AWS destekli veri gölleri, benzersiz kullanılabilirlik ile desteklenir Amazon Basit Depolama Hizmeti (Amazon S3), farklı veri ve analiz yaklaşımlarını birleştirmek için gereken ölçeği, çevikliği ve esnekliği karşılayabilir. Veri göllerinin boyutu büyüdükçe ve kullanım olgunlaştıkça, verileri iş olaylarıyla tutarlı tutmak için önemli miktarda çaba harcanabilir. Dosyaların işlem açısından tutarlı bir şekilde güncellendiğinden emin olmak için giderek daha fazla müşteri, aşağıdaki gibi açık kaynaklı işlem tablosu formatlarını kullanıyor: Apaçi Buzdağı, Apaçi Hudi, ve Linux Vakfı Delta Gölü Verileri yüksek sıkıştırma oranlarıyla depolamanıza, uygulamalarınız ve çerçevelerinizle yerel olarak arayüz oluşturmanıza ve Amazon S3 üzerinde oluşturulan veri göllerinde artımlı veri işlemeyi basitleştirmenize yardımcı olur. Bu formatlar, ACID (atomiklik, tutarlılık, izolasyon, dayanıklılık) işlemlerini, yükseltmeleri ve silmeleri ve daha önce yalnızca veri ambarlarında mevcut olan zaman yolculuğu ve anlık görüntüler gibi gelişmiş özellikleri etkinleştirir. Her depolama formatı bu işlevselliği biraz farklı şekillerde uygular; bir karşılaştırma için bkz. AWS'deki işlemsel veri gölünüz için açık tablo formatı seçme.
2023 olarak, AWS genel kullanıma sunulduğunu duyurdu Apache Iceberg, Apache Hudi ve Linux Foundation Delta Lake için Apache Spark için Amazon Athenaayrı bir bağlayıcı veya ilgili bağımlılıklar kurma ve sürümleri yönetme ihtiyacını ortadan kaldırır ve bu çerçeveleri kullanmak için gereken yapılandırma adımlarını basitleştirir.
Bu yazıda size Spark SQL'in nasıl kullanılacağını göstereceğiz. Amazon Atina not defterleri ve Iceberg, Hudi ve Delta Lake tablo formatlarıyla çalışır. Athena'da Spark SQL kullanarak Amazon S3'te veritabanları ve tablolar oluşturma, tablolara veri ekleme, verileri sorgulama ve tabloların anlık görüntülerine bakma gibi ortak işlemleri gösteriyoruz.
Önkoşullar
Aşağıdaki ön koşulları tamamlayın:
Amazon S3'ten örnek not defterlerini indirin ve içe aktarın
Devam etmek için bu yazıda tartışılan not defterlerini aşağıdaki konumlardan indirin:
Not defterlerini indirdikten sonra aşağıdaki adımları izleyerek bunları Athena Spark ortamınıza aktarın. Bir not defterini içe aktarmak için bölümündeki bölüm Not defteri dosyalarını yönetme.
Belirli Açık Tablo Formatı bölümüne gidin
Buzdağı tablo formatıyla ilgileniyorsanız şuraya gidin: Apache Iceberg tablolarıyla çalışma Bölüm.
Hudi tablo formatıyla ilgileniyorsanız şuraya gidin: Apache Hudi tablolarıyla çalışma Bölüm.
Delta Lake tablo formatıyla ilgileniyorsanız şuraya gidin: Linux temeli Delta Lake tablolarıyla çalışma Bölüm.
Apache Iceberg tablolarıyla çalışma
Athena'da Spark not defterlerini kullanırken PySpark'ı kullanmanıza gerek kalmadan doğrudan SQL sorguları çalıştırabilirsiniz. Bunu, bir dizüstü bilgisayar hücresindeki hücrenin davranışını değiştiren özel başlıklar olan hücre büyülerini kullanarak yapıyoruz. SQL için şunları ekleyebiliriz: %%sql Bu büyü, tüm hücre içeriğini Athena'da çalıştırılacak bir SQL ifadesi olarak yorumlayacak.
Bu bölümde Apache Iceberg tablolarını oluşturmak, analiz etmek ve yönetmek için Apache Spark for Athena'da SQL'i nasıl kullanabileceğinizi gösteriyoruz.
