şemayla veya tek bir akış içinde birden fazla şemayla yayınlanabilir; böylece tüketiciler, mesajları geldikçe dinamik olarak yorumlayabilir.
Şema kayıt defterinin avantajlarını daha derinlemesine incelemek için bkz. Hesaplar arası AWS Glue Schema Registry'deki şemaları kullanarak Amazon MSK üzerinden akış verilerini doğrulayın.
Dosyadaki şema
Toplu işleme kullanım durumları için uygulamalar, veri tüketimini kolaylaştırmak amacıyla verileri serileştirmek için kullanılan şemayı veri dosyasının kendisine yerleştirebilir. Bu, gömülü şema yaklaşımının bir uzantısıdır ancak veri dosyası genellikle daha büyük olduğundan daha az maliyetlidir, dolayısıyla şema, genel verilerin orantılı olarak daha küçük bir miktarını oluşturur. Bu durumda tüketiciler ek bir mantık gerektirmeden verileri doğrudan işleyebilirler. Amazon Redshift, COPY komutu kullanılarak bu şekilde serileştirilen Avro verilerinin yüklenmesini destekler.
JSON olmayan verileri JSON'a dönüştürün
JSON dışı serileştirme formatlarını kullanmayı amaçlayan kuruluşların, mesajlarını Amazon Redshift dışında ayrıştırmak için harici bir yöntem geliştirmesi gerekir. Bir kullanmanızı öneririz AWS Lambdatabanlı harici kullanıcı tanımlı işlev (UDF) bu süreç için. Harici bir Lambda UDF kullanmak, kuruluşların yerleşik şema, varsayılan şema ve yerleşik şema kimliği yaklaşımları dahil olmak üzere herhangi bir mesaj formatını desteklemek için rastgele seri durumdan çıkarma mantığını tanımlamasına olanak tanır. Amazon Redshift, bazı kullanım durumları için geçerli bir alternatif olabilecek Python UDF'lerini yerel olarak tanımlamayı desteklese de, bu yazıda daha karmaşık senaryoları kapsayacak şekilde Lambda UDF yaklaşımını gösteriyoruz. Amazon Redshift UDF örnekleri için bkz. GitHub'daki AWS Örnekleri.
Bu çözümün temel mimarisi aşağıdaki gibidir.

Aşağıdaki koda bakın:
Her adımı daha ayrıntılı olarak inceleyelim.
Lambda UDF'yi oluşturun
Genel amaç ham veriyi girdi olarak kabul edip çıktı olarak JSON kodlu veri üretebilen bir yöntem geliştirmektir. Bu, Amazon Redshift'in JSON'u yerel olarak SUPER veri türüne dönüştürme yeteneğiyle uyumludur. Fonksiyonun özellikleri serileştirme ve akış yaklaşımına bağlıdır. Örneğin, Avro biçimiyle varsayılan şema yaklaşımını kullanarak Lambda işleviniz aşağıdaki adımları tamamlayabilir:
- Akış adını ve onaltılık kodlanmış verileri giriş olarak alın.
- Verilen akış adına ilişkin şemayı tanımlamak amacıyla bir arama gerçekleştirmek için akış adını kullanın.
- Onaltılık veriyi ikili formata dönüştürün.
- İkili verileri okunabilir formatta seri durumdan çıkarmak için şemayı kullanın.
- Verileri JSON biçiminde yeniden serileştirin.
The f_glue_schema_registry_avro_to_json AWS örnekleri örneği, Avro şemalarını akış adına göre almak ve kullanmak için bir Lambda UDF'deki AWS Glue Schema Registry'yi kullanarak varsayılan şema yaklaşımını kullanarak Avro'nun kodunu çözme işlemini gösterir. Diğer yaklaşımlar için (katıştırılmış şema kimliği gibi), serileştirme işleminiz ve şema kayıt defteri uygulamanız tarafından tanımlandığı şekilde seri durumdan çıkarma işlemlerini gerçekleştirecek şekilde Lambda işlevinizi yazmalısınız. Uygulamanız mesaj şemasını işlemek için harici bir şema kaydına veya tablo aramasına bağlıysa, harici sistemlerdeki yükün azaltılmasına ve ortalama Lambda işlevi çağrı süresinin azaltılmasına yardımcı olmak için şema aramaları için önbelleğe alma uygulamanızı öneririz.
