AWS re:Invent 2022'de, Amazon Athena, Apache Spark desteğini başlattı. Bu lansmanla, Amazon Atina iki açık kaynaklı sorgu motorunu destekler: Apache Spark ve Trino. Athena Spark, Athena konsolunda veya Athena API'leri aracılığıyla basitleştirilmiş bir dizüstü bilgisayar deneyimi kullanarak Apache Spark uygulamaları oluşturmanıza olanak tanır. Athena Spark not defterleri, Spark SQL ile çalışmanıza olanak sağlamak için PySpark ve not defteri büyülerini destekler. Etkileşimli uygulamalar için Athena Spark, bir saniyeden kısa sürede uygulama başlatma süresiyle daha az bekleme süresi harcamanıza ve daha üretken olmanıza olanak tanır. Athena sunucusuz ve tümüyle yönetilen olduğundan, iş yüklerinizi temeldeki altyapı konusunda endişelenmeden çalıştırabilirsiniz.
Modern uygulamalar büyük miktarlarda veriyi depolar. Amazon Basit Depolama Hizmeti (Amazon S3) veri gölleri, uygun maliyetli ve son derece dayanıklı depolama sağlar ve verileriniz hakkında öngörüler oluşturmak için veri gölünüzden analitik ve makine öğrenimi (ML) çalıştırmanıza olanak tanır. Bu iş yüklerini çalıştırmadan önce çoğu müşteri, verileri etkileşimli olarak ayıklamak, filtrelemek, birleştirmek ve karar verme, model eğitimi veya çıkarım için kullanılabilecek bir şekilde toplamak için SQL sorguları çalıştırır. Veri göllerinde SQL çalıştırmak hızlıdır ve Athena, güçlü bir optimize edici içeren optimize edilmiş, Trino ve Presto uyumlu bir API sağlar. Ayrıca finansal hizmetler, sağlık hizmetleri ve perakende gibi birçok sektördeki kuruluşlar, her boyuttaki verilere karşı hızlı analizler ve gelişmiş dönüşümler için optimize edilmiş, popüler bir açık kaynaklı, dağıtılmış işleme sistemi olan Apache Spark'ı benimsiyor. Athena'nın Apache Spark desteği sayesinde, uygulama öngörüleri oluşturmak veya modeller oluşturmak için hem Spark SQL'i hem de PySpark'ı tek bir not defterinde kullanabilirsiniz. Çalışmak istediğiniz nitelikleri ayıklamak, filtrelemek ve projelendirmek için Spark SQL ile başlayın. Daha sonra, regresyon testleri ve zaman serisi tahmini gibi daha karmaşık veri analizi gerçekleştirmek için Matplot, Seaborn ve Plotly'de veri görselleştirme de dahil olmak üzere zengin bir kitaplık ekosisteminden yararlanmanıza olanak tanıyan Apache Spark'ı Python ile birlikte kullanabilirsiniz.
Üç bölümlük serinin bu ilk gönderisinde size Athena not defterlerinde Spark SQL kullanmaya nasıl başlayacağınızı gösteriyoruz. Amazon S3 ve Amazon SXNUMX'te veritabanlarının ve tabloların sorgulanmasını gösteriyoruz. AWS Tutkal Athena'da Spark SQL kullanan Veri Kataloğu. Spark SQL'de kullanılan bazı yaygın ve gelişmiş SQL komutlarını ele alıyoruz ve kullanıcı tanımlı işlevlerle (UDF'ler) işlevselliğinizi genişletmek ve sorgulanan verileri görselleştirmek için Python'u nasıl kullanacağınızı gösteriyoruz. Bir sonraki gönderide Athena Spark'ı açık kaynaklı işlem tablosu formatlarıyla nasıl kullanacağınızı göstereceğiz. Üçüncü gönderide Amazon S3 dışındaki veri kaynaklarının Athena Spark kullanılarak analiz edilmesini ele alacağız.