Not defteri oturumu ayarlama
Athena'da Apache Iceberg'i kullanmak için bir oturum oluştururken veya düzenlerken Apaçi Buzdağı seçeneği genişleterek Apache Spark'ın özellikleri bölüm. Aşağıdaki ekran görüntüsünde gösterildiği gibi özellikleri önceden dolduracaktır.
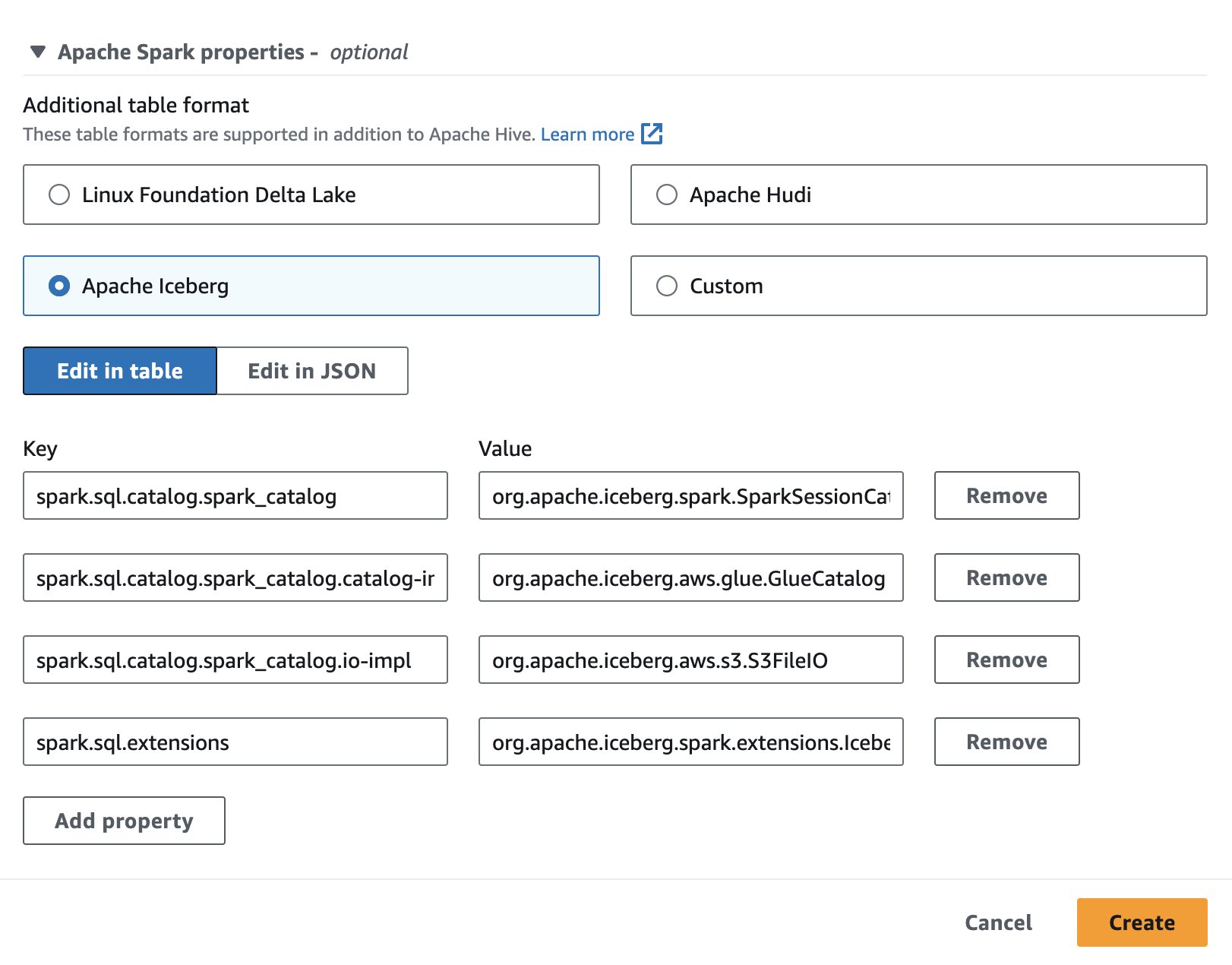
Adımlar için bkz. Oturum ayrıntılarını düzenleme or Kendi not defterinizi oluşturma.
