Günümüzün oldukça rekabetçi pazarında, makine öğrenimi (ML) modellerini kullanarak veri analitiği yapmak kuruluşlar için bir zorunluluk haline geldi. Verilerinin değerini ortaya çıkarmalarına, eğilimleri, kalıpları ve tahminleri belirlemelerine ve kendilerini rakiplerinden farklılaştırmalarına olanak tanır. Örneğin, sağlık sektöründe makine öğrenimi güdümlü analitik teşhis yardımı ve kişiselleştirilmiş tıp için kullanılabilirken, sağlık sigortasında kestirimci bakım yönetimi için kullanılabilir.
Ancak, sağlık hizmetleri veya sağlık sigortası gibi potansiyel sağlık verilerinin bulunduğu sektörlerdeki kuruluşlar ve kullanıcılar, kişilerin mahremiyetini korumaya öncelik vermeli ve düzenlemelere uymalıdır. Ayrıca, artan sayıda kullanım durumu için makine öğrenimi güdümlü analitiği kullanma konusunda zorluklarla karşılaşıyorlar. Bu zorluklar arasında sınırlı sayıda veri bilimi uzmanı, makine öğreniminin karmaşıklığı ve sınırlı Korunan Sağlık Bilgileri (PHI) ve altyapı kapasitesi nedeniyle düşük veri hacmi yer alır.
Sağlık, klinik ve yaşam bilimlerindeki kuruluşlar, veri analitiği için makine öğrenimi kullanma konusunda çeşitli zorluklarla karşılaşıyor:
- Düşük veri hacmi – Özel, korunan ve hassas sağlık bilgileri üzerindeki kısıtlamalar nedeniyle, kullanılabilir verilerin hacmi genellikle sınırlıdır ve bu da makine öğrenimi modellerinin doğruluğunu azaltır
- Sınırlı yetenek – Makine öğrenimi yeteneğini işe almak yeterince zordur, ancak yalnızca makine öğrenimi deneyimine değil, aynı zamanda derin tıbbi bilgiye sahip yetenekleri işe almak daha da zordur
- Altyapı yönetimi – Makine öğrenimi için özel altyapı sağlamak zor ve zaman alan bir iştir ve şirketler karmaşık teknik altyapıyı yönetmek yerine temel yetkinliklerine odaklanmayı tercih eder.
- Çok modlu sorunların tahmini – İnme gibi çok yönlü tıbbi olayların olasılığını tahmin ederken, tıbbi geçmiş, yaşam tarzı ve demografik bilgiler gibi farklı faktörler birleştirilmelidir.
Olası bir senaryo, tıbbi vakaları araştıran ve araştıran 30 klinik dışı hekimden oluşan bir ekiple bir sağlık teknolojisi şirketi olmanızdır. Bu ekip, sağlık hizmetleri alanında bilgi ve sezgiye sahip ancak modeller oluşturmak ve tahminler oluşturmak için makine öğrenimi becerilerine sahip değil. Bu klinisyenlerin "Sağlık düzenlemelerine uygun olarak ve mahremiyetten ödün vermeden faydalı verilere nasıl erişebilirim?" Ve SysOps çalışanlarının yönetmesi gereken sunucu sayısını artırmadan bunu nasıl yapabilirsiniz?
Bu gönderi, tüm bu sorunları aynı anda tek bir çözümde ele alıyor. İlk olarak, verileri otomatik olarak anonimleştirir. Amazon Sağlık Gölü. Ardından, bu verileri sunucusuz bileşenlerle ve kodsuz self servis çözümlerle kullanır. Amazon SageMaker Tuval ML modelleme karmaşıklığını ortadan kaldırmak ve temeldeki altyapıyı soyutlamak için.
Modern bir veri stratejisi, verileri yönetmek, bunlara erişmek, analiz etmek ve veriler üzerinde işlem yapmak için kapsamlı bir plan sunar. AWS, tüm iş yükleri, tüm veri türleri ve istenen tüm iş sonuçları için uçtan uca veri yolculuğunun tamamı için en eksiksiz hizmet setini sağlar.
Çözüme genel bakış
Bu gönderi, kuruluşların Amazon HealthLake'teki hassas verileri anonimleştirerek ve SageMaker Canvas'ın kullanımına sunarak, daha fazla paydaşın felç tahmini gibi çok modlu sorunlar için tahminler oluşturabilen makine öğrenimi modellerini makine öğrenimi kodu yazmadan kullanma yetkisi verebileceğini gösteriyor. hassas verilere erişim. Ve bunu olabildiğince ölçeklenebilir ve self servise uygun hale getirmek için bu anonimleştirmeyi otomatikleştirmek istiyoruz. Otomatikleştirme, uyumluluk gereksinimlerinizi karşılamak için anonimleştirme mantığını yinelemenize olanak tanır ve popülasyonunuzun sağlık verileri değiştikçe işlem hattını yeniden çalıştırma yeteneği sağlar.