Önkoşullar
Başlamak için aşağıdakilere ihtiyacınız olacak:
Bir IAM rolü aracılığıyla Athena Spark'ın verilerinize erişmesini sağlayın
Siz bu izlenecek yolda ilerledikçe yeni veritabanları ve tablolar oluşturuyoruz. Varsayılan olarak Athena Spark'ın bunu yapma izni yoktur. Bu erişimi sağlamak için aşağıdaki satır içi politikayı ekleyebilirsiniz. AWS Kimlik ve Erişim Yönetimi Bölgeyi ve hesap numaranızı sağlayan, çalışma grubuna eklenen (IAM) rolü. Daha fazla bilgi için bölüme bakın Bir kullanıcı veya rol (konsol) için satır içi politika yerleştirmek için in IAM kimlik izinleri ekleme (konsol).
Python kullanmadan SQL sorgularını doğrudan not defterinde çalıştırın
Athena Spark not defterlerini kullanırken PySpark kullanmaya gerek kalmadan doğrudan SQL sorguları çalıştırabiliyoruz. Bunu, bir not defterindeki hücrelerin davranışını değiştiren özel başlıklar olan hücre büyülerini kullanarak yapıyoruz. SQL için, tüm hücre içeriğini Athena Spark'ta çalıştırılacak bir SQL ifadesi olarak yorumlayacak %%sql büyüsünü ekleyebiliriz.
Artık çalışma grubumuzu ve not defterimizi oluşturduğumuza göre, keşfetmeye başlayalım. NOAA Küresel Yüzey Günün Özeti Dünyanın her yerindeki çeşitli konumlardan çevresel önlemler sağlayan veri kümesi. Bu gönderide kullanılan veri kümeleri, aşağıdaki Amazon S3 konumlarında barındırılan genel veri kümeleridir:
- 2020 yılı parke verileri -
s3://athena-examples-us-east-1/athenasparkblog/noaa-gsod-pds/parquet/2020/ - 2021 yılı parke verileri -
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2021/ - 2022 yılına ait parke verileri -
s3://athena-examples-us-east-1/athenasparksqlblog/noaa_pq/year=2022/
Bu verileri kullanmak için Athena'nın meta deposu görevi gören ve Amazon S3'teki veri kümelerinin konumunu gösteren harici tablolar oluşturmamıza olanak tanıyan bir AWS Glue Data Catalog veritabanına ihtiyacımız var. Öncelikle Data Catalog’da Athena ve Spark kullanarak bir veritabanı oluşturuyoruz.
Bir veritabanı oluşturun
Kullanarak not defterinizde aşağıdaki SQL'i çalıştırın %%sql büyü:
Aşağıdaki çıktıyı alırsınız: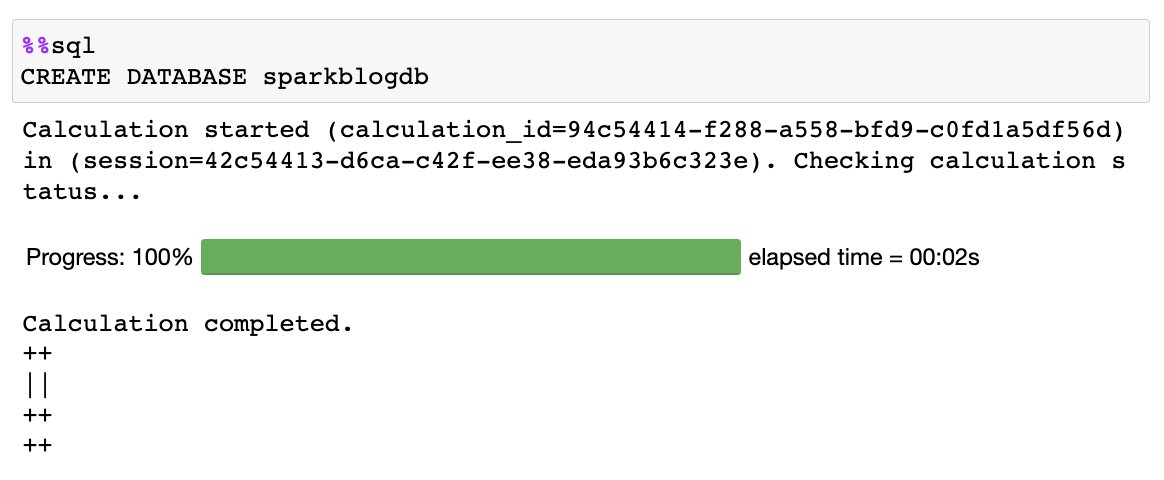
Tablo oluştur
Artık Veri Kataloğunda bir veritabanı oluşturduğumuza göre Amazon S3'te depolanan veri kümemize işaret eden bölümlenmiş bir tablo oluşturabiliriz:
Bu veri kümesi yıllara göre bölümlendirilmiştir; bu, veri dosyalarını her yıl için ayrı ayrı sakladığımız anlamına gelir; bu da yönetimi basitleştirir ve bir sorguda belirli S3 konumlarını hedefleyebildiğimiz için performansı artırır. Veri Kataloğu tabloyu biliyor ve şimdi kaç bölüme sahip olduğumuzu otomatik olarak hesaplamasına izin vereceğiz. MSCK Yarar:
Önceki ifade tamamlandığında, tabloda bulunan yıllık bölümleri listelemek için aşağıdaki komutu çalıştırabilirsiniz:

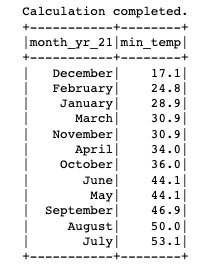
Artık tabloyu oluşturduğumuza ve bölümleri eklediğimize göre, ortam için kaydedilen minimum sıcaklığı bulmak için bir sorgu çalıştıralım. 'SEATTLE TACOMA AIRPORT, WA US' Konumu:

Athena Spark'tan hesaplar arası Veri Kataloğu sorgulama
Athena, hesaplar arası AWS Glue Veri Kataloglarına erişimi destekler; bu, yetkili bir AWS hesabındaki Veri Kataloğunu sorgulamak için Athena Spark'ta Spark SQL kullanmanıza olanak tanır.
Hesaplar arası Data Catalog erişim modeli genellikle veri ağı Bir veri üreticisinin bir kataloğu ve verileri tüketici hesaplarıyla paylaşmak istediği mimari. Tüketici hesapları daha sonra paylaşılan veriler üzerinde veri analizi ve keşifler gerçekleştirebilir. Bu, kullanmamıza gerek olmayan basitleştirilmiş bir modeldir. AWS Göl Oluşumu bilgi paylaşımı. Aşağıdaki şemada, bir üretici ile bir tüketici hesabı arasında kurulumun nasıl çalıştığına dair genel bir bakış sunulmaktadır; bu, birden fazla üretici ve tüketici hesabına genişletilebilir.
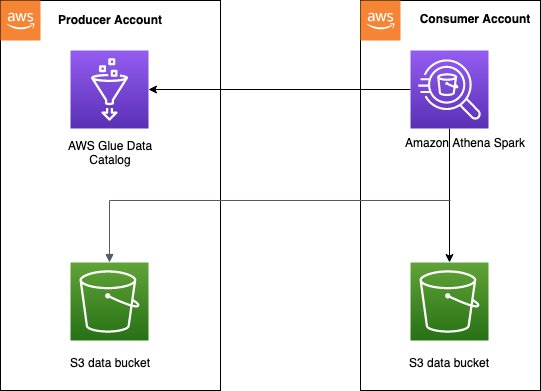
Hesaplar arası erişimi etkinleştirmek için üretici hesabının Veri Kataloğunda doğru erişim politikalarını ayarlamanız gerekir. Özellikle, Athena'da Spark hesaplamalarını çalıştırmak için kullanılan tüketici hesabının IAM rolünün, hesaplar arası Veri Kataloğu'na ve Amazon S3'teki verilere erişebildiğinden emin olmalısınız. Kurulum talimatları için bkz. Spark için Athena'da hesaplar arası AWS Glue erişimini yapılandırma.
Sorgulamanın tek bir üretici hesabından mı yoksa birden fazla üretici hesabından mı yapıldığına bağlı olarak, tüketici hesabının Athena Spark'ın hesaplar arası Veri Kataloğuna erişmesinin iki yolu vardır.
Tek bir üretici tablosunu sorgulama
Yalnızca tek bir üreticinin AWS hesabındaki verileri sorguluyorsanız Athena Spark'a veritabanı nesnelerini çözümlemek için yalnızca o hesabın kataloğunu kullanmasını söyleyebilirsiniz. Bu seçeneği kullanırken, AWS hesap kimliğini oturum düzeyinde yapılandırdığınız için SQL'i değiştirmeniz gerekmez. Bu yöntemi etkinleştirmek için oturumu düzenleyin ve özelliği ayarlayın "spark.hadoop.hive.metastore.glue.catalogid": "999999999999" aşağıdaki adımları kullanarak:
- Not defteri düzenleyicisinde, oturum menü seç Oturumu düzenle.