Bu bölümde kullanılan kod şu adreste mevcuttur: SparkSQL_iceberg.ipynb takip edilecek dosya.
Bir veritabanı ve Buzdağı tablosu oluşturun
Öncelikle AWS Glue Data Catalog'da bir veritabanı oluşturuyoruz. Aşağıdaki SQL ile adında bir veritabanı oluşturabiliriz. icebergdb:
Daha sonra veritabanında icebergdbadında bir Buzdağı tablosu oluşturuyoruz. noaa_iceberg Amazon S3'te verileri yükleyeceğimiz bir konumu işaret ediyor. Aşağıdaki ifadeyi çalıştırın ve konumu değiştirin s3://<your-S3-bucket>/<prefix>/ S3 klasörünüz ve önekiniz ile:
Tabloya veri ekleme
doldurmak için noaa_iceberg Buzdağı tablosuna Parke tablosundan veri ekliyoruz sparkblogdb.noaa_pq Bu, önkoşulların bir parçası olarak oluşturuldu. Bunu bir kullanarak yapabilirsiniz TAKIN Spark'taki ifade:
Alternatif olarak, kullanabilirsiniz SEÇİM OLARAK TABLO OLUŞTUR Bir Buzdağı tablosu oluşturmak ve tek adımda kaynak tablodan veri eklemek için USING buzdağı cümleciğiyle:
Buzdağı tablosunu sorgula
Artık veriler Buzdağı tablosuna eklendiğine göre analiz etmeye başlayabiliriz. Yıllara göre kaydedilen minimum sıcaklığı bulmak için bir Spark SQL çalıştıralım. 'SEATTLE TACOMA AIRPORT, WA US' Konumu:
Aşağıdaki çıktıyı alıyoruz.

Buzdağı tablosundaki verileri güncelleme
Tablomuzdaki verileri nasıl güncelleyeceğimize bakalım. İstasyon adını güncellemek istiyoruz 'SEATTLE TACOMA AIRPORT, WA US' için 'Sea-Tac'. Spark SQL'i kullanarak bir çalıştırabiliriz. GÜNCELLEME Buzdağı tablosuna karşı açıklama:
Daha sonra minimum kaydedilen sıcaklığı bulmak için önceki SELECT sorgusunu çalıştırabiliriz. 'Sea-Tac' Konumu:
Aşağıdaki çıktıyı alıyoruz.

Kompakt veri dosyaları
Iceberg gibi açık tablo formatları, dosya depolamada delta değişiklikleri oluşturarak ve bildirim dosyaları aracılığıyla satır sürümlerini izleyerek çalışır. Daha fazla veri dosyası, bildirim dosyalarında daha fazla meta verinin depolanmasına yol açar ve küçük veri dosyaları genellikle gereksiz miktarda meta veriye neden olarak daha az verimli sorgulara ve daha yüksek Amazon S3 erişim maliyetlerine neden olur. Buzdağının Çalıştırılması rewrite_data_files Spark for Athena'daki prosedür, birçok küçük delta değişiklik dosyasını daha küçük bir okuma için optimize edilmiş Parke dosyaları kümesinde birleştirerek veri dosyalarını sıkıştıracaktır. Dosyaların sıkıştırılması, sorgulandığında okuma işlemini hızlandırır. Tablomuzda sıkıştırmayı çalıştırmak için aşağıdaki Spark SQL'i çalıştırın:
rewrite_data_files seçenekler sunar Verilerin yeniden düzenlenmesine ve sıkıştırılmasına yardımcı olabilecek sıralama stratejinizi belirlemek için.