Bu çözümde kullanılan veri kümesi, Synthea™kapsamında bir Sentetik Hasta Nüfus Simülatörü ve açık kaynaklı bir projedir. Apache Lisansı 2.0.
İş akışı, bulut mühendisleri ve alan uzmanları arasında bir el değiştirmeyi içerir. İlki boru hattını dağıtabilir. İkincisi, ardışık düzenin verileri doğru bir şekilde anonimleştirdiğini doğrulayabilir ve ardından kodsuz tahminler oluşturabilir. Gönderinin sonunda, anonimleştirmeyi doğrulamak için ek hizmetlere bakacağız.
Çözümde yer alan üst düzey adımlar aşağıdaki gibidir:
- kullanım AWS Basamak İşlevleri sağlık verileri anonimleştirme işlem hattını düzenlemek için.
- kullanım Amazon Atina aşağıdakiler için sorgular:
- Hassas olmayan yapılandırılmış verileri Amazon HealthLake'ten çıkarın.
- Yapılandırılmamış bloblardan hassas olmayan verileri ayıklamak için Amazon HealthLake'te doğal dil işlemeyi (NLP) kullanın.
- Şununla tek sıcak kodlama gerçekleştirin: Amazon SageMaker Veri Düzenleyicisi.
- Analitik ve tahminler için SageMaker Canvas'ı kullanın.
Aşağıdaki şemada çözüm mimarisi gösterilmektedir.
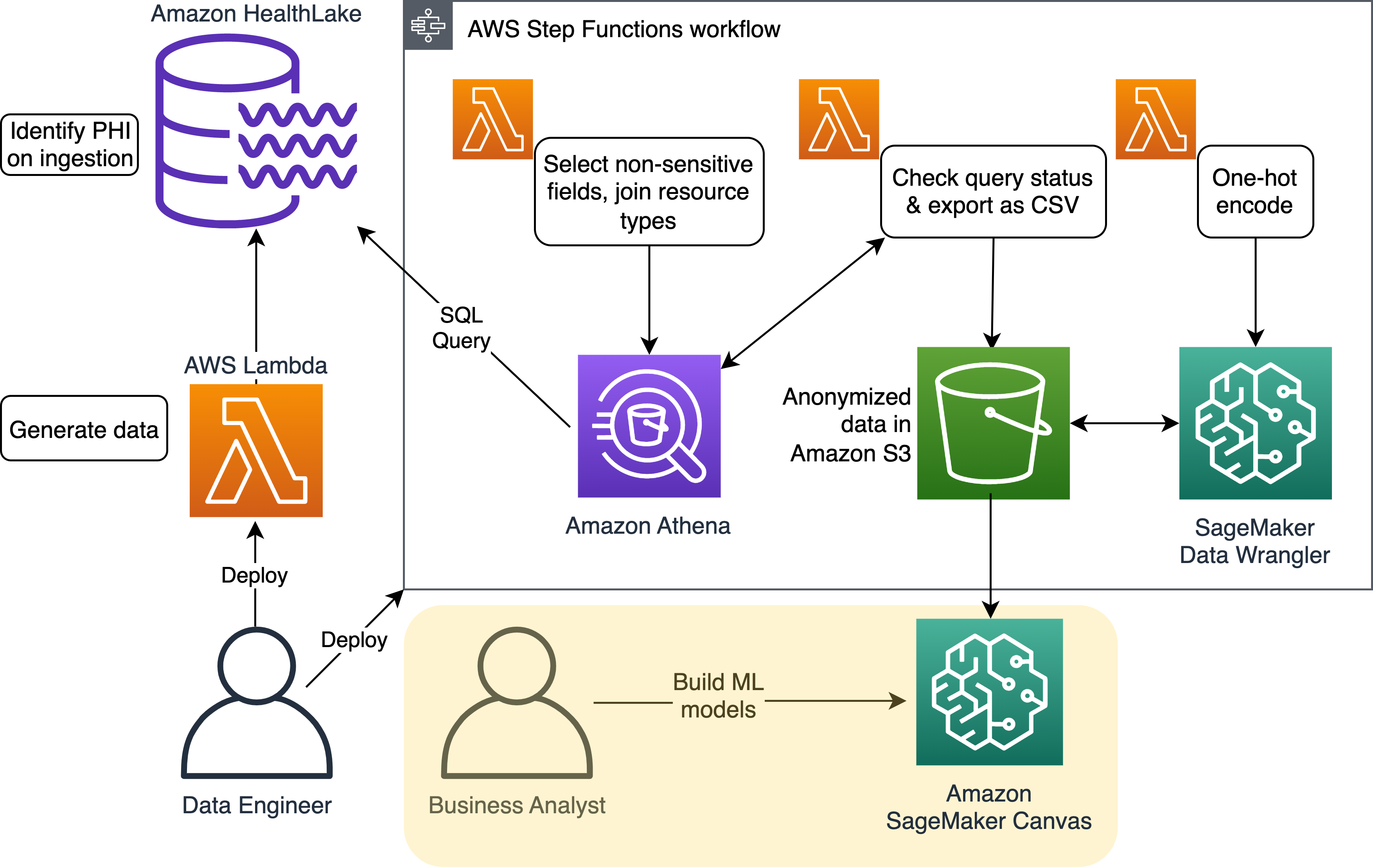
Verileri hazırlayın
İlk olarak, Synthea™ kullanarak hayali bir hasta popülasyonu oluşturuyoruz ve bu verileri yeni oluşturulmuş bir Amazon HealthLake veri deposuna aktarıyoruz. Sonuç, bir sağlık teknolojisi şirketinin bu gönderide açıklanan boru hattını ve çözümü çalıştırabileceği başlangıç noktasının bir simülasyonudur.