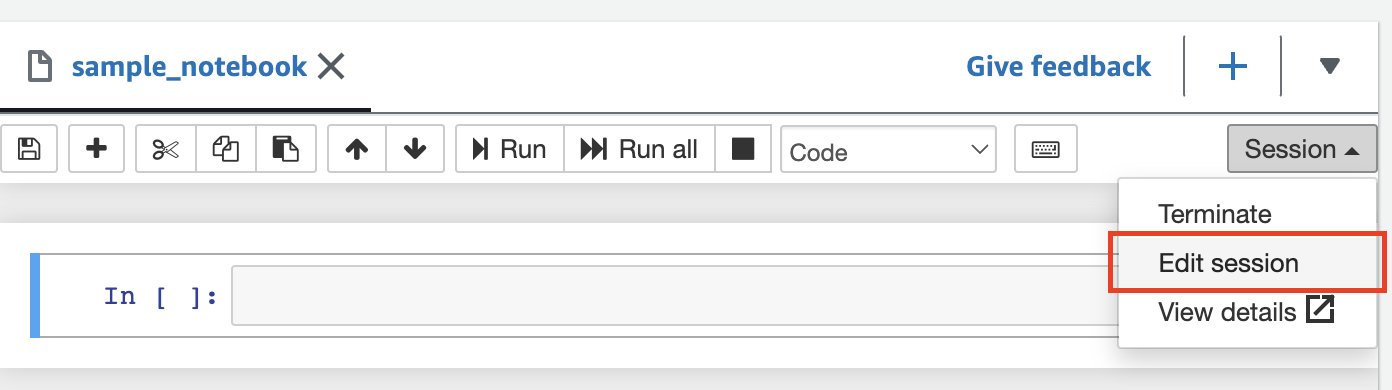
- Klinik JSON'da düzenle.
- Aşağıdaki özelliği ekleyin ve seçin İndirim:
{"spark.hadoop.hive.metastore.glue.catalogid": "999999999999"}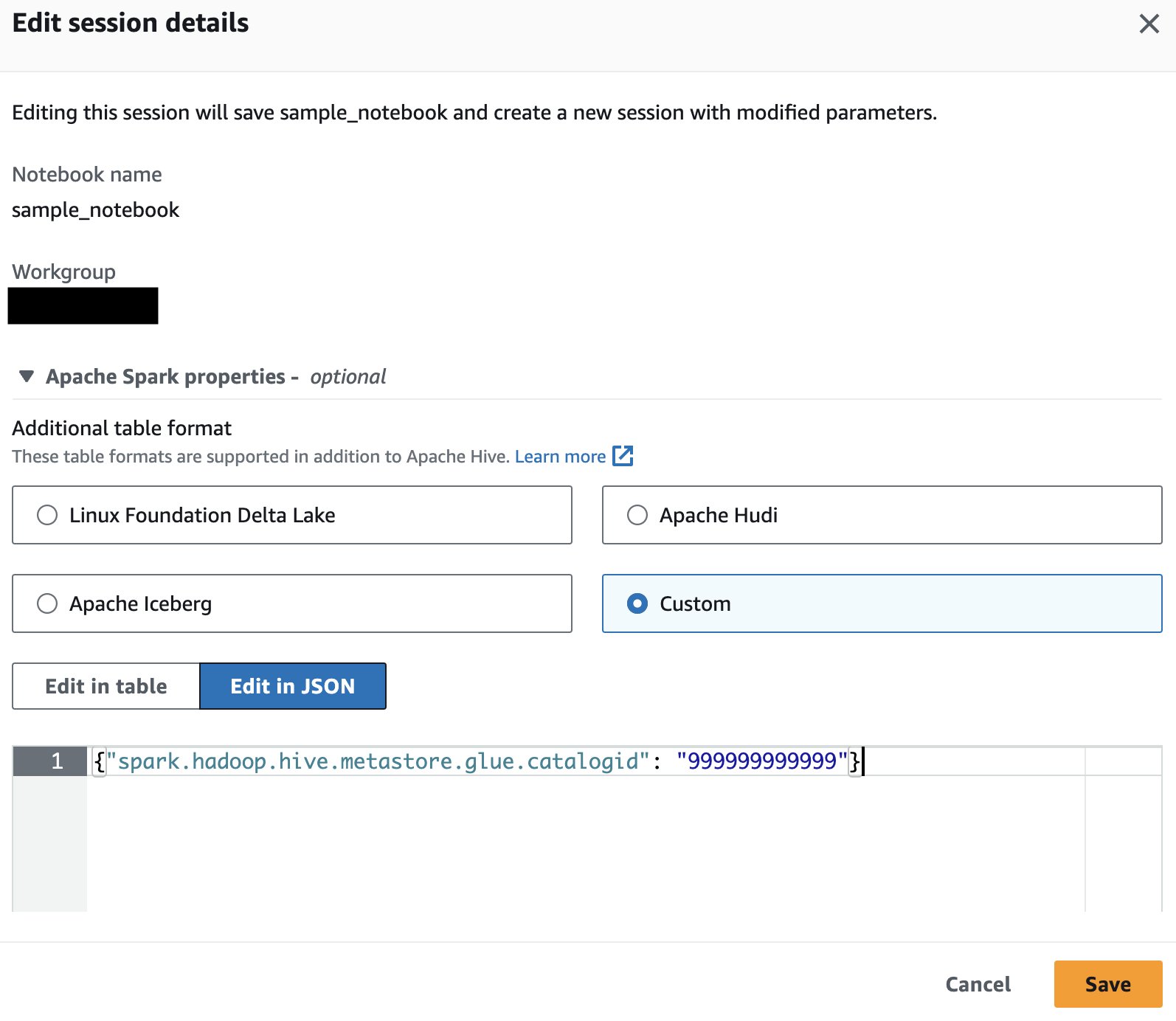 Bu, güncellenen parametrelerle yeni bir oturum başlatacaktır.
Bu, güncellenen parametrelerle yeni bir oturum başlatacaktır. - Üretici hesabının kataloğundaki tabloları sorgulamak için Spark'ta aşağıdaki SQL deyimini çalıştırın:
Birden çok üretici tablosunu sorgulayın
Alternatif olarak, her veritabanı adına üretici AWS hesap kimliğini ekleyebilirsiniz; bu, farklı sahiplerin Veri Kataloglarını sorgulayacaksanız yararlı olur. Bu yöntemi etkinleştirmek için özelliği ayarlayın {"spark.hadoop.aws.glue.catalog.separator": "/"} oturumu başlatırken veya düzenlerken (önceki bölümle aynı adımları kullanarak). Daha sonra, kaynak Veri Kataloğunun AWS hesap kimliğini veritabanı adının bir parçası olarak eklersiniz:
Üretici AWS hesabına ait olan S3 klasörü, Talep Eden Ödemeler etkin olacak şekilde yapılandırılmışsa istekler ve indirmeler için paket sahibi yerine tüketiciden ücret alınır. Bu durumda, bu paketlerden veri okumak için bir Athena Spark oturumunu çağırırken veya düzenlerken aşağıdaki özelliği ekleyebilirsiniz:
{"spark.hadoop.fs.s3.useRequesterPaysHeader": "true"}
Amazon S3'teki verilerinizin şemasını çıkarın ve Veri Kataloğu'nda taranan tablolarla birleştirin
Spark, tablo yapısını anlamak için yalnızca Veri Kataloğu'nu incelemek yerine şemayı çıkarabilir ve verileri doğrudan depolama alanından okuyabilir. Bu özellik, veri analistlerinin ve veri bilimcilerinin, bir veritabanı veya tablo oluşturmaya gerek kalmadan veriler üzerinde hızlı bir araştırma yapmalarına olanak tanır; ancak bu, aynı veya farklı hesaplarda Veri Kataloğunda depolanan diğer mevcut tablolarla da kullanılabilir. Bunu yapmak için, bir veri çerçevesinde depolanan verilerin şemasını saklayan bir bellek içi veri yapısı olan Spark geçici görünümünü kullanırız.