Lambda işlevini oluştururken Amazon Redshift giriş olayı formatına uyum sağladığınızdan ve beklenen Amazon Redshift olay çıkış formatıyla uyumlu olduğundan emin olun. Ayrıntılar için bkz. Ölçekli bir Lambda UDF oluşturma.
Lambda işlevini oluşturup test ettikten sonra bunu Amazon Redshift'te UDF olarak tanımlayabilirsiniz. Amazon Redshift'te etkili entegrasyon için bu Lambda işlevi UDF'sini DEĞİŞTİRİLEBİLİR olarak atayın. Bu sınıflandırma, artımlı gerçekleştirilmiş görünüm güncellemelerini destekler. Bu, Lambda işlevini bağımsız olarak ele alır ve çözüm için Lambda işlevi maliyetlerini en aza indirir; çünkü bir ileti daha önce işlenmişse işlenmesine gerek yoktur.
Temel Kinesis veri akışını yapılandırma
Mesajlaşma biçiminiz veya yaklaşımınız (gömülü şema, varsayılan şema ve yerleşik şema kimliği) ne olursa olsun, mesajlaşma kaynağınızdan Amazon Redshift'e akış beslemesi için harici şemayı ayarlamayla başlarsınız. Daha fazla bilgi için bkz. Akış besleme.
Ham materyalleştirilmiş görünümü oluşturma
Daha sonra ham materyalleştirilmiş görünümünüzü tanımlarsınız. Bu görünüm, akış kaynağından gelen ham mesaj verilerini Amazon Redshift VARBYTE formatında içerir.
VARBYTE verilerini VARCHAR formatına dönüştürün
Harici Lambda işlevi UDF'leri, giriş veri türü olarak VARBYTE'ı desteklemez. Bu nedenle akıştaki ham VARBYTE verilerini Lambda işlevine geçirmek için VARCHAR biçimine dönüştürmeniz gerekir. Amazon Redshift'te bunu yapmanın en iyi yolu TO_HEX yerleşik yöntem. Bu, ikili verileri Lambda UDF'ye gönderilebilecek onaltılık kodlanmış karakter verilerine dönüştürür.
JSON verilerini almak için Lambda işlevini çağırın
UDF tanımlandıktan sonra, onaltılık kodlanmış verilerimizi JSON kodlu VARCHAR verilerine dönüştürmek için UDF'yi çağırabiliriz.
JSON verilerini SUPER veri türüne dönüştürmek için JSON_PARSE yöntemini kullanın
Son olarak Amazon Redshift yerel JSON ayrıştırma yöntemlerini aşağıdaki gibi kullanabiliriz: JSON_PARSE, JSON_EXTRACT_PATH_TEXTve JSON verilerini analiz için kullanabileceğimiz bir formatta ayrıştırmak için daha fazlasını kullanın.
Hususlar
Bu stratejiyi kullanırken aşağıdakileri göz önünde bulundurun:
- Ücret – Amazon Redshift, ölçeklenebilirliği geliştirmek ve genel Lambda çağrı sayısını azaltmak için Lambda işlevini toplu olarak çağırır. Bu çözümün maliyeti, akışınızdaki ileti sayısına, yenileme sıklığına ve Amazon Redshift'ten toplu olarak iletilerin işlenmesi için gereken çağrı süresine bağlıdır. Amazon Redshift'te IMMUTABLE UDF türünün kullanılması, gerçekleştirilmiş görünüm için artımlı yenileme stratejisinden yararlanılarak maliyetlerin en aza indirilmesine de yardımcı olabilir.
- İzinler ve ağ erişimi - AWS Kimlik ve Erişim Yönetimi Amazon Redshift UDF için kullanılan (IAM) rolünün Lambda işlevini çağırma izinleri olması gerekir ve Lambda işlevini, harici bağımlılıklarını çağırma erişimine sahip olacak şekilde dağıtmanız gerekir (örneğin, onu bir VPC'de dağıtmanız gerekebilir). şema kaydı gibi özel kaynaklara erişim).