Amazon HealthLake verileri aldığında, doktor notları gibi yapılandırılmamış verilerden hasta adları ve tıbbi durumlar gibi ayrı yapılandırılmış alanlara otomatik olarak anlam çıkarır. Bunu yapılandırılmamış veriler üzerinde gerçekleştirmek için DocumentReference FHIR kaynakları, Amazon HealthLake şeffaf bir şekilde tetikler Amazon Medikalvarlıkların, ontolojilerin ve bunların ilişkilerinin ayıklanıp kayıtların uzantı segmentinde gizli veriler olarak Amazon HealthLake'e eklendiği yer.
We Adım İşlevlerini kullanabilir verilerin toplanmasını ve hazırlanmasını kolaylaştırmak için. İş akışının tamamı, tüm hatalar veya istisnalar vurgulanarak tek bir yerde görülebilir ve tekrarlanabilir, denetlenebilir ve genişletilebilir bir süreç sağlar.
Athena'yı kullanarak verileri sorgulayın
Athena SQL sorgularını doğrudan Amazon HealthLake üzerinde çalıştırarak, yalnızca kişisel olarak tanımlanmayan alanları seçebiliyoruz; örneğin, isim ve hasta kimliğinin seçilmemesi ve doğum tarihinin doğum yılına indirilmesi. Amazon HealthLake'i kullanarak, yapılandırılmamış verilerimiz (içindeki metin alanı) DocumentReference) otomatik olarak, yapılandırılmamış verilerde PHI'yi maskelemek için kullanabileceğimiz bir algılanan PHI listesiyle birlikte gelir. Ayrıca, oluşturulan Amazon HealthLake tabloları ile entegre olduğundan AWS Göl Oluşumu, saha düzeyine kadar kimlerin erişebileceğini kontrol edebilirsiniz.
Aşağıdakiler, sentetik bir ortamda bulunan yapılandırılmamış veri örneğinden bir alıntıdır. DocumentReference kayıt:
# Mevcut hastalık Tarihi
Marki
45 yaşında. Hastanın hipertansiyon, viral sinüzit (hastalık), kronik obstrüktif bronşit (hastalık), stres (bulma), sosyal izolasyon (bulma) öyküsü vardır.
# Sosyal Tarih
Hasta evli. Hasta 16 yaşında sigarayı bıraktı.
Hasta şu anda UnitedHealthcare'e sahiptir.
# alerjiler
Bilinen Alerjisi Yok.
# İlaçlar
albuterol 5 mg/ml inhalasyon solüsyonu; amlodipin 2.5 mg oral tablet; 60 aktif flutikazon propiyonat 0.25 mg/aktif / salmeterol 0.05 mg/aktif kuru toz inhaler
# Değerlendirme ve Plan
Hasta inme ile başvuruyor.
Amazon HeathLake NLP'nin, aynı hasta kimliğine sahip ve "inme" görüntüleyen durum kaydını sorgulayarak bunu "inme" koşulunu içerdiği şeklinde yorumladığını görebiliriz. Ve DocumentReference içinde bulunan varlıkların otomatik olarak etiketlenmesi gerçeğinden faydalanabiliriz. SYSTEM_GENERATED:
Sonuç aşağıdaki gibidir:
Amazon HealthLake'te toplanan veriler, tüm notları yorumlamak yerine G46.4 gibi belirli durum kodlarını seçebilme özelliği sayesinde artık analitik için etkili bir şekilde kullanılabilir. Bu veriler daha sonra bir CSV dosyası olarak depolanır. Amazon Basit Depolama Hizmeti (Amazon S3).
Not: Bu çözümü uygularken, lütfen takip edin talimatlar HealthLake veri deponuza veri almadan önce bir destek vakası aracılığıyla HealthLake'in entegre NLP özelliğini açma.
Tek seferlik kodlama gerçekleştirin
Verilerin tüm potansiyelini ortaya çıkarmak için, koşul sütunu gibi kategorik sütunları sayısal verilere dönüştürmek için tek sıcak kodlama adı verilen bir teknik kullanıyoruz.