Tablo anlık görüntülerini listeleme
Bir Iceberg tablosundaki her yazma, güncelleme, silme, yükseltme ve sıkıştırma işlemi, tablonun yeni bir anlık görüntüsünü oluştururken, anlık görüntü izolasyonu ve zaman yolculuğu için eski verileri ve meta verileri ortalıkta tutar. Bir Iceberg tablosunun anlık görüntülerini listelemek için aşağıdaki Spark SQL deyimini çalıştırın:
Eski anlık görüntülerin süresinin dolması
Artık gerekmeyen veri dosyalarını silmek ve tablo meta verilerinin boyutunu küçük tutmak için düzenli olarak süresi dolan anlık görüntülerin kullanılması önerilir. Süresi dolmamış bir anlık görüntünün hala gerekli olduğu dosyaları asla kaldırmaz. Spark for Athena'da, tablonun anlık görüntülerinin süresinin dolmasını sağlamak için aşağıdaki SQL'i çalıştırın icebergdb.noaa_iceberg belirli bir zaman damgasından daha eski olanlar:
Zaman damgası değerinin biçiminde bir dize olarak belirtildiğini unutmayın. yyyy-MM-dd HH:mm:ss.fff. Çıktı, silinen veri ve meta veri dosyalarının sayısını verecektir.
Tabloyu ve veritabanını bırakın
Bu alıştırmayı kullanarak Amazon S3'teki Iceberg tablolarını ve ilgili verileri temizlemek için aşağıdaki Spark SQL'i çalıştırabilirsiniz:
Icebergdb veritabanını kaldırmak için aşağıdaki Spark SQL'i çalıştırın:
Spark for Athena'yı kullanarak Iceberg tablolarında gerçekleştirebileceğiniz tüm işlemler hakkında daha fazla bilgi edinmek için bkz. Kıvılcım Sorguları ve Kıvılcım Prosedürleri Iceberg belgelerinde.
Apache Hudi tablolarıyla çalışma
Daha sonra, Apache Hudi tablolarını oluşturmak, analiz etmek ve yönetmek için Spark for Athena'da SQL'i nasıl kullanabileceğinizi göstereceğiz.
Not defteri oturumu ayarlama
Athena'da Apache Hudi'yi kullanmak için bir oturum oluştururken veya düzenlerken Apaçi Hudi seçeneği genişleterek Apache Spark'ın özellikleri Bölüm.
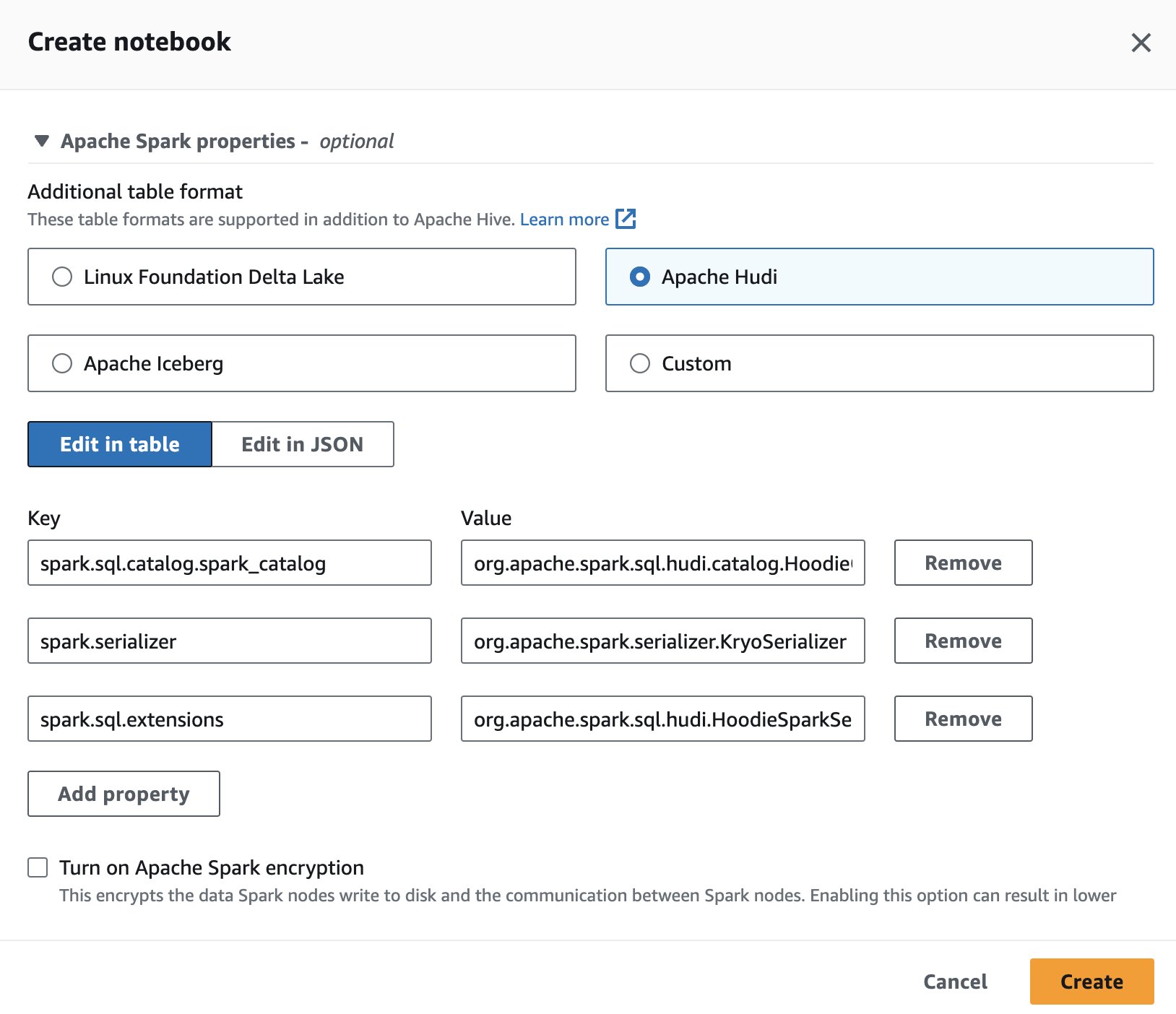