2020 için NOAA veri kümesi bölümünü kullanarak S3 verilerini bir veri çerçevesine okuyarak geçici bir görünüm oluşturuyoruz:
Artık sorgulayabilirsiniz y20view Spark SQL'i sanki bir Data Catalog veritabanıymış gibi kullanmak:

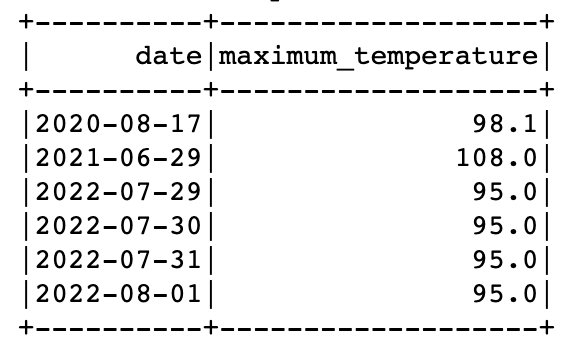
Spark'ta aynı sorguda hem geçici görünümlerden hem de Veri Kataloğu tablolarından verileri sorgulayabilirsiniz. Örneğin, artık 2021 ve 2022 yıllarına ait verileri içeren bir tablomuz ve 2020 verilerinin yer aldığı geçici bir görünümümüz olduğuna göre, her yıl için maksimum sıcaklığın kaydedildiği tarihleri bulabiliriz. 'SEATTLE TACOMA AIRPORT, WA US'.
Bunu yapmak için pencere fonksiyonunu ve UNION'u kullanabiliriz:
Spark SQL'de SQL'inizi UDF ile genişletin
Athena Spark'ta özel kullanıcı tanımlı bir işlevi kaydederek ve kullanarak SQL işlevselliğinizi genişletebilirsiniz. Bu UDF'ler, Spark SQL'de bulunan önceden tanımlanmış ortak işlevlere ek olarak kullanılır ve bir kez oluşturulduktan sonra belirli bir oturumda birçok kez yeniden kullanılabilir.
Bu bölümde, sayısal bir ay değerini tam ay adına dönüştüren basit bir UDF'yi inceleyeceğiz. UDF'yi Java veya Python'da yazma seçeneğiniz vardır.
Java tabanlı UDF
UDF'nin Java kodunu şu adreste bulabilirsiniz: GitHub deposu. Bu yazı için UDF'nin önceden oluşturulmuş bir JAR'ını yükledik. s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.jar.
UDF'yi kaydetmek için geçici bir işlev oluşturmak üzere Spark SQL'i kullanırız:
Python tabanlı UDF
Şimdi mevcut Spark oturumuna Python UDF'nin nasıl ekleneceğini görelim. UDF'nin Python kodunu şu adreste bulabilirsiniz: GitHub deposu. Bu yazı için kod şuraya yüklendi: s3://athena-examples-us-east-1/athenasparksqlblog/udf/month_number_to_name.py.
Python UDF'leri Spark SQL'e kaydedilemez; bunun yerine Python dosyasını eklemek, işlevi içe aktarmak ve ardından onu UDF olarak kaydetmek için küçük bir PySpark kodu parçası kullanırız:
SQL sorgularından görseller çizin
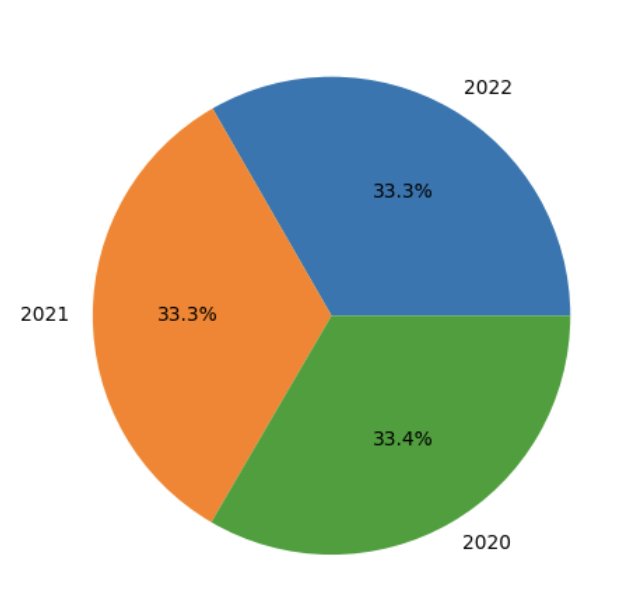
Veri araştırması için AWS hesapları dahil olmak üzere Spark SQL'i kullanmak kolaydır ve Athena Spark'ı UDF'lerle genişletmek karmaşık değildir. Şimdi verilerdeki kalıpları aramak amacıyla aynı Spark oturumundaki verileri görselleştirmek için Python kullanarak SQL'in ötesine nasıl geçebileceğimizi görelim. İstasyon için her yıl alınan okumaların yüzdesini gösteren bir pasta grafiği oluşturmak için daha önce oluşturulan tabloyu ve geçici görünümleri kullanırız. 'SEATTLE TACOMA AIRPORT, WA US'.