Kategorik verilerle çalışmanın zorluklarından biri, birçok makine öğrenimi algoritmasında kullanılmaya uygun olmamasıdır. Bunun üstesinden gelmek için, bir sütundaki her kategoriyi ayrı bir ikili sütuna dönüştüren ve verileri daha geniş bir algoritma yelpazesi için uygun hale getiren one-hot kodlama kullanıyoruz. Bu, Data Wrangler kullanılarak yapılır, yerleşik işlevlere sahip olan bunun için:
SageMaker Data Wrangler'da tek geçişli kodlama için yerleşik işlev
One-hot kodlama, kategorik sütundaki her benzersiz değeri ikili gösterime dönüştürerek her benzersiz değer için yeni bir sütun kümesi oluşturur. Aşağıdaki örnekte, koşul sütunu, her biri benzersiz bir değeri temsil eden altı sütuna dönüştürülmüştür. Tek sıcak kodlamadan sonra, aynı satırlar ikili bir gösterime dönüşecektir.

Artık kodlanan verilerle, analitik ve tahminler için SageMaker Canvas'ı kullanmaya geçebiliriz.
Analitik ve tahminler için SageMaker Canvas'ı kullanın
Nihai CSV dosyası daha sonra, sağlık hizmeti analistlerinin (iş kullanıcıları) felç tahmini gibi çok değişkenli problemler için makine öğreniminde uzmanlığa ihtiyaç duymadan tahminler oluşturmak için kullanabilecekleri SageMaker Canvas için girdi haline gelir. Veriler herhangi bir hassas bilgi içermediğinden özel izinler gerekmez.
Vuruş tahmini örneğinde, SageMaker Canvas, aşağıdaki ekran görüntüsünde gösterildiği gibi, gelişmiş makine öğrenimi modellerini kullanarak %99.829'luk bir doğruluk oranına ulaşmayı başardı.
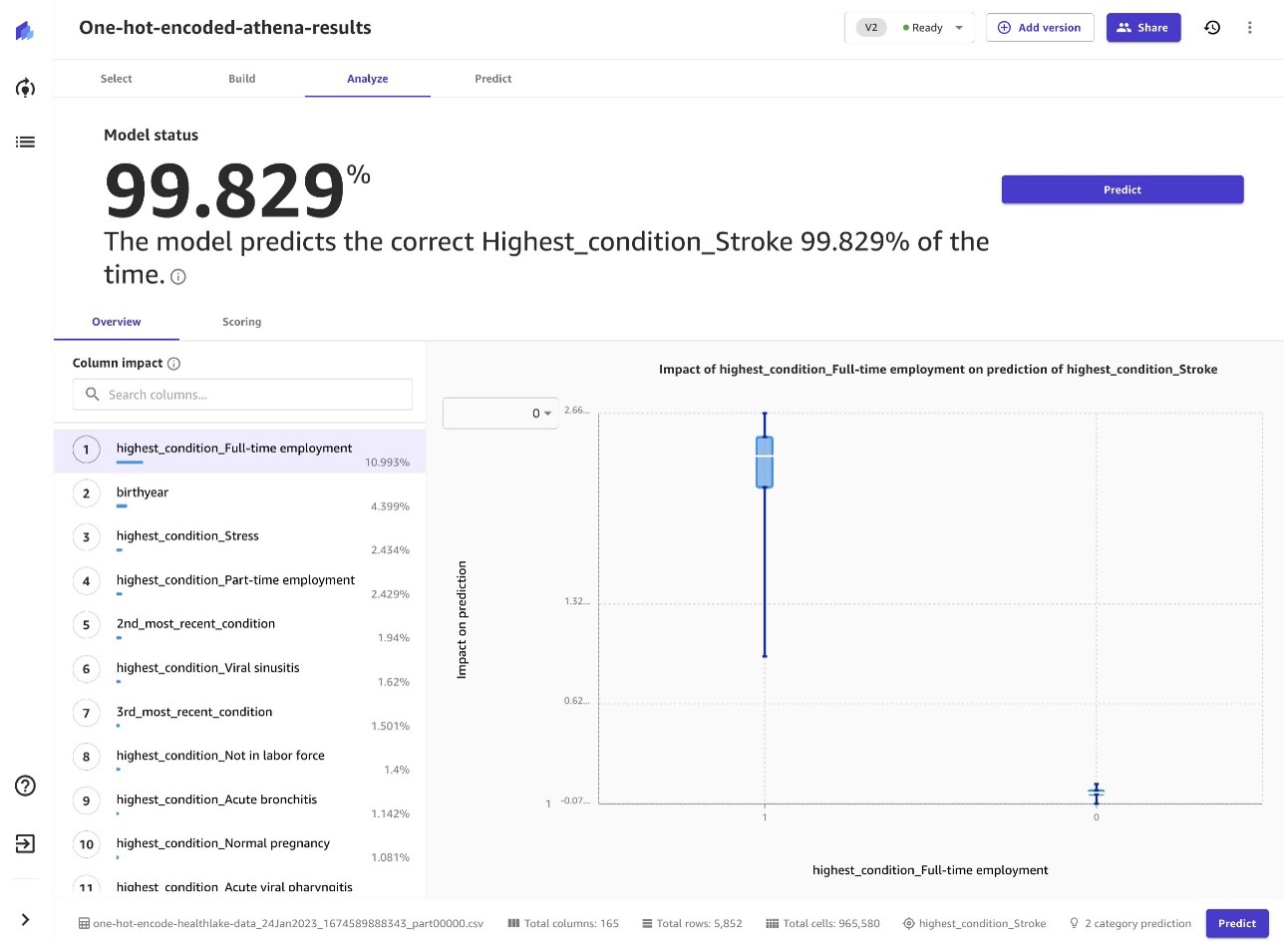
Bir sonraki ekran görüntüsünde, modelin tahminine göre bu hastanın felç geçirmeme ihtimalinin %53 olduğunu görebilirsiniz.