Adımlar için bkz. Oturum ayrıntılarını düzenleme or Kendi not defterinizi oluşturma.
Bu bölümde kullanılan kod şu adreste mevcut olmalıdır: SparkSQL_hudi.ipynb takip edilecek dosya.
Bir veritabanı ve Hudi tablosu oluşturun
Öncelikle adında bir veritabanı oluşturuyoruz. hudidb AWS Glue Data Catalog'da saklanacak ve ardından Hudi tablosu oluşturulacak:
Amazon S3’te veriyi yükleyeceğimiz lokasyona işaret eden bir Hudi tablosu oluşturuyoruz. Tablonun şu şekilde olduğunu unutmayın: yazma üzerine kopyalama tip. Tarafından tanımlanır type= 'cow' DDL tablosunda. İstasyon ve tarihi birden fazla birincil anahtar olarak, preCombinedField'ı ise yıl olarak tanımladık. Ayrıca tablo yıllara göre bölümlendirilmiştir. Aşağıdaki ifadeyi çalıştırın ve konumu değiştirin s3://<your-S3-bucket>/<prefix>/ S3 klasörünüz ve önekiniz ile:
Tabloya veri ekleme
Iceberg'de olduğu gibi, şunu kullanıyoruz: TAKIN tablodaki verileri okuyarak tabloyu doldurma ifadesi sparkblogdb.noaa_pq önceki gönderide oluşturulan tablo:
Hudi tablosunu sorgula
Artık tablo oluşturulduğuna göre, oda için kaydedilen maksimum sıcaklığı bulmak için bir sorgu çalıştıralım. 'SEATTLE TACOMA AIRPORT, WA US' Konumu:
Hudi tablosundaki verileri güncelleyin
İstasyon adını değiştirelim 'SEATTLE TACOMA AIRPORT, WA US' için 'Sea–Tac'. Athena için Spark'ta bir UPDATE ifadesi çalıştırabiliriz. güncelleştirme kayıtları noaa_hudi tablosu:
Kaydedilen maksimum sıcaklığı bulmak için önceki SELECT sorgusunu çalıştırıyoruz. 'Sea-Tac' Konumu:
Zaman yolculuğu sorgularını çalıştırma
Geçmiş veri anlık görüntülerini analiz etmek için Athena'da SQL'de zaman yolculuğu sorgularını kullanabiliriz. Örneğin:
Bu sorgu geçmişteki belirli bir zamana ait Seattle Havaalanı sıcaklık verilerini kontrol eder. Zaman damgası maddesi mevcut verileri değiştirmeden geriye gitmemizi sağlar. Zaman damgası değerinin biçiminde bir dize olarak belirtildiğini unutmayın. yyyy-MM-dd HH:mm:ss.fff.