- İzleme – Seri durumdan çıkarma, şema kayıt defterine bağlantı ve veri işlemedeki hataları belirlemek için Lambda işlevi günlük kaydını ve ölçümlerini kullanın. UDF Lambda işlevinin izlenmesine ilişkin ayrıntılar için bkz. Metrikleri günlüklere gömme ve Lambda işlevlerini izleme ve sorun giderme.
Sonuç
Bu yazıda, akış kullanım senaryosu için farklı veri formatlarını ve besleme yöntemlerini inceledik. JSON olmayan veri formatlarını işlemeye yönelik stratejileri keşfederek, gerçekleştirilmiş görünümleri kullanarak bu formatları neredeyse gerçek zamanlı olarak sorunsuz bir şekilde almak, işlemek ve analiz etmek için Amazon Redshift akışının kullanımını inceledik.
Ayrıca, akış başına şema, yerleşik şema, varsayılan şema ve yerleşik şema kimliği yaklaşımları arasında gezinerek bunların yararlarını ve dikkate alınması gereken hususları vurguladık. JSON olmayan formatlar ile Amazon Redshift arasındaki boşluğu kapatmak amacıyla veri ayrıştırma ve dönüştürmeye yönelik Lambda UDF'lerin oluşturulmasını araştırdık. Bu yaklaşım, çeşitli veri akışlarının daha sonraki analizler için Amazon Redshift'e entegre edilmesine yönelik kapsamlı bir araç sunar.
Sürekli gelişen veri formatları ve analiz ortamında gezinirken, bu keşfin veri akışlarınızdan anlamlı bilgiler elde etmek için değerli bir rehberlik sağlayacağını umuyoruz. Yorumlar bölümünde her türlü düşünceyi veya soruyu memnuniyetle karşılıyoruz.
Yazarlar Hakkında
 M Mehrtens Kariyerleri boyunca dağıtık sistem mühendisliği alanında Yazılım Mühendisi, Mimar ve Veri Mühendisi olarak çalışmıştır. Geçmişte M, terabaytlarca akış verisini düşük gecikmeyle işlemek, kurumsal Makine Öğrenimi işlem hatlarını çalıştırmak ve çeşitli veri araç setleri ve yazılım yığınlarıyla verileri ekipler arasında sorunsuz bir şekilde paylaşmak için sistemler oluşturmak için sistemleri desteklemiş ve oluşturmuştur. AWS'de ABD Federal Finans müşterilerini destekleyen Kıdemli Çözüm Mimarıdırlar.
M Mehrtens Kariyerleri boyunca dağıtık sistem mühendisliği alanında Yazılım Mühendisi, Mimar ve Veri Mühendisi olarak çalışmıştır. Geçmişte M, terabaytlarca akış verisini düşük gecikmeyle işlemek, kurumsal Makine Öğrenimi işlem hatlarını çalıştırmak ve çeşitli veri araç setleri ve yazılım yığınlarıyla verileri ekipler arasında sorunsuz bir şekilde paylaşmak için sistemler oluşturmak için sistemleri desteklemiş ve oluşturmuştur. AWS'de ABD Federal Finans müşterilerini destekleyen Kıdemli Çözüm Mimarıdırlar.
 Sindhu Ahuthan AWS'de Federal Financials'ta Kıdemli Çözüm Mimarıdır. AWS Glue, Amazon EMR, Amazon Kinesis ve diğer hizmetleri kullanan analiz çözümlerine ilişkin mimari rehberlik sağlamak için müşterilerle birlikte çalışıyor. İş dışında Kendin Yap çalışmalarını, uzun yürüyüşlere çıkmayı ve yoga yapmayı seviyor.
Sindhu Ahuthan AWS'de Federal Financials'ta Kıdemli Çözüm Mimarıdır. AWS Glue, Amazon EMR, Amazon Kinesis ve diğer hizmetleri kullanan analiz çözümlerine ilişkin mimari rehberlik sağlamak için müşterilerle birlikte çalışıyor. İş dışında Kendin Yap çalışmalarını, uzun yürüyüşlere çıkmayı ve yoga yapmayı seviyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/non-json-ingestion-using-amazon-kinesis-data-streams-amazon-msk-and-amazon-redshift-streaming-ingestion/