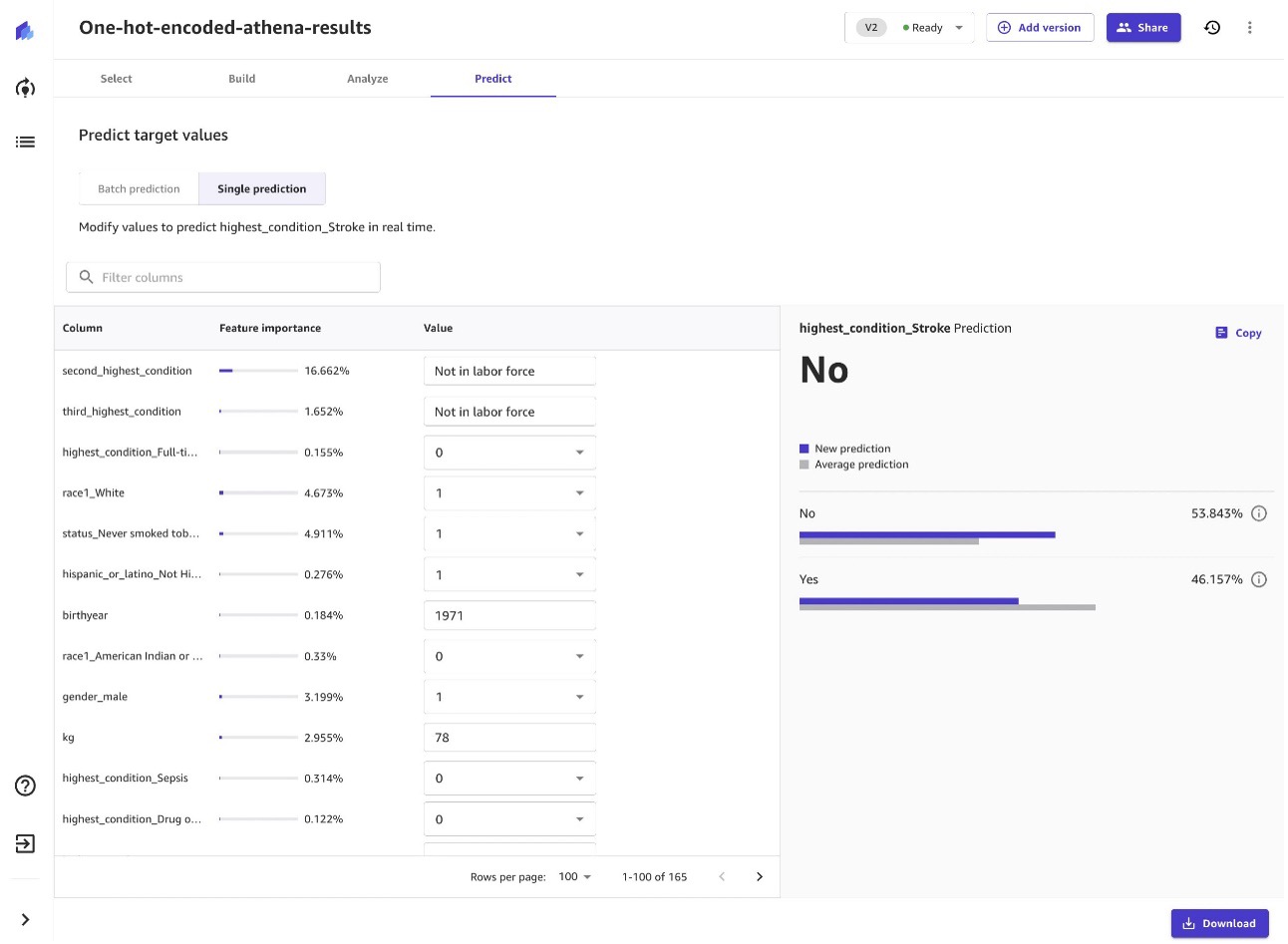
Bir e-tabloda kural tabanlı mantık kullanarak bu tahmini oluşturabileceğinizi varsayabilirsiniz. Ancak bu kurallar size özelliğin önemini söylüyor mu? Örneğin, tahminin %4.9'unun hiç tütün içip içmediğine dayandığını söylüyor mu? Peki ya sigara içme durumu ve tansiyon gibi mevcut sütunlara ek olarak 900 sütun (özellikler) daha eklerseniz? Tüm bu boyutların kombinasyonlarını korumak ve yönetmek için yine de bir elektronik tablo kullanabilir misiniz? Gerçek hayattaki senaryolar birçok kombinasyona yol açar ve buradaki zorluk, bunu doğru düzeyde çabayla büyük ölçekte yönetmektir.