Kümelemeyle sorgu hızını optimize edin
Sorgu performansını artırmak için şunları gerçekleştirebilirsiniz: kümeleme Athena için Spark'ta SQL kullanan Hudi tablolarında:
Kompakt masalar
Sıkıştırma, temel dosyanın yeni bir sürümünü oluşturmak için satır tabanlı günlük dosyalarından ilgili sütun tabanlı temel dosyaya güncellemeleri periyodik olarak birleştirmek için Hudi tarafından özellikle Okumada Birleştir (MOR) tablolarında kullanılan bir tablo hizmetidir. Sıkıştırma Yazıldığında Kopyala (COW) tabloları için geçerli değildir ve yalnızca MOR tabloları için geçerlidir. MOR tablolarında sıkıştırma gerçekleştirmek için Spark for Athena'da aşağıdaki sorguyu çalıştırabilirsiniz:
Tabloyu ve veritabanını bırakın
Oluşturduğunuz Hudi tablosunu ve ilişkili verileri Amazon S3 konumundan kaldırmak için aşağıdaki Spark SQL'i çalıştırın:
Veritabanını kaldırmak için aşağıdaki Spark SQL'i çalıştırın hudidb:
Spark for Athena kullanarak Hudi tablolarında gerçekleştirebileceğiniz tüm işlemler hakkında bilgi edinmek için bkz. SQL DDL'si ve Prosedürleri Hudi belgelerinde.
Linux temeli Delta Lake tablolarıyla çalışma
Daha sonra Delta Lake tablolarını oluşturmak, analiz etmek ve yönetmek için Spark for Athena'da SQL'i nasıl kullanabileceğinizi göstereceğiz.
Not defteri oturumu ayarlama
Bir oturum oluştururken veya düzenlerken Spark for Athena'da Delta Lake'i kullanmak için Linux Vakfı Delta Gölü genişleterek Apache Spark'ın özellikleri Bölüm.

Adımlar için bkz. Oturum ayrıntılarını düzenleme or Kendi not defterinizi oluşturma.
Bu bölümde kullanılan kod şu adreste mevcut olmalıdır: SparkSQL_delta.ipynb takip edilecek dosya.
Veritabanı ve Delta Lake tablosu oluşturma
Bu bölümde AWS Glue Data Catalog'da bir veritabanı oluşturuyoruz. Aşağıdaki SQL'i kullanarak, adında bir veritabanı oluşturabiliriz. deltalakedb:
Daha sonra veritabanında deltalakedbadında bir Delta Lake tablosu oluşturuyoruz. noaa_delta Amazon S3'te verileri yükleyeceğimiz bir konumu işaret ediyor. Aşağıdaki ifadeyi çalıştırın ve konumu değiştirin s3://<your-S3-bucket>/<prefix>/ S3 klasörünüz ve önekiniz ile:
Tabloya veri ekleme
Biz kullanıyoruz TAKIN tablodaki verileri okuyarak tabloyu doldurma ifadesi sparkblogdb.noaa_pq önceki gönderide oluşturulan tablo:
Delta Lake tablosu oluşturmak ve kaynak tablodan tek sorguya veri eklemek için CREATE TABLE AS SELECT seçeneğini de kullanabilirsiniz.
Delta Lake tablosunu sorgulayın
Artık veriler Delta Lake tablosuna eklendiğine göre analiz etmeye başlayabiliriz. Kaydedilen minimum sıcaklığı bulmak için bir Spark SQL çalıştıralım. 'SEATTLE TACOMA AIRPORT, WA US' Konumu:
Delta gölü tablosundaki verileri güncelleme
İstasyon adını değiştirelim 'SEATTLE TACOMA AIRPORT, WA US' için 'Sea–Tac'. Çalıştırabiliriz GÜNCELLEME Athena'nın kayıtlarını güncellemek için Spark'a ilişkin açıklama noaa_delta tablosu:
Kaydedilen minimum sıcaklığı bulmak için önceki SELECT sorgusunu çalıştırabiliriz. 'Sea-Tac' konum ve sonuç öncekiyle aynı olmalıdır:
Kompakt veri dosyaları
Athena için Spark'ta, küçük dosyaları daha büyük dosyalara sıkıştıracak olan Delta Lake tablosunda OPTIMIZE'ı çalıştırabilirsiniz, böylece sorgular küçük dosya yükünün yükünü taşımaz. Sıkıştırma işlemini gerçekleştirmek için aşağıdaki sorguyu çalıştırın:
Bakın Optimizasyonları OPTIMIZE çalıştırılırken kullanılabilen farklı seçenekler için Delta Lake belgelerinde.