Bir SQL sorgusundan Spark veri çerçevesi oluşturup bunu pandas veri çerçevesine dönüştürerek başlayalım:
Temizlemek
Bu gönderi için oluşturulan kaynakları temizlemek için aşağıdaki adımları tamamlayın:
- Veritabanını ve tabloları Veri Kataloğundan silmek için not defterinin hücresinde aşağıdaki SQL ifadelerini çalıştırın:
- Çalışma grubunu sil bu yazı için oluşturuldu. Bu aynı zamanda çalışma grubunun parçası olan kayıtlı not defterlerini de siler.
- S3 klasörünü silin çalışma grubunun bir parçası olarak oluşturduğunuz.
Sonuç
Athena Spark, AWS Glue Data Catalog'daki veritabanlarını ve tabloları doğrudan Athena'daki Spark SQL aracılığıyla sorgulamayı ve hızlı veri keşfi için bir metastore'a ihtiyaç duymadan verileri doğrudan Amazon S3'ten sorgulamayı her zamankinden daha kolay hale getiriyor. Ayrıca, özel işlevler için UDF'lerin kaydedilmesi de dahil olmak üzere Spark SQL'de kullanılan yaygın ve gelişmiş SQL komutlarının kullanımını da kolaylaştırır. Ayrıca Athena Spark, Spark SQL aracılığıyla sorgulanan verileri görselleştirmek ve analiz etmek için hızlı başlangıçlı bir dizüstü bilgisayar ortamında Python'un kullanılmasını zahmetsiz hale getirir.
Genel olarak Spark SQL, Athena'da standart SQL'in ötesine geçme yeteneğinin kilidini açarak ileri düzey kullanıcılara tek bir entegre not defterinde hem SQL hem de Python aracılığıyla daha fazla esneklik ve güç sağlar ve altyapı kurulumu olmadan Amazon S3'te hızlı, karmaşık veri analizi sağlar. Athena Spark hakkında daha fazla bilgi edinmek için bkz. Apache Spark için Amazon Athena.
Yazarlar Hakkında
 Pathik Şah Amazon Athena'da Kıdemli Analitik Mimarıdır. AWS'ye 2015 yılında katıldı ve o zamandan bu yana büyük veri analitiği alanına odaklanarak müşterilerin AWS analiz hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler oluşturmasına yardımcı oluyor.
Pathik Şah Amazon Athena'da Kıdemli Analitik Mimarıdır. AWS'ye 2015 yılında katıldı ve o zamandan bu yana büyük veri analitiği alanına odaklanarak müşterilerin AWS analiz hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler oluşturmasına yardımcı oluyor.
 Raj Devnath Amazon Athena'da AWS'de Ürün Yöneticisidir. Müşterilerin sevdiği ürünler oluşturma ve müşterilerin verilerinden değer elde etmelerine yardımcı olma konusunda tutkulu. Geçmişi finans, perakende, akıllı binalar, ev otomasyonu ve veri iletişim sistemleri gibi çok sayıda son pazara yönelik çözümler sunmaktır.
Raj Devnath Amazon Athena'da AWS'de Ürün Yöneticisidir. Müşterilerin sevdiği ürünler oluşturma ve müşterilerin verilerinden değer elde etmelerine yardımcı olma konusunda tutkulu. Geçmişi finans, perakende, akıllı binalar, ev otomasyonu ve veri iletişim sistemleri gibi çok sayıda son pazara yönelik çözümler sunmaktır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/run-spark-sql-on-amazon-athena-spark/