Artık bu modele sahip olduğumuza göre, ne olursa olsun soruları sorarak toplu veya tekil tahminler yapmaya başlayabiliriz. Örneğin, bu kişi tüm değişkenleri aynı tutarsa, ancak tıbbi sistemle önceki iki karşılaşması itibarıyla şu şekilde sınıflandırılırsa ne olur? Tam zamanlı iş yerine iş gücünde değil?
Modelimize ve onu Synthea'dan beslediğimiz sentetik verilere göre, kişinin felç geçirme riski %62'dir.
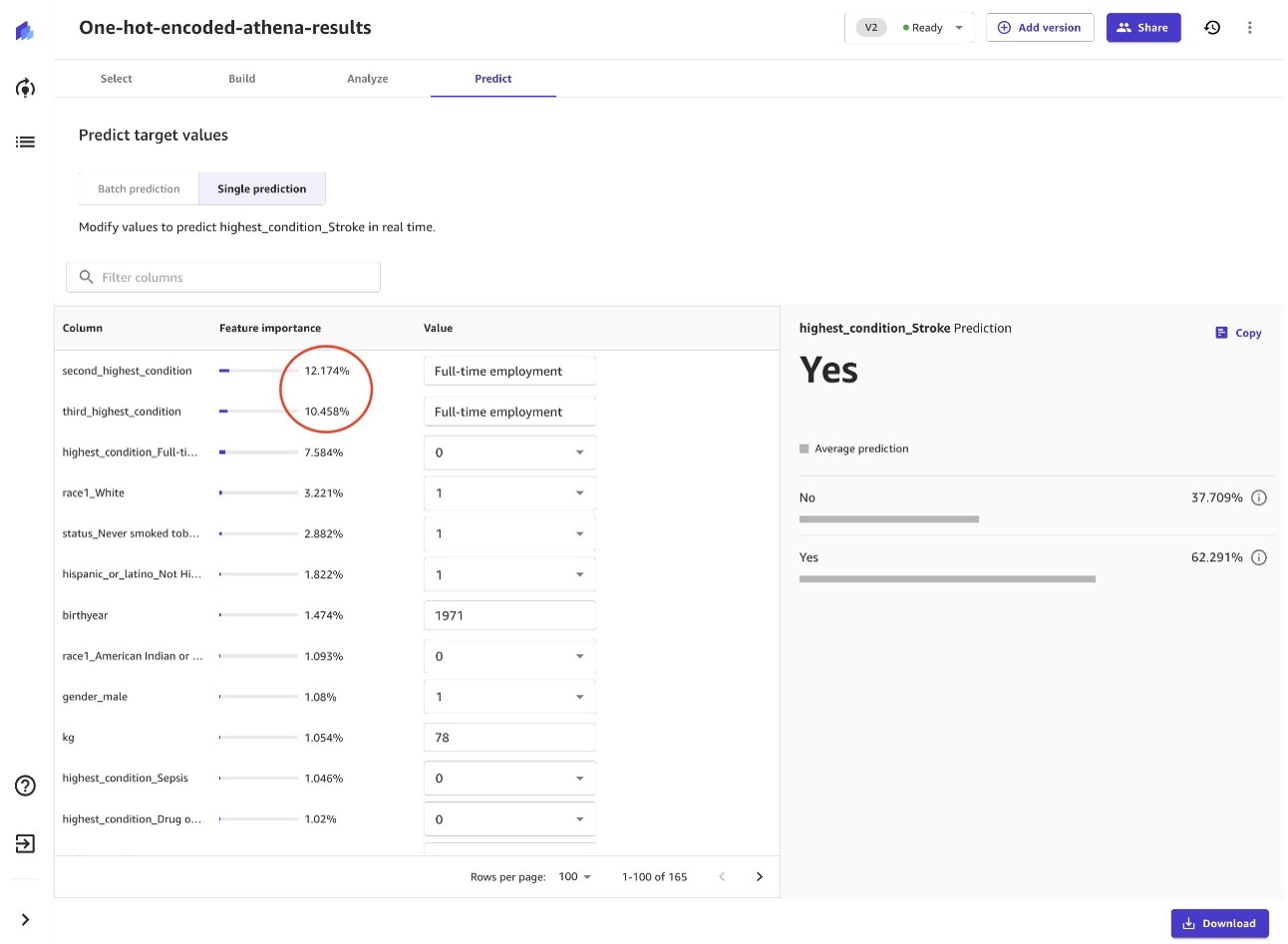
Yuvarlak içine alınmış %12 ve %10 özelliklerinden de anlayacağımız gibi, tıbbi sistemle en son karşılaştıkları durumların önemi, tam zamanlı çalışıp çalışmamalarının inme riskleri üzerinde büyük etkisi vardır. Bu modelin bulgularının ötesinde, benzer bir bağlantı olduğunu gösteren araştırmalar var:
Bu çalışmalar büyük nüfusa dayalı örneklemler kullanmış ve diğer risk faktörleri için kontrol etmiştir, ancak bunların doğaları gereği gözlemsel olduklarını ve nedensellik oluşturmadıklarını not etmek önemlidir. Tam zamanlı istihdam ile inme riski arasındaki ilişkiyi tam olarak anlamak için daha fazla araştırmaya ihtiyaç vardır.