Artık Delta Lake tablosu tarafından referans verilmeyen dosyaları kaldırın
Amazon S3'te depolanan, artık bir Delta Lake tablosu tarafından başvurulmayan ve saklama eşiğinden daha eski olan dosyaları, Spark for Athena'yı kullanarak tablodaki VACCUM komutunu çalıştırarak kaldırabilirsiniz:
Bakın Artık Delta tablosu tarafından referans verilmeyen dosyaları kaldırın VACUUM ile kullanılabilen seçenekler için Delta Lake belgelerinde.
Tabloyu ve veritabanını bırakın
Oluşturduğunuz Delta Lake tablosunu kaldırmak için aşağıdaki Spark SQL'i çalıştırın:
Veritabanını kaldırmak için aşağıdaki Spark SQL'i çalıştırın deltalakedb:
DROP TABLE DDL'nin Delta Lake tablosunda ve veritabanında çalıştırılması bu nesnelerin meta verilerini siler ancak Amazon S3'teki veri dosyalarını otomatik olarak silmez. Verileri S3 konumundan silmek için not defterinin hücresinde aşağıdaki Python kodunu çalıştırabilirsiniz:
Spark for Athena'yı kullanarak Delta Lake tablosunda çalıştırabileceğiniz SQL ifadeleri hakkında daha fazla bilgi edinmek için bkz. hızlı başlangıç Delta Lake belgelerinde.
Sonuç
Bu gönderi, veritabanları ve tablolar oluşturmak, verileri eklemek ve sorgulamak ve Hudi, Delta Lake ve Iceberg tablolarında güncellemeler, sıkıştırmalar ve zaman yolculuğu gibi ortak işlemleri gerçekleştirmek için Athena not defterlerinde Spark SQL'in nasıl kullanılacağını gösterdi. Açık tablo formatları, veri göllerine ACID işlemleri, artışlar ve silmeler ekleyerek ham nesne depolama sınırlamalarının üstesinden gelir. Spark on Athena'nın yerleşik entegrasyonu, ayrı bağlayıcılar kurma ihtiyacını ortadan kaldırarak, Amazon S3'te güvenilir veri gölleri oluşturmak için bu popüler çerçeveleri kullanırken yapılandırma adımlarını ve yönetim yükünü azaltır. Data lake iş yükleriniz için açık tablo formatı seçme hakkında daha fazla bilgi edinmek için bkz. AWS'deki işlemsel veri gölünüz için açık tablo formatı seçme.
Yazarlar Hakkında
![]() Pathik Şah Amazon Athena'da Kıdemli Analitik Mimarıdır. AWS'ye 2015 yılında katıldı ve o zamandan bu yana büyük veri analitiği alanına odaklanarak müşterilerin AWS analiz hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler oluşturmasına yardımcı oluyor.
Pathik Şah Amazon Athena'da Kıdemli Analitik Mimarıdır. AWS'ye 2015 yılında katıldı ve o zamandan bu yana büyük veri analitiği alanına odaklanarak müşterilerin AWS analiz hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler oluşturmasına yardımcı oluyor.
![]() Raj Devnath Amazon Athena'da AWS'de Ürün Yöneticisidir. Müşterilerin sevdiği ürünler oluşturma ve müşterilerin verilerinden değer elde etmelerine yardımcı olma konusunda tutkulu. Geçmişi finans, perakende, akıllı binalar, ev otomasyonu ve veri iletişim sistemleri gibi çok sayıda son pazara yönelik çözümler sunmaktır.
Raj Devnath Amazon Athena'da AWS'de Ürün Yöneticisidir. Müşterilerin sevdiği ürünler oluşturma ve müşterilerin verilerinden değer elde etmelerine yardımcı olma konusunda tutkulu. Geçmişi finans, perakende, akıllı binalar, ev otomasyonu ve veri iletişim sistemleri gibi çok sayıda son pazara yönelik çözümler sunmaktır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/