Geliştirmeler ve alternatif yöntemler
Uyumluluğu daha fazla doğrulamak için aşağıdaki hizmetleri kullanabiliriz: Amazon Macie'si, S3 kovasındaki CSV dosyalarını tarayacak ve herhangi bir hassas veri varsa bizi uyaracaktır. Bu, anonimleştirilmiş verilerin güven düzeyini artırmaya yardımcı olur.
Bu gönderide, SageMaker Canvas için girdi veri kaynağı olarak Amazon S3'ü kullandık. Ancak, doğrudan SageMaker Canvas'a veri aktarabiliriz. Amazon RedShift'i ve Snowflake—birçok müşteri tarafından verilerini ve popüler üçüncü taraf çözümlerini düzenlemek için kullanılan popüler kurumsal veri ambarı hizmetleri. Bu, özellikle diğer BI analitiği için kullanılan Snowflake veya Amazon Redshift'teki verileri olan müşteriler için önemlidir.
Çözümü düzenlemek için Adım İşlevlerini kullanarak çözüm daha genişletilebilir. Macie'yi çağırmak için ayrı bir tetikleyici yerine, PHI'yi iki kez kontrol etmesi için Macie'yi çağırmak üzere ardışık düzenin sonuna başka bir adım ekleyebilirsiniz. Veri ardışık düzeninizin kalitesini zaman içinde izlemek için kurallar eklemek isterseniz, aşağıdakiler için bir adım ekleyebilirsiniz: AWS Glue Veri Kalitesi.
Ve daha fazla ısmarlama entegrasyon eklemek isterseniz, Step Functions paralel olarak ihtiyaç duyduğunuz kadar çok veya az veriyi işlemek ve yalnızca kullandığınız kadar ödeme yapmak için ölçeklendirme yapmanızı sağlar. Paralelleştirme yönü, yüzlerce GB veriyi işlerken kullanışlıdır, çünkü tüm bunları tek bir işleve sıkıştırmak istemezsiniz. Bunun yerine, parçalayıp paralel olarak çalıştırmak istiyorsunuz, böylece tek bir kuyrukta işlenmesini beklemiyorsunuz. Bu, mağazadaki bir ödeme kuyruğuna benzer; tek bir kasiyere sahip olmak istemezsiniz.
Temizlemek
İleride oturum ücreti ödememek için SageMaker Canvas oturumunu kapatın.
Sonuç
Bu yazıda, inme gibi kritik sağlık sorunları için tahminlerin tıp uzmanları tarafından karmaşık makine öğrenimi modelleri kullanılarak ancak kodlamaya gerek olmadan yapılabileceğini gösterdik. Bu, özel alan bilgisi olan ancak makine öğrenimi deneyimi olmayan kişileri dahil ederek kaynak havuzunu büyük ölçüde artıracaktır. Ayrıca sunucusuz ve yönetilen hizmetleri kullanmak, mevcut BT çalışanlarının kullanılabilirlik, dayanıklılık ve ölçeklenebilirlik gibi altyapı zorluklarını daha az çabayla yönetmesine olanak tanır.
Bu gönderiyi, sağlık sektörünü daha iyi hasta bakımına yönlendirmenin anahtarı olan diğer karmaşık çok modlu tahminleri araştırmak için bir başlangıç noktası olarak kullanabilirsiniz. Çok yakında, mühendislerin bu gönderide sunduğumuz türden fikirleri daha hızlı bir şekilde hayata geçirmelerine yardımcı olacak bir GitHub depomuz olacak.
SageMaker Canvas'ın gücünü bugün deneyimleyin ve kullanıcı dostu bir grafik arayüzü kullanarak modellerinizi oluşturun. 2 aylık Ücretsiz Kullanım SageMaker Canvas'ın sunduğu. Başlamak için herhangi bir kodlama bilgisine ihtiyacınız yoktur ve modellerinizin nasıl performans gösterdiğini görmek için farklı seçenekleri deneyebilirsiniz.
Kaynaklar
SageMaker Canvas hakkında daha fazla bilgi edinmek için aşağıdakilere bakın:
SageMaker Canvas ile çözebileceğiniz diğer kullanım durumları hakkında daha fazla bilgi edinmek için aşağıdakilere göz atın:
Amazon HealthLake hakkında daha fazla bilgi edinmek için aşağıdakilere bakın:
Yazarlar Hakkında
 Yann Stoneman Boston, MA merkezli AWS'de bir Çözüm Mimarıdır ve AI/ML Teknik Alan Topluluğunun (TFC) bir üyesidir. Yann, lisans eğitimini The Juilliard School'da aldı. Yann, küresel işletmeler için iş yüklerini modernleştirmediği zamanlarda piyano çalıyor, React ve Python'da tamircilik yapıyor ve bulut yolculuğu hakkında düzenli olarak YouTube'lar açıyor.
Yann Stoneman Boston, MA merkezli AWS'de bir Çözüm Mimarıdır ve AI/ML Teknik Alan Topluluğunun (TFC) bir üyesidir. Yann, lisans eğitimini The Juilliard School'da aldı. Yann, küresel işletmeler için iş yüklerini modernleştirmediği zamanlarda piyano çalıyor, React ve Python'da tamircilik yapıyor ve bulut yolculuğu hakkında düzenli olarak YouTube'lar açıyor.
 Ramesh Dwarakanath Boston, MA merkezli AWS'de Baş Çözüm Mimarıdır. Bulut yolculuklarında Kuzeydoğu bölgesindeki Enterprises ile birlikte çalışıyor. İlgi alanları Konteynerler ve DevOps'tur. Boş zamanlarında, Ramesh tenis ve raketboldan hoşlanır.
Ramesh Dwarakanath Boston, MA merkezli AWS'de Baş Çözüm Mimarıdır. Bulut yolculuklarında Kuzeydoğu bölgesindeki Enterprises ile birlikte çalışıyor. İlgi alanları Konteynerler ve DevOps'tur. Boş zamanlarında, Ramesh tenis ve raketboldan hoşlanır.
 Bakha Nurjanov AWS'de Birlikte Çalışabilirlik Çözümleri Mimarıdır ve AWS'de Sağlık Hizmetleri ve Yaşam Bilimleri teknik alan topluluğunun bir üyesidir. Bakha, Bilgisayar Bilimleri alanında Master derecesini Washington Üniversitesi'nden aldı ve boş zamanlarında Bakha ailesiyle vakit geçirmekten, kitap okumaktan, bisiklete binmekten ve yeni yerler keşfetmekten hoşlanıyor.
Bakha Nurjanov AWS'de Birlikte Çalışabilirlik Çözümleri Mimarıdır ve AWS'de Sağlık Hizmetleri ve Yaşam Bilimleri teknik alan topluluğunun bir üyesidir. Bakha, Bilgisayar Bilimleri alanında Master derecesini Washington Üniversitesi'nden aldı ve boş zamanlarında Bakha ailesiyle vakit geçirmekten, kitap okumaktan, bisiklete binmekten ve yeni yerler keşfetmekten hoşlanıyor.
 Scott Schreckengaust biyomedikal mühendisliği diplomasına sahiptir ve kariyerinin başlangıcından beri kürsüde bilim adamlarıyla birlikte cihazlar icat etmektedir. Sağlık ve Yaşam Bilimleri alanındaki çok uluslu büyük kuruluşlara yeni başlayan şirketlerde onlarca yıllık deneyimiyle bilim, teknoloji ve mühendisliği seviyor. Scott, robotik sıvı işleyicileri, programlama araçlarını rahatça komut dosyası olarak yazabiliyor, yerleşik sistemleri kurumsal sistemlere entegre edebiliyor ve düzenleyici ortamlarda sıfırdan eksiksiz yazılım dağıtımları geliştirebiliyor. İnsanlara yardım etmenin yanı sıra, müşterinin bilimsel iş akışlarını ve sorunlarını ortaya çıkarma ve ardından bunları uygulanabilir çözümlere dönüştürme yolculuğunun tadını çıkararak inşa etme konusunda başarılıdır.
Scott Schreckengaust biyomedikal mühendisliği diplomasına sahiptir ve kariyerinin başlangıcından beri kürsüde bilim adamlarıyla birlikte cihazlar icat etmektedir. Sağlık ve Yaşam Bilimleri alanındaki çok uluslu büyük kuruluşlara yeni başlayan şirketlerde onlarca yıllık deneyimiyle bilim, teknoloji ve mühendisliği seviyor. Scott, robotik sıvı işleyicileri, programlama araçlarını rahatça komut dosyası olarak yazabiliyor, yerleşik sistemleri kurumsal sistemlere entegre edebiliyor ve düzenleyici ortamlarda sıfırdan eksiksiz yazılım dağıtımları geliştirebiliyor. İnsanlara yardım etmenin yanı sıra, müşterinin bilimsel iş akışlarını ve sorunlarını ortaya çıkarma ve ardından bunları uygulanabilir çözümlere dönüştürme yolculuğunun tadını çıkararak inşa etme konusunda başarılıdır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/extract-non-phi-data-from-amazon-healthlake-reduce-complexity-and-increase-cost-efficiency-with-amazon-athena-and-amazon-sagemaker-canvas/

